利用LangChain实现RAG
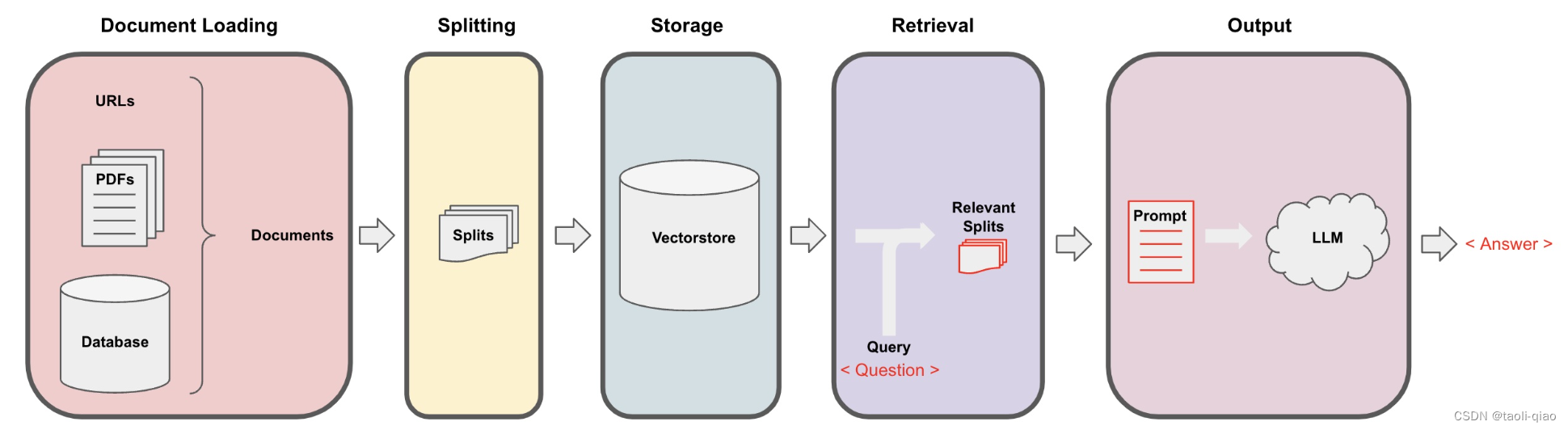
检索增强生成(Retrieval-Augmented Generation, RAG)结合了搜寻检索生成能力和自然语言处理架构,透过这个架构,模型可以从外部知识库搜寻相关信息,然后使用这些信息来生成response。要完成检索增强生成主要包含四个步骤:
1.TextLoad:
2.TextSplit:
3.Generate and save Embedding:
4.Search relavant context and get final anwser.
DocumentLoader
Langchain的document_loader目录下提供多种Load不同类型文档的方法,文档大类型总体可以分为结构化文档和非结构化文档。不同Loader的API信息如下图所示,更多Loader相关的API信息可查看这里。

下面是Load csv格式文件数据的代码和结果,import CSVLoader,print load的结果。可以看到,结果是一个List,List中每一个item是一个Document对象,包含page_content 和metadata数据,metadata包含source和row两个信息。

除了Load csv格式文件,还可以load pdf文件,import PyPDFLoader,load后的数据也是一个List,list中的每个value是Document对象,具体结果如下所示:

在Load PDF格式文档的时候,可以选择多种Loader,例如UnstructuredPDFLoader,MathpixPDFLoader,OnlinePDFLoader,PyPDFium2Loader,PDFMinerLoader,PyMuPDFLoader,PyPDFDirectoryLoader,PDFPlumberLoader。另外,在load PDF文档时还可以通过参数控制是否需要解析图片上的文字信息等。总之,PDF的loader是非常成熟和丰富的。
除了load PDF格式文档,当然还支持txt格式,markdown格式,html格式等文档,在load的时候可以通过参数选择是否显示load进度,是否使用多线程进行load,多线程load可提升load效率。代码如下所示:
loader = DirectoryLoader('testdata', glob="**/*.txt",show_progress=True, use_multithreading=True)docs = loader.load()print(docs)TextSplitter
langchain提供了多种TextSplitter,具体如下图所示,这些spliter中比较常用的有TextSplitter,CharacterTextSplitter,RecursiveCharacterTextSplitter等。

下面是调用CharacterTextSplitter对文本进行切割,需要指定separator,chunk_size,chunk_overlap等参数。chunk_size:定义文本应该被分割成的最大块的大小。在这个例子中,设置为 1000,所以每个块最多包含 1000 个字符。这只是一个最大字符数量控制,真正在分割的时候还要参考separator。chunk_overlap:块之间的最大重叠量。这里设置为 200,所以连续块之间最多可以有 200 个字符的重叠。length_function:用于计算块长度的函数。在这个例子中,使用内置的 len 函数,所以块的长度就是它的字符数.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(separator = "\n\n",chunk_size = 1000,chunk_overlap = 200,length_function = len,is_separator_regex = False,
)上面是最简单的文本切割方式,在切割分本时,我们需要尽量保证文本的语句含义不要丢失,即相关性很强的内容最好能放到一个chunk内,上面的切割方式虽然简单,但是容易把文本含义丢失。所以除了上面最简单的切割方式外,langchain还提供了RecursiveCharacterTextSplitter 切割方式。该切割方式的默认separator是["\n\n", "\n", " ", ""]。文本分割器首先尝试在每个双换行符 ("\n\n") 处拆分文本,这通常用于分隔文本中的段落。如果生成的块过大,它接着尝试在每个换行符 ("\n") 处拆分,这通常用于分隔句子。如果块仍然过大,它最后尝试在每个空格 (" ") 处拆分,这用于分隔单词。如果块仍然过大,它会在每个字符 ("") 处拆分,尽管在大多数情况下,这种细粒度的拆分是不必要的。这种方法的优点是它尽量保留了语义上下文,通过保持段落、句子和单词的完整性。这些文本单元往往具有强烈的语义关系,其中的单词在意义上通常密切相关,这对于许多自然语言处理任务是有益的。
根据经验,采用RecursiveCharacterTextSplitter进行文本切割时,chunk_size设置在500-1000分为内效果较好,chunk_overlap设置在chunk_size大小的10%-20%左右。
如果文档内容包含格式信息,例如html,markdown等,langchain还提供了HTMLHeaderTextSplitter和MarkdownHeaderTextSplitter切割方式。即在切割的时候按标题头切割,如果是在一个标题下的内容就放在一起。这样能最大程度保证相关性强的内容被切割在一个chunk里面。除了对文本进行切割,Langchain还可以对Code进行切割。下面的代码中就是加载代码目录地址,对该目录下的代码进行切割。
repo_path = "/Users/taoli/study/Python/langchain/langchain"
loader = GenericLoader.from_filesystem(repo_path,glob="**/*",suffixes=[".py"],parser=LanguageParser(language=Language.PYTHON, parser_threshold=500),
)
documents = loader.load()
python_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.PYTHON, chunk_size=1000, chunk_overlap=100
)
texts = python_splitter.split_documents(documents)Embedding model
介绍完了Splitter,接着来看看Embedding。langchain支持多种Embedding model的载入。部分Embedding model如下图所示,更多Embedding信息可查看这里。比较常用的有OpenAIEmbeddings和HuggingFaceEmbeddings。

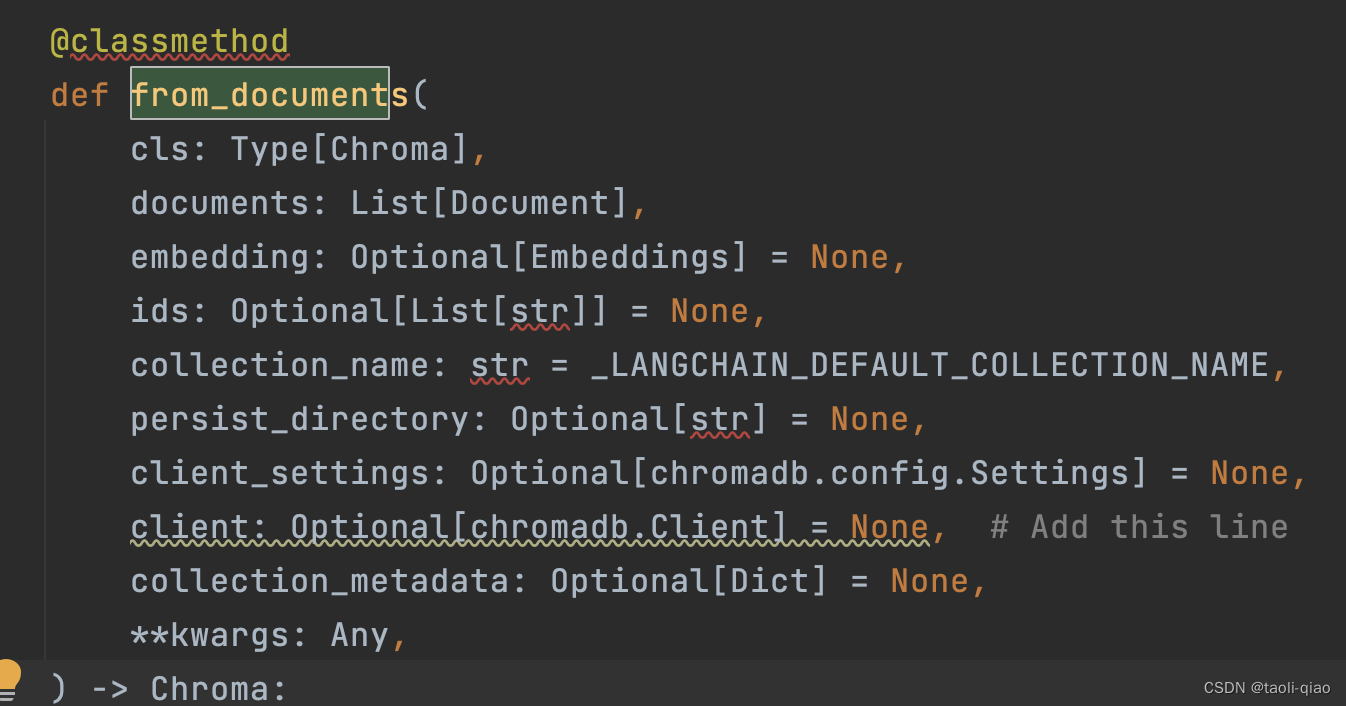
如下面代码所示,在调用向量数据库的classmethod from_document,就需要指定调用的Embedding方法,可以使用HuggingFace中某个特定的Embedding模型,也可以直接使用OpenAIEmbedding。设置Embedding后,调用from_document方法,就会把texts中的内容转换成向量并存放在向量数据库中,用于后面的检索获取。
db = Chroma.from_documents(texts, HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2"))
db = Chroma.from_documents(texts,OpenAIEmbeddings)在调用from_document方法时,除了指定embedding function,texts内容外,还可以指定persist_directory,即持久化向量信息的目录等多个参数信息。
Search relavant context and get final anwser
介绍完Embedding后,再来看看相关性检索和得到最终结果的部分。如下面代码所示,在获取到向量库对象后,需要转换成retriever。Retriever类可以根据输入的查询问题,从文档中检索相关性高的内容并返回,检索器不需要存储文档,只需要返回(或检索)文档。向量存储可以用作检索器的支撑,但还有其他类型的检索器。
retriever = db.as_retriever(search_type="mmr",search_kwargs={"k": 8})llm = ChatOpenAI(model_name="gpt-3.5-turbo")
qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever, chain_type_kwargs={"prompt": rag_prompt})
result = qa_chain({"query": "What classes are derived from the Chain class?"})
print(result)memory = ConversationSummaryMemory(llm=llm, memory_key="chat_history", return_messages=True
)
qa = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
questions = ["What is the class hierarchy?","What classes are derived from the Chain class?","What one improvement do you propose in code in relation to the class hierarchy for the Chain class?",
]
for question in questions:result = qa(question)print(f"-> **Question**: {question} \n")print(f"**Answer**: {result['answer']} \n")
在调用as_retriever()方法中可以指定search_type,search_type主要包括两种:query- Similarity Search and Max Marginal Relevance Search (MMR Search),其中MMR Search旨在提高搜索结果的多样性,常用于推荐系统。如果想检索更准确则推荐选择query- Similarity Search,默认的search_type也是query- Similarity Search。
search_kwargs中可以传入多个参数,常见的参数包括:
k 定义返回多少个文档;默认为 4。
如果search_type是 "similarity_score_threshold" ,可以设置score_threshold,即减少相关性的分数阀值。
fetch_k 确定传递给MMR算法的文档数量;默认为 20。
lambda_mult 控制MMR算法返回结果的多样性,1表示最小多样性,0表示最大多样性。默认为 0.5。
filter 允许您根据文档的元数据定义文档检索的筛选条件。如果Vectorstore不存储任何元数据,则此选项无效。

获取到retriver后,在检索文档生成答案时,有多种方式,既可以通过RetrievalQA这个chain, 还可以通过ConversationalRetrievalChain来获取最终的答案。在调用chain的时候还可以指定chain_type,langchain提供了四种类型的chain_type.Stuff,Refine,Map Reduce和Map re-rank.默认是使用Stuff类型。
Stuff:stuff文件链("stuff "是指 "to stuff "或 "to fill")是最直接的文件链。它接收一个文件列表,将它们全部插入一个提示,并将该提示传递给一个LLM。这条链非常适合于文件数量较少且大多数调用只传递几个文件的应用。

Refine:完善文档链通过循环输入文档和迭代更新其答案来构建一个响应。对于每个文档,它将所有非文档输入、当前文档和最新的中间答案传递给LLM链,以获得一个新的答案。由于Refine链每次只向LLM传递一个文档,所以它很适合需要分析更多文档的任务,这条链会比Stuff文档链等调用更多的LLM。当然,也有一些任务是很难迭代完成的。例如,当文档之间经常相互参照,或者当一个任务需要许多文档的详细信息时,Refine链的表现就很差。下图是Refine的过程源代码中Refine背后的Prompt信息。


Map_Reduce: map reduce文档链首先对每个文档单独应用LLM链(map步骤),将链的输出视为一个新的文档。然后,它将所有的新文档传递给一个单独的组合文档链,以获得一个单一的输出(Reduce步骤)。


Map re_rank:map re-rank文件链对每个文件进行初始提示,不仅试图完成一项任务,而且对其答案的确定程度进行评分。得分最高的回答会被返回。


在使用chain生成最终答案时,如果调用ConversationalRetrievalChain,可以在from_llm中传入如下的参数,包括chain_type,自定义的prompt等。例如要传入自定义的prompt,那么可以通过condense_question_prompt传入,或者通过combine_docs_chain_kwargs参数传入:
combine_docs_chain_kwargs={"prompt": TEST_PROMPT},

在使用chain生成最终答案时,如果调用RetrievalQA的from_chain_type方法,可以通过chain_type_kwargs传入自定义prompt等参数。

以上就是RAG的过程,总结而言包含Document Loader,Document splitter,Embedding,Search and get final answer四个步骤。步骤示意图如下所示:
相关文章:
利用LangChain实现RAG
检索增强生成(Retrieval-Augmented Generation, RAG)结合了搜寻检索生成能力和自然语言处理架构,透过这个架构,模型可以从外部知识库搜寻相关信息,然后使用这些信息来生成response。要完成检索增强生成主要包含四个步骤…...

零基础学习Matlab,适合入门级新手,了解Matlab
一、认识Matlab Matlab安装请参见博客 安装步骤 1.界面 2.清空环境变量及命令 (1)clear all :清除Workspace中的所有变量 (2)clc:清除Command Window中的所有命令 二、Matlab基础 1.变量命名规则 &a…...

CCF ChinaSoft 2023 论坛巡礼 | 自动驾驶仿真测试论坛
2023年CCF中国软件大会(CCF ChinaSoft 2023)由CCF主办,CCF系统软件专委会、形式化方法专委会、软件工程专委会以及复旦大学联合承办,将于2023年12月1-3日在上海国际会议中心举行。 本次大会主题是“智能化软件创新推动数字经济与社…...

vue封装useWatch hook支持停止监听和重启监听功能
import { watch, reactive } from vue;export function useWatch(source, cb, options) {const state reactive({stop: null});function start() {state.stop watch(source, cb, options);}function stop() {state.stop();state.stop null;}// 返回一个对象,包含…...

智能配方颗粒管理系统解决方案,专业实现中医药产业数字化-亿发
“中药配方颗粒”,又被称为免煎中药,源自传统中药饮片,经过提取、分离、浓缩、干燥、制粒、包装等工艺加工而成。这种新型配方药物完整保留了原中药饮片的所有特性。既能满足医师的辨证论治和随症加减需求,同时具备强劲好人高效的…...
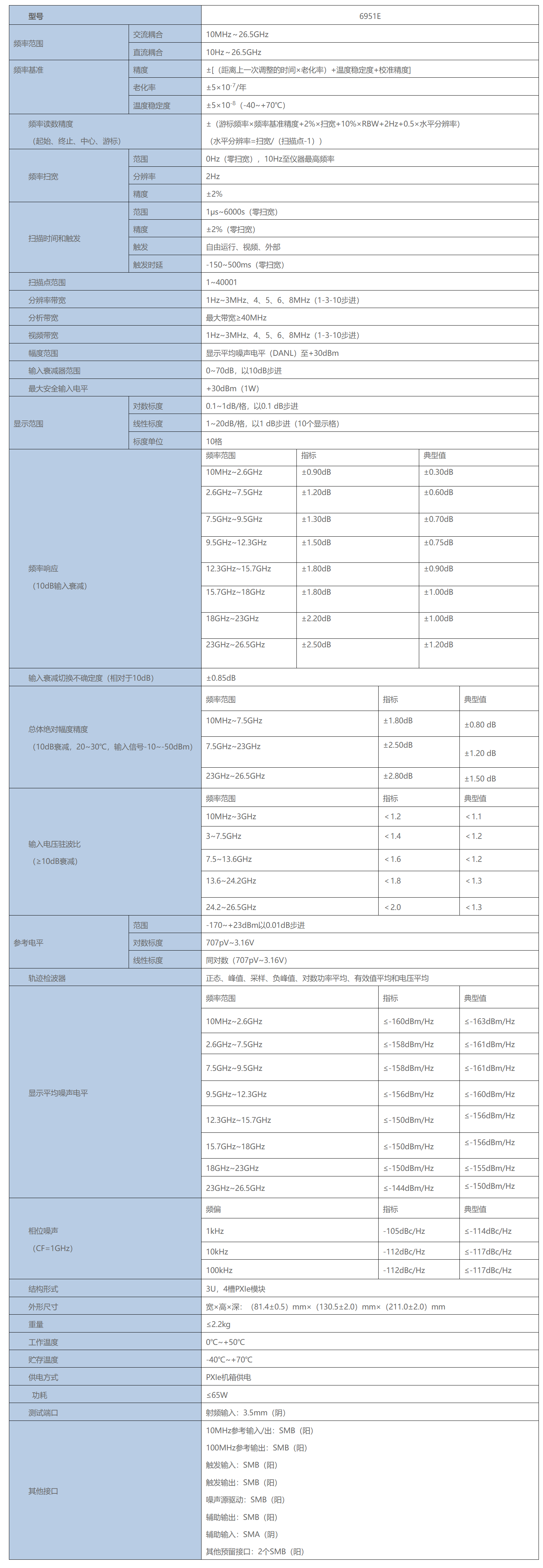
PXI总线测试模块-6951E 信号分析仪
6951E 信号分析仪 频率范围:10Hz~26.5GHz 6951E信号分析仪率范围覆盖10Hz~26.5GHz、带宽40MHz,具备频谱分析、相邻信道功率测试、模拟解调、噪声系数测试等多种测量功能。 6951E信号分析仪采用PXIe总线3U 4槽结构形式ÿ…...

精确杂草控制植物检测模型的改进推广
Improved generalization of a plant-detection model for precision weed control 摘要1、介绍2、结论摘要 植物检测模型缺乏普遍性是阻碍实现自主杂草控制系统的主要挑战之一。 本文研究了训练和测试数据集分布对植物检测模型泛化误差的影响,并使用增量训练来减小泛化误差。…...
C++:对象成员方法的使用
首先复习一下const : //const: //Complex* const pthis1 &ca; //约束指针自身 不能指向其他对象 // pthis1 &cb; err //pthis1->real; //const Complex* const pthis1 &ca;//指针指向 指针自身 都不能改 //pthis1->real; 只可读 …...
深入了解SpringMvc接收数据
目录 一、访问路径(RequestMapping) 1.1 访问路径注解作用域 1.2 路径精准(模糊)匹配 1.3 访问路径限制请求方式 1.4 进阶访问路径请求注解 1.5 与WebServlet的区别 二、接收请求数据 2.1 请求param参数 2.2 请求路径参数 2.3 请求…...

华东“启明”青少年音乐艺术实践中心揭幕暨中国“启明”巴洛克合奏团首演音乐会
2023年11月11日,华东“启明”青少年音乐艺术实践中心在上海揭幕,中国“启明”巴洛克合奏团开启了首场音乐会。 华东“启明”青少年音乐艺术实践中心由中共宁波市江北区委宣传部与上音管风琴艺术中心联合指导,宁波音乐港、宁波市江北区洛奇音乐…...

17. 机器学习——SVM
机器学习面试题汇总与解析——SVM 本章讲解知识点 什么是 SVMSVM 的基本原理线性不可分 SVM非线性 SVMSVM 优缺点本专栏适合于Python已经入门的学生或人士,有一定的编程基础。 本专栏适合于算法工程师、机器学习、图像处理求职的学生或人士。 本专栏针对面试题答案进行了优化…...

算法导论笔记5:贪心算法
P216 第15章动态规划 最优子结构 具有它可能意味着适合应用贪心策略 动态规划(Dynamic Programming)算法的核心思想是:将大问题划分为小问题进行解决,从而一步步获取最优解的处理算法。 剪切-粘贴技术证明 每个子问题的解就是它本身的最优解(利用反证法࿰…...

Vue的高级表格组件库【vxe-table】
文章目录 前言vxe-table官网实现表头拖拽树形表格全键盘操作后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:前端系列文章 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板…...

从0到0.01入门React | 002.精选 React 面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...

假冒 Skype 应用程序网络钓鱼分析
参考链接: https://slowmist.medium.com/fake-skype-app-phishing-analysis-35c1dc8bc515 背景 在Web3世界中,涉及假冒应用程序的网络钓鱼事件相当频繁。慢雾安全团队此前曾发表过分析此类网络钓鱼案例的文章。由于Google Play在中国无法访问,许多用户…...
软件外包开发的需求表达方法
软件开发需求的有效表达对于项目的成功至关重要。无论选择哪种需求表达方法,清晰、详细、易于理解是关键。与开发团队建立良好的沟通渠道,确保他们对需求有充分的理解,并随着项目的推进及时调整和更新需求文档。以下是一些常用的需求表达方法…...
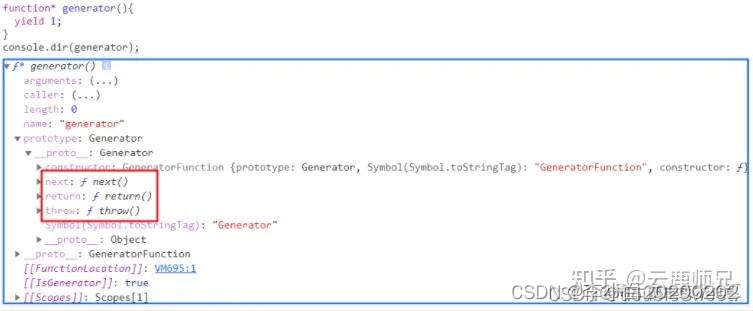
详解JS的四种异步解决方案:回调函数、Promise、Generator、async/await
同步&异步的概念 在讲这四种异步方案之前,我们先来明确一下同步和异步的概念: 所谓同步(synchronization),简单来说,就是顺序执行,指的是同一时间只能做一件事情,只有目前正在执行的事情做完之后&am…...

Python进行多线程爬取数据通用模板
首先,我们需要导入所需的库,包括requests和BeautifulSoup。requests库用于发送HTTP请求,BeautifulSoup库用于解析HTML文档。 import requests from bs4 import BeautifulSoup然后,我们需要定义一个函数来发送HTTP请求并返回响应。…...
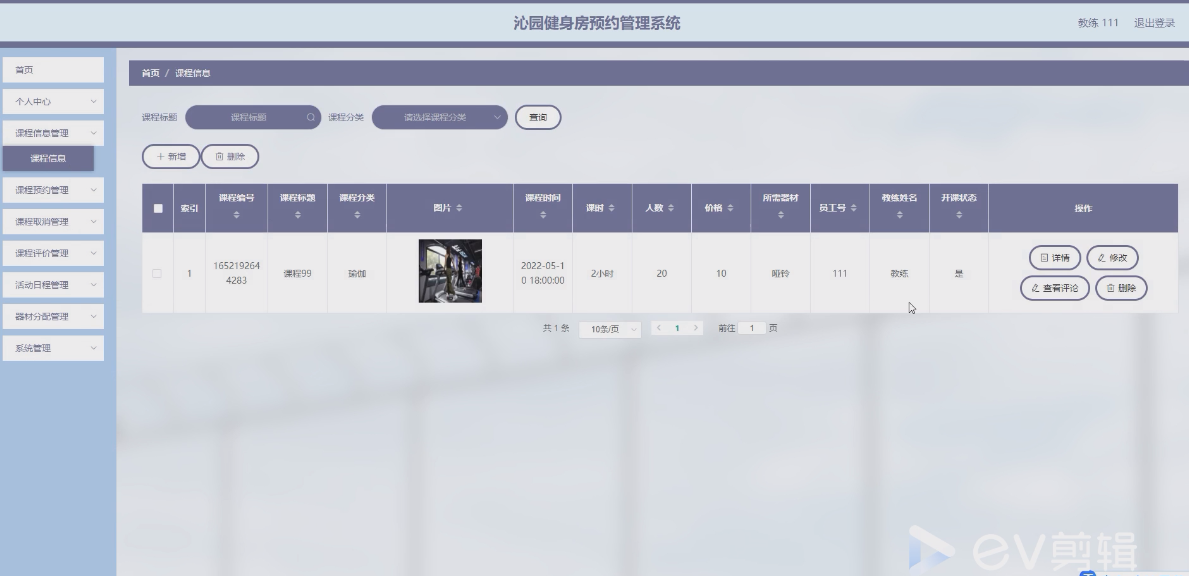
基于springboot实现沁园健身房预约管理系统【项目源码】
基于springboot实现沁园健身房预约管理系统演示 B/S架构 B/S结构是目前使用最多的结构模式,它可以使得系统的开发更加的简单,好操作,而且还可以对其进行维护。使用该结构时只需要在计算机中安装数据库,和一些很常用的浏览器就可以…...

论文笔记:Deep Trajectory Recovery with Fine-Grained Calibration using Kalman Filter
TKDE 2021 1 intro 1.1 背景 用户轨迹数据对于改进以用户为中心的应用程序很有用 POI推荐城市规划路线规划由于设备和环境的限制,许多轨迹以低采样率记录 采样的轨迹无法详细说明物体的实际路线增加了轨迹中两个连续采样点之间的不确定性——>开发有效的算法以…...

微信聊天记录管理:让个人数据资产化的完整解决方案
微信聊天记录管理:让个人数据资产化的完整解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMs…...
观测数据)
【数据集】SOCAT-表层海洋二氧化碳逸散度(fCO₂)观测数据
目录 数据概述 数据下载 参考 数据概述 1. 数据背景与意义 宏观背景(SOCAT):SOCAT(Surface Ocean CO₂ Atlas)是国际海洋碳研究界的一项核心数据综合项目,汇集了全球经过严格质量控制的表层海洋二氧化碳逸散度(fCO₂)观测数据。该项目受到全球海洋观测系统(GOOS)的认…...

颠覆式角色定制:开源工具Diablo Edit2如何重塑暗黑破坏神2游戏体验
颠覆式角色定制:开源工具Diablo Edit2如何重塑暗黑破坏神2游戏体验 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 在暗黑破坏神2的冒险旅程中,每位玩家都曾面临存档管理的…...
)
从到的木马免杀之旅(过卡巴)
开发个什么Skill呢? 通过 Skill,我们可以将某些能力进行模块化封装,从而实现特定的工作流编排、专家领域知识沉淀以及各类工具的集成。 这里我打算来一次“套娃式”的实践:创建一个用于自动生成 Skill 的 Skill,一是用…...

从零手写VSCODE 配置文件
VSCODE 配置文件书写详解 一.task.json 决定文件怎么编译,本质就是在指定的type下不断重复执行command和args构成的命令 1.基本框架 {"version":"2.0.0",//固定版本号"tasks":[ //任务数组,可以定义多个任务 {//任务一},{//任务二}],"i…...

Qwen3.5-9B企业知识库构建:PDF/Markdown文档注入+语义检索集成教程
Qwen3.5-9B企业知识库构建:PDF/Markdown文档注入语义检索集成教程 1. 项目概述 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,具备强大的逻辑推理、代码生成和多轮对话能力。其多模态变体Qwen3.5-9B-VL支持图文输入,并拥有长达128K token…...

Kandinsky-5.0-I2V-Lite-5s部署教程:Linux服务器supervisor配置+开机自启设置
Kandinsky-5.0-I2V-Lite-5s部署教程:Linux服务器supervisor配置开机自启设置 1. 环境准备与快速部署 在开始部署Kandinsky-5.0-I2V-Lite-5s之前,我们需要确保服务器环境满足以下要求: 操作系统:Ubuntu 20.04/22.04 LTS…...

LM339比较器:从基础参数到典型应用场景解析
1. LM339比较器基础解析 第一次接触LM339时,我完全被它"四合一"的设计惊艳到了——这个比指甲盖还小的芯片里,竟然藏着四个独立工作的电压比较器。简单来说,它就像四个并排摆放的天平,能同时比较八路电压信号的高低。实…...

《思想合奏:一场关于“自感即界面即自我”的深度对话综述》
《思想合奏:一场关于“自感即界面即自我”的深度对话综述》目录引言:从文本到事件一、起点:核心概念的厘定二、深化:五重维度的展开三、突破:自感诚实度循环与痕迹可检测性四、建构:伦理中间件与抵抗策略五…...

SecGPT-14B模型微调:OpenClaw自动化准备标注数据与训练脚本
SecGPT-14B模型微调:OpenClaw自动化准备标注数据与训练脚本 1. 为什么需要自动化微调流程 当我第一次尝试微调SecGPT-14B模型时,最让我头疼的不是模型本身,而是那些繁琐的前期准备工作。作为安全领域的从业者,我深知专业数据的价…...