原始GAN-pytorch-生成MNIST数据集(代码)
文章目录
- 原始GAN生成MNIST数据集
- 1. Data loading and preparing
- 2. Dataset and Model parameter
- 3. Result save path
- 4. Model define
- 6. Training
- 7. predict
原始GAN生成MNIST数据集
原理很简单,可以参考原理部分原始GAN-pytorch-生成MNIST数据集(原理)
import os
import time
import torch
from tqdm import tqdm
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torchvision.utils import save_image
import sys
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
1. Data loading and preparing
测试使用loadlocal_mnist加载数据
from mlxtend.data import loadlocal_mnist
train_data_path = "../data/MNIST/train-images.idx3-ubyte"
train_label_path = "../data/MNIST/train-labels.idx1-ubyte"
test_data_path = "../data/MNIST/t10k-images.idx3-ubyte"
test_label_path = "../data/MNIST/t10k-labels.idx1-ubyte"train_data,train_label = loadlocal_mnist(images_path = train_data_path,labels_path = train_label_path
)
train_data.shape,train_label.shape
((60000, 784), (60000,))
import matplotlib.pyplot as pltimg,ax = plt.subplots(3,3,figsize=(9,9))
plt.subplots_adjust(hspace=0.4,wspace=0.4)
for i in range(3):for j in range(3):num = np.random.randint(0,train_label.shape[0])ax[i][j].imshow(train_data[num].reshape((28,28)),cmap="gray")ax[i][j].set_title(train_label[num],fontdict={"fontsize":20})
plt.show()
2. Dataset and Model parameter
构造pytorch数据集datasets和数据加载器dataloader
input_size = [1, 28, 28]
batch_size = 128
Epoch = 1000
GenEpoch = 1
in_channel = 64
from torch.utils.data import Dataset,DataLoader
import numpy as np
from mlxtend.data import loadlocal_mnist
import torchvision.transforms as transformsclass MNIST_Dataset(Dataset):def __init__(self,train_data_path,train_label_path,transform=None):train_data,train_label = loadlocal_mnist(images_path = train_data_path,labels_path = train_label_path)self.train_data = train_dataself.train_label = train_label.reshape(-1)self.transform=transformdef __len__(self):return self.train_label.shape[0] def __getitem__(self,index):if torch.is_tensor(index):index = index.tolist()images = self.train_data[index,:].reshape((28,28))labels = self.train_label[index]if self.transform:images = self.transform(images)return images,labelstransform_dataset =transforms.Compose([transforms.ToTensor()]
)
MNIST_dataset = MNIST_Dataset(train_data_path=train_data_path,train_label_path=train_label_path,transform=transform_dataset)
MNIST_dataloader = DataLoader(dataset=MNIST_dataset,batch_size=batch_size,shuffle=True,drop_last=False)
img,ax = plt.subplots(3,3,figsize=(9,9))
plt.subplots_adjust(hspace=0.4,wspace=0.4)
for i in range(3):for j in range(3):num = np.random.randint(0,train_label.shape[0])ax[i][j].imshow(MNIST_dataset[num][0].reshape((28,28)),cmap="gray")ax[i][j].set_title(MNIST_dataset[num][1],fontdict={"fontsize":20})
plt.show()

3. Result save path
time_now = time.strftime('%Y-%m-%d-%H_%M_%S', time.localtime(time.time()))
log_path = f'./log/{time_now}'
os.makedirs(log_path)
os.makedirs(f'{log_path}/image')
os.makedirs(f'{log_path}/image/image_all')
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'using device: {device}')
using device: cuda
4. Model define
import torch
from torch import nn class Discriminator(nn.Module):def __init__(self,input_size,inplace=True):super(Discriminator,self).__init__()c,h,w = input_sizeself.dis = nn.Sequential(nn.Linear(c*h*w,512), # 输入特征数为784,输出为512nn.BatchNorm1d(512),nn.LeakyReLU(0.2), # 进行非线性映射nn.Linear(512, 256), # 进行一个线性映射nn.BatchNorm1d(256),nn.LeakyReLU(0.2),nn.Linear(256, 1),nn.Sigmoid() # 也是一个激活函数,二分类问题中,# sigmoid可以班实数映射到【0,1】,作为概率值,# 多分类用softmax函数)def forward(self,x):b,c,h,w = x.size()x = x.view(b,-1)x = self.dis(x)x = x.view(-1)return x class Generator(nn.Module):def __init__(self,in_channel):super(Generator,self).__init__() # 调用父类的构造方法self.gen = nn.Sequential(nn.Linear(in_channel, 128),nn.LeakyReLU(0.2),nn.Linear(128, 256),nn.BatchNorm1d(256),nn.LeakyReLU(0.2),nn.Linear(256, 512),nn.BatchNorm1d(512),nn.LeakyReLU(0.2),nn.Linear(512, 1024),nn.BatchNorm1d(1024),nn.LeakyReLU(0.2),nn.Linear(1024, 784),nn.Tanh())def forward(self,x):res = self.gen(x)return res.view(x.size()[0],1,28,28)D = Discriminator(input_size=input_size)
G = Generator(in_channel=in_channel)
D.to(device)
G.to(device)
D,G
(Discriminator((dis): Sequential((0): Linear(in_features=784, out_features=512, bias=True)(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): LeakyReLU(negative_slope=0.2)(3): Linear(in_features=512, out_features=256, bias=True)(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): LeakyReLU(negative_slope=0.2)(6): Linear(in_features=256, out_features=1, bias=True)(7): Sigmoid())),Generator((gen): Sequential((0): Linear(in_features=64, out_features=128, bias=True)(1): LeakyReLU(negative_slope=0.2)(2): Linear(in_features=128, out_features=256, bias=True)(3): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): LeakyReLU(negative_slope=0.2)(5): Linear(in_features=256, out_features=512, bias=True)(6): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(7): LeakyReLU(negative_slope=0.2)(8): Linear(in_features=512, out_features=1024, bias=True)(9): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(10): LeakyReLU(negative_slope=0.2)(11): Linear(in_features=1024, out_features=784, bias=True)(12): Tanh())))
6. Training
criterion = nn.BCELoss()
D_optimizer = torch.optim.Adam(D.parameters(),lr=0.0003)
G_optimizer = torch.optim.Adam(G.parameters(),lr=0.0003)
D.train()
G.train()
gen_loss_list = []
dis_loss_list = []for epoch in range(Epoch):with tqdm(total=MNIST_dataloader.__len__(),desc=f'Epoch {epoch+1}/{Epoch}')as pbar:gen_loss_avg = []dis_loss_avg = []index = 0for batch_idx,(img,_) in enumerate(MNIST_dataloader):img = img.to(device)# the output labelvalid = torch.ones(img.size()[0]).to(device)fake = torch.zeros(img.size()[0]).to(device)# Generator inputG_img = torch.randn([img.size()[0],in_channel],requires_grad=True).to(device)# ------------------Update Discriminator------------------# forwardG_pred_gen = G(G_img)G_pred_dis = D(G_pred_gen.detach())R_pred_dis = D(img)# the misfitG_loss = criterion(G_pred_dis,fake)R_loss = criterion(R_pred_dis,valid)dis_loss = (G_loss+R_loss)/2dis_loss_avg.append(dis_loss.item())# backwardD_optimizer.zero_grad()dis_loss.backward()D_optimizer.step()# ------------------Update Optimizer------------------# forwardG_pred_gen = G(G_img)G_pred_dis = D(G_pred_gen)# the misfitgen_loss = criterion(G_pred_dis,valid)gen_loss_avg.append(gen_loss.item())# backwardG_optimizer.zero_grad()gen_loss.backward()G_optimizer.step()# save figureif index % 200 == 0 or index + 1 == MNIST_dataset.__len__():save_image(G_pred_gen, f'{log_path}/image/image_all/epoch-{epoch}-index-{index}.png')index += 1# ------------------进度条更新------------------pbar.set_postfix(**{'gen-loss': sum(gen_loss_avg) / len(gen_loss_avg),'dis-loss': sum(dis_loss_avg) / len(dis_loss_avg)})pbar.update(1)save_image(G_pred_gen, f'{log_path}/image/epoch-{epoch}.png')filename = 'epoch%d-genLoss%.2f-disLoss%.2f' % (epoch, sum(gen_loss_avg) / len(gen_loss_avg), sum(dis_loss_avg) / len(dis_loss_avg))torch.save(G.state_dict(), f'{log_path}/{filename}-gen.pth')torch.save(D.state_dict(), f'{log_path}/{filename}-dis.pth')# 记录损失gen_loss_list.append(sum(gen_loss_avg) / len(gen_loss_avg))dis_loss_list.append(sum(dis_loss_avg) / len(dis_loss_avg))# 绘制损失图像并保存plt.figure(0)plt.plot(range(epoch + 1), gen_loss_list, 'r--', label='gen loss')plt.plot(range(epoch + 1), dis_loss_list, 'r--', label='dis loss')plt.legend()plt.xlabel('epoch')plt.ylabel('loss')plt.savefig(f'{log_path}/loss.png', dpi=300)plt.close(0)
Epoch 1/1000: 100%|██████████| 469/469 [00:11<00:00, 41.56it/s, dis-loss=0.456, gen-loss=1.17]
Epoch 2/1000: 100%|██████████| 469/469 [00:11<00:00, 42.34it/s, dis-loss=0.17, gen-loss=2.29]
Epoch 3/1000: 100%|██████████| 469/469 [00:10<00:00, 43.29it/s, dis-loss=0.0804, gen-loss=3.11]
Epoch 4/1000: 100%|██████████| 469/469 [00:11<00:00, 40.74it/s, dis-loss=0.0751, gen-loss=3.55]
Epoch 5/1000: 100%|██████████| 469/469 [00:12<00:00, 39.01it/s, dis-loss=0.105, gen-loss=3.4]
Epoch 6/1000: 100%|██████████| 469/469 [00:11<00:00, 39.95it/s, dis-loss=0.112, gen-loss=3.38]
Epoch 7/1000: 100%|██████████| 469/469 [00:11<00:00, 40.16it/s, dis-loss=0.116, gen-loss=3.42]
Epoch 8/1000: 100%|██████████| 469/469 [00:11<00:00, 42.51it/s, dis-loss=0.124, gen-loss=3.41]
Epoch 9/1000: 100%|██████████| 469/469 [00:11<00:00, 40.95it/s, dis-loss=0.136, gen-loss=3.41]
Epoch 10/1000: 100%|██████████| 469/469 [00:11<00:00, 39.59it/s, dis-loss=0.165, gen-loss=3.13]
Epoch 11/1000: 100%|██████████| 469/469 [00:11<00:00, 40.28it/s, dis-loss=0.176, gen-loss=3.01]
Epoch 12/1000: 100%|██████████| 469/469 [00:12<00:00, 37.60it/s, dis-loss=0.19, gen-loss=2.94]
Epoch 13/1000: 100%|██████████| 469/469 [00:11<00:00, 39.17it/s, dis-loss=0.183, gen-loss=2.95]
Epoch 14/1000: 100%|██████████| 469/469 [00:12<00:00, 38.51it/s, dis-loss=0.182, gen-loss=3.01]
Epoch 15/1000: 100%|██████████| 469/469 [00:10<00:00, 44.58it/s, dis-loss=0.186, gen-loss=2.95]
Epoch 16/1000: 100%|██████████| 469/469 [00:10<00:00, 44.08it/s, dis-loss=0.198, gen-loss=2.89]
Epoch 17/1000: 100%|██████████| 469/469 [00:10<00:00, 45.11it/s, dis-loss=0.187, gen-loss=2.99]
Epoch 18/1000: 100%|██████████| 469/469 [00:10<00:00, 44.98it/s, dis-loss=0.183, gen-loss=3.03]
Epoch 19/1000: 100%|██████████| 469/469 [00:10<00:00, 46.68it/s, dis-loss=0.187, gen-loss=2.98]
Epoch 20/1000: 100%|██████████| 469/469 [00:10<00:00, 46.12it/s, dis-loss=0.192, gen-loss=3]
Epoch 21/1000: 100%|██████████| 469/469 [00:10<00:00, 46.80it/s, dis-loss=0.193, gen-loss=3.01]
Epoch 22/1000: 100%|██████████| 469/469 [00:10<00:00, 45.86it/s, dis-loss=0.186, gen-loss=3.04]
Epoch 23/1000: 100%|██████████| 469/469 [00:10<00:00, 46.00it/s, dis-loss=0.17, gen-loss=3.2]
Epoch 24/1000: 100%|██████████| 469/469 [00:10<00:00, 46.41it/s, dis-loss=0.173, gen-loss=3.19]
Epoch 25/1000: 100%|██████████| 469/469 [00:10<00:00, 45.15it/s, dis-loss=0.19, gen-loss=3.1]
Epoch 26/1000: 100%|██████████| 469/469 [00:10<00:00, 44.26it/s, dis-loss=0.178, gen-loss=3.16]
Epoch 27/1000: 100%|██████████| 469/469 [00:10<00:00, 45.14it/s, dis-loss=0.187, gen-loss=3.17]
Epoch 28/1000: 1%|▏ | 6/469 [00:00<00:12, 38.20it/s, dis-loss=0.184, gen-loss=3.04]---------------------------------------------------------------------------
7. predict
input_size = [3, 32, 32]
in_channel = 64
gen_para_path = './log/2023-02-11-17_52_12/epoch999-genLoss1.21-disLoss0.40-gen.pth'
dis_para_path = './log/2023-02-11-17_52_12/epoch999-genLoss1.21-disLoss0.40-dis.pth'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator_Transpose(in_channel=in_channel).to(device)
dis = DiscriminatorLinear(input_size=input_size).to(device)
gen.load_state_dict(torch.load(gen_para_path, map_location=device))
gen.eval()
# 随机生成一组数据
G_img = torch.randn([1, in_channel, 1, 1], requires_grad=False).to(device)
# 放入网路
G_pred = gen(G_img)
G_dis = dis(G_pred)
print('generator-dis:', G_dis)
# 图像显示
G_pred = G_pred[0, ...]
G_pred = G_pred.detach().cpu().numpy()
G_pred = np.array(G_pred * 255)
G_pred = np.transpose(G_pred, [1, 2, 0])
G_pred = Image.fromarray(np.uint8(G_pred))
G_pred.show()
相关文章:
原始GAN-pytorch-生成MNIST数据集(代码)
文章目录原始GAN生成MNIST数据集1. Data loading and preparing2. Dataset and Model parameter3. Result save path4. Model define6. Training7. predict原始GAN生成MNIST数据集 原理很简单,可以参考原理部分原始GAN-pytorch-生成MNIST数据集(原理&am…...

注意,这些地区已发布2023年上半年软考报名时间
距离2023年上半年软考报名越来越近了,目前已有山西、四川、山东等地区发布报名简章,其中四川3月13日、山西3月14日、山东3月17日开始报名。 四川 报名时间:3月13日至4月3日。 2.报名入口:https://www.ruankao.org.cn/ 缴费时间…...

Html引入外部css <link>标签 @import
Html引入外部css 方法1: <link rel"stylesheet" href"x.css"> <link rel"stylesheet" href"x.css" /><link rel"stylesheet" href"x.css" type"text/css" /><link rel"sty…...

React源码分析8-状态更新的优先级机制
这是我的剖析 React 源码的第二篇文章,如果你没有阅读过之前的文章,请务必先阅读一下 第一篇文章 中提到的一些注意事项,能帮助你更好地阅读源码。 文章相关资料 React 16.8.6 源码中文注释,这个链接是文章的核心,文…...

如何在ChatGPT的API中支持多轮对话
一、问题 ChatGPT的API支持多轮对话。可以使用API将用户的输入发送到ChatGPT模型中,然后将模型生成的响应返回给用户,从而实现多轮对话。可以在每个轮次中保留用户之前的输入和模型生成的响应,以便将其传递给下一轮对话。这种方式可以实现更…...

华为OD机试模拟题 用 C++ 实现 - 猜字谜(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 最多获得的短信条数(2023.Q1)) 文章目录 最近更新的博客使用说明猜字谜题目输入输出描述备注示例一输入输出示例二输入输出思路Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,...

Containerd容器运行时将会替换Docker?
文章目录一、什么是Containerd?二、Containerd有哪些功能?三、Containerd与Docker的区别四、Containerd是否会替换Docker?五、Containerd安装、部署和使用公众号: MCNU云原生,欢迎微信搜索关注,更多干货&am…...

java虚拟机中对象创建过程
java虚拟机中对象创建过程 我们平常创建一个对象,仅仅只是使用new关键字new一个对象,这样一个对象就被创建了,但是在我们使用new关键字创建对象的时候,在java虚拟机中一个对象是如何从无到有被创建的呢,我们接下来就来…...

3485. 最大异或和
Powered by:NEFU AB-IN Link 文章目录3485. 最大异或和题意思路代码3485. 最大异或和 题意 给定一个非负整数数列 a,初始长度为 N。 请在所有长度不超过 M的连续子数组中,找出子数组异或和的最大值。 子数组的异或和即为子数组中所有元素按位异或得到的…...
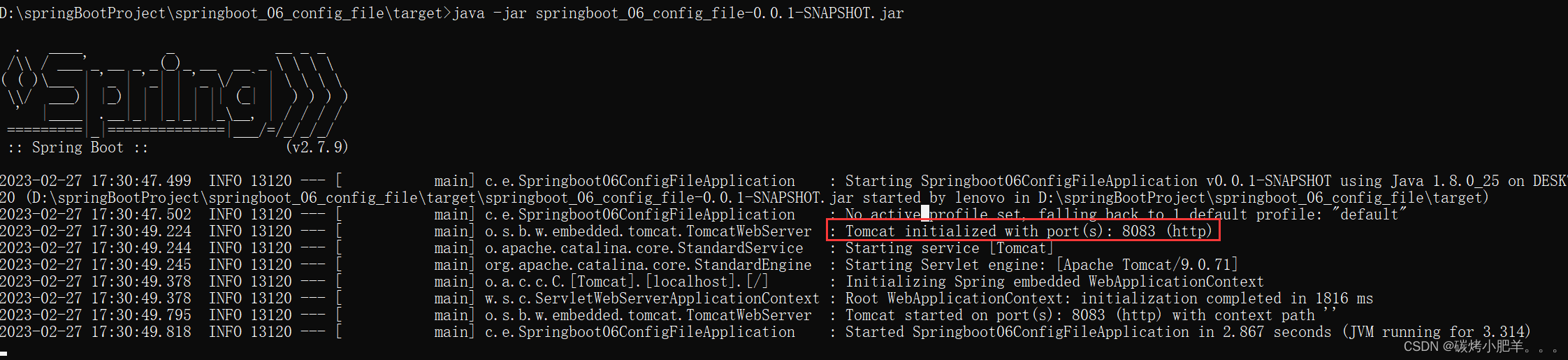
SpringBoot:SpringBoot配置文件.properties、.yml 和 .ymal(2)
SpringBoot配置文件1. 配置文件格式1.1 application.properties配置文件1.2 application.yml配置文件1.3 application.yaml配置文件1.4 三种配置文件优先级和区别2. yaml格式2.1 语法规则2.2 yaml书写2.2.1 字面量:单个的、不可拆分的值2.2.2 数组:一组按…...

QT 学习之QPA
QT 为实现支持多平台,实现如下类虚函数 Class Overview QPlatformIntegration QAbstractEventDispatcherQPlatformAccessibilityQPlatformBackingStoreQPlatformClipboardQPlatformCursorQPlatformDragQPlatformFontDatabaseQPlatformGraphicsBufferQPlatformInput…...

Pytorch中FLOPs和Params计算
文章目录一. 含义二. 使用thop库计算FLOPs和Params三. 注意四. 相关链接一. 含义 FLOPs(计算量):注意s小写,是floating point operations的缩写(这里的小s则表示复数),表示浮点运算数ÿ…...

DP1621国产LCD驱动芯片兼容替代HT1621B
目录DP1621简介DP1621芯片特性DP1621简介 DP1621是点阵式存储映射的LCD驱动器芯片,可支持最大128点(32SEG * 4COM)的 LCD屏,也支持2COM和3COM的LCD屏。单片机可通过3/4个通信脚配置显示参数和发送显示数据,也可通过指…...

Linux 用户管理
用户管理 useradd新增用户 格式:useradd [参数] 用户名称 常用参数: -c comment 指定一段注释性描述。 -d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录。 -g 用户组 指定用户所属的用户组…...
)
前端vue面试题(持续更新中)
vue-router中如何保护路由 分析 路由保护在应用开发过程中非常重要,几乎每个应用都要做各种路由权限管理,因此相当考察使用者基本功。 体验 全局守卫: const router createRouter({ ... }) router.beforeEach((to, from) > {// .…...

Java查漏补缺-从入门到精通汇总
Java查漏补缺(01)计算机的硬件与软件、软件相关介绍、计算机编程语言、Java语言概述、Java开发环境搭建、Java开发工具、注释、API文档、JVM Java查漏补缺(02)关键字、标识符、变量、基本数据类型介绍、基本数据类型变量间运算规…...
软件测试2年半的我,谈谈自己的理解...
软件测试两年半的我,谈谈自己的理解从2020年7月毕业,就成为一名测试仔。日子混了一鲲年,感觉需要好好梳理一下自己的职业道路了,回顾与总结下吧。一、测试的定位做事嘛,搞清楚自己的定位很重要。要搞清楚自己的定位&am…...

什么是SAS硬盘
什么是SAS硬盘SAS是新一代的SCSI技术,和Serial ATA(SATA)硬盘都是采用串行技术,以获得更高的传输速度,并通过缩短连结线改善内部空间等。SAS是并行SCSI接口之后开发出的全新接口。此接口的设计是为了改善存储系统的效能、可用性和扩充性&…...

一文理解服务端渲染SSR的原理,附实战基于vite和webpack打造React和Vue的SSR开发环境
SSR和CSR 首先,我们先要了解什么是SSR和CSR,SSR是服务端渲染,CSR是客户端渲染,服务端渲染是指 HTTP 服务器直接根据用户的请求,获取数据,生成完整的 HTML 页面返回给客户端(浏览器)展…...

Matlab 实用小函数汇总
文章目录Part.I 元胞相关Chap.I 创建空 char 型元胞Part.II 矩阵相关Chap.I 矩阵插入元素Part.III 字符串相关Chap.I 获取一个文件夹下所有文件的文件名的部分内容Part.IV 结构体相关Chap.I 读取结构体Chap.II 取结构体中某一字段的所有值本篇博文记录一些笔者使用 Matlab 时&a…...

EurekaClaw:多智能体AI研究助手,自动化实现从灵感到论文的完整流程
1. 项目概述:从灵感到论文的自动化研究助手在科研工作中,最令人兴奋又最耗费精力的,莫过于从零散的文献、模糊的直觉中,一步步构建出严谨的、可发表的成果。这个过程通常需要经历文献调研、假设生成、理论证明、实验验证和论文撰写…...

别再死记硬背公式了!用‘能量流动’视角图解RLC二阶电路,轻松理解零输入响应
能量流动视角:用物理直觉破解RLC二阶电路零输入响应之谜 想象一下,你手中握着一个透明的能量沙漏。上层的沙子(电能)缓缓流入下层(磁能),又因为重力作用回弹,形成有节奏的流动——这…...

ARM链接器Scatter文件解析与内存布局优化
1. ARM链接器Scatter文件核心概念解析在嵌入式系统开发中,内存布局的精确控制是确保系统稳定运行的关键。ARM链接器通过Scatter文件这一强大工具,为开发者提供了细粒度的内存管理能力。Scatter文件本质上是一个描述文件,它定义了代码和数据在…...

婚宴座位规划中的优化算法:量子与经典方法对比
1. 婚宴座位规划中的优化算法对决:量子与经典方法谁更胜一筹?筹备婚礼时,最令人头疼的任务之一就是安排座位。去年我为自己婚礼设计座位表时,尝试了各种方法——从手工调整Excel表格到使用专业活动策划软件,结果都不尽…...

SQL Chat:用自然语言对话操作数据库的实战指南
1. 项目概述:当自然语言遇见数据库 作为一名和数据打了十几年交道的开发者,我深知与数据库交互的痛点。无论是写复杂的多表关联查询,还是排查一个数据异常,传统的SQL客户端工具(比如Navicat、DBeaver)虽然…...
)
别再满世界找旧版了!用JetBrains Toolbox App一键管理所有IDE版本(含IDEA/PyCharm/WebStorm)
高效管理开发环境:JetBrains Toolbox App 的进阶使用指南 每次打开编辑器都要重新配置环境?项目组里有人用新版有人用旧版导致协作困难?插件突然不兼容最新版本?这些问题困扰着许多开发者。JetBrains Toolbox App 作为官方推出的管…...

Neovim涂抹光标插件:提升编码体验的动态轨迹设计
1. 项目概述:一个为Neovim设计的“涂抹光标”插件 如果你和我一样,是个重度Neovim用户,每天有超过8小时的时间泡在终端和代码编辑器里,那你肯定对光标的“存在感”有要求。默认的方块或下划线光标,在长时间编码后&…...

独立语音AI创业必读,ElevenLabs Independent计划全链路解析:从白名单内测→额度扩容→月度用量审计→续期失败预警
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs Independent计划的战略定位与生态价值 ElevenLabs Independent 计划并非单纯的技术授权项目,而是面向独立开发者、开源创作者与小型 AI 应用团队构建的可持续协作基础设施。其核…...

别只盯着SQL了!GaussDB健康度巡检,这5个‘外围’命令和日志文件更重要
别只盯着SQL了!GaussDB健康度巡检,这5个‘外围’命令和日志文件更重要 当数据库出现性能波动时,大多数DBA的第一反应是检查慢SQL或调整参数。但根据某金融客户的生产环境统计,超过60%的数据库故障其实源于日志溢出、网络闪断或备份…...

003、LVGL与其他GUI库对比
LVGL与其他GUI库对比:从一次内存泄漏调试说起 去年做一款智能家居中控屏,选了某款轻量级GUI库,跑了两周发现系统每隔几小时就卡死一次。用FreeRTOS的任务栈监控一看,某个绘图任务栈溢出——查了三天,发现是字体缓存没释放,每次切换界面都偷偷吃掉几百字节。后来换成LVGL…...