Pytorch损失函数、反向传播和优化器、Sequential使用
Pytorch_Sequential使用、损失函数、反向传播和优化器
文章目录
- nn.Sequential
- 搭建小实战
- 损失函数与反向传播
- 优化器
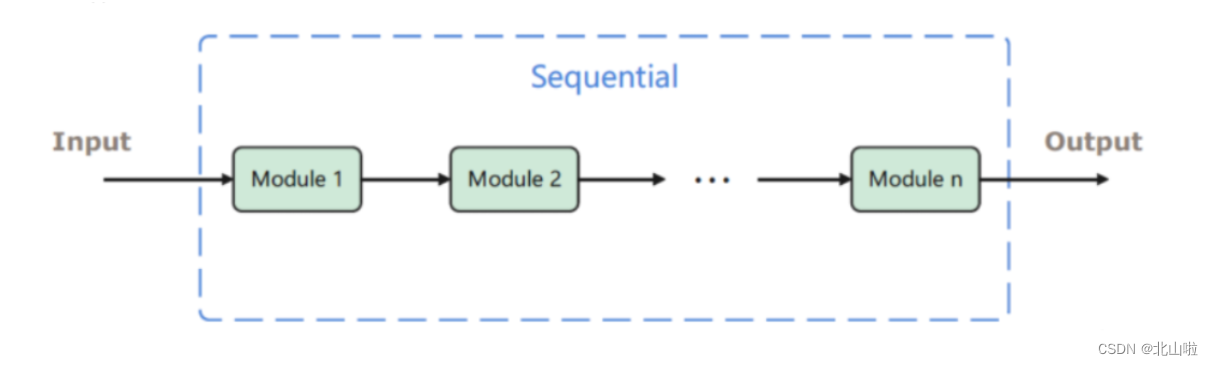
nn.Sequential
nn.Sequential是一个有序的容器,用于搭建神经网络的模块被按照被传入构造器的顺序添加到nn.Sequential()容器中。
import torch.nn as nn
from collections import OrderedDict
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(nn.Conv2d(1,20,5),nn.ReLU(),nn.Conv2d(20,64,5),nn.ReLU())# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(OrderedDict([('conv1', nn.Conv2d(1,20,5)),('relu1', nn.ReLU()),('conv2', nn.Conv2d(20,64,5)),('relu2', nn.ReLU())]))
print(model)
Sequential((conv1): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))(relu1): ReLU()(conv2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))(relu2): ReLU()
)
搭建小实战
还是以 C I F A R − 10 m o d e l CIFAR-10 model CIFAR−10model为例
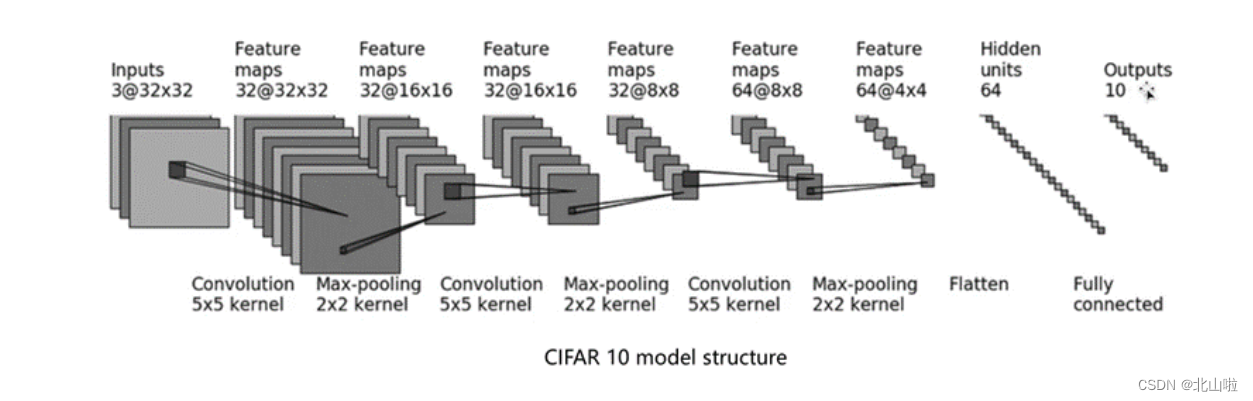
- 输入图像是3通道的32×32的
- 先后经过卷积层(5×5的卷积核)
- 最大池化层(2×2的池化核)
- 卷积层(5×5的卷积核)
- 最大池化层(2×2的池化核)
- 卷积层(5×5的卷积核)
- 最大池化层(2×2的池化核)
- 拉直(flatten)
- 全连接层的处理,
- 最后输出的大小为10
基于以上的介绍,后续将利用Pytorch构建模型,实现 C I F A R − 10 m o d e l s t r u c t u r e CIFAR-10 \quad model \quad structure CIFAR−10modelstructure
参数说明:in_channels: int、out_channels: int,kernel_size: Union由input、特征图以及卷积核即可看出,而stride、padding需要通过公式计算得到。
特得到的具体的特征图尺寸的计算公式如下:
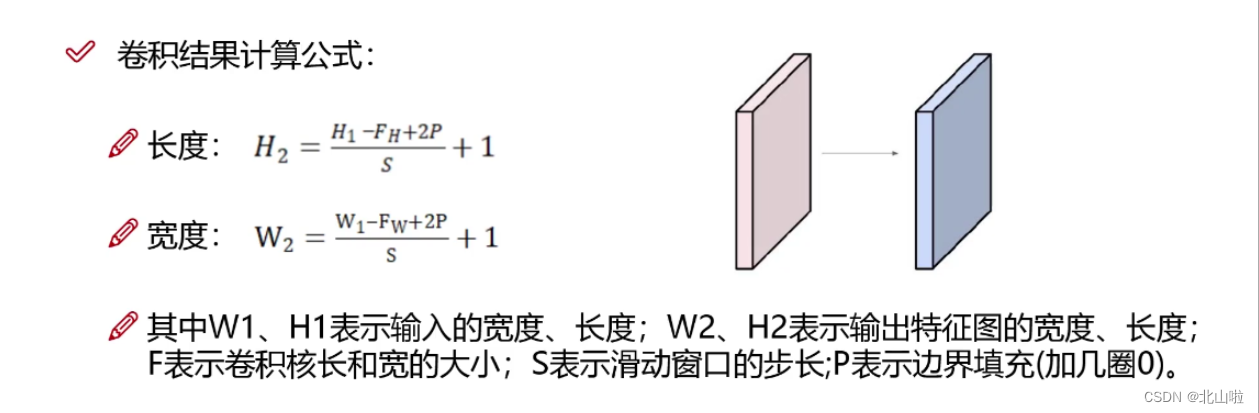
inputs : 3@32x32,3通道32x32的图片,5*5的kernel --> 特征图(Feature maps) : 32@32x32
即经过32个3@5x5的卷积层,输出尺寸没有变化(有x个卷积核即由x个卷积核,卷积核的通道数与输入的通道数相等)
由上述的计算公式来计算出 s t r i d e stride stride和 p a d d i n g padding padding

卷积层中的stride默认为1
池化层中的stride默认为kernel_size的大小
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class BS(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2) #stride和padding计算得到self.maxpool1 = nn.MaxPool2d(kernel_size=2)self.conv2 = nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2)self.maxpool2 = nn.MaxPool2d(kernel_size=2)self.conv3 = nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2)self.maxpool3 = nn.MaxPool2d(kernel_size=2)self.flatten = nn.Flatten() #变为63*4*4=1024self.linear1 = nn.Linear(in_features=1024, out_features=64)self.linear2 = nn.Linear(in_features=64, out_features=10)def forward(self,x):x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.linear1(x)x = self.linear2(x)return xbs = BS()
bs
BS((conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(maxpool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(flatten): Flatten(start_dim=1, end_dim=-1)(linear1): Linear(in_features=1024, out_features=64, bias=True)(linear2): Linear(in_features=64, out_features=10, bias=True)
)
利用Sequential优化代码,并在tensorboard显示
.add_graph函数用于将PyTorch模型图添加到TensorBoard中。通过这个函数,您可以以可视化的方式展示模型的计算图,使其他人更容易理解您的模型结构和工作流程。
add_graph(model, input_to_model, strip_default_attributes=True)
- model:要添加的PyTorch模型。
- input_to_model:用于生成模型图的输入数据。
- strip_default_attributes:是否删除模型中的默认属性,默认为True。
class BS(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #stride和padding计算得到nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(), #变为64*4*4=1024nn.Linear(in_features=1024, out_features=64),nn.Linear(in_features=64, out_features=10),)def forward(self,x):x = self.model(x)return xbs = BS()
print(bs)
BS((model): Sequential((0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(6): Flatten(start_dim=1, end_dim=-1)(7): Linear(in_features=1024, out_features=64, bias=True)(8): Linear(in_features=64, out_features=10, bias=True))
)
# 在tensorboard中显示
input_ = torch.ones((64,3,32,32))
writer = SummaryWriter(".logs")
writer.add_graph(bs, input_) # 定义的模型,数据
writer.close()
利用tensorboard可视化网络结构graph如下
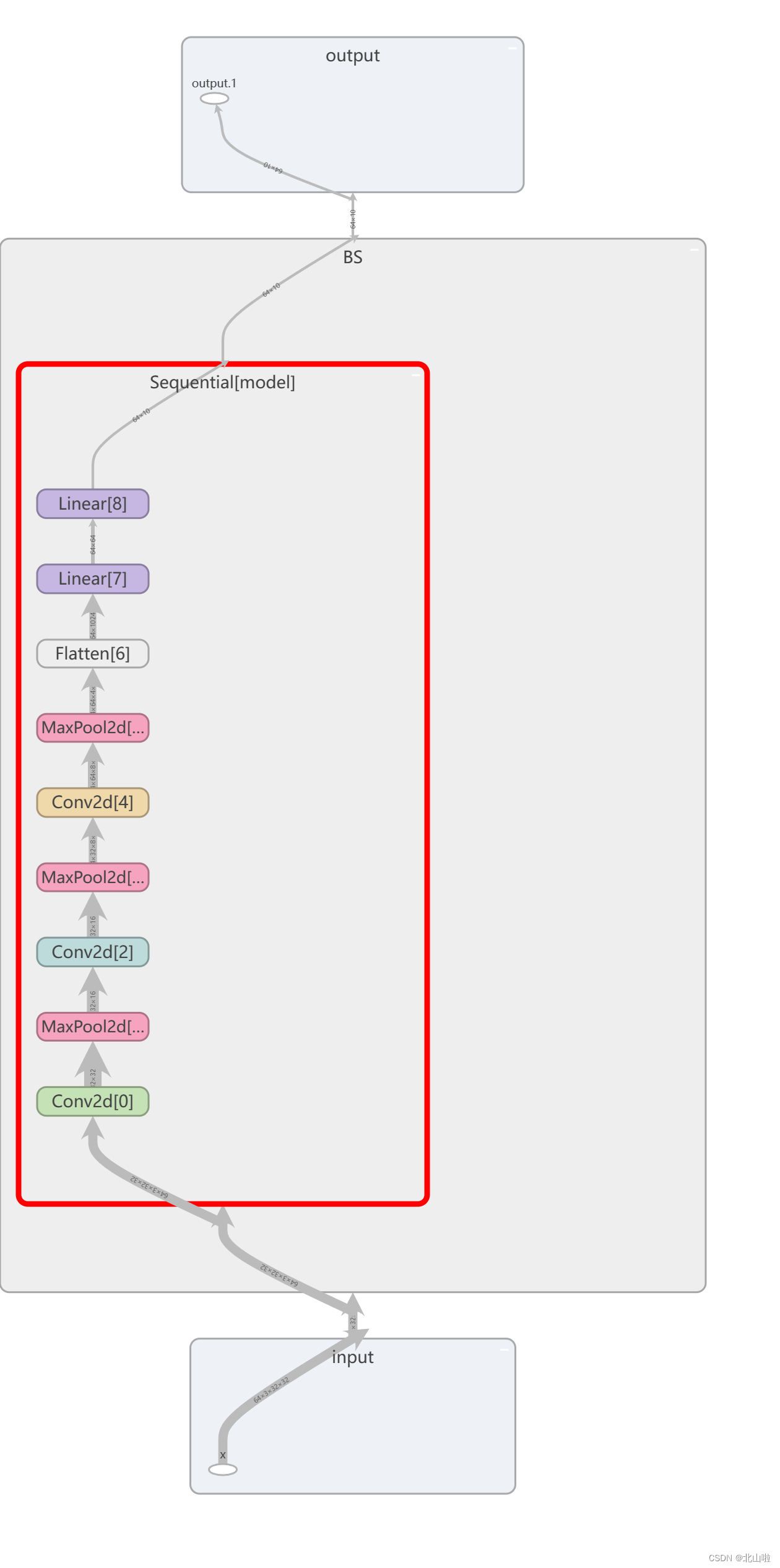
损失函数与反向传播
计算模型目标输出和实际输出之间的误差。并通过反向传播算法更新模型的权重和参数,以减小预测输出和实际输出之间的误差。
- 计算实际输出和目标输出之间的差距
- 为更新输出提供一定依据(反向传播)
不同的模型用的损失函数一般也不一样。
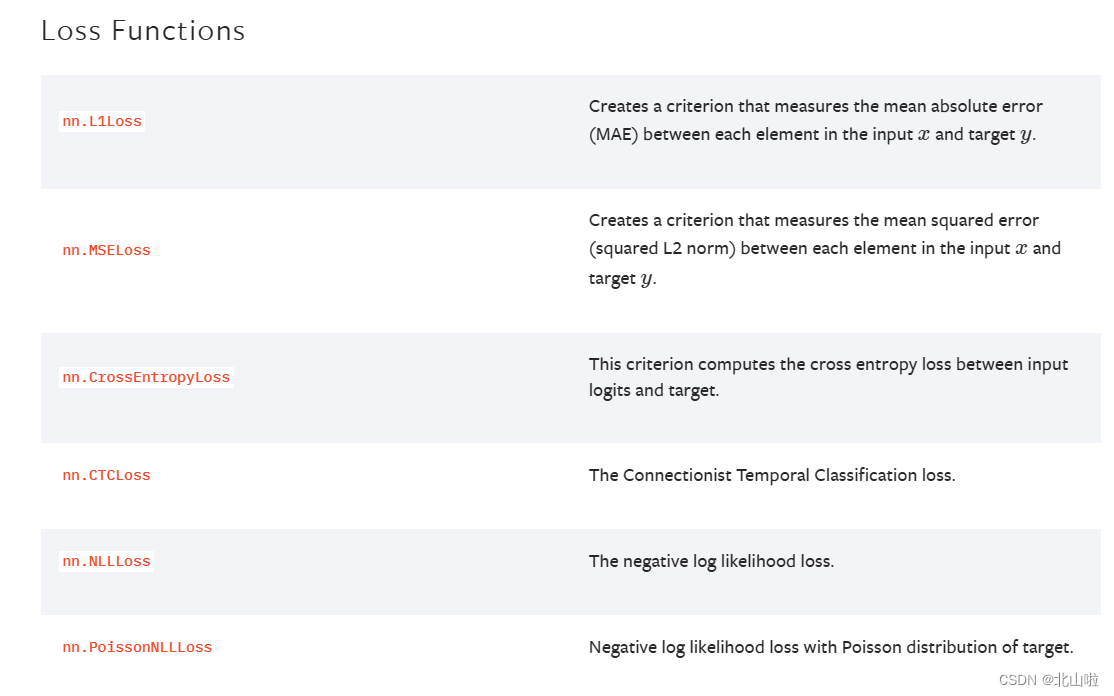
平均绝对误差MAE Mean Absolute Error
torch.nn.L1Loss(size_average=None, reduce=None, reduction=‘mean’)

import torch
import torch.nn as nn
# 实例化
criterion1 = nn.L1Loss(reduction='mean')#mean
criterion2 = nn.L1Loss(reduction="sum")#sum
output = torch.tensor([1.0, 2.0, 3.0])#或dtype=torch.float32
target = torch.tensor([2.0, 2.0, 2.0])#或dtype=torch.float32
# 平均值损失值
loss = criterion1(output, target)
print(loss) # 输出:tensor(0.6667)
# 误差和
loss1 = criterion2(output,target)
print(loss1) # tensor(2.)
tensor(0.6667)
tensor(2.)
loss = nn.L1Loss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()
output
tensor(1.0721, grad_fn=<MeanBackward0>)
均方误差MSE Mean-Square Error

torch.nn.MSELoss(size_average=None, reduce=None, reduction=‘mean’)

import torch.nn as nn
# 实例化
criterion1 = nn.MSELoss(reduction='mean')
criterion2 = nn.MSELoss(reduction="sum")
output = torch.tensor([1, 2, 3],dtype=torch.float32)
target = torch.tensor([1, 2, 5],dtype=torch.float32)
# 平均值损失值
loss = criterion1(output, target)
print(loss) # 输出:tensor(1.3333)
# 误差和
loss1 = criterion2(output,target)
print(loss1) # tensor(4.)
tensor(1.3333)
tensor(4.)
交叉熵损失 CrossEntropyLoss
torch.nn.CrossEntropyLoss(weight=None,size_average=None,ignore_index=-100,reduce=None,reduction='mean',label_smoothing=0.0)
当你有一个不平衡的训练集时,这是特别有用的

import torch
import torch.nn as nn# 设置三分类问题,假设是人的概率是0.1,狗的概率是0.2,猫的概率是0.3
x = torch.tensor([0.1, 0.2, 0.3])
print(x)
y = torch.tensor([1]) # 设目标标签为1,即0.2狗对应的标签,目标标签张量y
x = torch.reshape(x, (1, 3)) # tensor([[0.1000, 0.2000, 0.3000]]),批次大小为1,分类数3,即为3分类
print(x)
print(y)
# 实例化对象
loss_cross = nn.CrossEntropyLoss()
# 计算结果
result_cross = loss_cross(x, y)
print(result_cross)
tensor([0.1000, 0.2000, 0.3000])
tensor([[0.1000, 0.2000, 0.3000]])
tensor([1])
tensor(1.1019)
import torch
import torchvision
from torch.utils.data import DataLoader# 准备数据集
dataset = torchvision.datasets.CIFAR10(root="dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 数据集加载器
dataloader = DataLoader(dataset, batch_size=1)
"""
输入图像是3通道的32×32的,
先后经过卷积层(5×5的卷积核)、
最大池化层(2×2的池化核)、
卷积层(5×5的卷积核)、
最大池化层(2×2的池化核)、
卷积层(5×5的卷积核)、
最大池化层(2×2的池化核)、
拉直、
全连接层的处理,
最后输出的大小为10
"""# 搭建神经网络
class BS(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #stride和padding计算得到nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(), #变为64*4*4=1024nn.Linear(in_features=1024, out_features=64),nn.Linear(in_features=64, out_features=10),)def forward(self, x):x = self.model(x)return x# 实例化
bs = BS()
loss = torch.nn.CrossEntropyLoss()
# 对每一张图片进行CrossEntropyLoss损失函数计算
# 使用损失函数loss计算预测结果和目标标签之间的交叉熵损失for inputs,labels in dataloader:outputs = bs(inputs)result = loss(outputs,labels)print(result)tensor(2.3497, grad_fn=<NllLossBackward0>)
tensor(2.2470, grad_fn=<NllLossBackward0>)
tensor(2.2408, grad_fn=<NllLossBackward0>)
tensor(2.2437, grad_fn=<NllLossBackward0>)
tensor(2.3121, grad_fn=<NllLossBackward0>)
........
优化器
优化器(Optimizer)是用于更新神经网络参数的工具
它根据计算得到的损失函数的梯度来调整模型的参数,以最小化损失函数并改善模型的性能
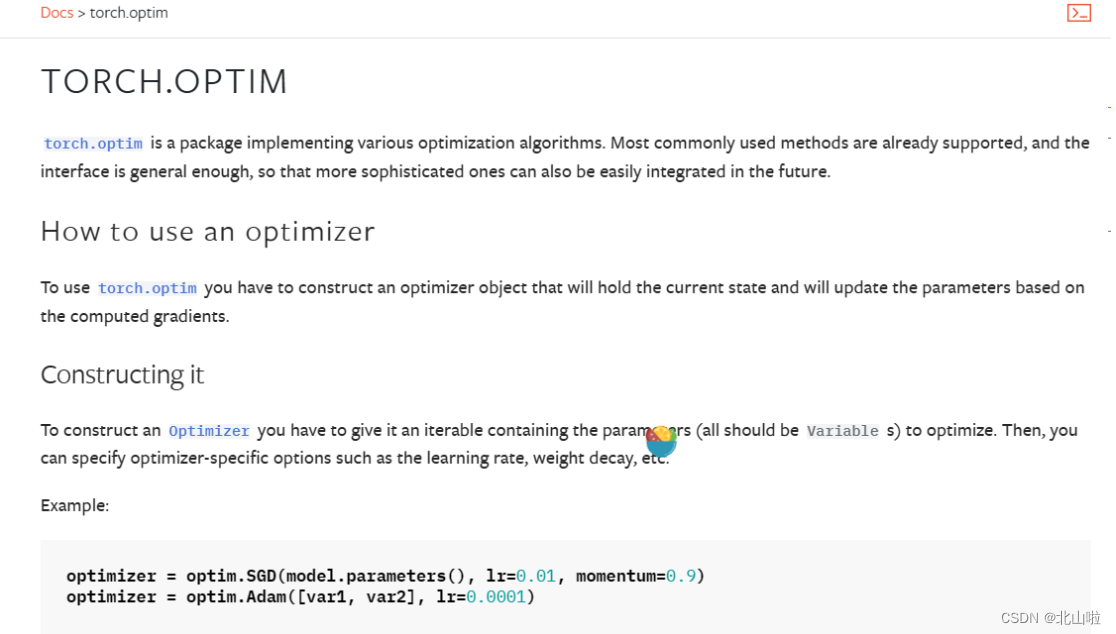
常见的优化器包括:SGD、Adam
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
model.parameters()用于获取模型的可学习参数
learning rate,lr表示学习率,即每次参数更新的步长
在每个训练批次中,需要执行以下操作:
-
输入训练数据到模型中,进行前向传播
-
根据损失函数计算损失
-
调用优化器的zero_grad()方法清零之前的梯度
-
调用backward()方法进行反向传播,计算梯度
-
调用优化器的step()方法更新模型参数
伪代码如下(运行不了的)
import torch
import torch.optim as optim# Step 1: 定义模型
model = ...
# Step 2: 定义优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Step 3: 定义损失函数
criterion = ...
# Step 4: 训练循环
for inputs, labels in dataloader:# 前向传播outputs = model(inputs)# 计算损失loss = criterion(outputs, labels)# 清零梯度optimizer.zero_grad()# 反向传播,得到梯度loss.backward()# 更新参数,根据梯度就行优化optimizer.step()
在上述模型代码中,SGD作为优化器,lr为0.01。同时根据具体任务选择适合的损失函数,例如torch.nn.CrossEntropyLoss、torch.nn.MSELoss等,以CIFRA10为例
import torch
import torch.optim as optim
import torchvision
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=1)
class BS(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #stride和padding计算得到nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(), #变为64*4*4=1024nn.Linear(in_features=1024, out_features=64),nn.Linear(in_features=64, out_features=10),)def forward(self, x):x = self.model(x)return xmodel = BS() #定义model
optimizer = optim.SGD(model.parameters(), lr=0.01) #定义优化器SGD
criterion = nn.CrossEntropyLoss() #定义损失函数,交叉熵损失函数'''循环一次,只对数据就行了一轮的学习'''
for inputs, labels in dataloader:# 前向传播outputs = model(inputs)# 计算损失loss = criterion(outputs, labels)# 清零梯度optimizer.zero_grad()# 反向传播loss.backward()# 更新参数optimizer.step()# 打印经过优化器后的结果print(loss)"""训练循环20次"""
# for epoch in range(20):
# running_loss = 0.0
# for inputs, labels in dataloader:
# # 前向传播
# outputs = model(inputs)
# # 计算损失
# loss = criterion(outputs,labels)
# # 清零梯度
# optimizer.zero_grad()
# # 反向传播
# loss.backward()
# # 更新参数
# optimizer.step()
# # 打印经过优化器后的结果
# running_loss = running_loss + loss
# print(running_loss)
Files already downloaded and verified
tensor(2.3942, grad_fn=<NllLossBackward0>)
tensor(2.2891, grad_fn=<NllLossBackward0>)
tensor(2.2345, grad_fn=<NllLossBackward0>)
tensor(2.2888, grad_fn=<NllLossBackward0>)
tensor(2.2786, grad_fn=<NllLossBackward0>)
........
相关文章:
Pytorch损失函数、反向传播和优化器、Sequential使用
Pytorch_Sequential使用、损失函数、反向传播和优化器 文章目录 nn.Sequential搭建小实战损失函数与反向传播优化器 nn.Sequential nn.Sequential是一个有序的容器,用于搭建神经网络的模块被按照被传入构造器的顺序添加到nn.Sequential()容器中。 import torch.nn …...

css:两个行内块元素和图片垂直居中对齐
目录 两个行内块元素垂直居中对齐图片垂直居中问题图片和文字垂直居中对齐参考文章 两个行内块元素垂直居中对齐 先看一段代码: <style> .box {width: 200px;height: 200px;line-height: 200px;font-size: 20px;text-align: center;display: inline-block;b…...
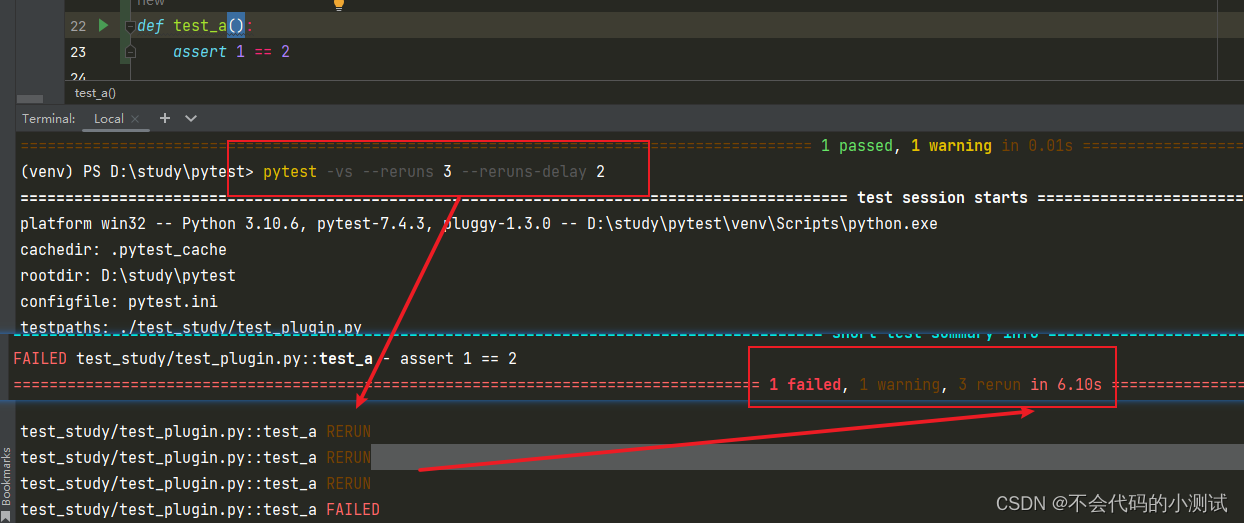
从0开始python学习-34.pytest常用插件
目录 1. pytest-html:生成HTML测试报告 2.pytest-xdist:并发执行用例 3. pytest-order:自定义用例的执行顺序 4. pytest-rerunfailures:用例失败时自动重试 5. pytest-result-log:用例执行结果记录到日志文件 1. pytest-html…...
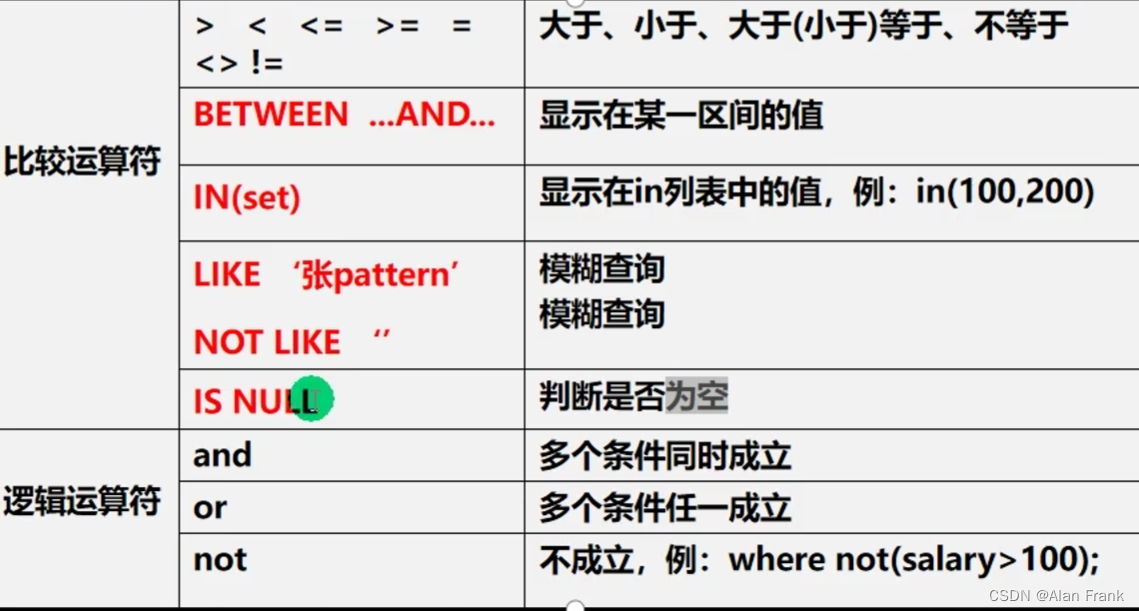
初始MySQL(二)(表的增删查改)
目录 修改表 CRUD(增删改查) insert语句(表中增加数据) update语句(修改表中的数据) delete删除语句 select语句 修改表 添加列 ALTER TABLE tablename ADD (column datatype [DEFAULT expr] [, column datatype] ...); 修改列 ALTER TABLE tablename MODIFY (column …...
SLAM从入门到精通(SLAM落地的难点)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 在所有的slam算法中,基于反光柱的激光slam和基于二维码的视觉slam是落地最彻底的两种slam方法。和磁条、色带等传统导航方式相比较&…...
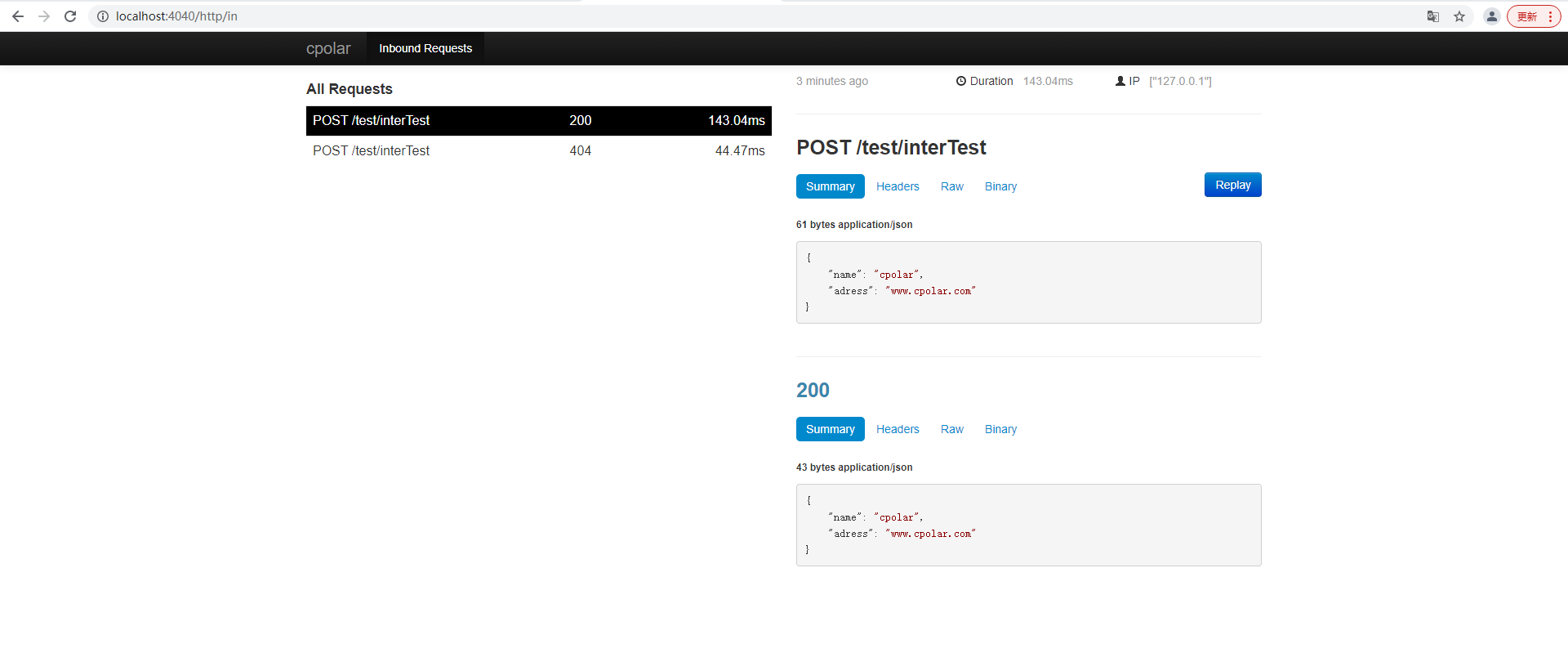
通过内网穿透快速搭建公网可访问的Spring Boot接口调试环境
文章目录 前言1. 本地环境搭建1.1 环境参数1.2 搭建springboot服务项目 2. 内网穿透2.1 安装配置cpolar内网穿透2.1.1 windows系统2.1.2 linux系统 2.2 创建隧道映射本地端口2.3 测试公网地址 3. 固定公网地址3.1 保留一个二级子域名3.2 配置二级子域名3.2 测试使用固定公网地址…...
职业迷茫,我该如何做好职业规划
案例25岁男,入职2月,感觉自己在混日子,怕能力没有提升,怕以后薪资也提不起来。完全不知道应该往哪个方向进修,感觉也没有自己特别喜欢的。感觉自己特别容易多想,想多年的以后一事无成的样子。 我觉得这个案…...
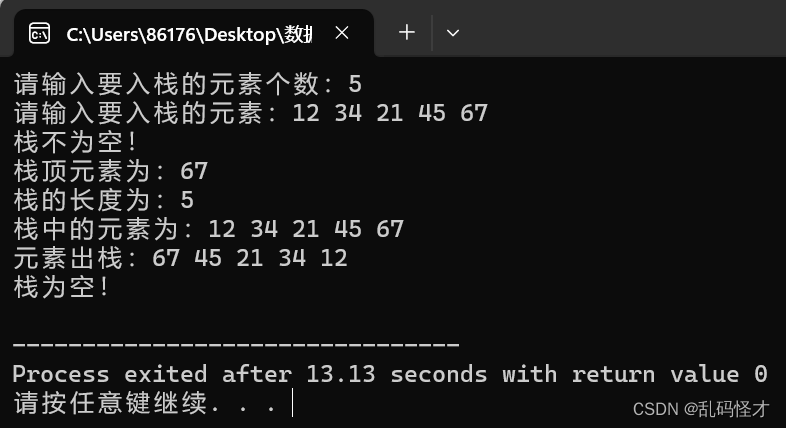
数据结构----顺序栈的操作
1.顺序栈的存储结构 typedef int SElemType; typedef int Status; typedef struct{SElemType *top,*base;//定义栈顶和栈底指针int stacksize;//定义栈的容量 }SqStack; 2.初始化栈 Status InitStack(SqStack &S){//初始化一个空栈S.basenew SElemType[MAXSIZE];//为顺序…...
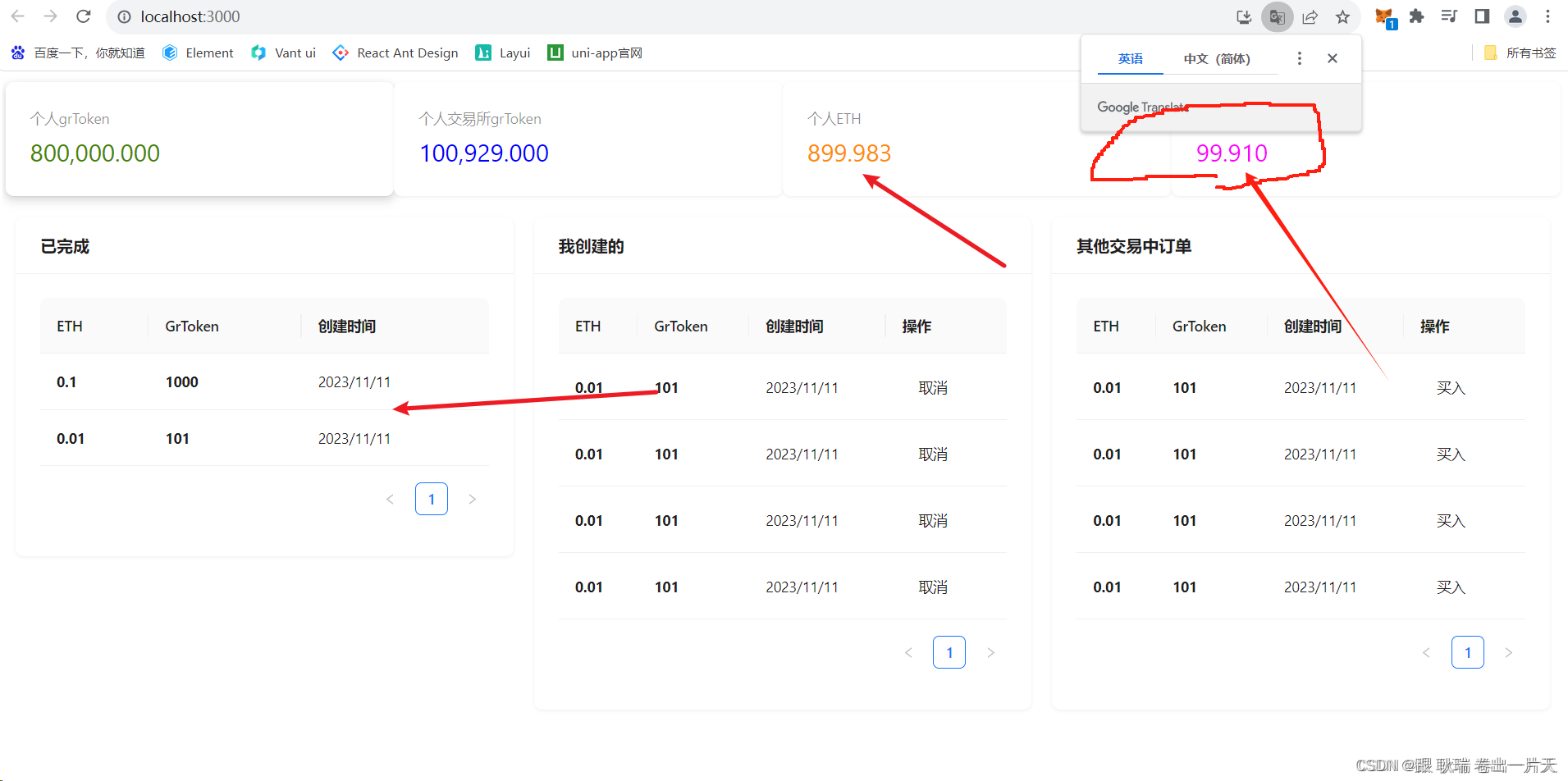
web3 React Dapp书写订单 买入/取消操作
好 上文web3 前端dapp从redux过滤出 (我创建与别人创建)正在执行的订单 并展示在Table上中 我们过滤出了 我创建的 与 别人创建的 且 未完成 未取消的订单数据 这边 我们起一下 ganache 环境 ganache -d然后 我们项目 发布一下智能合约 truffle migrate --reset然…...

C++学习---信号处理机制、中断、异步环境
文章目录 前言信号处理signal()函数关于异步环境 信号处理函数示例raise()函数 前言 信号处理 关于信号,信号是一种进程间通信的机制,用于在程序执行过程中通知进程发生了一些事件。在Unix和类Unix系统中,信号是一种异步通知机制,…...

机器学习——奇异值分解案例(图片压缩-代码简洁版)
本想大迈步进入前馈神经网络 但是…唉…瞅了几眼,头晕 然后想到之前梳理的奇异值分解、主成分分析、CBOW都没有实战 如果没有实际操作,会有一种浮在云端的虚无感 但是如果要实际操作,我又不想直接调用库包 可是…如果不直接调包,感…...
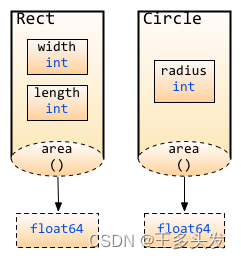
【Go入门】面向对象
【Go入门】面向对象 前面两章我们介绍了函数和struct,那你是否想过函数当作struct的字段一样来处理呢?今天我们就讲解一下函数的另一种形态,带有接收者的函数,我们称为method method 现在假设有这么一个场景,你定义…...

Asp.Net Core 中使用配置文件
本文参考微软文档:ASP.NET Core 中的配置 ASP.NET Core 中的应用程序配置是使用一个或多个配置程序提供程序执行的。 配置提供程序使用各种配置源从键值对读取配置数据: 设置文件,例如 appsettings.json环境变量Azure Key VaultAzure 应用配…...
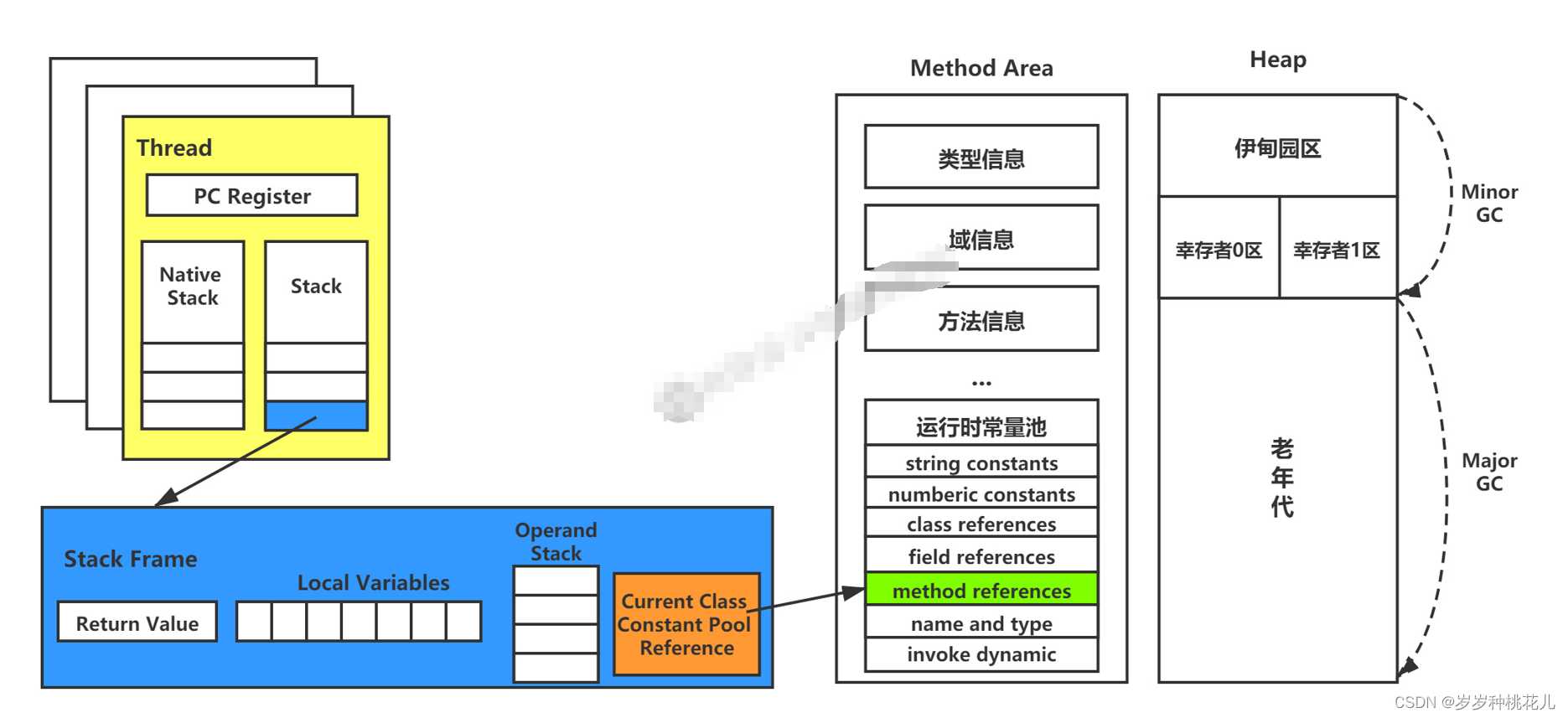
深入理解JVM虚拟机第二十四篇:详解JVM当中的动态链接和常量池的作用
大神链接:作者有幸结识技术大神孙哥为好友,获益匪浅。现在把孙哥视频分享给大家。 孙哥链接:孙哥个人主页 作者简介:一个颜值99分,只比孙哥差一点的程序员 本专栏简介:话不多说,让我们一起干翻J…...

QGridLayout
QGridLayout QGridLayout 是 Qt 框架中的一个布局管理器类,用于在窗口或其他容器中创建基于网格的布局。 QGridLayout 将窗口或容器划分为行和列的网格,并将小部件放置在相应的单元格中。可以通过调整行、列和单元格的大小来控制布局的样式和结构。 以…...
万能在线预约小程序系统源码 适合任何行业在线预约小程序+预约到店模式 带完整的搭建教程
大家好啊,源码小编又来给大家分享啦!随着互联网的发展和普及,越来越多的服务行业开始使用在线预约系统以方便客户和服务管理。例如,美发店、健身房、餐厅等都可以通过在线预约系统提高服务效率,减少等待时间࿰…...

Leetcode 2935. Maximum Strong Pair XOR II
Leetcode 2935. Maximum Strong Pair XOR II 1. 解题思路2. 代码实现 题目链接:2935. Maximum Strong Pair XOR II 1. 解题思路 这一题又是一个限制条件下找“最大值”的问题,不过这里的最大值是XOR之后的最大值。 而要求XOR之后结果的最大值&#x…...
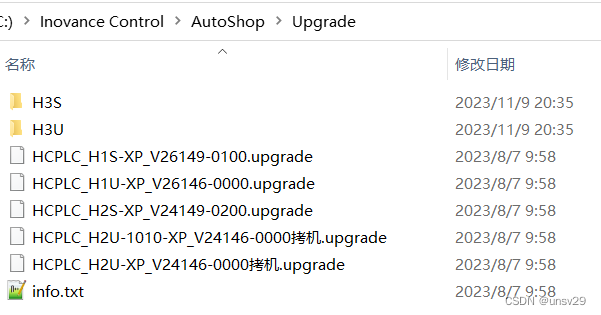
[直播自学]-[汇川easy320]搞起来(4)看文档 查找设备(续)
2023.11.12 周六 19:05 补充一下关于以太网查找设备,如果设置如下: 然后点击测试: 点击ping 如果设置如下: 测试和ping和上图一样。 这就设计的有点不大好了! 另…...
)
WebSphere Liberty 8.5.5.9 (四)
WebSphere Liberty 8.5.5.9 (四) [WebSphere Liberty 8.5.5.9]Linux 环境 ~$ unzip wlp-webProfile7-java8-linux-x86_64-8.5.5.9.zip ./ ~$ mkdir wlp-webProfile7-java8-8559 ~$ mv wlp ./wlp-webProfile7-java8-8559启动 WebSphere Liberty 8.5.5.9 服务 ~$ cd /home/tes…...

UE特效案例 —— 角色刀光
目录 一,环境配置 二,场景及相机设置 三,效果制作 刀光制作 地裂制作 击打地面炸开制作 一,环境配置 创建默认地形Landscape,如给地形上材质需确定比例;添加环境主光源DirectionalLight,设…...

Matlab七次非均匀B样条轨迹规划及基于NSGAII的优化方法
matlab-B样条轨迹规划-1 七次非均匀B样条轨迹规划, 基于NSGAII的时间-能量-冲击最优。 换上自己的关节值和时间就能用,简单好用,最近在搞机器人轨迹规划,发现七次非均匀B样条真是个好东西。它不仅能保证轨迹的平滑性,还…...

tmux 示例
技术文章大纲示例:人工智能在医疗诊断中的应用 引言 概述人工智能在医疗领域的重要性当前医疗诊断面临的挑战人工智能技术的引入如何改变传统诊断方式 人工智能技术基础 机器学习与深度学习的核心概念计算机视觉在医疗影像分析中的作用自然语言处理(NLP&…...

【2025最新】基于SpringBoot+Vue的游戏销售平台管理系统源码+MyBatis+MySQL
摘要 随着互联网技术的飞速发展,数字化娱乐产业迎来了前所未有的增长机遇。游戏作为数字娱乐的核心组成部分,其市场规模逐年扩大,用户需求日益多样化。传统的游戏销售模式已无法满足现代消费者的便捷性和个性化需求,亟需一个高效…...
开发环境到实战部署YOLOV5模型)
从零搭建QT(C++)开发环境到实战部署YOLOV5模型
1. 环境准备:从零搭建QT开发环境 第一次接触QT开发的朋友可能会被各种安装选项搞懵,我刚开始配置环境时也踩过不少坑。这里分享一个经过验证的安装方案,适用于大多数Linux系统(以Ubuntu为例)。 首先需要安装基础编译工…...
)
Codex CLI实战:5分钟搞定React Hooks重构与数据库迁移(附避坑指南)
Codex CLI实战:5分钟搞定React Hooks重构与数据库迁移(附避坑指南) 在快节奏的现代开发中,效率工具的价值愈发凸显。最近半年,身边不少团队开始将Codex CLI作为日常开发的"瑞士军刀"——特别是处理那些重复性…...

告别“权限不足”:手把手教你用CobaltStrike的Bypass UAC功能搞定Windows提权
实战指南:利用CobaltStrike突破Windows权限限制 当你手握一个普通用户权限的Beacon会话,却卡在"请求的操作需要提升"的提示前,这种挫败感每个渗透测试员都深有体会。Windows的用户账户控制(UAC)就像一堵无形的墙,将普通…...

Python核心控制结构全解析,Docker经典安装命令失效排查:Ubuntu/CentOS多系统测试与解决方案。
Python学习历程:核心控制结构解析 for循环结构 Python的for循环基于迭代器协议,可直接遍历序列或可迭代对象。典型语法为: for item in iterable:# 循环体print(item)支持else子句,当循环正常结束时执行: for i in ran…...

2025届必备的六大AI辅助写作平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 进行学术写作以及内容创作之际,使文本的AI生成痕迹得以降低,这是提升…...

macos简单配置openclaw贝
1 实用案例 1.1 表格样式生成 本示例用于生成包含富文本样式与单元格背景色的Word表格文档。 模板内容: 渲染代码: # python-docx-template/blob/master/tests/comments.py from docxtpl import DocxTemplate, RichText # data: python-docx-template/bl…...

C# 面试高频题:装箱和拆箱是如何影响性能的?彝
OCP原则 ocp指开闭原则,对扩展开放,对修改关闭。是七大原则中最基本的一个原则。 依赖倒置原则(DIP) 什么是依赖倒置原则 核心是面向接口编程、面向抽象编程, 不是面向具体编程。 依赖倒置原则的目的 降低耦合度&#…...