Redis之缓存
文章目录
- 前言
- 一、缓存
- 使用缓存的原因
- 二、使用缓存
- 实现思路
- 提出问题
- 三、三大缓存问题
- 缓存穿透
- 缓存雪崩
- 缓存击穿
- 互斥锁实现
- 逻辑过期时间实现
- 总结
前言
本篇文章即将探索的问题(以黑马点评为辅助讲解,大家主要体会实现逻辑)
- 使用redis缓存的原因
- 数据库与缓存不一致问题
- 三大缓存问题(缓存穿透、缓存雪崩、缓存击穿)。
`
一、缓存
缓存(Cache),就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码。
例1:Static final ConcurrentHashMap<K,V> map = new ConcurrentHashMap<>(); 本地用于高并发例2:static final Cache<K,V> USER_CACHE = CacheBuilder.newBuilder().build(); 用于redis等缓存例3:Static final Map<K,V> map = new HashMap(); 本地缓存
由于其被Static修饰,所以随着类的加载而被加载到内存之中,作为本地缓存,由于其又被final修饰,所以其引用(例3:map)和对象(例3:new HashMap())之间的关系是固定的,不能改变,因此不用担心赋值(=)会导致缓存失效;
使用缓存的原因
速度快、好用
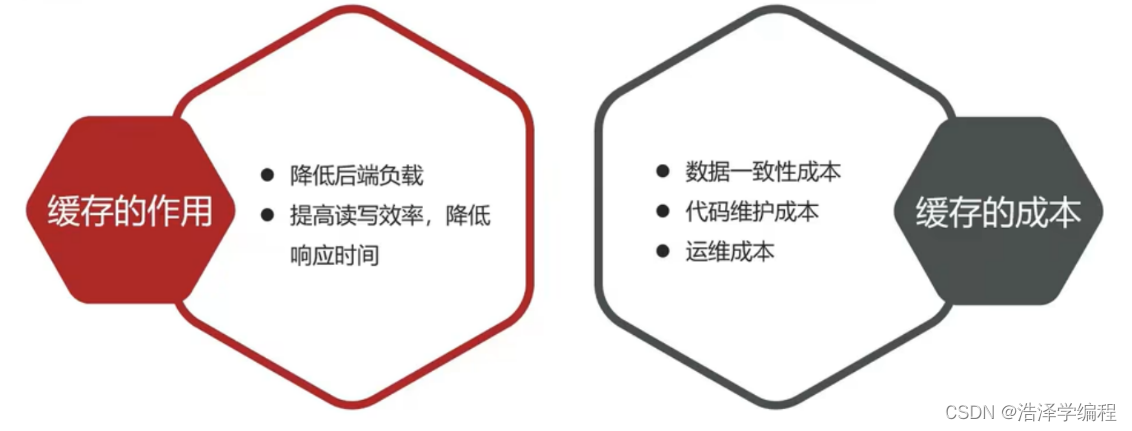
- 缓存数据存储于代码中,而代码运行在内存中,内存的读写性能远高于磁盘,缓存可以大大降低用户访问并发量带来的服务器读写压力。
- 实际开发过程中,企业的数据量,少则几十万,多则几千万,这么大数据量,如果没有缓存来作为"避震器",系统是几乎撑不住的,所以企业会大量运用到缓存技术。
- 但是缓存也会增加代码复杂度和运营的成本。
- 使用Redis缓存可以很好的解决大量操作访问数据库的带来的压力,让数据处理和响应更快,提高用户体验,毕竟Redis是100000+QPS级别的。
二、使用缓存
- 在一个项目中,存在一些很久不会变化的信息,如果每次访问都去数据库中读取,显然每次都要重复的动作是费时而毫无意义的。
- 案例: 在美团等应用上的商家店铺信息,比如照片,店铺名称,店铺位置等等几乎不经常变化的信息,我们每一次访问都去数据库中获取,会导致响应慢,而且还有高并发访问量给数据库带来巨大压力,所以我们就可以将这些放入redis中,下次响应直接去redis中获取,redis的性能能够大大改善这种问题。
实现思路
核心思路就是客户端先向Redis中获取,如果Redis中没有,再去数据库中获取,数据库中获取后,将获取的数据写入缓存,这样下一次访问就能在Redis中获取。如果数据库没有,那就是真的没有了,返回报错,比如该商铺不存在等等。
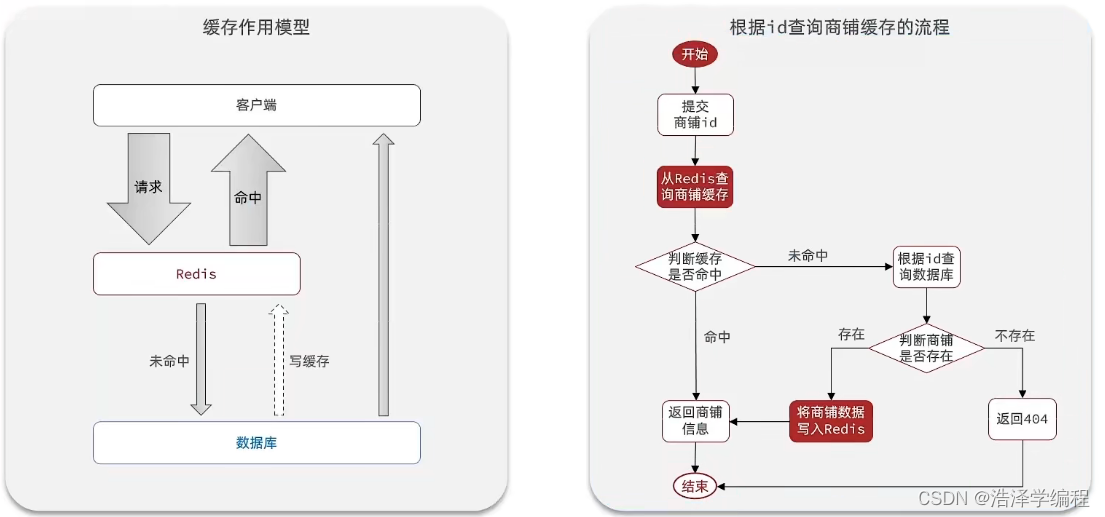
public Shop queryWithPassThrough(Long id){String key = "cache:shop:" + id;// 1.从redis查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isNotBlank(shopJson)){// 3.存在,直接返回return JSONUtil.toBean(shopJson, Shop.class);}// 判断命中的是否是空值if (shopJson != null) {// 返回一个错误信息return null;}// 4.不存在,根据id查询数据库Shop shop = getById(id);// 5.不存在,返回错误if (shop == null) {return Result.fail("店铺不存在!");}// 6.存在,写入redisstringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop));// 7.返回return shop;}
提出问题
第一次获取时Redi没有,去数据库中获取,这时候的数据肯定是准确的(排除一些数据库脏读幻读等等情况),但是这些存入Redis中的数据虽然是不经常发生改变的,但是肯定会存在改变的情况,当数据库信息改变的时候,你再去访问,还是先获取Redis中的,所以就会导致缓存更新的问题,数据库和缓存不一致的问题。
解决方案(三种常用的读写策略):

- Cache Aside Pattern (旁路缓存)人工编码方式:缓存调用者在更新完数据库后再去更新缓存,也称之为双写方案。
- Read/Write Through Pattern(读写穿透) : 由系统本身完成,数据库与缓存的问题交由系统本身去处理。
- Write Behind Caching Pattern(异步缓存) :调用者只操作缓存,其他线程去异步处理数据库,实现最终一致。
- 三种模式各有优劣,不存在最佳模式,根据具体的业务场景选择适合自己的缓存读写模式。
- 第一种方案常用,适合请求比较多的场景,这里综合考虑我们也使用该方案。
- 但是作为调用者处理上面对着三个问题:
- 删除缓存还是更新缓存
- 更新缓存:每次更新数据库都更新缓存,无效写操作较多
- 删除缓存:更新数据库时让缓存失效,查询时再更新缓存
- 如何保证缓存与数据库的操作同时成功或失败
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
- 先操作缓存还是先操作数据库
- 先删除缓存,再操作数据库:假设第一个线程先删除缓存,然后更新数据库,但是更新前有第二个线程来获取数据,它肯定先获取redis缓存,但是缓存已经被第一个线程删除,所以去数据库查询,然后将查询完的又写入redis缓存中。最后第一个线程再更新数据库,但是它更新数据库前第二个线程把原来的数据已经写入缓存了,又出现了不一致现象。
- 先操作数据库,再删除缓存:这种方案如果上诉场景也会出现不一致,但是第二次访问时就会一致,因为它操作完数据库后把缓存删了,所以删除缓存后,无论谁来访问肯定是要去访问数据库,然后再写入redis缓存中,实现了更新。
- 最终思路:
- 查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间,设置超时时间后会实现定缓存失效,然后后面访问数据库实现再次查询数据库并写入缓存,并设置时间,形成一个良性循环。
- 修改店铺时,先修改数据库,再删除缓存。
public Shop queryWithPassThrough(Long id){String key = CACHE_SHOP_KEY + id;// 1.从redis查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isNotBlank(shopJson)){// 3.存在,直接返回return JSONUtil.toBean(shopJson, Shop.class);}// 判断命中的是否是空值if (shopJson != null) {// 返回一个错误信息return Result.fail("店铺不存在!");}// 4.不存在,根据id查询数据库Shop shop = getById(id);// 5.不存在,返回错误if (shop == null) {// 将空值写入redisstringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);return null;}// 6.存在,写入redisstringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);// 7.返回return shop;}
@Transactionalpublic Result update(Shop shop) {Long id = shop.getId();if (id == null) {return Result.fail("店铺id不能为空");}// 1.更新数据库updateById(shop);// 2.删除缓存stringRedisTemplate.delete(CACHE_SHOP_KEY + id);return Result.ok();}
三、三大缓存问题
缓存穿透
缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
- 常见两种解决方案:
- 缓存空对象
- 优点:实现简单,维护方便
- 缺点:1.额外的内存消耗;2.可能造成短期不一致
- 布隆过滤
- 优点:内存占用较少,没有多余key
- 缺点:1.实现复杂;2.存在误判可能
缓存空对象思路分析:当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,简单的解决方案就是哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到缓存了。
布隆过滤:布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,假设布隆过滤器判断这个数据不存在,则直接返回。这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突。
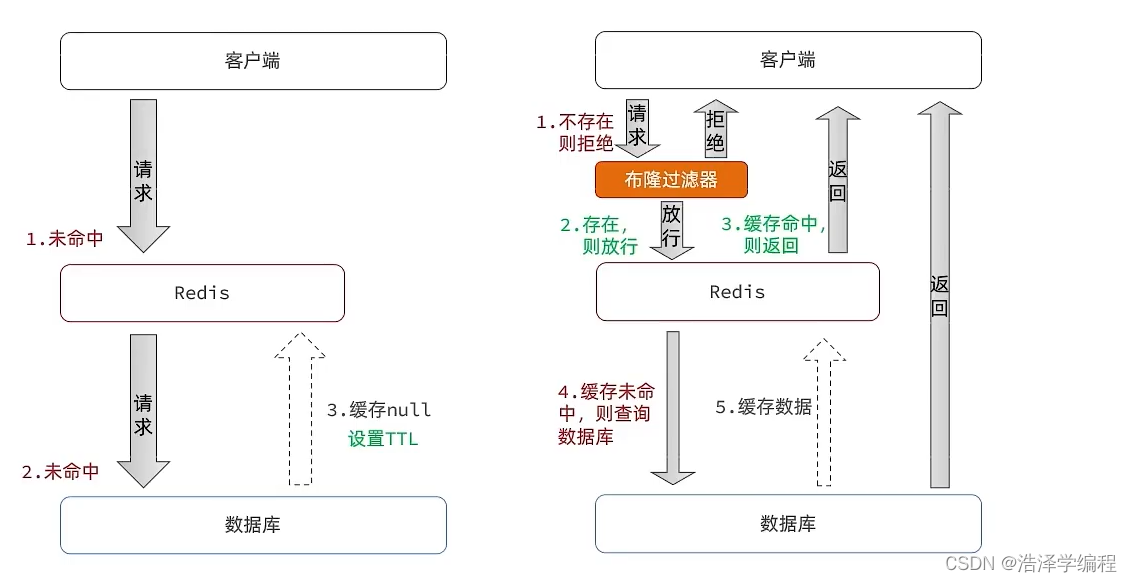
在原来的逻辑中,我们如果发现这个数据在mysql中不存在,直接就返回404了,这样是会存在缓存穿透问题的。大家可以想想如果有人恶意攻击你的网站,多个本来不存在的数据获取同时访问,因为缓存中没有,都会直达数据库。
现在的逻辑中:如果这个数据不存在,我们不会返回404 ,还是会把这个数据写入到Redis中,并且将value设置为空,再次发起查询时,我们如果发现命中之后,判断这个value是否是null,如果是null,则是之前写入的数据,证明是缓存穿透数据,如果不是,则直接返回数据。
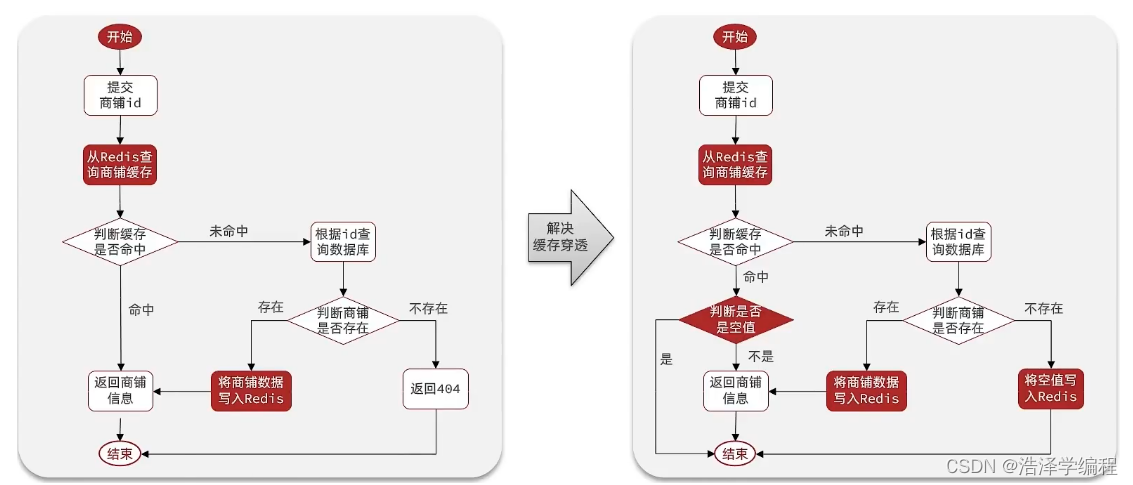
public Shop queryWithPassThrough(Long id){String key = "cache:shop:" + id;// 1.从redis查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isNotBlank(shopJson)){// 3.存在,直接返回return JSONUtil.toBean(shopJson, Shop.class);}// 判断命中的是否是空值if (shopJson != null) {// 返回一个错误信息return null;}// 4.不存在,根据id查询数据库Shop shop = getById(id);// 5.不存在,返回错误if (shop == null) {// 将空值写入redisstringRedisTemplate.opsForValue().set(key,"",30L,TimeUnit.MINUTES);return null;}// 6.存在,写入redisstringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);// 7.返回return shop;}
缓存穿透的解决方案有哪些?
- 缓存null值
- 布隆过滤
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
缓存雪崩
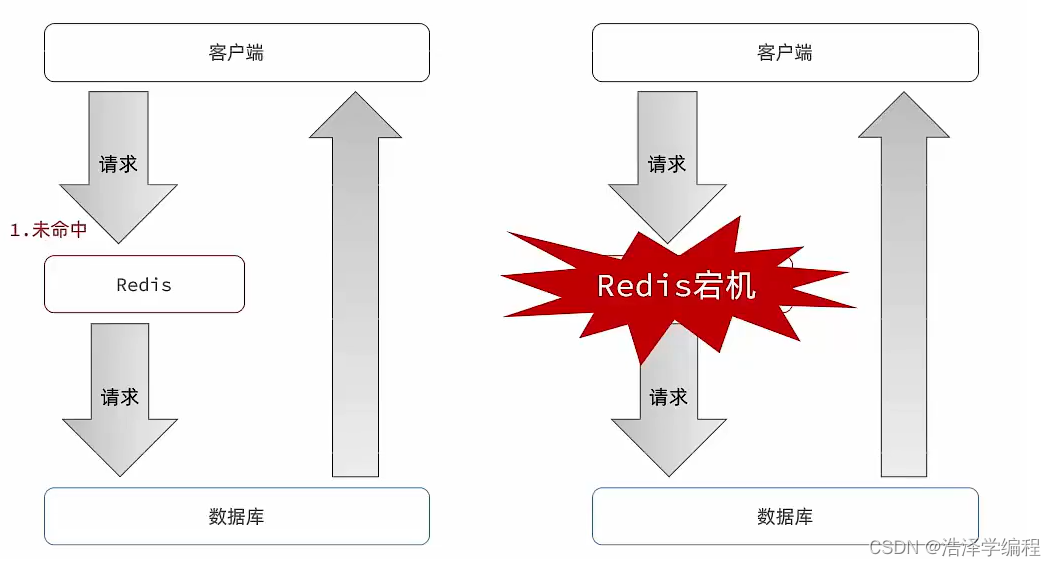
- 缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
- 解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿
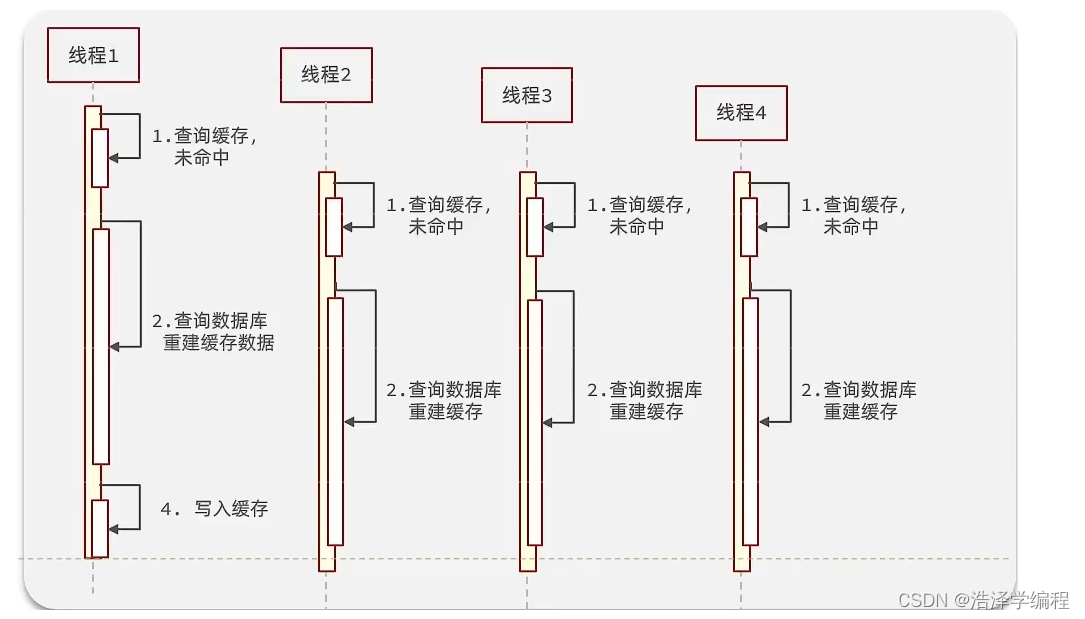
- 缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
- 常见的解决方案(两种):
- 互斥锁
- 逻辑过期锁
- 逻辑分析:假设线程1在查询缓存之后,本来应该去查询数据库,然后把这个数据重新加载到缓存的,此时只要线程1走完这个逻辑,其他线程就都能从缓存中加载这些数据了,但是假设在线程1没有走完的时候,后续的线程2,线程3,线程4同时过来访问当前这个方法, 那么这些线程都不能从缓存中查询到数据,那么他们就会同一时刻来访问查询缓存,都没查到,接着同一时间去访问数据库,同时的去执行数据库代码,对数据库访问压力过大。
互斥锁实现
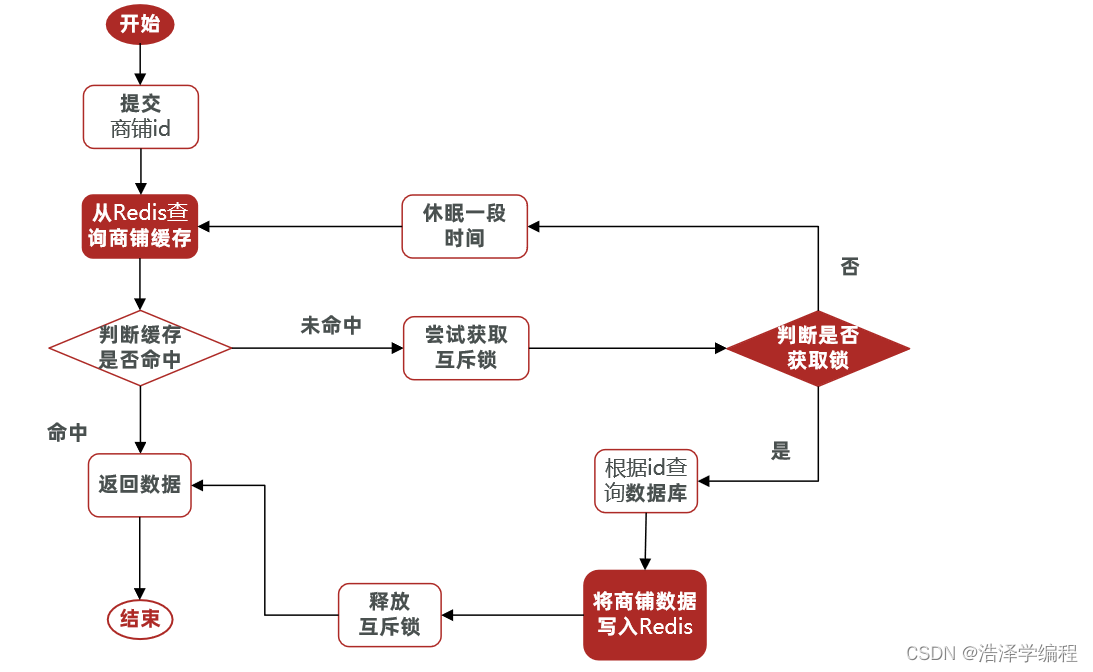
因为锁能实现互斥性。假设线程过来,只能一个人一个人的来访问数据库,从而避免对于数据库访问压力过大,但这也会影响查询的性能,因为此时会让查询的性能从并行变成了串行,我们可以采用tryLock方法 + double check来解决这样的问题。
假设现在线程1过来访问,他查询缓存没有命中,但是此时他获得到了锁的资源,那么线程1就会一个人去执行逻辑,假设现在线程2过来,线程2在执行过程中,并没有获得到锁,那么线程2就可以进行到休眠,直到线程1把锁释放后,线程2获得到锁,然后再来执行逻辑,此时就能够从缓存中拿到数据了。

核心思路:利用redis的setnx方法来表示获取锁,该方法含义是redis中如果没有这个key,则插入成功,返回1,在stringRedisTemplate中返回true, 如果有这个key则插入失败,则返回0,在stringRedisTemplate返回false,我们可以通过true,或者是false,来表示是否有线程成功插入key,成功插入的key的线程我们认为他就是获得到锁的线程。
private boolean tryLock(String key) {Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);
}private void unlock(String key) {stringRedisTemplate.delete(key);
}
public Shop queryWithMutex(Long id) {String key = CACHE_SHOP_KEY + id;// 1、从redis中查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get("key");// 2、判断是否存在if (StrUtil.isNotBlank(shopJson)) {// 存在,直接返回return JSONUtil.toBean(shopJson, Shop.class);}//判断命中的值是否是空值if (shopJson != null) {//返回一个错误信息return null;}// 4.实现缓存重构//4.1 获取互斥锁String lockKey = "lock:shop:" + id;Shop shop = null;try {boolean isLock = tryLock(lockKey);// 4.2 判断否获取成功if(!isLock){//4.3 失败,则休眠重试Thread.sleep(50);return queryWithMutex(id);}//4.4 成功,根据id查询数据库shop = getById(id);// 5.不存在,返回错误if(shop == null){//将空值写入redisstringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);//返回错误信息return null;}//6.写入redisstringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_NULL_TTL,TimeUnit.MINUTES);}catch (Exception e){throw new RuntimeException(e);}finally {//7.释放互斥锁unlock(lockKey);}return shop;}
逻辑过期时间实现
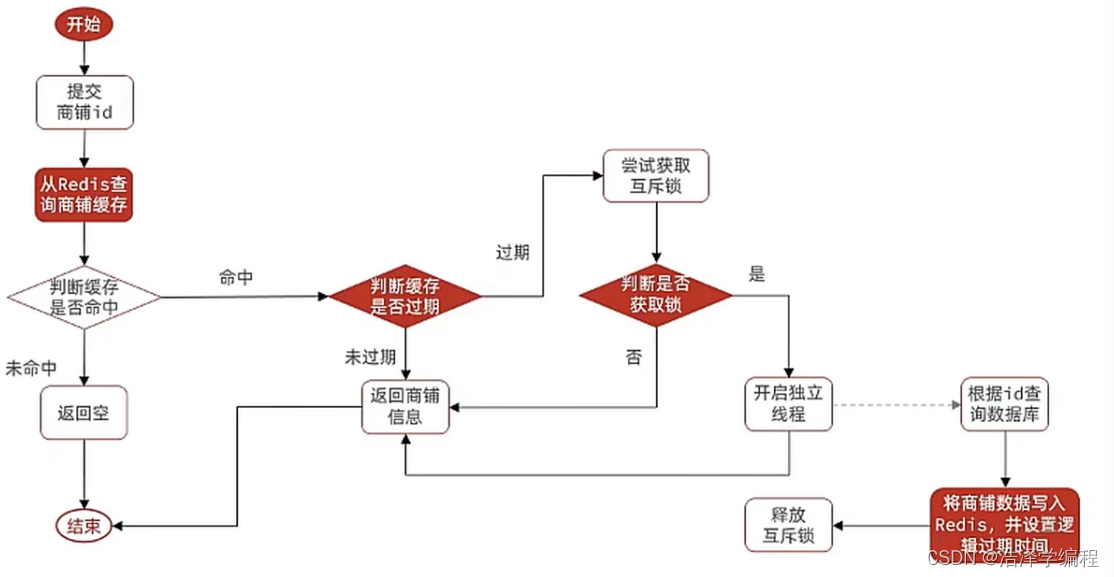
我们把过期时间设置在 redis的value中,注意:这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理。假设线程1去查询缓存,然后从value中判断出来当前的数据已经过期了,此时线程1去获得互斥锁,那么其他线程会进行阻塞,获得了锁的线程他会开启一个 线程去进行 以前的重构数据的逻辑,直到新开的线程完成这个逻辑后,才释放锁, 而线程1直接进行返回,假设现在线程3过来访问,由于线程线程2持有着锁,所以线程3无法获得锁,线程3也直接返回数据,只有等到新开的线程2把重建数据构建完后,其他线程才能走返回正确的数据。
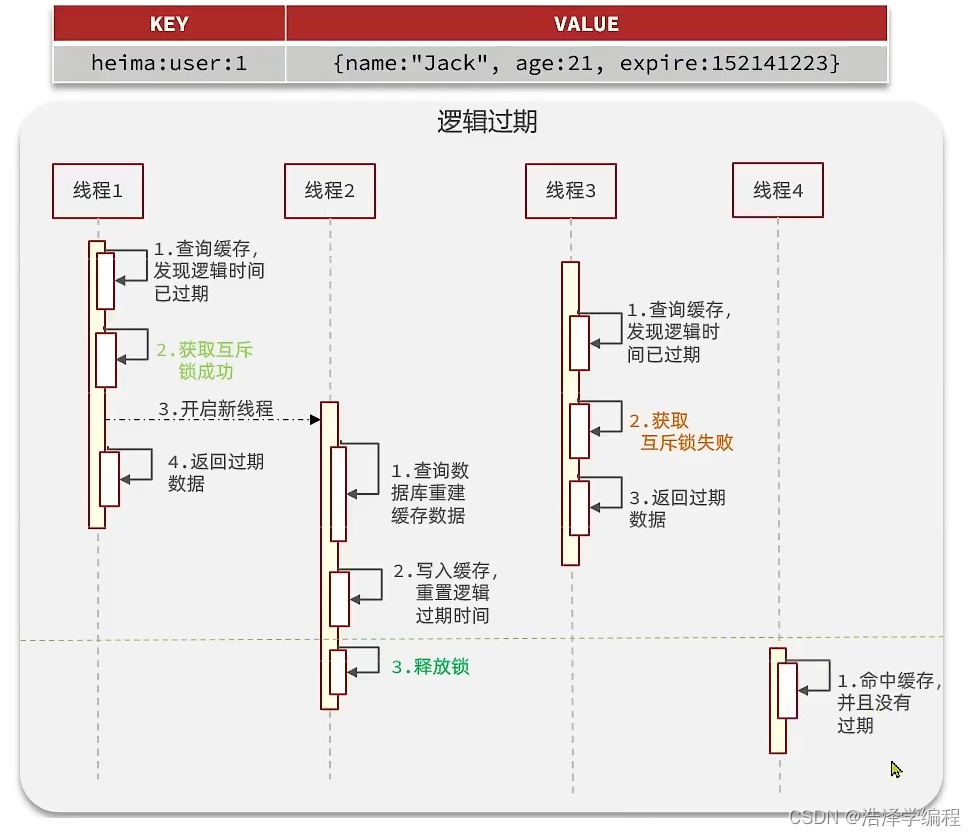
思路分析:当用户开始查询redis时,判断是否命中,如果没有命中则直接返回空数据,不查询数据库,而一旦命中后,将value取出,判断value中的过期时间是否满足,如果没有过期,则直接返回redis中的数据,如果过期,则在开启独立线程后直接返回之前的数据,独立线程去重构数据,重构完成后释放互斥锁。
因为现在redis中存储的数据的value需要带上过期时间,此时要么你去修改原来的实体类,要么你就是重新封装。
@Data
public class RedisData {private LocalDateTime expireTime;// 过期时间private Object data;// 存储的对象
}
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public Shop queryWithLogicalExpire( Long id ) {String key = CACHE_SHOP_KEY + id;// 1.从redis查询商铺缓存String json = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isBlank(json)) {// 3.存在,直接返回return null;}// 4.命中,需要先把json反序列化为对象RedisData redisData = JSONUtil.toBean(json, RedisData.class);Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);LocalDateTime expireTime = redisData.getExpireTime();// 5.判断是否过期if(expireTime.isAfter(LocalDateTime.now())) {// 5.1.未过期,直接返回店铺信息return shop;}// 5.2.已过期,需要缓存重建// 6.缓存重建// 6.1.获取互斥锁String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);// 6.2.判断是否获取锁成功if (isLock){CACHE_REBUILD_EXECUTOR.submit( ()->{try{//重建缓存this.saveShop2Redis(id,20L);}catch (Exception e){throw new RuntimeException(e);}finally {unlock(lockKey);}});}// 6.4.返回过期的商铺信息return shop;
}
总结
以上就是Redis缓存的详细讲解与实现。
相关文章:
Redis之缓存
文章目录 前言一、缓存使用缓存的原因 二、使用缓存实现思路提出问题 三、三大缓存问题缓存穿透缓存雪崩缓存击穿互斥锁实现逻辑过期时间实现 总结 前言 本篇文章即将探索的问题(以黑马点评为辅助讲解,大家主要体会实现逻辑) 使用redis缓存的…...
Redis6的IO多线程分析
性能测试 机器配置 C Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 14 On-line CPU(s) list: 0-13 Mem: 62G性能 配置推荐 官方表示,当使用redis时有性能瓶…...

kali linux安装教程
安装 Kali Linux 非常简单,下面是基本的步骤: 首先下载 Kali Linux 的 ISO 镜像文件。你可以从官方网站 https://www.kali.org/downloads/ 下载。 确保你的计算机支持使用盘或者 USB 启动。你可以在计算机开机时按下 F12 或者其他类似的按键,…...
React进阶之路(四)-- React-router-v6、Mobx
文章目录 ReactRouter前置基本使用核心内置组件说明编程式导航路由传参嵌套路由默认二级路由404路由配置集中式路由配置 Mobx什么是Mobx环境配置基础使用observer函数*计算属性(衍生状态)异步数据处理模块化多组件数据共享Mobx和React职责划分 ReactRout…...
55基于matlab的1.高斯噪声2.瑞利噪声3.伽马噪声4.均匀分布噪声5.脉冲(椒盐)噪声
基于matlab的1.高斯噪声2.瑞利噪声3.伽马噪声4.均匀分布噪声5.脉冲(椒盐)噪声五组噪声模型,程序已调通,可直接运行。 55高斯噪声、瑞利噪声 (xiaohongshu.com)...
Codeforces Round 908 (Div. 2)视频详解
Educational Codeforces Round 157 (A--D)视频详解 视频链接A题代码B题代码C题代码D题代码 视频链接 Codeforces Round 908 (Div. 2)视频详解 A题代码 #include<bits/stdc.h> #define endl \n #define deb(x) cout << #x << "…...
电路综合-基于简化实频的SRFT集总参数切比雪夫低通滤波器设计
电路综合-基于简化实频的SRFT集总参数切比雪夫低通滤波器设计 6、电路综合-基于简化实频的SRFT微带线切比雪夫低通滤波器设计中介绍了使用微带线进行切比雪夫滤波器的设计方法,在此对集总参数的切比雪夫响应进行分析。 SRFT集总参数切比雪夫低通滤波器综合不再需要…...
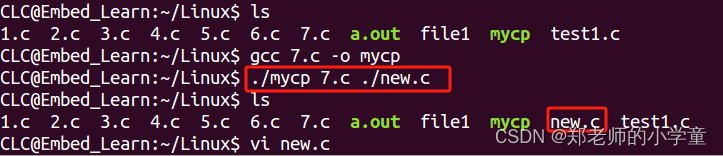
Linux系统编程——实现cp指令(应用)
cp指令格式 cp [原文件] [目标文件] cp 1.c 2.c 功能是将原文件1.c复制后并改名成2.c(内容相同,实现拷贝) 这里需要引入main函数的参数解读: 我们在定义函数时许多都带有参数,输入参数后便可进行定义函数内的功能执行,而main…...
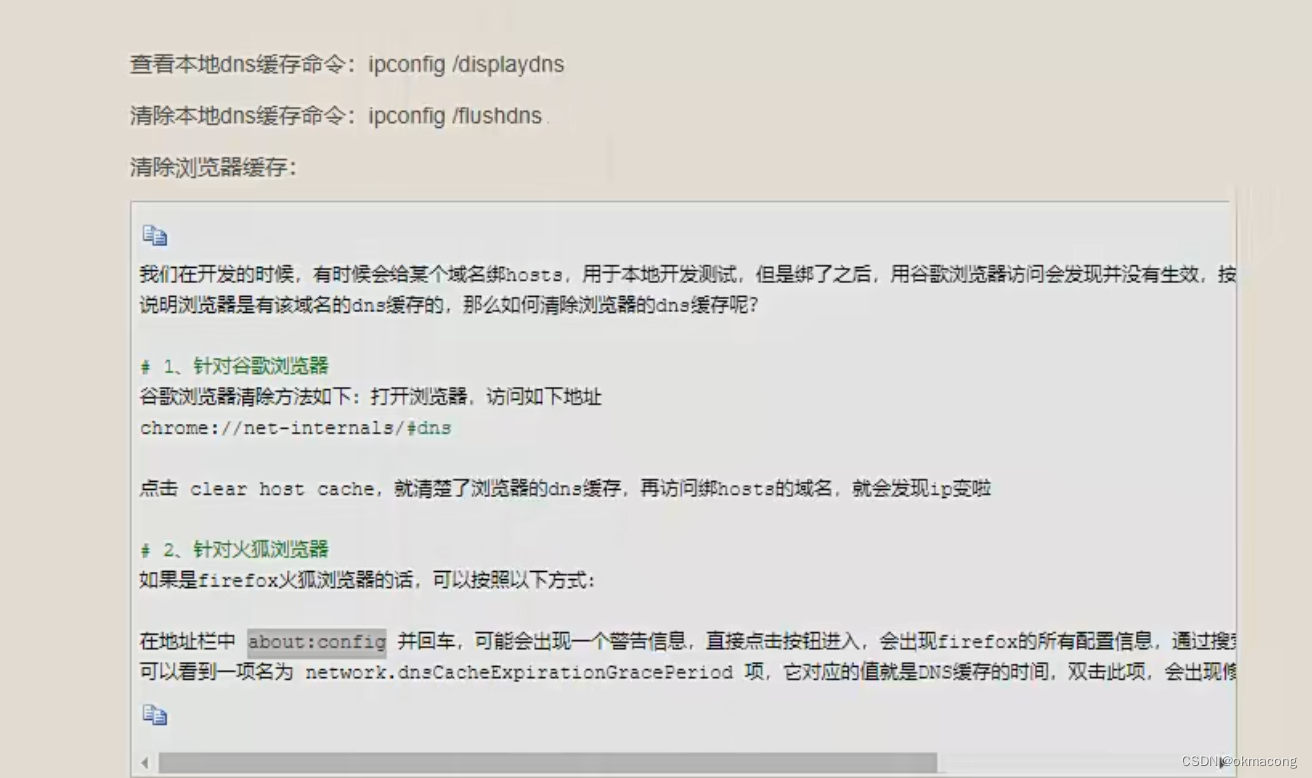
20231112_DNS详解
DNS是实现域名与IP地址的映射。 1.映射图2.DNS查找顺序图3.DNS分类和地址4.如何清除缓存 1.映射图 图片来源于http://egonlin.com/。林海峰老师课件 2.DNS查找顺序图 3.DNS分类和地址 4.如何清除缓存...

使用ssh上传数据到阿里云ESC云服务上
在这之前需要安装 ssh2-sftp-client 直接在终端输入:npm i ssh2-sftp-client 直接上代码: const path require(path); const Client require(ssh2-sftp-client);// 配置连接参数 const config {host: your-server-ip, // 云服务器的IP地址port: 22, …...

【408】计算机学科专业基础 - 数据结构
数据结构知识 绪论 数据结构在学什么 如何用程序代码把现实世界的问题信息化 如何用计算机高效地处理这些信息从而创造价值 数据结构的基本概念 什么是数据: 数据是信息的载体,是描述客观事物属性的数、字符及所有能输入到计算机中并被计算机程序…...

SpringSpringBoot自动装配
文章目录 spring自动装配的好处Spring框架提供了三种自动装配的方式:Springboot自动装配Springboot自动装配的原理 spring自动装配的好处 Spring的自动装配(Autoscan or Autowiring)在开发中带来了多方面的好处,使得应用程序更加…...
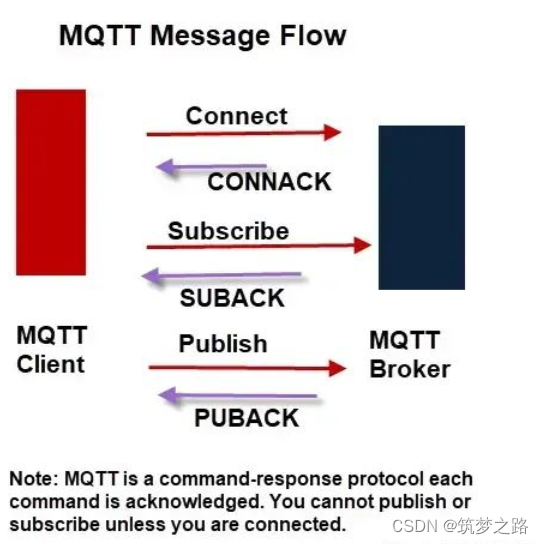
k8s 部署mqtt —— 筑梦之路
mqtt是干嘛的,网上有很多资料,这里就不再赘述。 --- apiVersion: apps/v1 kind: Deployment metadata:labels:app: mqttname: mqttnamespace: default spec:replicas: 1selector:matchLabels:app: mqttstrategy:rollingUpdate:maxSurge: 25%maxUnavaila…...

模型部署:量化中的Post-Training-Quantization(PTQ)和Quantization-Aware-Training(QAT)
模型部署:量化中的Post-Training-Quantization(PTQ)和Quantization-Aware-Training(QAT) 前言量化Post-Training-Quantization(PTQ)Quantization-Aware-Training(QAT) 参…...
- - - 题目答案)
C++模板元模板(异类词典与policy模板)- - - 题目答案
目录 一、书中第一题 二、书中第三题 三、书中第五题 四、书中第六题 五、书中第七题 六、书中十一题 七、书中十二题 八、 书中十三题 总结 一、书中第一题 #include <iostream>template <typename T, size_t N> struct NSVarTypeDict {static void Cre…...

二十三种设计模式全面解析-组合模式与迭代器模式的结合应用:构建灵活可扩展的对象结构
在前文中,我们介绍了组合模式的基本原理和应用,以及它在构建对象结构中的价值和潜力。然而,组合模式的魅力远不止于此。在本文中,我们将继续探索组合模式的进阶应用,并展示它与其他设计模式的结合使用,以构…...
postgresql|数据库|提升查询性能的物化视图解析
前言: 我们一般认为数字的世界是一个虚拟的世界,OK,但我们其实有些需求是和现实世界一模一样的,比如,数据库尤其是关系型数据库,希望在使用的数据库能够更快(查询速度),…...
Unity中Shader雾效的原理
文章目录 前言一、我们先看一下现实中的雾二、雾效的混合公式最终的颜色 lerp(雾效颜色,物体颜色,雾效混合因子) 三、雾效的衰减1、FOG_LINEAR(线性雾衰减)2、FOG_EXP(指数雾衰减1)3、FOG_EXP(指数雾衰减2) 前言 Unity中Shader雾…...

chatgpt辅助论文优化表达
chatgpt辅助论文优化表达 写在最前面最终版什么是好的论文整体上:逻辑/连贯性细节上一些具体的修改例子 一些建议,包括具体的提问范例1. **明确你的需求**2. **提供上下文信息**3. **明确问题类型**4. **测试不同建议**5. **请求详细解释**综合提问范例&…...
——初始化应用实例)
Vue3 源码解读系列(二)——初始化应用实例
初始化应用实例 创建 Vue 实例对象 createApp 中做了两件事: 创建 app 对象保存并重写 mount /*** 创建 Vue 实例对象*/ const createApp ((...args) > {// 1、创建 app 对象,延时创建渲染器,优点是当用户只依赖响应式包的时候࿰…...

基于前述双系统安装与切换遇到的问题
一、 引导管理类问题 这类问题是双系统环境中最常见且最影响使用的核心故障。 1. GRUB菜单丢失,开机直接进入Windows 问题现象:安装Kali后首次重启或Windows系统更新后,GRUB引导菜单消失,计算机直接启动至Windows。根本原因&am…...

OpenClaw技能市场挖掘:百川2-13B-4bits量化版适配插件精选
OpenClaw技能市场挖掘:百川2-13B-4bits量化版适配插件精选 1. 为什么需要专门适配百川模型的技能? 去年冬天第一次尝试用OpenClaw对接百川2-13B模型时,我遇到了一个典型问题:虽然模型本身运行良好,但很多现成的技能模…...

uniSDK5.06 HBuilder-Integrate-AS 引入 AeroFFmpeg
用Android Studio 导入 unisdk5.06\Android-SDK5.06.82597_20260401\HBuilder-Integrate-AS 工程需要下载 jdk17 安卓SDK通过网盘分享的文件:unisdk5.06.rar 链接: https://pan.baidu.com/s/1cYeW29xsoqIa6lh4wk16FQ?pwdp8ak 提取码: p8ak...

一文讲清,精益六西格玛咨询是什么意思?做精益六西格玛咨询对企业有什么用?
精益六西格玛咨询到底是什么?简单来说,精益六西格玛咨询是一种将精益生产的效率与六西格玛的质量管理相结合的系统化服务,旨在帮助企业消除浪费并减少变异。通过引入精益六西格玛咨询,企业能够利用数据驱动的方法解决复杂的管理难…...

Pokerobo_PSx:轻量级PS2手柄嵌入式驱动库
1. Pokerobo_PSx 库概述Pokerobo_PSx 是一个专为嵌入式系统设计的轻量级 PS2 DualShock 手柄通信协议栈,面向 STM32、ESP32、nRF52 等主流 MCU 平台,提供完整、稳定、可裁剪的 PlayStation 2 游戏手柄(含 DualShock 1/2 及兼容设备࿰…...
(基于System V的信号量和消息队列))
Linux相关概念和易错知识点(52)(基于System V的信号量和消息队列)
目录1、System V信号量(1)信号量的本质与核心原理(2)PV原语(均为原子操作)a. P原语(申请资源)b. V原语(归还资源)(3)System V信号量接…...

Blazor组件化演进终极指南:2026年必须掌握的5大架构范式与3种反模式规避清单
第一章:Blazor组件化演进的底层动因与2026技术坐标系Blazor 的组件化并非单纯语法糖的迭代,而是对 Web 前端架构范式、.NET 生态边界以及现代云原生交付链路三重压力下的系统性响应。其底层动因根植于三个不可逆趋势:WebAssembly 运行时成熟度…...

终极指南:readme.so无障碍设计如何为所有开发者打造包容性体验
终极指南:readme.so无障碍设计如何为所有开发者打造包容性体验 【免费下载链接】readme.so An online drag-and-drop editor to easily build READMEs 项目地址: https://gitcode.com/gh_mirrors/re/readme.so readme.so作为一款在线拖拽式README编辑器&…...

亚洲美女-造相Z-TurboGPU算力优化:FP16量化+FlashAttention加速部署方案
亚洲美女-造相Z-Turbo GPU算力优化:FP16量化FlashAttention加速部署方案 想快速部署一个能生成高质量亚洲美女图片的AI模型,但又担心显存不够、速度太慢?今天分享一个经过深度优化的部署方案,让你用更少的资源,跑出更…...
)
仅限首批200名开发者获取:Java 25虚拟线程高并发架构迁移评估工具包(含代码扫描器+风险热力图+ROI预测模型)
第一章:Java 25虚拟线程高并发架构迁移全景认知Java 25正式将虚拟线程(Virtual Threads)从预览特性转为标准特性,标志着JVM并发模型进入轻量级、高密度、低开销的新纪元。虚拟线程基于Project Loom多年演进,以java.lan…...