自然语言处理中的文本聚类:揭示模式和见解
一、介绍
在自然语言处理(NLP)领域,文本聚类是一种基本且通用的技术,在信息检索、推荐系统、内容组织和情感分析等各种应用中发挥着关键作用。文本聚类是将相似文档或文本片段分组为簇或类别的过程。这项技术使我们能够发现隐藏的模式、提取有价值的见解并简化大量非结构化文本数据。在本文中,我们将深入研究 NLP 中的文本聚类领域,探讨其重要性、方法论和实际应用。
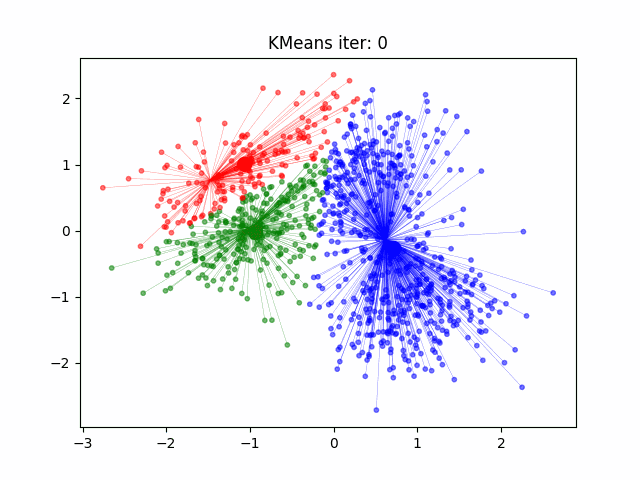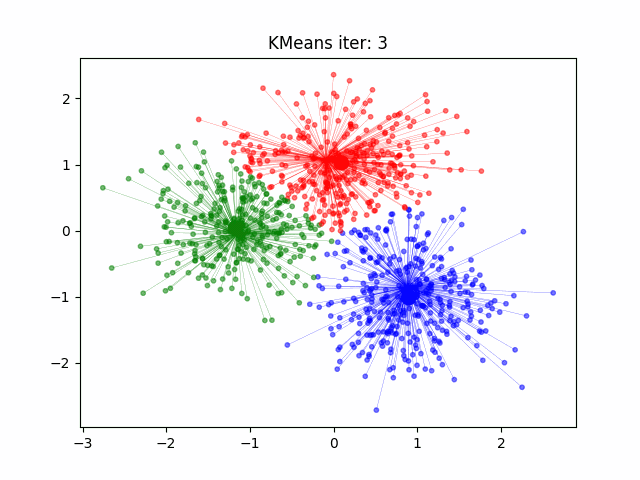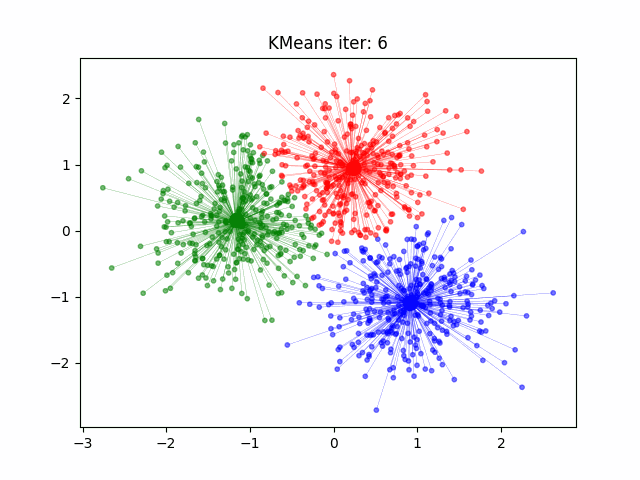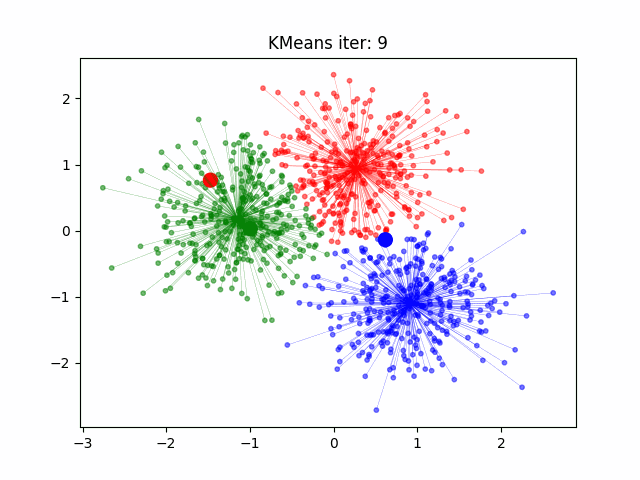
自然语言处理中的文本聚类就像浩瀚文字海洋中的指南针,引导我们到达模式和见解的隐藏海岸。
二、文本聚类的重要性
文本聚类是文本分析中的关键步骤,因为它可以从非结构化文本数据中提取有意义的结构和见解。以下是文本聚类在 NLP 中至关重要的几个关键原因:
- 信息检索:搜索引擎和推荐系统使用文本聚类来有效地分类和检索相关信息。它可以帮助用户找到与其查询语义相关的文档或内容。
- 内容组织:在内容管理中,集群有助于对大量文档档案进行分类和组织。它有助于创建层次结构,使内容更易于导航。
- 主题发现:研究人员和分析师使用文本聚类来识别文档集合中的新兴趋势、主题或模式。这对于跟踪新闻、社交媒体或学术研究特别有用。
- 情绪分析:以情绪为重点的文本聚类有助于衡量公众对各种主题的看法。这对于企业和政府了解公众的看法并相应地调整策略来说非常宝贵。
三、文本聚类方法
文本聚类涉及多种方法和途径。以下是一些常用的技术:
- K-Means 聚类: K-Means 是一种广泛使用的聚类算法。它通过最小化文档与簇质心之间的距离来将文档分配给簇。每个簇代表一组相似的文档。
- 层次聚类:层次聚类创建树状的簇结构。它可以是凝聚性的(自下而上),也可以是分裂性的(自上而下)。这种方法提供了集群的层次结构,提供了更细致的数据视图。
- DBSCAN(基于密度的噪声应用空间聚类): DBSCAN 可以根据数据点的密度有效识别不同形状和大小的聚类。它还可以发现数据中的异常值和噪音。
- 潜在狄利克雷分配(LDA): LDA是一种用于主题建模的概率模型。它发现文档集合中的主题,并为每个文档分配这些主题的分布。
- 词嵌入: Word2Vec 和 Doc2Vec 等技术可创建单词和文档的向量表示,从而更容易根据向量空间中的相似性对文本数据进行聚类。
四、实际应用
文本聚类在各个领域都有应用,提供有价值的见解和解决方案。一些现实世界的例子包括:
- 新闻聚合:新闻网站根据主题对文章进行聚合,为读者提供更有组织性和个性化的新闻源。
- 电子商务:在线零售商使用文本聚类对产品进行分组,使客户更容易找到相关商品并改进推荐。
- 学术研究:研究人员使用文本聚类来识别研究趋势,这可以帮助发现新的探索领域。
- 社交媒体分析:企业使用通过文本聚类进行的情感分析来衡量客户满意度并调整营销策略。
五、代码
使用数据集和绘图创建用于文本聚类的完整 Python 代码示例可能相当广泛,但我可以为您提供一个简化的示例,使用流行的 scikit-learn 库进行文本聚类,并使用 Matplotlib 进行可视化。在此示例中,我们将使用 20 个新闻组数据集,其中包含分类为 20 个不同主题的新闻组文档。
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.datasets import fetch_20newsgroups
from sklearn.decomposition import TruncatedSVD
import matplotlib.pyplot as plt# Load the 20 Newsgroups dataset
newsgroups = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))# Vectorize the text data using TF-IDF
tfidf_vectorizer = TfidfVectorizer(max_df=0.5, max_features=1000, stop_words='english')
tfidf_matrix = tfidf_vectorizer.fit_transform(newsgroups.data)# Reduce dimensionality using LSA (Latent Semantic Analysis)
lsa = TruncatedSVD(n_components=2)
lsa_matrix = lsa.fit_transform(tfidf_matrix)# Perform K-Means clustering
k = 20 # Number of clusters (based on the 20 Newsgroups categories)
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(lsa_matrix)# Visualize the clusters
labels = kmeans.labels_
cluster_centers = kmeans.cluster_centers_plt.figure(figsize=(10, 8))
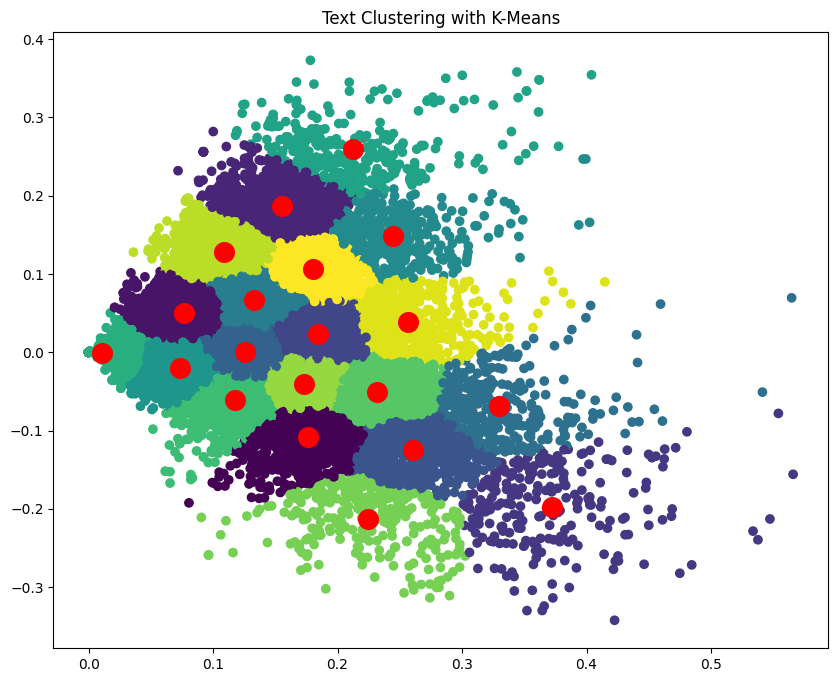
plt.scatter(lsa_matrix[:, 0], lsa_matrix[:, 1], c=labels, cmap='viridis')
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1,], s=200, c='red')
plt.title("Text Clustering with K-Means")
plt.show()在此代码中:
- 我们加载 20 个新闻组数据集,其中包含来自不同新闻组的文本文档。
- 我们使用 TF-IDF(词频-逆文档频率)向量化将文本数据转换为数值特征。
- LSA(潜在语义分析)用于将维度降低到 2D 以实现可视化目的。
- K-Means 聚类的聚类数量等于新闻组类别的数量 (k = 20)。
- 最后,我们在 2D 空间中绘制文本文档,并根据聚类对它们进行着色。红点代表聚类中心。
请注意,这是一个简化的示例,在实践中,您可能需要预处理文本数据、调整超参数并使用更高级的技术来获得更好的聚类结果。
六、结论
NLP 中的文本聚类是一种多功能且必不可少的工具,用于从非结构化文本数据中提取有价值的见解和结构。它的方法论,包括 K-Means、层次聚类和 LDA,使我们能够发现模式、对相似文档进行分组并组织内容。它的实际应用有很多,从新闻聚合到电子商务中的情绪分析。随着 NLP 的不断发展,文本聚类仍将是利用文本数据的力量推动各个领域的明智决策和解决方案的基石。
埃弗顿戈梅德
相关文章:
自然语言处理中的文本聚类:揭示模式和见解
一、介绍 在自然语言处理(NLP)领域,文本聚类是一种基本且通用的技术,在信息检索、推荐系统、内容组织和情感分析等各种应用中发挥着关键作用。文本聚类是将相似文档或文本片段分组为簇或类别的过程。这项技术使我们能够发现隐藏的…...

C/C++内存管理——“C++”
各位CSDN的uu们你们好呀,好久没有更新小雅兰的C专栏啦,下面,小雅兰继续开始更新C专栏的内容!!!今天,小雅兰的内容是C和C的内存管理,下面,让我们进入C的世界吧!…...

jsp小知识
jsp小知识 1[单选题] 用户登录功能中,用到的数据库操作是( )。 正确答案: C 我的答案: C A. 增加 B. 删除 C. 查询 D. 修改 2[单选题] 下列说法错误的是( )。 正确答案: C 我的答案: C A. JDBC API包括一组支…...

Flutter:改变手机状态栏颜色,与appBar状态颜色抱持一致
前言 最近在搞app的开发,本来没怎么注意appBar与手机状态栏颜色的问题。但是朋友一说才注意到这两种的颜色是不一样的。 我的app 京东 qq音乐 这样一对比发现是有的丑啊,那么如何实现呢? 实现 怎么说呢,真不会。百度到的一些是…...

深入分析:一体化运维监控在金融行业的关键作用
金融行业,作为现代经济的核心支柱,对信息技术的依赖程度极高。在飞速发展的金融科技背景下,如何保障IT系统的稳定运行,成为了行业关注的焦点。一体化运维监控,通过实时监控、智能预警、快速定位及自动化恢复等功能&…...

物联网AI MicroPython学习之语法 network网络配置模块
学物联网,来万物简单IoT物联网!! network介绍 模块功能: 用于管理Wi-Fi和以太网的网络模块参考用法: import network import time nic network.WLAN(network.STA_IF) nic.active(True) if not nic.isconnected():…...

java根据前、中序遍历结果重新生成二叉树
1、首先写一个类表示二叉树 public class TreeNode {int num;TreeNode left;TreeNode right;public TreeNode(int num) {this.num num;}}2、根据前,中序遍历,在控制台我们可以得到两个结果pre 和 in: /*** 前序遍历* param node*/public st…...

利用检测结果实现半自动标注
1. 将目标检测结果保存为xml格式 #-----------------------------------------------------------------------------------# # 下面定义了xml里面的组成模块,无需改动。 #-----------------------------------------------------------------------------------…...

Android修行手册 - 万字梳理JNI开发正确技巧和错误缺陷
JNI 简介 JNI,Java Native Interface,是 native code 的编程接口。JNI 使 Java 代码程序可以与 native code 交互——在 Java 程序中调用 native code;在 native code 中嵌入 Java 虚拟机调用 Java 的代码。 它支持将 Java 代码与使用其他…...

C++学习 --类和对象之继承
目录 1, 继承的语法 1-1, 继承方式 1-1-1, 公共继承public 1-1-2, 私有继承private 1-1-3, 保护继承protected 2, 父类,子类同名属性处理 2-1, 成员变量同名 2-2, 成员函数同…...
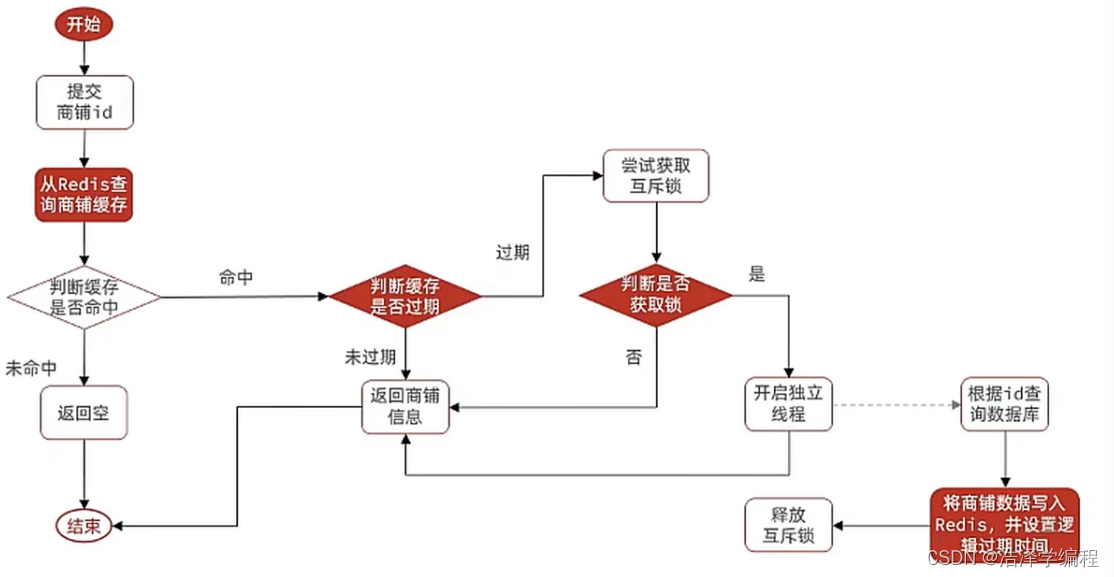
Redis之缓存
文章目录 前言一、缓存使用缓存的原因 二、使用缓存实现思路提出问题 三、三大缓存问题缓存穿透缓存雪崩缓存击穿互斥锁实现逻辑过期时间实现 总结 前言 本篇文章即将探索的问题(以黑马点评为辅助讲解,大家主要体会实现逻辑) 使用redis缓存的…...
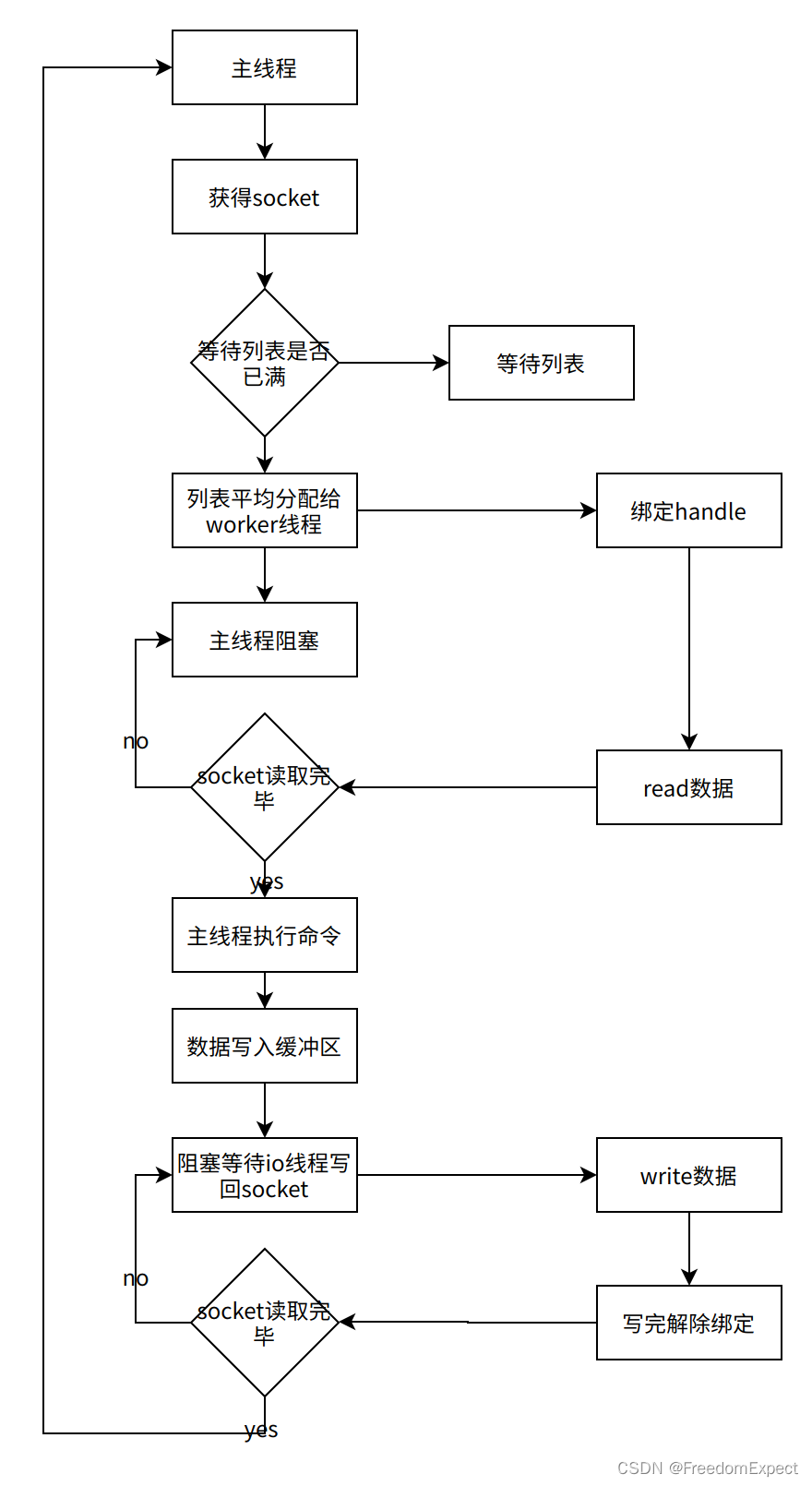
Redis6的IO多线程分析
性能测试 机器配置 C Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 14 On-line CPU(s) list: 0-13 Mem: 62G性能 配置推荐 官方表示,当使用redis时有性能瓶…...

kali linux安装教程
安装 Kali Linux 非常简单,下面是基本的步骤: 首先下载 Kali Linux 的 ISO 镜像文件。你可以从官方网站 https://www.kali.org/downloads/ 下载。 确保你的计算机支持使用盘或者 USB 启动。你可以在计算机开机时按下 F12 或者其他类似的按键,…...
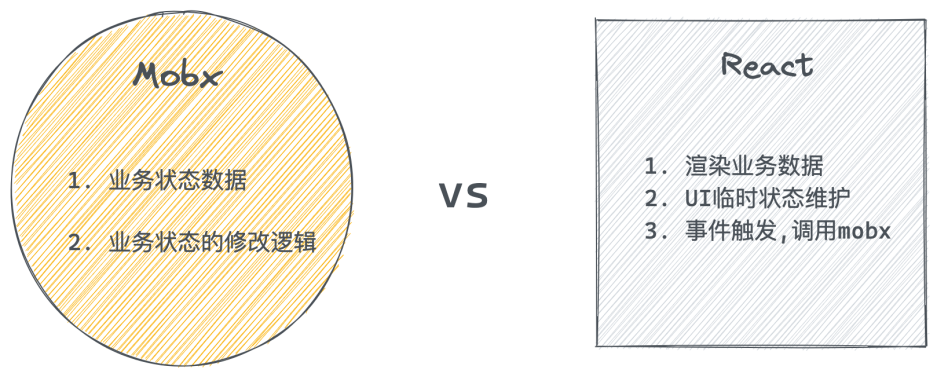
React进阶之路(四)-- React-router-v6、Mobx
文章目录 ReactRouter前置基本使用核心内置组件说明编程式导航路由传参嵌套路由默认二级路由404路由配置集中式路由配置 Mobx什么是Mobx环境配置基础使用observer函数*计算属性(衍生状态)异步数据处理模块化多组件数据共享Mobx和React职责划分 ReactRout…...
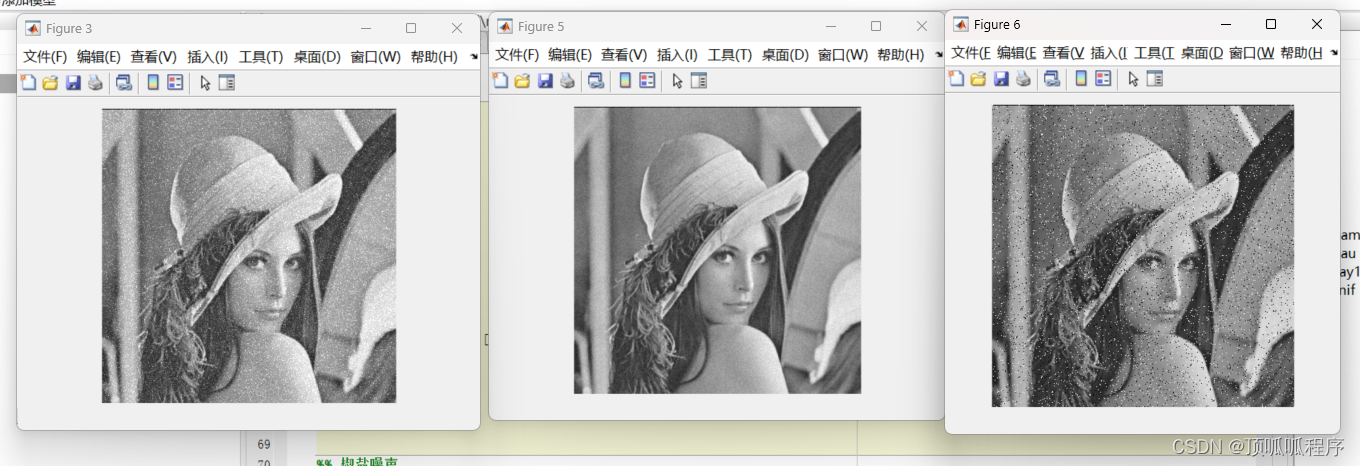
55基于matlab的1.高斯噪声2.瑞利噪声3.伽马噪声4.均匀分布噪声5.脉冲(椒盐)噪声
基于matlab的1.高斯噪声2.瑞利噪声3.伽马噪声4.均匀分布噪声5.脉冲(椒盐)噪声五组噪声模型,程序已调通,可直接运行。 55高斯噪声、瑞利噪声 (xiaohongshu.com)...
Codeforces Round 908 (Div. 2)视频详解
Educational Codeforces Round 157 (A--D)视频详解 视频链接A题代码B题代码C题代码D题代码 视频链接 Codeforces Round 908 (Div. 2)视频详解 A题代码 #include<bits/stdc.h> #define endl \n #define deb(x) cout << #x << "…...
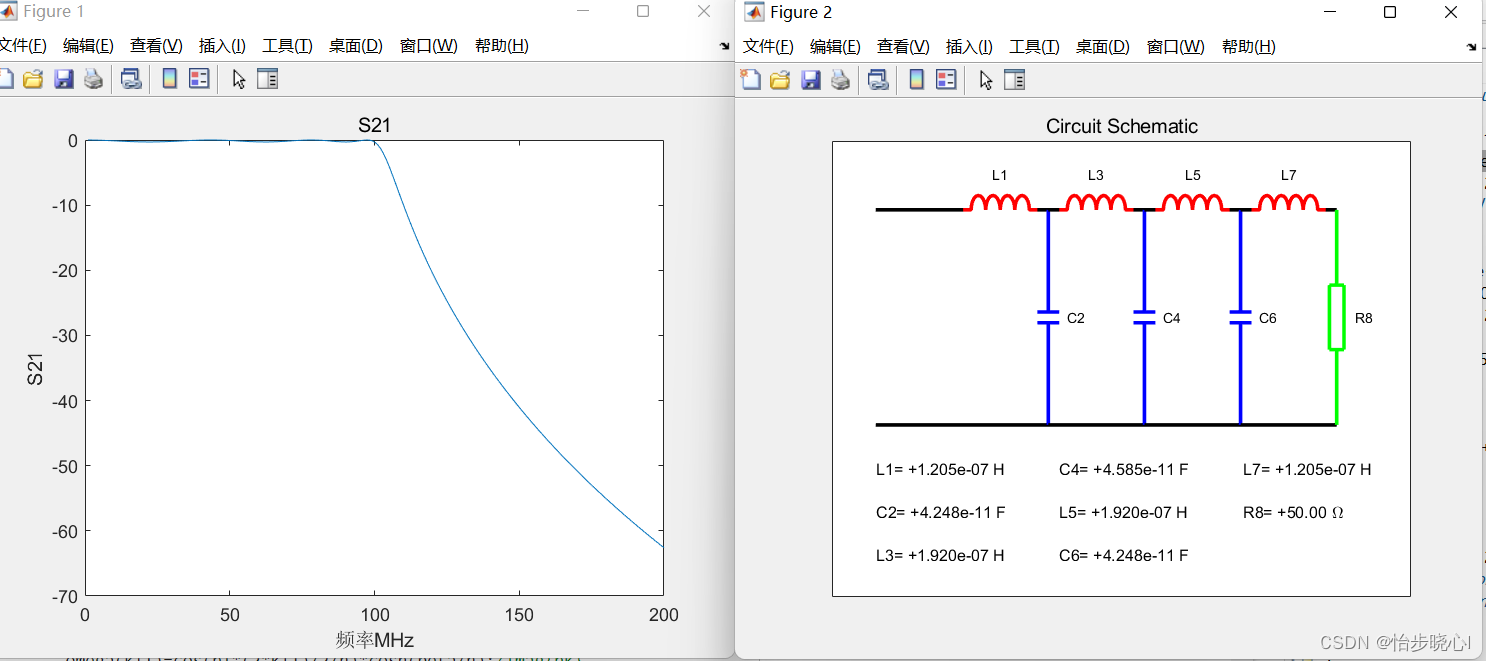
电路综合-基于简化实频的SRFT集总参数切比雪夫低通滤波器设计
电路综合-基于简化实频的SRFT集总参数切比雪夫低通滤波器设计 6、电路综合-基于简化实频的SRFT微带线切比雪夫低通滤波器设计中介绍了使用微带线进行切比雪夫滤波器的设计方法,在此对集总参数的切比雪夫响应进行分析。 SRFT集总参数切比雪夫低通滤波器综合不再需要…...
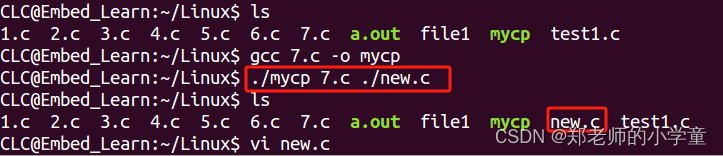
Linux系统编程——实现cp指令(应用)
cp指令格式 cp [原文件] [目标文件] cp 1.c 2.c 功能是将原文件1.c复制后并改名成2.c(内容相同,实现拷贝) 这里需要引入main函数的参数解读: 我们在定义函数时许多都带有参数,输入参数后便可进行定义函数内的功能执行,而main…...
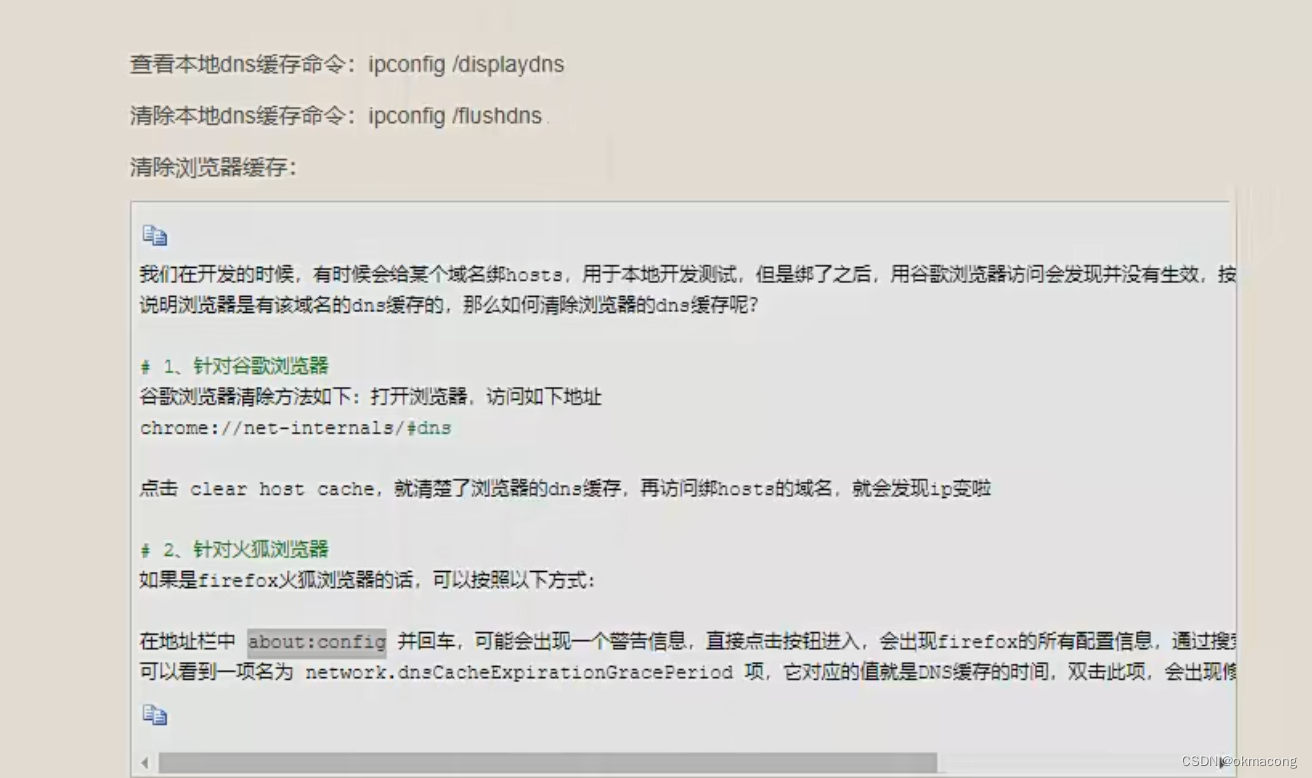
20231112_DNS详解
DNS是实现域名与IP地址的映射。 1.映射图2.DNS查找顺序图3.DNS分类和地址4.如何清除缓存 1.映射图 图片来源于http://egonlin.com/。林海峰老师课件 2.DNS查找顺序图 3.DNS分类和地址 4.如何清除缓存...

使用ssh上传数据到阿里云ESC云服务上
在这之前需要安装 ssh2-sftp-client 直接在终端输入:npm i ssh2-sftp-client 直接上代码: const path require(path); const Client require(ssh2-sftp-client);// 配置连接参数 const config {host: your-server-ip, // 云服务器的IP地址port: 22, …...

P4561 [JXOI2018] 排序问题
题意 有一个序列,现在要在结尾加上 mmm 个 [l,r][l,r][l,r] 之间的数,求在所有方案中,猴子排序(每次随机一个排列,检查是否有序)的次数期望最大次数。 思路 假设最终的序列中数 iii 出现的次数是 cic_ici…...

[具身智能-319]:分词器的词典的内容有哪些因素决定,该字典中的内容是如何构建的?英文的分词器字典多大?中文的分词器字典有多大?分别举例说明分词器字典中的内容?
分词器的词典(Vocabulary)是决定大语言模型如何“看”世界的关键组件。它不仅仅是一个单词列表,更是一个包含了各种粒度文本单元及其对应数字编号(Token ID)的映射表。 以下为你详细解析词典的决定因素、构建过程、英…...

【万字文档+源码】基于springboot与vue海鲜市场系统-计算机项目设计学习
基于springboot与vue海鲜市场系统1.项目简介 管理员的功能是对用户和商家的信息进行监管,使得管理员能够管理用户、商家、海鲜分类等,并可以对这些进行修改和删除等来保证系统的整体运行。 用户的功能有可以去浏览系统首页和商品的信息,查看…...

收藏!程序员转型AI必看:手把手教你构建百万级文档RAG系统
本文聚焦于企业级大模型应用中的RAG技术,针对10万级文档规模,探讨了如何构建一个高效、稳定且可扩展的RAG系统。文章从RAG的基本原理出发,分析了检索慢、召回率低和部署复杂三大痛点,并提出了相应的优化策略,包括文档预…...

RAG是什么?为什么它能让AI更靠谱,告别“一本正经地胡说八道”
RAG可以理解为“先查资料,再回答”:让AI更像带依据的助手,而不是自由发挥的写作机。 你会拿到:RAG人话解释 引用式输出模板(可复制)。 本文由“壹伴编辑器”提供技术支持 1|一句话讲清 你可能遇…...

4个效率倍增技巧:D3KeyHelper让暗黑3操作自动化更精准
4个效率倍增技巧:D3KeyHelper让暗黑3操作自动化更精准 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 在暗黑破坏神3的高难度游戏场景中&…...

《Python 架构师的自动化哲学:从基础语法到企业级作业调度系统与 Airflow 止损实战》
《Python 架构师的自动化哲学:从基础语法到企业级作业调度系统与 Airflow 止损实战》 引言:凌晨三点的警报声与调度的艺术 你好,我是你的 Python 技术向导。在多年的软件架构与数据工程生涯中,我见过无数技术团队的变迁。如果说…...

HTTPie 完全指南:比 curl 更人性化的 HTTP 调试工具
HTTPie 完全指南:比 curl 更人性化的 HTTP 调试工具如果你厌倦了 curl 的冗长语法,HTTPie 是一个值得尝试的替代方案。一、HTTPie 是什么 HTTPie(发音:aitch-tee-tee-pie)是一个命令行 HTTP 客户端,目标是让…...

解密OpenStego:重新定义信息隐藏的颠覆性方案
解密OpenStego:重新定义信息隐藏的颠覆性方案 【免费下载链接】openstego OpenStego is a steganography application that provides two functionalities: a) Data Hiding: It can hide any data within an image file. b) Watermarking: Watermarking image files…...

终极指南:如何实现北京理工大学校园网自动登录与断线重连
终极指南:如何实现北京理工大学校园网自动登录与断线重连 【免费下载链接】BIT-srun-login-script 北京理工大学深澜校园网登录脚本,以实现命令行登录或者断线重连等,仅提供登录功能 项目地址: https://gitcode.com/gh_mirrors/bi/BIT-srun…...