加班把数据库重构完毕
加班把数据库重构完毕
本文的数据库重构是基于 clickhouse 时序非关系型的数据库。该数据库适合存储股票数据,速度快,一般查询都是 ms 级别,不需要异步查询更新界面 ui。
达到目标效果:数据表随便删除,重新拉数据以及指标计算,十多年的数据,整一个过程 5-6 分钟即可,速度远超通达信。因为每个季度数据回除权,所以旧的数据是有问题的,现在再也不怕删数据重新拉取重新计算了。
为啥要重构?
-
以前日行情数据和指标数值是分开两个表的,后面继续研究 clickhouse 数据库,发现根本不需要多表存储,因为 clickhouse 是列存储方式,所以宽表并不会影响查询速度。
-
以前数据经常出现不完整情况,指标数据计算会发生日级别的断层。
-
以前数据重复插入的时候,查出来经常需要去重,增加了消耗。
-
以前很害怕数据重新拉取和计算,因为经常出现数据不完整问题,都不敢删重新来过,不然又要停机查问题了,现在随便删随便重新计算,彻底解决了这个问题。
关键设计
把所有的股票的日行情数据和指标数据存储在一个表
理由:
-
可以多个股票同时查询。 -
可以多个股票同一个时间段同时查询。 -
可以选择性查询某部分字段,不需要跨表,从而提高效率。 -
可以完成数据的完整性和自动去重。
疑问:
-
有的同学疑惑,所有日行情数据和指标数据放一个表会不会增加查询速度。
答案:不会,这是因为 clickhouse 为快速处理这大数据问题效率慢设计好了。 -
如何设置排序值?
答案:因为我们把所有股票数据以及指标放在了同一个表中,所以需要把 date 和 code 两个字段作为键值。
如何避免重复插入,查询数据是使用最新的数据?
-
clickhouse 数据库并不擅长单列更新的,所以我们要更新某列的时候,原则是:先把要更新的行查出来,然后计算指标数据,填充完后,直接插回去即可,所以每一行需要添加一个 version 版本号,数据库会自动去重保存最新的版本号数据,旧数据数据库会自动删除。
-
由于采取的策略是查询数据出来,计算指标填充完重新插回去,所以我们使用的引擎策略是,ReplacingMergeTree,这个的意思是 clickhouse 数据库会自动去重。
-
查询,由于插入新的行的时候,如果有重复行 clickhouse 数据库是在后台不知何时才会自动触发去掉旧数据的,所以查询的使用要加个小技巧,要以版本号进行排序,然后取最新的一条, ORDER BY version DESC,LIMIT 1 BY code,date。具体的见代码。
-
创建表的关键。 引擎: ENGINE=ReplacingMergeTree(version) 以版本号作为去重标准,保留最新版本号的数据
主键: PRIMARY KEY(javaHash(code), date) ,由于所有日行情数据放一个表,所以以 code,date 两个字段确定一行数据。
排序值: ORDER BY(javaHash(code), date),以 code 和 date 作为排序,有了解过 clickhouse 数据库的同学就会知道,这两个字段决定了 clickhouse 的数据存储方式。
福利
如何同学也使用 clickhouse 数据库用来存储股票数据,或者还未建立数据库来存储数据的,建议你使用 clickhouse 用来存储,别用 MySql,场景不一样,MySql 适合业务型的,clickhouse 天生就是为数据分析而产生的。所以在查询速度上,clickhouse 是碾压 MySql 的。
可以直接使用我的代码,是经过不断测试趋于完善的了,没 bug 了。
我的重构代码:
import time
import pandahouse as ph
import pandas as pd
from clickhouse_driver import Client
'''
pandahouse 是通过http url 链接,端口号是8123
'''
connection = dict(database="stock",
host="http://localhost:8123",
user='default',
password='sykent')
'''
clickhouse_driver 是通过TCP链接,端口号是9000
'''
DB = 'stock'
# settings = {'max_threads': 5}
client = Client(database=f'{DB}',
host='127.0.0.1',
port='9000',
user='default',
password='sykent',
# settings=settings
)
sql = 'SET max_partitions_per_insert_block = 200'
client.execute(sql)
"""
表名
"""
STOCK_DAILY_TABLE = 'stock_daily_price_v2'
INDUSTRY_DAILY_TABLE = 'industry_daily_v2'
INDUSTRY_CONSTITUENT_STOCK_TABLE = 'industry_constituent_stock_v2'
MARKET_DAILY_TABLE = 'market_daily_v2'
def stock_daily(
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询股票某个时间段日线数据
:param pool_code: 股票代码池 list() ['000001', '000002'] 或者 '000001'
:param start_time: 开始时间
:param end_time: 结束时间
:param use_col: 使用的列 list() ['open', 'close'],不传则使用全部列
"""
return __query_daily_related(
STOCK_DAILY_TABLE,
pool_code,
start_time,
end_time,
use_col
)
def stock_daily_http(
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询股票某个时间段日线数据
:param pool_code: 股票代码池 list() ['000001', '000002'] 或者 '000001'
:param start_time: 开始时间
:param end_time: 结束时间
:param use_col: 使用的列 list() ['open', 'close'],不传则使用全部列
"""
return __query_daily_related_http(
STOCK_DAILY_TABLE,
pool_code,
start_time,
end_time,
use_col
)
def stock_daily_on_date(
pool_code,
date_time,
use_col=None
) -> pd.DataFrame:
"""
查询股票某日日线数据
:param pool_code: 股票代码池 list() ['000001', '000002'] 或者 '000001'
:param date_time: 日期
:param use_col: 使用的列 list() ['open', 'close'],不传则使用全部列
"""
return stock_daily(
pool_code,
date_time,
date_time,
use_col
)
def industry_daily(
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询行业某个时间段日线数据
:param 参照stock_daily
"""
return __query_daily_related(
INDUSTRY_DAILY_TABLE,
pool_code,
start_time,
end_time,
use_col
)
def industry_daily_on_date(
pool_code,
date_time,
use_col=None
) -> pd.DataFrame:
"""
查询行业某日日线数据
:param 参照stock_daily_on_date
"""
return industry_daily(
pool_code,
date_time,
date_time,
use_col
)
def all_industry_daily_on_date(
date_time,
use_col=None
) -> pd.DataFrame:
"""
查询所有板块的某个日期的rps
:param date_time:
:param use_col:
:return:
"""
if use_col is None:
sql = f"""
SELECT *
FROM {DB}.{INDUSTRY_DAILY_TABLE}
WHERE date == '{date_time}'
ORDER BY version DESC
LIMIT 1 BY code,date
"""
else:
columns = 'date,code,' + ','.join(use_col) + ',version'
sql = f"""
SELECT {columns}
FROM {DB}.{INDUSTRY_DAILY_TABLE}
WHERE date == '{date_time}'
ORDER BY version DESC
LIMIT 1 BY code,date
"""
df = from_table(sql)
if df.empty:
return df
else:
df.drop(columns='date', inplace=True)
return df
def market_daily(
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询大盘指数某个时间段日线数据
:param 参照stock_daily
"""
return __query_daily_related(
MARKET_DAILY_TABLE,
pool_code,
start_time,
end_time,
use_col
)
def market_daily_on_date(
pool_code,
date_time,
use_col=None
) -> pd.DataFrame:
"""
查询大盘指数某日日线数据
:param 参照stock_daily_on_date
"""
return market_daily(
pool_code,
date_time,
date_time,
use_col
)
def board_constituent_stock(
code
) -> pd.DataFrame:
"""
板块成分股
:param code: 板块代码
:return:
"""
sql = f"""
SELECT *
FROM {DB}.{INDUSTRY_CONSTITUENT_STOCK_TABLE}
WHERE industry_code == '{code}'
"""
return from_table(sql)
# @timing_decorator
def to_table(data, table):
if data.empty:
return 0
# 获取columns 如果不包含 'date',重置index
if 'date' not in data.columns:
data.reset_index(inplace=True)
data.insert(data.shape[1], 'version', int(time.time()))
columns = ', '.join(data.columns)
sql = f'INSERT INTO {table} ({columns}) VALUES'
client.execute(sql, data.values.tolist())
return data.shape[0]
# @timing_decorator
def to_table_common(data, table):
columns = ', '.join(data.columns)
sql = f'INSERT INTO {table} ({columns}) VALUES'
client.execute(sql, data.values.tolist())
return data.shape[0]
# @timing_decorator
def from_table(sql) -> pd.DataFrame:
last_time = time.time()
try:
result = client.query_dataframe(sql)
except Exception as e:
print(e)
result = pd.DataFrame()
print("db-> 耗时: {} sql: {}".format((time.time() - last_time) * 1000, sql))
return result
def from_table_http(sql):
"""
查询表
:param sql:
:return: dataframe
"""
last_time = time.time()
df = ph.read_clickhouse(sql, connection=connection)
print("db-> 耗时: {} sql: {}".format((time.time() - last_time) * 1000, sql))
return df
def __creat_daily_related_table(table_name, **kwargs):
"""
创建日行情相关的表
注意:一定需要date,code这两列,作为排序值
:param table_name: 表名
:param kwargs: 列名
:return:
"""
columns_str = ''
for key, value in kwargs.items():
columns_str = columns_str + f'{key} {value},'
columns_str = columns_str[:len(columns_str) - 1]
# 自动添加列名 version 用于插入更新数据
columns_str = columns_str + ',version Int64'
if 'code' not in columns_str or 'date' not in columns_str:
raise Exception('not column code date!!')
sql = f"""
CREATE TABLE if NOT EXISTS {table_name}({columns_str})
ENGINE=ReplacingMergeTree(version)
PRIMARY KEY(javaHash(code), date)
ORDER BY(javaHash(code), date)
"""
print('创建表sql:', sql)
client.execute(sql)
def __creat_common_table(table_name, order_by=None, **kwargs):
"""
创建通用的表,默认使用 ReplacingMergeTree,并自动添加列 version 用于插入更新数据,
而且去重的时候,只会保留version最大的数据
:param table_name: 表名
:param order_by: 排序字段
:param kwargs: 列名
"""
columns_str = ''
for key, value in kwargs.items():
columns_str = columns_str + f'{key} {value},'
columns_str = columns_str[:len(columns_str) - 1]
# 自动添加列名 version 用于插入更新数据
columns_str = columns_str + ',version Int64'
sql = f"""
CREATE TABLE if NOT EXISTS {table_name}({columns_str})
ENGINE=ReplacingMergeTree(version)
"""
if order_by is not None:
sql = sql + f' ORDER BY{order_by}'
print('创建表sql:', sql)
client.execute(sql)
def __drop_table(table_name):
"""
删除表
:param table_name:
:return:
"""
sql = f'DROP TABLE IF EXISTS {table_name}'
client.execute(sql)
print('删除表sql:', sql)
def __query_daily_related(
table,
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询股票相关的表
eg:query_daily_related(['000001', '000002'], '2021-01-01', '2022-09-30')
:param pool_code: 股票池 数据类型 list eg:'[000001', '000002']
:param start_time: 开始时间
:param end_time: 结束时间
:param use_col: list 需要返回的列,默认返回 'date,code' 并设置 date 为 index
:return:
如果 start_time == end_time 则认为是查询某一天的数据
version 为最新的数据,以此来去重
"""
# 如果传入的是单个code,转换成list
if type(pool_code) is not list:
code = pool_code
pool_code = list()
pool_code.append(code)
# 时间不相等,查询时间段的数据
if start_time != end_time:
if use_col is None:
sql = f"""
SELECT *
FROM {DB}.{table}
WHERE date BETWEEN '{start_time}' AND '{end_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
else:
columns = 'date,code,' + ','.join(use_col) + ',version'
sql = f"""
SELECT {columns}
FROM {DB}.{table}
WHERE date BETWEEN '{start_time}' AND '{end_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
df = from_table_http(sql)
if df.empty:
return df
# 设置date为index,并排序
df.set_index('date', inplace=True)
df.sort_index(inplace=True)
# 时间相等,查询某一天的数据
else:
if use_col is None:
sql = f"""
SELECT *
FROM {DB}.{table}
WHERE date == '{start_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
else:
columns = 'date,code,' + ','.join(use_col) + ',version'
sql = f"""
SELECT {columns}
FROM {DB}.{table}
WHERE date == '{start_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
df = from_table_http(sql)
if df.empty:
return df
df.drop(columns=['date'], inplace=True)
# version 为更新插入使用,删除version列
df.drop(columns=['version'], inplace=True)
return df
def __query_daily_related_http(
table,
pool_code,
start_time,
end_time,
use_col=None
) -> pd.DataFrame:
"""
查询股票相关的表
eg:query_daily_related(['000001', '000002'], '2021-01-01', '2022-09-30')
:param pool_code: 股票池 数据类型 list eg:'[000001', '000002']
:param start_time: 开始时间
:param end_time: 结束时间
:param use_col: list 需要返回的列,默认返回 'date,code' 并设置 date 为 index
:return:
如果 start_time == end_time 则认为是查询某一天的数据
version 为最新的数据,以此来去重
"""
# 如果传入的是单个code,转换成list
if type(pool_code) is not list:
code = pool_code
pool_code = list()
pool_code.append(code)
# 时间不相等,查询时间段的数据
if start_time != end_time:
if use_col is None:
sql = f"""
SELECT *
FROM {DB}.{table}
WHERE date BETWEEN '{start_time}' AND '{end_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
else:
columns = 'date,code,' + ','.join(use_col) + ',version'
sql = f"""
SELECT {columns}
FROM {DB}.{table}
WHERE date BETWEEN '{start_time}' AND '{end_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
df = from_table_http(sql)
if df.empty:
return df
df.set_index('date', inplace=True)
df.sort_index(inplace=True)
# 时间相等,查询某一天的数据
else:
if use_col is None:
sql = f"""
SELECT *
FROM {DB}.{table}
WHERE date == '{start_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
else:
columns = 'date,code,' + ','.join(use_col) + ',version'
sql = f"""
SELECT {columns}
FROM {DB}.{table}
WHERE date == '{start_time}'
AND code IN {pool_code}
ORDER BY version DESC
LIMIT 1 BY code,date
"""
df = from_table_http(sql)
if df.empty:
return df
df.drop(columns=['date'], inplace=True)
# version 为更新插入使用,删除version列
df.drop(columns=['version'], inplace=True)
return df
def stock_length(code):
"""
查询股票上市最小日期
:param code:
:return:
"""
sql = f"""
SELECT count()
FROM {DB}.{STOCK_DAILY_TABLE}
WHERE code == \'{code}\'
"""
count = client.execute(sql)[0][0]
print('stock_length sql:', sql, f'result count {count}')
return count
def create_market_daily_table():
"""
大盘数据表
:return:
"""
columns = {
'date': 'Date',
'code': 'String',
'name': 'String',
'open': 'Float32',
'high': 'Float32',
'low': 'Float32',
'close': 'Float32',
'volume': 'Float64',
'amount': 'Float64',
'change': 'Float32',
'change_amount': 'Float32',
'amplitude': 'Float32',
'turnover': 'Float32'}
__creat_daily_related_table(MARKET_DAILY_TABLE, **columns)
def create_stock_daily_table():
"""
创建日行情数据表
:return:
"""
columns = {
'date': 'Date',
'code': 'String',
'name': 'String',
'open': 'Float32',
'high': 'Float32',
'low': 'Float32',
'close': 'Float32',
'change': 'Float32',
'change_amount': 'Float32',
'volume': 'Float64',
'amount': 'Float64',
'amplitude': 'Float32',
'turnover': 'Float32',
'amp05': 'Float32',
'amp10': 'Float32',
'amp20': 'Float32',
'amp50': 'Float32',
'amp120': 'Float32',
'amp250': 'Float32',
'ma05': 'Float32',
'ma10': 'Float32',
'ma20': 'Float32',
'ma50': 'Float32',
'ma120': 'Float32',
'ma250': 'Float32',
'rps05': 'Float32',
'rps10': 'Float32',
'rps20': 'Float32',
'rps50': 'Float32',
'rps120': 'Float32',
'rps250': 'Float32', }
__creat_daily_related_table(STOCK_DAILY_TABLE, **columns)
def create_industry_daily_table():
"""
创建板块日行情
:return:
"""
columns = {
'date': 'Date',
'code': 'String',
'name': 'String',
'open': 'Float32',
'high': 'Float32',
'low': 'Float32',
'close': 'Float32',
'change': 'Float32',
'change_amount': 'Float32',
'volume': 'Float64',
'amount': 'Float64',
'amplitude': 'Float32',
'turnover': 'Float32',
'amp05': 'Float32',
'amp10': 'Float32',
'amp20': 'Float32',
'amp50': 'Float32',
'amp120': 'Float32',
'amp250': 'Float32',
'ma05': 'Float32',
'ma10': 'Float32',
'ma20': 'Float32',
'ma50': 'Float32',
'ma120': 'Float32',
'ma250': 'Float32',
'rps05': 'Float32',
'rps10': 'Float32',
'rps20': 'Float32',
'rps50': 'Float32',
'rps120': 'Float32',
'rps250': 'Float32', }
__creat_daily_related_table(INDUSTRY_DAILY_TABLE, **columns)
def create_industry_constituent_stock_table():
"""
创建板块成分股
:return:
"""
columns = {
'industry_code': 'String',
'stock_code': 'String',
'industry_name': 'String',
'stock_name': 'String'}
__creat_common_table(
table_name=INDUSTRY_CONSTITUENT_STOCK_TABLE,
order_by='(javaHash(industry_code), javaHash(stock_code))',
**columns)
def create_all_table():
# 创建日行情数据表
create_stock_daily_table()
# 创建板块日行情表
create_industry_daily_table()
# 创建板块成分股表
create_industry_constituent_stock_table()
# 创建大盘数据表
create_market_daily_table()
def optimize(table_name):
"""
手动触发数据表去重操作
场景: 在更新表后,由于重复的ReplacingMergeTree是不定时触发的,
所以可以强制调用触发。
:param table_name:
:return:
"""
sql = f'optimize table stock.{table_name}'
client.execute(sql)
def drop_all_table():
__drop_table(STOCK_DAILY_TABLE)
__drop_table(INDUSTRY_DAILY_TABLE)
__drop_table(INDUSTRY_CONSTITUENT_STOCK_TABLE)
__drop_table(MARKET_DAILY_TABLE)
def optimize_all():
optimize(STOCK_DAILY_TABLE)
optimize(INDUSTRY_DAILY_TABLE)
optimize(INDUSTRY_CONSTITUENT_STOCK_TABLE)
optimize(MARKET_DAILY_TABLE)
if __name__ == '__main__':
count = stock_length('000001')
print(count)
效果
-
重构的时候要用新的表,这样在重构的过程中不会影响旧数据的运行,稳定后就可以把新表替换旧表的逻辑了。
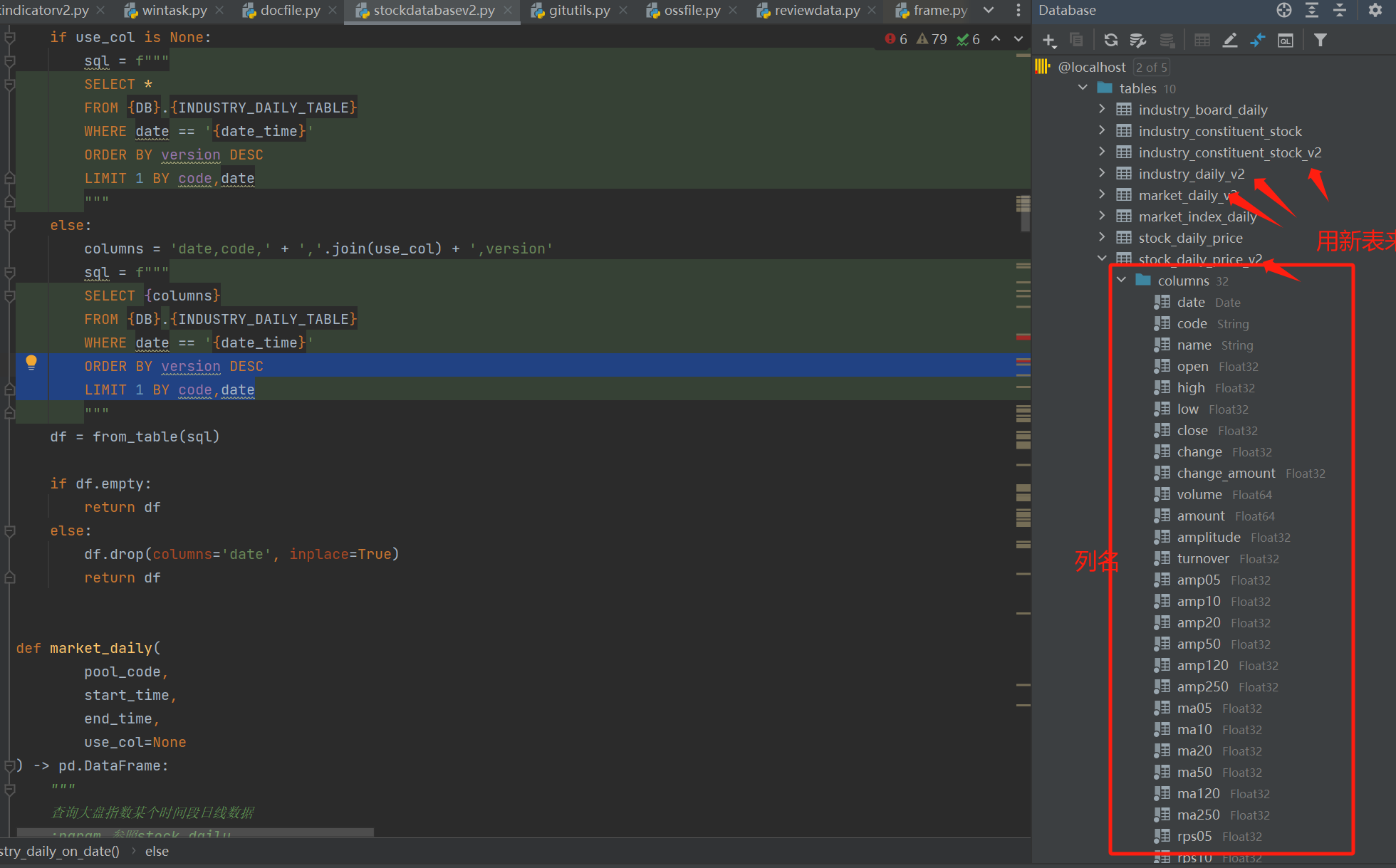
-
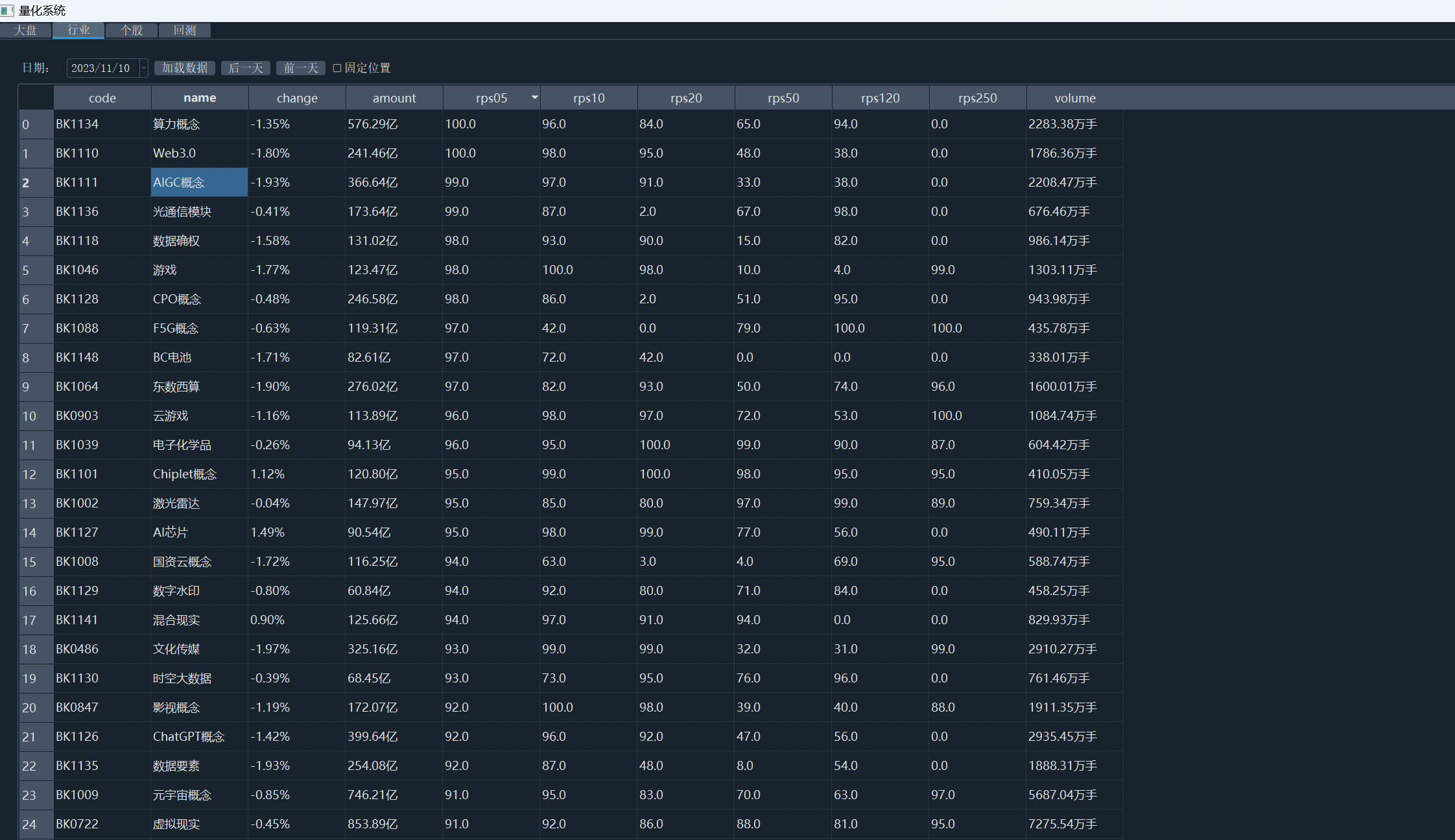
新数据替换旧表,接回原来的 ui 使用中,这个过程其实也很简单,替换数据库的查询类即可。
行业板块面板 ui
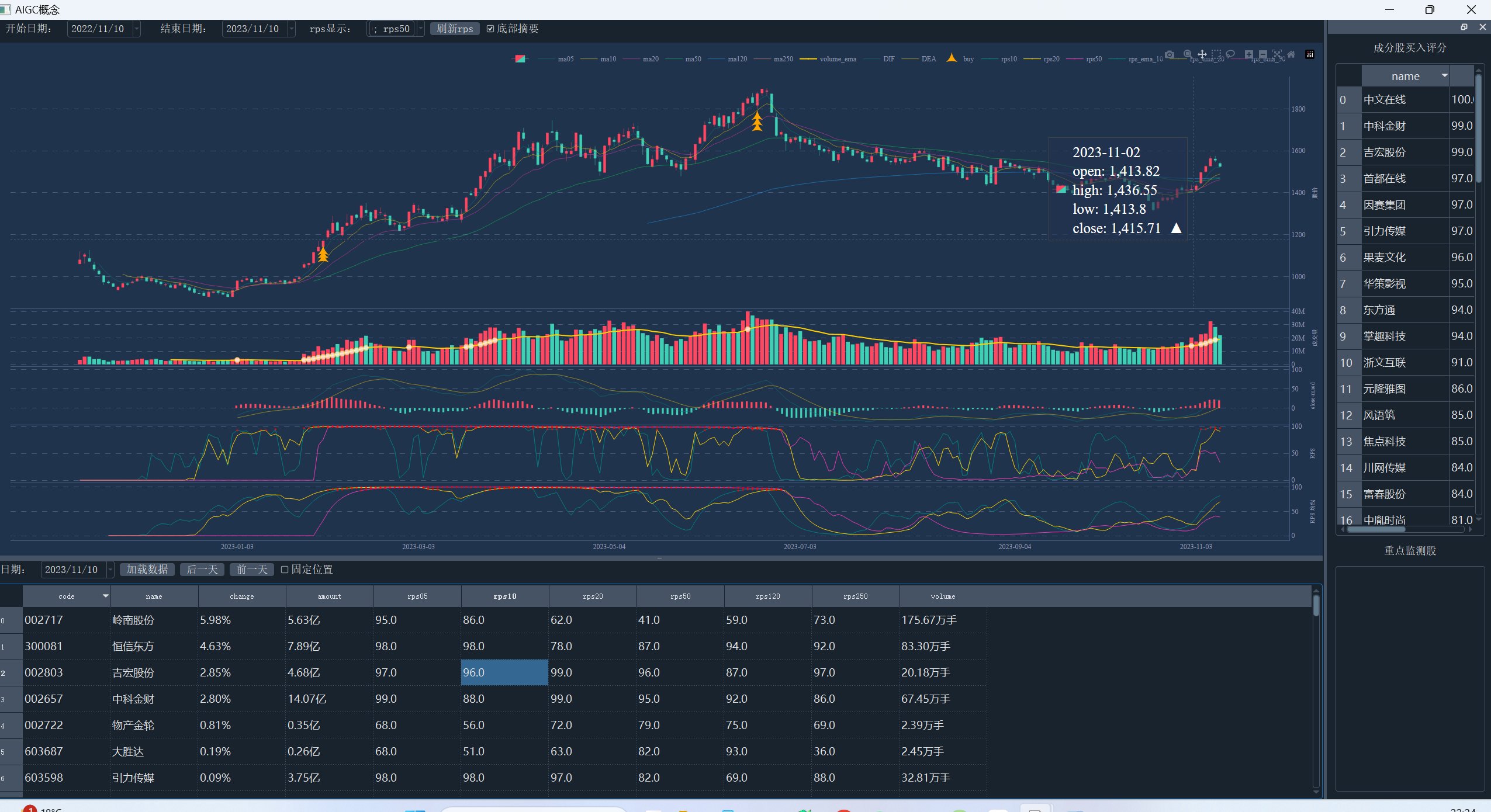
单个板块的可视化,板块成分股 ui
个股的数据 ui
本文由 mdnice 多平台发布
相关文章:
加班把数据库重构完毕
加班把数据库重构完毕 本文的数据库重构是基于 clickhouse 时序非关系型的数据库。该数据库适合存储股票数据,速度快,一般查询都是 ms 级别,不需要异步查询更新界面 ui。 达到目标效果:数据表随便删除,重新拉数据以及指…...
安装mysql数据库)
Centos(Linux)安装mysql数据库
1. 环境准备 1.1 更新系统和安装依赖项 在进行MySQL安装之前,确保系统包是最新的,并安装必要的依赖项: yum update yum install epel-release yum install wget 1.2 下载MySQL社区版软件包 使用https方式下载MySQL社区版软件包…...
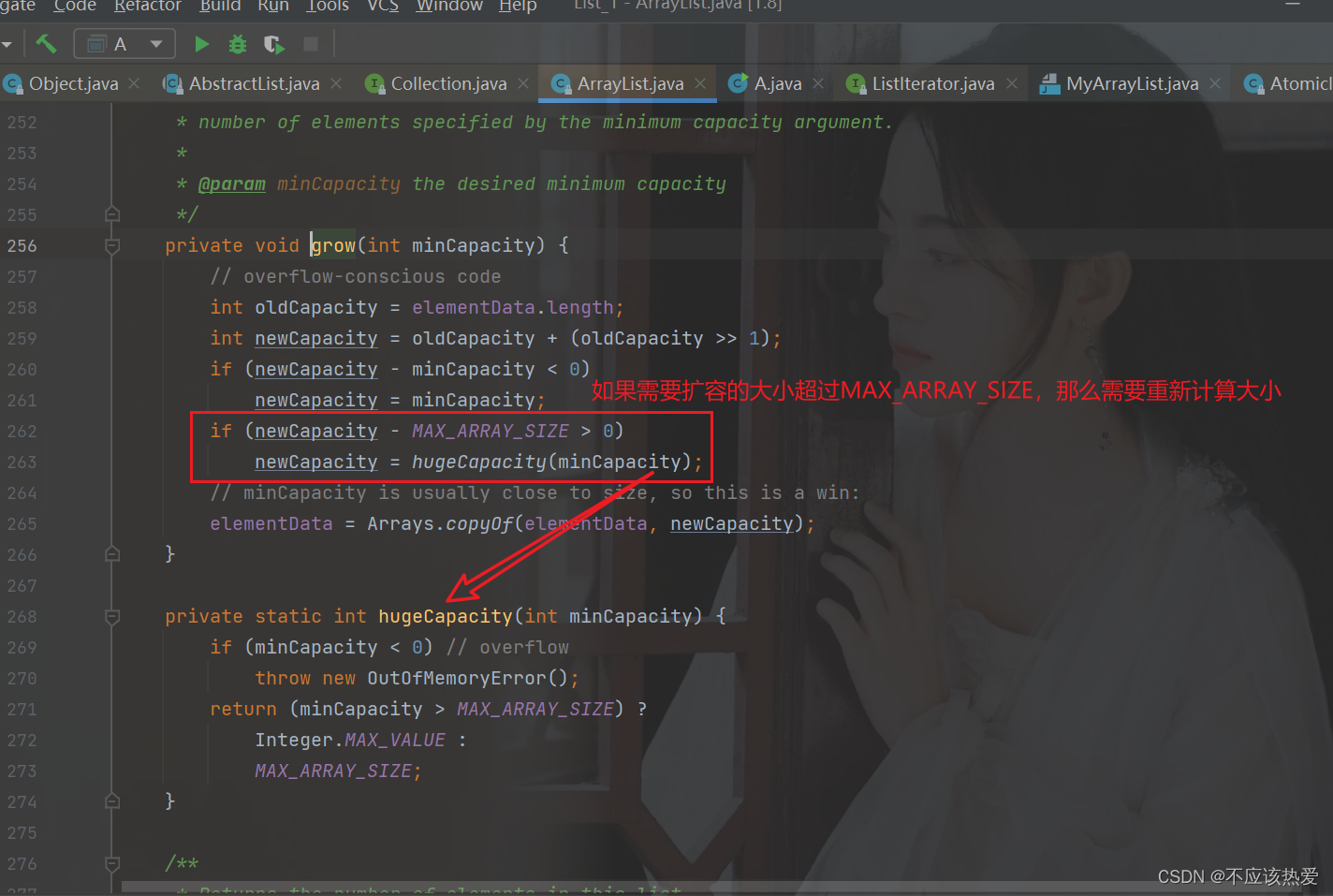
【数据结构】深度剖析ArrayList
目录 ArrayLIst介绍 ArrayList实现的接口有哪些? ArrayList的序列化:实现Serializable接口 serialVersionUID 有什么用? 为什么一定要实现Serialzable才能被序列化? transient关键字 为什么ArrayList中的elementData会被transient修…...
)
离线环境通过脚本实现服务器时钟同步(假同步)
1、背景 最近遇到一个时钟同步问题,是内网多台服务器之间时钟不同步,然后部署在不同服务器间的应用展示得时间戳不能统一,所以用户让做一下内网服务器间得时钟同步。 内网服务器x86和arm都有,而且有得系统是centos有得是ubuntu&…...
等级考试试卷(一级))
2023年9月青少年软件编程(C语言)等级考试试卷(一级)
日期输出 给定两个整数,表示一个日期的月和日。请按照"MM-DD"的格式输出日期,即如果月和日不到2位时,填补0使得满足2位。 时间限制:10000 内存限制:65536 输入 2个整数m,d(0 < m < 12…...
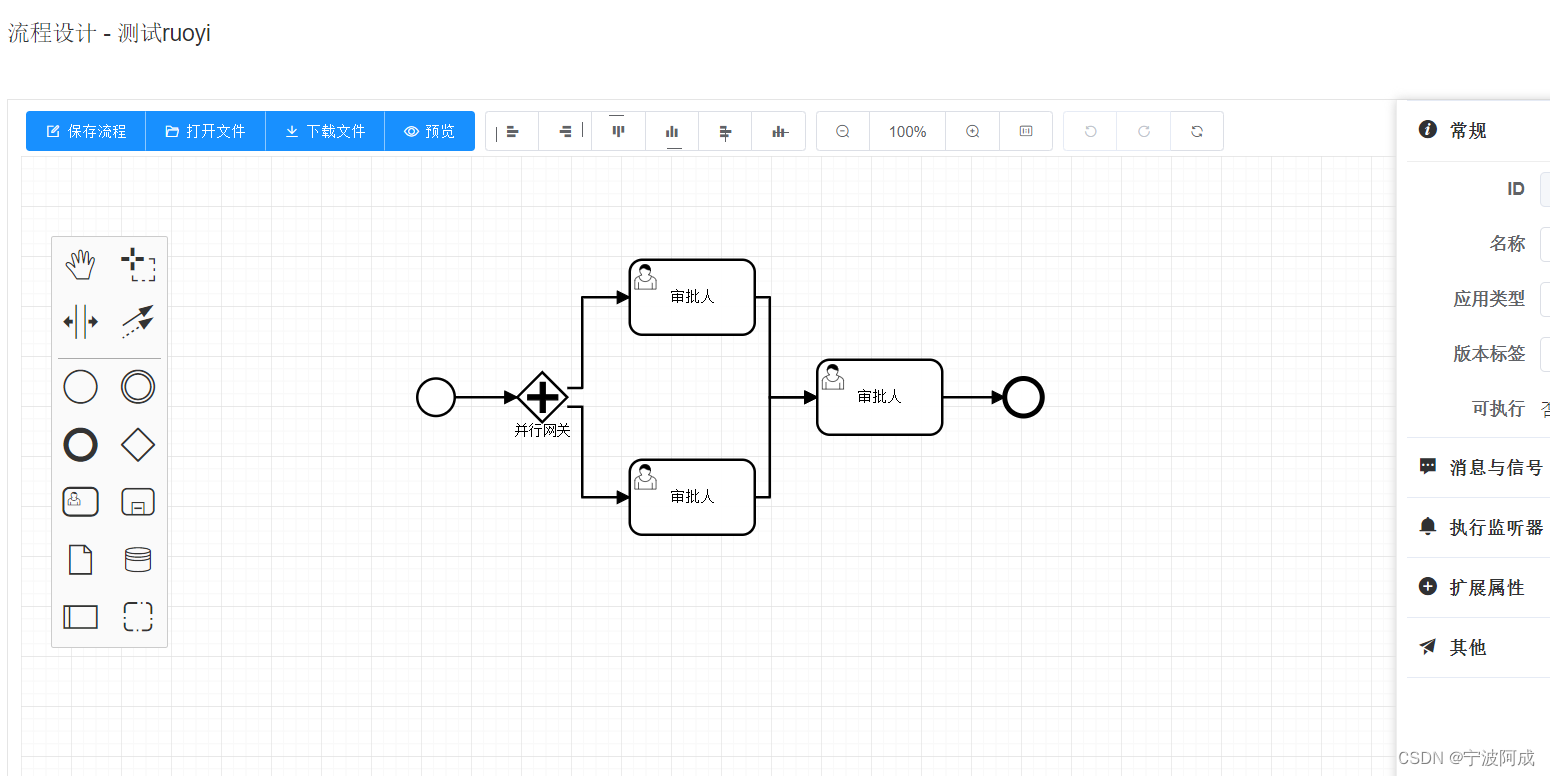
基于若依的ruoyi-nbcio流程管理系统仿钉钉流程json转bpmn的flowable的xml格式(支持并行网关)
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 这个章节来完成并行网关,前端无需修改,直接后端修改就可以了。 1、并行网关后端修…...

软件测试面试-银行篇
今天参加了一场比较正式的面试,汇丰银行的视频面试。在这里把面试的流程记录一下,结果还不确定,但是面试也是自我学习和成长的过程,所以记录下来大家也可以互相探讨一下。 请你做一下自我介绍?(汇丰要求英…...

基于Amazon EC2和Amazon Systems Manager Session Manager的堡垒机设计和自动化实现
01 背景 在很多企业的实际应用场景中,特别是金融类的客户,大部分的应用都是部署在私有子网中。为了能够让客户的开发人员和运维人员从本地的数据中心中安全的访问云上资源,堡垒机是一个很好的选择。传统堡垒机的核心实现原理是基于 SSH 协议的…...
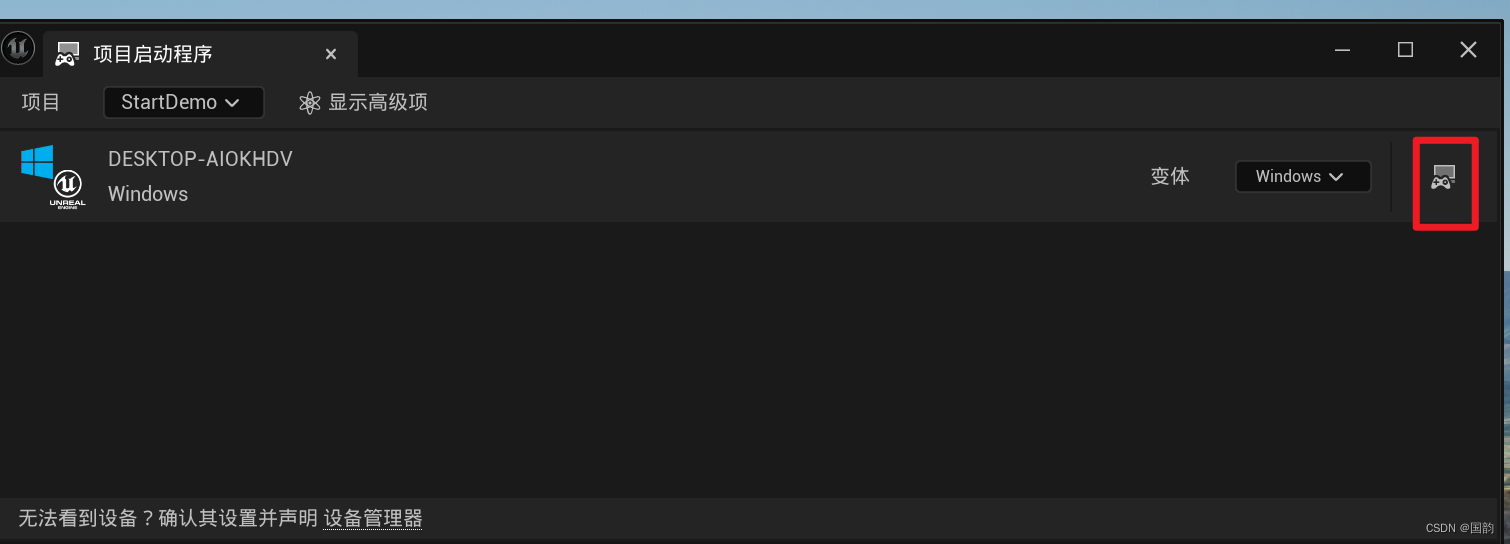
虚幻5.3打包Windows失败
缺失UnrealGame二进制文件。 必须使用集成开发环境编译该UE项目。或者借助虚幻编译工具使用命令行命令进行编译 解决办法: 1.依次点击平台-项目启动程序 2.点击后面的按钮进行设置 3.稍等后,打包后的程序即可运行,之后就可以愉快的打包了...
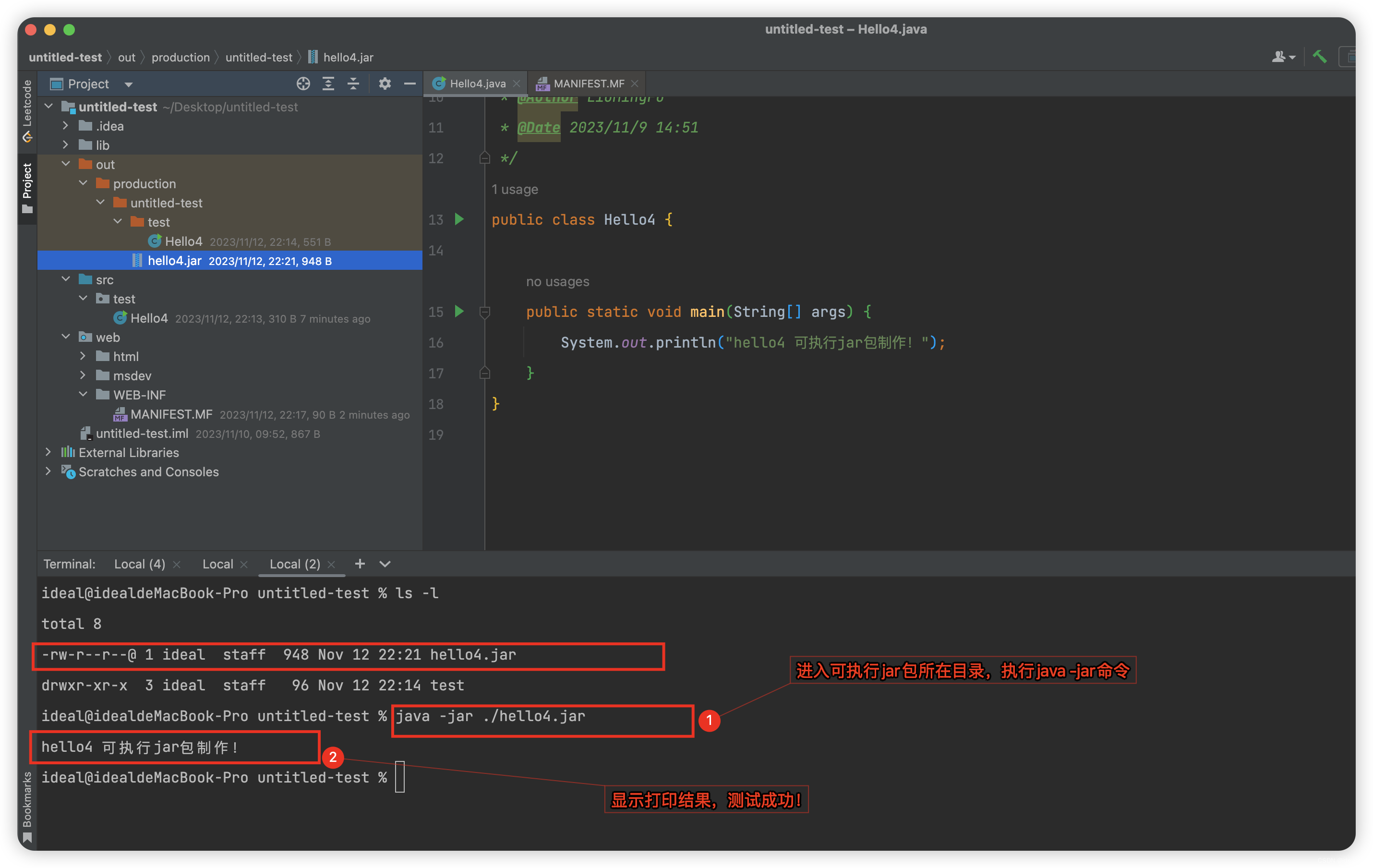
总结:利用JDK原生命令,制作可执行jar包与依赖jar包
总结:利用JDK原生命令,制作可执行jar包与依赖jar包 一什么是jar包?二制作jar包的工具:JDK原生自带的jar命令(1)jar命令注意事项:(2)jar包清单文件创建示例:&a…...
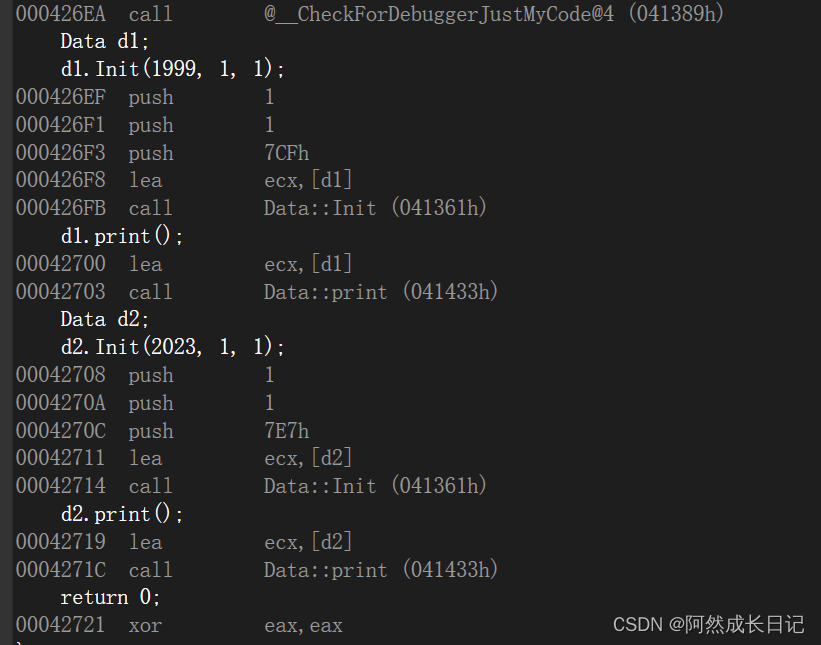
【C++】this指针讲解超详细!!!
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
的用法)
系统讲解java中list.stream()的用法
在Java 8及以后的版本中,引入了新的Stream API,这个API提供了一组新的操作方法,可以便捷 地对Java集合进行过滤、映射、排序、分组等操作。 在Stream API中主要分中间操作,和终止操作 中间操作是对流进行处理但不产生最终结果的…...

字节面试:请说一下DDD的流程,用电商系统为场景
说在前面 在40岁老架构师 尼恩的读者交流群(50)中,最近有小伙伴拿到了一线互联网企业字节、如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题: 谈谈你的DDD落地经验? 谈谈你对DDD的理解&…...
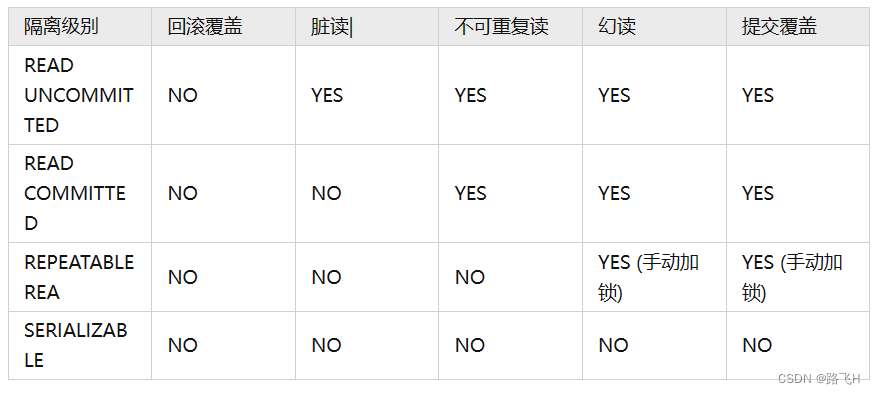
第26章_事务概述与隔离级别
文章目录 事务事务的特征事务的控制语句事务的生命周期事务的执行过程 ACID特性原子性一致性隔离性持久性 隔离级别不同隔离级别并发异常脏读不可重复读幻读区别 总结 事务 (1)事务的前提:并发连接访问。MySQL的事务就是将多条SQL语句作为整…...

合肥工业大学网络安全实验IP-Table
✅作者简介:CSDN内容合伙人、信息安全专业在校大学生🏆 🔥系列专栏 :hfut实验课设 📃新人博主 :欢迎点赞收藏关注,会回访! 💬舞台再大,你不上台,永远是个观众。平台再好,你不参与,永远是局外人。能力再大,你不行动,只能看别人成功!没有人会关心你付出过多少…...

Docker本地镜像发布到阿里云或私有库
本地镜像发布到阿里云流程 : 1.自己生成个要传的镜像 2.将本地镜像推送到阿里云: 阿里云开发者平台:开放云原生应用-云原生(Cloud Native)-云原生介绍 - 阿里云 2.1.创建仓库镜像: 2.1.1 选择控制台,进入容器镜像服…...
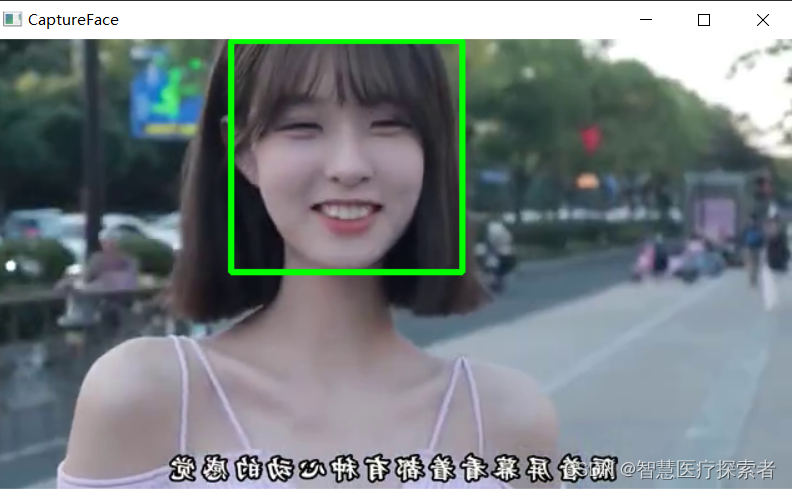
使用openvc进行人脸检测:Haar级联分类器
1 人脸检测介绍 1.1 什么是人脸检测 人脸检测的目标是确定图像或视频中是否存在人脸。如果存在多个面,则每个面都被一个边界框包围,因此我们知道这些面的位置 人脸检测算法的主要目标是准确有效地确定图像或视频中人脸的存在和位置。这些算法分析数据…...

Netty心跳检测
文章目录 一、网络连接假死现象二、服务器端的空闲检测三、客户端的心跳报文 客户端的心跳检测对于任何长连接的应用来说,都是一个非常基础的功能。要理解心跳的重要性,首先需要从网络连接假死的现象说起。 一、网络连接假死现象 什么是连接假死呢&…...
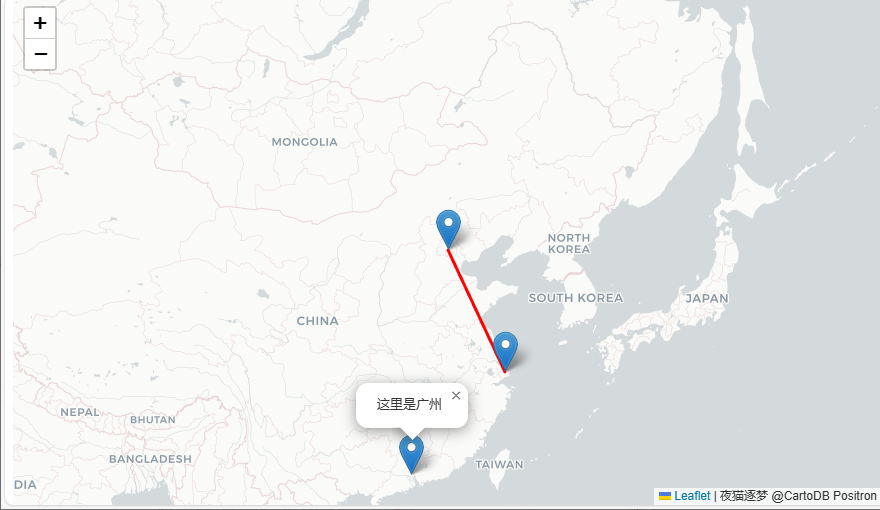
【leaflet】1. 初见
▒ 目录 ▒ 🛫 导读需求开发环境 1️⃣ 概念概念解释特点 2️⃣ 学习路线图3️⃣ html示例🛬 文章小结📖 参考资料 🛫 导读 需求 要做游戏地图了,看到大量产品都使用的leaflet,所以开始学习这个。 开发环境…...
 | 详解十大经典排序算法之一:冒泡排序)
数据结构与算法(Java版) | 详解十大经典排序算法之一:冒泡排序
前面虽然大家已经知道了多种不同的排序算法,但是我一直都没来得及给大家讲,所以,从这一讲起,我就要开始来给大家详细讲解具体的这些排序算法了。 下面,我们先来看第一个最常见的排序,即冒泡排序。 冒泡排…...
的配置_数据库自动化任务的备份)
如何导出包含事件调度器(Events)的配置_数据库自动化任务的备份
mysqldump 默认不导出 EVENTS,必须显式加 --events;还需配合 --routines 和 --triggers 确保依赖逻辑完整,并注意 --skip-definer 和 --set-gtid-purgedOFF 等关键参数。mysqldump 默认不导出 EVENTS,必须显式加 --eventsmysql 的…...
)
蓝桥杯单片机组——榨干选手资源包(STC)
文章目录前言巧用STCSTC生成定时器STC配置定时器(定时器中断)定时器定时器中断STC获取数码管码表STC上升沿下降沿检测其他总结目录前言 笔者参加的是第十一届蓝桥杯的单片机组,当时由于疫情,比赛一直推迟,推到最后还和…...

PHP电商系统扛不住大促?揭秘Redis+协程+异步队列三级熔断体系:3小时压测调优全记录
第一章:PHP电商系统扛不住大促?揭秘Redis协程异步队列三级熔断体系:3小时压测调优全记录面对双11级流量洪峰,某基于Laravel构建的PHP电商系统在5000 QPS下频繁出现502超时、库存扣减超卖、支付回调堆积等故障。我们未选择简单扩容…...

被遗忘的宝藏:深度挖掘一款停更20年的神器——拖把更名器
在软件的海洋中,有这样一类特殊的存在:它们并非出自大公司之手,也没有大规模的商业推广,却凭借着优秀的设计和实用的功能,在用户中口口相传。 它们可能已经停更多年,在主流软件平台上难觅踪迹,但…...

Generalist最新长文定调:具身原生才是正道,中国玩家原力灵机已交卷
Jay 发自 凹非寺量子位 | 公众号 QbitAIGeneralist AI的GEN-1热度,仍在发酵。自节前那场引爆全网的Demo之后,昨日,创始人Pete Florence与团队,正式释出了GEN-1的技术博客。与其说这是一篇技术分享,不如说这是一篇「教同…...

3分钟解锁Windows安卓应用安装:告别模拟器的高效解决方案
3分钟解锁Windows安卓应用安装:告别模拟器的高效解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在数字化工作与娱乐场景中,用户常常面…...
简易流程介绍谖)
大模型智能体 (agent)简易流程介绍谖
引言 在现代软件开发中,性能始终是衡量应用质量的重要指标之一。无论是企业级应用、云服务还是桌面程序,性能优化都能显著提升用户体验、降低基础设施成本并增强系统的可扩展性。对于使用 C# 开发的应用程序而言,性能优化涉及多个层面&#x…...

如何快速掌握MuseTalk:实时高质量AI唇同步的完整实践指南
如何快速掌握MuseTalk:实时高质量AI唇同步的完整实践指南 【免费下载链接】MuseTalk MuseTalk: Real-Time High Quality Lip Synchorization with Latent Space Inpainting 项目地址: https://gitcode.com/gh_mirrors/mu/MuseTalk MuseTalk是一款由腾讯音乐娱…...

STM32 Modbus通信学习笔记——通信流程
文章目录前言Modbus协议硬件连接基于RS485的Modbus通信Modbus拓扑结构Modbus通信流程Modbus主机帧结构传输方式RTU传输方式ASC传输方式数据帧格式ASCII 帧RTU 帧设备地址(找谁)功能码(干什么)校验CRC-16(循环冗余错误校…...

Phi-3-mini-128k-instruct效果对比:vs Phi-3-4K在长文本摘要任务中的质量差异
Phi-3-mini-128k-instruct效果对比:vs Phi-3-4K在长文本摘要任务中的质量差异 1. 模型简介与背景 Phi-3-Mini-128K-Instruct是一个38亿参数的轻量级开放模型,属于Phi-3系列的最新成员。该模型使用专门设计的Phi-3数据集进行训练,该数据集包…...