Pandas数据预处理python 数据分析之4——pandas 预处理在线闯关_头歌实践教学平台
Pandas数据预处理python 数据分析之4——pandas 预处理
- 第1关 数据读取与合并
- 第2关 数据清洗
- 第3关 数据转换
第1关 数据读取与合并
任务描述
本关任务:加载 csv 数据集,实现 DataFrame 合并。
编程要求
根据提示,在右侧编辑器补充代码,完成本关任务。
测试说明
平台会对你的代码进行测试,若与预期输出一致,则算通关。
开始你的任务吧,祝你成功!
# -*- coding: utf-8 -*-'''
第1关 数据读取与合并
现有源自世界银行的四个数据集:
1)economy-60-78.csv,
2)economy-79-19.csv,
3)population-60-78.csv,
4)population-79-19.csv,
其中分别存放了不同时间段(1960-1978和1979-2019)的
中国经济相关数据和中国人口及教育相关数据。
'''
#请将上述数据集内容读取至DataFrame结构中,
#年份为列索引,Indicator Name为行索引,
#观察其结构和内容,把它们合并为一个DataFrame,命名为ChinaData。
#输出ChinaData的形状
############begin############import pandas as pd
d1 = pd.read_csv('economy-60-78.csv',index_col = 0)
d2 = pd.read_csv('economy-79-19.csv',index_col = 0)
d3 = pd.read_csv('population-60-78.csv',index_col = 0)
d4 = pd.read_csv('population-79-19.csv',index_col = 0)
#print(d1.shape)
#print(d2.shape)
#print(d3.shape)
#print(d4.shape)d12 = pd.concat([d1,d2],axis = 1,sort=True)
d34 = pd.concat([d3,d4],axis = 1,sort=True)
ChinaData = pd.concat([d34,d12],sort=True)print(ChinaData.shape)#############end#############第2关 数据清洗
任务描述
本关任务:数据清洗
包括:空白行删除、数据完整性检验、数据填充、插值等内容。
编程要求
根据提示,在右侧编辑器补充代码,完成本关任务。
测试说明
平台会对你的代码进行测试,若与预期输出一致,则算通关。
开始你的任务吧,祝你成功!
# -*- coding: utf-8 -*-
'''
第2关 数据清洗
'''
import pandas as pd
d1 = pd.read_csv('economy-60-78.csv',index_col = 0)
d2 = pd.read_csv('economy-79-19.csv',index_col = 0)
d3 = pd.read_csv('population-60-78.csv',index_col = 0)
d4 = pd.read_csv('population-79-19.csv',index_col = 0)
d12 = pd.concat([d1,d2],axis = 1,sort=True)
d34 = pd.concat([d3,d4],axis = 1,sort=True)
ChinaData = pd.concat([d34,d12],sort=True)
'''
请针对ChinaData完成如下操作。
'''
# 2.1 删除空白行
# 提示:dropna,inplace
############begin############
print('原表形状',ChinaData.shape)
linenum = ChinaData.shape[0]
ChinaData.dropna(how='all',inplace=True)
print('新表形状',ChinaData.shape)
linenum -=ChinaData.shape[0]
print("%d个空白行被删除。"%linenum)
#############end############## 2.2 查找数据最完整(空值最少)的年份并输出
# 提示:notnull(),根据值找索引(上课讲过的方法)
############begin############
#print(ChinaData.notnull().sum().sort_values(ascending=False)[0])
nullsummary = ChinaData.isnull().sum()
y = nullsummary.loc[nullsummary==nullsummary.min()].index[0]
print(y)#############end############## 2.3 前向填充"男性吸烟率(吸烟男性占所有成年人比例)",输出2000年至2019年的数据
# fillna,ffill
############begin############cigarette = ChinaData.loc['男性吸烟率(吸烟男性占所有成年人比例)',:]
print(cigarette.fillna(method = 'ffill').loc['2000':'2019'])#############end############## 2.4 用2015年到2018年4年的gdp数据对2019年GDP数值进行拉格朗日插值预测,输出预测结果
# lagrange,
# 注意:x的取值从0开始,即x = np.array([0,1,2,3]),代表2015至2018 4年,2019年的x取值为4。
############begin############from scipy.interpolate import lagrange
gdp = ChinaData.loc['GDP',:]
lagf = lagrange(range(0,4),gdp.values[-5:-1])
print(lagf(4))
#############end############## 2.5 用线性插值法填充“入学率,高等院校,男生(占总人数的百分比)”1995年到2002年数据,并输出插值后的94年至03年的数据
# interp1d
############begin############from scipy.interpolate import interp1d
student = ChinaData.loc['入学率,高等院校,男生(占总人数的百分比)',:]
linevalue = interp1d([0,9],[student.loc['1994'],student.loc['2003']],kind = 'linear')
student.loc['1995':'2002'] = linevalue(range(1,9))
print(student.loc['1994':'2003'])#############end#############第3关 数据转换
任务描述
本关任务:数据转换。包括数据标准化和数据离散化。
编程要求
根据提示,在右侧编辑器补充代码,完成本关任务。
测试说明
平台会对你的代码进行测试,若与预期输出一致,则算通关。
开始你的任务吧,祝你成功!
# -*- coding: utf-8 -*-'''
第3关 数据转换
'''
import pandas as pd
d1 = pd.read_csv('economy-60-78.csv',index_col = 0)
d2 = pd.read_csv('economy-79-19.csv',index_col = 0)
d3 = pd.read_csv('population-60-78.csv',index_col = 0)
d4 = pd.read_csv('population-79-19.csv',index_col = 0)
d12 = pd.concat([d1,d2],axis = 1,sort=True)
d34 = pd.concat([d3,d4],axis = 1,sort=True)
ChinaData = pd.concat([d34,d12],sort=True)
'''
请针对ChinaData实现下列操作
'''
# 3.1 对“人口,总数”数据(1960-2018)进行离差标准化,并输出。
# 提示:自定义离差标准化函数,注意统计年份区间
############begin############def MinMaxScale(data):data = (data-data.min())/(data.max()-data.min())return data
population = ChinaData.loc['人口,总数',:][:-1]
npopu = MinMaxScale(population)
print(npopu)#############end############## 3.2 对“GDP 增长率(年百分比)”(1961-2018)数据进行等宽离散化为7类,输出分布情况
# 提示:cut,注意统计年份区间
############begin############gdpRatio = ChinaData.loc['GDP 增长率(年百分比)',:][1:-1]
result = pd.cut(gdpRatio,7)
print(result.value_counts())#############end#############相关文章:

Pandas数据预处理python 数据分析之4——pandas 预处理在线闯关_头歌实践教学平台
Pandas数据预处理python 数据分析之4——pandas 预处理 第1关 数据读取与合并第2关 数据清洗第3关 数据转换 第1关 数据读取与合并 任务描述 本关任务:加载 csv 数据集,实现 DataFrame 合并。 编程要求 根据提示,在右侧编辑器补充代码&#…...

[html] 动态炫彩渐变背景
废话不多说,直接上源码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>ZXW-NUDT: 动态炫…...
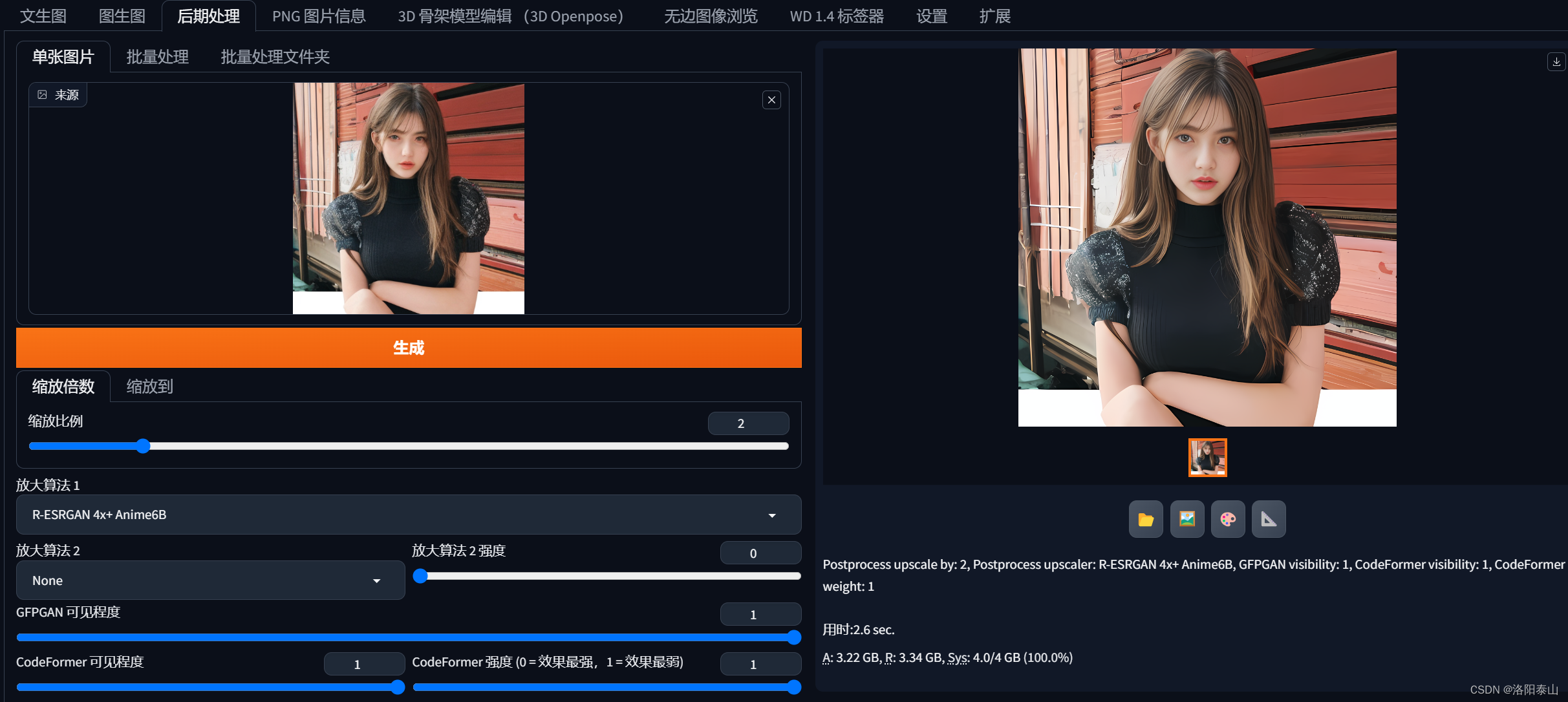
AI 绘画 | Stable Diffusion 高清修复、细节优化
前言 在 Stable Diffusion 想要生成高清分辨率的图片。在文生图的功能里,需要设置更大的宽度和高度。在图生图的功能里,需要设置更大的重绘尺寸或者重绘尺寸。但是设置完更大的图像分辨率,需要更大显存,1024*1024的至少要电脑的空…...
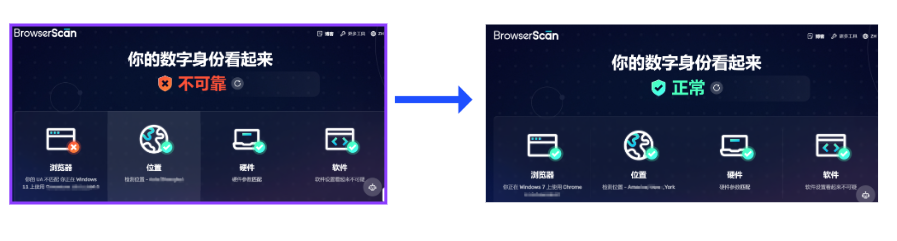
想要检测TikTok网络是否安全?这五个网站请收好
Tiktok目前在海外大火,越来越多的人想要进入TikTok的海外市场并捞一桶金。然而,成功并非易事。想要在TikTok中立足,我们必须保证我们的设备、网络环境和网络节点完全符合官方的要求,并且没有任何异常或风险。那么我们该如何设置、…...
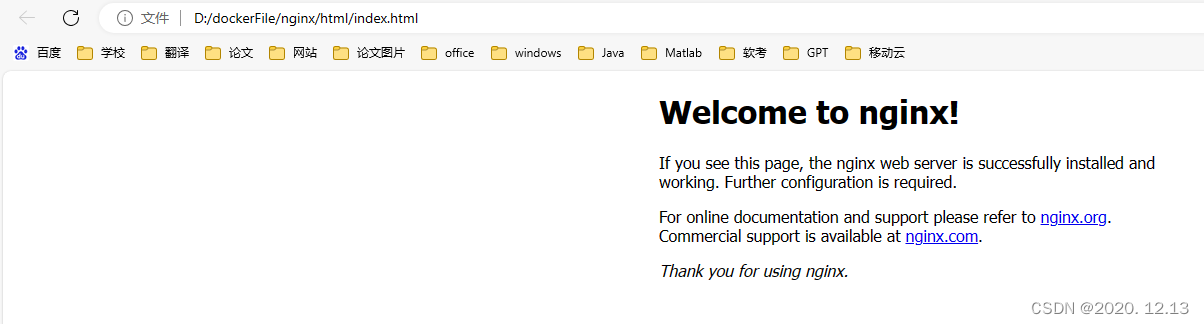
【docker:容器提交成镜像】
容器创建部分请看:点击此处查看我的另一篇文章 容器提交为镜像 docker commit -a "sinwa lee" -m "首页变化" mynginx lxhnginx:1.0docker run -d -p 88:80 --name lxhnginx lxhnginx:1.0为啥没有变啊,首页? 镜像打包 …...

UE5中一机一码功能
创建蓝图函数库 1、获取第一个有效的硬盘ID // Fill out your copyright notice in the Description page of Project Settings.#pragma once#include "CoreMinimal.h" #include "Kismet/BlueprintFunctionLibrary.h" #include "GetDiskIDClass.gen…...
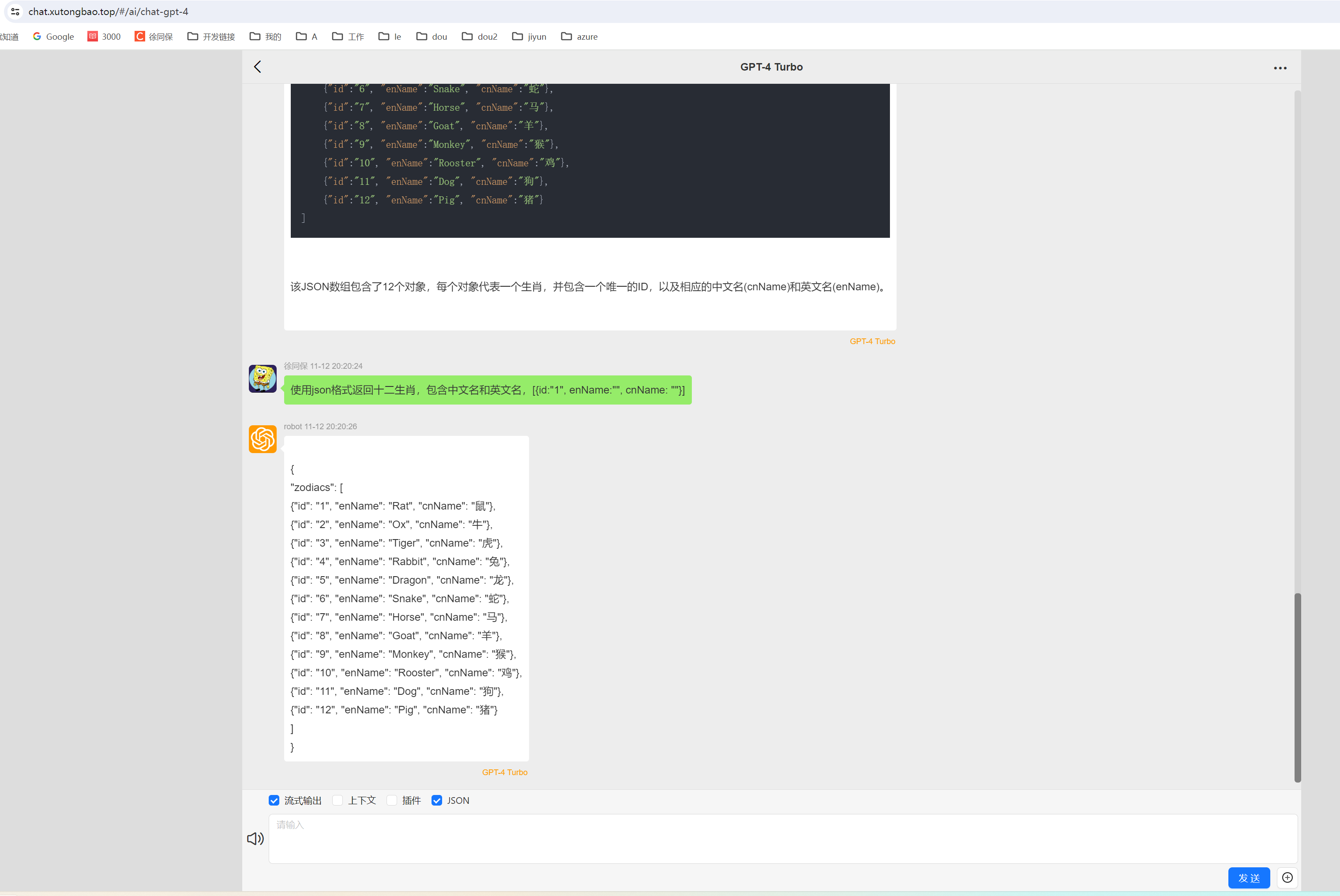
gpt支持json格式的数据返回(response_format: ‘json_object‘)
Api.h5.chatCreateChatCompletion({model: gpt-3.5-turbo-1106,token: sk-f4fe8b67-fcbe-46fd-8cc9-fd1dac5d6d59,messages: [{role: user,content:使用json格式返回十二生肖,包含中文名和英文名,[{id:"1", enName:"", cnName: &quo…...
:约束)
MySQL(13):约束
约束(constraint)概述 数据完整性(Data Integrity)是指数据的精确性(Accuracy)和可靠性(Reliability)。 它是防止数据库中存在不符合语义规定的数据和防止因错误信息的输入输出造成无效操作或错误信息 而提…...
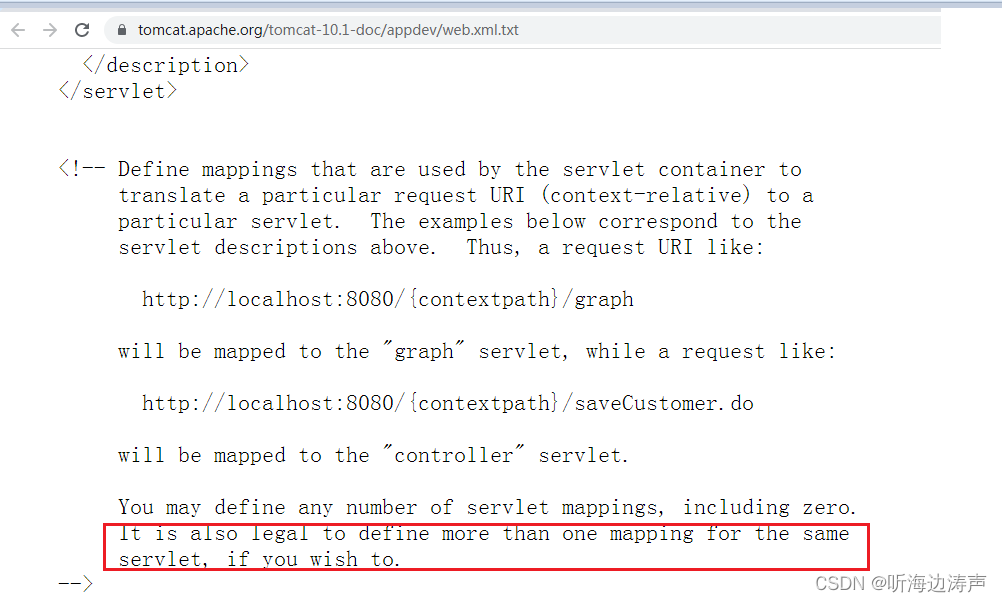
可以为一个servlet定义多个servlet-mapping、或url-pattern
在web描述符文件web.xml文件中,可以为同一个servlet定义多个servlet-mapping;也可以在同一个servlet-mapping中,定义多个url-pattern。也就是说,可以把多个地址(相对于上下文路径)映射到同一个servlet处理。…...

.net在使用存储过程中IN参数的拼接方案,使用Join()方法
有时候拼接SQL语句时,可能会需要将list中的元素都加上单引号,并以逗号分开,但是Join只能简单的分开,没有有单引号! 1.第一种拼接方案 List<string> arrIds new List<string>(); arrIds.Add("aa&qu…...
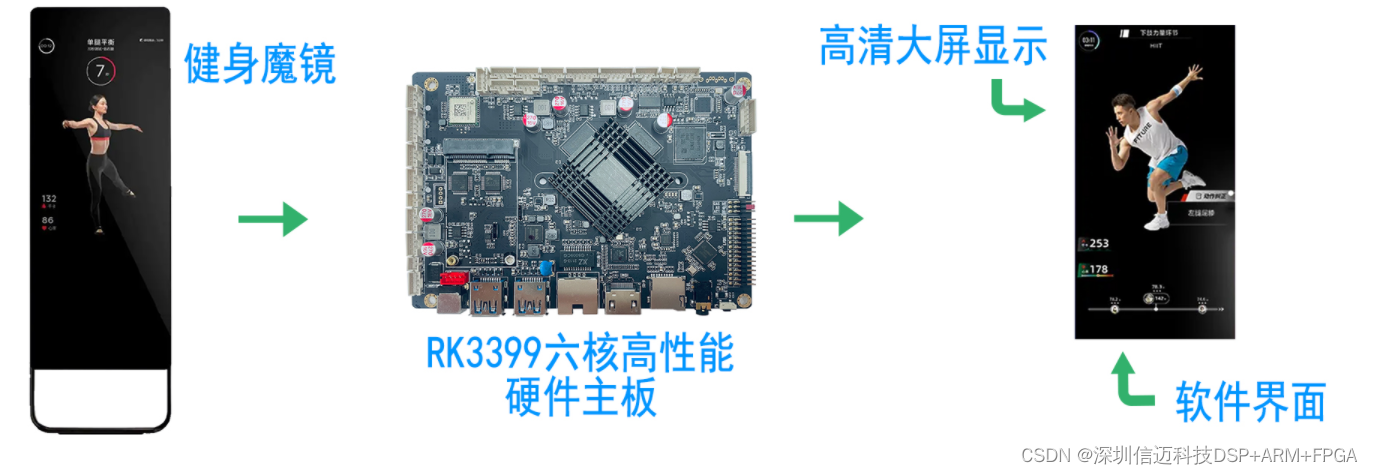
基于RK3399的室内健身魔镜方案
I 方案背景 一、健身魔镜的兴起 2020年疫情席卷全球,宅家是防疫的措施之一,因而宅家运动火爆,随之而来的宅家运动器材也风靡起来,其中包含既有颜值又具有多种功能的健身魔镜。 Ⅱ 方案介绍 一、健身魔镜的方案介绍 …...

leetCode 25.K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。k 是一个正整数,它的值小于 或 等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。你不能只是单纯的改变节点内部的值&a…...
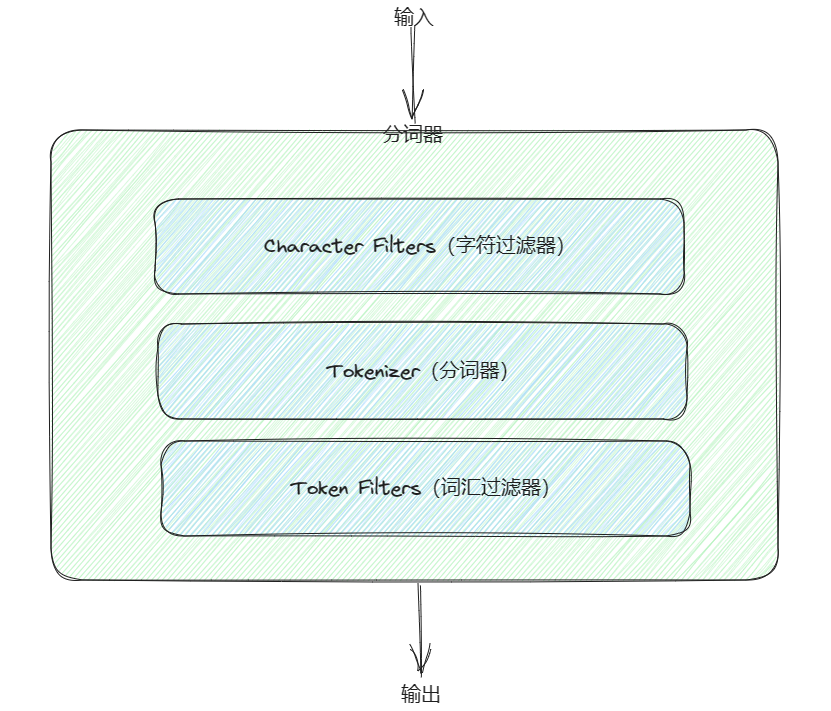
ElasticSearch中常见的分词器介绍
文章目录 ElasticSearch中常见的分词器介绍前言分词器的作用如何指定分词器分词器的组成分词器的类型标准分词器空格分词器简单分词器关键词分词器停用词分词器IK分词器NGram分词器正则匹配分词器语言分词器自定义分词器 ElasticSearch中常见的分词器介绍 前言 ElasticSearch是…...

前端案例-css实现ul中对li进行换行
场景描述: 我想要实现,在展示的item个数少于4个的时候,则排成一行,并且均分(比如说有3个,则每个的宽度为33.3%),如果item 个数大于4,则进行换行。 效果如下:…...
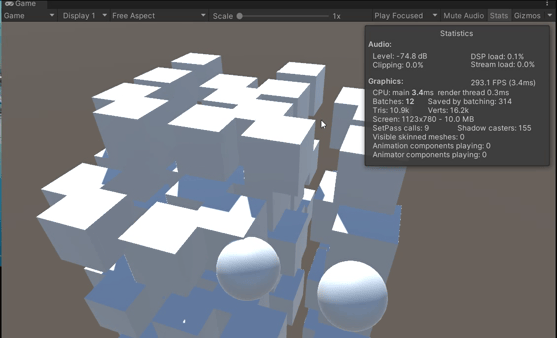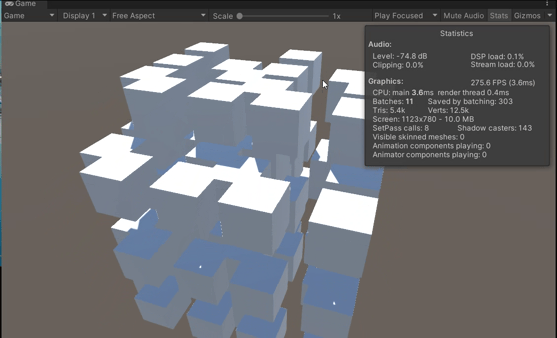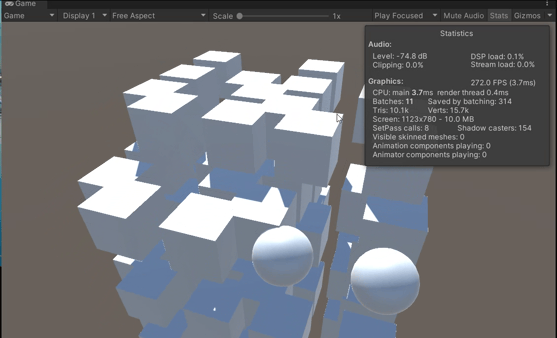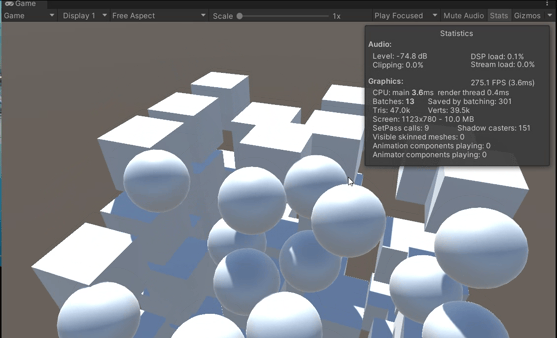
【Unity】 场景优化策略
Unity 场景优化策略 GPU instancing 使用GPU Instancing可以将多个网格相同、材质相同、材质属性可以不同的物体合并为一个批次,从而减少Draw Calls的次数。这可以提高性能和渲染效率。 GPU instancing可用于绘制在场景中多次出现的几何体,例如树木或…...

JavaWeb Day09 Mybatis-基础操作01-增删改查
目录 环境准备 ①Emp.sql ②Emp.java 一、删除 ①Mapper层 ②测试类 ③预编译SQL(查看mybatis日志) 1.性能 2.安全 ④总结 二、新增 ①Mapper层 ②测试类 ③结果 ④新增(主键返回) 1.Mapper层 2.测试类 ⑤总结…...

2.前端调试(控制台使用)
消息堆叠 如果一条消息连续重复,而不是在新行上输出每一个消息实例,控制台将“堆叠”消息并在左侧外边距显示一个数字。此数字表示该消息已重复的次数。 如果您倾向于为每一个日志使用一个独特的行条目,请在 DevTools 设置中启用 Show times…...
Jenkins简介及Docker Compose部署
Jenkins是一个开源的自动化服务器,用于自动化构建、测试和部署软件项目。它提供了丰富的插件生态系统,支持各种编程语言和工具,使得软件开发流程更加高效和可靠。在本文中,我们将介绍Jenkins的基本概念,并展示如何使用…...
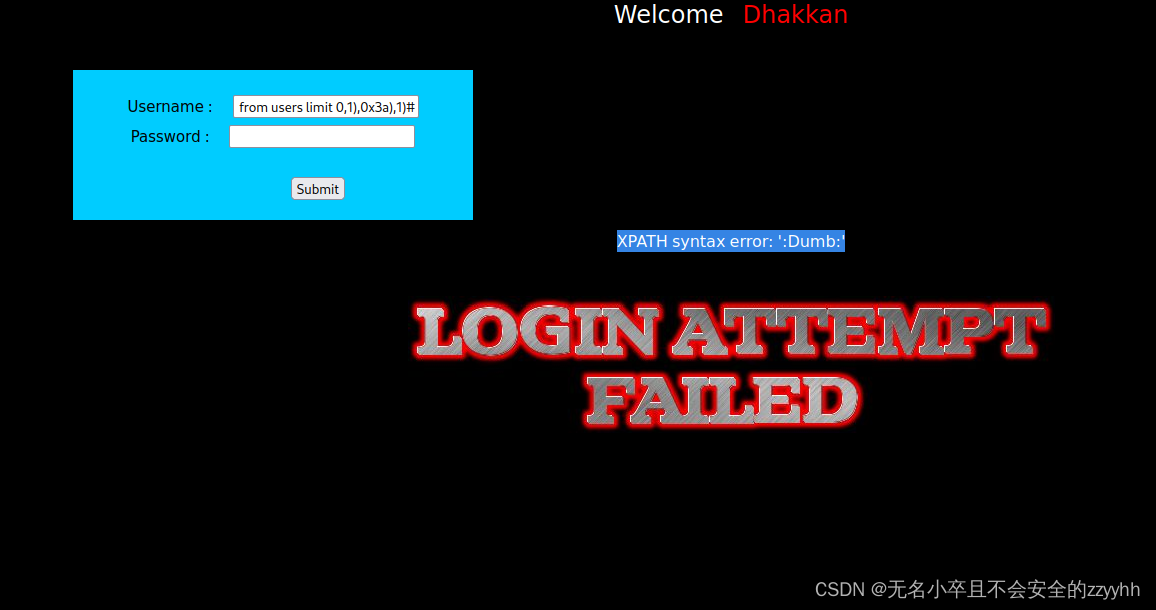
sqli-labs关卡14(基于post提交的双引号闭合的报错注入)通关思路
文章目录 前言一、回顾上一关知识点二、靶场第十四关通关思路1、判断注入点2、爆显位3、爆数据库名4、爆数据库表5、爆数据库列6、爆数据库关键信息 总结 前言 此文章只用于学习和反思巩固sql注入知识,禁止用于做非法攻击。注意靶场是可以练习的平台,不…...

【广州华锐互动】楼宇智能化VR虚拟教学系统
在如今的技术时代,教育行业正在逐步引入各种创新方法以提升教学质量。VR公司广州华锐互动开发的楼宇智能化VR虚拟教学系统就是其中的一种,它利用虚拟现实(VR)技术,为学生提供一种全新的、沉浸式的学习体验。 楼宇智能化VR虚拟教学系统涵盖综合…...

UE5 BaseEditorSettings.ini加载原理与配置生效机制
1. 为什么你改了BaseEditorSettings.ini却没生效?——从UE5编辑器启动流程讲起很多人在UE5项目里折腾半天,把BaseEditorSettings.ini文件翻来覆去改了十几遍,重启编辑器后发现:缩放比例还是不对、网格间距没变、甚至“启用实时预览…...
原理与ScalableHD架构优化实践)
超维计算(HDC)原理与ScalableHD架构优化实践
1. 超维计算(HDC)基础解析超维计算(Hyperdimensional Computing, HDC)是一种受大脑信息处理机制启发的计算范式,其核心思想是用高维随机向量(通常称为超向量或HV)来表示和处理信息。与传统神经网…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制
如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web…...

如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南
如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重新焕发活力&a…...

HarmonyOS DateUtil 日期工具入门:格式化、时间戳与今日信息
文章目录背景一、HarmonyOS 日期处理的痛点二、核心方法:getFormatDate三、时间戳自动补位四、核心方法:getFormatDateStr五、今日信息快速获取六、完整 Demo 演示6.1 刷新当前时间6.2 格式化演示6.3 常用格式展示6.4 基础信息 UI6.5 intl.DateTimeForma…...

3步解决英雄联盟回放难题:ROFL-Player终极使用指南
3步解决英雄联盟回放难题:ROFL-Player终极使用指南 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 你是否曾经遇到过这样的烦…...

游戏开发/机器人导航必看:极坐标到底比XY坐标强在哪?Unity/ROS中的实战案例
你的输出 (必须严格遵循以下YAML格式,无需任何分析过程)相关性: ... 改写后查询: ... 企业名称: ... 基础信息: ... 职位: ... json {"business_segment": "礼品","main_product": "百度电商","reason": "用…...

基于Arduino与ADXL335的自制地震预警系统:从传感器原理到多点联动实现
1. 项目概述与核心思路最近在捣鼓一个挺有意思的玩意儿——一个能自主工作的地震预警系统。这可不是什么高深莫测的科研项目,而是基于一些常见的电子模块,自己动手就能搭建起来的实用装置。它的核心目标很明确:当检测到建筑物出现异常振动时&…...

九大网盘直链解析工具:如何让文件传输效率提升300%以上
九大网盘直链解析工具:如何让文件传输效率提升300%以上 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...