ElasticSearch的文档、字段、映射和高级查询
1. 文档(Document)
在ES中一个文档是一个可被索引的基础信息单元,也就是一条数据
比如:你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。
1.1 创建文档
POST users/_doc
{
"user" : "Mike",
"post_date" : "2019-04-15T14:12:12",
"message" : "trying out Kibana"
}
PUT users/_doc/1?op_type=create
{"user" : "Jack","post_date" : "2019-05-15T14:12:12","message" : "trying out Elasticsearch"
}

1.2 查看文档
GET users/_doc/1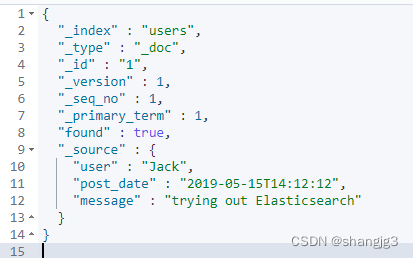
1.3 更新文档
POST users/_doc/1
{"user": "Lucy"
}
GET users/_doc/1

在原文档上增加字段
POST users/_update/1/
{"doc":{"post_date" : "2019-05-15T14:12:12","message" : "trying out Elasticsearch"}
}
再次查看结果

1.4 删除文档
DELETE users/_doc/1

条件删除
POST users/_delete_by_query
{"query":{"match": {"user": "Mike"}}
}

2. 字段(Field)
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
3. 映射(Mapping)
mapping是处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引等等。这些都是映射里面可以设置的,其它就是处理ES里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
3.1 创建映射
PUT /studentPUT /student/_mapping
{"properties": {"name":{"type": "text","index": true},"sex":{"type": "text","index": true},"age":{"type": "long","index": true}}
}
映射数据说明:
l字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
ltype:类型,Elasticsearch中支持的数据类型非常丰富,说几个关键的:
nString类型,又分两种:
text:可分词
keyword:不可分词,数据会作为完整字段进行匹配
nNumerical:数值类型,分两类
基本数据类型:long、integer、short、byte、double、float、half_float
浮点数的高精度类型:scaled_float
nDate:日期类型
nArray:数组类型
nObject:对象
lindex:是否索引,默认为true,也就是说你不进行任何配置,所有字段都会被索引。
true:字段会被索引,则可以用来进行搜索
false:字段不会被索引,不能用来搜索
lstore:是否将数据进行独立存储,默认为false
原始的文本会存储在_source里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true即可,获取独立存储的字段要比从_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。
lanalyzer:分词器,这里的ik_max_word即使用ik分词器。
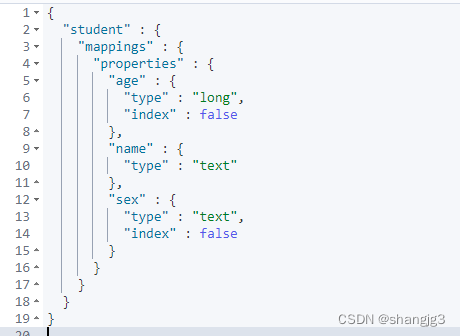
3.2 查看映射
GET /student/_mapping
3.3 索引映射关联
PUT /student1
{"settings": {},"mappings": {"properties": {"name":{"type": "text","index": true},"sex":{"type": "text","index": false},"age":{"type": "long","index": false}}}
}
4. ES高级查询
Elasticsearch提供了基于JSON提供完整的查询DSL来定义查询
定义数据 :
POST /student/_doc/1001
{
"name":"zhangsan",
"nickname":"zhangsan","sex":"男","age":30
}
POST /student/_doc/1002
{
"name":"lisi",
"nickname":"lisi","sex":"男","age":20
}
POST /student/_doc/1003
{
"name":"wangwu","nickname":"wangwu","sex":"女","age":40
}
POST /student/_doc/1004
{
"name":"zhangsan1",
"nickname":"zhangsan1","sex":"女","age":50
}
POST /student/_doc/1005
{
"name":"zhangsan2",
"nickname":"zhangsan2","sex":"女","age":30
}
4.1 查询所有文档:match_all
term查询,精确的关键词匹配查询,不对查询条件进行分词。
GET /student/_search
{"query":{"match_all": {}}
}

4.2 匹配查询:match
GET /student/_search
{"query": {"match": {"name": "zhangsan"}}
}

4.3 字段匹配查询:multi_match
GET /student/_search
{"query": {"multi_match": {"query": "zhangsan","fields": ["name", "nickname"]}}
}

4.4 关键字精确查询:term
GET /student/_search
{"query": {"term": {"name": {"value": "wangwu"}}}
}

4.5 多关键字精确查询:terms
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。
如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件,类似于mysql的in
GET /student/_search
{"query": {"terms": {"name": ["zhangsan","lisi"]}}
}

4.6 指定返回字段_source
默认情况下,Elasticsearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source的过滤
GET /student/_search
{"_source": "name", "query": {"terms": {"name": ["zhangsan"]}}
}

4.7 过滤字段:includes
我们也可以通过:
includes:来指定想要显示的字段
excludes:来指定不想要显示的字段
GET /student/_search
{"_source": {"includes": ["name","nickname"]}, "query": {"terms": {"nickname": ["zhangsan"]}}
}

GET /student/_search
{"_source": {"excludes": ["name","nickname"]}, "query": {"terms": {"nickname": ["zhangsan"]}}
}

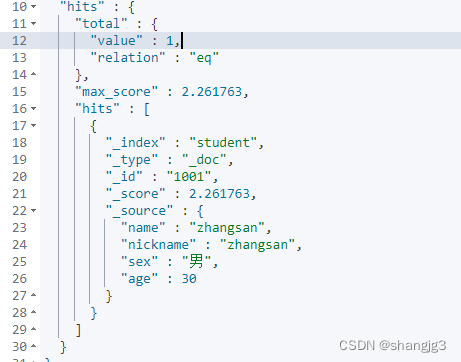
4.8 组合查询:bool
bool把各种其它查询通过must(必须 )、must_not(必须不)、should(应该)的方式进行组合
GET /student/_search
{"query": {"bool": {"must": [{"match": {"name": "zhangsan"}}],"must_not": [{"match": {"age": 40}}],"should": [{"match": {"sex": "男"}}]}}
}
4.9 范围查询
range 查询找出那些落在指定区间内的数字或者时间。range查询允许以下字符
| 操作符 | 说明 |
| gt | 大于> |
| gte | 大于等于>= |
| lt | 小于< |
| lte | 小于等于<= |
GET /student/_search
{"query": {"range": {"age": {"gte": 30,"lte": 35}}}
}

4.10 模糊查询
返回包含与搜索字词相似的字词的文档。
编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数。这些更改可以包括:
更改字符(box → fox)
删除字符(black → lack)
插入字符(sic → sick)
转置两个相邻字符(act → cat)
为了找到相似的术语,fuzzy查询会在指定的编辑距离内创建一组搜索词的所有可能的变体或扩展。然后查询返回每个扩展的完全匹配。
通过fuzziness修改编辑距离。一般使用默认值AUTO,根据术语的长度生成编辑距离。
GET /student/_search
{"query": {"fuzzy": {"name": {"value": "zhangsan"}}}
}

4.11 单字段排序
sort 可以让我们按照不同的字段进行排序,并且通过order指定排序的方式。desc降序,asc升序。
GET /student/_search
{"query": {"fuzzy": {"name": "zhangsan"}},"sort": [{"age": {"order" : "desc"}}]
}

4.12 多字段排序
假定我们想要结合使用 age和 _score进行查询,并且匹配的结果首先按照年龄排序,然后按照相关性得分排序
GET /student/_search
{"query": {"fuzzy": {"name": "zhangsan"}},"sort": [{"age": {"order" : "desc"}},{"_score": {"order": "desc"}}]
}

4.13 高亮查询
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮。
在Bing搜索"大数据"
Elasticsearch可以对查询内容中的关键字部分,进行标签和样式(高亮)的设置。
在使用match查询的同时,加上一个highlight属性:
lpre_tags:前置标签
lpost_tags:后置标签
lfields:需要高亮的字段
title:这里声明title字段需要高亮,后面可以为这个字段设置特有配置,也可以空
GET /student/_search
{"query": {"match": {"name": "zhangsan"}},"highlight": {"pre_tags": "<font color='red'>","post_tags": "</font>","fields": {"name": {}}}
}

4.14 分页查询
from:当前页的起始索引,默认从0开始。 from = (pageNum - 1) * size
size:每页显示多少条
GET /student/_search
{"query": {"match_all": {}},"sort": [{"age": {"order": "desc"}}],"from": 0,"size": 2
}

4.15 聚合查询
聚合允许使用者对es文档进行统计分析,类似与关系型数据库中的group by,当然还有很多其他的聚合,例如取最大值、平均值等等。
对某个字段取最大值max
GET /student/_search
{"aggs":{"max_age":{"max":{"field":"age"}}},"size":0
}

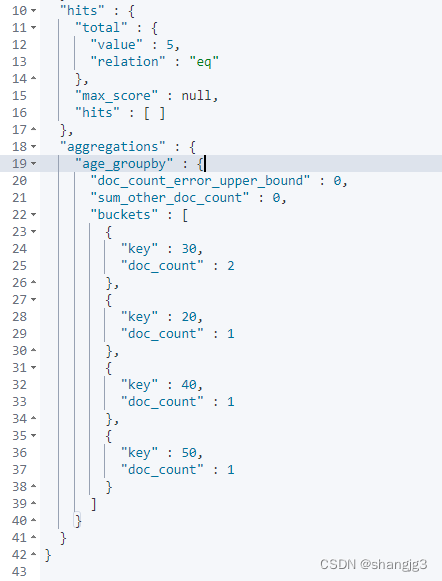
4.16 桶聚合查询
桶聚和相当于sql中的group by语句
terms聚合,分组统计
GET /student/_search
{"aggs":{"age_groupby":{"terms":{"field":"age"}}},"size":0
}
相关文章:
ElasticSearch的文档、字段、映射和高级查询
1. 文档(Document) 在ES中一个文档是一个可被索引的基础信息单元,也就是一条数据 比如:你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON&…...

vim相关命令讲解!
本文旨在讲解vim 以及其相关的操作! 希望读完本文,读者会有一定的收获!好的,干货马上就来! 初识vim 在讲解vim之前,我们首先要了解vim是什么,有什么作用?只有了解了vim才能更好的理…...

22.构造一个关于员工信息的结构体数组,存储十个员工的信息
结构体问题。构造一个关于员工信息的结构体数组,存储十个员工的信息,包括员工工号,员工工资,员工所得税,员工实发工资。要求工号和工资由键盘输入,并计算出员工所得税(所得税工资*0.2࿰…...


calico
calico:默认是ip-ip模式, ipip 开销小 vxlan模式:后期版本才支持 不会创建虚拟交换机 Calico 是一种用于构建和管理容器网络的开源软件定义网络(SDN)解决方案。它专门设计用于在容器和虚拟机之间提供高性能、高可扩展性和灵活的…...
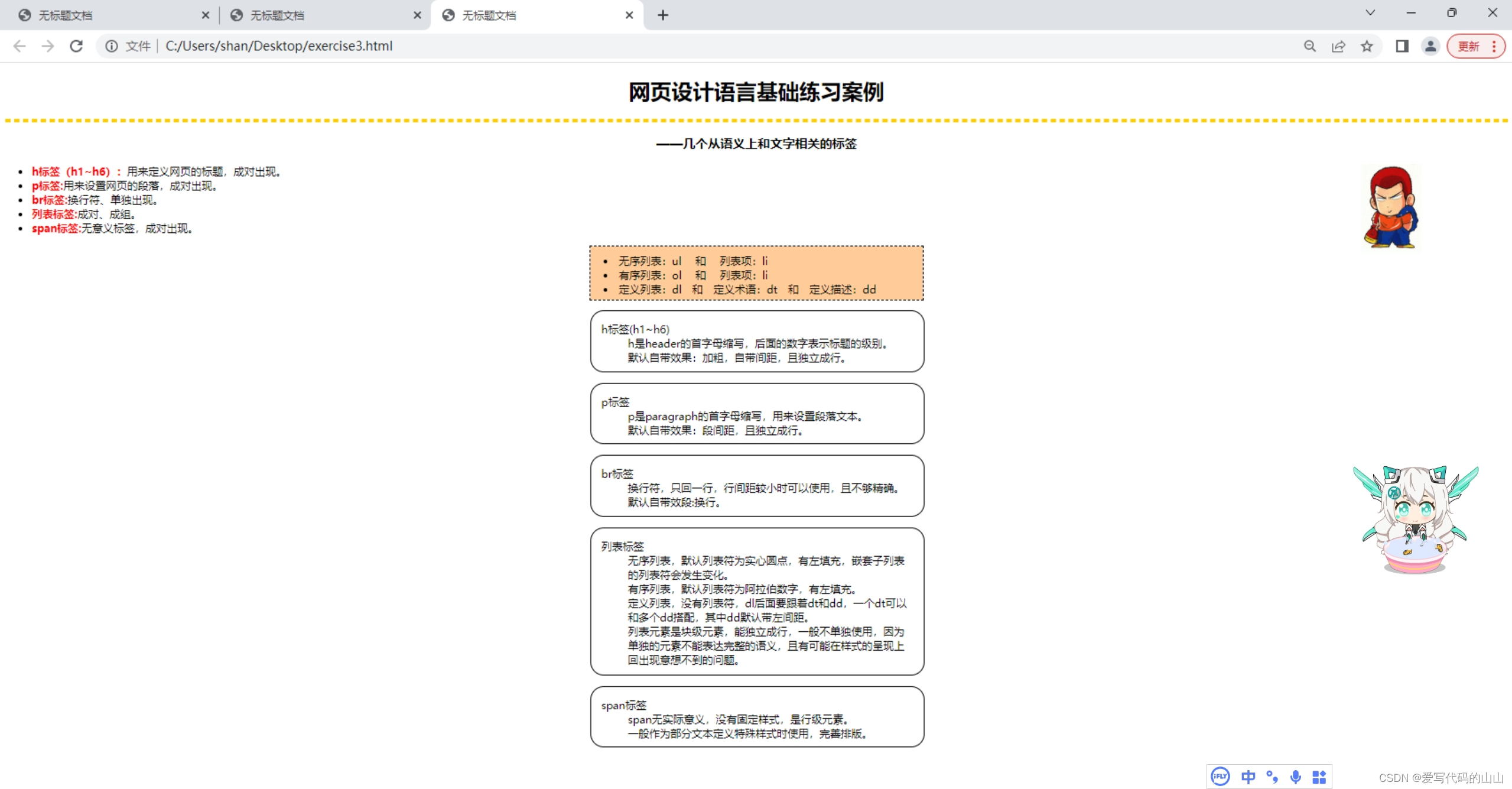
web前端开发第3次Dreamweave课堂练习/html练习代码《网页设计语言基础练习案例》
目标图片: 文字素材: 网页设计语言基础练习案例 ——几个从语义上和文字相关的标签 * h标签(h1~h6):用来定义网页的标题,成对出现。 * p标签:用来设置网页的段落,成对出现。 * b…...
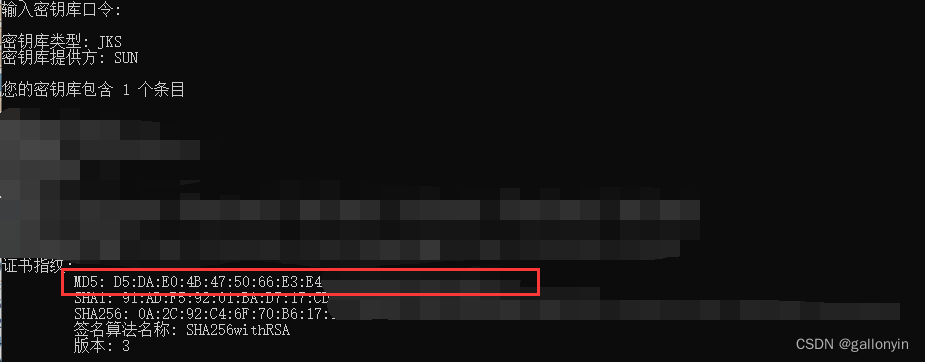
APP备案获取安卓app证书公钥获取方法和签名MD5值
前言 在开发和发布安卓应用程序时,了解应用程序证书的公钥和签名MD5值是很重要的。这些信息对于应用程序的安全性和合规性至关重要。现在又因为今年开始APP必须接入备案才能在国内各大应用市场上架,所以获取这两个值成了所有开发者的必经之路。本文将介…...

cefsharp 93.1.140 如何在js中暴露c#类
从cefsharp79版本开始,旧的RegisterJsObject方法被删除了。 也就是说想使用79以后的版本,就必须更新js暴露c#对象的方法了。由于79之前的注册方法是不需要在js中进行注册的,在93版本上如何在不改动前端页面的基础上实现内核升级咧,…...
)
同一台Linux同时安装MYSQL5.7和MYSQL8(第一篇)
在一台Linxu上面同时安装mysql5.7和mysql8.0的步骤,记录一下,方便后续回顾,后续文章之后会接着介绍搭建两台虚拟机一主一从的架构。 其中配置的文件名称、目录、端口号、IP地址要根据自己电脑的实际情况进行更改。 安装完成后效果 [rootzong…...

【CSS】解决上层盒子遮挡下层图片点击事件的三种方法
1. Pointer Events 属性 CSS 的 pointer-events 属性是一个强大的工具,可以控制元素是否接收用户的交互事件。通过将上层盒子的 pointer-events 设置为 none,我们可以确保它不会阻止下层图片的点击事件。 .upper-box {z-index: 999; /* 设置更高的 z-i…...

力扣每日一题 ---- 2906. 构造乘积矩阵
这题很简单(一下就能想到是前缀和的提米),但是在处理12345上面需要仔细一点,本来我最开始想到的时候全部累乘在除掉当前数,但是这样就没有把12345考虑进去,如果他本身是12345的话,那么除他以外的乘积并不一定是0&#…...

Tomcat学习
一、入门 在webapp里面必须先创建一个文件夹,文件夹里面放的内容,才会被访问到。 创建一个javaweb项目后 二、servlet 1.概述 2.servlet生命周期 3.servlet实例的创建时机 4.Servlet实例的初始化参数 5.HTTP状态码 6.servelet返回JSON数据 7.服务端设置…...
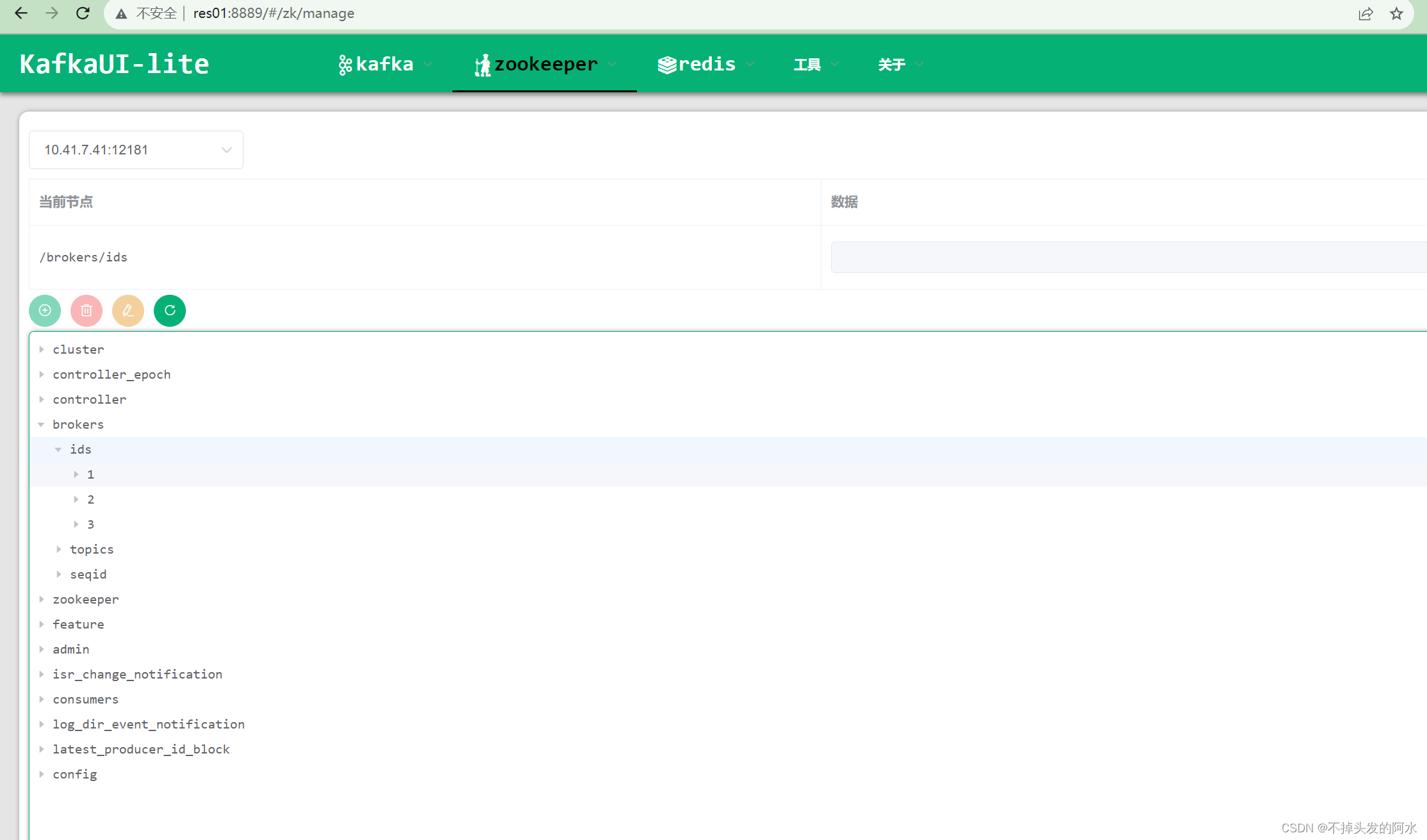
Linux系统上搭建高可用Kafka集群(使用自带的zookeeper)
本次在CentOS7.6上搭建Kafka集群 Apache Kafka 是一个高吞吐量的分布式消息系统,被广泛应用于大规模数据处理和实时数据管道中。本文将介绍在CentOS操作系统上搭建Kafka集群的过程,以便于构建可靠的消息处理平台。 文件分享(KafkaUI、kafka…...
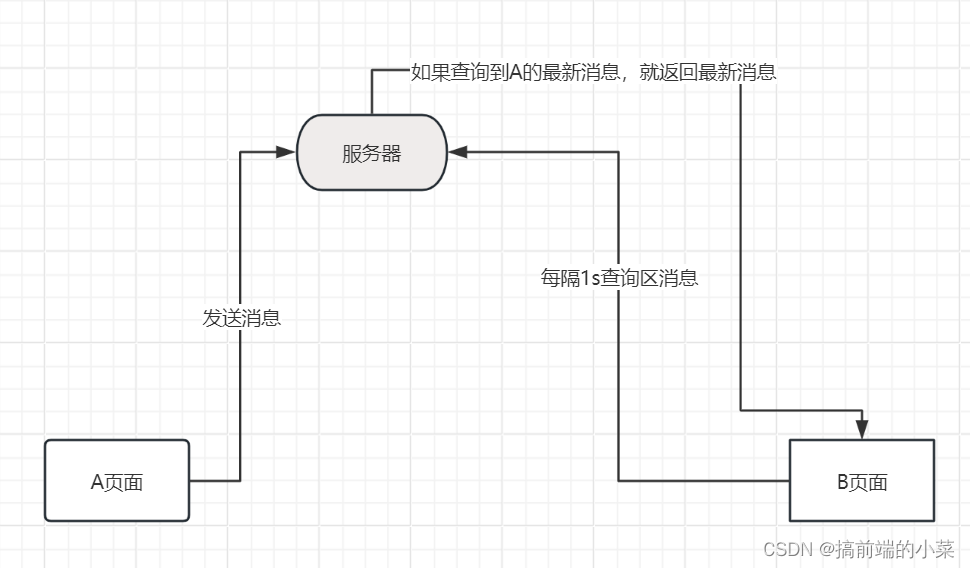
WebSocket在node端和客户端的使用
摘要 如果想要实现一个聊天的功能,就会想到使用WebSocket来搭建。那如果没有WebSocet的时候,我们会以什么样的思路来实现聊天功能呢? 假如有一个A页面 和 B页面进行通信,当A发送信息后,我们可以将信息存储在文件或者…...

ENVI IDL:如何将txt文本文件转化为GeoTIFF文件?
01 前言 此处的文本文件形式如下: 里面包含了众多点位信息(不是站点数据),我们需要依据上述点的经纬度信息放到对应位置的像素点位置,放置完后如下: 可以发现,还存在部分缺失值,我们…...

北邮22级信通院数电:Verilog-FPGA(9)第九周实验(2)实现下降沿触发的JK触发器(带异步复位和置位功能)
北邮22信通一枚~ 跟随课程进度更新北邮信通院数字系统设计的笔记、代码和文章 持续关注作者 迎接数电实验学习~ 获取更多文章,请访问专栏: 北邮22级信通院数电实验_青山如墨雨如画的博客-CSDN博客 JK.v module JK (input clk,input J,input K,input…...

pyqt5UI同步加载
问题记录:pyqt5 怎样实现修改ui而不改变py代码,例如一个文件存入ui代码,另一个文件引入ui代码 起因:由于在写一个漏扫工具,由于ui的平频繁改动导致主体代码结构变动,所以先有没有方法能够不改变主题代码&am…...
)
CentOS 7 安装 Redis 5 (单机 6379)
CentOS 7 安装 Redis 5 (单机 6379) 自己准备好 Redis 5 的安装包并上传至 /opt/ 下的 redis 文件夹下: cd /opt mkdir redis cd redis准备好 Redis 所需的编译环境: yum -y install gcc yum -y install gcc-c解压上传的 Redis…...

sqlplus set参数大区
通过设置不同的SET参数,可以定制SQLPlus的行为和输出格式: SET 参数描述SET AUTOTRACE显示SQL语句的执行计划和统计信息,用于性能优化。SET FEEDBACK控制是否显示SQL语句执行的行数,可提高结果可读性。SET LINESIZE设置每行的最大…...

从0到0.01入门React | 006.精选 React 面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...

实测GLM-TTS:方言克隆效果惊艳,情感表达自然流畅
实测GLM-TTS:方言克隆效果惊艳,情感表达自然流畅 1. 语音克隆技术的新突破 近年来,语音合成技术取得了显著进展,但传统方案在方言支持和情感表达方面仍存在明显短板。GLM-TTS作为智谱AI开源的文本转语音模型,通过创新…...

Qwen3智能字幕对齐系统Anaconda环境配置指南:Python依赖一键安装
Qwen3智能字幕对齐系统Anaconda环境配置指南:Python依赖一键安装 你是不是也遇到过这种情况:好不容易找到一个开源项目,比如这个Qwen3智能字幕对齐系统,兴致勃勃地准备跑起来试试,结果第一步“环境配置”就卡住了。不…...
Pixel Aurora Engine 赋能Web应用:Node.js全栈项目集成AI绘图功能
Pixel Aurora Engine 赋能Web应用:Node.js全栈项目集成AI绘图功能 1. 项目背景与价值 想象一下,你正在开发一个创意设计平台,用户需要快速将想法转化为视觉作品。传统方案要么依赖专业设计师,要么使用复杂的图形工具,…...

Anything to RealCharacters引擎在创意项目中的应用:生成一致性真人形象
Anything to RealCharacters引擎在创意项目中的应用:生成一致性真人形象 1. 项目背景与核心价值 在数字内容创作领域,将2.5D或卡通形象转换为写实真人风格一直是个技术挑战。传统方法要么效果生硬不自然,要么需要专业美术人员手动调整&…...

OpenClaw+千问3.5-35B-A3B-FP8:24小时运行的竞品监测系统
OpenClaw千问3.5-35B-A3B-FP8:24小时运行的竞品监测系统 1. 为什么需要个人级竞品监测系统 去年在做独立产品时,我每天要手动检查5个竞品官网的更新情况。重复的复制粘贴、版本号比对、功能点记录消耗了大量时间。直到发现OpenClaw千问3.5的组合&#…...

OpenClaw技能组合技:Phi-3-mini-128k-instruct串联多工具完成复杂任务
OpenClaw技能组合技:Phi-3-mini-128k-instruct串联多工具完成复杂任务 1. 为什么需要技能组合技? 上周我需要完成一个周期性市场分析报告,传统流程需要手动执行四个步骤:从行业网站抓取最新数据、用Python脚本清洗分析、用Excel…...

小米手机解锁全攻略:从申请到完成的详细步骤
1. 申请解锁前的准备工作 第一次接触小米手机解锁的朋友可能会觉得流程复杂,其实只要按照步骤操作并不难。在开始之前,我们需要做好几项准备工作。首先确认你的小米账号已经实名认证,这是解锁的必要条件。我遇到过不少朋友因为账号没实名导致…...

避开这些坑,你的STM32 CAN总线通信才能稳定跑起来:从硬件电路到软件配置的避坑指南
STM32 CAN总线通信实战避坑指南:从硬件设计到软件调试的深度解析 在工业控制、汽车电子和物联网领域,CAN总线因其高可靠性和实时性成为首选通信协议。然而,许多工程师在STM32平台上实现CAN通信时,总会遇到各种"诡异"问题…...
)
网络安全学习(面试)
前言:今天就不学习,有更重要的事情明天写,还有一点感觉逻辑不通正题:面试题今天学习安全设备的使用依托全流量分析、NDR、EDR、WAF、蜜罐等多源安全设备我需要知道了,这上面几种设备是什么,做什么用的&…...

深入解析CryptoJS:AES加密与解密在前端安全传输中的实战应用
1. 为什么前端需要加密传输? 想象一下这样的场景:用户在登录页面输入账号密码,点击提交按钮后,这些敏感信息会以明文形式在网络中传输。如果被中间人截获,后果不堪设想。这就是为什么我们需要在前端对敏感数据进行加密…...