论文阅读[121]使用CAE+XGBoost从荧光光谱中检测和识别饮用水中的有机污染物
【论文基本信息】 标题:Detection and Identification of Organic Pollutants in
Drinking Water from Fluorescence Spectra Based on Deep Learning Using
Convolutional Autoencoder 标题译名:基于使用卷积自动编码器的深度学习,从荧光光谱中检测和识别饮用水中的有机污染物
期刊与年份:Water 2021(JCR - Q2)
作者机构:浙江大学控制科学与工程学院
原文:https://www.mdpi.com/2073-4441/13/19/2633
一、介绍
- 荧光光谱由于其多重优势,越来越多地被用于检测水处理系统中的污染物。
- 荧光光谱实验的结果以EEM的形式提供。然而,EEM很难直接分析,因为它是高维的。
- 多路方法是典型的EEM降维方法,包括主成分分析(PCA)和平行因子分析(PARAFAC)。
- 尽管它们被广泛使用,但它们有一些局限性。例如,它们提取的特征是线性的,这种线性可能会带来特征信息的损失,从而降低检测精度。
- 近年来,许多学者提出了其他荧光分析方法来弥补这一不足。此外,深度学习在图像识别中的日益成熟,也为实现光谱特征提取提供了新的思路。
- 然而,这些方法几乎没有提到模型在水质背景变化下的适应性。
- 本文介绍一种基于EEM的饮用水中有机污染物检测新方法,该方法适用于在水质背景波动的情况下,低浓度分析物的光谱信号较弱的情况。
- 该方法设计了深度卷积自动编码器(CAE),用于降低EEM的维数并从中提取多层特征。它保证了有机污染物光谱在背景变化下的特征不变性,以及有机污染物光谱非线性特征的泛化自动学习;接着使用XGBoost分类器(一种梯度增强方法)来识别有机污染物。对3种有机污染物进行了测试,以验证上述方法。
二、方法
2.1 模型架构
图1:识别和测量水样中有机污染物的流程图。

2.2 数据预处理
采用三次插值法减少瑞利散射,消除拉曼散射。
2.3 卷积自动编码器
自动编码器是一种典型的自监督学习算法,它分为两部分:编码器和解码器。

编码器将高维输入数据x转换成低维编码表示h;解码器将低维编码h恢复为高维原始输入x。
f:非线性激活函数;W, W’:权重;b, b’:偏置
传统的自动编码器忽略了图像的邻域特征,并且输入层和隐藏层完全连接,引入了太多冗余参数。CAE直接处理二维图像,提取重叠块上的特征,并保留图像的邻域特征。多层CAE叠加形成了一个深层CAE,可用于提取深层光谱特征。
假设卷积层具有H个特征图,第k个特征图的权重矩阵为Wk,偏移量为bk,激活函数为f。使用EEM作为输入x来训练卷积层神经元,以获得第k−th(k=1,2,··,H)特征图: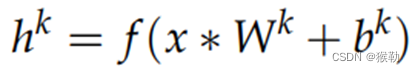
*:二维卷积
然后由解码器获得特征图的重建: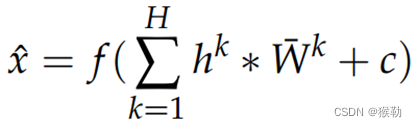
Wk:第k个特征图的权重矩阵Wk的转置;c:偏移量。
卷积自动编码器的目的是最小化重构误差函数E(W,b)的值: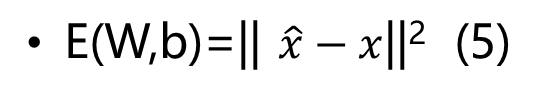
卷积自动编码器的工作过程如下图所示。
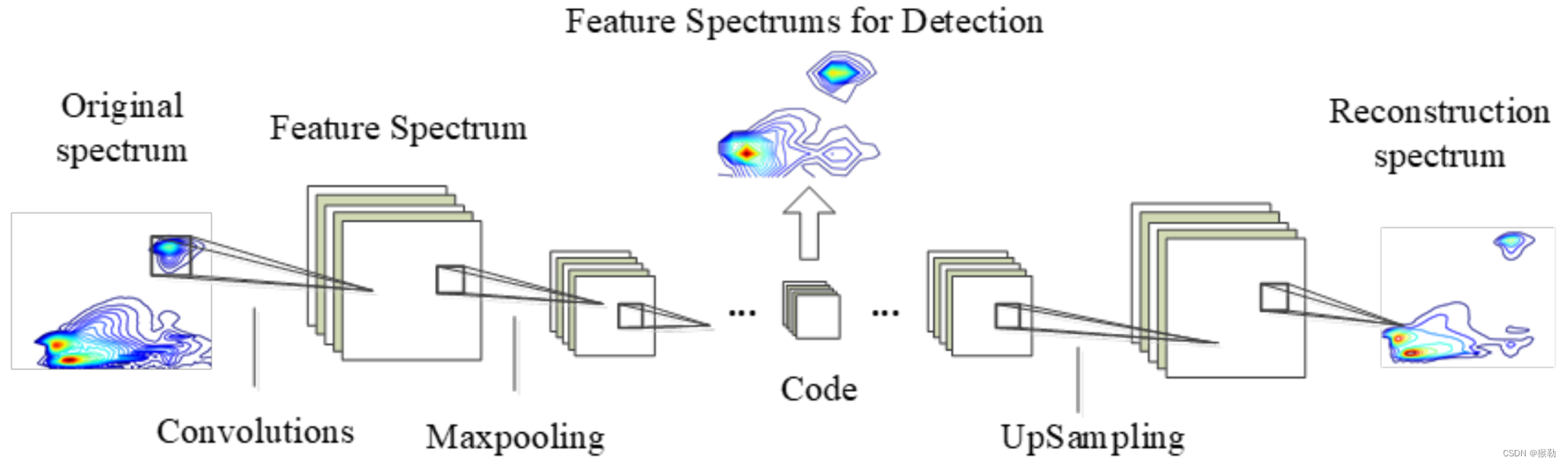
输入:原始光谱。
编码器层:由卷积层、ReLU激活函数(公式9,见下)和最大池化层组成。
每个编码器层都有相应的解码器层。
每个编码器中的最大采样层(即最大池化层)存储特征图上最大值的索引。
解码器中的上采样层使用由相应编码器存储的位置对特征图进行采样,并通过解码器中的卷积层来重建输入的光谱。
本文使用的编码器和解码器网络由3个层组成,每个层的卷积核心大小分别为16、8和6通道。通过卷积层和Sigmoid激活函数(公式10,见下)重建解码器的最终输出。使用随机梯度下降方法一次更新一次单个训练图像的参数。

2.4 XGBoost分类器
XGBoost是2016年提出的一种可扩展的Boost树机器学习方法,基于Gradient boosting。Gradient boosting是一种基于迭代累积的决策树算法,它构建一组弱决策树,并将多个决策树的结果累积为最终预测输出。
XGBoost的目标函数:J(Θ)=L(Θ)+Ω(Θ) (11)
Θ:模型训练参数。L:损失函数(均方误差或交叉熵)Ω:正则化术语(term),用于在模型复杂性和准确性之间取得平衡。
由于基础分类器是决策树,因此模型输出为K个回归树fk的集合F的投票或平均值: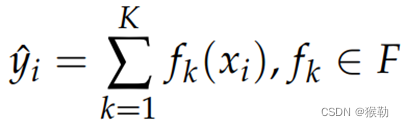
假设有n个训练样本,在第t次迭代后,目标函数转化为: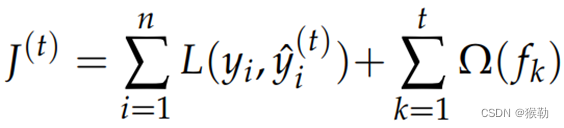
三、结果与讨论
3.1 荧光与样本描述
使用日立F-4600荧光分光光度计进行所有荧光测量。
使用饮用水中经常检测到的3种有机污染物作为测试化合物:苯酚、罗丹明B和水杨酸。
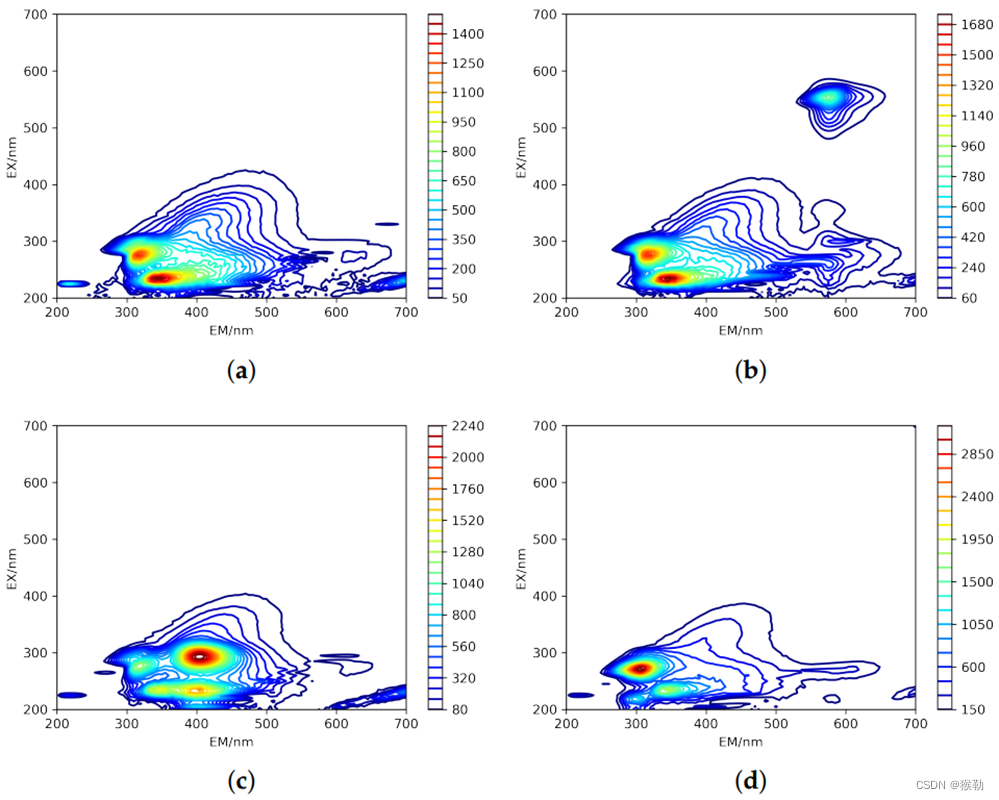
图3:4个样品在预处理后的光谱(饮用水、罗丹明B、水杨酸、苯酚,溶液浓度为20µg/L)。从图中可以读出,罗丹明B的特征峰为545–555/570–580nm,水杨酸的特征峰为290–300/400–410nm。苯酚的特征峰为270–280/305–315,在饮用水的一个特征峰(260–290/280–320)之内。
3.2 基于CAE的光谱特征提取结果
输入100×100的光谱,提取特征,得到特征光谱。它是一个6通道特征图,每个通道的尺寸为13×13。
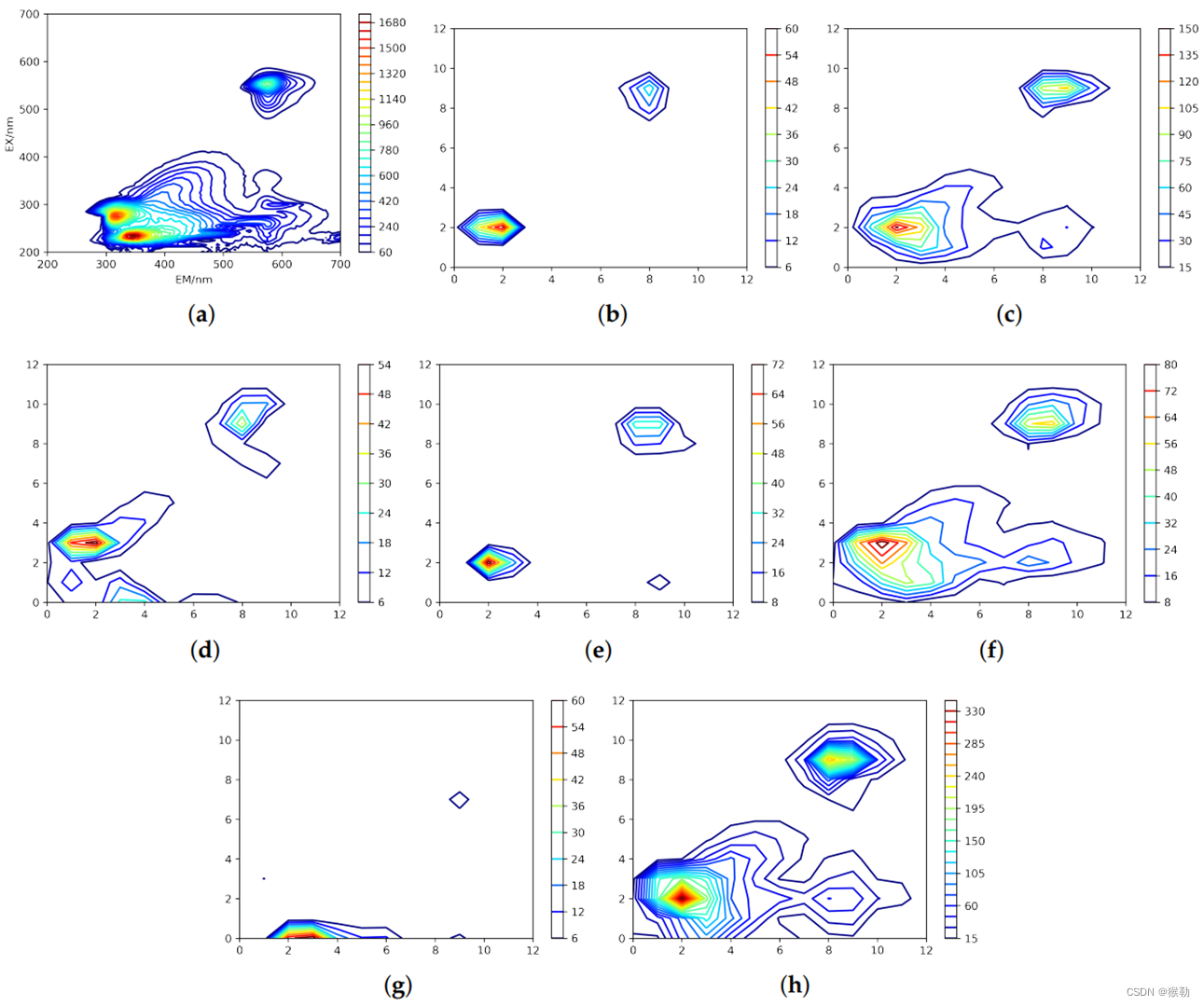
图4:(a)同图3(b),浓度为20µg/L的罗丹明B的光谱。(b)–(g)是6个通道的特征图,(h)是(b)–(g)的叠加结果。结合(a)和图(b)–(h),可以看出CAE在EEM中同时寻找高贡献(点)和纹理特征。
3.3 基于XGBoost的定性识别结果
将浓度高于10µg/L的分析物样品定义为高浓度样品,浓度等于或低于10µg/L的定义为低浓度样品。
3.3.1 饮用水中高浓度有机污染物的检测
表1:高浓度有机污染物检测结果对比,其中RhB代表罗丹明B,SA代表水杨酸。召回率均为100%,说明3种方法都可以正确识别饮用水中高浓度的3种有机物。

图5:使用多路分解方法得到的主要特征向量。从(c)(d)可以看出,一些饮用水样本可能会被误判为含有水杨酸,从而导致假阳性。
| 有机物\方法 | PARAFAC | PCA |
|---|---|---|
| 罗丹明B | (a) | (b) |
| 水杨酸 | © | (d) |
| 苯酚 | (e) | (f) |
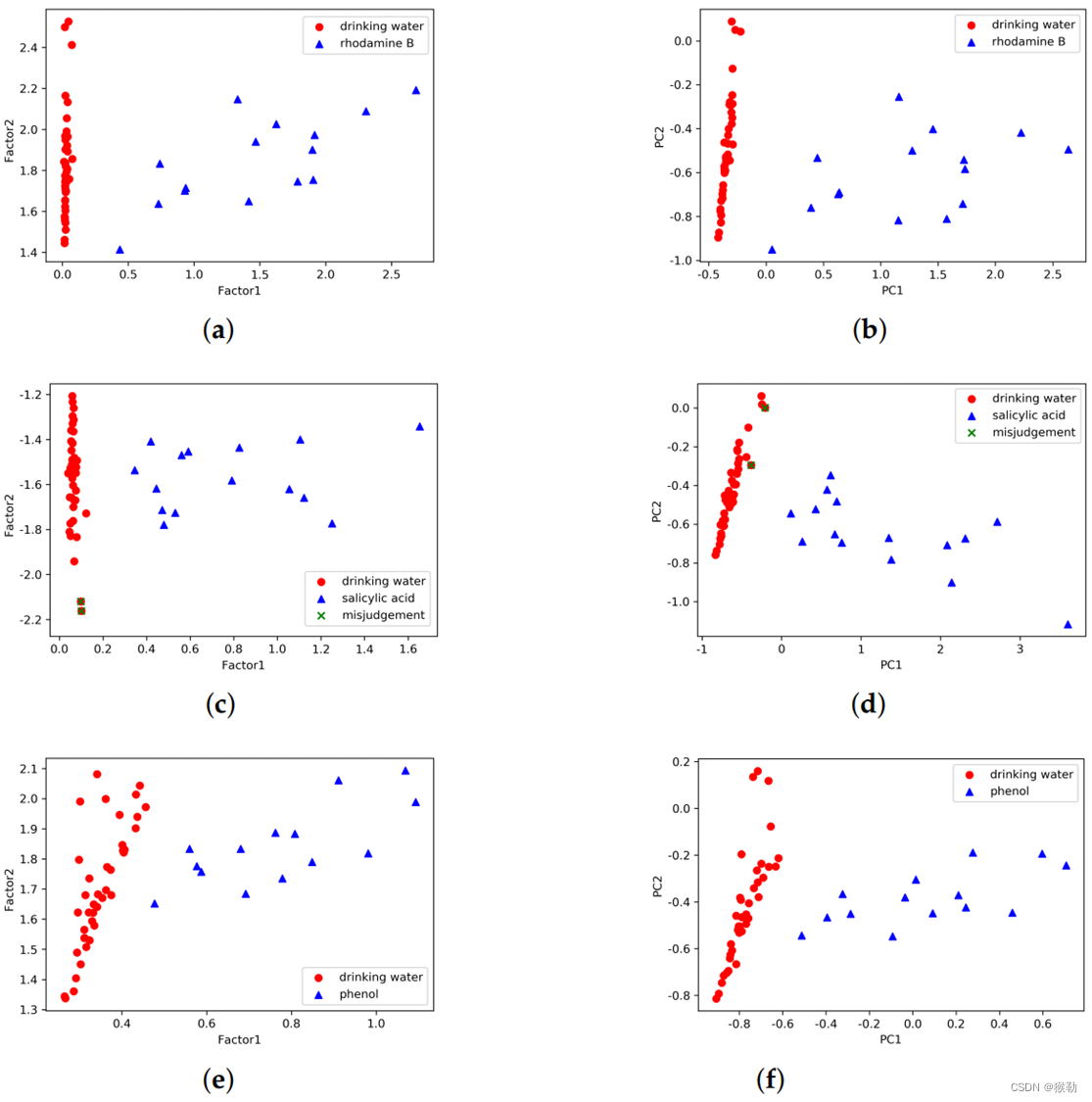
3.3.2 饮用水中低浓度有机污染物的检测
表2:低浓度有机污染物检测结果对比。

图7:使用多种分解方法鉴定低浓度测试样品。对于水杨酸和苯酚,存在假阳性。
| 有机物\方法 | PARAFAC | PCA |
|---|---|---|
| 罗丹明B | (a) | (b) |
| 水杨酸 | © | (d) |
| 苯酚 | (e) | (f) |
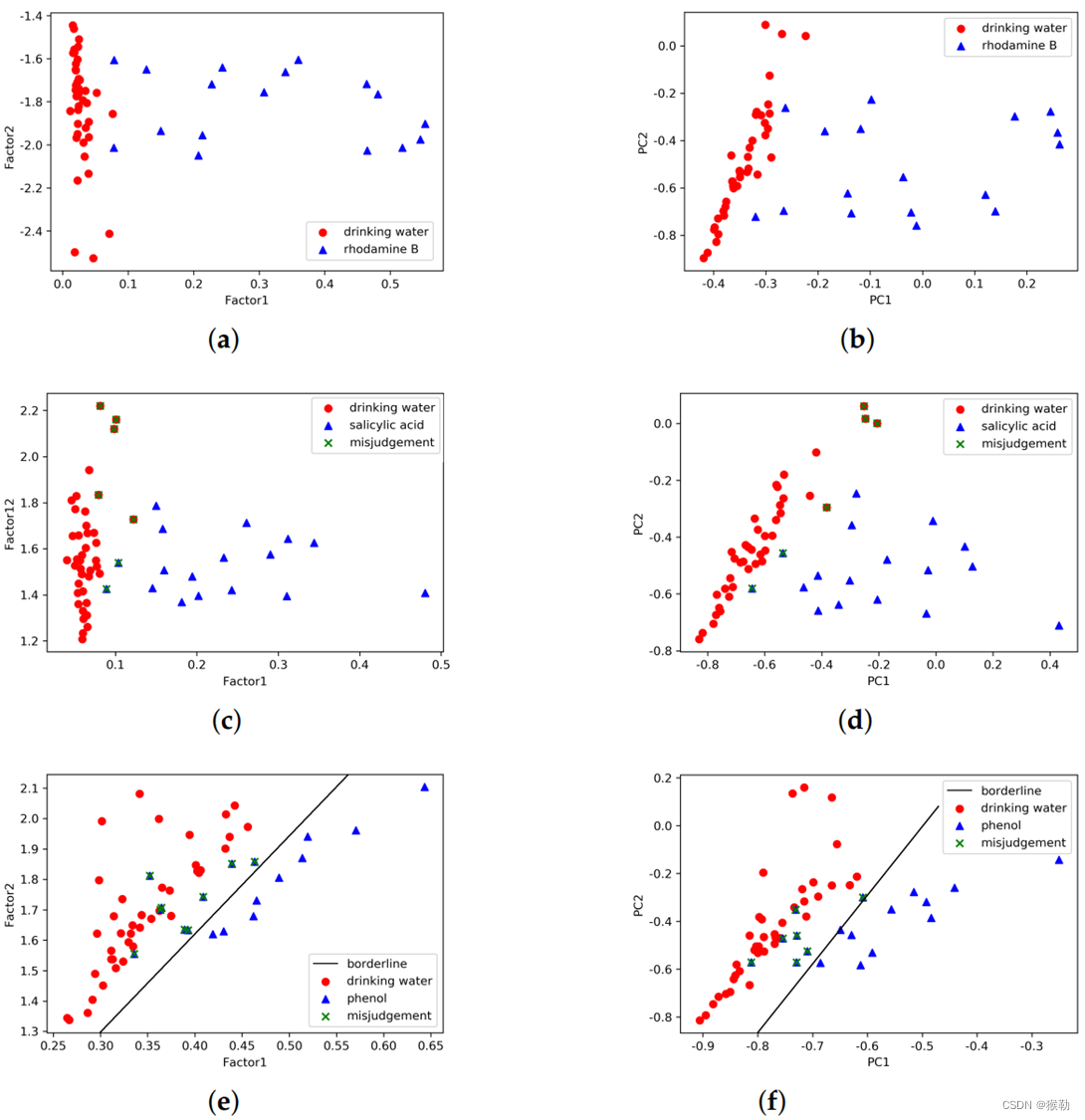
如下图所示,从上下两行的对比可以看出,训练样本的分类边界与测试样本有着显著差异。造成这种结果的主要原因是:多路方法只提取光谱的线性特征,对背景水质的变化不敏感。
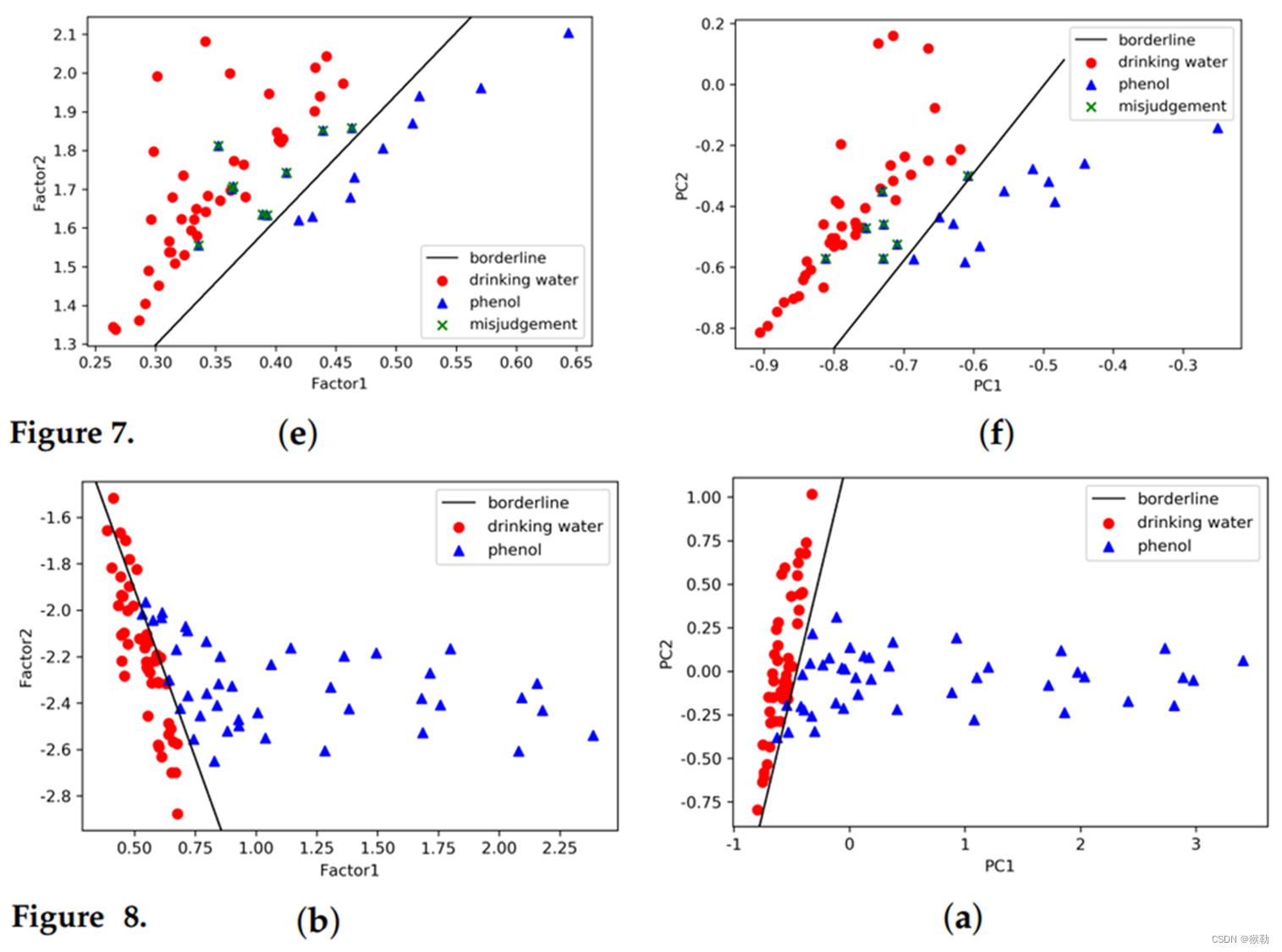
图9:通道4(浓度为4µg/L)的特征光谱。其中a为测试样本,b为饮用水,c为训练样本。a与c的相似度非常高,说明了CAE的有效性。
3.3.3 饮用水背景波动的影响
- 由于受到水处理厂的活动和运输过程中物质的变化的影响,饮用水的质量经常出现波动。
- 在3个月的时间内,以均匀的时间间隔对饮用水进行采样,记录荧光光谱。
图10:其中4个样品的荧光光谱。水质在样品1和2之间以及样品3和4之间仅略有波动,但是在样品2和样品3之间的水质变化剧烈。

接下来,将3个月内采集的200个饮用水样本添加到先前的测试样本中,进行分析。
表3:将饮用水视为污染物的误报率。CAE的误报率均为0。

表4:将污染物视为正常水样的误报率。CAE对苯酚的误报率最低。

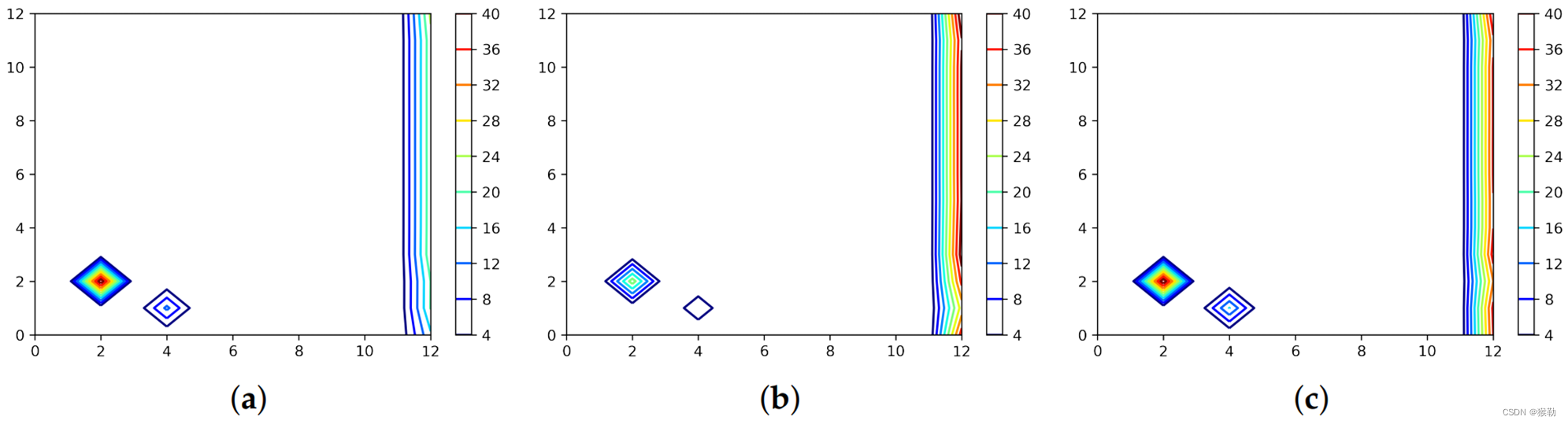
通过查看三种方法在训练和设置样本中提取的特征,进一步研究了原因,如下图所示。
上排:将饮用水误报为苯酚,PARAFAC的误报率达到2%,而PCA的误报率达到14%。
下排:训练集和测试集中饮用水的特征谱。
四、结论
针对饮用水中有机污染物的特征进行分类的问题,本文提出了CAE+XGBoost的新方法,该方法优于传统方法。传统方法在污染物浓度较低时的识别性能较差,且更容易受到干扰。由于CAE可以获取多层卷积特征的并减少信息损失,因此它能够从光谱中收集高贡献(点)和纹理特征,从而获得更好的污染物识别性能。
随着在线光谱仪的快速发展和在线监测站点的快速增加,本文的新方法可以在在线监测和饮用水污染预警系统中得到应用。
相关文章:
论文阅读[121]使用CAE+XGBoost从荧光光谱中检测和识别饮用水中的有机污染物
【论文基本信息】 标题:Detection and Identification of Organic Pollutants in Drinking Water from Fluorescence Spectra Based on Deep Learning Using Convolutional Autoencoder 标题译名:基于使用卷积自动编码器的深度学习,从荧光光谱…...
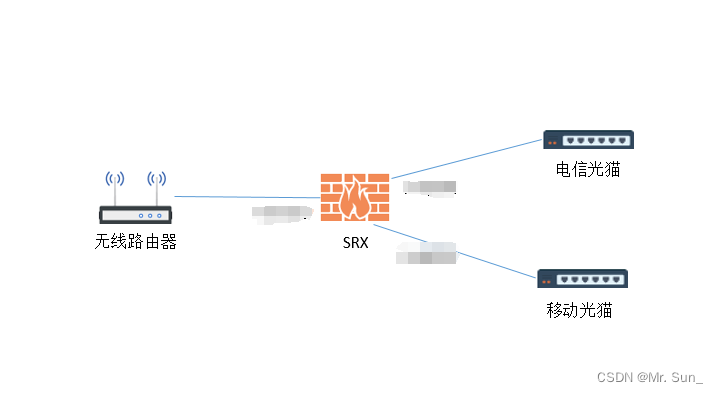
Juniper SRX PPPoE配置
直接上配置脚本 6号口接运营商进行拨号 ---------- set interfaces ge-0/0/6 unit 0 encapsulation ppp-over-ether set interfaces ge-0/0/6 description "Connect_to_Modem" set interfaces pp0 unit 0 pppoe-options underlying-interface ge-0/0/6.0 set inte…...
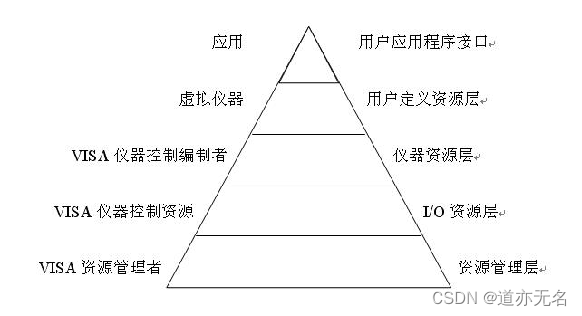
虚拟仪器软件结构VISA
1、什么是VISA VISA是虚拟仪器软件结构(Virtual Instrument Software Architectuere)的简称,是由VXI plug & play系统联盟所统一制定的I/O接口软件标准及其相关规范的总称。一般称这个I/O函数库为VISA库(用于仪器编程的标准I/O函数库)。…...

/etc/init.d/functions: Syntax error: “(“ unexpected (expecting “done“)
一.问题描述: ubuntu系统安装服务时报错: 二.问题解析: Ubuntu安装时默认使用dash,shell脚本命令失败,需要安装bash来运行,长期解决该问题就是重新配置dash 三:问题解决: sudo dpkg-reconfi…...

Google/微端/Amazon/IBM四个厂家在分布式里面提供的服务总结
1.背景 最近在复习分布式的课程,发现总有四家公司——Google/微端/Amazon/IBM绕不过去,而他们又开发了许许多多的服务和架构,需要去记忆,于是乎就整理了一下他们提供的服务 2.Google提供的服务 (1)GFS(Go…...

计网:第一章 概述
目录 1.1计算机网络在信息时代作用 1.2因特网概述 1.3三种交换方式 1.4计算机网络的定义和分类 1.5计算机网络的性能指标 1.6计算机网络的体系结构 基于湖科大教书匠b站计算机网络教学视频以及本校课程老师ppt 整合出的计算机网络学习笔记 根据文章目录,具体内…...

RT-DETR算法优化改进:新颖的多尺度卷积注意力(MSCA),即插即用,助力小目标检测 | NeurIPS2022
💡💡💡本文独家改进: 多尺度卷积注意力(MSCA),有效地提取上下文信息,新颖度高,创新十足。 1)代替RepC3进行使用; 2)MSCAAttention直接作为注意力进行使用; 推荐指数:五星 RT-DETR魔术师专栏介绍: https://blog.csdn.net/m0_63774211/category_12497375.ht…...

基于遗传算法改进的GRNN多输入多输出回归预测,基于多目标遗传算法+GRNN的帕累托前沿求解,基于遗传工具箱调用GRNN模型的多目标求解
目录 背影 遗传算法的原理及步骤 基本定义 编码方式 适应度函数 运算过程 代码 结果分析 展望 完整代码下载链接:grnn多输入多输出训练测试,遗传算法改进grnn神经网络,NSGA-2多目标遗传算法,多目标遗传算法和grnn结合优化资源-CSDN文库 https://download.csdn.net/downloa…...
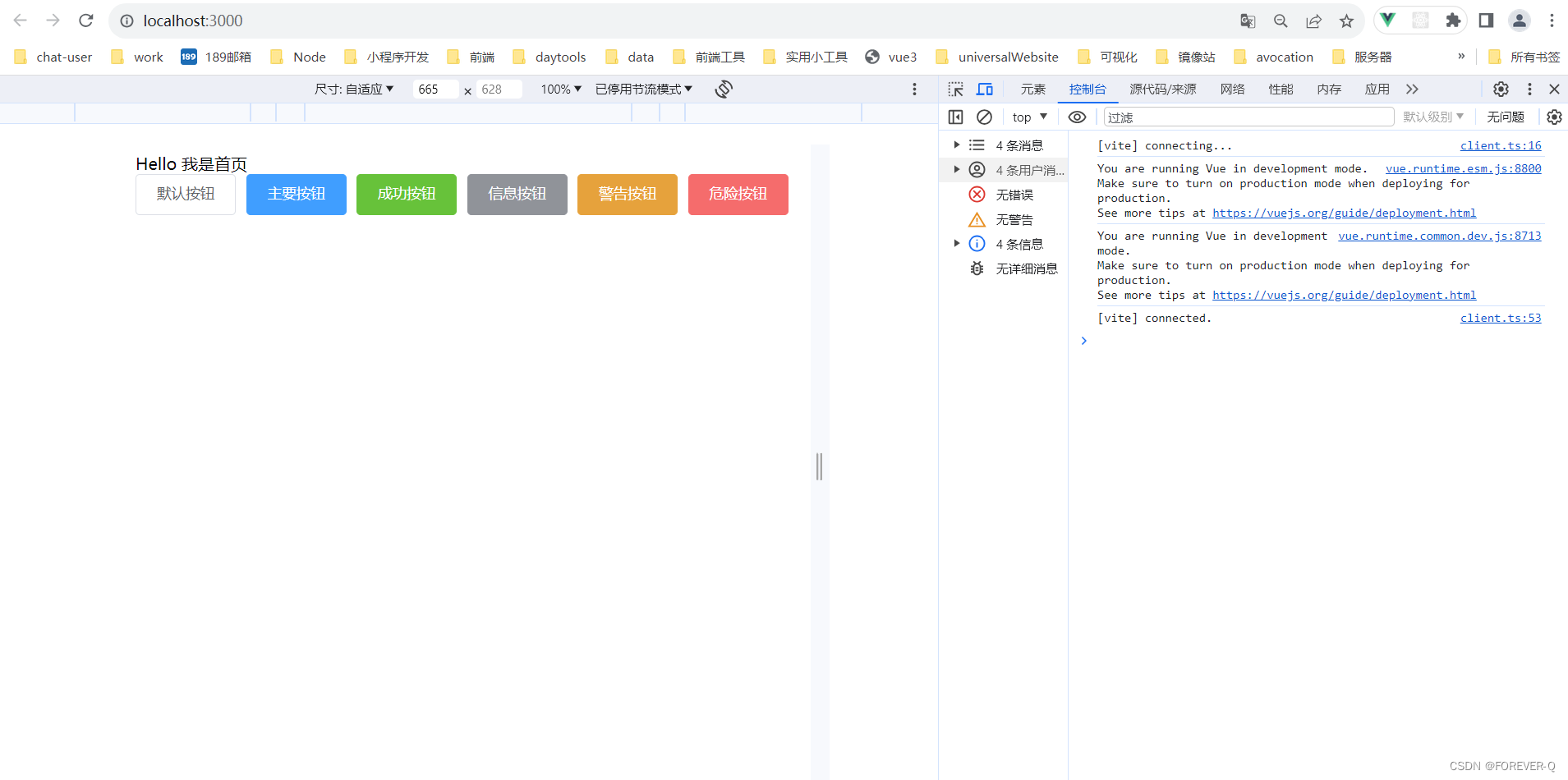
vue2按需导入Element(vite打包)
1.安装element 说明:-S是生产依赖。 npm install element-ui2 -S 2.安装babel-plugin-component 说明:-D是开发模式使用。 npm install babel-plugin-component -D 3. vite.config.js 说明:借助 babel-plugin-component ,我们可…...

力扣117双周赛
第 117 场双周赛 给小朋友们分糖果 I 同T2 给小朋友们分糖果 II 数学 class Solution { public:long long distributeCandies(int n, int limit) {long long ans 0;for (int i 0; i < min(n, limit); i) {if (n - i < limit) {ans n - i 1;} else if (n - i <…...
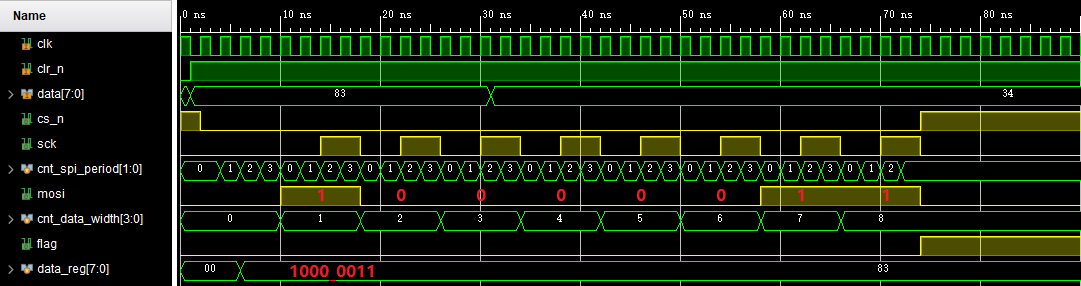
SPI简介及FPGA通用MOSI模块实现
简介 SPI(Serial Peripheral Interface,串行外围设备接口)通讯协议,是Motorola公司提出的一种同步串行接口技术。是一种高速、全双工、同步通信总线。在芯片中只占用四根管脚用来控制及数据传输。 优缺点: SPI通讯协…...

K8S篇之K8S详解
一、K8S简介 k8s全称kubernetes,是为容器服务而生的一个可移植容器的编排管理工具。k8s目前已经主导了云业务流程,推动了微服务架构等热门技术的普及和落地。 k8s是自动化容器操作的开源平台。这些容器操作包括:部署、调度和节点集群间扩展。…...

进博会再现上亿大单 EZZ携手HIC海橙嗨选签署2024年度合作备忘录
正在举行的第六届中国国际进口博览会上,再现上亿大单。11月6日,在澳大利亚新南威尔士州政府代表的见证下,澳交所基因组龙头上市公司EZZ生命科学和中国跨境社交电商龙头HIC海橙嗨选签署2024合作备忘录,在未来的一年,EZZ…...
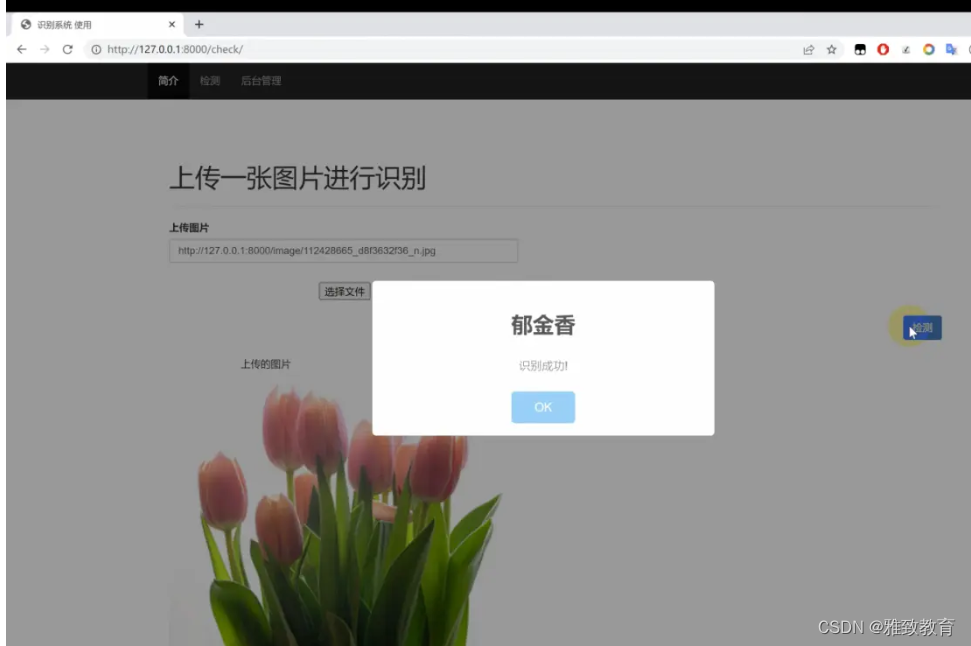
深度学习基于python+TensorFlow+Django的花朵识别系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 花朵识别系统,基于Python实现,深度学习卷积神经网络,通过TensorFlow搭建卷积神经…...
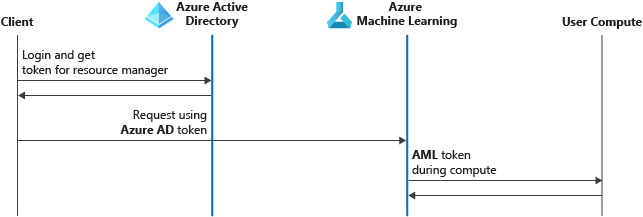
Azure 机器学习 - 机器学习中的企业安全和治理
目录 限制对资源和操作的访问网络安全性和隔离数据加密数据渗透防护漏洞扫描审核和管理合规性 在本文中,你将了解可用于 Azure 机器学习的安全和治理功能。 如果管理员、DevOps 和 MLOps 想要创建符合公司策略的安全配置,那么这些功能对其十分有用。 通过…...

Unity - 各向异性 - 丝绸材质
文章目录 目的环境主观美术效果的[假]丝绸基于物理的方式ProjectPBR filament web captureReferences 目的 拾遗,备份 环境 Unity : 2020.3.37f1 Pipeline : Builtin Rendering Pipeline 主观美术效果的[假]丝绸 非常简单 : half specualr pow(1 - NdotV, _Edg…...
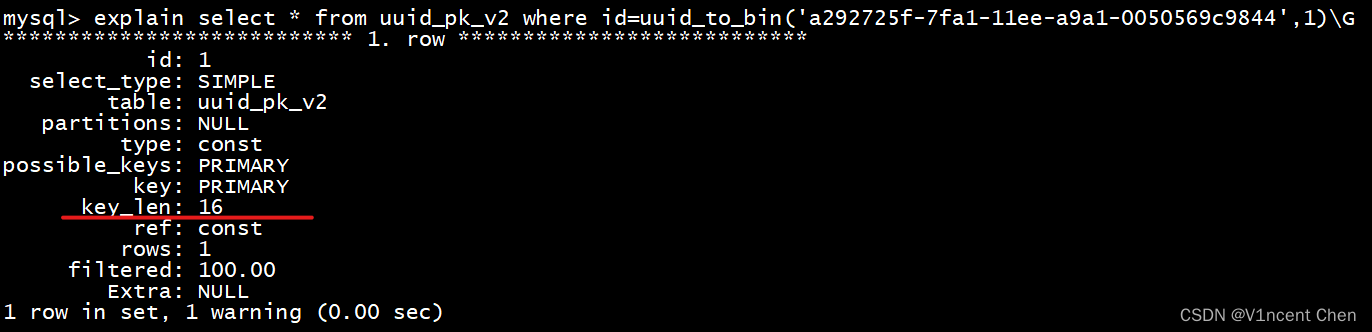
MySQL中UUID主键的优化
UUID(Universally Unique IDentifier 通用唯一标识符),是一种常用的唯一标识符,在MySQL中,可以利用函数uuid()来生产UUID。因为UUID可以唯一标识记录,因此有些场景可能会用来作为表的主键,但直接…...
Python实现WOA智能鲸鱼优化算法优化BP神经网络分类模型(BP神经网络分类算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 鲸鱼优化算法 (whale optimization algorithm,WOA)是 2016 年由澳大利亚格里菲斯大学的Mirjalili 等提…...

Rust语言代码示例
安装Rust语言,然后创建一个新的Rust项目。接下来,你需要安装一个名为"requests"的Rust包,这个包可以帮助你发送请求。然后,你需要安装一个名为"rust-crawler"的Rust包,这个包可以帮助你编写爬虫程…...
【SpringBoot3+Vue3】一【基础篇】
目录 一、Spring Boot概述 1、Spring Boot 特性 1.1 起步依赖 1.2 自动配置 1.3 其他特性 1.3.1 内嵌的Tomcat、Jetty (无需部署WAR文件) 1.3.2 外部化配置 1.3.3 不需要XML配置(properties/yml) 二、Spring Boot入门 1、一个入门程序需求 2、步骤 2.1 创建Maven工…...

SEO原创文章的发布频率应该如何确定
SEO原创文章的发布频率应该如何确定 在当今的互联网时代,搜索引擎优化(SEO)已经成为网站运营的关键环节之一。为了在百度上获得更好的排名,发布高质量的原创文章是必不可少的策略。如何确定SEO原创文章的发布频率,是许…...

SAP ABAP老系统也能玩转REST API?手把手教你用SICF和IF_HTTP_EXTENSION打通接口
SAP ABAP老系统也能玩转REST API?手把手教你用SICF和IF_HTTP_EXTENSION打通接口 在数字化转型浪潮中,许多企业仍运行着历史悠久的SAP ABAP系统。这些系统承载着核心业务逻辑,却常因技术栈陈旧而难以与现代应用生态对接。本文将揭示如何利用AB…...

Guardrails多区域部署终极指南:构建全球LLM安全服务架构
Guardrails多区域部署终极指南:构建全球LLM安全服务架构 【免费下载链接】guardrails Adding guardrails to large language models. 项目地址: https://gitcode.com/gh_mirrors/gu/guardrails 在当今AI应用全球化的浪潮中,如何为大型语言模型&am…...

c++如何读取BMP位图文件并精确提取每个像素点的RGB值【实战】
直接用fread读BMP会错乱因像素数据BGR存储、行末补零对齐且从左下到右上排列;需跳过bfOffBits,按每行字节数对齐读取并反向索引,再手动转为RGB。为什么直接用 fread 读 BMP 文件会得到错乱的 RGB 顺序?BMP 文件头和信息头之后&…...

GeekDoc
GeekDoc 中文系列教程是一个庞大且组织良好的技术文档集合,它并非单一教程,而是一个开源文档翻译与整理项目,旨在将优秀的技术文档和教程翻译成中文,并按技术领域进行分类。其内容广泛覆盖了信息技术领域的多个核心方向࿰…...

信号处理基础:时域与频域分析详解
1. 信号分析的双重视角:时域与频域 作为一名在信号处理领域工作多年的工程师,我经常需要向新人解释时域和频域的关系。简单来说,时域就像观察一个人的日常行为记录,而频域则像是给这个人做了一次全面的体检报告。两者描述的是同一…...

2025届必备的十大AI辅助写作平台解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 现在处于主流地位的AI论文平台数量众多且种类繁杂,这里包含着:DeepSe…...

告别网络依赖:下载、切片、集成,三步构建你的专属高德离线地图库
构建企业级高德离线地图资产库:从瓦片管理到前端集成的工程化实践 在政务、军工、能源等对数据安全性要求极高的领域,或是偏远地区网络条件受限的场景,在线地图服务往往成为系统可靠性的短板。我曾参与某省级政务内网项目的架构设计ÿ…...

开源歌词工具技术解析:跨平台音乐资源整合与高效处理方案
开源歌词工具技术解析:跨平台音乐资源整合与高效处理方案 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 开源歌词工具作为一款专注于音乐资源处理的解决方案…...
》--32.最长的斐波那契子序列的长度,33.最长等差数列,34.等差数列划分II-子序列)
《算法题讲解指南:动态规划算法--子序列问题(附总结)》--32.最长的斐波那契子序列的长度,33.最长等差数列,34.等差数列划分II-子序列
🔥小叶-duck:个人主页 ❄️个人专栏:《Data-Structure-Learning》《C入门到进阶&自我学习过程记录》 《算法题讲解指南》--优选算法 《算法题讲解指南》--递归、搜索与回溯算法 《算法题讲解指南》--动态规划算法 ✨未择之路࿰…...