C++--二叉树经典例题
本文,我们主要讲解一些适合用C++的数据结构来求解的二叉树问题,其中涉及了二叉树的遍历,栈和队列等数据结构,递归与回溯等知识,希望可以帮助你进一步理解二叉树。

目录
1.二叉树的层序遍历
2.二叉树的公共祖先
3.二叉搜索树与双向链表
4.二叉树的创建(前序+中序,后序+中序)
前序+中序:
中序+后序:
5.二叉树的三种迭代法遍历
1.二叉树的层序遍历
题目链接:二叉树的层序遍历
思路分析:
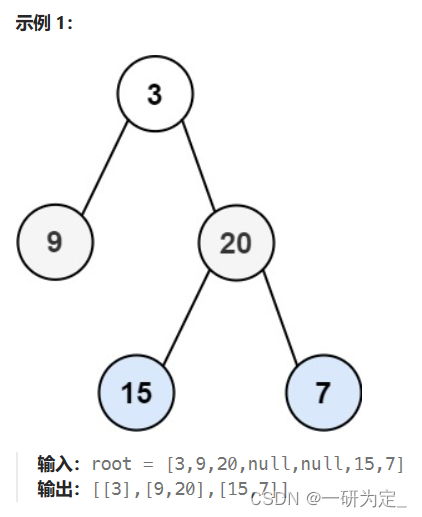
这个题目的难点是如何控制层序遍历的同时还能保持入队操作,我们知道,二叉树的的层序遍历一般和队列联系在一起使用,包括一些bfs的习题也经常以队列、栈作为遍历的容器,本题,我们需要思考如何能够遍历某一层的同时,将该层的下一层的节点保存下来,同时还需要将该层的节点按从左到右的顺序输出,显然,我们需要将每一层的节点聚在一起保存,这样才能保证输出的正确性,我们可以提供一个输出的变量len,表示该层需要输出几个节点,然后将该层的节点输出的同时把它的左右孩子都入队,这样一来,就能保证每一层的节点都聚在一起并且按从左到右的顺序排列,之后保存输出即可。
AC代码:
class Solution {
public:queue<TreeNode*> q;vector<vector<int>> ans;vector<vector<int>> levelOrder(TreeNode* root) {if(!root)return ans;vector<int> cot;q.push(root);int len=1;while(!q.empty()){while(len--){TreeNode* tmp=q.front();q.pop();if(tmp->left!=nullptr) q.push(tmp->left);if(tmp->right!=nullptr) q.push(tmp->right);cot.push_back(tmp->val);}len=q.size();ans.push_back(cot);cot.clear();} return ans;}
};2.二叉树的公共祖先
题目链接:二叉树的公共祖先
思路分析:
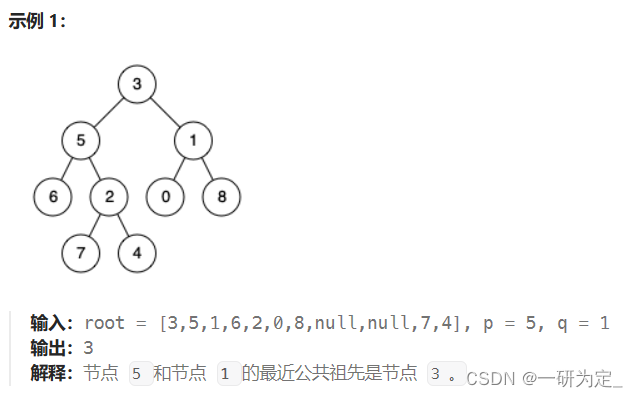
难点在于如何在找到两个节点的条件下,回溯双方的祖先节点来确定最近公共祖先,这里仅提供其中一个思路,我们可以保存寻找路径,然后让两个路径中较长的路径(也就是离公共祖先节点较远的)逐渐向上走,直到两条路径交合,交合点就是最近公共祖先。
class Solution {
public:bool isexist(TreeNode*root,TreeNode *key){if(root==nullptr)return false;else if(root==key)return true;elsereturn isexist(root->left,key)||isexist(root->right,key);}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {stack<TreeNode*>ppath;stack<TreeNode*>qpath;TreeNode*cur=root;ppath.push(root);qpath.push(root);//寻找p的路径while(cur){if(cur==p)break;else if(isexist(cur->left,p)) {ppath.push(cur->left);cur=cur->left;}else if(isexist(cur->right,p)){ppath.push(cur->right);cur=cur->right;}}//寻找q的路径cur=root;while(cur){if(cur==q)break;else if(isexist(cur->left,q)) {qpath.push(cur->left);cur=cur->left;}else if(isexist(cur->right,q)){qpath.push(cur->right);cur=cur->right;}}//开始寻找TreeNode *ans=nullptr;while(ppath.size()&&qpath.size()){if(ppath.size() > qpath.size())ppath.pop();else if(ppath.size() < qpath.size())qpath.pop();else if(ppath.size() == qpath.size()){if(ppath.top()==qpath.top()){ans=ppath.top();break;}else{ppath.pop();qpath.pop();}}}return ans;}
};3.二叉搜索树与双向链表
题目链接:二叉搜索树与双向链表
思路分析:
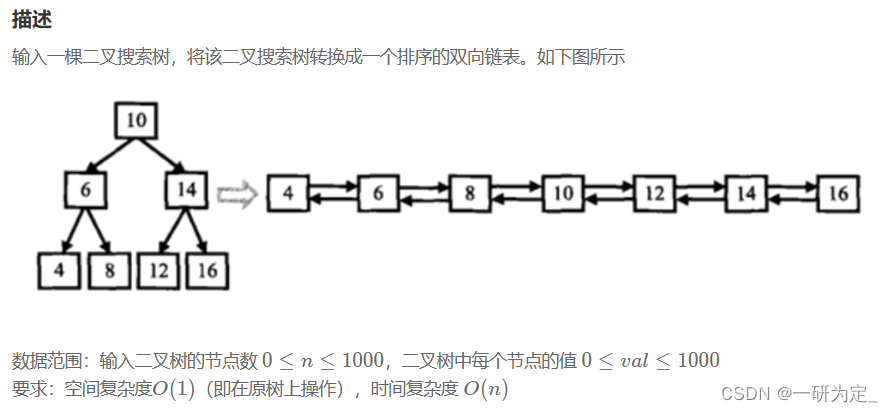

本体的难点在于,如何在原树上做修改而不影响接下来的操作,当然,暴力也可以做,但是这里要求我们在原树上直接做修改,所以,这里不解释暴力做法,我们就按题目规定的思路来,我们知道,二叉搜索树最左端的元素一定最小,最右端的元素一定最大,因此二叉搜索树的中序遍历就是一个递增序列,我们只要对它中序遍历就可以组装成为递增双向链表。
我们可以使用一个指针pre指向当前结点root的前继。(例如root为指向10的时候,preNode指向8),对于当前结点root,有root->left要指向前继pre(中序遍历时,对于当前结点root,其左孩子已经遍历完成了,此时root->left可以被修改。);同时,pr->right要指向当前结点(当前结点是pre的后继),此时对于pre结点,它已经完全加入双向链表。
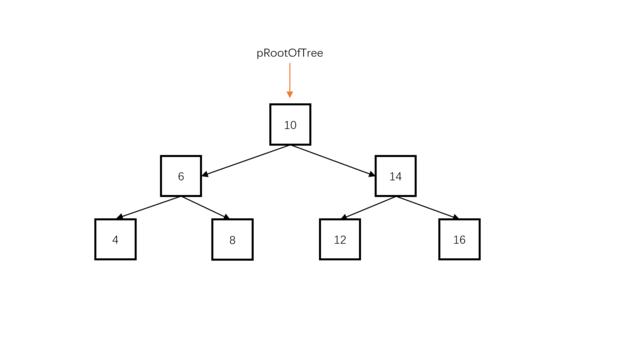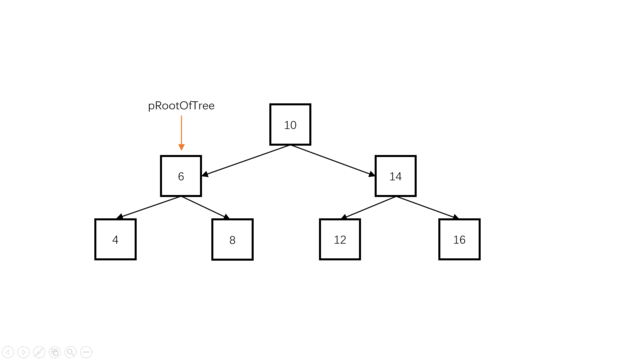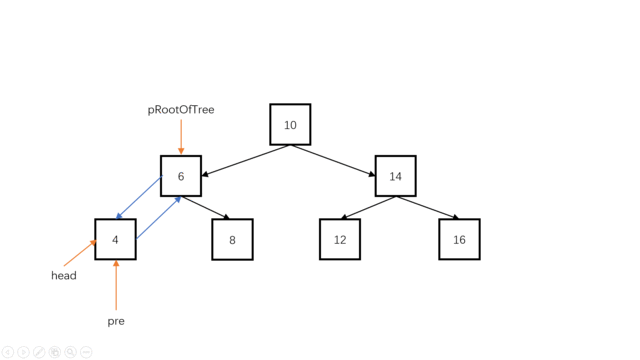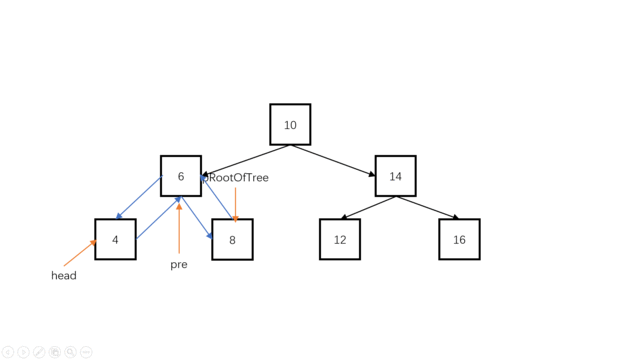
class Solution {
public:TreeNode *head=nullptr;TreeNode*pre=nullptr;TreeNode* Convert(TreeNode* pRootOfTree) {if(pRootOfTree==nullptr)return nullptr;Convert(pRootOfTree->left);//找到最左节点,也就是最小的那个点if(head==nullptr)//此时是第一个最小值,也就是头结点{head=pRootOfTree;pre=pRootOfTree;}else{pre->right=pRootOfTree;pRootOfTree->left=pre;pre=pRootOfTree;}Convert(pRootOfTree->right);return head;}
};
4.二叉树的创建(前序+中序,后序+中序)
这应该算是一个老生常谈的问题了,算是经典中的经典了,其实不论是前序+中序还是后序+中序,其原理都大同小异,所以,我们将这两个例子放在一起讲解,有助于理解和记忆。
题目链接:105. 从前序与中序遍历序列构造二叉树 - 力扣(LeetCode)
106. 从中序与后序遍历序列构造二叉树 - 力扣(LeetCode)
思路分析:
前序+中序:
递归法:
只要我们在中序遍历中定位到根节点,那么我们就可以分别知道左子树和右子树中的节点数目。由于同一颗子树的前序遍历和中序遍历的长度显然是相同的,因此我们就可以对应到前序遍历的结果中,也就是每次都从中序遍历中寻找根节点,然后通过中序遍历将左右子树划分开来,再递归构造新的左右子树即可;
class Solution {
public:TreeNode *root=nullptr;TreeNode* build(vector<int>& pre, vector<int>& in,int pl,int pr,int il,int ir){if(pl>pr)//如果越界直接返回空即可return nullptr;TreeNode* cur=new TreeNode(pre[pl]);//前序遍历第一个元素一定是某棵子树的根节点int idx=0,len=0;//分别表示根节点在中序遍历的位置和左子树的节点个数for(int i=il;i<=ir;i++){if(in[i]==pre[pl]) //找到根节点所在的中序遍历的位置以确定根的左右子树{idx=i;len=i-il;//找到对应的左子树的节点个数break;}}cur->left=build(pre,in,pl+1,pl+len,il,idx-1);cur->right=build(pre,in,pl+1+len,pr,idx+1,ir);return cur;}TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {root= build(preorder,inorder,0,preorder.size()-1,0,inorder.size()-1);return root;}
};迭代法:
我们先来假设一种极端情况,如果一棵二叉树只有左孩子,那么其结构就类似于一张单链表,它的前序遍历和中序遍历一定就相反,我们将这个由此就可以判断此之前的过程中的每一个节点都没有右孩子,为了便于理解,我们用例子加以说明:
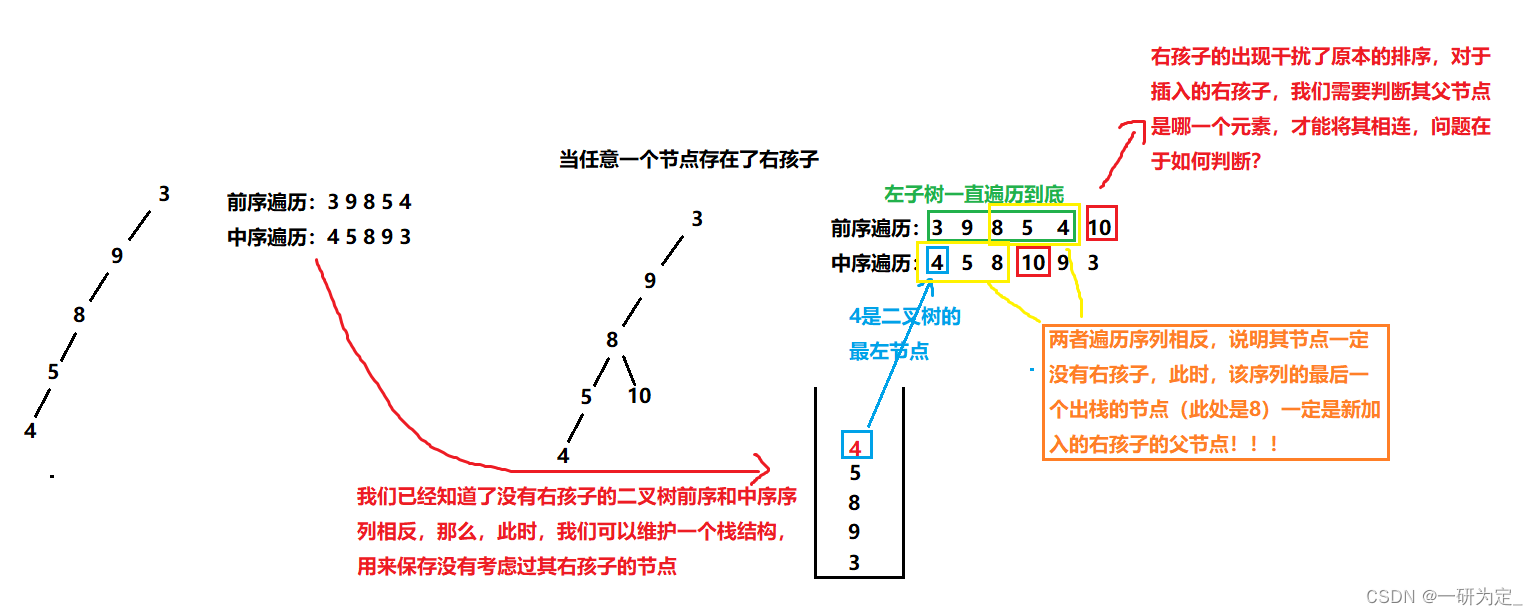
那么此时我们就可以维护一个栈,用来保存还没有考虑过右孩子的节点,按前序遍历的序列一直向二叉树的左端去遍历,当某个时刻遍历到了二叉树的最左节点,此时说明前序遍历的下一个元素一定是栈中某个节点的右孩子了,然后我们再依次对比栈中元素和中序序列,取出栈中的最后一个满足前序和中序序列相反的元素,将新加入的节点加入其右孩子,再将其入栈,我们无需再考虑已经出栈的元素,因为他们的右子树都已经被考虑完了,所以其树结构已经形成了,重复该过程直到前序序列遍历完毕即可形成一棵完整的树。
class Solution {
public:TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {if(!preorder.size())return nullptr;TreeNode *root=new TreeNode(preorder[0]);//先序遍历的第一个节点一定是根stack<TreeNode*>st;st.push(root);int idx=0;//初始idx指向中序遍历的第一个元素(整棵二叉树的最左节点)for(int i=1;i<preorder.size();i++)//根节点已经加入,所以前序遍历从下标1开始即可{TreeNode* node=st.top();if(node->val!=inorder[idx])//如果加入节点还没判断是不是有右孩子{node->left=new TreeNode(preorder[i]);st.push(node->left);//节点入栈等待判断}else //此时说明已经到达了某棵子树的最左节点,开始判断新加入的节点(preorder[i])是哪一个栈中节点的右孩子{TreeNode* parent=nullptr;while(!st.empty()&& st.top()->val==inorder[idx]) //前中序遍历序列一致,此时该节点没有右孩子{parent=st.top();//最后一个出栈的节点一定是那个父节点,用于保存上次出栈记录st.pop();++idx;}parent->right=new TreeNode(preorder[i]);//创建其右孩子st.push(parent->right);//不能忘了将新创建的节点加入,因为该节点可能还有左右子树需要创建}}return root;}
};中序+后序:
递归法:
后序遍历的数组最后一个元素代表的即为根节点。知道这个性质后,我们可以利用已知的根节点信息在中序遍历的数组中找到根节点所在的下标,然后根据其将中序遍历的数组分成左右两部分,左边部分即左子树,右边部分为右子树,针对每个部分可以用同样的方法继续递归下去构造。
class Solution {
public:TreeNode*build(vector<int>& in, vector<int>& pos,int il,int ir,int pl,int pr){if(pl>pr)return nullptr;TreeNode*root=new TreeNode(pos[pr]);//后序遍历的最后一个节点一定是根节点int idx=0,len=0;for(int i=il;i<=ir;i++){if(pos[pr]==in[i]){idx=i;len=i-il;break;}}root->left=build(in,pos,il,idx-1,pl,pl+len-1);root->right=build(in,pos,idx+1,ir,pl+len,pr-1);return root;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {return build(inorder,postorder,0,inorder.size()-1,0,postorder.size()-1);}
};迭代法:
此处和前中序创建的方法大同小异,我们只需要注意前序和后序的区别即可,因为后序遍历中,和根节点挨在一块的是右子树,所以,我们转变一下思路,可以通过构建右子树的过程中插入左节点来实现,其余的原理均和前中序的原理类似。
class Solution {
public:TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {if(!postorder.size())return nullptr;stack<TreeNode*>st;TreeNode* root=new TreeNode(postorder[postorder.size()-1]);st.push(root);int idx=postorder.size()-1;for(int i=postorder.size() - 2;i>=0;i--){TreeNode* node=st.top();if(node->val!=inorder[idx])//这次是县创建右子树{node->right=new TreeNode(postorder[i]);st.push(node->right);}else//找到了第一个左孩子节点{TreeNode* parent=nullptr;while(!st.empty()&&st.top()->val==inorder[idx]){parent=st.top();st.pop();--idx;}parent->left=new TreeNode(postorder[i]);st.push(parent->left);}}return root;}
};5.二叉树的三种迭代法遍历
题目链接:二叉树的前序遍历、二叉树的中序遍历、二叉树的后序遍历
思路分析:
前序遍历:
对于前序遍历,根左右的形式,根节点一定是最先输出的,难点在于如何转换方向,也就是当遍历到左子树最后一个节点时,如何将其转换为右子树再进行输出,此时,我们可以设置一个指针cur,初始时,cur一直向着左子树走,当左子树遍历到最左节点时,我们可以将当前的cur更新其父节点的右孩子节点,然后cur再次往左走,走到叶节点再次转向右子树,重复递归这个过程即可。
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> ans;stack<TreeNode*> st;TreeNode*cur=root;while(cur || !st.empty()){while(cur){ans.push_back(cur->val);//将每棵子树的根节点直接加入st.push(cur);cur=cur->left;//接着寻找最左节点}//此时节点已经找到了最左节点cur=st.top()->right;//转而进入最左节点的右子树st.pop();//删除最左节点 }return ans;}
};中序遍历:
和前序遍历的大同小异,此时我们的输出模式变成了左根右,那么此时我们循环找到最左节点的时候,就需要先输出最左节点,在回溯找到根节点输出,然后再递归到右子树进行输出即可。
class Solution {
public:vector<int> inorderTraversal(TreeNode* root) {vector<int> ans;stack<TreeNode*> st;if(!root)return ans;TreeNode* cur=root;while(cur||!st.empty()){while(cur){st.push(cur);//将左子树根节点入栈cur=cur->left;//向左查找最左节点}//此时cur已经是该子树上的最左节点TreeNode* p=st.top();st.pop();ans.push_back(p->val);cur=p->right; //无论最左节点是否有右子树,我们转换为右子树的子问题,此时cur如果为空,可直接回溯到最左节点的父节点进行操作}return ans;}
};后序遍历:
后序遍历与上面的两种方式有着些许不同,其中,后序遍历的难点是如何判断当前的节点能否作为根输出,也就相当于,如果左节点存在右子树且还没有输出,那么我们就需要先考虑右子树的输出而不能先输出左节点,反之,如果其没有右子树或者右子树已经输出完了,那么就可以直接输出,所以,每个左节点都需要进行特殊分析,由于我们知道后序遍历的形式是左右根,那么每个子树输出的最后个一定是其根节点,而如果一个左节点有右子树,那么此时其后序遍历的输出,在左节点之前的节点一定是其右孩子节点,我们可以以这个条件作为其右子树是否输出完毕的条件,设置一个指针pre指向上一个被访问的节点,此时就有两种情况:
1.当前节点的右子树为空或者当前节点的右子树是上一个被访问的节点,此时说明该节点作为根节点,其右子树的输出已经完毕,可以输出根节点了;(注意此时要更新pre指针)
2.如果右树存在且没有被访问,那么就需要转到右树上去继续输出,此时根节点不能删除。
class Solution {
public:vector<int> postorderTraversal(TreeNode* root) {vector<int> ans;stack<TreeNode*> st;TreeNode* cur=root;TreeNode* pre=nullptr;while(cur || !st.empty()){while(cur){st.push(cur);cur=cur->left;}//此时已经到达了最左节点TreeNode* top=st.top();if(top->right==nullptr || top->right==pre) //如果此时最左节点的右子树为空或者右子树已经被访问直接输出该左节点即可{st.pop();ans.push_back(top->val); pre=top;//更新上次访问的节点}else{cur=top->right;//先访问其右子树,再输出根} }return ans;}
};后面有好的题目会继续补充,敬请期待......
相关文章:
C++--二叉树经典例题
本文,我们主要讲解一些适合用C的数据结构来求解的二叉树问题,其中涉及了二叉树的遍历,栈和队列等数据结构,递归与回溯等知识,希望可以帮助你进一步理解二叉树。 目录 1.二叉树的层序遍历 2.二叉树的公…...

软件测试需要学习什么?好学吗?需要学多久?到底是报班好还是自学好?
前言: 我发现很多的小伙伴刚刚毕业和想转行的小伙伴对于软件测试很陌生,其中很有很多的小伙伴还踩不少的坑,花费了大量的精力和时间去探索,结果还是一无所获。这里给大家出一期关于软件测试萌新的疑惑,看完这篇文章你就…...

Ubuntu搭建AI画图工具stable diffusion-webui
Ubuntu搭建 安装依赖项 安装以下依赖项: # Debian-based: sudo apt install wget git python3 python3-venv libgl1 libglib2.0-0# Red Hat-based: sudo dnf install wget git python3# Arch-based: sudo pacman -S wget git python3下载并安装WebUI 进入您想要安…...

智能优化算法(一):伪随机数的产生
文章目录 1.伪随机数介绍1.1.伪随机产生的意义1.2.伪随机产生的过程 2.产生U(0,1)的乘除同余法2.1.原始的乘同余法2.2.改进的乘同余法 3.产生正态分布的伪随机数4.基于逆变法产生伪随机数 1.伪随机数介绍 1.1.伪随机产生的意义 1.随机数的产生是进行随机优化的第一步也是最重要…...

python 调用Oracle有返回参数的存储过程
python 调用Oracle有返回参数的存储过程 1. 存储过程 create or replace procedure pro_test_args(a in integer,b in integer, c out integer) is beginc: a * b ;end pro_test_args;2. Python调用存储过程 import cx_Oracle import os import sys# 连接数据库 #conn cx_O…...

700. 二叉搜索树中的搜索
原题链接700. 二叉搜索树中的搜索 思路: 给定的就是一个二叉搜索树 二叉搜索树是一个有序树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结…...

GO学习之 互斥锁、读写锁该如何取舍
GO系列 1、GO学习之Hello World 2、GO学习之入门语法 3、GO学习之切片操作 4、GO学习之 Map 操作 5、GO学习之 结构体 操作 6、GO学习之 通道(Channel) 7、GO学习之 多线程(goroutine) 8、GO学习之 函数(Function) 9、GO学习之 接口(Interface) 10、GO学习之 网络通信(Net/Htt…...

Internet的特点
Internet是一个全球性的计算机网络系统,它将全世界各个地方已有的各种网络(如计算机网、数据通信网以及公用电话交换网等)互联起来,组成一个跨越国界范围的庞大的互联网,因此,也称为“网络的网络”。Internet在很短的时间内风靡全…...

Rust4.2 Common Collections
Rust学习笔记 Rust编程语言入门教程课程笔记 参考教材: The Rust Programming Language (by Steve Klabnik and Carol Nichols, with contributions from the Rust Community) Lecture 8: Common Collections fn main() {//Vectorlet mut v: Vec<i32> Vec::new();//…...

芸鹰蓬飞:抖音投流以后还有自然流量吗?
随着抖音平台的普及,企业和个人纷纷加入到这个短视频的热潮中。然而,一旦投入抖音投流,是否还能依赖自然流量?这是许多用户和品牌关心的问题。本文将深入剖析这一话题,探讨抖音投流与自然流量之间的关系。 一、抖音投…...
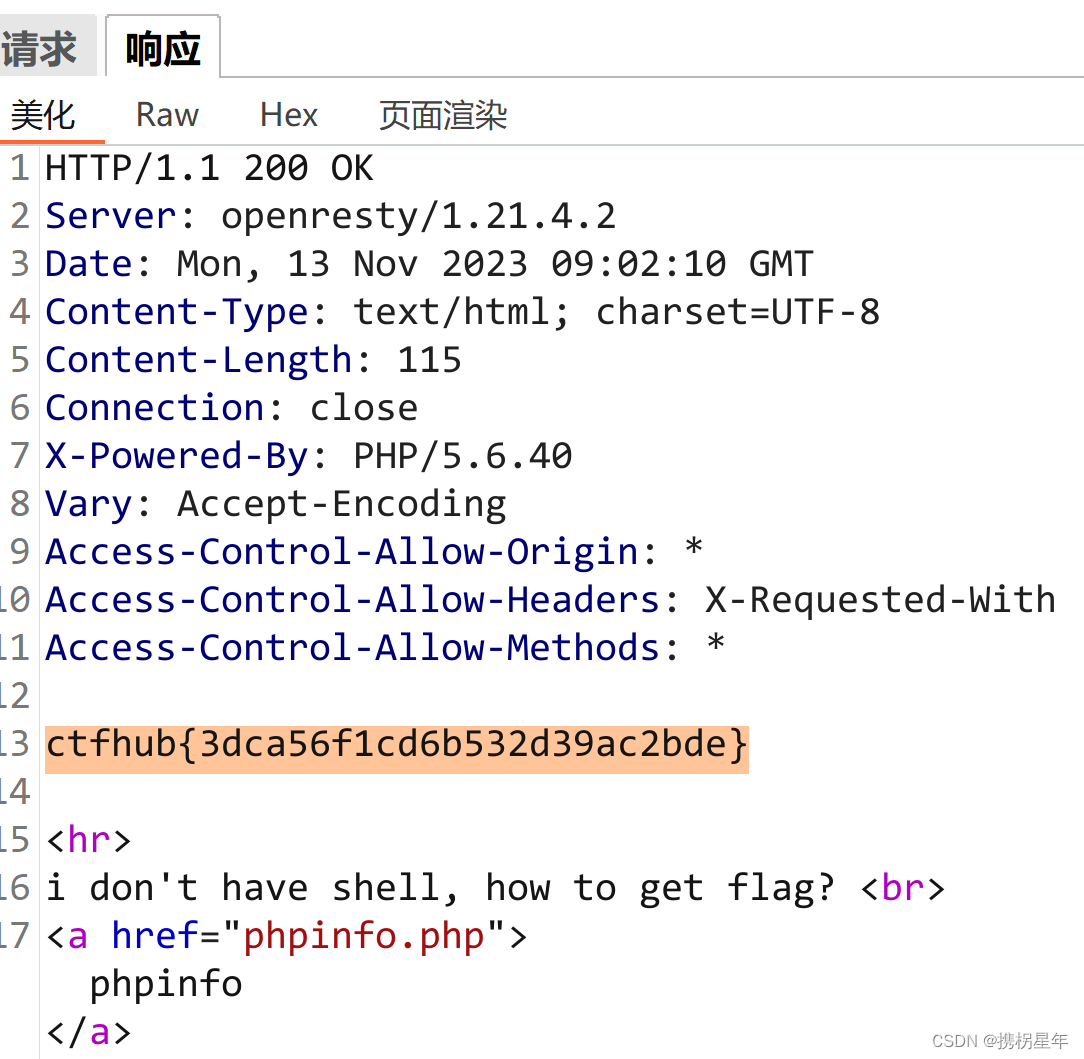
CTFhub-RCE-php://input
我们需要使用php://input来构造发送的指令 查看phpinfo,找到一下字段 证明是可以使用php://input 1. 使用Burpsuite抓包并转至Repeater 2. 构造包 方法:POST 目标:/?filephp://input Body:<?php system("ls /"…...

RISC-V处理器设计(五)—— 在 RISC-V 处理器上运行 C 程序
目录 一、前言 二、从 C 程序到机器指令 三、实验 3.1 实验环境 3.11 Windows 平台下环境搭建 3.12 Ubuntu 平台下环境搭建 3.13 实验涉及到的代码或目录 3.2 各文件作用介绍 3.2.1 link.lds 3.2.2 start.S 3.2.3 lib 和 include 目录 3.2.4 common.mk 3.2.5 demo …...
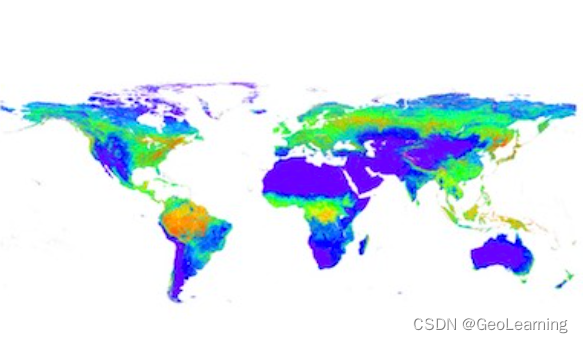
【PIE-Engine 数据资源】全球250米LAI产品
文章目录 一、 简介二、描述三、波段四、示例代码参考资料 一、 简介 数据名称全球250米LAI产品时间范围2015年空间范围全球数据来源北京师范大学肖志强教授团队代码片段var images pie.ImageCollection(“BNU/LAI/GLOBAL-250”) 二、描述 全球 250 米叶面指数产品由北京师范…...

vcomp120.dll丢失怎么办?vcomp120.dll丢失的解决方法分享
vcomp120.dll丢失”。这个错误通常会导致某些应用程序无法正常运行,给用户带来困扰。那么,当我们遇到这个问题时,应该如何修复呢?下面我将为大家介绍四个修复vcomp120.dll丢失的方法。 一、使用dll修复程序修复 可以通过百度或许…...

linux下使用Docker Compose部署Spug实现公网远程访问
📑前言 本文主要是linux下使用Docker Compose部署Spug实现公网远程访问的文章,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是青衿🥇 ☁️博客首页:CSDN主页放风讲故事 &am…...
【STM32 CAN】STM32G47x 单片机FDCAN作为普通CAN外设使用教程
STM32G47x 单片机FDCAN作为普通CAN外设使用教程 控制器局域网总线(CAN,Controller Area Network)是一种用于实时应用的串行通讯协议总线,它可以使用双绞线来传输信号,是世界上应用最广泛的现场总线之一。CAN协议用于汽…...

Apache Log4j2漏洞
Log4j2是一个Java日志组件,被各类Java框架广泛地使用。它的前身是Log4j,Log4j2重新构建和设计了框架,可以认为两者是完全独立的两个日志组件。本次漏洞影响范围为Log4j2最早期的版本2.0-beta9到2.15.0。Log4j2分为2个jar包,一个是接口log4j-api-${版本号}.jar,一个是具体实…...
超级干货:光纤知识总结最全的文章
你们好,我的网工朋友。 光纤已经是远距离有线信号传输的主要手段,而安装、维护光纤也是很多人网络布线的基本功。 在网络布线中,通常室外楼宇间幢与幢之间使用的是光缆,室内楼宇内部大都使用的是以太网双绞线,也有使用…...
PyCharm因安装了illuminated Cloud插件导致加载项目失败
打开Pycharm时会有弹窗提示: The license for Illuminated Cloud is invalid or has expired. All Illuminated Cloud features will be disabled. 这个弹窗会导致你加载项目一直失败,close project 也关不掉,我都是用任务管理器杀死进程的…...

微服务拆分的一些基本原则
文章首发公众号:海天二路搬砖工 单一职责原则 什么是单一职责原则 单一职责原则原本是面向对象设计中的一个基本原则,它指的是一个类只负责一项职责,不要存在多于一个导致类变更的原因。 在微服务架构中,一个微服务也应该只负…...

优化Blazor渲染逻辑的实践
在Blazor应用程序开发中,页面渲染逻辑的优化是提升用户体验的重要环节。特别是当页面包含多个条件渲染的组件时,如何高效地控制渲染流程成为了一个关键问题。本文将通过一个实际的案例,展示如何在Blazor中使用RenderFragment和return语句来优化页面渲染逻辑。 背景 假设我…...
)
告别手动转换!用Python脚本一键将Labelme关键点标注转为YOLO格式(附完整代码)
告别手动转换!用Python脚本一键将Labelme关键点标注转为YOLO格式(附完整代码) 在计算机视觉项目中,数据标注的格式转换往往是开发者最头疼的环节之一。特别是当项目涉及人体姿态估计、面部关键点检测等复杂任务时,标注…...
)
Mamba实战:如何用选择性状态空间模型提升你的长序列处理效率(附代码)
Mamba实战:如何用选择性状态空间模型提升你的长序列处理效率(附代码) 在自然语言处理、基因组学和金融时间序列分析等领域,处理长序列数据一直是个棘手的问题。传统Transformer架构虽然强大,但随着序列长度增加&#x…...

中文语音识别工具实测:Fun-ASR识别准确率对比,效果令人惊喜
中文语音识别工具实测:Fun-ASR识别准确率对比,效果令人惊喜 1. 为什么选择Fun-ASR进行测试? 在当今语音识别技术百花齐放的市场中,Fun-ASR作为钉钉联合通义实验室推出的开源语音识别系统,凭借其本地化部署、中文优化…...

手把手教你使用Qwen3.5推理模型:从部署到实战问答全流程
手把手教你使用Qwen3.5推理模型:从部署到实战问答全流程 1. 模型介绍与特点 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF 是一个基于 Qwen3.5-4B 的推理蒸馏模型,重点强化了结构化分析、分步骤回答、代码与逻辑类问题的处理能力。该版本以 G…...

**云迁移实战:基于Python自动化脚本实现从本地到AWS的无缝迁移**在当前数字化转型浪潮中,**云迁移已成为企业架构升级的核
云迁移实战:基于Python自动化脚本实现从本地到AWS的无缝迁移 在当前数字化转型浪潮中,云迁移已成为企业架构升级的核心路径之一。无论是为了提升弹性扩展能力、降低运维成本,还是增强灾备容灾水平,将传统部署环境迁移到云端都是大…...

React Native Interactable跨平台开发终极指南:iOS与Android差异处理技巧
React Native Interactable跨平台开发终极指南:iOS与Android差异处理技巧 【免费下载链接】react-native-interactable Experimental implementation of high performance interactable views in React Native 项目地址: https://gitcode.com/gh_mirrors/re/react…...

SaaS Boilerplate支付集成终极方案:Stripe订阅管理与计费系统完整指南
SaaS Boilerplate支付集成终极方案:Stripe订阅管理与计费系统完整指南 【免费下载链接】saas-boilerplate SaaS Boilerplate - Open Source and free SaaS stack that lets you build SaaS products faster in React, Django and AWS. Focus on essential business …...

终极ChatTTS语音合成指南:3分钟搭建本地AI语音系统 [特殊字符]
终极ChatTTS语音合成指南:3分钟搭建本地AI语音系统 🎤 【免费下载链接】ChatTTS-ui 一个简单的本地网页界面,使用ChatTTS将文字合成为语音,同时支持对外提供API接口。A simple native web interface that uses ChatTTS to synthes…...
)
别再说AI懂你了!先搞清楚AI中的Context到底是什么(上篇)
你有没有遇到过这种情况——跟ChatGPT聊了五句话,第四句你说了“那个方案不行”,第五句它问“哪个方案?”。或者你让AI写一篇关于“苹果”的文章,它给你写了一整页水果种植技术,而你想说的是苹果公司。这就是AI中的Con…...