大数据-玩转数据-Flume
一、Flume简介
-
- Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务,Flume只能在Unix环境下运行。
-
- Flume基于流式架构,容错性强,也很灵活简单。
-
- Flume、Kafka用来实时进行数据收集,Spark、Flink用来实时处理数据,impala用来实时查询。
二、Flume角色
2.1、Source
用于采集数据,Source是产生数据流的地方,同时Source会将产生的数据流传输到Channel,这个有点类似于Java IO部分的Channel。
2.2、Channel
用于桥接Sources和Sinks,类似于一个队列。
2.3、Sink
从Channel收集数据,将数据写到目标源(可以是下一个Source,也可以是HDFS或者HBase)。
2.4、Event
传输单元,Flume数据传输的基本单元,以事件的形式将数据从源头送至目的地。
三、Flume传输过程
source监控某个文件或数据流,数据源产生新的数据,拿到该数据后,将数据封装在一个Event中,并put到channel后commit提交,channel队列先进先出,sink去channel队列中拉取数据,然后写入到HDFS中。
四、Flume部署及使用
4.1 采集架构
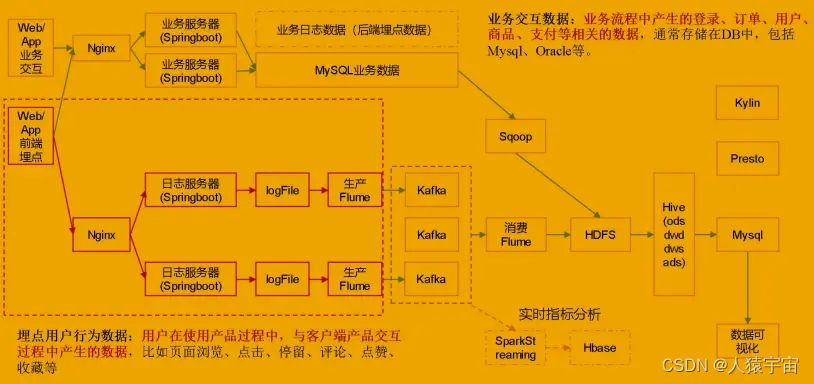
4.2 Flume安装
4.2.1 下载
apache-flume-1.6.0-bin.tar.gz
链接:https://pan.baidu.com/s/1ySmEEObFtKtyT7GsEldnfA
提取码:436t
4.2.2 安装
Flume的安装非常简单,只需要解压即可
tar -zxvf apache-flume-1.6.0-bin.tar.gz
然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
在这里,我们使用集群模式,因此,需要把在master节点部署的flume分发到slave节点上:
]# scp -rp apache-flume-1.7.0-bin slave1:KaTeX parse error: Expected 'EOF', got '#' at position 6: PWD ]#̲ scp -rp apache…PWD
4.2.3 测试
采集配置:
vi netcat-logger.conf
# 定义这个agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述和配置sink组件:k1
a1.sinks.k1.type = logger
# 描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置source channel sink之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
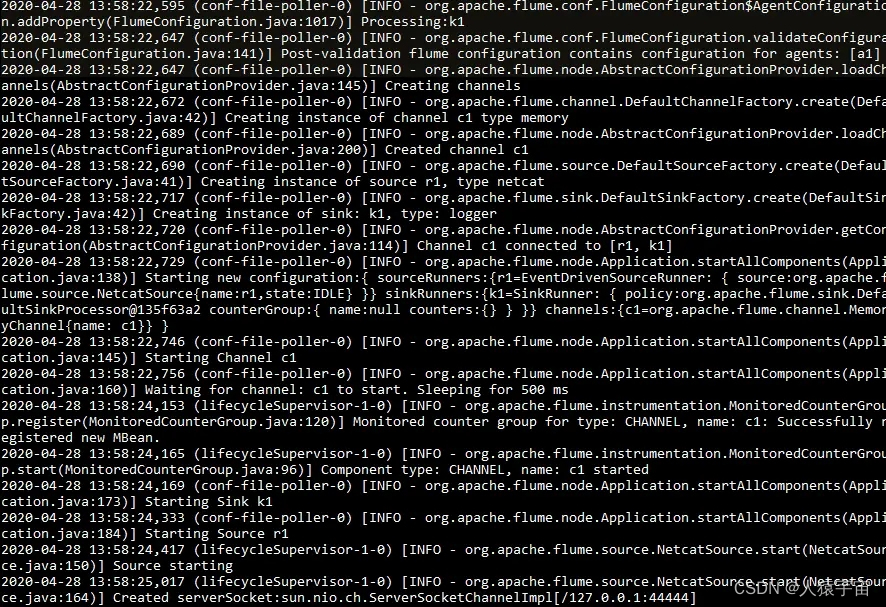
启动agent去采集数据
启动命令:
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
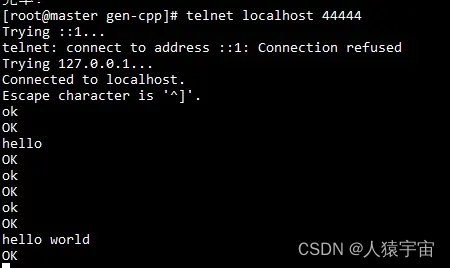
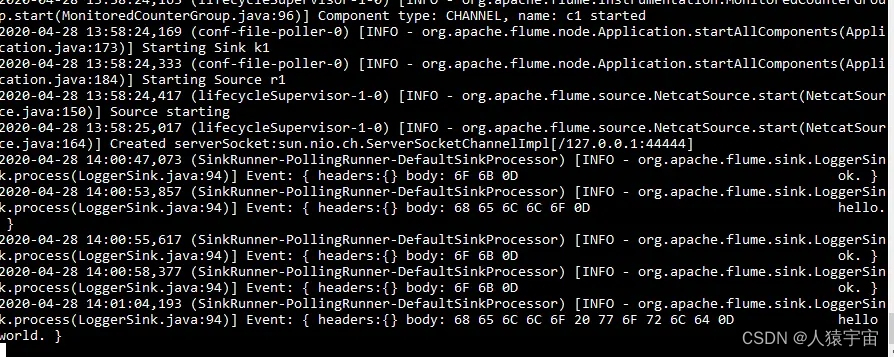
先要往agent采集监听的端口上发送数据,让agent有数据可采
发送命令:
安装telnet:
]# yum install telnet
]# telnet anget-hostname port (telnet localhost 44444)
测试输入输出如下图:
4.3 Flume配置
1)Flume 配置分析
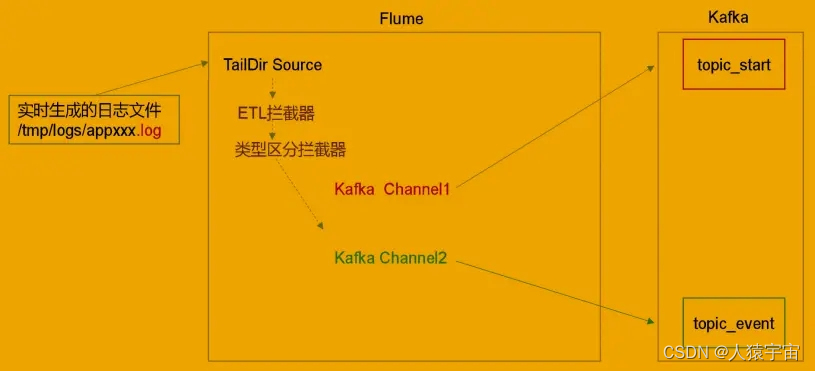
Flume 直接读 log 日志的数据,log 日志的格式是 app-yyyy-mm-dd.log。
2)Flume 的具体配置如下:
(1)在/opt/module/flume/conf 目录下创建 file-flume-kafka.conf 文件
vim file-flume-kafka.conf
a1.sources=r1
a1.channels=c1 c2
#configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /usr/local/src/apache-flume-1.7.0-bin/test/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/log/2020-11-03/app.*.log
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
#interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.zgjy.flume.interceptor.LogETLInterceptor$Builder
a1.sources.r1.interceptors.i2.type = com.zgjy.flume.interceptor.LogTypeInterceptor$Builder
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_resource = c1
a1.sources.r1.selector.mapping.topic_action = c2
# configure channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
a1.channels.c1.kafka.topic = topic_resource
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c1.kafka.consumer.group.id = flume-consumer
# configure channe2
a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
a1.channels.c2.kafka.topic = topic_action
a1.channels.c2.parseAsFlumeEvent = false
a1.channels.c2.kafka.consumer.group.id = flume-consumer
测试日志:
配置说明如下:

4.4 Flume 的 ETL 和分类型拦截器
本项目中自定义了两个拦截器,分别是:ETL 拦截器、日志类型区分拦截器。
ETL 拦截器主要作用:过滤时间戳不合法和 Json 数据不完整的日志
日志类型区分拦截器主要作用:将启动日志和事件日志区分开来,方便发往 Kafka 的不 同 Topic。
1)创建 Maven 工程 flume-interceptor
2)创建包名:com.zgjy.flume.interceptor
3)在 pom.xml 文件中添加如下配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.zgjy</groupId><artifactId>flume-interceptor</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.1.41</version></dependency><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.7.0</version></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>2.5.3</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration></plugin></plugins></build></project>
4)在 com.zgjy.flume.interceptor 包下创建 LogETLInterceptor 类名
Flume ETL 拦截器 LogETLInterceptor实现代码如下:
package 相关文章:
大数据-玩转数据-Flume
一、Flume简介 Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务,Flume只能在Unix环境下运行。Flume基于流式架构,容错性强,也很灵活简单。Flume、Kafka用来实时进行数据收集,Spark、Flink用来实时处理数据,impala用来实时查询。二、Flume…...

【Linux】进程概念IV 进程地址空间
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法…感兴趣就关注我吧!你定不会失望。 本篇导航 0. 数据在内存中的分布1. 虚拟地址与真实物理地址2. 进程地址空间2.1 进程地址空间概念2.2 进程->页表->内存 0. 数据在内…...

Flink在汽车行业的应用【面试加分系列】
很多同学问我为什么要发这些大数据前沿汇报? 一方面是自己学习完后觉得非常好,然后总结发出来方便大家阅读;另外一方面,看这些汇报对你的面试帮助会很大,特别是面试前可以看看即将面试公司在大数据前沿的发展动向&…...
智慧工地源码:助力数字建造、智慧建造、安全建造、绿色建造
智慧工地围绕建设过程管理,建设项目与智能生产、科学管理建设项目信息生态系统集成在一起,该数据在虚拟现实环境中,将物联网收集的工程信息用于数据挖掘和分析,提供过程趋势预测和专家计划,实现工程建设的智能化管理&a…...

Spring Boot(二)
1、运行维护 1.1、打包程序 SpringBoot程序是基于Maven创建的,在Maven中提供有打包的指令,叫做package。本操作可以在Idea环境下执行。 mvn package 打包后会产生一个与工程名类似的jar文件,其名称是由模块名版本号.jar组成的。 1.2、程序…...
上海亚商投顾:沪指缩量调整跌 高位强势股继续退潮
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 三大指数11月10日弱势震荡,上证50盘中跌超1%,以保险为首的权重板块走势较弱。 高位强…...

药理学试卷
1【单选题】关于尼可刹米,错误的是 C A、直接兴奋延脑呼吸中枢 B、刺激颈动脉体化学感受器 C、作用时间较长 D、过量可致惊厥 2【单选题】属于第三代头孢菌素的药物是 C A、头孢克洛 B、头孢噻吩 C、头孢曲松 D、头孢匹罗 3【单选题】不属于β受体阻断药禁…...

SpringBoot3-快速入门
1.前置知识 Java17Spring、SpringMVC、MyBatisMaven、IDEA\ 2. 环境要求 环境&工具 版本(or later) SpringBoot 3.0.5 IDEA 2021.2.1 Java 17 Maven 3.5 Tomcat 10.0 Servlet 5.0 GraalVM Community 22.3 Native Build Tools 0.9…...

具名挂载和匿名挂载
匿名卷挂载 : -v 的时候只指定容器内的路径 如下面这个:/etc/nginx 1.docker run -d -P --name nginx -v /etc/nginx nginx 2.查看所有卷 docker volume ls 这里发现,这就是匿名挂载,只指定容器内的路径,没有指定…...
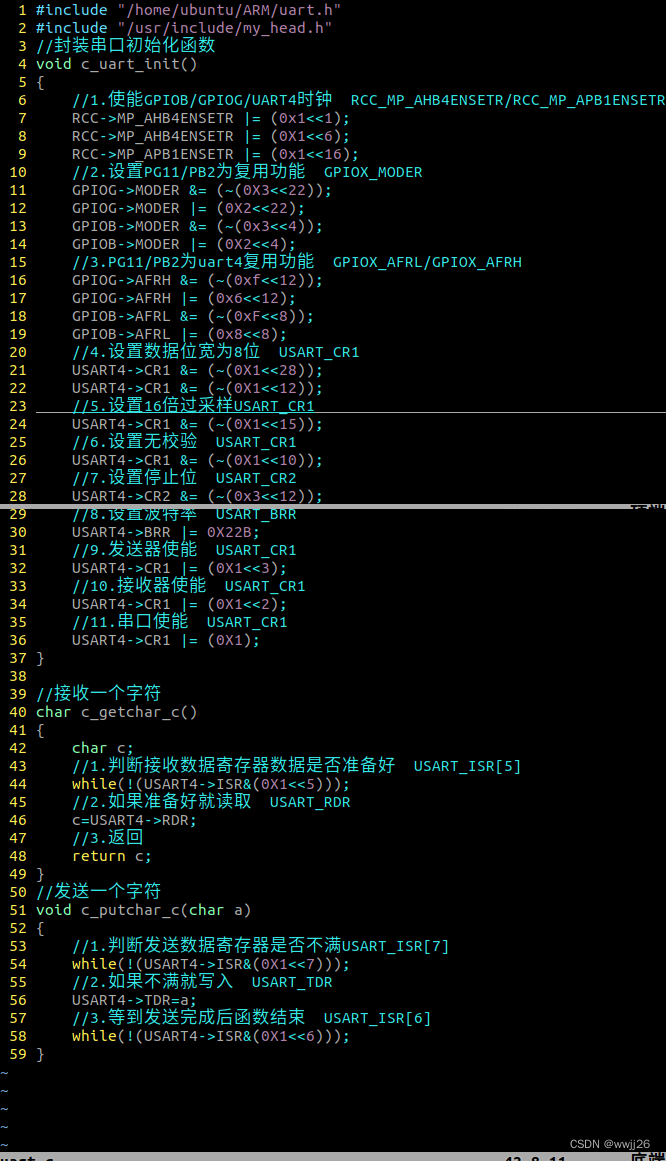
ARM串口
...
)
C++ Qt 学习(文章链接汇总)
C Qt 学习(一):Qt 入门 C Qt 学习(二):常用控件使用与界面布局 C Qt 学习(三):无边框窗口设计 C Qt 学习(四):自定义控件与 qss 应用 …...

2311d9月会议
DLF2023年9月月度会议摘要 Robert Robert,在DConf上做了一些初步的JSON5工作.他还更新了Bugzilla到GitHub的迁移脚本.他使用了"隐藏"API,现在脚本要快得多. 除此外,他在DScanner上做了一些小事,并等待JanJurzitza(Webfreak)合并它们.他指出,沃尔特曾要求他写一篇演…...
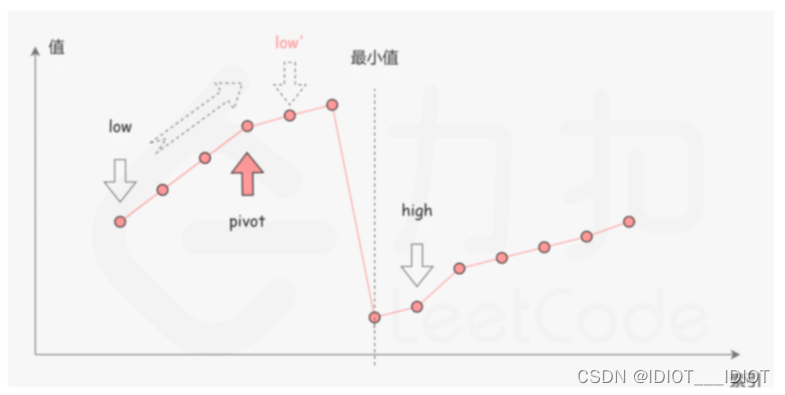
《算法通关村——二分查找在旋转数字中的应用》
《算法通关村——二分查找在旋转数字中的应用》 这里我们直接通过一个题目,来了解二分查找的应用。 153. 寻找旋转排序数组中的最小值 已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如&a…...
)
C/S架构学习之基于TCP的本地通信(服务器)
基于TCP的本地通信(服务器):创建流程:一、创建字节流式套接字(socket函数): int sock_fd socket(AF_LOCAL,SOCK_STREAM,0);二、创建服务器和客户机的本地网络信息结构体并填充服务器本地网络信…...
乡镇村污水处理智慧水务智能监管平台,助力污水监管智慧化、高效化
一、背景与需求 随着城市化进程的加速,排放的污水量也日益增加,导致水污染严重。深入打好污染防治攻坚战的重要抓手,对于改善城镇人居环境,推进城市治理体系和治理能力现代化,加快生态文明建设,推动高质量…...

OSPF综合
实验拓扑 实验需求: 1 R4为ISP,其上只能配置IP地址; R4与其他所有直连设备间均使用公有IP 2 R3-R5/6/7为MGRE环境,R3为中心站点 ; 3 整个OSPF环境IP基于172.16.0.0/16划分; 4 所有设备均可访问R4的环回; 5 减少LSA的更新量,加快收…...

vue分片上传视频并转换为m3u8文件并播放
开发环境: 基于若依开源框架的前后端分离版本的实践,后端java的springboot,前端若依的vue2,做一个分片上传视频并分段播放的功能,因为是小项目,并没有专门准备文件服务器和CDN服务,后端也是套用…...

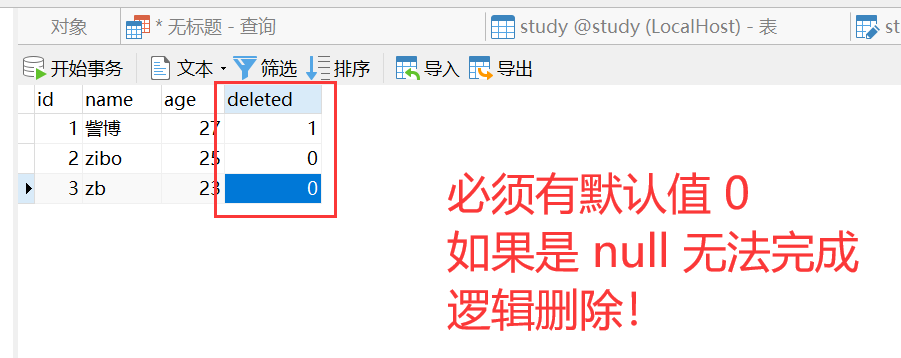
【MySQL】对表结构进行增删查改的操作
表的操作 前言正式开始建表查看表show tables;desc xxx;show create table xxx; 修改表修改表名 rename to对表结构进行修改新增一个列 add 对指定列的属性做修改 modify修改列名 change 删除某列 drop 删除表 drop 前言 前一篇讲了库相关的操作,如果你不太懂&…...
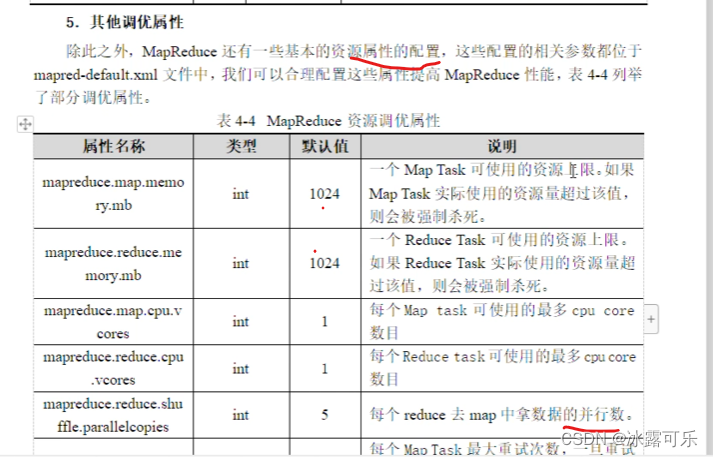
Hadoop原理,HDFS架构,MapReduce原理
Hadoop原理,HDFS架构,MapReduce原理 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,…...
【Spring Boot】035-Spring Boot 整合 MyBatis Plus
【Spring Boot】035-Spring Boot 整合 MyBatis Plus 【Spring Boot】010-Spring Boot整合Mybatis https://blog.csdn.net/qq_29689343/article/details/108621835 文章目录 【Spring Boot】035-Spring Boot 整合 MyBatis Plus一、MyBatis Plus 概述1、简介2、特性3、结构图4、相…...

番茄小说下载器:终极开源工具,轻松构建个人数字图书馆 [特殊字符]
番茄小说下载器:终极开源工具,轻松构建个人数字图书馆 📚 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 还在为网络小说阅读体验差而烦恼吗…...

Spring Boot后端实战:手把手教你处理Google Play订阅续费、降级与退款回调
Spring Boot实战:Google Play订阅状态变更的深度处理指南 订阅业务中的关键挑战 移动应用订阅模式已成为开发者重要的收入来源,而Google Play作为全球最大的应用分发平台,其订阅系统的复杂性往往让开发者头疼。特别是当用户进行订阅续费、降…...

Qwen3-VL-8B效果实测:上传图片,看AI如何精准描述与回答
Qwen3-VL-8B效果实测:上传图片,看AI如何精准描述与回答 1. 轻量级视觉语言模型的惊艳表现 当你第一次看到Qwen3-VL-8B处理图片的能力时,很难相信这只是一个8B参数的模型。它不仅能准确识别图片中的物体和场景,还能理解上下文关系…...

基于xlsx.core.min.js实现前端表格数据的智能导入与精准导出
1. 为什么选择xlsx.core.min.js处理表格数据 第一次接触前端Excel处理需求时,我试过至少5种方案。有的库体积太大,有的兼容性差,还有的文档晦涩难懂。直到发现xlsx.core.min.js这个宝藏库,才真正解决了我的痛点。这个只有200KB左右…...

50天学习FPGA第41天-PCIe的的介绍及使用
目录 简介 配置过程 简介 XDMA是一种DMA/Bridge Subsystem for PCI Express IP,由Xilinx提供。 XDMA IP核设计使用Xilinx提供的DMASubsystem for PCI Express IP是一个高性能、可配置的适用于PCIE 2.0、PCIE 3.0的SG模式DMA,提供用户可选择的AXI4接口或者AXI4-Stream接口。…...

Kandinsky-5.0-I2V-Lite-5s效果展示:手绘草图→线条流动+色彩渐变动态视频
Kandinsky-5.0-I2V-Lite-5s效果展示:手绘草图→线条流动色彩渐变动态视频 1. 模型简介 Kandinsky-5.0-I2V-Lite-5s是一款轻量级图生视频模型,它能将静态图片转化为约5秒、24fps的短视频。你只需要上传一张首帧图片,再补充一句运动或镜头描述…...

DeepSeek-R1-Distill-Qwen-1.5B效果展示:同一问题下思考链vs直答效果对比
DeepSeek-R1-Distill-Qwen-1.5B效果展示:同一问题下思考链vs直答效果对比 1. 项目概述 DeepSeek-R1-Distill-Qwen-1.5B是一个超轻量级的智能对话模型,基于魔塔平台下载量最高的蒸馏模型构建。这个模型巧妙融合了DeepSeek强大的逻辑推理能力和Qwen成熟的…...

Ollama部署Phi-3-mini完整指南:从安装到实战应用场景解析
Ollama部署Phi-3-mini完整指南:从安装到实战应用场景解析 1. 为什么选择Phi-3-mini-4k-instruct? Phi-3-mini-4k-instruct是微软推出的轻量级AI模型,虽然只有38亿参数,但在多个基准测试中表现优异。这个模型特别适合需要快速部署…...

intv_ai_mk11开发者友好:提供RESTful API文档、Curl示例、SDK接入指引
intv_ai_mk11开发者友好:提供RESTful API文档、Curl示例、SDK接入指引 1. 平台概述 intv_ai_mk11是基于Llama架构的中等规模文本生成模型,专为开发者设计,提供完整的API接入方案。该模型擅长处理通用问答、文本改写、解释说明和简短创作等任…...

高效下载B站视频全攻略:Downkyi让你轻松管理视频资源
高效下载B站视频全攻略:Downkyi让你轻松管理视频资源 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&#x…...