在报错中学python something
这里写目录标题
- 动手学深度学习pandas完整代码
- 数据处理
- TypeError: can only concatenate str (not "int") to str(fillna填补缺失值)
- 创建文件夹
- 学习这个数据分组
- get_dummies实现one hot encode
动手学深度学习pandas完整代码
import osimport numpy as np
import pandas as pd
import torch
from numpy import nan as NaNos.makedirs(os.path.join('..', 'data'), exist_ok=True) # 在上级目录创建data文件夹
datafile = os.path.join('..', 'data', 'house_tiny.csv') # 创建文件
with open(datafile, 'w') as f: # 往文件中写数据f.write('NumRooms,Alley,Price\n') # 列名f.write('NA,Pave,127500\n') # 第1行的值f.write('2,NA,106000\n') # 第2行的值f.write('4,NA,178100\n') # 第3行的值f.write('NA,NA,140000\n') # 第4行的值data = pd.read_csv(datafile) # 可以看到原始表格中的空值NA被识别成了NaN
print('1.原始数据:\n', data)inputs, outputs = data.iloc[:, 0: 2], data.iloc[:, 2]
# inputs = inputs.fillna(inputs.mean()) # 用均值填充NaN
# inputs = inputs.fillna(66) # 用均值填充NaN
#在mean()括号里面加入numeric_only=Ture
inputs = inputs.fillna(inputs.mean(numeric_only=True))
print(inputs)
print(outputs)
# 利用pandas中的get_dummies函数来处理离散值或者类别值。
# [对于 inputs 中的类别值或离散值,我们将 “NaN” 视为一个类别。] 由于 “Alley”列只接受两种类型的类别值 “Pave” 和 “NaN”
inputs = pd.get_dummies(inputs, dummy_na=True)
print('2.利用pandas中的get_dummies函数处理:\n', inputs)# x, y = torch.tensor(inputs.values), torch.tensor(outputs.values)报错!!!x = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
print('3.转换为张量:')
print(x)
print(y)# 扩展填充函数fillna的用法
df1 = pd.DataFrame([[1, 2, 3], [NaN, NaN, 2], [NaN, NaN, NaN], [8, 8, NaN]]) # 创建初始数据
print('4.函数fillna的用法:')
print(df1)
print(df1.fillna(100)) # 用常数填充 ,默认不会修改原对象
print(df1.fillna({0: 10, 1: 20, 2: 30})) # 通过字典填充不同的常数,默认不会修改原对象
print(df1.fillna(method='ffill')) # 用前面的值来填充
# print(df1.fillna(0, inplace=True)) # inplace= True直接修改原对象df2 = pd.DataFrame(np.random.randint(0, 10, (5, 5))) # 随机创建一个5*5
df2.iloc[1:4, 3] = NaN
df2.iloc[2:4, 4] = NaN # 指定的索引处插入值
print(df2)
print(df2.fillna(method='bfill', limit=2)) # 限制填充个数
print(df2.fillna(method="ffill", limit=1, axis=1)) #
数据处理
TypeError: can only concatenate str (not “int”) to str(fillna填补缺失值)
不能让字符串 和int 值 连接
这里报错不是简单的连接,是因为mean函数的,求mean的对象中有整数也有字符串
解决方法
#在mean()括号里面加入numeric_only=Ture
inputs = inputs.fillna(inputs.mean(numeric_only=True))
import osimport numpy as np
import pandas as pd
import torch
from numpy import nan as NaNos.makedirs(os.path.join('..', 'data'), exist_ok=True) # 在上级目录创建data文件夹
datafile = os.path.join('..', 'data', 'house_tiny.csv') # 创建文件
with open(datafile, 'w') as f: # 往文件中写数据f.write('NumRooms,Alley,Price\n') # 列名f.write('NA,Pave,127500\n') # 第1行的值f.write('2,NA,106000\n') # 第2行的值f.write('4,NA,178100\n') # 第3行的值f.write('NA,NA,140000\n') # 第4行的值data = pd.read_csv(datafile) # 可以看到原始表格中的空值NA被识别成了NaN
print('1.原始数据:\n', data)inputs, outputs = data.iloc[:, 0: 2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean()) # 用均值填充NaN
print(inputs)
print(outputs)

创建文件夹
在上级目录创建data文件夹,记得找到上级目录的data再删
os.makedirs(os.path.join('..', 'data'), exist_ok=True) # 在上级目录创建data文件夹
datafile = os.path.join('..', 'data', 'house_tiny.csv') # 创建文件
1.1 os.makedirs(path, mode=0o777) 方法:用于递归创建目录。
path – 需要递归创建的目录,可以是相对或者绝对路径。。
mode – 权限模式。
无返回值
1.2 os.path.join()函数:连接两个或更多的路径名组件
- 如果各组件名首字母不包含’/’,则函数会自动加上
- 如果有一个组件是一个绝对路径,则在它之前的所有组件均会被舍弃
- 如果最后一个组件为空,则生成的路径以一个’/’分隔符结尾
学习这个数据分组
get_dummies实现one hot encode
get_dummies方法可以把把 离散的类别信息转化为onehot编码形式,
dummy_na=True意为是否把nan单独看做一个类别。
get_dummies
是利用pandas实现one hot encode的方式
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False) import pandas as pd
df = pd.DataFrame([ ['green' , 'A'], ['red' , 'B'], ['blue' , 'A']]) df.columns = ['color', 'class']
pd.get_dummies(df) 
对每个类别的值都进行0-1编码
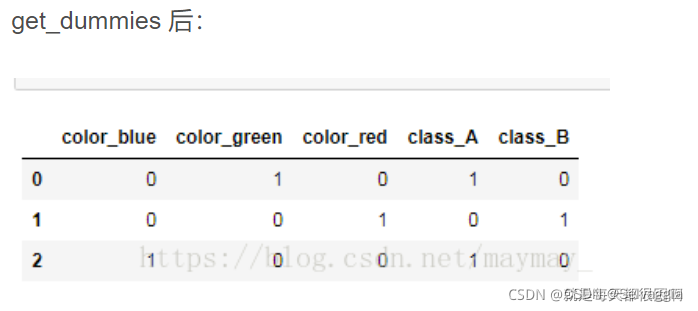
上述执行完以后再打印df 出来的还是get_dummies 前的图,因为你没有写,赋值
df = pd.get_dummies(df)
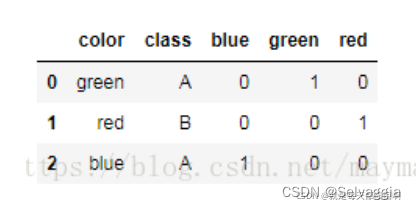
可以对指定列进行get_dummies
pd.get_dummies(df.color)

将指定列进行get_dummies 后合并到元数据中
df = df.join(pd.get_dummies(df.color))
相关文章:
在报错中学python something
这里写目录标题 动手学深度学习pandas完整代码数据处理TypeError: can only concatenate str (not "int") to str(fillna填补缺失值) 创建文件夹学习这个数据分组get_dummies实现one hot encode 动手学深度学习pandas完整代码 import osimpor…...

如何调用 DBMS_DISKGROUP 对 ASM 文件进行随机读取
目录 一、概述 二、实现思路与注意点 三、Java Demo 1、直接调用 2、读写异步 一、概述 对于 Oracle Rac 环境下,数据文件大多默认存放在 ASM 共享存储上,当我们需要读取 ASM 上存储的数据文件时可以使用 Oracle 提供的一些方法,比如 ASMCMD CP。但是,对于一些备份场景…...

UART学习
uart.c #include "stm32mp1xx_gpio.h" #include "stm32mp1xx_uart.h" // UART4_TX : PG11 AF6 // UART4_RX : PB2 AF8 void __uart_init() {// GPIOB2 设置为复用功能GPIOB->MODER & (~(0x3 << 4));GPIOB->MODER | (0x2 << 4);G…...

洗地机哪个牌子最好用?洗地机品牌排行榜
近年来,洗地机相当热门,洗地机结合了扫地拖地吸地为一体的多功能清洁工具,让我们告别了传统方式打扫卫生,让我们清洁不再费劲,可是市面上的洗地机五花八门,怎么挑选到一个洗地机也是一个问题,下…...
国际阿里云:Windows实例中数据恢复教程!!!
在处理磁盘相关问题时,您可能会碰到操作系统中数据盘分区丢失的情况。本文介绍了Windows系统下常见的数据盘分区丢失的问题以及对应的处理方法,同时提供了使用云盘的常见误区以及最佳实践,避免可能的数据丢失风险。 前提条件 已注册阿里云账…...

浅谈二叉树
✏️✏️✏️今天给大家分享一下二叉树的基本概念以及性质、二叉树的自定义实现,二叉树的遍历等。 清风的CSDN博客 😛😛😛希望我的文章能对你有所帮助,有不足的地方还请各位看官多多指教,大家一起学习交流&…...
 用QWebSocket 实现服务端和客户端(详细代码直接使用))
(二) 用QWebSocket 实现服务端和客户端(详细代码直接使用)
目录 前言 一、服务器的代码: 1、服务器的思路 2、具体服务器的代码示例 二、客户端的代码: 1、客户端的思路(和服务器类似) 2、具体客户端的代码示例 前言 要是想了解QWebSocket的详细知识,还得移步到上一篇文…...

关于我在配置zookeeper出现,启动成功,进程存在,但是查看状态却没有出现Mode:xxxxx的问题和我的解决方案
在我输入:zkServer.sh status 之后出现报错码. 报错码: ZooKeeper JMX enabled by default Using config: /opt/software/zookeeper/bin/../conf/zoo.cfgClient port found: 2181. Client address: localhost. Error contacting service. It is probably not runni…...

react及相关面试问题汇总
目录 1、什么是React?它的特点是什么? 2、解释一下虚拟DOM(Virtual DOM)的概念以及它的工作原理。 3、什么是组件(Component)?如何定义一个React组件? 4、什么是JSX?它与HTML的区别是什么?如何在React中…...

QT4到QT5移植出现的一些问题
转自:QT4到QT5移植出现的一些问题_西门子3gl qt5 许可证-CSDN博客 在上述作者基础上修改: 一、问题1:头文件的问题 1、QtGui/QApplication: No such file or directory 1.1错因 原因是Qt5源文件位置的改动 1.2解决 pro文件里࿰…...
【可解释AI】Alibi explain: 解释机器学习模型的算法
Alibi explain: 解释机器学习模型的算法 可解释人工智能简介Alibi特点算法Library设计展望参考资料 今天介绍Alibi Explain,一个开源Python库,用于解释机器学习模型的预测(https://github.com/SeldonIO/alibi)。该库具有最先进的分类和回归模型可解释性算…...

No191.精选前端面试题,享受每天的挑战和学习
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...

ROS基础—vscode创建工作空间
1、创建ROS工作空间 首先打开ubuntu的终端,接着依次输入如下的命令行; mkdir -p xxx_ws/src(必须得有 src) cd xxx_ws catkin_make当然我一般是新建一个叫做demo的工作空间,如 mkdir -p demo04_ws/src 2、启动vscode cd xxx_ws code . …...
)
机器学习复习(待更新)
01绪论 (1)机器学习基本分类: 监督学习(有标签)半监督学习(部分标签,找数据结构)无监督学习(无标签,找数据结构)强化学习(不断交互&…...
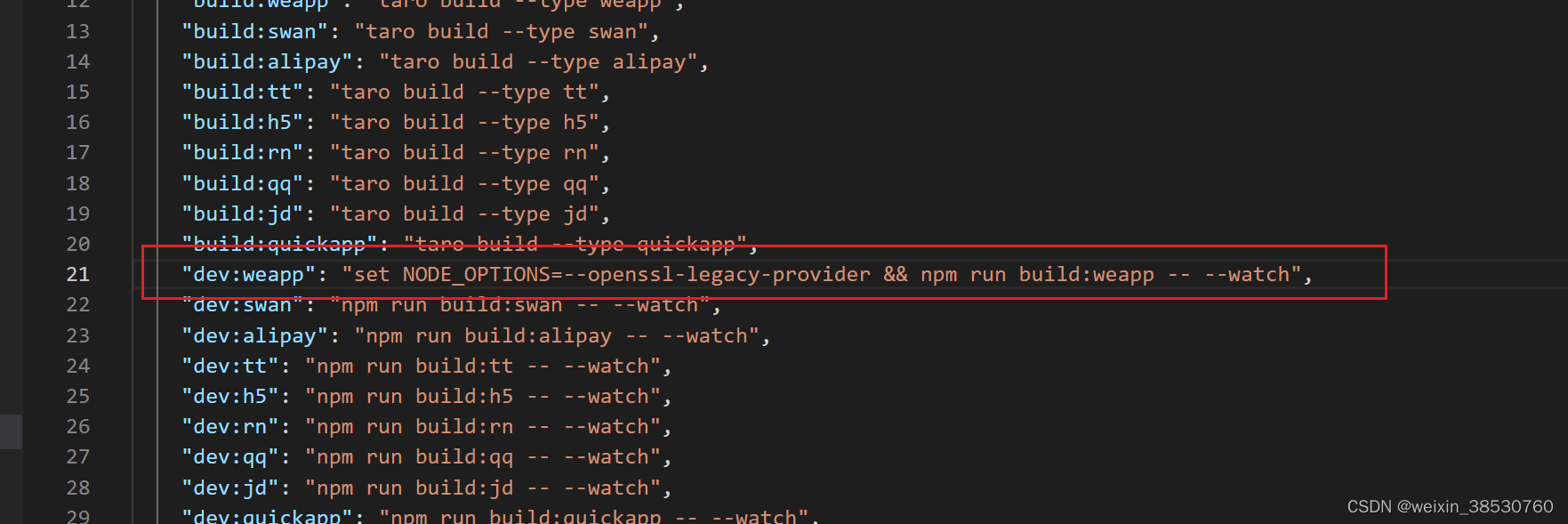
taro(踩坑) npm run dev:weapp 微信小程序开发者工具预览报错
控制台报错信息: VM72:9 app.js错误: Error: module vendors-node_modules_taro_weapp_prebundle_chunk-JUEIR267_js.js is not defined, require args is ./vendors-node_modules_taro_weapp_prebundle_chunk-JUEIR267_js.js 环境: node 版本&#x…...

3. 深度学习——损失函数
机器学习面试题汇总与解析——损失函数 本章讲解知识点 什么是损失函数?为什么要使用损失函数?详细讲解损失函数本专栏适合于Python已经入门的学生或人士,有一定的编程基础。 本专栏适合于算法工程师、机器学习、图像处理求职的学生或人士。 本专栏针对面试题答案进行了优化…...

交叉编译 openssl
要在 x86 平台上编译适用于 aarch64 架构的 OpenSSL 动态库,你需要使用交叉编译工具链。可以按照以下步骤进行: 安装 aarch64 交叉编译工具链: $ sudo apt-get install gcc-aarch64-linux-gnu g-aarch64-linux-gnu 这将安装 aarch64 交叉编…...

C++文件的读取和写入
1、C对txt文件的读,ios::in #include<iostream> #include<fstream> using namespace std;int main() {ifstream ifs;ifs.open("test.txt",ios::in);if(!ifs.is_open()){cout<<"打开文件失败!"<<endl;}char…...

住宅IP、家庭宽带IP以及原生IP,它们有什么区别?谷歌开发者账号应选择哪种IP?
IP地址(Internet Protocol Address)是互联网协议地址的简称,是互联网通信的基础,互联网上每一个网络设备的唯一标识符每个在线的设备都需要一个IP地址,这样才能在网络中找到它们并进行数据交换。 IP地址有很多种类型&…...
--内存管理之I/O交换与性能调优)
Linux内核分析(十三)--内存管理之I/O交换与性能调优
目录 一、引言 二、page cache ------>2.1、file-backed ------>2.2、匿名页(Anonymous page) ------>2.3、读写方式 ------>2.4、常驻内存 三、页面回收 ------>3.1、LRU算法 ------>3.2、嵌入式系统的zRAM 四、内存性能调优 ------>4.1、存储…...

Mem Reduct终极指南:一键释放内存,让你的Windows电脑飞起来
Mem Reduct终极指南:一键释放内存,让你的Windows电脑飞起来 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/m…...

【从零开始学Java | 第二十九篇】数组工具类Arrays和集合工具类Collections
目录 前言 一、数组工具类Arrays 1.数组的打印 2.数组的排序和查找 3.数组的复制和扩容 4.数组转换集合 二、集合工具类Collections 1.排序和位置操作 2.查找和极值运算 前言 本次学习两个Java提供的工具类,第一个是用来操作数组的工具类——Arrays&#x…...

如何构建自修复AI系统:Seldon Core 2数据漂移检测终极指南
如何构建自修复AI系统:Seldon Core 2数据漂移检测终极指南 【免费下载链接】seldon-core An MLOps framework to package, deploy, monitor and manage thousands of production machine learning models 项目地址: https://gitcode.com/gh_mirrors/se/seldon-cor…...

前端 SEO 优化与图片 SEO 优化的关系是什么_如何利用前端框架进行 SEO 优化
前端 SEO 优化与图片 SEO 优化的关系是什么? 在当今的互联网时代,搜索引擎优化(SEO)已经成为了任何网站想要获得高流量的关键步骤。前端 SEO 优化与图片 SEO 优化在这其中扮演着至关重要的角色。尽管它们看起来独立存在ÿ…...

高效办公隐私保护工具:Boss-Key老板键一键隐藏窗口解决方案
高效办公隐私保护工具:Boss-Key老板键一键隐藏窗口解决方案 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在现代办公环境中&…...

如何用TPFanCtrl2解决ThinkPad散热难题:5个智能控制进阶技巧与实战案例
如何用TPFanCtrl2解决ThinkPad散热难题:5个智能控制进阶技巧与实战案例 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 一、重新定义散热控制:T…...

BANG C语言在DLP平台上的矩阵乘法优化:从标量到五级流水线的性能跃迁
1. 矩阵乘法优化的核心挑战 矩阵乘法是深度学习中最基础也最耗时的操作之一。在DLP平台上,一个128x256x128规模的矩阵乘法,如果用最基础的标量实现方式,性能往往只有CPU的1/10。这就像用自行车和跑车比赛,完全不在一个量级。 为什…...

如何用快马平台与jdk1.8特性十分钟搭建商品管理系统原型
今天想和大家分享一个快速搭建商品管理系统原型的经验。作为一个经常需要验证业务逻辑的后端开发,我发现用jdk1.8配合InsCode(快马)平台可以十分钟内完成从零到可运行的原型开发,特别适合敏捷开发场景。 为什么选择jdk1.8 企业级开发中jdk1.8仍然是主流选…...

PHP实现异步请求的四种方法
PHP中的cURL可用于发起 HTTP 请求,通常同步地等待服务器响应。如果你想要实现异步操作,即 PHP 程序继续执行而无需等待 cURL 请求完成,你可以考虑以下几种方式:使用curl_multicURL 提供了设置 curl_multi 和 curl_multi_exec 来同…...
到彩色地图的转换)
告别黑白世界:用QGIS的GDAL工具,5分钟搞定单波段数据(温度/人口)到彩色地图的转换
告别黑白世界:用QGIS的GDAL工具,5分钟搞定单波段数据(温度/人口)到彩色地图的转换 当我们面对温度分布、人口密度或污染物浓度等单波段栅格数据时,如何让这些冰冷的数字在空间上"活"起来?传统灰度…...