竞赛 题目:基于FP-Growth的新闻挖掘算法系统的设计与实现
文章目录
- 0 前言
- 1 项目背景
- 2 算法架构
- 3 FP-Growth算法原理
- 3.1 FP树
- 3.2 算法过程
- 3.3 算法实现
- 3.3.1 构建FP树
- 3.4 从FP树中挖掘频繁项集
- 4 系统设计展示
- 5 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
基于FP-Growth的新闻挖掘算法系统的设计与实现
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 项目背景
如今新闻泛滥,令人眼花缭乱,即使同一话题下的新闻也多得数不胜数。人们可以根据自己的职业和爱好关注专业新闻网站的不同热点要闻。因此,通过对人们关注新闻的热点问题进行分析,可以得出民众对某个领域的关切程度和社会需要解决的问题,也有利于了解当前的舆论焦点,有助于政府了解民意,便于国家对舆论进行正确引导,使我们的社会更加安定和谐。本文以财经领域为例,通过爬虫技术抓取网络上的大量财经新闻,通过对新闻内容文本进行预处理及密度聚类分析来发现热点;从发现的热点中,再进行词汇聚类分析,得出热点所涉及的人或事物,以此分析出社会对经济领域关注的问题和需要解决的问题。

2 算法架构
该项目学长要通过文本挖掘技术进行新闻热点问题分析,把从网上抓取到的财经新闻,通过对新闻内容的聚类,得到新闻热点;再对热点进行分析,通过对某一热点相关词汇的聚类,得到热点问题所涉及的人物、行业或组织等。

1、利用新闻 API、爬虫算法、多线程并行技术,抓取三大专业财经新闻网站(新浪财经、搜狐财经、新华网财经)的大量财经新闻报道;
2、对新闻进行去重、时间段过滤,然后对新闻内容文本进行 jieba
分词并词性标注,过滤出名词、动词、简称等词性,分词前使用自定义的用户词词典增加分词的准确性,分词后使用停用词词典、消歧词典、保留单字词典过滤掉对话题无关并且影响聚类准确性的词,建立每篇新闻的词库,利用
TF-IDF 特征提取之后对新闻进行 DBSCAN 聚类,并对每个类的大小进行排序;
3、针对聚类后的每一类新闻,为了得到该处热点的话题信息,还需要提取它们的标题,利用 TextRank
算法,对标题的重要程度进行排序,用重要性最高的标题来描述该处热点的话题
4、对所有的新闻内容进行 jieba 分词,并训练出 word2vec 词嵌入模型,然后对聚类后的每一类新闻,提取它们的内容分词后的结果,运用
word2vec 模型得到每个词的词向量,再利用 FP-Growth类算法进行相关新闻挖掘。
3 FP-Growth算法原理
3.1 FP树
FP树是一种存储数据的树结构,如下图所示,每一路分支表示数据集的一个项集,数字表示该元素在某分支中出现的次数

3.2 算法过程
1 构建FP树
- 遍历数据集获得每个元素项的出现次数,去掉不满足最小支持度的元素项
- 构建FP树:读入每个项集并将其添加到一条已存在的路径中,若该路径不存在,则创建一条新路径(每条路径是一个无序集合)
2 从FP树中挖掘频繁项集
- 从FP树中获得条件模式基
- 利用条件模式基构建相应元素的条件FP树,迭代直到树包含一个元素项为止
算法过程写得比较简略,具体过程我们在下节的实操中进一步理解。
3.3 算法实现
3.3.1 构建FP树
class treeNode:def __init__(self,nameValue,numOccur,parentNode):self.name=nameValue #节点名self.count=numOccur #节点元素出现次数self.nodeLink=None #存放节点链表中,与该节点相连的下一个元素self.parent=parentNodeself.children={} #用于存放节点的子节点,value为子节点名def inc(self,numOccur):self.count+=numOccurdef disp(self,ind=1):print(" "*ind,self.name,self.count) #输出一行节点名和节点元素数,缩进表示该行节点所处树的深度for child in self.children.values():child.disp(ind+1) #对于子节点,深度+1# 构造FP树# dataSet为字典类型,表示探索频繁项集的数据集,keys为各项集,values为各项集在数据集中出现的次数# minSup为最小支持度,构造FP树的第一步是计算数据集各元素的支持度,选择满足最小支持度的元素进入下一步def createTree(dataSet,minSup=1):headerTable={}#遍历各项集,统计数据集中各元素的出现次数for key in dataSet.keys():for item in key:headerTable[item]=headerTable.get(item,0)+dataSet[key] #遍历各元素,删除不满足最小支持度的元素for key in list(headerTable.keys()):if headerTable[key]<minSup:del headerTable[key]freqItemSet=set(headerTable.keys())#若没有元素满足最小支持度要求,返回None,结束函数if len(freqItemSet)==0:return None,Nonefor key in headerTable.keys():headerTable[key]=[headerTable[key],None] #[元素出现次数,**指向每种项集第一个元素项的指针**]retTree=treeNode("Null Set",1,None) #初始化FP树的顶端节点for tranSet,count in dataSet.items():localD={} #存放每次循环中的频繁元素及其出现次数,便于利用全局出现次数对各项集元素进行项集内排序for item in tranSet:if item in freqItemSet:localD[item]=headerTable[item][0]if len(localD)>0:orderedItems=[v[0] for v in sorted(localD.items(),key=operator.itemgetter(1),reverse=True)] #根据元素全局出现次数对每个项集(tranSet)中的元素进行排序updateTree(orderedItems,retTree,headerTable,count) #使用排序后的项集对树进行填充return retTree,headerTable#树的更新函数#items为按出现次数排序后的项集,是待更新到树中的项集;count为items项集在数据集中的出现次数#inTree为待被更新的树;headTable为头指针表,存放满足最小支持度要求的所有元素def updateTree(items,inTree,headerTable,count):#若项集items当前最频繁的元素在已有树的子节点中,则直接增加树子节点的计数值,增加值为items[0]的出现次数if items[0] in inTree.children: inTree.children[items[0]].inc(count)else:#若项集items当前最频繁的元素不在已有树的子节点中(即,树分支不存在),则通过treeNode类新增一个子节点inTree.children[items[0]]=treeNode(items[0],count,inTree)#若新增节点后表头表中没有此元素,则将该新增节点作为表头元素加入表头表if headerTable[items[0]][1]==None: headerTable[items[0]][1]=inTree.children[items[0]]else:#若新增节点后表头表中有此元素,则更新该元素的链表,即,在该元素链表末尾增加该元素updateHeader(headerTable[items[0]][1],inTree.children[items[0]])#对于项集items元素个数多于1的情况,对剩下的元素迭代updateTreeif len(items)>1:updateTree(items[1::],inTree.children[items[0]],headerTable,count)#元素链表更新函数#nodeToTest为待被更新的元素链表的头部#targetNode为待加入到元素链表的元素节点def updateHeader(nodeToTest,targetNode):#若待被更新的元素链表当前元素的下一个元素不为空,则一直迭代寻找该元素链表的末位元素while nodeToTest.nodeLink!=None: nodeToTest=nodeToTest.nodeLink #类似撸绳子,从首位一个一个逐渐撸到末位#找到该元素链表的末尾元素后,在此元素后追加targetNode为该元素链表的新末尾元素nodeToTest.nodeLink=targetNode测试
#加载简单数据集
def loadSimpDat():simpDat = [['r', 'z', 'h', 'j', 'p'],['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],['z'],['r', 'x', 'n', 'o', 's'],['y', 'r', 'x', 'z', 'q', 't', 'p'],['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]return simpDat#将列表格式的数据集转化为字典格式
def createInitSet(dataSet):retDict={}for trans in dataSet:retDict[frozenset(trans)]=1return retDictsimpDat=loadSimpDat()
dataSet=createInitSet(simpDat)
myFPtree1,myHeaderTab1=createTree(dataSet,minSup=3)
myFPtree1.disp(),myHeaderTab1
输入数据:

由此数据集构建的FP树长这样,看看是不是满足上一节介绍的FP树结构

3.4 从FP树中挖掘频繁项集
具体过程如下:
1 从FP树中获得条件模式基
- 条件模式基:以所查找元素项为结尾的路径集合,每条路径都是一条前缀路径,路径集合包括前缀路径和路径计数值。
- 例如,元素"r"的条件模式基为 {x,s}2,{z,x,y}1,{z}1
- 前缀路径:介于所查找元素和树根节点之间的所有内容
- 路径计数值:等于该条前缀路径的起始元素项(即所查找的元素)的计数值
2 利用条件模式基构建相应元素的条件FP树
- 对每个频繁项,都要创建一棵条件FP树。
- 例如对元素t创建条件FP树:使用获得的t元素的条件模式基作为输入,利用构建FP树相同的逻辑构建元素t的条件FP树
3 迭代步骤(1)(2),直到树包含一个元素项为止
-
接下来继续构建{t,x}{t,y}{t,z}对应的条件FP树(tx,ty,tz为t条件FP树的频繁项集),直到条件FP树中没有元素为止
-
至此可以得到与元素t相关的频繁项集,包括2元素项集、3元素项集。。。
#由叶节点回溯该叶节点所在的整条路径 #leafNode为叶节点,treeNode格式;prefixPath为该叶节点的前缀路径集合,列表格式,在调用该函数前注意prefixPath的已有内容 def ascendTree(leafNode,prefixPath):if leafNode.parent!=None:prefixPath.append(leafNode.name)ascendTree(leafNode.parent,prefixPath)#获得指定元素的条件模式基 #basePat为指定元素;treeNode为指定元素链表的第一个元素节点,如指定"r"元素,则treeNode为r元素链表的第一个r节点 def findPrefixPath(basePat,treeNode):condPats={} #存放指定元素的条件模式基while treeNode!=None: #当元素链表指向的节点不为空时(即,尚未遍历完指定元素的链表时)prefixPath=[]ascendTree(treeNode,prefixPath) #回溯该元素当前节点的前缀路径if len(prefixPath)>1:condPats[frozenset(prefixPath[1:])]=treeNode.count #构造该元素当前节点的条件模式基treeNode=treeNode.nodeLink #指向该元素链表的下一个元素return condPats#有FP树挖掘频繁项集 #inTree: 构建好的整个数据集的FP树 #headerTable: FP树的头指针表 #minSup: 最小支持度,用于构建条件FP树 #preFix: 新增频繁项集的缓存表,set([])格式 #freqItemList: 频繁项集集合,list格式def mineTree(inTree,headerTable,minSup,preFix,freqItemList):#按头指针表中元素出现次数升序排序,即,从头指针表底端开始寻找频繁项集bigL=[v[0] for v in sorted(headerTable.items(),key=lambda p:p[1][0])] for basePat in bigL:#将当前深度的频繁项追加到已有频繁项集中,然后将此频繁项集追加到频繁项集列表中newFreqSet=preFix.copy()newFreqSet.add(basePat)print("freqItemList add newFreqSet",newFreqSet)freqItemList.append(newFreqSet)#获取当前频繁项的条件模式基condPatBases=findPrefixPath(basePat,headerTable[basePat][1])#利用当前频繁项的条件模式基构建条件FP树myCondTree,myHead=createTree(condPatBases,minSup)#迭代,直到当前频繁项的条件FP树为空if myHead!=None:mineTree(myCondTree,myHead,minSup,newFreqSet,freqItemList)
接着刚才构建的FP树,测试一下,
freqItems=[]
mineTree(myFPtree1,myHeaderTab1,3,set([]),freqItems)
freqItems
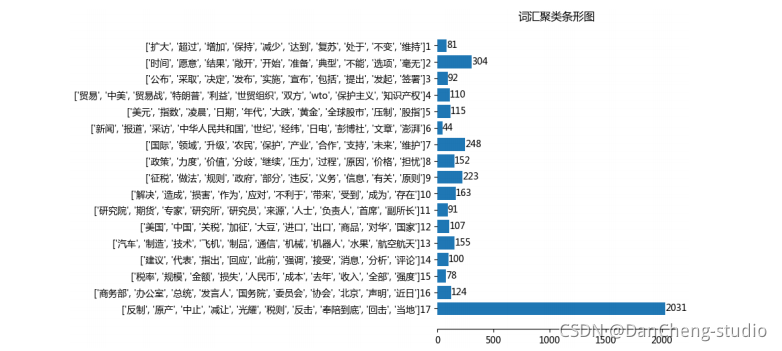
我们从FP树中挖掘到的频繁项集如下,这里设置的最小支持度为3:

上图表示数据集中,支持度大于3(出现3次以上)的元素项集,即,频繁项集。
4 系统设计展示
为了方便操作及理解,学长使用 Python 的 tkinter 模块设计了一个系统操作界面

分析可视化




(未完待续。。。。)
5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛 题目:基于FP-Growth的新闻挖掘算法系统的设计与实现
文章目录 0 前言1 项目背景2 算法架构3 FP-Growth算法原理3.1 FP树3.2 算法过程3.3 算法实现3.3.1 构建FP树 3.4 从FP树中挖掘频繁项集 4 系统设计展示5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 基于FP-Growth的新闻挖掘算法系统的设计与实现…...

保姆级jupyter lab配置清单
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...
数据结构预算法--链表(单链表,双向链表)
1.链表 目录 1.链表 1.1链表的概念及结构 1.2 链表的分类 2.单链表的实现(不带哨兵位) 2.1接口函数 2.2函数的实现 3.双向链表的实现(带哨兵位) 3.1接口函数 3.2函数的实现 1.1链表的概念及结构 概念:链表是一种物理存储结…...

数据结构线性表——栈
前言:哈喽小伙伴们,今天我们将一起进入数据结构线性表的第四篇章——栈的讲解,栈还是比较简单的哦,跟紧博主的思路,不要掉队哦。 目录 一.什么是栈 二.如何实现栈 三.栈的实现 栈的初始化 四.栈的操作 1.数据入栈…...

自定义 springboot 启动器 starter 与自动装配原理
Maven 依赖 classpath 类路径管理 Maven 项目中的类路径添加来源分为三类 自定义 springboot starter starter 启动器定义的规则自定义 starter 示例 自动装配 文章链接...

16 _ 二分查找(下):如何快速定位IP对应的省份地址?
通过IP地址来查找IP归属地的功能,不知道你有没有用过?没用过也没关系,你现在可以打开百度,在搜索框里随便输一个IP地址,就会看到它的归属地。 这个功能并不复杂,它是通过维护一个很大的IP地址库来实现的。地址库中包括IP地址范围和归属地的对应关系。 当我们想要查询202…...

vb.net圣经带快捷键,用原装的数据库
Imports System.Data.SqlServerCe Imports System.Text.RegularExpressions Imports System.Data.OleDbPublic Class Form1Dim jiuyue As String() {"创", "出", "利", "民", "申", "书", "士", "…...
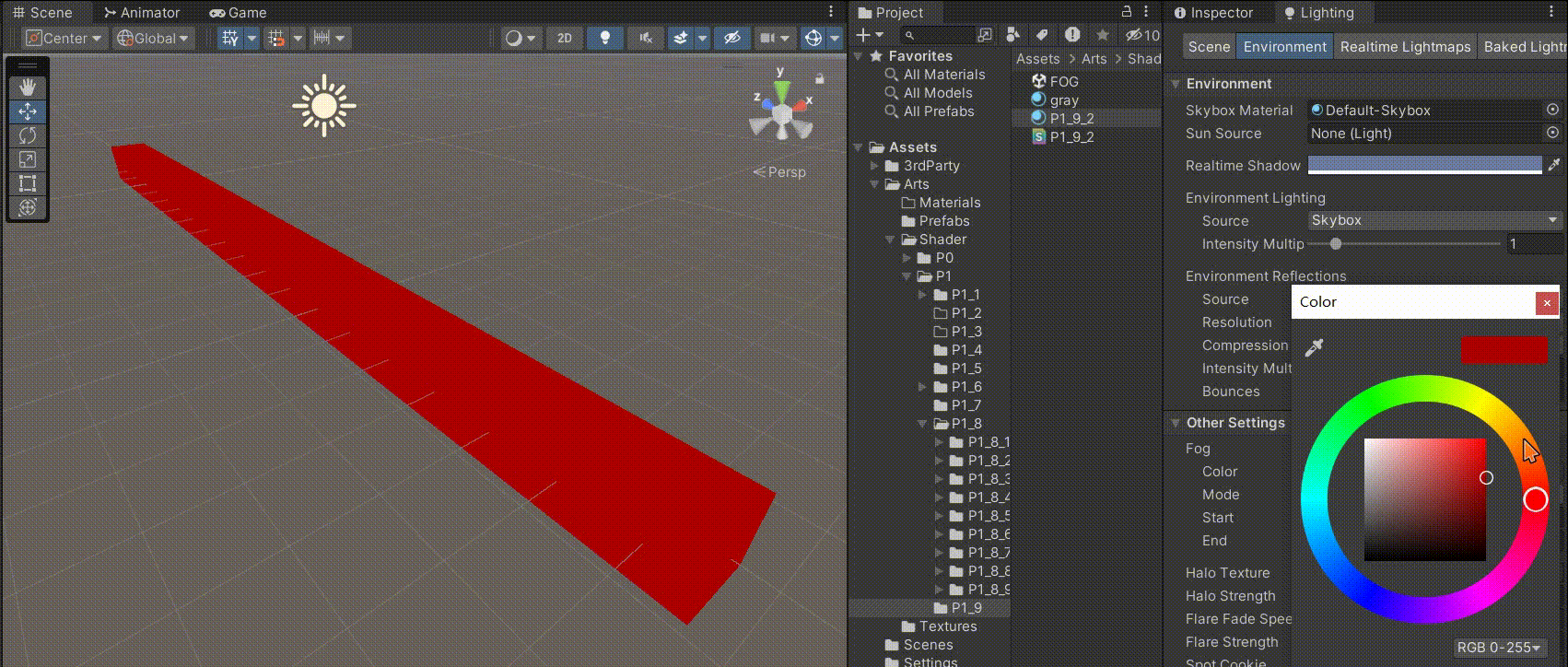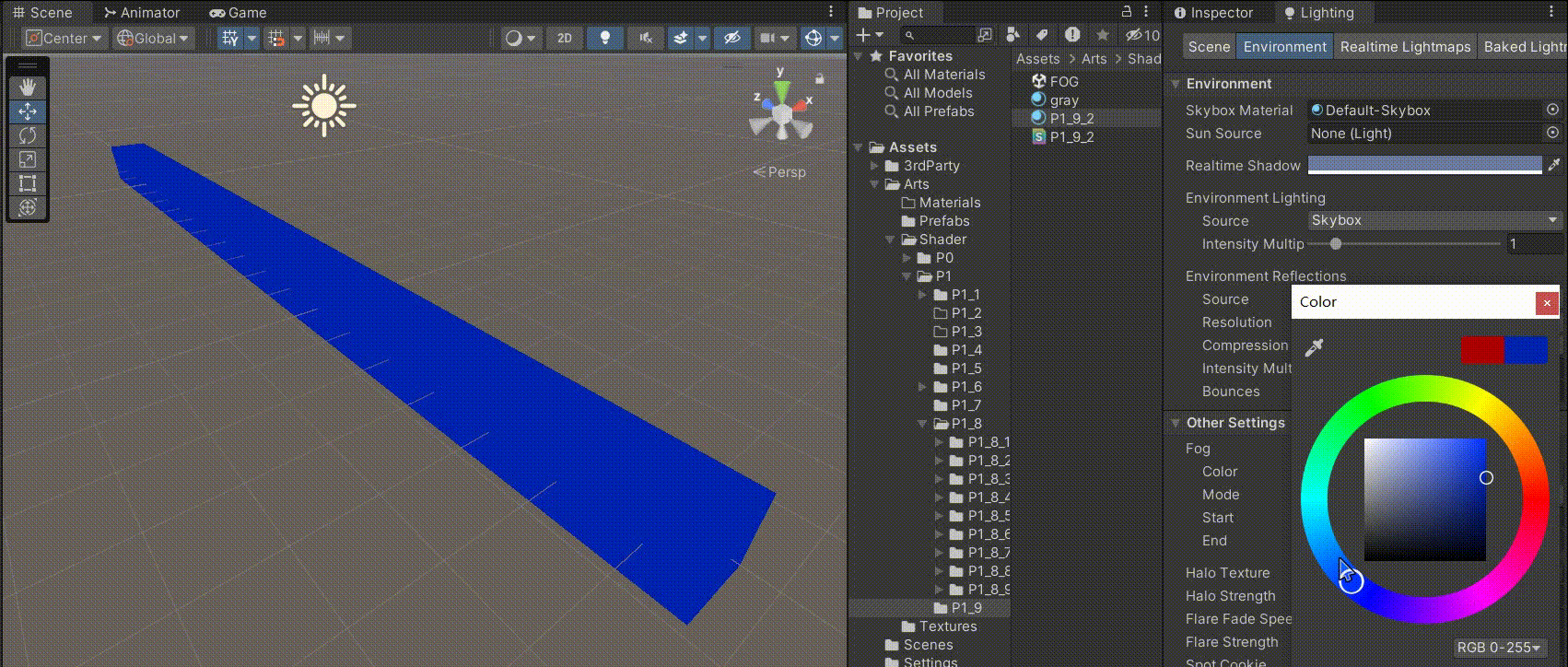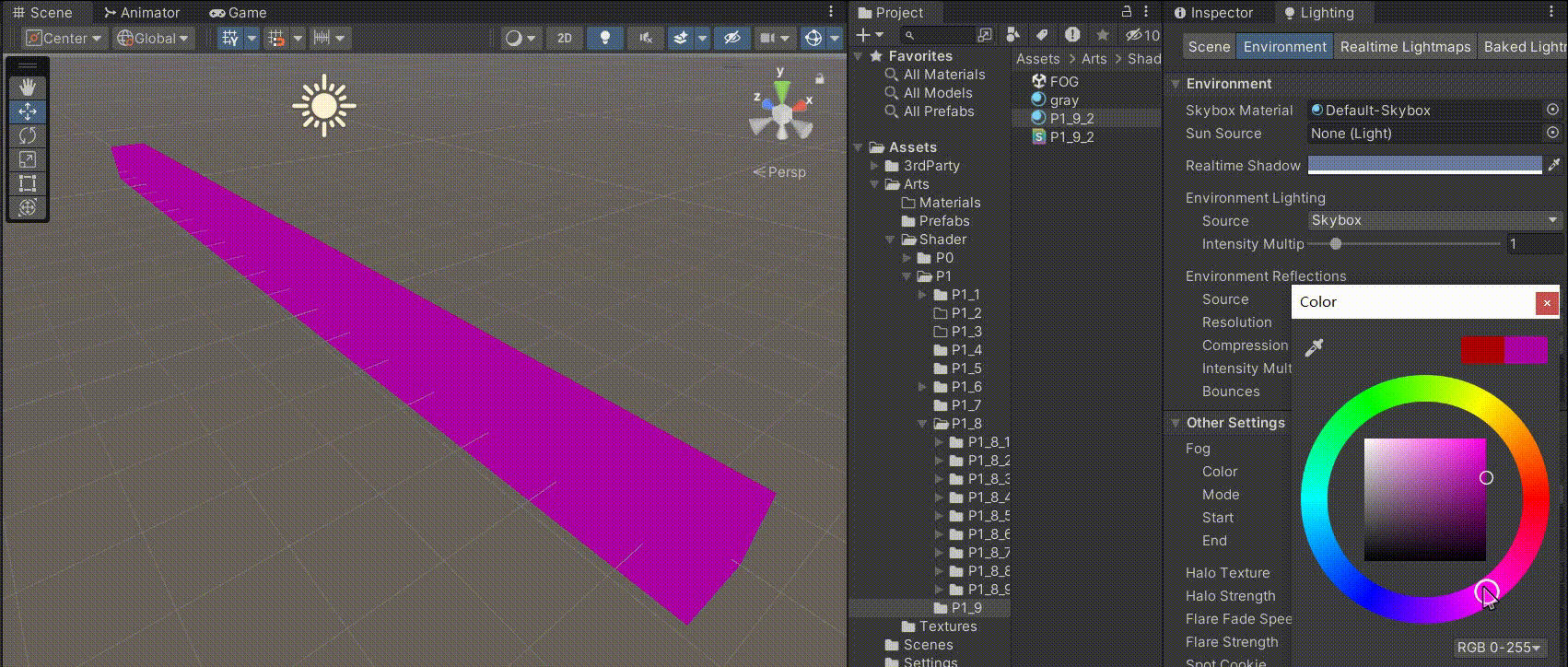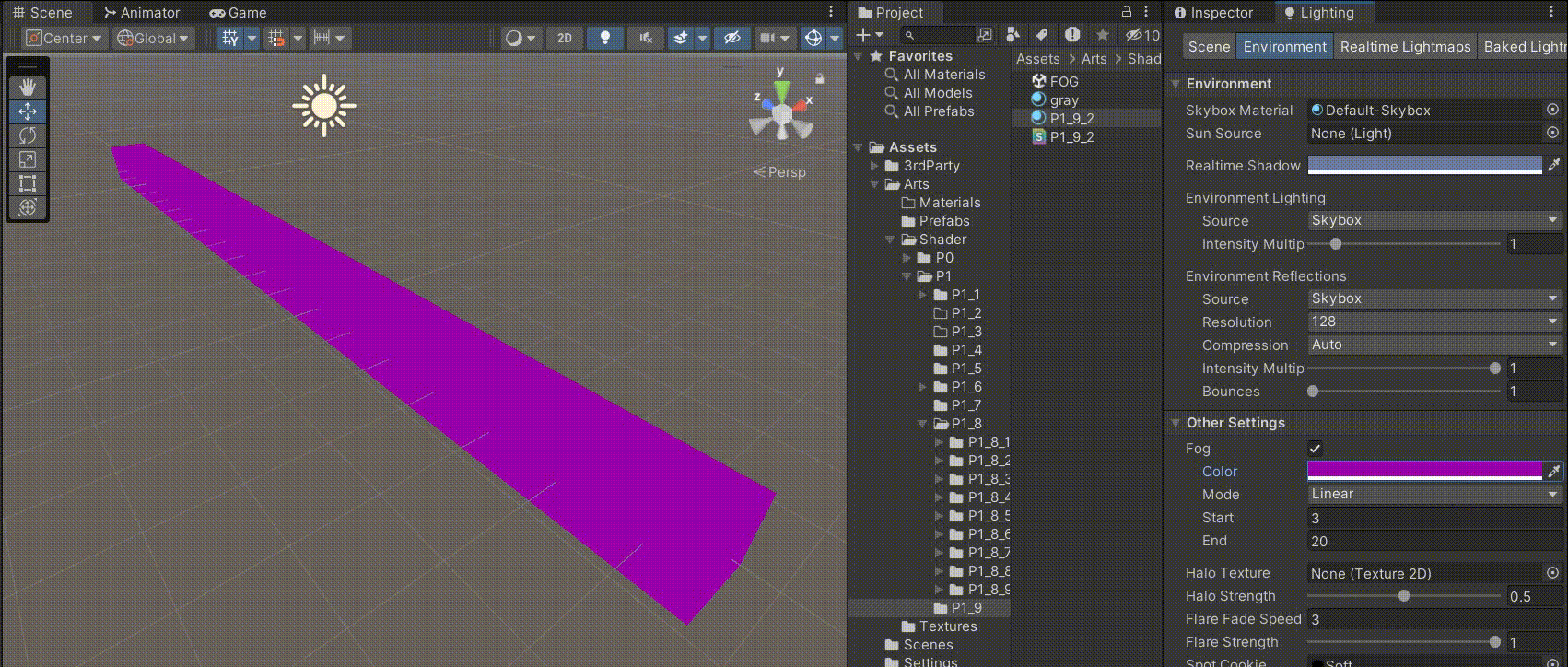
Unity中Shader的雾效
文章目录 前言一、Unity中的雾效在哪开启二、Unity中不同种类雾的区别1、线性雾2、指数雾1(推荐用这个,兼具效果和性能)3、指数雾2(效果更真实,性能消耗多) 三、在我们自己的Shader中实现判断,是…...

企业微信开发教程一:添加企微应用流程图解以及常见问题图文说明
最近在前辈的基础上新添加了一个企微应用,过程中遇到了一些卡点,这里一一通过图片标注与注释的方式记录一下,希望能给后来人提供一些清晰明了的帮助,话不多说,大家直接看图吧。 (文中包括一些本项目独有的配…...

【LeetCode】67. 二进制求和
67. 二进制求和 难度:简单 题目 给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 示例 1: 输入:a "11", b "1" 输出:"100"示例 2: 输入:a "…...

【LeetCode刷题笔记】二叉树(一)
102. 二叉树的层序遍历 解题思路: 1. BFS广度优先遍历 ,使用队列,按层访问 解题思路: 2. 前序遍历 , 递归 ,在递归方法参数中,将 层索引...

NativeScript开发ios应用,怎么生成测试程序?
在 NativeScript 中,要部署 iOS 应用程序,你需要遵循以下一般步骤: 1、确保开发环境: 确保你的开发环境中已经安装了 Xcode,并且你有一个有效的 Apple 开发者账号。 2、构建 iOS 应用: 在你的 NativeScri…...

Js面试题:说一下js的模块化?
作用: 一个模块就是实现某个特定功能的文件,在文件中定义的变量、函数、类都是私有的,对其他文件不可见。 为了解决引入多个js文件时,出现 命名冲突、污染作用域 等问题 AMD: 浏览器端模块解决方案 AMD即是“异步模块定…...
媒体转码软件Media Encoder 2024 mac中文版功能介绍
Media Encoder 2024 mac是一款媒体转码软件,它可以将视频从一种格式转码为另一种格式,支持H.265、HDR10等多种编码格式,同时优化了视频质量,提高了编码速度。此外,Media Encoder 2024还支持收录、创建代理和输出各种格…...

整治PPOCRLabel中cv2文件读取问题(更新中)
PPOCRLabel 使用PPOCRLabel对ocr预标注结果进行纠正由于PaddleOCR代码库十分混乱,路径经常乱调pip和代码库的代码(pip库和源码冲突),经常报错,因此paddleocr和ppocrlabel都是使用pip包;PPOCRLabel中使用了cv2进行图片数据的读取,…...

网络运维Day09-补充
文章目录 rsync增量同步scp与rsync的区别rsync常用选项 rsync本地实验rsync远程同步实验练习上传练习下载 总结 rsync增量同步 rsync是增量同步的一种工具,可以实现本地目录之间数据同步,也可以实现远程跨主机之间数据同步 scp与rsync的区别 scp属于全…...
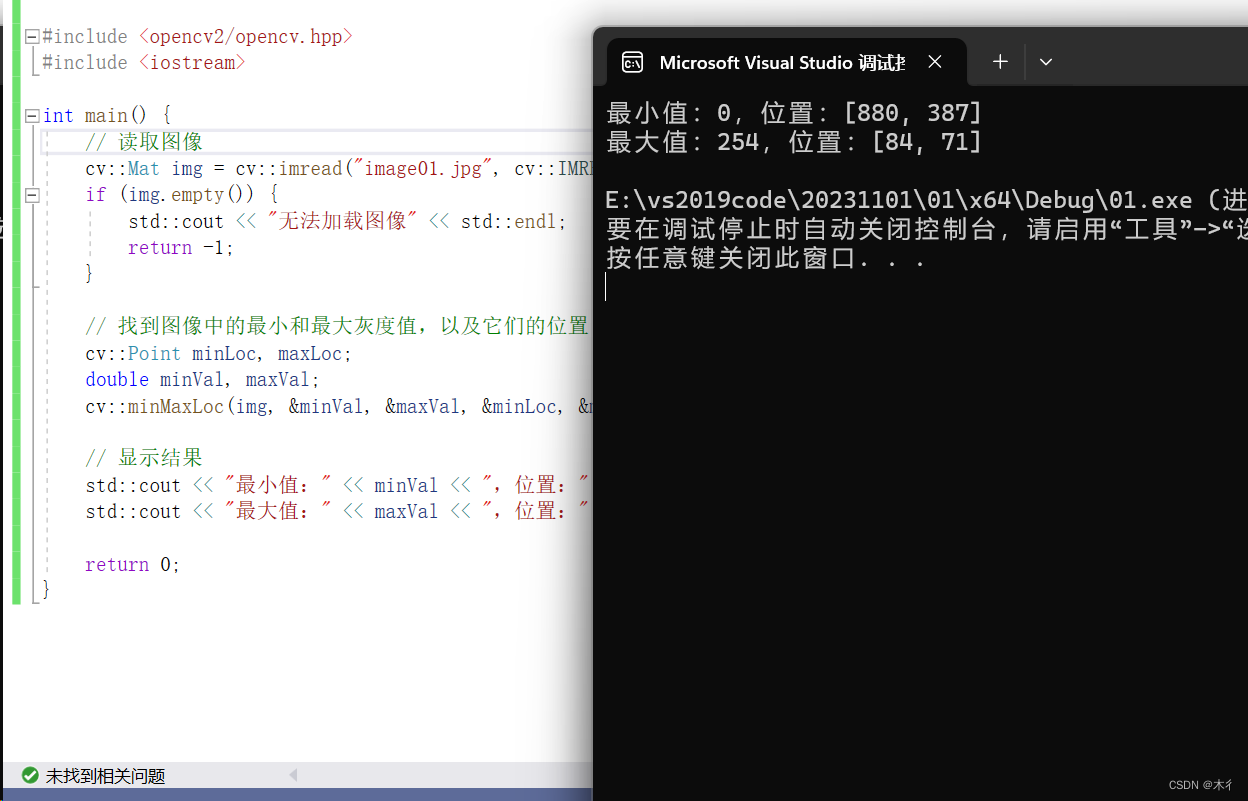
【C++】【Opencv】minMaxLoc()函数详解和示例
minMaxLoc()函数 是 OpenCV 库中的一个函数,用于找到一个多维数组中的最小值和最大值,以及它们的位置。这个函数对于处理图像和数组非常有用。本文通过参数和示例详解,帮助大家理解和使用该函数。 参数详解 函数原型…...
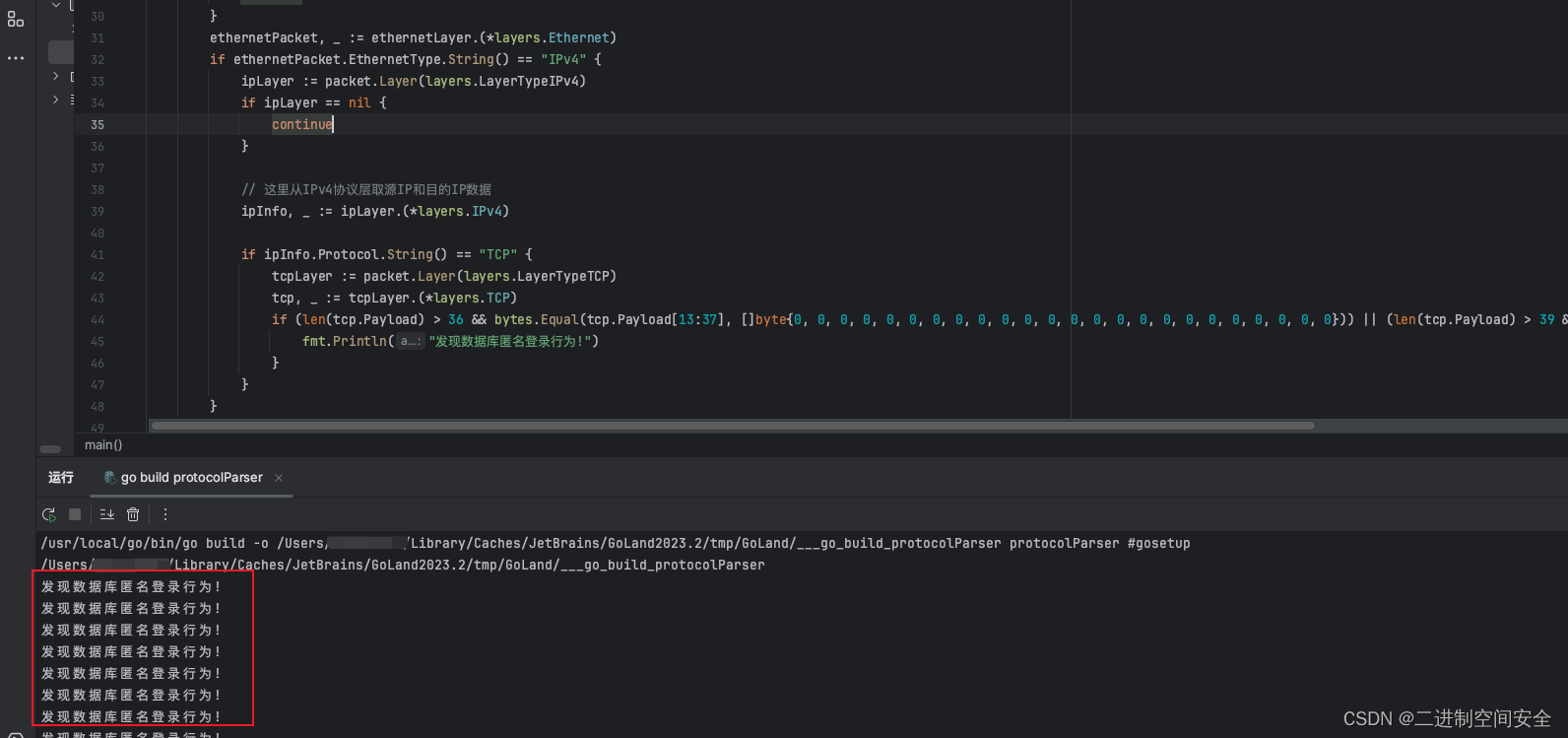
用Go实现网络流量解析和行为检测引擎
1.前言 最近有个在学校读书的迷弟问我:大德德, 有没有这么一款软件, 能够批量读取多个抓包文件,并把我想要的数据呈现出来, 比如:源IP、目的IP、源mac地址、目的mac地址等等。我说:“这样的软件你要认真找真能找出不少开源软件, 但毕竟没有你自己的灵魂在里面,要不…...

Mysql数据备份 — mysqldump
一 备份类型 - 逻辑备份(mysqldump): - 优点: - 恢复简单,可以使用管道将他们输入到mysql。 - 与存储引擎无关,因为是从MySQL服务器中提取数据而生成的,所以消除了底层数据…...

vue使用Echarts5实现词云图
先上官网 词云图有些特殊,它属于Echarts 的扩展,需要额外安装Echarts-wordcloud包。 Echarts 官网 Echarts-wordcloud 词云图官网 先安装 npm install echarts npm install echarts-wordcloud再引入 echarts选一个引入就行;4或5版本都可以 …...

OpenClaw定时任务管理:千问3.5-35B-A3B-FP8实现早间资讯自动推送
OpenClaw定时任务管理:千问3.5-35B-A3B-FP8实现早间资讯自动推送 1. 为什么需要自动化资讯推送 每天早上打开电脑第一件事,就是查看行业动态和技术新闻。但手动检索各大平台、整理关键信息要耗费20多分钟,经常打乱晨间工作节奏。直到发现Op…...

Qwen3-ForcedAligner-0.6B模型量化实战:减小部署体积
Qwen3-ForcedAligner-0.6B模型量化实战:减小部署体积 语音处理中的强制对齐技术,能够精确匹配文本与语音的时间戳,是语音识别、字幕生成等应用的关键环节。Qwen3-ForcedAligner-0.6B作为一款基于大语言模型的强制对齐工具,支持11种…...

北京天文馆新馆玻璃幕墙及玻璃旋体设计与施工技术
北京天文馆新馆玻璃幕墙及玻璃旋体设计与施工技术 摘要:本文对北京天文馆新馆异形玻璃幕墙及采光顶、马鞍形玻璃通道和 四个体形各异的玻璃旋体,在设计和施工中碰到的技术难题及解决方案作了详细的介绍,特别是对异形钢结构和不规则双曲面玻璃的加工制作以及特殊节点的外观…...

SEO 项目如何进行链接建设_SEO 项目如何进行品牌形象优化
SEO 项目如何进行链接建设_SEO 项目如何进行品牌形象优化 SEO 项目如何进行链接建设 在当今的互联网时代,网站的流量和排名直接关系到企业的发展和市场竞争力。其中,搜索引擎优化(SEO)是提升网站在搜索引擎中的排名的重要手段。…...

【GD32F407】内部Flash高效读写策略与实战优化
1. GD32F407内部Flash特性解析 GD32F407作为国产MCU中的明星产品,其内部Flash设计颇具特色。第一次拿到芯片手册时,我发现它的存储架构比想象中复杂得多。最让我印象深刻的是前512KB空间的零等待特性——这意味着在此范围内的代码执行速度堪比RAM&#x…...

CubeIDE用户看过来:当你的STM32板载CMSIS-DAP不被支持时,3种实用的替代烧录方案
CubeIDE用户实战指南:当CMSIS-DAP不被支持时的3种高效烧录方案 作为一名长期使用STM32CubeIDE的开发者,你一定遇到过这样的尴尬场景——手头的开发板明明集成了CMSIS-DAP仿真器,却因为CubeIDE的兼容性问题无法直接使用。这种"看得见却用…...
)
新手必看:用Wireshark分析CTF流量包的5个实战技巧(附BUUCTF真题解析)
新手必看:用Wireshark分析CTF流量包的5个实战技巧(附BUUCTF真题解析) 当你第一次打开一个陌生的pcap文件时,面对密密麻麻的数据包列表,是不是感觉无从下手?作为CTF比赛中最常见的题型之一,流量分…...

Perl环境变量设置全攻略:从银河麒麟V10到CentOS的通用配置方法
Perl环境变量跨平台配置实战指南 在混合云和异构系统环境中,Perl作为系统管理和应用开发的重要工具,其环境配置的一致性直接影响脚本的跨平台运行能力。本文将深入探讨从银河麒麟V10到CentOS等主流Linux发行版的Perl环境变量配置方法论,帮助运…...

大模型微调终极指南:从基础概念到实战技巧
前言 近年来,大语言模型(LLM)的爆发式发展正在深刻改变人工智能的格局。然而,如何将这些通用模型适配到特定领域和任务,成为了开发者面临的核心挑战。本文将系统性地梳理大模型后训练的核心方法,从监督微调…...
)
告别Keil C51安装烦恼:STC8单片机开发环境保姆级配置指南(含芯片包添加)
从零搭建STC8开发环境:Keil C51避坑指南与实战技巧 第一次接触STC8单片机时,最让人头疼的莫过于开发环境的搭建。网上教程要么过于简略,要么步骤不全,总会在某个环节卡住——可能是Keil安装报错,可能是芯片包添加失败&…...