Python爬虫是否合法?
Python爬虫是否合法的问题颇具争议,主要涉及到使用爬虫的目的、操作方式以及是否侵犯了其他人的权益。本文将介绍Python爬虫的合法性问题,并提供一些相关的法律指导和最佳实践。
1. 什么是Python爬虫?
Python爬虫是一种自动化程序,可以从互联网上获取信息并提取数据。通过模拟网页浏览器的行为,爬虫可以访问网页、抓取数据、解析内容,并将其保存到本地或用于进一步分析。
2. 爬虫的合法性问题
使用Python爬虫的合法性问题主要涉及到以下几个方面:
2.1 网站的使用政策
大多数网站都有使用政策或使用条款,这些政策规定了用户在访问网站时的行为规范。在使用爬虫之前,你应该先仔细阅读网站的使用政策,了解是否允许使用爬虫程序来访问和抓取数据。
2.2 网络伦理和道德问题
使用爬虫可能会侵犯其他人的隐私和权益。如果你的爬虫程序用于获取个人信息、盗取敏感数据或滥用访问权限,那么它就是非法的。要遵循网络伦理和道德规范,确保你的爬虫程序不会侵犯他人的合法权益。
2.3 法律法规
不同国家和地区对爬虫的合法性问题有不同的法律法规。一些国家对爬虫有详细的法律规定,而另一些国家则缺乏明确的法律指导。在使用爬虫之前,你应该了解当地的法律法规,确保你的行为合法。
3. Python爬虫的合法使用指导
为了确保你使用Python爬虫的合法性,以下是一些指导原则:
3.1 确定你的使用目的
在确定使用爬虫之前,明确你的使用目的非常重要。如果你的目的是为了学习和研究,获取公开可用的信息,那么你的行为可能是合法的。例如,爬取公开的新闻网站上的新闻文章以进行文本分析是合法的。然而,如果你的目的是商业化利用他人的数据,如未经许可地收集用户个人信息用于广告推送,那么你的行为可能是非法的。
3.2 尊重网站的使用政策和使用条款
使用爬虫之前,务必仔细阅读网站的使用政策和使用条款。这些政策规定了用户在访问网站时的行为规范。有些网站可能明确禁止使用爬虫程序来访问和抓取数据,而另一些网站可能允许使用爬虫,但有一些限制。尊重网站的规定非常重要,如果网站明确禁止使用爬虫,你应该遵守这些规定。
3.3 控制爬虫的频率和访问深度
为了减少对网站的负担,避免对其正常运行造成干扰,你应该控制爬虫的访问频率和访问深度。过于频繁的访问会给网站带来过大的负担,可能会导致网站的崩溃或服务中断。合理设置爬虫的延迟时间和访问间隔,以避免对网站造成不必要的压力。
3.4 不侵犯他人的隐私和权益
在使用爬虫时,要确保不侵犯他人的隐私和权益。不要获取个人信息、敏感数据或滥用访问权限。尊重网站的隐私政策和用户协议,遵循网络伦理和道德规范。如果你要爬取的网页包含用户个人信息,你需要获得用户的明确同意,遵守相关法律法规。
3.5 遵守当地法律法规
不同国家和地区对于爬虫的合法性问题有不同的法律法规。在使用爬虫之前,你应该了解当地的法律法规,确保你的行为合法。有些国家可能对爬虫有详细的法律规定,而另一些国家可能缺乏明确的法律指导。如果你对当地的法律法规不确定,可以咨询专业律师或相关机构的意见。
通过遵循以上指导原则,你可以确保你的Python爬虫程序的合法性。同时,要记住合法使用爬虫可以为你提供许多便利,但不当使用可能会带来法律和伦理问题。要始终保持诚信和合法性,确保你的行为不会侵犯他人的权益。
4.爬虫学习大纲
当学习Python爬虫时,以下是一个入门学习大纲供参考:
4.1. 基础知识:
- Python基础语法:学习Python的基本语法、变量、数据类型、流程控制、函数等基础知识。
- HTML基础:了解HTML标签的基本结构和常见标签的使用。
- HTTP协议:熟悉HTTP请求和响应的基本结构,了解HTTP的GET、POST等常用方法。
4.2. 网络请求:
- requests库:学习如何使用Python中的requests库发送HTTP请求,并获取响应数据。
- 网络爬虫框架:了解Scrapy等常用的网络爬虫框架,学习如何使用框架进行数据爬取。
4.3. 数据解析和提取:
- 正则表达式:学习正则表达式的基本语法和用法,用于从HTML文本中提取所需信息。
- BeautifulSoup库:掌握BeautifulSoup库的使用,用于解析HTML文档,并提供简单的数据提取方法。
- XPath:了解XPath语法,学习使用XPath从HTML文档中提取数据。
4.4. 数据存储:
- 文件存储:学习将爬取到的数据存储到本地文件中,如CSV、JSON等格式。
- 数据库存储:了解如何将爬取到的数据存储到数据库中,如MySQL、MongoDB等。
4.5. 反爬虫和数据清洗:
- 反爬虫机制:学习常见的反爬虫机制,如User-Agent检测、验证码处理等。
- 数据清洗:了解数据清洗的基本方法,如去除HTML标签、去除重复数据等。
4.6. 进阶技巧:
- 并发爬虫:学习如何使用多线程、协程等技术提高爬虫的效率。
- 动态网页爬取:了解如何处理使用JavaScript动态生成内容的网页。
- IP代理和登录验证:了解如何使用IP代理和处理登录验证等问题。
4.7. 伦理和法律问题:
- 合法使用:学习爬虫的合法使用原则,遵守网站的使用条款和隐私政策。
- 遵守法律法规:了解当地的法律法规,确保爬虫行为合法。
以上是一个大致的学习大纲,你可以按照顺序逐步学习每个模块,逐渐掌握Python爬虫的技能。同时,可以结合实际项目和练习来提升自己的能力。记住,不断实践和探索是学习爬虫的关键。
5.爬虫使用场景:
假设你正在研究某个特定领域的产品价格走势,并希望通过爬取相关网站上的商品价格数据来进行分析和比较。
5.1. 数据采集:
使用爬虫技术,你可以编写程序来自动访问目标网站,获取商品页面的HTML内容。
5.2. 数据解析:
利用解析库(如BeautifulSoup或XPath),你可以从HTML中提取出商品名称、价格、评价等关键信息。
5.3. 数据存储:
将爬取到的数据存储到本地文件或数据库中,以备后续的分析和处理。
5.4. 数据分析:
通过对爬取到的数据进行统计、可视化等操作,你可以对不同商品的价格走势进行比较和分析。
通过这个场景,你可以了解到如何使用爬虫来获取所需的数据,然后进行后续的数据处理和分析。这种爬虫应用可以帮助你快速、准确地获取大量数据,并提供数据支持来进行定量分析和决策。
6. 结论
Python爬虫的合法性问题是一个复杂而有争议的话题。在使用爬虫之前,你应该了解网站的使用政策、遵循网络伦理和道德规范,并遵守当地的法律法规。合法使用爬虫可以为你提供许多便利,但不当使用可能会带来法律和伦理问题。要始终保持诚信和合法性,确保你的行为不会侵犯他人的权益。
相关文章:

Python爬虫是否合法?
Python爬虫是否合法的问题颇具争议,主要涉及到使用爬虫的目的、操作方式以及是否侵犯了其他人的权益。本文将介绍Python爬虫的合法性问题,并提供一些相关的法律指导和最佳实践。 1. 什么是Python爬虫? Python爬虫是一种自动化程序ÿ…...

3.2 IDAPro脚本IDC常用函数
IDA Pro内置的IDC脚本语言是一种灵活的、C语言风格的脚本语言,旨在帮助逆向工程师更轻松地进行反汇编和静态分析。IDC脚本语言支持变量、表达式、循环、分支、函数等C语言中的常见语法结构,并且还提供了许多特定于反汇编和静态分析的函数和操作符。由于其…...
用python将csv表格数据做成热力图
python的开发者为处理表格和画图提供了库的支持,使用pandas库可以轻松完成对csv文件的读写操作,使用matplotlib库提供了画热力图的各种方法。实现这个功能首先需要读出csv数,然后设置自定义色条的各种属性如颜色,位置,…...

【程序基础】递归法
算法思想 递归法,其实可以说是一种编程技巧,通过调用自身,防止无限循环而给予递归出口。 思考使用场景 1.一个问题可以拆分成子问题,每个子问题相互独立。 2.数据满足递推关系,或者数据结构满足,例如图&…...

AI 绘画 | Stable Diffusion WebUI的基本设置和插件扩展
前言 Stable Diffusion WebUI是一个基于Gradio库的浏览器界面,用于配置和生成AI绘画作品,并且进行各种精细地配置。它支持目前主流的开源AI绘画模型,例如NovelAI/Stable Diffusion。 在基本设置方面,Stable Diffusion WebUI的默…...
如何用自然语言 5 分钟构建个人知识库应用?我的 GPTs builder 尝试
开发者的想象力闸门一旦打开,迎接我们的必然是目不暇接的 AI 应用浪潮冲击。 兴奋 早晨,我突然发现 ChatGPT 最新的 Create GPTs 功能可以用了。 这太让我意外了,没想到这么快。根据页面上的提示,我一直以为还得等上一周左右。于是…...

rabbitmq启动异常解决
如果 RabbitMQ 节点一直停在 "Stopping and halting node" 阶段,可能是由于一些原因导致节点无法正常停止。以下是一些建议的步骤,以尝试解决此问题: 手动强制终止节点: 尝试使用 rabbitmqctl 命令手动终止节点。在终端…...
OpenGL_Learn08(坐标系统与3D空间)
目录 1. 概述 2. 局部空间 3. 世界空间 4. 观察空间 5. 剪裁空间 6. 初入3D 7. 3D旋转 8. 多个正方体 9. 观察视角 1. 概述 OpenGL希望在每次顶点着色器运行后,我们可见的所有顶点都为标准化设备坐标(Normalized Device Coordinate, NDC)。也就是说&#x…...
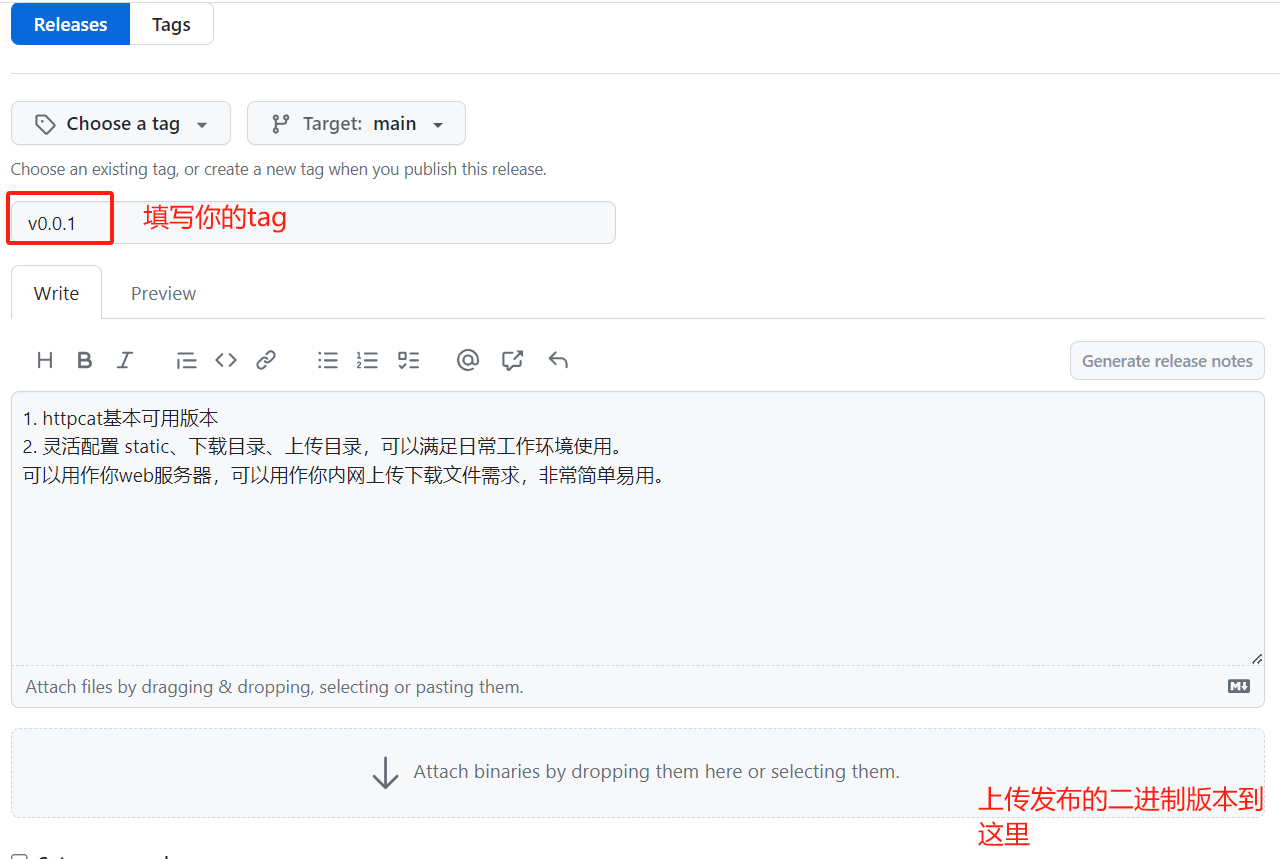
github私有仓库开发,公开仓库发布版本
文章目录 github私有仓库开发,公开仓库发布版本需求背景实现思路GitHub Releases具体步骤广告 github私有仓库开发,公开仓库发布版本 需求背景 github私有仓库开发,公开仓库发布版本,既可以保护源代码,又可以发布版本给用户使用。许多知名软件项目都采用了这样的开…...

绿色低碳 数字未来-辽宁省建筑电气2023年学术年会-安科瑞 蒋静
2023年8月18日,辽宁省建筑电气2023年学术年会在辽宁友谊国宾馆成功召开。本届大会以“绿色低碳 数字未来”为主题,着眼为辽宁省建设提供智慧化电气设计及高质量产品服务。 安科瑞围绕“绿色低碳 数字未来”的主题,携充电桩及运营管理平台、工…...

day55
今日内容概要 路由层 无名分组 有名分组 反向解析 无名分组反向解析 有名分组反向解析 路由分发 伪静态的概念(了解) 名称空间(了解) 虚拟环境(了解) django1.x和django2.x的区别 路由层 url(r^test/$, views.test), url(rtestadd, views.testadd), ## 首页的地址 u…...
如何安装Node.js? 创建Vue脚手架
1.进入Node.js官网,点击LTS版本进行下载 Node.js (nodejs.org)https://nodejs.org/en 2.然后一直【Next】即可 3.打开【cmd】,输入【node -v】注意node和-v中间的空格 查看已安装的Node.js的版本号,如果可以看到版本号,则安装成功 创建Vue脚手…...
ASP.NETWeb开发(C#版)-day1-C#基础+实操
目录 .NET实操:创建项目执行 C#基础语法数据类型变量实操001_变量如何在一个解决方案 中创建另一个项目实操002结构实操003-if else实操004-多分支多行注释按钮实操:循环 面向对象基础如何在同一个项目下创建新的.cs文件实操-类的定义与访问实操-练习实操…...

LGSVL Python API 使用
1. References [1] LGSVL-python API使用方法 - 简书 [2] GitHub - lgsvl/PythonAPI: Python API for Simulator...
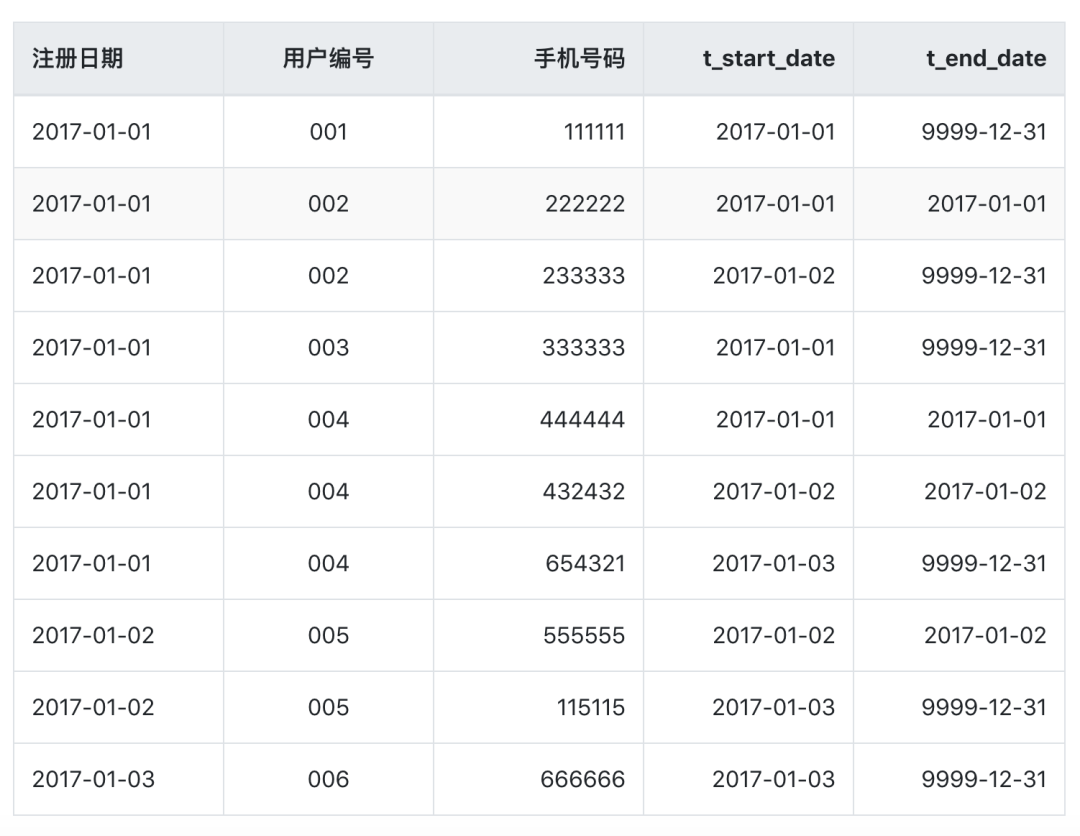
详解数据仓库之拉链表(原理、设计以及在Hive中的实现)
最近发现一本好书,读完感觉讲的非常好,首先安利给大家,国内第一本系统讲解数据血缘的书!点赞!近几天也会安排朋友圈点赞赠书活动(ง•̀_•́)ง 0x00 前言 本文将会谈一谈在数据仓库中拉链表相关的内容,包…...

使用Nodejs搭建简单的web网页并实现公网访问
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《Linux》《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 使用Nodejs搭建简单的web网页并实现公网访问 前言 Node.js是建立在谷歌Chrome的JavaScript引擎…...

C++学习第三十七天----第十章--对象和类
10.2.2 C中的类 类是一种将抽象转换未用户定义类型的C工具,它将数据表示和操作数据的方法合成一个整洁的包。 接口:一个共享框架,供两个系统交互时使用。 1.访问控制 使用类对象的程序可以直接访问类的公有部分,但只能通过公有…...

TikTok影响力经济:解锁社交媒体的商业机遇
社交媒体平台的崛起改变了我们与世界互动的方式,而TikTok作为其中的一员,已经成为全球范围内的现象。这个短视频应用不仅让用户在几秒钟内分享创意和娱乐,还为企业和创作者提供了巨大的商业机会。本文将深入探讨TikTok的影响力经济࿰…...
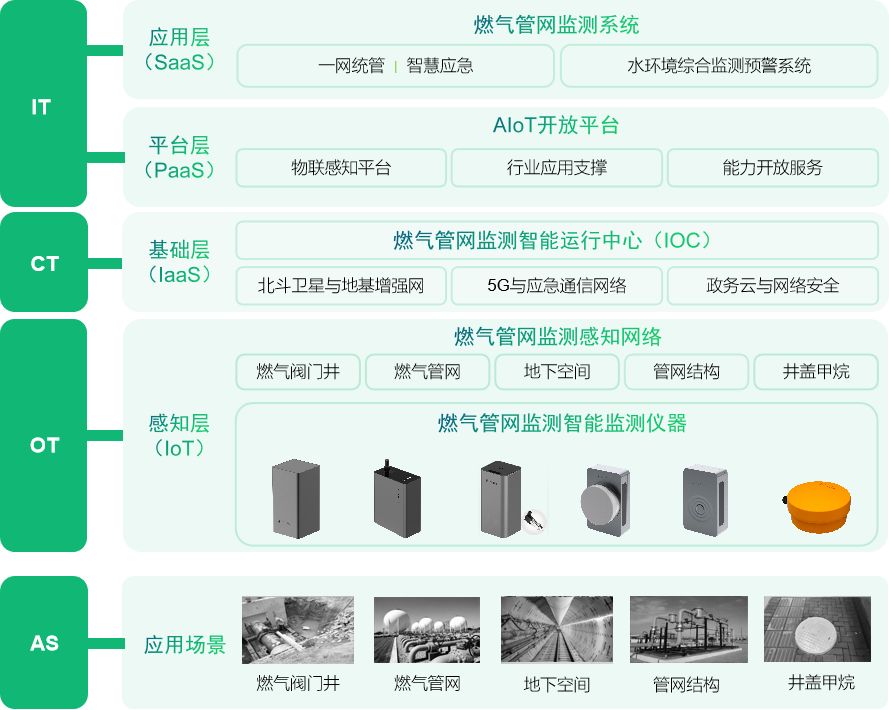
燃气管网监测系统|全面保障燃气安全
根据新华日报的报道,2023年上半年,我国共发生了294起燃气事故,造成了57人死亡和190人受伤,燃气事故的发生原因有很多,其中涉及到燃气泄漏、设备故障等因素。因此,加强燃气安全管理,提高城市的安…...
)
第三章:人工智能深度学习教程-基础神经网络(第六节-ML深度学习层列表)
要指定所有层按顺序连接的神经网络的架构,请直接创建层数组。要指定层可以有多个输入或输出的网络架构,请使用 LayerGraph 对象。使用以下函数创建不同的图层类型。 输入层: 功能描述图像输入层 将图像输入网络应用数据标准化序列输入层 将…...

还在手动拖动进度条整理长视频总结?2026年这4款AI视频总结工具,3分钟搞定1小时长片
我做内容创作快五年,光整理音视频素材这块,踩过的坑能绕办公桌三圈。之前天天手动拖进度条截重点,一小时长视频整理完大半天就没了。测了市面上十多款热门AI视频总结工具,我可以直接给结论:听脑AI是同类工具中最值得用…...

混合储能系统容量优化配置中的信号分解与容量分配算法解析
混合储能容量优化配置(钠硫电池、超级电容) 基于emd和vmd容量配置 1、先用vmd进行输入功率分解,通过分解出高频信号和低频信号,混合储能的功率分配,分给钠硫电池、超级电容。 2、分解后再求出储能的额定容量和额定功率…...

矽力杰 Silergy SY8810 降压稳压器 佰祥电子
突破算力供电瓶颈:SY8810单芯片15A大电流与IC数字调压全景拆解导语:在边缘计算SoC、高速光模块(如QSFP-DD)以及企业级SSD的主板设计中,核心处理器的供电轨正面临着极其苛刻的物理学挑战。随着先进制程工艺不断演进&…...

从Python到Maple:给程序员的数据结构与函数包迁移避坑手册
从Python到Maple:给程序员的数据结构与函数包迁移避坑手册 当你习惯了Python的灵活与简洁,突然切换到Maple的数学王国时,那种感觉就像从喧闹的都市搬进了严谨的实验室。作为一款专注于符号计算和数学建模的工具,Maple有着独特的思…...

ESPHome配置避坑指南:从编译到OTA,让你的ESP32-CAM一次点亮不折腾
ESPHome实战避坑手册:ESP32-CAM从编译到OTA的进阶配置策略 第一次接触ESP32-CAM时,我对着闪烁的蓝色LED灯整整调试了六个小时——不是因为硬件故障,而是YAML配置里一个不起眼的frequency参数写错了单位。这种令人抓狂的经历促使我整理了这份实…...

MKVToolNix Batch Tool 全功能指南:从批量处理到生态协作
MKVToolNix Batch Tool 全功能指南:从批量处理到生态协作 【免费下载链接】mkvtoolnix-batch-tool Batch video and subtitle processing program with the ability to add, remove, or extract subtitles from all video files in a directory and its sub-directo…...

Windows Defender Remover:彻底解决Windows安全组件冲突与性能瓶颈的终极方案
Windows Defender Remover:彻底解决Windows安全组件冲突与性能瓶颈的终极方案 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitc…...

从相位差到厘米级精度:深入解析蓝牙6.0 CS中PBR公式的推导与验证
1. 蓝牙6.0 CS技术中的相位测距原理 蓝牙6.0引入的信道探测(CS)功能将定位精度提升到了厘米级,这主要得益于其采用的相位测距法(PBR)。想象一下,这就像用无线电波玩"激光测距",只不过我们用的是相位差而不是光脉冲。在实际操作中&a…...

OpCore-Simplify智能配置工具:让系统环境适配不再复杂
OpCore-Simplify智能配置工具:让系统环境适配不再复杂 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 当技术爱好者小张第三次尝试配置系统…...

WSL2 子系统配置 SSH 并实现 VSCode 远程开发
1. 为什么要在WSL2中配置SSH服务? 作为一个长期使用WSL2进行开发的程序员,我发现直接通过终端操作WSL2虽然方便,但在某些场景下还是存在局限性。比如当需要同时管理多个项目时,终端窗口切换就显得不够高效;再比如团队协…...