【chatglm3】(3):在AutoDL上,使用4090显卡,部署ChatGLM3API服务,并微调AdvertiseGen数据集,完成微调并测试成功!附视频演示。
在AutoDL上,使用4090显卡,部署ChatGLM3API服务,并微调AdvertiseGen数据集,完成微调并测试成功!
其他chatgpt 和chatglm3 资料:
https://blog.csdn.net/freewebsys/category_12270092.html
视频地址:
https://www.bilibili.com/video/BV1zQ4y1t7x7/?vd_source=4b290247452adda4e56d84b659b0c8a2
在AutoDL上,使用4090显卡,部署ChatGLM3API服务,并微调AdvertiseGen数据集,完成微调并测试成功!
1,显卡市场,租个显卡性价比最高!
https://www.autodl.com/
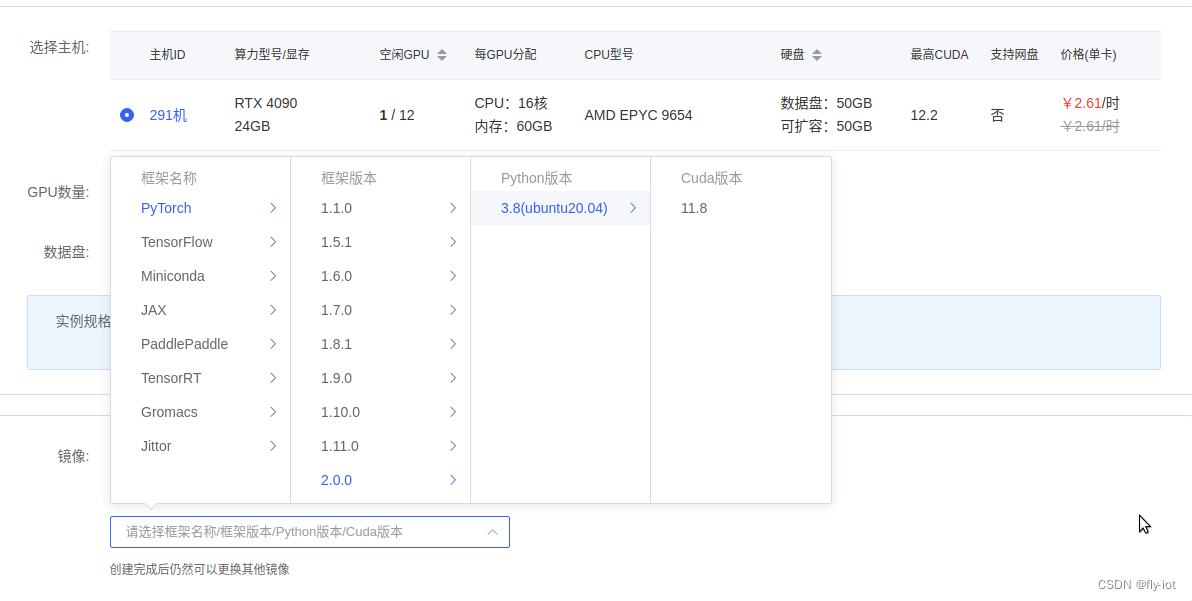
创建完成可以使用 juypter 进入:
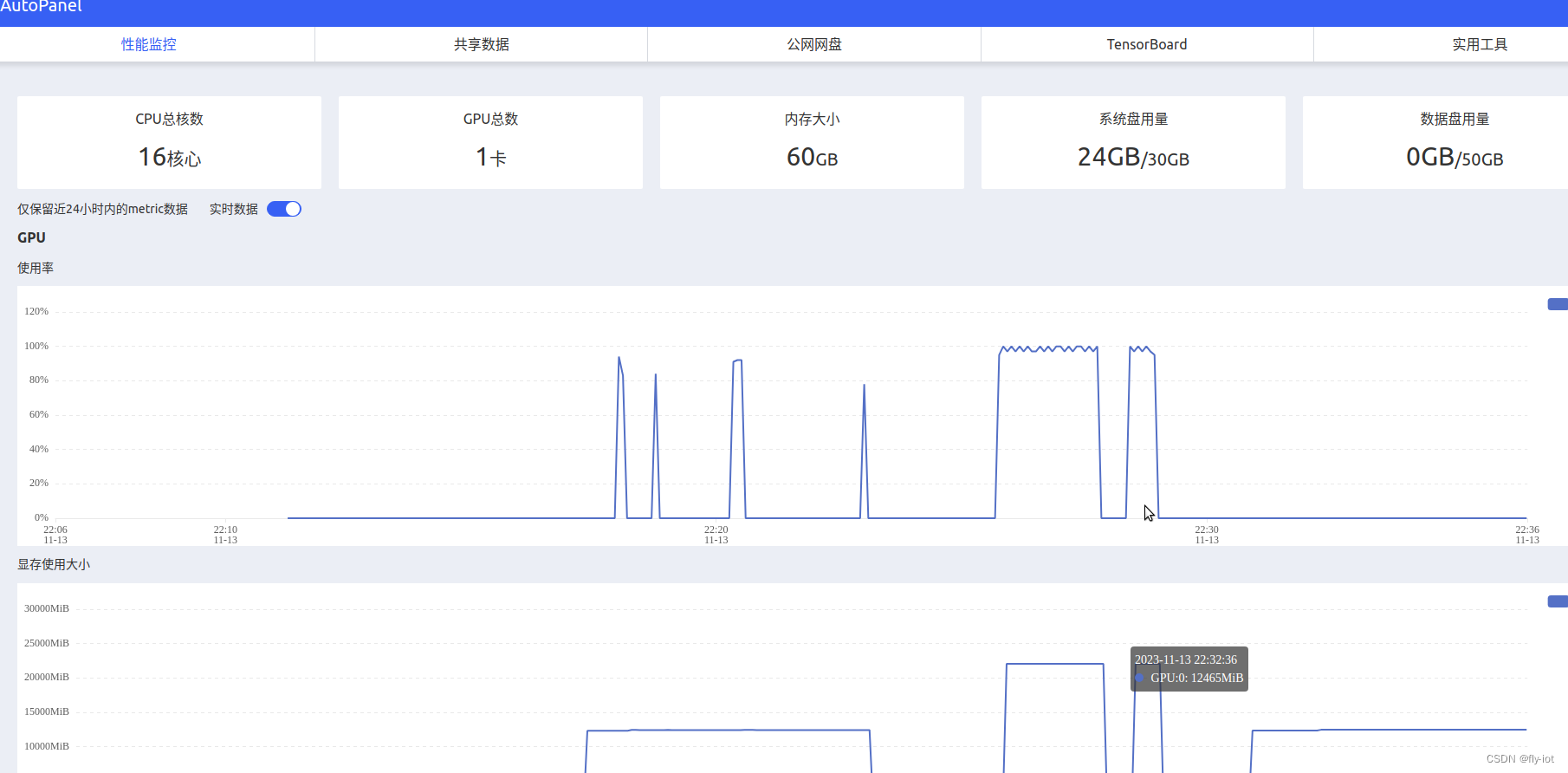
也可以监控服务器运行状况:
2,下载源代码,下载模型,启动服务
下载模型速度超级快 :
apt update && apt install git-lfs -y
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git chatglm3-6b-models
Cloning into 'chatglm3-6b-models'...
remote: Enumerating objects: 101, done.
remote: Counting objects: 100% (101/101), done.
remote: Compressing objects: 100% (58/58), done.
remote: Total 101 (delta 42), reused 89 (delta 38), pack-reused 0
Receiving objects: 100% (101/101), 40.42 KiB | 1.84 MiB/s, done.
Resolving deltas: 100% (42/42), done.
Filtering content: 100% (8/8), 11.63 GiB | 203.56 MiB/s, done.
再下载github 项目:
https://github.com/THUDM/ChatGLM3/tree/main
或者上传代码
然后安装依赖库:
# 安装完成才可以启动:
pip3 install uvicorn fastapi loguru sse_starlette transformers sentencepiece
cd /root/ChatGLM3-main/openai_api_demo
python3 openai_api.py
启动成功,端口 8000
可以运行命令进行测试:
curl http://localhost:8000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "chatglm3-6b","messages": [{"role": "user", "content": "北京景点"}],"temperature": 0.7}'
3,使用脚本进行token测试,速度50 tokens/s 速度挺快的
然后使用测试脚本进行 token 测试,修改的 fastcaht的测试脚本:
# coding=utf-8
"""token测试工具:python3 test_throughput.py
或者:
python3 test_throughput.py --api-address http://localhost:8000 --n-thread 20"""
import argparse
import jsonimport requests
import threading
import timedef main():headers = {"User-Agent": "openai client", "Content-Type": "application/json"}ploads = {"model": args.model_name,"messages": [{"role": "user", "content": "生成一个50字的故事,内容随即生成。"}],"temperature": 1,}thread_api_addr = args.api_addressdef send_request(results, i):print(f"thread {i} goes to {thread_api_addr}")response = requests.post(thread_api_addr + "/v1/chat/completions",headers=headers,json=ploads,stream=False,)print(response.text)response_new_words = json.loads(response.text)["usage"]["completion_tokens"]print(f"=== Thread {i} ===, words: {response_new_words} ")results[i] = response_new_words# use N threads to prompt the backendtik = time.time()threads = []results = [None] * args.n_threadfor i in range(args.n_thread):t = threading.Thread(target=send_request, args=(results, i))t.start()# time.sleep(0.5)threads.append(t)for t in threads:t.join()print(f"Time (POST): {time.time() - tik} s")n_words = sum(results)time_seconds = time.time() - tikprint(f"Time (Completion): {time_seconds}, n threads: {args.n_thread}, "f"throughput: {n_words / time_seconds} words/s.")if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--api-address", type=str, default="http://localhost:8000")parser.add_argument("--model-name", type=str, default="chatglm3-6b")parser.add_argument("--n-thread", type=int, default=10)args = parser.parse_args()main()
测下下服务:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.06 Driver Version: 545.23.06 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 On | 00000000:42:00.0 Off | Off |
| 30% 39C P2 56W / 450W | 12429MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------++---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
速度特别快:
Time (POST): 22.13719415664673 s
Time (Completion): 22.137234687805176, n threads: 10, throughput: 51.22591037193507 words/s.
完全可以满足内部使用了。
3,下载微调数据,并进行模型训练
https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
AdvertiseGen以商品网页的标签与文案的信息对应关系为基础构造
载处理好的 AdvertiseGen 数据集,将解压后的 AdvertiseGen 目录放到本目录下。
./scripts/format_advertise_gen.py --path "AdvertiseGen/train.json"
来下载和将数据集处理成上述格式。
微调模型
# 安装依赖库
pip install transformers==4.30.2 accelerate sentencepiece astunparse deepspeed./scripts/finetune_pt.sh # P-Tuning v2 微调
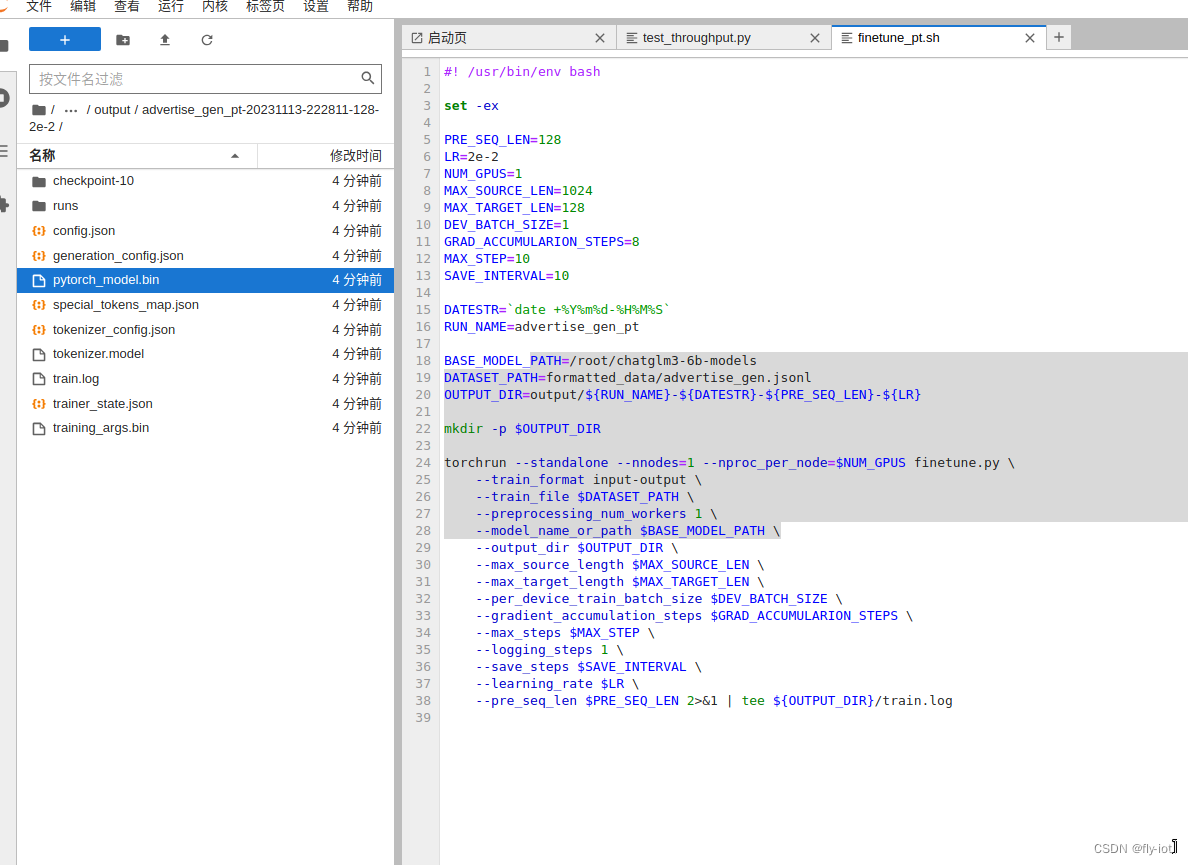
为了验证演示,调整参数,快速训练:
#! /usr/bin/env bashset -exPRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
MAX_SOURCE_LEN=1024
MAX_TARGET_LEN=128
DEV_BATCH_SIZE=1
GRAD_ACCUMULARION_STEPS=8
MAX_STEP=10
SAVE_INTERVAL=10DATESTR=`date +%Y%m%d-%H%M%S`
RUN_NAME=advertise_gen_ptBASE_MODEL_PATH=/root/chatglm3-6b-models
DATASET_PATH=formatted_data/advertise_gen.jsonl
OUTPUT_DIR=output/${RUN_NAME}-${DATESTR}-${PRE_SEQ_LEN}-${LR}mkdir -p $OUTPUT_DIRtorchrun --standalone --nnodes=1 --nproc_per_node=$NUM_GPUS finetune.py \--train_format input-output \--train_file $DATASET_PATH \--preprocessing_num_workers 1 \--model_name_or_path $BASE_MODEL_PATH \--output_dir $OUTPUT_DIR \--max_source_length $MAX_SOURCE_LEN \--max_target_length $MAX_TARGET_LEN \--per_device_train_batch_size $DEV_BATCH_SIZE \--gradient_accumulation_steps $GRAD_ACCUMULARION_STEPS \--max_steps $MAX_STEP \--logging_steps 1 \--save_steps $SAVE_INTERVAL \--learning_rate $LR \--pre_seq_len $PRE_SEQ_LEN 2>&1 | tee ${OUTPUT_DIR}/train.log4,推理验证,使用命令行的方式
对于输入输出格式的微调,可使用 inference.py 进行基本的推理验证。
python inference.py \--model /root/chatglm3-6b-models \--pt-checkpoint "output/advertise_gen_pt-20231113-222811-128-2e-2"
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████| 7/7 [00:05<00:00, 1.32it/s]
Some weights of ChatGLMForConditionalGeneration were not initialized from the model checkpoint at /root/chatglm3-6b-models and are newly initialized: ['transformer.prefix_encoder.embedding.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Prompt:类型#裙*材质#网纱*颜色#粉红色*裙袖长#短袖*裙领型#圆领
Response: *裙下摆流苏设计,轻轻松松演绎甜美可爱风。这条裙子真的太仙了,粉红色网纱,在阳光的照耀下,真的太仙了,仿佛置身于童话故事中。短袖的设计,既不会过于露肤,也能展示出修长的身材线条。裙摆处流苏的设计,让整个裙子的层次感更加明显,给人一种飘逸的感觉。5,总结
在 4090 上面运行 chatgm3 速度还是挺快的。
然后找到官方的 AdvertiseGen 数据集,就是对商品的标签和文案的匹配数据。
然后根据内容进行训练,然后再输入相关类似的标签,就可以自动生成广告文案了。
这个是AIGC的挺好的落地场景。
可以在 4090 上完成训练,并验证成功了!
相关文章:
【chatglm3】(3):在AutoDL上,使用4090显卡,部署ChatGLM3API服务,并微调AdvertiseGen数据集,完成微调并测试成功!附视频演示。
在AutoDL上,使用4090显卡,部署ChatGLM3API服务,并微调AdvertiseGen数据集,完成微调并测试成功! 其他chatgpt 和chatglm3 资料: https://blog.csdn.net/freewebsys/category_12270092.html 视频地址&#…...
python爬虫top250电影数据
之前看到的,我改了一下,多了很多东西 import requests from bs4 import BeautifulSoup from openpyxl import Workbook from openpyxl.styles import Font import redef extract_movie_info(info):# 使用正则表达式提取信息pattern re.compile(r导演:…...

STL简介+浅浅了解string——“C++”
各位CSDN的uu们好呀,终于到小雅兰的STL的学习了,下面,让我们进入CSTL的世界吧!!! 1. 什么是STL 2. STL的版本 3. STL的六大组件 4. STL的重要性 5. 如何学习STL 6.STL的缺陷 7.为什么要学习string类 …...

wpf 和winform 的区别
WPF (Windows Presentation Foundation) 和 WinForms (Windows Forms) 是 Microsoft .NET 桌面应用程序开发中两种不同的技术框架,它们有一些重要的区别: 1. **UI 抽象层次结构:** - **WinForms:** 使用基于控件(Controls)的 …...

【Apifox】国产测试工具雄起
在开发过程中,我们总是避免不了进行接口的测试, 而相比手动敲测试代码,使用测试工具进行测试更为便捷,高效 今天发现了一个非常好用的接口测试工具Apifox 相比于Postman,他还拥有一个非常nb的功能, 在接…...
PNAS | 蛋白质结构预测屈服于机器学习
今天为大家介绍的是来自James E. Rothman的一篇短文。今年的阿尔伯特拉斯克基础医学研究奖表彰了AlphaFold的发明,这是蛋白质研究历史上的一项革命性进展,首次提供了凭借序列信息就能够准确预测绝大多数蛋白质的三维氨基酸排列的实际能力。这一非凡的成就…...

PlayCanvas通过IFrame嵌入页面如何与canvasplay脚本通讯
PlayCanvas可以通过IFrame嵌入HTML页面,实现混合编程,扩充PlayCanvas的页面功能。 问:在IFrame嵌入页面中如何与PlayCanvas通讯,调用PlayCanvas功能? 答:可以调用PlayCanvas的全局对象pc来访问其他脚本&…...

springboot整合Redis后间歇性io.lettuce.core.RedisCommandTimeoutException
在springboot中引入spring-boot-starter-data-redis依赖时,默认使用的时Lettuce 产生这种问题的原因有如下两点: 1、Lettuce 自适应拓扑刷新(Adaptive updates)与定时拓扑刷新(Periodic updates) 是默认关闭…...

基于springboot+vue的学生毕业离校信息网站
项目介绍 该学生毕业离校系统包括管理员、学生和教师。其主要功能包括管理员:首页、个人中心、学生管理、教师管理、离校信息管理、费用结算管理、论文审核管理、管理员管理、留言板管理、系统管理等,前台首页;首页、离校信息、网站公告、留…...
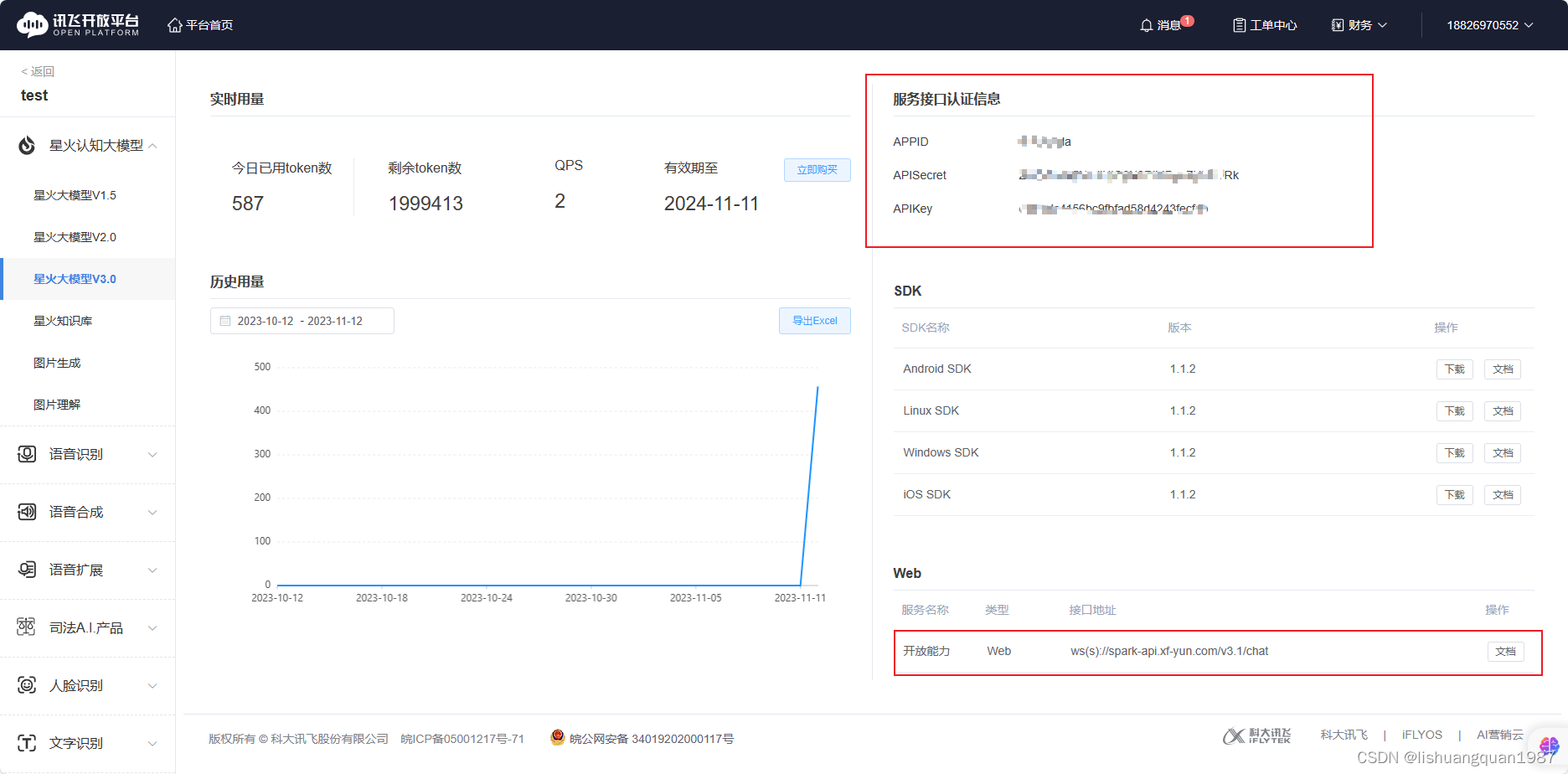
基于C#+WPF编写的调用讯飞星火大模型工具
工具源码:https://github.com/lishuangquan1987/XFYun.SparkChat 工具效果截图: 支持流式输出: 其中ApiKey/ApiSecret/AppId需要自己到讯飞星火大模型官网去注册账号申请,免费的。 申请地址:https://xinghuo.xfyun.cn/ 注册之…...

科普测量开关电源输出波形的三种方法及电源波形自动化测试步骤
开关电源波形测试就是对开关电源的输出波形进行检测和分析,观察开关电源参数变化,以此来判断开关电源的性能是否符合要求。好的开关电源对于设备以及整个电路的正常运行是非常重要的,因此开关电源输出波形测试是开关电源测试的重要环节&#…...

【优化版】DOSBox及常用汇编工具的详细安装教程
🌈个人主页:聆风吟 🔥系列专栏:网络奇遇记、图解数据结构 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. dosbox的介绍、下载和安装1.1 dosbos简介1.2 dosbox的下载1.2.1 方式一&a…...
【Devchat 插件】创建一个GUI应用程序,使用Python进行加密和解密
VSCode 插件 DevChat——国内开源的 AI 编程! 写在最前面DevChat是什么?什么是以提示为中心的软件开发 (PCSD)?为什么选择DevChat?功能概述情境构建添加到上下文生成提交消息提示扩展 KOL粉丝专属福利介绍D…...
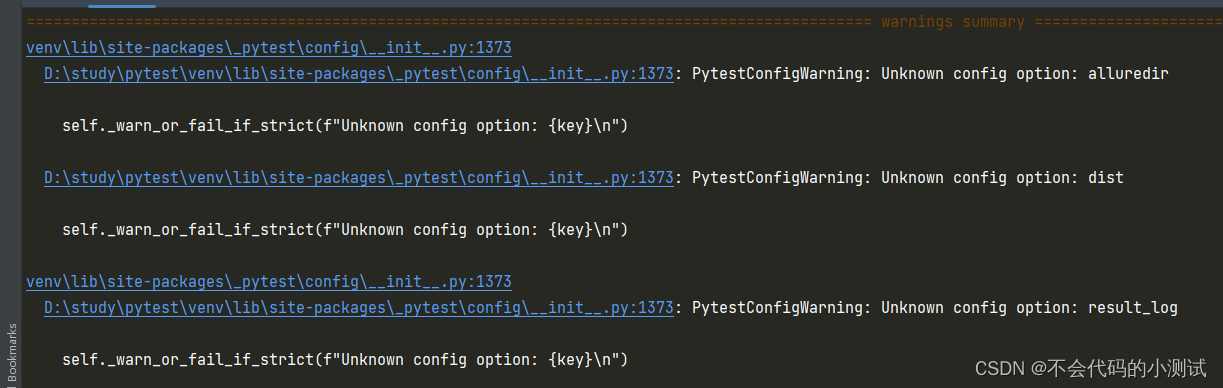
运行pytest时,给出警告 PytestConfigWarning: Unknown config option: result_log
问题:在ini中配置了一些选项后运行pytest,会出现下面的警告信息 解决:在ini中增加配置:addopts -p no:warnings...
初始MySQL(五)(自我复制数据,合并查询,外连接,MySQL约束:主键,not null,unique,foreign key)
目录 表复制 自我复制数据(蠕虫复制) 合并查询 union all(不会去重) union(会自动去重) MySQL表的外连接 左连接 右连接 MySQL的约束 主键 not null unique(唯一) foreign key(外键) 表复制 自我复制数据(蠕虫复制) #为了对某个sql语句进行效率测试,我们需要海量…...

ssh秘钥登录
1.设置 SSH 通过密钥登录 密钥形式登录的原理是:利用密钥生成器制作一对密钥——一只公钥和一只私钥。 将公钥添加到服务器的某个账户上,然后在客户端利用私钥即可完成认证并登录。这样一来,没有私钥,任何人都无法通过 SSH 暴力…...

Vue3+NodeJS 接入文心一言, 发布一个 VSCode 大模型问答插件
目录 一:首先明确插件开发方式 二:新建一个Vscode 插件项目 1. 官网教程地址 2. 一步一步来创建 3. 分析目录结构以及运行插件 三:新建一个Vue3 项目,在侧边栏中展示,实现vscode插件 <> vue项目 双向消息传…...

VUE element组件生成的全选框如何获取值
//先声明 const Selection ref([]);//获取 const handleSelectCodeForTicket (val) > {console.log(val);// values.value val;Selection.value [];val.forEach((v) > {Selection.value.push(v);});console.log(Selection.value); }; <el-table selection-change…...

第三章:代码块
系列文章目录 文章目录 系列文章目录前言一、代码块总结 前言 代码块是只有方法体的类成员。 一、代码块 代码块又成为初始化块,属于类中的成员,类似于方法,将逻辑语句封装在方法体中,通过{}包围起来。但与方法不同,…...

javaEE案例,前后端交互,计算机和用户登录
加法计算机,前端的代码如下 : 浏览器访问的效果如图 : 后端的代码如下 再在浏览器进行输入点击相加,就能获得结果 开发中程序报错,如何定位问题 1.先定位前端还是后端(通过日志分析) 1)前端 : F12 看控制台 2)后端 : 接口,控制台日志 举个例子: 如果出现了错误,我们就在后端…...

EZModbus:面向ESP32的异步无锁Modbus C++库
1. EZModbus项目概述EZModbus是一个专为ESP32平台设计的C Modbus通信库,深度集成FreeRTOS实时操作系统,支持Arduino IDE与原生ESP-IDF两种开发框架。该库并非对现有Modbus协议栈的简单封装,而是从零构建的异步事件驱动型实现,其核…...

爱站网SEO工具包的站点诊断功能有什么用
爱站网SEO工具包的站点诊断功能有什么用 随着互联网市场的日益竞争,网站的SEO优化成为了每一个网站运营者必须面对的挑战。在这样的背景下,SEO工具包成为了网站运营者的得力助手。其中,爱站网SEO工具包的站点诊断功能尤为重要。这个功能到底…...

深入解析Anaconda中的pkgs文件夹:功能、管理与优化策略
1. pkgs文件夹的核心功能解析 第一次打开Anaconda安装目录时,很多人都会被那个占据几个GB空间的pkgs文件夹吓一跳。这个看似普通的文件夹,其实是Anaconda生态系统的"心脏"。它不仅仅是存放安装包的仓库,更承担着环境管理的关键角色…...

补题记录2
牛客周赛137 C D Epta 天梯赛6 8,9,10,11...

药流和人流哪个恢复快?术后修护行业洞察与实用指南
意外怀孕后,药流和人流的恢复差异及术后修护,是女性关注的核心话题,也是孕产修护领域的重点议题。术后修护作为缩短恢复周期、减少并发症的关键,其科学合理性直接影响女性生殖健康。本文结合行业现状与实用经验,探讨药…...

OpenClaw多模型切换:Qwen2.5-VL-7B与文本模型协同工作
OpenClaw多模型切换:Qwen2.5-VL-7B与文本模型协同工作 1. 为什么需要多模型协同 去年夏天,当我第一次尝试用OpenClaw自动化处理团队的知识库文档时,遇到了一个棘手的问题:有些文档包含大量截图和图表说明,而纯文本模…...

OpenClaw性能调优:Qwen3-14B镜像响应速度提升3倍实操
OpenClaw性能调优:Qwen3-14B镜像响应速度提升3倍实操 1. 为什么需要性能调优? 上周我在用OpenClaw自动处理100份PDF文档时,发现一个奇怪现象:同样的任务,晚上执行比白天快得多。经过排查才发现,白天我的本…...

龙迅LT9211D芯片解析:如何实现MIPI与双端口LVDS的高效转换
1. 龙迅LT9211D芯片的核心价值 第一次接触龙迅LT9211D芯片是在一个车载显示项目上,当时客户要求实现4K视频从主控芯片到双屏显示的无损传输。这个看似简单的需求背后,其实隐藏着MIPI和LVDS两种信号标准的转换难题。LT9211D的出现完美解决了这个问题&…...

2025届学术党必备的六大AI论文助手解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek DeepSeek身为人工智能写作工具,于学术论文撰写里能够起到辅助方面的作用…...

分布式微电网能源交易算法matlab源代码, 代码按照高水平文章复现,保证正确 孤岛微电网之间...
分布式微电网能源交易算法matlab源代码, 代码按照高水平文章复现,保证正确 孤岛微电网之间的能源交易问题,提出了一种分布式算法。 这个问题由几个通过任意拓扑交换能量流的岛屿微网格组成。 提出了一种基于次梯度的开销最小化算法࿰…...