Mysql Explain工具介绍
使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析查询语句或是结构的性能瓶颈。
准备表
-- 课程表
CREATE TABLE `class` (`id` int(11) NOT NULL,`name` varchar(45) DEFAULT NULL,`update_time` datetime DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `class` (`id`, `name`) VALUES (1,'a'), (2,'b'), (3,'c');-- 学生表
CREATE TABLE `student` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(10) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_name` (`name`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO `student` (`id`, `name`) VALUES (3,'java1'),(1,'java2'),(2,'java3');-- 成绩单CREATE TABLE `student_score` (`id` int(11) NOT NULL,`student_id` int(11) NOT NULL,`class_id` int(11) NOT NULL,`score` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_class_id` (`student_id`,`class_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO `student_score` (`id`, `student_id`, `class_id`,`score`) VALUES (1,1,1,60),(2,1,2,70),(3,2,1,80);
EXPLAIN使用方式
在sql语句前加上explain 指令。
explain select * from `class` where id = 1
结果输出展示:

结果解读
id列
id列的编号是 select 的序列号,有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。
id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。
select_type列
select_type 表示对应行是简单还是复杂的查询。

table列
表示当前这一行正在访问哪张表,如果SQL定义了别名,则展示表的别名
type列
表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。
依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL
一般来说,得保证查询达到range级别,最好达到ref
system
system是const的特例,表里只有一条元组匹配时为system
const
针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const 查询速度非常快, 因为它仅仅读取一次即可
explain select * from `class` where id = 1;
eq_ref
当使用了索引的全部组成部分,并且索引是PRIMARY KEY或UNIQUE NOT NULL 才会使用该类型,最多只会返回一条符合条件的记录。性能仅次于system及const。
explain select * from student_score s left join student on s.student_id = student.id;

ref
当满足索引的最左前缀规则,或者索引不是主键也不是唯一索引时才会发生。相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。如果使用的索引只会匹配到少量的行,性能也是不错的。
explain select * from student where name = 'java';#使用idx_class_id 索引一部分
explain select student_id from student s left join student_score c on s.id = c.student_id;
range
范围扫描,表示检索了指定范围的行,主要用于有限制的索引扫描。比较常见的范围扫描是带有BETWEEN子句或WHERE子句里有>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE、IN()等操作符。
index
扫描全索引就能拿到结果,一般是扫描某个二级索引,这种扫描不会从索引树根节点开始快速查找,而是直接对二级索引的叶子节点遍历和扫描,速度还是比较慢的,这种查询一般为使用覆盖索引,二级索引一般比较小,所以这种通常比ALL快一些。
-
有两种场景会触发:
-
- 如果索引是查询的覆盖索引,并且索引查询的数据就可以满足查询中所需的所有数据,则只扫描索引树。此时,explain的Extra 列的结果是Using index。index通常比ALL快,因为索引的大小通常小于表数据。
- 按索引的顺序来查找数据行,执行了全表扫描。此时,explain的Extra列的结果不会出现Uses index。
ALL
全表扫描,性能最差,扫描你的聚簇索引的所有叶子节点。通常情况下这需要增加索引来进行优化了。
possible_keys列
这一列显示查询可能使用哪些索引来查找。
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。
key列
实际采用哪个索引来优化对该表的访问。
如果没有使用索引,则该列是 NULL。如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用 force index、ignore index。
key_len列
在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
key_len计算规则如下:
字符串,char(n)和varchar(n),5.0.3以后版本中,**n均代表字符数,而不是字节数,**如果是utf-8,一个数字或字母占1个字节,一个汉字占3个字节
char(n):如果存汉字长度就是 3n 字节
varchar(n):如果存汉字则长度是 3n + 2 字节,加的2字节用来存储字符串长度,因为
varchar是变长字符串数值类型
tinyint:1字节
smallint:2字节
int:4字节
bigint:8字节
时间类型
date:3字节timestamp:4字节
datetime:8字节
如果字段允许为 NULL,需要1字节记录是否为 NULL
索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索
引。
ref列
显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名(例:s.id)
rows列
mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
Extra列
这一列展示的是额外信息。
**Using index:**使用覆盖索引
Using where:使用 where 语句来处理结果,并且查询的列未被索引覆盖
Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围;先按条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行。
explain select * from student_score where student_id > 1;

Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
explain select DISTINCT name from class ;
此时会出现Using temporary,如果在name字段上加了索引,就会变成Using index
Using filesort:将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。这种情况下一般也是要考虑使用索引来优化的。
explain select * from class order by name;
Select tables optimized away:使用某些聚合函数(比如 max、min)来访问存在索引的某个字段
explain select min(id) from class ;
相关文章:
Mysql Explain工具介绍
使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析查询语句或是结构的性能瓶颈。 准备表 -- 课程表 CREATE TABLE class (id int(11) NOT NULL,name varchar(45) DEFAULT NULL,update_time datetime DEFAULT NULL,PRIMARY KEY (id)) ENGINEInnoDB DEFAULT CHARSET…...
Linux系统中的静态库和共享库,以及一些计算机的基础知识
目录 1.库文件 2.静态库 3.共享库 4.静态库与共享库的区别 5.计算机基础知识 6.进程的基础知识 7.主函数的三个参数 1.库文件 1).库文件库是一组预先编译好的方法的集合;Linux系统存储库的位置一般在/lib 和 /usr/lib (64位系统/usr/lib64)库的头文件放在/usr/include 2…...

商品管理图片更换实现
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.java1234.mapper.ProductMa…...

SDL2 加载图片
1.简介 在SDL中,本身只支持加载BMP格式的图片SDL_LoadBMP,如果想要加载别的格式图片,需要编译SDL_image库。 SDL_image库中IMG_Load和都是IMG_LoadTexture用于加载图片的函数,但是它们的使用方式和返回值有所不同。 IMG_Load和…...
监控和数据采集软件架构和详细设计
介绍 监控和数据采集软件通过提供实时监控、数据收集和分析功能,在各个行业中发挥着至关重要的作用。这些软件应用程序可帮助企业收集有价值的见解、优化流程并做出明智的决策。在本文中,我们将探讨监测和数据采集软件的软件架构、编程技术和详细设计规范…...

链动2+1模式系统开发之区域代理深度解析
区域代理的保护机制:在链动商城系统里设定的代理有唯一性,每个省只有一个省代,每个市只有一个市代,每个区县只有一个区县代。这样也是保护每个代理的收益权益。 区域代理包含的权益类别:购物奖励折扣;区域实…...

Amazon Bedrock | 大语言模型CLAUDE 2体验
这场生成式AI与大语言模型的饥饿游戏,亚马逊云科技也参与了进来。2023年,亚马逊云科技正式发布了 Amazon Bedrock,是客户使用基础模型构建和扩展生成式AI应用程序的最简单方法,为所有开发者降低使用门槛。在 Bedrock 上࿰…...

通讯协议学习之路(实践部分):IIC开发实践
通讯协议之路主要分为两部分,第一部分从理论上面讲解各类协议的通讯原理以及通讯格式,第二部分从具体运用上讲解各类通讯协议的具体应用方法。 后续文章会同时发表在个人博客(jason1016.club)、CSDN;视频会发布在bilibili(UID:399951374) 本文…...
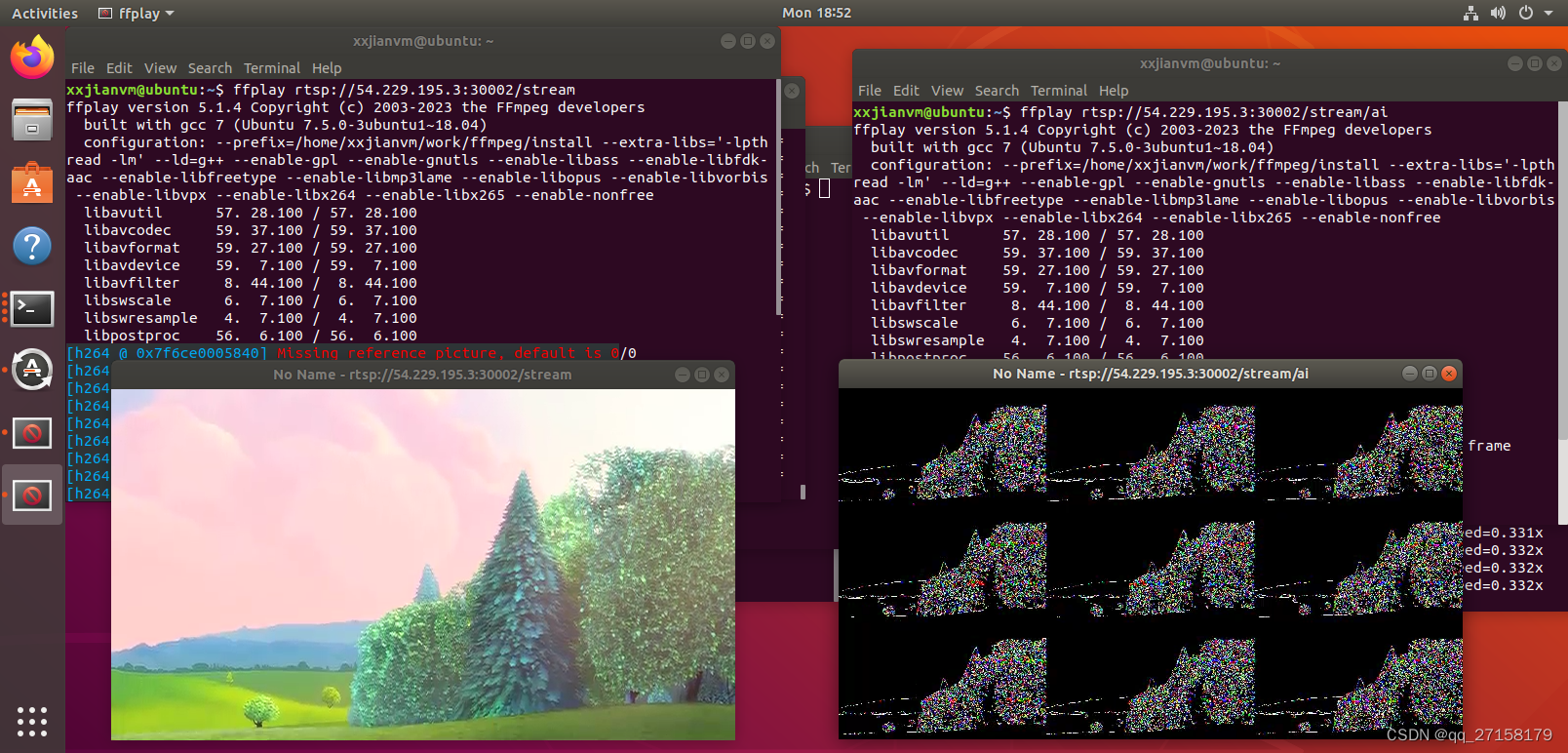
『亚马逊云科技产品测评』活动征文|搭建带有“弱”图像处理功能的流媒体服务器
授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 Developer Centre, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道。 本文基于以下软硬件工具: aws ec2 frp-0.52.3 mediamtx-1.3…...
正交矩阵的定义
对于n阶矩阵A,如果,其中为单位矩阵,为A的转置矩阵,那么就称A为正交矩阵。 对于正交矩阵, 对于正交矩阵,其列向量都是单位向量,行向量都是单位向量...

K8S集群etcd 某个节点数据不一致如何修复 —— 筑梦之路
背景说明 二进制方式安装的k8s集群,etcd集群有3个节点,某天有一台机器hang住了,无法远程ssh登陆,于是被管理员直接重启了,重启后发现k8s集群删除一个deployment应用,多次刷新一会有,一会没有&am…...

selenium/webdriver运行原理与机制
最近在看一些底层的东西。driver翻译过来是驱动,司机的意思。如果将webdriver比做成司机,竟然非常恰当。 我们可以把WebDriver驱动浏览器类比成出租车司机开出租车。在开出租车时有三个角色: 乘客:他/她告诉出租车司机去哪里&a…...
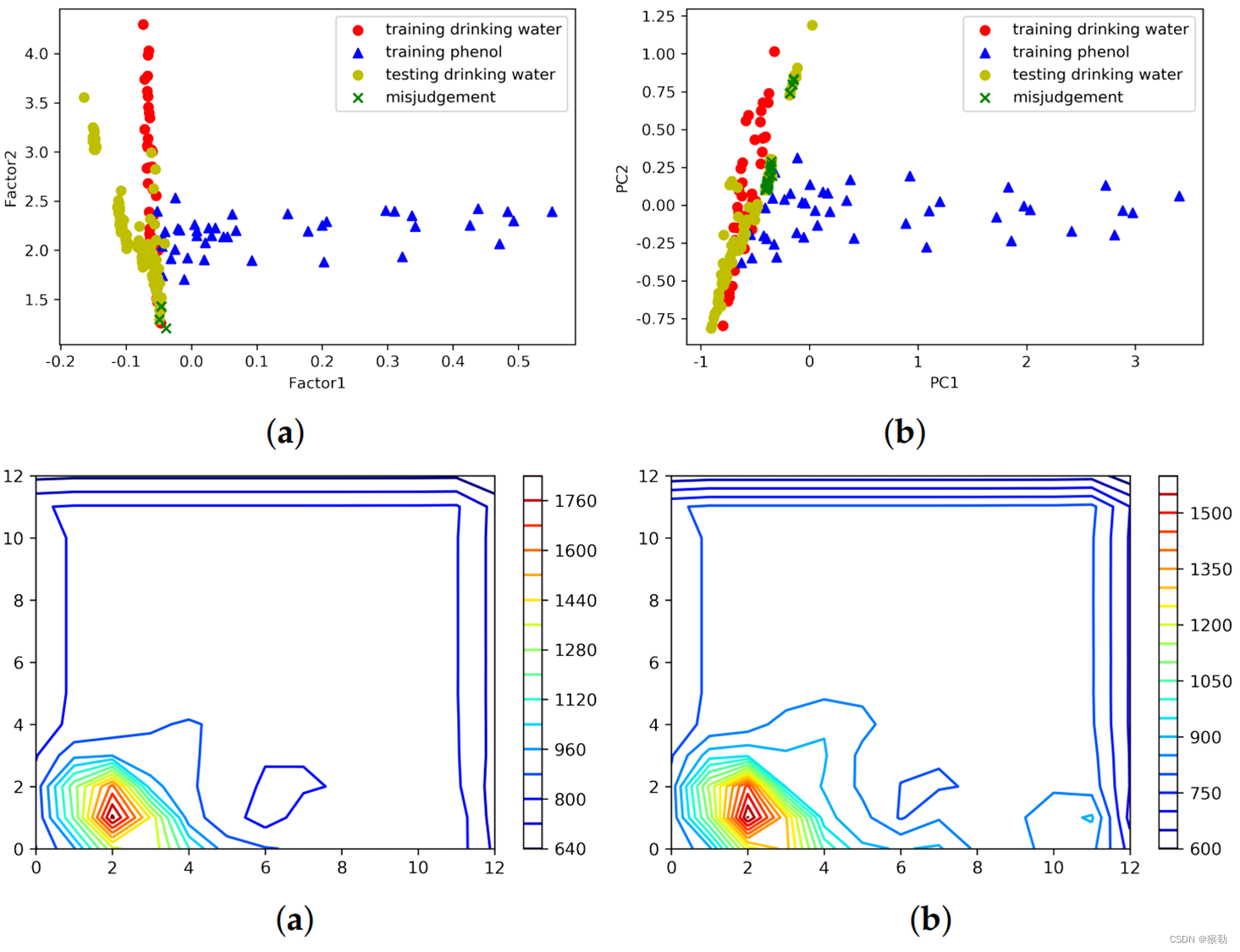
论文阅读[121]使用CAE+XGBoost从荧光光谱中检测和识别饮用水中的有机污染物
【论文基本信息】 标题:Detection and Identification of Organic Pollutants in Drinking Water from Fluorescence Spectra Based on Deep Learning Using Convolutional Autoencoder 标题译名:基于使用卷积自动编码器的深度学习,从荧光光谱…...
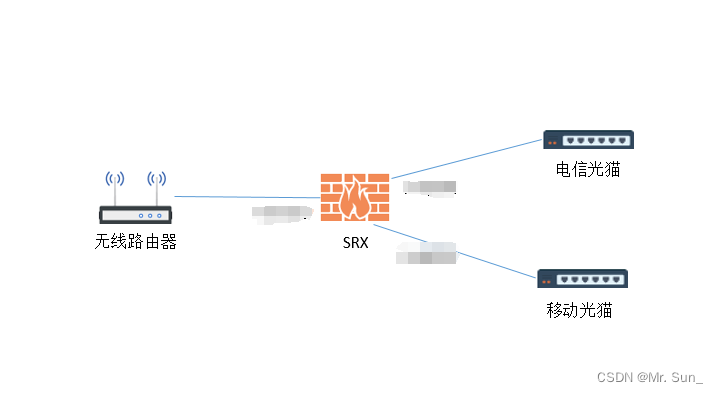
Juniper SRX PPPoE配置
直接上配置脚本 6号口接运营商进行拨号 ---------- set interfaces ge-0/0/6 unit 0 encapsulation ppp-over-ether set interfaces ge-0/0/6 description "Connect_to_Modem" set interfaces pp0 unit 0 pppoe-options underlying-interface ge-0/0/6.0 set inte…...
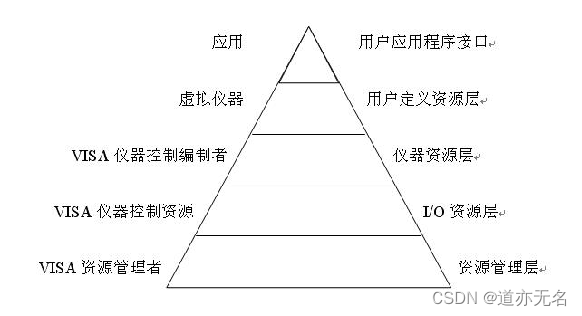
虚拟仪器软件结构VISA
1、什么是VISA VISA是虚拟仪器软件结构(Virtual Instrument Software Architectuere)的简称,是由VXI plug & play系统联盟所统一制定的I/O接口软件标准及其相关规范的总称。一般称这个I/O函数库为VISA库(用于仪器编程的标准I/O函数库)。…...

/etc/init.d/functions: Syntax error: “(“ unexpected (expecting “done“)
一.问题描述: ubuntu系统安装服务时报错: 二.问题解析: Ubuntu安装时默认使用dash,shell脚本命令失败,需要安装bash来运行,长期解决该问题就是重新配置dash 三:问题解决: sudo dpkg-reconfi…...

Google/微端/Amazon/IBM四个厂家在分布式里面提供的服务总结
1.背景 最近在复习分布式的课程,发现总有四家公司——Google/微端/Amazon/IBM绕不过去,而他们又开发了许许多多的服务和架构,需要去记忆,于是乎就整理了一下他们提供的服务 2.Google提供的服务 (1)GFS(Go…...

计网:第一章 概述
目录 1.1计算机网络在信息时代作用 1.2因特网概述 1.3三种交换方式 1.4计算机网络的定义和分类 1.5计算机网络的性能指标 1.6计算机网络的体系结构 基于湖科大教书匠b站计算机网络教学视频以及本校课程老师ppt 整合出的计算机网络学习笔记 根据文章目录,具体内…...

RT-DETR算法优化改进:新颖的多尺度卷积注意力(MSCA),即插即用,助力小目标检测 | NeurIPS2022
💡💡💡本文独家改进: 多尺度卷积注意力(MSCA),有效地提取上下文信息,新颖度高,创新十足。 1)代替RepC3进行使用; 2)MSCAAttention直接作为注意力进行使用; 推荐指数:五星 RT-DETR魔术师专栏介绍: https://blog.csdn.net/m0_63774211/category_12497375.ht…...

基于遗传算法改进的GRNN多输入多输出回归预测,基于多目标遗传算法+GRNN的帕累托前沿求解,基于遗传工具箱调用GRNN模型的多目标求解
目录 背影 遗传算法的原理及步骤 基本定义 编码方式 适应度函数 运算过程 代码 结果分析 展望 完整代码下载链接:grnn多输入多输出训练测试,遗传算法改进grnn神经网络,NSGA-2多目标遗传算法,多目标遗传算法和grnn结合优化资源-CSDN文库 https://download.csdn.net/downloa…...

html 列表和表格的使用
1:列表是以结构化,易读性更强的方式提供信息的方法,我们学习了有序列表和无序列表。有序列表特点是有先后顺序,用数字,字母或数字标记,适合步骤,排名,流程,核心标签<o…...

终极指南:如何利用HTTPS-PORTAL与Docker Gen实现自动HTTPS配置的魔法
终极指南:如何利用HTTPS-PORTAL与Docker Gen实现自动HTTPS配置的魔法 【免费下载链接】https-portal A fully automated HTTPS server powered by Nginx, Lets Encrypt and Docker. 项目地址: https://gitcode.com/gh_mirrors/ht/https-portal HTTPS-PORTAL是…...

嵌入式Linux网络状态检测方案与优化实践
1. 嵌入式设备网络状态检测实战指南 在嵌入式Linux开发中,网络连接状态的实时监测是个常见但容易被忽视的需求。想象一下,你正在开发一个智能家居网关,突然Wi-Fi断了,但设备还在傻乎乎地发送数据;或者工业现场的设备&a…...

OpenClaw开源贡献:为Qwen3.5-9B-AWQ-4bit开发社区技能
OpenClaw开源贡献:为Qwen3.5-9B-AWQ-4bit开发社区技能 1. 为什么选择为OpenClaw开发技能? 去年冬天,当我第一次在本地部署OpenClaw时,就被它的设计理念所吸引——一个真正能在个人电脑上运行的AI智能体框架。但很快我发现&#…...

PyAutoGUI实战指南:从基础操作到自动化脚本编写
1. PyAutoGUI入门:解放双手的自动化神器 每次看到同事在电脑前重复点击几百次鼠标时,我都想冲过去安利PyAutoGUI。这个Python库能让你用代码控制鼠标键盘,把枯燥的机械操作变成一键运行的脚本。上周我帮财务部写了个自动填报表的脚本…...

Hydra使用教程
Hydra(全称THC-Hydra)是一款由THC(The Hacker’s Choice)开发的经典暴力破解工具,也是Kali Linux中最常用的凭据攻击工具之一。其核心功能是通过字典攻击或暴力猜测的方式,对多种网络服务的登录凭据&#x…...

STM32串口通信优化:环形队列防数据丢失方案
1. STM32 串口数据接收的痛点与环形队列解决方案在嵌入式开发中,串口通信是最基础也最常用的外设之一。但新手常会遇到这样的问题:当大量数据快速涌入时,传统的串口接收方式很容易丢失数据。我曾经在一个工业传感器项目中就吃过这个亏——传感…...


如何高效使用付费墙绕过工具:Chrome扩展的完整实践指南
如何高效使用付费墙绕过工具:Chrome扩展的完整实践指南 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在信息获取日益重要的今天,付费墙成为许多用户访问优质…...

MySQL常用命令速查手册,用户权限控制功能实现说明。
MySQL常用命令全攻略 连接与退出MySQL 通过命令行连接到MySQL服务器: mysql -u username -p系统会提示输入密码。 退出MySQL命令行界面: exit;或使用快捷键 Ctrl D。 数据库操作 创建新数据库: CREATE DATABASE database_name;查看所有数据库…...