模型部署:量化中的Post-Training-Quantization(PTQ)和Quantization-Aware-Training(QAT)
模型部署:量化中的Post-Training-Quantization(PTQ)和Quantization-Aware-Training(QAT)
- 前言
- 量化
- Post-Training-Quantization(PTQ)
- Quantization-Aware-Training(QAT)
- 参考文献
前言
随着人工智能的不断发展,深度学习网络被广泛应用于图像处理、自然语言处理等实际场景,将其部署至多种不同设备的需求也日益增加。然而,常见的深度学习网络模型通常包含大量参数和数百万的浮点数运算(例如ResNet50具有95MB的参数以及38亿浮点数运算),实时地运行这些模型需要消耗大量内存和算力,这使得它们难以部署到资源受限且需要满足实时性、低功耗等要求的边缘设备。为了进一步推动深度学习网络模型在移动端或边缘设备中的快速部署,深度学习领域提出了一系列的模型压缩与加速方法:
- 知识蒸馏(Knowledge distillation):使用教师-学生网络结构,让小型的学生网络模仿大型教师网络的行为,以使得准确率尽可能高的同时,能够获得一个轻量化的网络。
- 剪枝(Parameter pruning):删除不必要的网络参数,以减少模型的规模和计算复杂度。
- 低秩分解(Low-rank factorization):将模型的参数矩阵分解为较低秩的小矩阵,以减少模型的复杂度和计算成本。
- 参数共享(Parameter sharing):将多个层共用一组参数,以减少模型的参数数量。
- 量化(Quantization):将模型的参数和运算转化为更小的数据类型,以减少内存占用和计算时间。
量化
模型量化(Quantization)是一种将浮点计算转化为定点计算的技术,例如从FP32降低至INT8,主要用于减少模型的计算强度、参数大小以及内存消耗,以提高模型在设备上的推理计算效率,但是也有可能会带来一定的精度损失。
模型量化精度损失的主要原因为量化-反量化(Quantization-Dequantization)过程中取整引起的误差。这里简单介绍一下量化的计算方法,以FP32到INT8的量化为例,量化的核心思想就是将浮点数区间的参数映射到INT8的离散区间中。
量化公式:
q = r s + Z q = \frac{r}{s} + Z q=sr+Z反量化公式:
r = S ( q − Z ) r = S(q-Z) r=S(q−Z)其中, r r r 为FP32的浮点数(real value), q q q 为INT8的量化值(quantization value),
S S S 、 Z Z Z 分别为缩放因子(Scale-factor)和零点(Zero-Point)。
量化最重要的便是确定 S S S 和 Z Z Z 的值, S S S 和 Z Z Z 的计算公式如下:
S = r m a x − r m i n q m a x − q m i n S = \frac{r_{max}-r_{min}}{q_{max}-q_{min}} S=qmax−qminrmax−rmin Z = − r m i n S + q m i n Z = -\frac{r_{min}}{S} + q_{min} Z=−Srmin+qmin其中, r m a x r_{max} rmax 和 r m i n r_{min} rmin 分别为FP32网络参数最大、最小值, q m a x q_{max} qmax 和 q m i n q_{min} qmin 分别为INT8网络参数最大、最小值。
为了减少量化所带来的精度损失,学者提出了Quantization-Aware-Training(QAT)方法,再介绍此之前,由于Post-Training-Quantization(PTQ)方法也经常在文献中出现,此篇博客将着重介绍这两个方法的含义与区别。

Post-Training-Quantization(PTQ)
Post-Training-Quantization(PTQ)是目前常用的模型量化方法之一。以INT8量化为例,PTQ方法的处理流程为:
- 首先在数据集上以FP32精度进行模型训练,得到训练好的模型;
- 使用小部分数据对FP32模型进行采样(Calibration),主要是为了得到网络各层参数的数据分布特性(比如统计最大最小值);
- 根据步骤2中的数据分布特性,计算出网络各层 S 和 Z 量化参数;
- 使用步骤3中的量化参数对FP32模型进行量化得到INT8模型,并将其部署至推理框架进行推理。
PTQ方法会使用小部分数据集来估计网络各层参数的数据分布,找到合适的S和Z的取值,从而一定程度上降低模型精度损失。然而,论文中指出PTQ方式虽然在大模型上效果较好(例如ResNet101),但是在小模型上经常会有较大的精度损失(例如MobileNet) 不同通道的输出范围相差可能会非常大(大于100x), 对异常值较为敏感。
Quantization-Aware-Training(QAT)
由上文可知PTQ方法中模型的训练和量化是分开的,而Quantization-Aware-Training(QAT)方法则是在模型训练时加入了伪量化节点,用于模拟模型量化时引起的误差,并通过微调使得模型在量化后尽可能减少精度损失。以INT8量化为例,QAT方法的处理流程为:
- 首先在数据集上以FP32精度进行模型训练,得到训练好的FP32模型;
- 在FP32模型中插入伪量化节点,得到QAT模型,并且在数据集上对QAT模型进行微调(Fine-tuning);
- 同PTQ方法中的采样(Calibration),并计算量化参数 S 和 Z ;
- 使用步骤3中得到的量化参数对QAT模型进行量化得到INT8模型,并部署至推理框架中进行推理。
在PyTorch中,可以使用 torch.quantization.quantize_dynamic() 方法来执行 QAT。这是一个基本的 QAT 代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.quantization import quantize_dynamic, QuantStub, DeQuantStub# 定义简单的模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.quant = QuantStub()self.dequant = DeQuantStub()self.fc1 = nn.Linear(784, 256)self.relu = nn.ReLU()self.fc2 = nn.Linear(256, 10)def forward(self, x):x = self.quant(x)x = self.fc1(x)x = self.relu(x)x = self.fc2(x)x = self.dequant(x)return x# 数据加载
# 这里使用 MNIST 数据集作为示例
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])train_loader = torch.utils.data.DataLoader(datasets.MNIST('./data', train=True, download=True, transform=transform),batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('./data', train=False, download=True, transform=transform),batch_size=64, shuffle=False)# 定义损失函数和优化器
model = SimpleModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 定义 QAT 训练函数
def train(model, train_loader, criterion, optimizer, num_epochs=5):model.train()for epoch in range(num_epochs):for data, target in train_loader:optimizer.zero_grad()output = model(data.view(data.shape[0], -1))loss = criterion(output, target)loss.backward()optimizer.step()# 训练模型
train(model, train_loader, criterion, optimizer, num_epochs=5)# 在训练完成后执行动态量化
quantized_model = quantize_dynamic(model, {nn.Linear}, dtype=torch.qint8)# 评估量化模型
def test(model, test_loader, criterion):model.eval()correct = 0total = 0with torch.no_grad():for data, target in test_loader:output = model(data.view(data.shape[0], -1))_, predicted = torch.max(output.data, 1)total += target.size(0)correct += (predicted == target).sum().item()accuracy = correct / totalprint(f'Accuracy of the network on the test images: {accuracy * 100:.2f}%')# 测试量化模型
test(quantized_model, test_loader, criterion)
上述代码示例中,我使用了一个简单的全连接神经网络,并在训练完成后使用torch.quantization.quantize_dynamic()对模型进行动态量化。在量化之前,我们通过QuantStub()和DeQuantStub()添加了量化和反量化的辅助模块。这个示例使用了MNIST数据集,你可以根据你的实际需求替换成其他数据集和模型。
参考文献
量化感知训练(Quantization-aware-training)探索-从原理到实践
相关文章:
模型部署:量化中的Post-Training-Quantization(PTQ)和Quantization-Aware-Training(QAT)
模型部署:量化中的Post-Training-Quantization(PTQ)和Quantization-Aware-Training(QAT) 前言量化Post-Training-Quantization(PTQ)Quantization-Aware-Training(QAT) 参…...
- - - 题目答案)
C++模板元模板(异类词典与policy模板)- - - 题目答案
目录 一、书中第一题 二、书中第三题 三、书中第五题 四、书中第六题 五、书中第七题 六、书中十一题 七、书中十二题 八、 书中十三题 总结 一、书中第一题 #include <iostream>template <typename T, size_t N> struct NSVarTypeDict {static void Cre…...

二十三种设计模式全面解析-组合模式与迭代器模式的结合应用:构建灵活可扩展的对象结构
在前文中,我们介绍了组合模式的基本原理和应用,以及它在构建对象结构中的价值和潜力。然而,组合模式的魅力远不止于此。在本文中,我们将继续探索组合模式的进阶应用,并展示它与其他设计模式的结合使用,以构…...
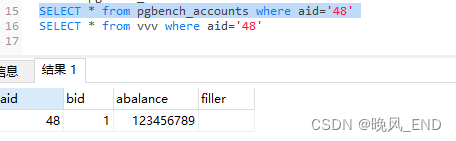
postgresql|数据库|提升查询性能的物化视图解析
前言: 我们一般认为数字的世界是一个虚拟的世界,OK,但我们其实有些需求是和现实世界一模一样的,比如,数据库尤其是关系型数据库,希望在使用的数据库能够更快(查询速度),…...
Unity中Shader雾效的原理
文章目录 前言一、我们先看一下现实中的雾二、雾效的混合公式最终的颜色 lerp(雾效颜色,物体颜色,雾效混合因子) 三、雾效的衰减1、FOG_LINEAR(线性雾衰减)2、FOG_EXP(指数雾衰减1)3、FOG_EXP(指数雾衰减2) 前言 Unity中Shader雾…...

chatgpt辅助论文优化表达
chatgpt辅助论文优化表达 写在最前面最终版什么是好的论文整体上:逻辑/连贯性细节上一些具体的修改例子 一些建议,包括具体的提问范例1. **明确你的需求**2. **提供上下文信息**3. **明确问题类型**4. **测试不同建议**5. **请求详细解释**综合提问范例&…...
——初始化应用实例)
Vue3 源码解读系列(二)——初始化应用实例
初始化应用实例 创建 Vue 实例对象 createApp 中做了两件事: 创建 app 对象保存并重写 mount /*** 创建 Vue 实例对象*/ const createApp ((...args) > {// 1、创建 app 对象,延时创建渲染器,优点是当用户只依赖响应式包的时候࿰…...

网络原理-UDP/TCP详解
一. UDP协议 UDP协议端格式 由上图可以看出,一个UDP报文最大长度就是65535. • 16位长度,表示整个数据报(UDP首部UDP数据)的最大长度(注意,这里的16位UDP长度只是一个标识这个数据报长度的字段࿰…...
C#多线程入门概念及技巧
C#多线程入门概念及技巧 一、什么是线程1.1线程的概念1.2为什么要多线程1.3线程池1.4线程安全1.4.1同步机制1.4.2原子操作 1.5线程安全示例1.5.1示例一1.5.2示例二 1.6C#一些自带的方法实现并行1.6.1 Parallel——For、ForEach、Invoke1.6.1 PLINQ——AsParallel、AsSequential…...
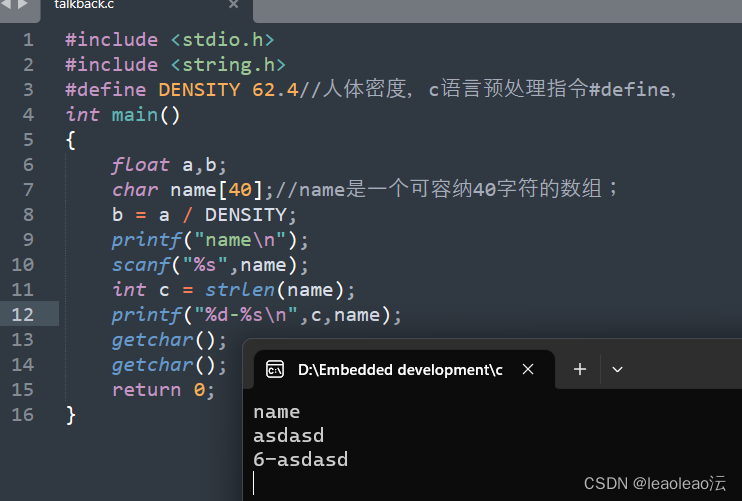
c primer plus_chapter_four——字符串和格式化输入/输出
1、strlen();const;字符串;用c预处理指令#define和ANSIC的const修饰符创建符号常量; 2、c语言没有专门储存字符串的变量类型,字符串被储存在char类型的数组中;\0标记字符串的结束&a…...

Python Fastapi+Vue+JWT实现注册、登录、状态续签【登录保持】
文章目录 一、实现流程1.注册2.登录3.登录保持【状态续签】二、实现方法1.注册2.登录+登陆状态保持* 后端部分* 前端部分一、实现流程 1.注册 Created with Raphal 2.3.0...

oracle-sql语句解析类型
语句执行过程:1. 解析(将sql解析成执行计划) 2.执行 3.获取数据(fetch) 1. shared pool的组成。 share pool是一块内存池。 主要分成3块空间。free, library(库缓存,缓存sql以及执行计划),row cache(字典缓存) select * from v…...
2023 年最新企业微信官方会话机器人开发详细教程(更新中)
目标是开发一个简易机器人,能接收消息并作出回复。 获取企业 ID 企业信息页面链接地址:https://work.weixin.qq.com/wework_admin/frame#profile 自建企业微信机器人 配置机器人应用详情 功能配置 接收消息服务器配置 配置消息服务器配置 配置环境变量…...

3、FFmpeg基础
1、FFmpeg 介绍 FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。它提供了录制、转换以及流化音视频的完整解决方案。它包含了非常先进的音频/视频编解码库。 2、FFmpeg 组成 - libavformat:用于各种音视频[封装…...

c语言:用指针解决有关字符串等问题
题目1:将一个字符串str的内容颠倒过来,并输出。 数据范围:1≤len(str)≤10000 代码和思路: #include <stdio.h> #include<string.h> int main() {char str1[10000];gets(str1);//读取字符串内容char* p&str1[…...
吃透 Spring 系列—Web部分
目录 ◆ Spring整合web环境 - Javaweb三大组件及环境特点 - Spring整合web环境的思路及实现 - Spring的web开发组件spring-web ◆ web层MVC框架思想与设计思路 ◆ Spring整合web环境 - Javaweb三大组件及环境特点 在Java语言范畴内,web层框架都是基于J…...

JAVA后端服务端与移动端客户端高精度时间同步思路
一、脑补 在Chrome--->Network----> Timing中可以查看一个请求在各个阶段所花费的时间。 Timing中各个字段的意思发: 1、Queueing:从增加到等待处理队列到实际开始处理的时间间隔——浏览器也有线程机制,所有的请求不能同时发送&…...

nsd的资料
nsd是一款开源的DNS服务器应用。 近期参与项目过程中,涉及到DNS业务,结果被打的满头包。 虽然在校学习时就知道DNS协议,但从业这么多年,对于DNS协议的理解其实一直处于一知半解的状态。 当前处理问题时,接触到了nsd&am…...
关于Maven中pom.xml文件不报错但无法导包解决方法
问题 我的pom文件没有报红,但是依赖无法正常导入。 右下角还总出现这种问题。 点开查看报错日志。大致如下 1) Error injecting constructor, java.lang.NoSuchMethodError: org.apache.maven.model.validation.DefaultModelValidator: method <init>()V no…...

使用决策树分类
任务描述 本关任务:使用决策树进行分类 相关知识 为了完成本关任务,你需要掌握:1.使用决策树进行分类 使用决策树进行分类 依靠训练数据构造了决策树之后,我们可以将它用于实际数据的分类。在执行数据分类时,需要…...

Safeboxie沙盘,电脑多开程序神器,系统安全工具,非常好用!
Safeboxie沙盘,电脑多开程序神器,系统安全工具,非常好用! 软件介绍 菜鸟高手裸奔工具沙盘Safeboxie是一款国外著名的系统安全工具,它可以让选定程序在安全的隔离环境下运行,只要在此环境中运行的软件&#…...

每日热门Skill:ClawdCursor 深度研究报告
第一章:当日热门Skill概览 1.1 今日热门:ClawdCursor 在2026年4月9日的GitHub OpenClaw Skill热榜中,**ClawdCursor(AmrDab/clawdcursor)**凭借其创新的AI桌面智能体定位和今天(2026-04-09)的最新提交记录,综合热度排名第一,成为当日最值得关注的OpenClaw Skill。 …...

探索信息获取新维度:突破信息茧房的智能工具实践指南
探索信息获取新维度:突破信息茧房的智能工具实践指南 你是否曾在海量信息中迷失方向?当打开浏览器面对无数标签页却找不到真正需要的内容时,当花费数小时筛选资料却发现质量参差不齐时,当重要信息被层层付费壁垒阻隔时——这种普遍…...

安装对中不到位,丝杆升降机越用越费!5大严重后果必看
在设备安装现场,经常能看到这样的场景:工人用卷尺大概量一下电机座和升降机输入轴的距离,然后用锤子把联轴器敲进去,螺栓拧紧就完事了。他们不知道,这种“差不多”的对中操作,正在为丝杆升降机埋下致命隐患…...

ITG3200陀螺仪驱动开发:寄存器配置、多量程切换与FreeRTOS集成
1. ITG3200陀螺仪驱动库技术解析与工程实践ITG3200是InvenSense公司于2009年前后推出的单芯片三轴数字陀螺仪传感器,采用MEMS工艺制造,集成16位ADC、数字温度传感器、可编程低通滤波器及IC/SPI双接口。尽管该器件已停产多年,但在工业控制、无…...

可口可乐在美国250周年庆活动中唱响“我想给美国买瓶可乐”
可口可乐公司正式启动一项为期一年的全国性营销活动,以配合其与“美国250周年委员会(America250)”的合作伙伴关系。该委员会是负责筹备美国建国250周年庆典的非营利组织。 活动核心是一支三分钟的赞歌式视频《畅饮美国(Drink In…...

STM32智慧停车场系统开发实战
1. 项目概述这个智慧停车场管理系统项目基于STM32微控制器开发,主要解决传统停车场管理效率低下、人工成本高、用户体验差等问题。我在实际开发中发现,一套完整的智慧停车场系统需要整合硬件感知、数据处理、用户交互和远程管理四大模块,而ST…...

OpenClaw技能调试技巧:千问3.5-35B-A3B-FP8任务失败的日志分析方法
OpenClaw技能调试技巧:千问3.5-35B-A3B-FP8任务失败的日志分析方法 1. 问题背景与调试困境 上周我尝试用OpenClaw对接千问3.5-35B-A3B-FP8模型实现一个自动化流程:让AI助手读取截图中的文字内容,整理成结构化数据后存入本地Excel文件。结果…...

和AI一起搞事情#:边剥龙虾边做个中医技能来起号酌
1. 核心概念 在 Antigravity 中,技能系统分为两层: Skills (全局库):实际的代码、脚本和指南,存储在系统级目录(如 ~/.gemini/antigravity/skills)。它们是“能力”的本体。 Workflows (项目级):…...

加州大学洛杉矶分校、腾讯混元等推出Unify-Agent
这项由加州大学洛杉矶分校、腾讯混元、香港中文大学和香港科技大学联合研究团队发表于2026年3月的研究(arXiv:2603.29620v1),彻底改变了我们对AI图像生成的认知。想象一下,如果你请AI画一个不太知名的动漫角色或者某个地方的特色小…...