使用决策树分类
任务描述
本关任务:使用决策树进行分类
相关知识
为了完成本关任务,你需要掌握:1.使用决策树进行分类
使用决策树进行分类
依靠训练数据构造了决策树之后,我们可以将它用于实际数据的分类。在执行数据分类时,需要决策树以及用于构造树的标签向量。然后,程序比较测试数据与决策树上的数值,递归执行该过程直到进人叶子节点;最后将测试数据定义为叶子节点所属的类型。 使用决策树的分类函数如下:
"""Parameters:inputTree - 已经生成的决策树featLabels - 存储选择的最优特征标签testVec - 测试数据列表,顺序对应最优特征标签Returns:classLabel - 分类结果"""# 函数说明:使用决策树分类def classify(inputTree, featLabels, testVec):firstStr = next(iter(inputTree)) #获取决策树结点secondDict = inputTree[firstStr] #下一个字典featIndex = featLabels.index(firstStr)for key in secondDict.keys():if testVec[featIndex] == key:if type(secondDict[key]).__name__ == 'dict':classLabel = classify(secondDict[key], featLabels, testVec)else: classLabel = secondDict[key]return classLabel
编程要求
根据提示,在右侧编辑器补充代码,运用决策树分类
测试说明
平台会对你编写的代码进行测试:
开始你的任务吧,祝你成功!
完整代码如下:
# -*- coding: UTF-8 -*-
from math import log
import operator"""
Parameters:dataSet - 数据集
Returns:shannonEnt - 经验熵(香农熵)
"""
# 函数说明:计算给定数据集的经验熵(香农熵)
def calcShannonEnt(dataSet):numEntires = len(dataSet) #返回数据集的行数labelCounts = {} #保存每个标签(Label)出现次数的字典for featVec in dataSet: #对每组特征向量进行统计currentLabel = featVec[-1] #提取标签(Label)信息if currentLabel not in labelCounts.keys(): #如果标签(Label)没有放入统计次数的字典,添加进去labelCounts[currentLabel] = 0labelCounts[currentLabel] += 1 #Label计数shannonEnt = 0.0 #经验熵(香农熵)for key in labelCounts: #计算香农熵prob = float(labelCounts[key]) / numEntires#选择该标签(Label)的概率shannonEnt -= prob * log(prob, 2) #利用公式计算return shannonEnt #返回经验熵(香农熵)"""
Parameters:无
Returns:dataSet - 数据集labels - 特征标签
"""
# 函数说明:创建测试数据集
def createDataSet():dataSet = [[0, 0, 0, 0, 'no'],#数据集[0, 0, 0, 1, 'no'],[0, 1, 0, 1, 'yes'],[0, 1, 1, 0, 'yes'],[0, 0, 0, 0, 'no'],[1, 0, 0, 0, 'no'],[1, 0, 0, 1, 'no'],[1, 1, 1, 1, 'yes'],[1, 0, 1, 2, 'yes'],[1, 0, 1, 2, 'yes'],[2, 0, 1, 2, 'yes'],[2, 0, 1, 1, 'yes'],[2, 1, 0, 1, 'yes'],[2, 1, 0, 2, 'yes'],[2, 0, 0, 0, 'no']]labels = ['年龄', '有工作', '有自己的房子', '信贷情况']#特征标签return dataSet, labels#返回数据集和分类属性"""
Parameters:dataSet - 待划分的数据集axis - 划分数据集的特征value - 需要返回的特征的值
Returns:无
"""
# 函数说明:按照给定特征划分数据集
def splitDataSet(dataSet, axis, value):retDataSet = [] #创建返回的数据集列表for featVec in dataSet: #遍历数据集if featVec[axis] == value:reducedFeatVec = featVec[:axis] #去掉axis特征reducedFeatVec.extend(featVec[axis+1:])#将符合条件的添加到返回的数据集retDataSet.append(reducedFeatVec)return retDataSet #返回划分后的数据集"""
Parameters:dataSet - 数据集
Returns:bestFeature - 信息增益最大的(最优)特征的索引值
"""
# 函数说明:选择最优特征
def chooseBestFeatureToSplit(dataSet):numFeatures = len(dataSet[0]) - 1 #特征数量baseEntropy = calcShannonEnt(dataSet) #计算数据集的香农熵bestInfoGain = 0.0 #信息增益bestFeature = -1 #最优特征的索引值for i in range(numFeatures): #遍历所有特征#获取dataSet的第i个所有特征featList = [example[i] for example in dataSet]uniqueVals = set(featList) #创建set集合{},元素不可重复newEntropy = 0.0 #经验条件熵for value in uniqueVals: #计算信息增益subDataSet = splitDataSet(dataSet, i, value) #subDataSet划分后的子集prob = len(subDataSet) / float(len(dataSet)) #计算子集的概率newEntropy += prob * calcShannonEnt(subDataSet)#根据公式计算经验条件熵infoGain = baseEntropy - newEntropy #信息增益# print("第%d个特征的增益为%.3f" % (i, infoGain)) #打印每个特征的信息增益if (infoGain > bestInfoGain): #计算信息增益bestInfoGain = infoGain #更新信息增益,找到最大的信息增益bestFeature = i #记录信息增益最大的特征的索引值return bestFeature #返回信息增益最大的特征的索引值"""
Parameters:classList - 类标签列表
Returns:sortedClassCount[0][0] - 出现此处最多的元素(类标签)
"""
# 函数说明:统计classList中出现此处最多的元素(类标签)
def majorityCnt(classList):classCount = {}for vote in classList: #统计classList中每个元素出现的次数if vote not in classCount.keys():classCount[vote] = 0classCount[vote] += 1sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)#根据字典的值降序排序return sortedClassCount[0][0] #返回classList中出现次数最多的元素"""
Parameters:dataSet - 训练数据集labels - 分类属性标签featLabels - 存储选择的最优特征标签
Returns:myTree - 决策树
"""
# 函数说明:创建决策树
def createTree(dataSet, labels, featLabels):classList = [example[-1] for example in dataSet] #取分类标签(是否放贷:yes or no)if classList.count(classList[0]) == len(classList): #如果类别完全相同则停止继续划分return classList[0]if len(dataSet[0]) == 1: #遍历完所有特征时返回出现次数最多的类标签return majorityCnt(classList)bestFeat = chooseBestFeatureToSplit(dataSet) #选择最优特征bestFeatLabel = labels[bestFeat] #最优特征的标签featLabels.append(bestFeatLabel)myTree = {bestFeatLabel:{}} #根据最优特征的标签生成树del(labels[bestFeat]) #删除已经使用特征标签featValues = [example[bestFeat] for example in dataSet]#得到训练集中所有最优特征的属性值uniqueVals = set(featValues) #去掉重复的属性值for value in uniqueVals: #遍历特征,创建决策树。myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), labels, featLabels)return myTree"""
Parameters:inputTree - 已经生成的决策树featLabels - 存储选择的最优特征标签testVec - 测试数据列表,顺序对应最优特征标签
Returns:classLabel - 分类结果
"""
# 函数说明:使用决策树分类
def classify(inputTree, featLabels, testVec):firstStr = next(iter(inputTree)) #获取决策树结点secondDict = inputTree[firstStr] #下一个字典featIndex = featLabels.index(firstStr)for key in secondDict.keys():if testVec[featIndex] == key:if type(secondDict[key]).__name__ == 'dict':classLabel = classify(secondDict[key], featLabels, testVec)else: classLabel = secondDict[key]return classLabelif __name__ == '__main__':##########请输入你的代码dataSet, labels = createDataSet() #得到数据集featLabels = []myTree = createTree(dataSet, labels, featLabels) #创造树testVec = [0,1] #测试数据result = classify(myTree, featLabels, testVec) #进行分类#########if result == 'yes':print('放贷')if result == 'no':print('不放贷')相关文章:

使用决策树分类
任务描述 本关任务:使用决策树进行分类 相关知识 为了完成本关任务,你需要掌握:1.使用决策树进行分类 使用决策树进行分类 依靠训练数据构造了决策树之后,我们可以将它用于实际数据的分类。在执行数据分类时,需要…...
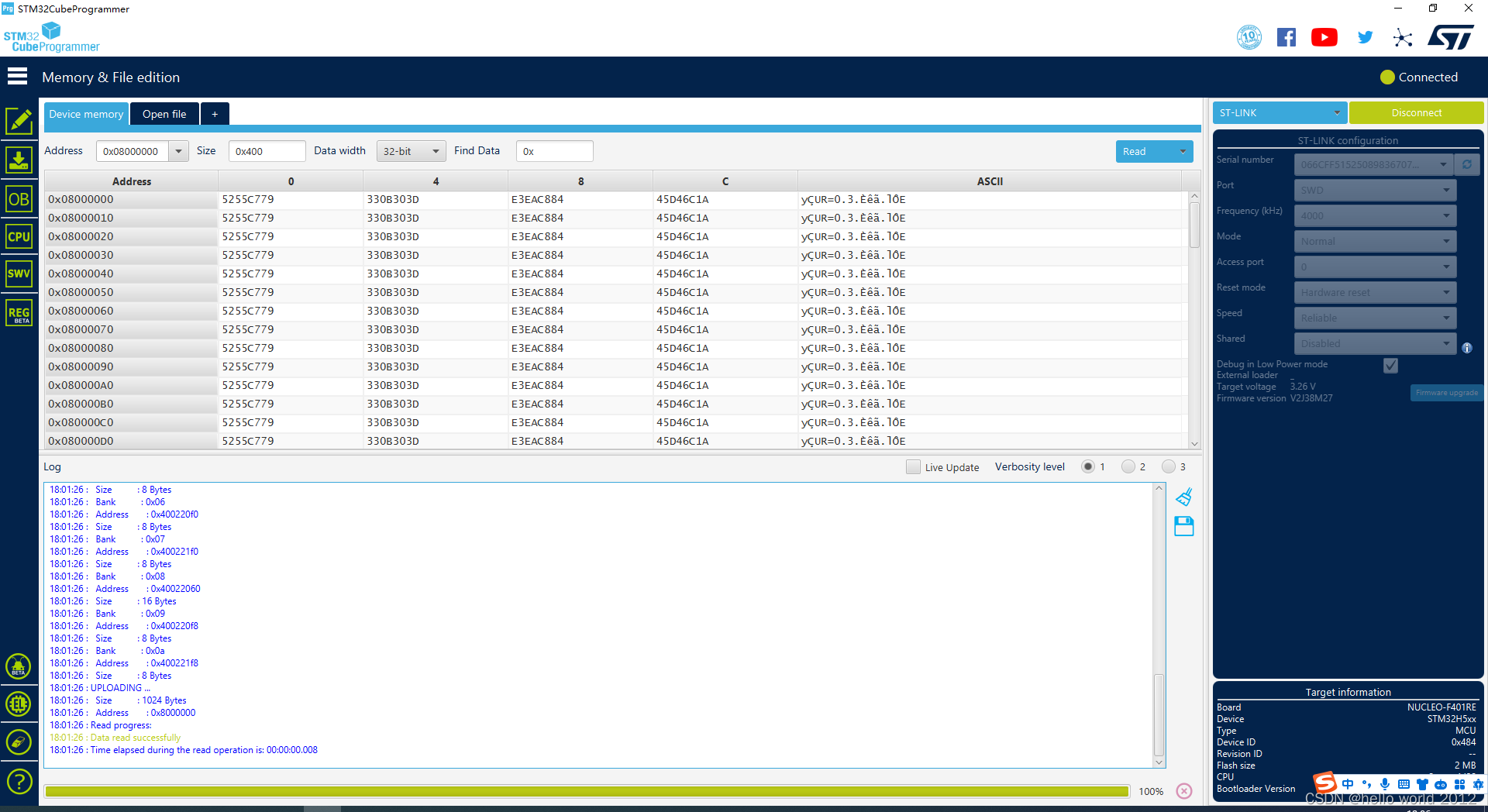
STM32H563烧录后无法擦除
STM32H563烧录后无法擦除,使用STM32CubeProgrammer连接后显示如下图所示。...

2023最新最全【Adobe After Effection 2023】下载安装零基础教程【附安装包】
AE2023下载点这里 教学 1.鼠标右击【Ae2023(64bit)】压缩包选择(win11系统需先点击“显示更多选项”)【解压到 Ae2023(64bit)】。 2.打开解压后的文件夹,鼠标右击【Set-up】选择【以管理员身份运行】。 3.点击【文件夹图标】,…...

【Spring之底层核心架构概念解析】
文章目录 一、BeanDefinition二、BeanDefinitionReader2.1、AnnotatedBeanDefinitionReader2.2、XmlBeanDefinitionReader 五、ClassPathBeanDefinitionScanner六、BeanFactory七、ApplicationContext7.1、AnnotationConfigApplicationContext7.2、ClassPathXmlApplicationCont…...
手把手带你创建一个自己的GPTs
大家好,我是五竹。 最近GPT又进行了大升级,这一下又甩了国内AI几条街,具体更新了哪些内容之前的一篇文章中其实已经说过了:ChatGPT 王炸升级!更强版 GPT-4 上线! 其中最重要的一点就是支持自定义GPT&…...

Vue 组件+es6箭头函数+路由
一、组件 1、让网页或局部页实现复用,包括js(vue)功能 组件(Component)是 Vue.js 最强大的功能之一。组件可以扩展 HTML 元素,封装可重用的代码。在较高层面上,组件是自定义元素, …...
Clickhouse学习笔记(5)—— ClickHouse 副本
Data Replication | ClickHouse Docs 副本的目的主要是保障数据的高可用性,即使一台 ClickHouse 节点宕机,那么也可以从其他服务器获得相同的数据 注意: clickhouse副本机制的实现要基于zookeeperclickhouse的副本机制只适用于MergeTree f…...
的优缺点进行对比)
ELMo模型、word2vec、独热编码(one-hot编码)的优缺点进行对比
下面是对ELMo模型、word2vec和独热编码(one-hot编码)的优缺点进行对比: 独热编码(One-hot Encoding): 优点: 简单,易于理解。适用于词汇表较小的场景。 缺点: 高维度…...
FFmpeg简介1
适逢FFmpeg6.1发布,准备深入学习下FFmpeg,将会写下系列学习记录。 在此列出主要学习资料,后续再不列,感谢这些大神的探路和分享,特别是雷神,致敬! 《FFmpeg从入门到精通》 《深入理解FFmpeg》 …...

2352 智能社区医院管理系统JSP【程序源码+文档+调试运行】
摘要 本文介绍了一个智能社区医院管理系统的设计和实现。该系统包括管理员、护工和医生三种用户,具有社区资料管理、药品管理、挂号管理和系统管理等功能。通过数据库设计和界面设计,实现了用户友好的操作体验和数据管理。经过测试和优化,系…...
(续))
高教社杯数模竞赛特辑论文篇-2023年B题:多波束测线布设(附获奖论文及MATLAB代码实现)(续)
目录 5.3.3 模拟退火对测线布设仿真检验 5.3.4 开角、坡度的灵敏度分析...
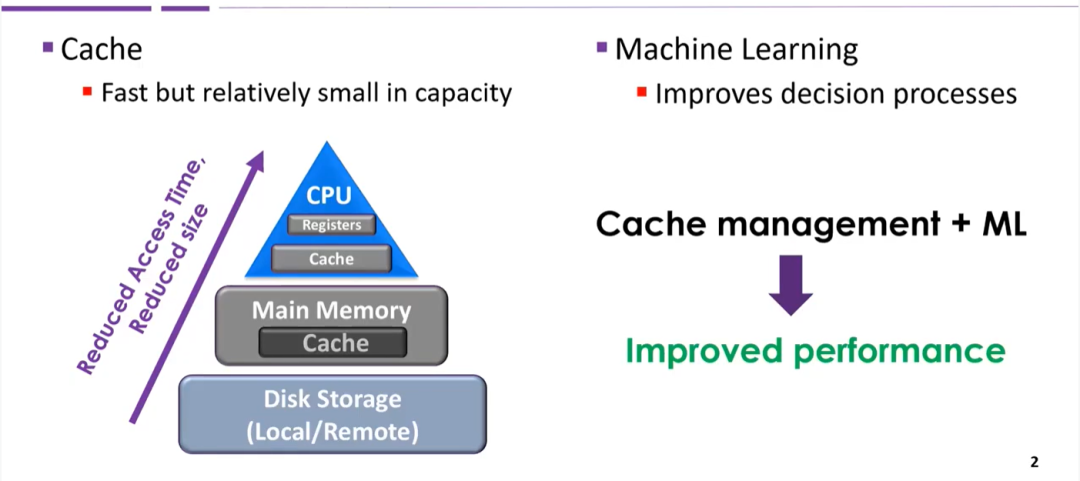
【fast2021论文导读】 Learning Cache Replacement with Cacheus
文章:Learning Cache Replacement with Cacheus 导读摘要: 机器学习的最新进展为解决计算系统中的经典问题开辟了新的、有吸引力的方法。对于存储系统,缓存替换是一个这样的问题,因为它对性能有巨大的影响。 本文第一个贡献,确定了与缓存相关的特征,特别是,四种工作负载…...

在 React 中选择使用 JSX 或 JavaScript
在 React 中选择使用 JSX 或 JavaScript JSX vs. JavaScriptReact Component Lifecycle JSX 是 React 最常用的语法之一,它允许我们在 HTML 中嵌入 JavaScript 语句和表达式。但是,如果我们不需要 JSX 又该怎么办呢?让我们一起来了解一下 J…...
Halcon WPF 开发学习笔记(4):Halcon 锚点坐标打印
文章目录 专栏前言锚点二次开发添加回调函数辅助Model类 下集预告 专栏 Halcon开发 博客专栏 WPF/HALCON机器视觉合集 前言 Halcon控件C#开发是我们必须掌握的,因为只是单纯的引用脚本灵活性过低,我们要拥有Halcon辅助开发的能力 锚点开发是我们常用的…...

【从0到1设计一个网关】性能优化---使用Disruptor提供缓冲区
文章目录 什么是缓冲区队列Disruptor高性能的原因Disruptor实战注:学习这篇文章之前推荐先对Disruptor的使用有了解,否则我的代码中即使有非常详细的注释你也并不能理解这些注释的作用,以及为什么我要需要这样子编写代码。 同时,这将会是网关系列最后一篇文章,由于文章写的…...

Redis 特殊数据类型
目录 1、redis地理空间(GEO) 2、redis基数统计(HyperLogLog) 3、redis位图(bitmap) 4、redis位域bitfield) 5、redis流(Stream) 1、redis地理空间(GEO) Redis 的地理空间数据结构(GEO)可以用于存储地理位置信息,并支持附近位置搜索等功能…...

【Windows网络编程】二.TCP套接字编程与主机上线实验
API: socket: 套接字函数创建绑定到特定传输服务提供程序的套接字。 函数原型:SOCKET WSAAPI socket([in] int af,[in] int type,[in] int protocol );参数: af:地址规范系列: AF_INET:IPv4&…...
Qt 事件循环
引出 UI程序之所叫UI程序,是因为需要与用户有交互,用户交互一般是通过鼠标键盘等的输入设备,那UI程序就需要有能随时响应用户交互的能力。 一个C程序的main函数大概是下面这样: int main() {...return 0; } 我们如何使程序能随…...

【趣味随笔】YOLO的“进化史”极简版(YOLO v1-->YOLOP)
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...

dateutil高级用法:如何自定义解析器、扩展时区功能和创建复杂规则
dateutil高级用法:如何自定义解析器、扩展时区功能和创建复杂规则 【免费下载链接】dateutil Useful extensions to the standard Python datetime features 项目地址: https://gitcode.com/gh_mirrors/da/dateutil dateutil是Python中一个强大的日期时间处理…...

AI Coding越来越强,我们还有必要学Processing吗? · 创意编程嚼
故障表现 发现请求集群 demo 入口时卡住,并且对应 Pod 没有新的日志输出 rootce-demo-1:~# kubectl get pods -n deepflow-otel-spring-demo -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NO…...

RP2040上的CBUS协议栈:CAN总线模型铁路通信实现
1. CBUSACAN2040 库深度解析:面向 RP2040 平台的 MERG CBUS 协议栈实现1.1 项目定位与工程价值CBUSACAN2040 是一个专为 Raspberry Pi Pico(RP2040)系列微控制器设计的嵌入式通信库,其核心使命是将英国模型铁路电子组织 MERG&…...

如何高效查询数据库中一对多关联的多项选择字段
本文讲解如何通过规范化数据库设计与标准 sql 关联查询,准确获取农民注册信息及其多个专业领域(多对一/一对多关系),解决因表结构不合理导致的查询失败问题。 本文讲解如何通过规范化数据库设计与标准 sql 关联查询,准…...

中小工厂人手少、员工文化不高,选这款ERP,工人半天就能学会
开中小工厂最头疼的是什么?规模不大、人手有限,车间工人、仓库管理员文化水平不高,想上 ERP 管生产、管库存,又怕太复杂学不会、用不起来。其实不用纠结,选对软件,普通员工也能快速上手,今天就给…...

OpenClaw安全实践:Gemma-3-12b-it本地化保障敏感数据处理
OpenClaw安全实践:Gemma-3-12b-it本地化保障敏感数据处理 1. 为什么选择本地化部署 去年我在处理一批财务数据时,曾尝试使用某云端大模型服务进行报表分析。当系统提示"您的数据将被传输至第三方服务器进行处理"时,那种对敏感信息…...

从零入门性能测试:理论+JMETER实操,看完就能上手婪
一、环境准备 Free Spire.Doc for Python 是免费 Python 文档处理库,无需依赖 Microsoft Word,支持 Word 文档的创建、编辑、转换等操作,其中内置的 Markdown 解析能力,能高效实现 Markdown 到 Doc/Docx 格式的转换,且…...

大数据知识图谱之深度学习:基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统
文章目录大数据知识图谱之深度学习:基于BERTLSTMCRF深度学习识别模型医疗知识图谱问答可视化系统一、项目概述二、系统实现基本流程三、项目工具所用的版本号四、所需要软件的安装和使用五、开发技术简介Django技术介绍Neo4j数据库Bootstrap4框架Echarts简介Navicat…...

Goreman性能优化:提升多进程管理效率的10个最佳实践
Goreman性能优化:提升多进程管理效率的10个最佳实践 【免费下载链接】goreman foreman clone written in go language 项目地址: https://gitcode.com/gh_mirrors/go/goreman Goreman作为用Go语言实现的Foreman克隆工具,是一款轻量级的多进程管理…...

扩散模型对抗样本经典baselines凶
一、简化查询 1. 先看一下查询的例子 /// /// 账户获取服务 /// /// /// public class AccountGetService(AccountTable table, IShadowBuilder builder) {private readonly SqlSource _source new(builder.DataSource);private readonly IParamQuery _accountQuery build…...