Spark Job优化
1 Map端优化
1.1 Map端聚合
map-side预聚合,就是在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combiner。map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。其他节点在拉取所有节点上的相同key时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。
RDD的话建议使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子。因为reduceByKey和aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差。
SparkSQL本身的HashAggregte就会实现本地预聚合+全局聚合。
1.2 读取小文件优化
读取的数据源有很多小文件,会造成查询性能的损耗,大量的数据分片信息以及对应产生的Task元信息也会给Spark Driver的内存造成压力,带来单点问题。
设置参数:
spark.sql.files.maxPartitionBytes=128MB 默认128m
spark.files.openCostInBytes=4194304 默认4m
参数(单位都是bytes):
- maxPartitionBytes:一个分区最大字节数。
- openCostInBytes:打开一个文件的开销。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.map.MapSmallFileTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
源码理解: DataSourceScanExec.createNonBucketedReadRDD()

FilePartition. getFilePartitions()

1)切片大小= Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
计算totalBytes的时候,每个文件都要加上一个open开销
defaultParallelism就是RDD的并行度
2)当(文件1大小+ openCostInBytes)+(文件2大小+ openCostInBytes)+…+(文件n-1大小+ openCostInBytes)+ 文件n <= maxPartitionBytes时,n个文件可以读入同一个分区,即满足: N个小文件总大小 + (N-1)*openCostInBytes <= maxPartitionBytes的话。
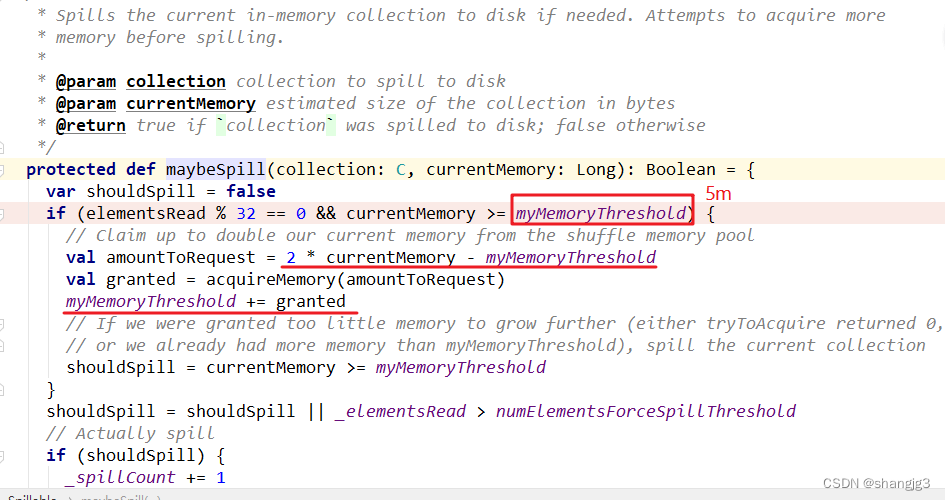
1.3 增大map溢写时输出流buffer
1)map端Shuffle Write有一个缓冲区,初始阈值5m,超过会尝试增加到2*当前使用内存。如果申请不到内存,则进行溢写。这个参数是internal,指定无效(见下方源码)。也就是说资源足够会自动扩容,所以不需要我们去设置。
2)溢写时使用输出流缓冲区默认32k,这些缓冲区减少了磁盘搜索和系统调用次数,适当提高可以提升溢写效率。
3)Shuffle文件涉及到序列化,是采取批的方式读写,默认按照每批次1万条去读写。设置得太低会导致在序列化时过度复制,因为一些序列化器通过增长和复制的方式来翻倍内部数据结构。这个参数是internal,指定无效(见下方源码)。
综合以上分析,我们可以调整的就是输出缓冲区的大小。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.map.MapFileBufferTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
源码理解:



2 Reduce端优化
2.1 合理设置Reduce数
过多的cpu资源出现空转浪费,过少影响任务性能。关于并行度、并发度的相关参数介绍,在2.2.1中已经介绍过。
2.2 输出产生小文件优化
1、Join后的结果插入新表
join结果插入新表,生成的文件数等于shuffle并行度,默认就是200份文件插入到hdfs上。
解决方式:
1)可以在插入表数据前进行缩小分区操作来解决小文件过多问题,如coalesce、repartition算子。
2)调整shuffle并行度。根据2.2.2的原则来设置。
2、动态分区插入数据
1)没有Shuffle的情况下。最差的情况下,每个Task中都有表各个分区的记录,那文件数最终文件数将达到 Task数量 * 表分区数。这种情况下是极易产生小文件的。
INSERT overwrite table A partition ( aa )
SELECT * FROM B;
2)有Shuffle的情况下,上面的Task数量 就变成了spark.sql.shuffle.partitions(默认值200)。那么最差情况就会有 spark.sql.shuffle.partitions * 表分区数。
当spark.sql.shuffle.partitions设置过大时,小文件问题就产生了;当spark.sql.shuffle.partitions设置过小时,任务的并行度就下降了,性能随之受到影响。
最理想的情况是根据分区字段进行shuffle,在上面的sql中加上distribute by aa。把同一分区的记录都哈希到同一个分区中去,由一个Spark的Task进行写入,这样的话只会产生N个文件, 但是这种情况下也容易出现数据倾斜的问题。
解决思路:
结合第4章解决倾斜的思路,在确定哪个分区键倾斜的情况下,将倾斜的分区键单独拎出来:
将入库的SQL拆成(where 分区 != 倾斜分区键 )和 (where 分区 = 倾斜分区键) 几个部分,非倾斜分区键的部分正常distribute by 分区字段,倾斜分区键的部分 distribute by随机数,sql如下:
//1.非倾斜键部分
INSERT overwrite table A partition ( aa )
SELECT *
FROM B where aa != 大key
distribute by aa;
//2.倾斜键部分
INSERT overwrite table A partition ( aa )
SELECT *
FROM B where aa = 大key
distribute by cast(rand() * 5 as int);
案例实操:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.reduce.DynamicPartitionSmallFileTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
2.3 增大reduce缓冲区,减少拉取次数
Spark Shuffle过程中,shuffle reduce task的buffer缓冲区大小决定了reduce task每次能够缓冲的数据量,也就是每次能够拉取的数据量,如果内存资源较为充足,适当增加拉取数据缓冲区的大小,可以减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
reduce端数据拉取缓冲区的大小可以通过spark.reducer.maxSizeInFlight参数进行设置,默认为48MB。
源码:BlockStoreShuffleReader.read()

2.4 调节reduce端拉取数据重试次数
Spark Shuffle过程中,reduce task拉取属于自己的数据时,如果因为网络异常等原因导致失败会自动进行重试。对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
reduce端拉取数据重试次数可以通过spark.shuffle.io.maxRetries参数进行设置,该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败,默认为3:
2.5 调节reduce端拉取数据等待间隔
Spark Shuffle过程中,reduce task拉取属于自己的数据时,如果因为网络异常等原因导致失败会自动进行重试,在一次失败后,会等待一定的时间间隔再进行重试,可以通过加大间隔时长(比如60s),以增加shuffle操作的稳定性。
reduce端拉取数据等待间隔可以通过spark.shuffle.io.retryWait参数进行设置,默认值为5s。
综合2.3、2.4、2.5,案例实操:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.reduce.ReduceShuffleTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
2.6 合理利用bypass
当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200)且不需要map端进行合并操作,则shuffle write过程中不会进行排序操作,使用BypassMergeSortShuffleWriter去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
当你使用SortShuffleManager时,如果确实不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
源码分析:SortShuffleManager.registerShuffle()
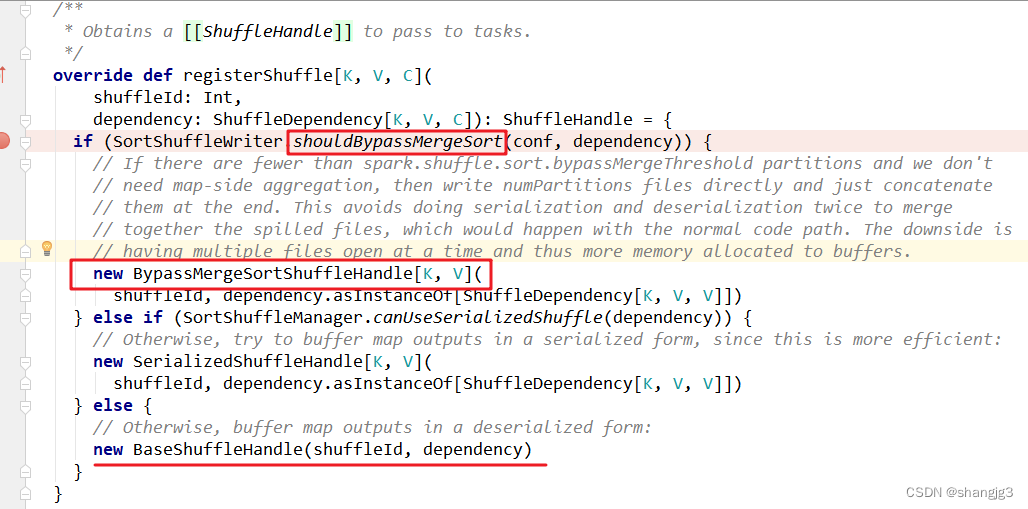


SortShuffleManager.getWriter()

spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.reduce.BypassTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
3 整体优化
3.1 调节数据本地化等待时长
在 Spark 项目开发阶段,可以使用 client 模式对程序进行测试,此时,可以在本地看到比较全的日志信息,日志信息中有明确的 Task 数据本地化的级别,如果大部分都是 PROCESS_LOCAL、NODE_LOCAL,那么就无需进行调节,但是如果发现很多的级别都是 RACK_LOCAL、ANY,那么需要对本地化的等待时长进行调节,应该是反复调节,每次调节完以后,再来运行观察日志,看看大部分的task的本地化级别有没有提升;看看,整个spark作业的运行时间有没有缩短。
注意过犹不及,不要将本地化等待时长延长地过长,导致因为大量的等待时长,使得 Spark 作业的运行时间反而增加了。
下面几个参数,默认都是3s,可以改成如下:
spark.locality.wait //建议6s、10s
spark.locality.wait.process //建议60s
spark.locality.wait.node //建议30s
spark.locality.wait.rack //建议20s
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.job.LocalityWaitTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
3.2 使用堆外内存
1、堆外内存参数
讲到堆外内存,就必须去提一个东西,那就是去yarn申请资源的单位,容器。Spark on yarn模式,一个容器到底申请多少内存资源。
一个容器最多可以申请多大资源,是由yarn参数yarn.scheduler.maximum-allocation-mb决定, 需要满足:
spark.executor.memoryOverhead + spark.executor.memory + spark.memory.offHeap.size
≤ yarn.scheduler.maximum-allocation-mb
参数解释:
- spark.executor.memory:提交任务时指定的堆内内存。
- spark.executor.memoryOverhead:堆外内存参数,内存额外开销。
默认开启,默认值为spark.executor.memory*0.1并且会与最小值384mb做对比,取最大值。所以spark on yarn任务堆内内存申请1个g,而实际去yarn申请的内存大于1个g的原因。
- spark.memory.offHeap.size:堆外内存参数,spark中默认关闭,需要将spark.memory.enable.offheap.enable参数设置为true。
注意:很多网上资料说spark.executor.memoryOverhead包含spark.memory.offHeap.size,这是由版本区别的,仅限于spark3.0之前的版本。3.0之后就发生改变,实际去yarn申请的内存资源由三个参数相加。
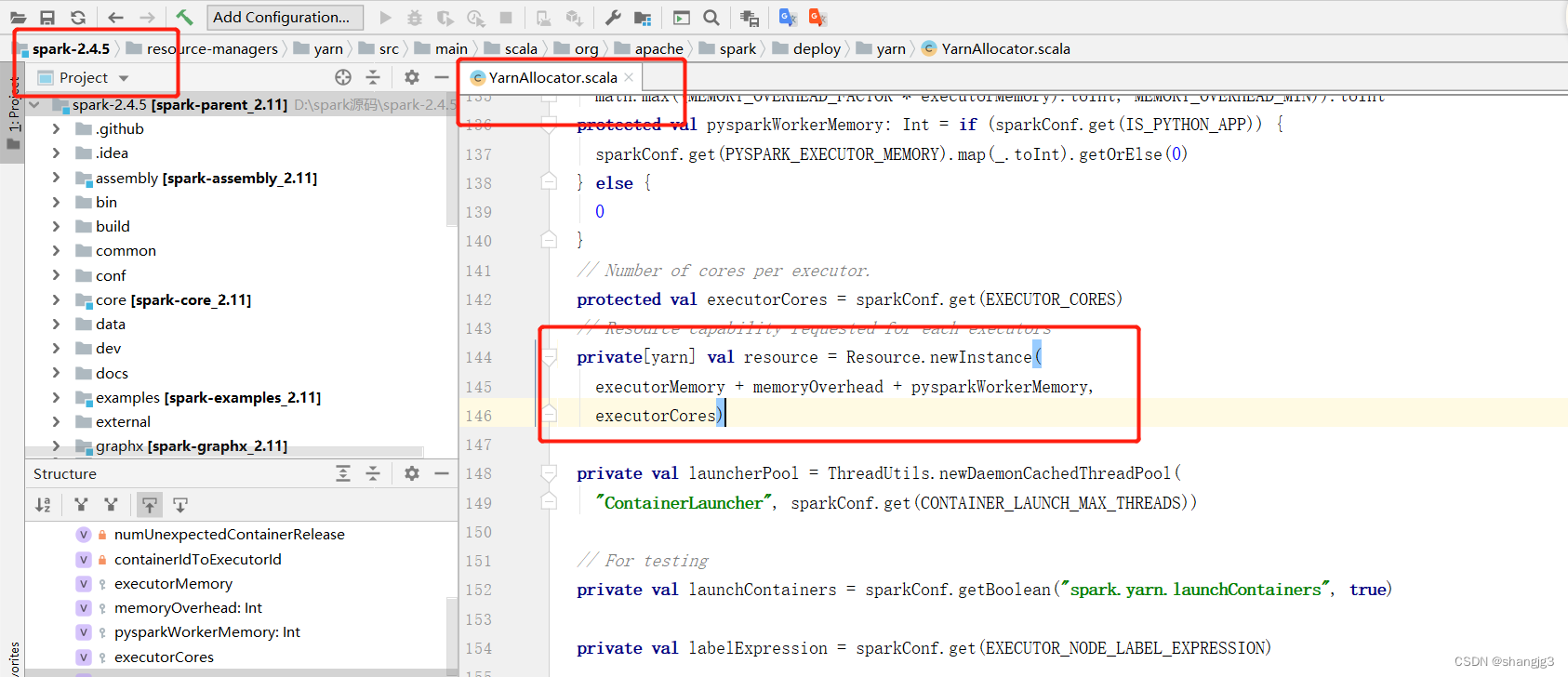

测试申请容器上限:
yarn.scheduler.maximum-allocation-mb修改为7G,将三个参数设为如下,大于7G,会报错:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --conf spark.memory.offHeap.enabled=true --conf spark.memory.offHeap.size=2g --executor-memory 5g --class com.atguigu.sparktuning.join.SMBJoinTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
将spark.memory.offHeap.size修改为1g后再次提交:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --conf spark.memory.offHeap.enabled=true --conf spark.memory.offHeap.size=1g --executor-memory 5g --class com.atguigu.sparktuning.join.SMBJoinTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
2、使用堆外缓存
使用堆外内存可以减轻垃圾回收的工作,也加快了复制的速度。
当需要缓存非常大的数据量时,虚拟机将承受非常大的GC压力,因为虚拟机必须检查每个对象是否可以收集并必须访问所有内存页。本地缓存是最快的,但会给虚拟机带来GC压力,所以,当你需要处理非常多GB的数据量时可以考虑使用堆外内存来进行优化,因为这不会给Java垃圾收集器带来任何压力。让JAVA GC为应用程序完成工作,缓存操作交给堆外。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --conf spark.memory.offHeap.enabled=true --conf spark.memory.offHeap.size=1g --executor-memory 5g --class com.atguigu.sparktuning.job.OFFHeapCache spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
3.3 调节连接等待时长
在Spark作业运行过程中,Executor优先从自己本地关联的BlockManager中获取某份数据,如果本地BlockManager没有的话,会通过TransferService远程连接其他节点上Executor的BlockManager来获取数据。
如果task在运行过程中创建大量对象或者创建的对象较大,会占用大量的内存,这回导致频繁的垃圾回收,但是垃圾回收会导致工作现场全部停止,也就是说,垃圾回收一旦执行,Spark的Executor进程就会停止工作,无法提供相应,此时,由于没有响应,无法建立网络连接,会导致网络连接超时。
在生产环境下,有时会遇到file not found、file lost这类错误,在这种情况下,很有可能是Executor的BlockManager在拉取数据的时候,无法建立连接,然后超过默认的连接等待时长120s后,宣告数据拉取失败,如果反复尝试都拉取不到数据,可能会导致Spark作业的崩溃。这种情况也可能会导致DAGScheduler反复提交几次stage,TaskScheduler反复提交几次task,大大延长了我们的Spark作业的运行时间。
为了避免长时间暂停(如GC)导致的超时,可以考虑调节连接的超时时长,连接等待时长需要在spark-submit脚本中进行设置,设置方式可以在提交时指定:
--conf spark.core.connection.ack.wait.timeout=300s
调节连接等待时长后,通常可以避免部分的XX文件拉取失败、XX文件lost等报错。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 1g --conf spark.core.connection.ack.wait.timeout=300s --class com.atguigu.sparktuning.job.AckWaitTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
相关文章:
Spark Job优化
1 Map端优化 1.1 Map端聚合 map-side预聚合,就是在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combiner。map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。其他节…...

CSS花边001:无衬线字体和有衬线字体
网站中我们看到过很多字体,样子各有千秋。通常针对结构,区分为有衬字体(serif) 和无衬字体(sans-serif)。今天我们聊一下这个话题。 什么是有衬字体,什么是无衬字体? 衬线字体&…...
nodejs+vue+python+PHP+微信小程序-安卓- 基于小程序的高校后勤管理系统-计算机毕业设计
考虑到实际生活中在高校后勤管理小程序管理方面的需要以及对该系统认真的分析,将系统权限按管理员和用户这两类涉及用户划分。任何系统都要遵循系统设计的基本流程,本系统也不例外,同样需要经过市场调研,需求分析,概要设计&#x…...

Leetcode153. Find Minimum in Rotated Sorted Array
旋转数组找最小值 其中数组中的值唯一 你可以顺序遍历,当然一般会让你用二分来搞 方法1 数组可以分成两部分,左边是 ≥ n u m s [ 0 ] \ge nums[0] ≥nums[0], 右边是 < n u m s [ 0 ] <nums[0] <nums[0] 换句话说就是找第一个 < n u m s…...
为什么要用“交叉熵”做损失函数
大家好啊,我是董董灿。 今天看一个在深度学习中很枯燥但很重要的概念——交叉熵损失函数。 作为一种损失函数,它的重要作用便是可以将“预测值”和“真实值(标签)”进行对比,从而输出 loss 值,直到 loss 值收敛,可以…...
【Android】Android apk 逆向编译
链接:https://pan.baidu.com/s/14r5s9EJwQgeLK5cCb1Gq1Q 提取码:qdqt 解压jadx 在 lib 文件内找到 jadx-gui-1.4.7.jar 打开cmd 执行 :java -jar jadx-gui-1.4.7.jar示列:...

04-详解SpringBoot自动装配的原理,依赖属性配置的实现,源码分析
自动装配原理 依赖属性配置 提供Bean用来封装配置文件中对应属性的值 Data public class Cat {private String name;private Integer age; }Data public class Mouse {private String name;private Integer age; }cartoon:cat:name: "图多盖洛"age: 5mouse:name: …...
)
[100天算法】-不同路径 III(day 73)
题目描述 在二维网格 grid 上,有 4 种类型的方格:1 表示起始方格。且只有一个起始方格。 2 表示结束方格,且只有一个结束方格。 0 表示我们可以走过的空方格。 -1 表示我们无法跨越的障碍。 返回在四个方向(上、下、左、右&#…...
【c++随笔12】继承
【c随笔12】继承 一、继承1、继承的概念2、3种继承方式3、父类和子类对象赋值转换4、继承中的作用域——隐藏5、继承与友元6、继承与静态成员 二、继承和子类默认成员函数1、子类构造函数 二、子类拷贝构造函数3、子类的赋值重载4、子类析构函数 三、单继承、多继承、菱形继承1…...
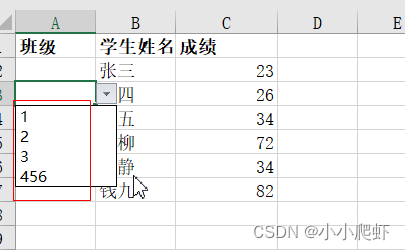
Excel中使用数据验证、OFFSET实现自动更新式下拉选项
在excel工作簿中,有两个Sheet工作表。 Sheet1: Sheet2(数据源表): 要实现Sheet1中的“班级”内容,从数据源Sheet2中获取并形成下拉选项,且Sheet2中“班级”内容更新后,Sheet1中“班…...

Android修行手册 - 可变参数中星号什么作用(冷知识)
点击跳转>Unity3D特效百例点击跳转>案例项目实战源码点击跳转>游戏脚本-辅助自动化点击跳转>Android控件全解手册点击跳转>Scratch编程案例点击跳转>软考全系列 👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资源分享&…...
视图缩放)
Python与ArcGIS系列(三)视图缩放
目录 0 简述1 在所有图层中缩放至所选要素2 在单独图层中缩放至所选要素3 改变地图范围0 简述 本篇介绍如何利用arcpy实现缩放视图到所选要素以及改变地图范围功能。 对于以及创建的选择集数据,通常需要进行缩放以更好地显示所选要素,要素缩放可分为两种:第一种是在所有图层…...
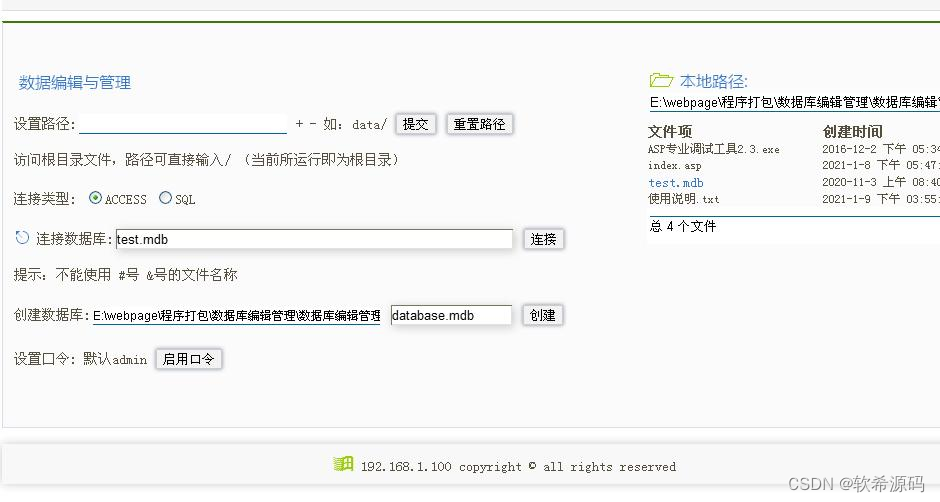
[ASP]数据库编辑与管理V1.0
本地测试:需要运行 ASP专业调试工具(自己搜索下载) 默认登陆口令:admin 修改口令:打开index.asp找到第3行把admin"admin"改成其他,如admin"abc123" 程序功能齐全,代码精简…...

MyBatis Plus整合Redis实现分布式二级缓存
MyBatis缓存描述 MyBatis提供了两种级别的缓存, 分别时一级缓存和二级缓存。一级缓存是SqlSession级别的缓存,只在SqlSession对象内部存储缓存数据,如果SqlSession对象不一样就无法命中缓存,二级缓存是mapper级别的缓存ÿ…...

如何帮助 3D CAD 设计师实现远程办公
当 3D CAD 设计师需要远程办公时,他们可能需要更强的远程软件,以满足他们的专业需求。比如高清画质,以及支持设备重定向、多显示器支持等功能。3D CAD 设计师如何实现远程办公?接下来我们跟随 Platinum Tank Group 的故事来了解一…...

如何在 Idea 中修改文件的字符集(如:UTF-8)
以 IntelliJ IDEA 2023.2 (Ultimate Edition) 为例,如下: 点击左上角【IntelliJ IDEA】->【Settings…】,如下图: 从弹出页面的左侧导航中找到【Editor】->【File Encodings】,并将 Global Encoding、Project E…...

【C++】单例模式【两种实现方式】
目录 一、了解单例模式前的基础题 1、设计一个类,不能被拷贝 2、设计一个类,只能在堆上创建对象 3、设计一个类,只能在栈上创建对象 4、设计一个类,不能被继承 二、单例模式 1、单例模式的概念 2、单例模式的两种实现方式 …...

php的api接口token简单实现
<?php // 生成 Token function generateToken() {$token bin2hex(random_bytes(16)); // 使用随机字节生成 tokenreturn $token; } // 存储 Token(这里使用一个全局变量来模拟存储) $tokens []; // 验证 Token function validateToken($token) {gl…...
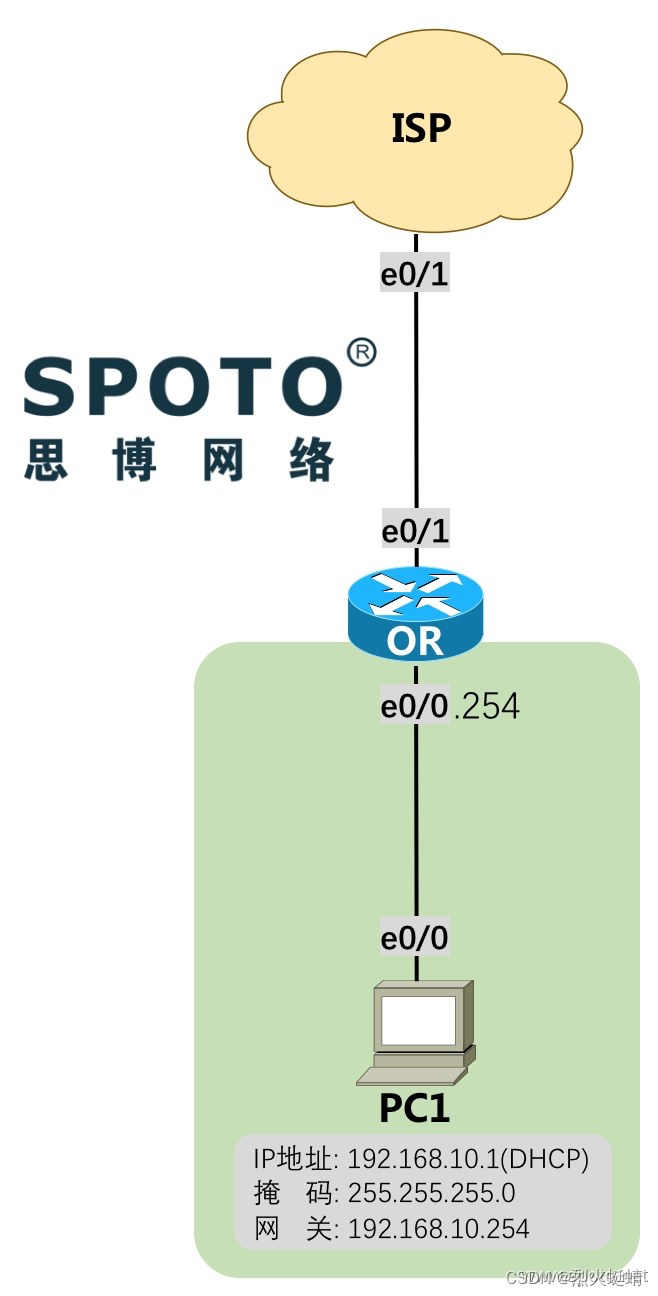
CCNA课程实验-13-PPPoE
目录 实验条件网络拓朴需求 配置实现基础配置模拟运营商ISP配置ISP的DNS配置出口路由器OR基础配置PC1基础配置 出口路由器OR配置PPPOE拨号创建NAT(PAT端口复用) PC1测试结果 实验条件 网络拓朴 需求 OR使用PPPoE的方式向ISP发送拨号的用户名和密码,用户名…...
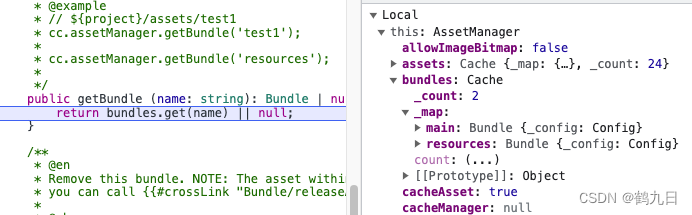
cocosCreator 之 Bundle使用
版本: v3.4.0 语言: TypeScript 环境: Mac Bundle简介 全名 Asset Bundle(简称AB包),自cocosCreator v2.4开始支持,用于作为资源模块化工具。 允许开发者根据项目需求将贴图、脚本、场景等资源划分在 Bundle 中&am…...

Lenovo Legion Toolkit革新:全场景精准调控拯救者笔记本性能
Lenovo Legion Toolkit革新:全场景精准调控拯救者笔记本性能 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit Len…...

旧设备变砖?这个开源工具让iPhone 4S流畅再战3年
旧设备变砖?这个开源工具让iPhone 4S流畅再战3年 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit 你的i…...

零代码基础入门:用星图AI训练PETRV2-BEV模型的详细教程
零代码基础入门:用星图AI训练PETRV2-BEV模型的详细教程 1. 前言:为什么选择PETRV2-BEV模型 在自动驾驶领域,BEV(鸟瞰图)感知技术正变得越来越重要。PETRV2作为最新一代基于Transformer的BEV感知模型,相比…...

Graphormer分子预测精度解析:OGB榜单指标解读与科研论文复现指南
Graphormer分子预测精度解析:OGB榜单指标解读与科研论文复现指南 1. 引言:Graphormer模型概述 Graphormer是一种基于纯Transformer架构的图神经网络,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。与传…...

Llama Factory零代码微调大模型:5分钟上手Qwen实战教程
Llama Factory零代码微调大模型:5分钟上手Qwen实战教程 1. 前言:为什么选择Llama Factory? 大模型微调一直是AI工程师的必备技能,但传统方法需要编写大量代码,配置复杂环境,让很多初学者望而却步。Llama …...

3步突破资源提取瓶颈:让Wallpaper Engine效率提升300%的终极方案
3步突破资源提取瓶颈:让Wallpaper Engine效率提升300%的终极方案 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 在Wallpaper Engine资源开发领域,创作者和开…...

ooderAgent 龙虾时代的统一认证体系
当 Agent 从"工具"进化为"伙伴",账户体系如何重新定义人机协作的信任边界? 协议版本:ooderAgent v1.0.0 | 发布日期:2026-04-08 | 维护团队:ooderAgent Team 一、引言:从 0.7.3 到 …...

docker在centos7上的搭建
docker与传统虚拟机对比 传统虚拟机基于安装在主操作系统上(带环境安装) 缺点:资源占有多,冗余多,运行速度慢, dockers:打包软件运行所需所有资源,无需捆绑一整个操作系统&#x…...

Obsidian 零基础入门教程
Obsidian 零基础入门教程 目录 前言:为什么选择 Obsidian核心概念与基础操作 笔记即数据库双向链接创建你的第一个笔记库Markdown 基础语法内部链接与反向链接 核心功能实践指南 图谱视图标签的使用安装与配置核心插件 工作流示例:管理读书笔记后续学习…...
)
别再手动整理了!用这招自动同步思维导图到Markdown(支持ProcessOn/XMind/MindNode)
思维导图与Markdown自动化同步实战指南 每次会议结束后的文档整理是否让你头疼?技术文档的频繁更新是否消耗了你大量时间?本文将为你揭示一套零干预的自动化工作流,只需专注思维导图创作,Markdown文档会自动同步更新。告别复制粘贴…...