ElasticSearch中常见的分词器介绍
文章目录
- ElasticSearch中常见的分词器介绍
- 前言
- 分词器的作用
- 如何指定分词器
- 分词器的组成
- 分词器的类型
- 标准分词器
- 空格分词器
- 简单分词器
- 关键词分词器
- 停用词分词器
- IK分词器
- NGram分词器
- 正则匹配分词器
- 语言分词器
- 自定义分词器
ElasticSearch中常见的分词器介绍
前言
ElasticSearch是一个高效的分布式搜索引擎,其中分词器是它的核心组件之一,平常开发中选择一个合适的分词器可以很大程度上提高检索效率,所以特意花点时间快速了解ElasticSearch中各大常见的分词器,本文也将分别介绍ElasticSearch中常见的几大分词器的特点、适用场景,以及如何使用
推荐阅读:
- ElasticSearch快速入门_知识汲取者的博客-CSDN博客
分词器的作用
分词器是在搜索引擎和文本处理中起关键作用的组件,它负责将文本切分成一个个有意义的词语,以建立索引或进行搜索和分析。
上面可能说的有一些太官方了,详细点说就是,ES搜索引擎是根据词条进行检索的,这里的词条相当于MySQL中的索引,是ElasticSearch能实现海量数据高效检索的核心,在MySQL中,如果我们不恰当的建立索引,就会影响数据库的查询性能,比如我们为区分度不大的字段建立索引,SQL优化器评测发现走索引性能和全表扫描的性能差不多,这时候就直接进行全表扫描了,此时索引就一点作用都没有了,同理这个分词也是一样的道理,他都目的也是将一个一句话分成若干个词条,以词条为索引,以此来提高检索的效率和检索的正确性。
再举一个实际的例子,比如这里有一句话“他们在商店买了一些苹果手机和一些苹果”,如果我们分词时将苹果手机进行拆分,我们搜索苹果手机,可能无法搜索出带有苹果手机的文档
他们 在 商店 买 一些 苹果 手机 和 一些 苹果而一下的分词,则可以正确搜索出带有苹果手机的词条
他们 在 商店 买 了 一些 苹果手机 和 一些 苹果
- 文本切分: 分词器根据一定的规则将文本切分为单个的词语或词汇单元。这个过程通常涉及到处理空格、标点符号、停用词等。
- 标准化: 分词器可以对词语进行标准化,例如将所有字符转为小写,以实现大小写不敏感的搜索。这有助于提高搜索的准确性。
- 去除停用词: 分词器通常会去除一些常见的停用词,这些词语在搜索中往往没有实际的意义,例如 “and”, “the”, “is” 等。
- 词干化: 对于词语的各种形式(如单数和复数、动词的不同时态等),分词器可以将它们转化为同一个基本形式,以提高搜索的准确性。
- 自定义规则: 分词器允许用户根据具体需求定义自己的切分规则、标准化规则等,以适应特定的搜索场景。
- 支持多语言: 对于全球化的应用,分词器能够支持多种语言,包括中文、英文、法文等,以确保对不同语言的文本都能有效地进行处理。
- 支持搜索建议: 通过使用边缘 n-gram 等技术,分词器可以支持搜索建议功能,提供更智能的搜索提示。
如何指定分词器
-
方式一:创建索引时,通过映射直接指定分词器
PUT /your_index_name {"mappings": {"properties": {"your_field_name": {"type": "text","analyzer": "your_analyzer_name"},// other fields...}} } -
Step2:修改索引时,通过修改映射修改分词器
PUT /your_index_name/_mapping {"properties": {"your_field_name": {"type": "text","analyzer": "your_analyzer_name"},// other fields...} }
注意:
- 如果不指定分词器,则默认使用标准分词器
standard - 不同的字段可以使用不同的分词器,根据实际需求选择适当的分词策略
- ElasticSearch默认自带
Standard Analyzer、Whitespace Analyzer、Simple Analyzer、Keyword Analyzer、Stop Analyzer等分词器,其它分词器,比如:IK Analyzer需要手动下载
分词器的组成
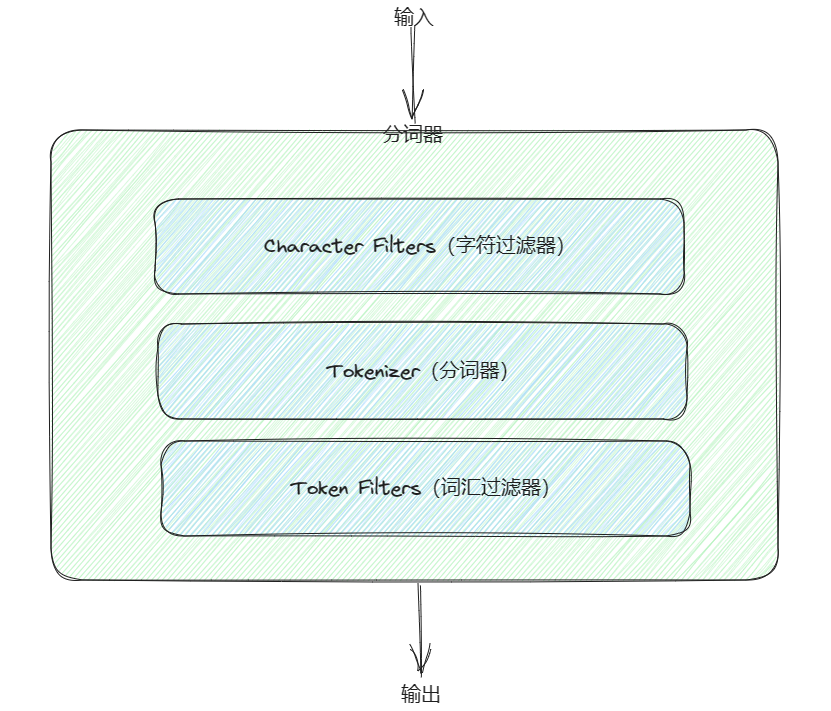
分词器主要由以下三部分组成
- Character Filters(字符过滤器):这一步针对原始文本进行预处理,对文本中的字符进行修改或删除。例如,去除 HTML 标签、替换特定字符等。
- Tokenizer(分词器):分词器将经过字符过滤器处理后的文本切分成一个个的词条,形成一个词条流。切分的规则可以是按空格、标点符号等,或者根据某种特定的算法,比如边缘 n-gram。
- Token Filters(词汇过滤器):这一步对切分后的词条流进行进一步的处理。可以进行词条的大小写转换、删除停用词(常用但无实际意义的词语)、词干化等操作。词汇过滤器对于调整文本以适应索引和搜索的需求非常重要。
分词器的类型
| 分词器 | 分词依据 | 特点 |
|---|---|---|
| Standard Analyzer | 空格、标点符号 | 小写化处理、过滤符号 |
| Whitespace Analyzer | 空格 | 不进行小写化处理、保留所有字符 |
| Simple Analyzer | 非字母(符号、数字) | 小写化处理、过滤符号、支持中文拼音分词 |
| Keyword Analyzer | 无 | 将整个输入作为一个词条 |
| Stop Analyzer | 空格 | 小写化处理、过滤停用词 |
| IK Analyzer | 词典 | 中文分词 |
| Edge NGram Analyzer | n-gram | 按指定步长进行分词 |
| Pattern Analyzer | 正则匹配字符 | 较为灵活 |
| Language Analyzer | 空格 | 支持多国语言 |
| Custom Analyzer | 自定义 | 灵活 |
标准分词器
-
Standard Analyzer(默认):
- 类型:
standard - 特点:
- 根据空格和标点符号分割文本
- 进行小写化处理
- 过滤符号
- 适用场景:适用于通用的全文搜索
示例:
原始文本:"The quick brown fox jumps over the lazy dog." 分词结果:["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"] - 类型:
空格分词器
-
Whitespace Analyzer:
- 类型:
whitespace - 特点:
- 根据空格分割文本
- 不进行小写化
- 保留所有字符
- 适用场景:适用于不需要额外处理的精确匹配场景。
示例:
原始文本:"The quick brown fox jumps over the lazy dog." 分词结果:["The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog."] - 类型:
简单分词器
-
Simple Analyzer:
-
类型:
simple -
特点:
- 按非字母切分
- 连续的数字为一个词条
- 进行小写处理
- 过滤符号
- 中文字单独建索引,并且把中文字转成拼音后也建搜索,这样就能同时支持中文和拼音检索。另外把拼音首字母也建索引,这样搜索 zjl 就能命中 “周杰伦”。
-
适用场景:适用一些简单的中文分词
示例:
原始文本:"The quick brown fox jumps over the lazy dog." 分词结果:["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"] -
关键词分词器
-
Keyword Analyzer:
- 类型:
keyword - 特点: 将整个输入视为单个关键字,不进行分词。
- 适用场景:适用于不需要分词的场景,比如精确匹配。
示例:
原始文本:"The quick brown fox jumps over the lazy dog." 分词结果:["The quick brown fox jumps over the lazy dog."] - 类型:
停用词分词器
-
Stop Analyzer:
- 类型:
stop - 特点:
- 去除停用词(is、a、the……)
- 根据空格分割文本
- 进行小写化处理。
- 适用场景:适用于需要去除常见停用词的场景。
示例:
原始文本:"The quick brown fox jumps over the lazy dog." 分词结果:["quick", "brown", "fox", "jumps", "over", "lazy", "dog"] - 类型:
IK分词器
-
IK Analyzer:
详情请参考:https://github.com/medcl/elasticsearch-analysis-ik
- 类型:
ik_max_word:会将文本做最细粒度的拆分,会穷尽各种可能的组合,适合 Term Queryik_smart:会做最粗粒度的拆分,不会对同一个词进行重复分词,适合 Phrase 查询
- 适用场景:适用于中文文本分析。
示例:
原始文本:"中华人民共和国国歌" ik_max_word分词结果:["中华人民共和国", "中华人民", "中华", "华人", "人民共和国", "人民", "人", "民", "共和国", "共和", "和", "国国", "国歌"] ik_smart分词结果:["中华人民共和国", "国歌"] - 类型:
-
ik分词器的使用步骤
- Step1:下载ik分词器
- Step2:将下载的压缩包解压到 Elasticsearch 插件目录(
plugins文件夹)中 - Step3:重启ElasticSearch
- Step4:直接指定即可
NGram分词器
-
NGram Analyzer:
详情参考:ElasticSearch之ngram分词器-CSDN博客
-
类型:
edge_ngram:从单词的开头提取 n-gramngram:在整个单词中提取 n-gram
-
适用场景:适用于前缀搜索和搜索建议
示例:
原始文本:"I am Chinese."edge_ngram分词结果: n=2(bigram): ["I am", "am Chinese."] n=3(trigram): ["I am Chinese."] n=4(four-gram): ["I am Chinese."]ngram分词结果: n=2(bigram): ["I am", "am Chinese."] n=3(trigram): ["I am Chinese."] n=4(four-gram): ["I am Chinese."]备注:
- NGram Analyzer 不会过滤符号
- NGram Analyzer默认的步长是1
{"settings": {// 创建分词器"analysis": {"analyzer": {"my_edge_ngram_analyzer": {"tokenizer": "standard", // 指定分词器"filter": ["my_edge_ngram_filter"] // 指定词汇过滤器}},"filter": {"my_edge_ngram_filter": {"type": "edge_ngram","min_gram": 1, // 词汇最小长度为一个字符,注意:一个单词、数字、中文都是一个字符"max_gram": 10 // 词汇最大长度为10个字符}}}},"mappings": {"properties": {"content": {"type": "text","analyzer": "my_edge_ngram_analyzer" // 使用我们配置的分词器}}} }知识拓展:n-gram 概念
n-gram 是一种文本处理的方法,其中 “n” 表示包含的元素的数量。在自然语言处理和信息检索中,n-gram 通常指的是连续的 n 个单词(或字符)序列。
- Unigram(1-gram): 包含一个单词的序列。例如,对于句子 “The quick brown fox”,每个单词都是一个 unigram。
- Bigram(2-gram): 包含两个相邻单词的序列。例如,对于句子 “The quick brown fox”,bigrams 包括 “The quick”、“quick brown”、“brown fox”。
- Trigram(3-gram): 包含三个相邻单词的序列。例如,对于句子 “The quick brown fox”,trigrams 包括 “The quick brown”、“quick brown fox”。
这个 n 表示按照几个单词来进行划分
-
正则匹配分词器
- Pattern Analyzer
- 类型:
pattern - 特点:根据正则匹配进行分词
- 类型:
{"settings": {"analysis": {"analyzer": {"my_pattern_analyzer": {"type": "pattern","pattern": "\\W+" // 正则表达式模式,表示使用非单词字符作为分隔符}}}},"mappings": {"properties": {"content": {"type": "text","analyzer": "my_pattern_analyzer"}}}
}
上诉配置的 Pattern Analyzer 与 Standard Analyzer的效果是一模一样的
语言分词器
- Language Analyzer
- 类型
english:英语分词器french:法语分词器
- 特点:
- 支持多个不同国家语言的分词,但就是没有支持中文的(中文分词器还得靠国内大佬或机构开发)
- 应用英文的 Stop Analyzer(停用词过滤器)
- 单词小写化
- 不会过滤符号
- 适用场景:一些国际化的软件可能会用,但是面向国内用户基本上用不上
- 类型
{"mappings": {"properties": {"content": {"type": "text","analyzer": "english"}}}
}原始文本:"The quick brown fox jumps over the lazy dog."
分词结果:["quick", "brown", "fox", "jumps", "over", "lazy", "dog"]
自定义分词器
-
Custom Analyzer:
-
类型:
custom -
特点: 可以根据具体需求自定义分词器,包括指定分词器、字符过滤器、标记过滤器等。
-
适用场景:现有分词器不满足当前功能,或者想要实现更加高效且灵活的分词
-
-
实现自定义分词器的步骤:
- Step1:定义字符过滤器(Char Filter),可以通过字符过滤器执行预处理,例如删除 HTML 标签或进行字符替换。
- Step2:定义分词器(Tokenizer), 分词器负责将文本切分为单词或词条。可以选择现有的分词器,也可以创建自定义的分词逻辑。
- Step3:定义词汇过滤器(Token Filter) ,可以通过词汇过滤器对切分后的单词进行进一步处理,例如小写处理、停用词过滤、同义词处理等。
- Step4:创建 Custom Analyzer ,将定义的字符过滤器、分词器和词汇过滤器组合成一个自定义的
Custom Analyzer。 - Step5:将 Custom Analyzer 应用到字段 ,在创建索引时,将自定义的
Custom Analyzer分配给相应的字段。
示例:
在下面的示例中,
my_analyzer是一个自定义的Custom Analyzer,包含了一个 HTML 标签过滤器、标准分词器和小写过滤器。该分析器被应用于名为 “content” 的字段。实际上,你可以根据需求自定义各个组件,以满足你的分词需求。
{"settings": {"analysis": {// 指定字符过滤器"char_filter": {"my_char_filter": {"type": "html_strip" // 去除文本中的 HTML 标签的字符过滤器}},// 指定分词器"tokenizer": {"my_tokenizer": {"type": "standard" // 指定标准分词器,按照标准分词器进行分词}},// 指定词汇过滤器"filter": {"my_filter": {"type": "lowercase" // 小写化处理}},// 创建自定义分词器"analyzer": {"my_analyzer": {"type": "custom","char_filter": ["my_char_filter"],"tokenizer": "my_tokenizer","filter": ["my_filter"]}}}},"mappings": {"properties": {"content": { // 给 content 字段应用 自定义分词器"type": "text","analyzer": "my_analyzer"}}}
}
原始文本:<p>This is <strong>bold</strong> text.</p>
分词结果:["this", "is", "bold", "text"]
参考资料:
- Anatomy of an analyzer | Elasticsearch Guide 8.11| Elastic
- ElasticSearch 分词器,了解一下 - 知乎 (zhihu.com)
相关文章:
ElasticSearch中常见的分词器介绍
文章目录 ElasticSearch中常见的分词器介绍前言分词器的作用如何指定分词器分词器的组成分词器的类型标准分词器空格分词器简单分词器关键词分词器停用词分词器IK分词器NGram分词器正则匹配分词器语言分词器自定义分词器 ElasticSearch中常见的分词器介绍 前言 ElasticSearch是…...

前端案例-css实现ul中对li进行换行
场景描述: 我想要实现,在展示的item个数少于4个的时候,则排成一行,并且均分(比如说有3个,则每个的宽度为33.3%),如果item 个数大于4,则进行换行。 效果如下:…...
【Unity】 场景优化策略
Unity 场景优化策略 GPU instancing 使用GPU Instancing可以将多个网格相同、材质相同、材质属性可以不同的物体合并为一个批次,从而减少Draw Calls的次数。这可以提高性能和渲染效率。 GPU instancing可用于绘制在场景中多次出现的几何体,例如树木或…...

JavaWeb Day09 Mybatis-基础操作01-增删改查
目录 环境准备 ①Emp.sql ②Emp.java 一、删除 ①Mapper层 ②测试类 ③预编译SQL(查看mybatis日志) 1.性能 2.安全 ④总结 二、新增 ①Mapper层 ②测试类 ③结果 ④新增(主键返回) 1.Mapper层 2.测试类 ⑤总结…...

2.前端调试(控制台使用)
消息堆叠 如果一条消息连续重复,而不是在新行上输出每一个消息实例,控制台将“堆叠”消息并在左侧外边距显示一个数字。此数字表示该消息已重复的次数。 如果您倾向于为每一个日志使用一个独特的行条目,请在 DevTools 设置中启用 Show times…...
Jenkins简介及Docker Compose部署
Jenkins是一个开源的自动化服务器,用于自动化构建、测试和部署软件项目。它提供了丰富的插件生态系统,支持各种编程语言和工具,使得软件开发流程更加高效和可靠。在本文中,我们将介绍Jenkins的基本概念,并展示如何使用…...
sqli-labs关卡14(基于post提交的双引号闭合的报错注入)通关思路
文章目录 前言一、回顾上一关知识点二、靶场第十四关通关思路1、判断注入点2、爆显位3、爆数据库名4、爆数据库表5、爆数据库列6、爆数据库关键信息 总结 前言 此文章只用于学习和反思巩固sql注入知识,禁止用于做非法攻击。注意靶场是可以练习的平台,不…...

【广州华锐互动】楼宇智能化VR虚拟教学系统
在如今的技术时代,教育行业正在逐步引入各种创新方法以提升教学质量。VR公司广州华锐互动开发的楼宇智能化VR虚拟教学系统就是其中的一种,它利用虚拟现实(VR)技术,为学生提供一种全新的、沉浸式的学习体验。 楼宇智能化VR虚拟教学系统涵盖综合…...

5. HTML常用标签
5.1 标签语义 学习标签是有技巧的,重点是记住每个标签的语义。简单理解就是指标签的含义。即这个标签是用来干嘛的。 根据标签的语义,在合适的地方给一个最为合理的标签。可以让页面结构给清晰。 5.2 标题标签 <h1>-<h6>(重要) HTML提供了…...
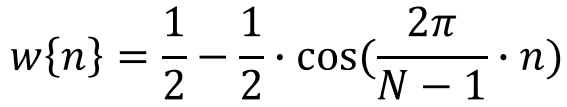
傅里叶分析(2)
在《傅里叶分析(1)》中,讲述了连续信号的傅里叶分析方法,本文讲述离散信号的傅里叶分析方法。 虽然电、声、光、机械振动等信号在物理上是连续函数,但在实际工程中,其通常为离散信号,即若干离散…...

Mysql8数据库如何给用户授权
转载自:https://blog.csdn.net/Numb_ZL/article/details/124222795 查看用户已有权限 SHOW GRANTS FOR [用户名];使用root用户授予所有权限 -- 授权 GRANT ALL PRIVILEGES ON [数据库名].[表明] TO [用户名][连接主机ip地址] WITH GRANT OPTION; -- 刷新权限 FLU…...

reticulate | R-python调用 | 安装及配置 | conda文件配置
reticulate | R-python安装及配置 | conda文件配置 1. 基础知识2. 安装reticulate from CRAN3. 包含了用于Python和R之间协同操作的全套工具,在R和Rstudio中均可使用4. 配置python环境4.1 4种环境配置方式4.2 miniconda 环境install_miniconda()报错一install_minic…...

VueRequest——管理请求状态库
文章目录 前言一、为什么选择 VueRequest?二、使用步骤1.安装2.用例 前言 VueRequest——开发文档 VueReques——GitHub地址 在以往的业务项目中,我们经常会被 loading 状态的管理、请求的节流防抖、接口数据的缓存、分页等重复的功能实现所困扰。每次开…...

GPT-4 Turbo 发布 | 大模型训练的新时代:超算互联网的调度与调优
★OpenAI;ChatGPT;Sam Altman;Assistance API;GPT4 Turbo;DALL-E 3;多模态交互;算力调度;算力调优;大模型训练;GH200;snowflake;AGI;A…...
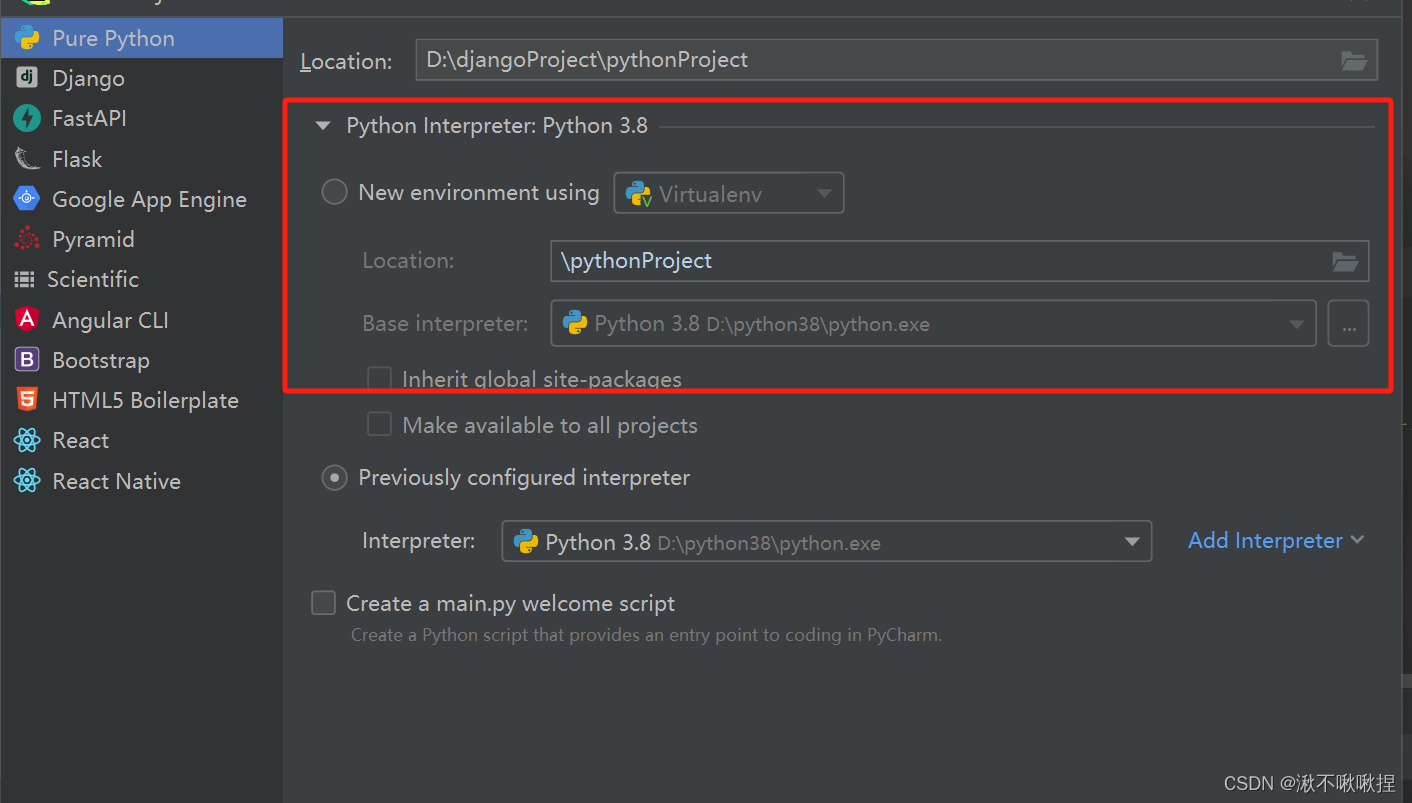
Django路由层
路由层(urls) Django的路由层是负责将用户请求映射到相应的视图函数的一层。在Django的MVT架构中,路由层负责处理用户的请求,然后将请求交给相应的视图函数进行处理,最后将处理结果返回给用户。 在Django中,…...
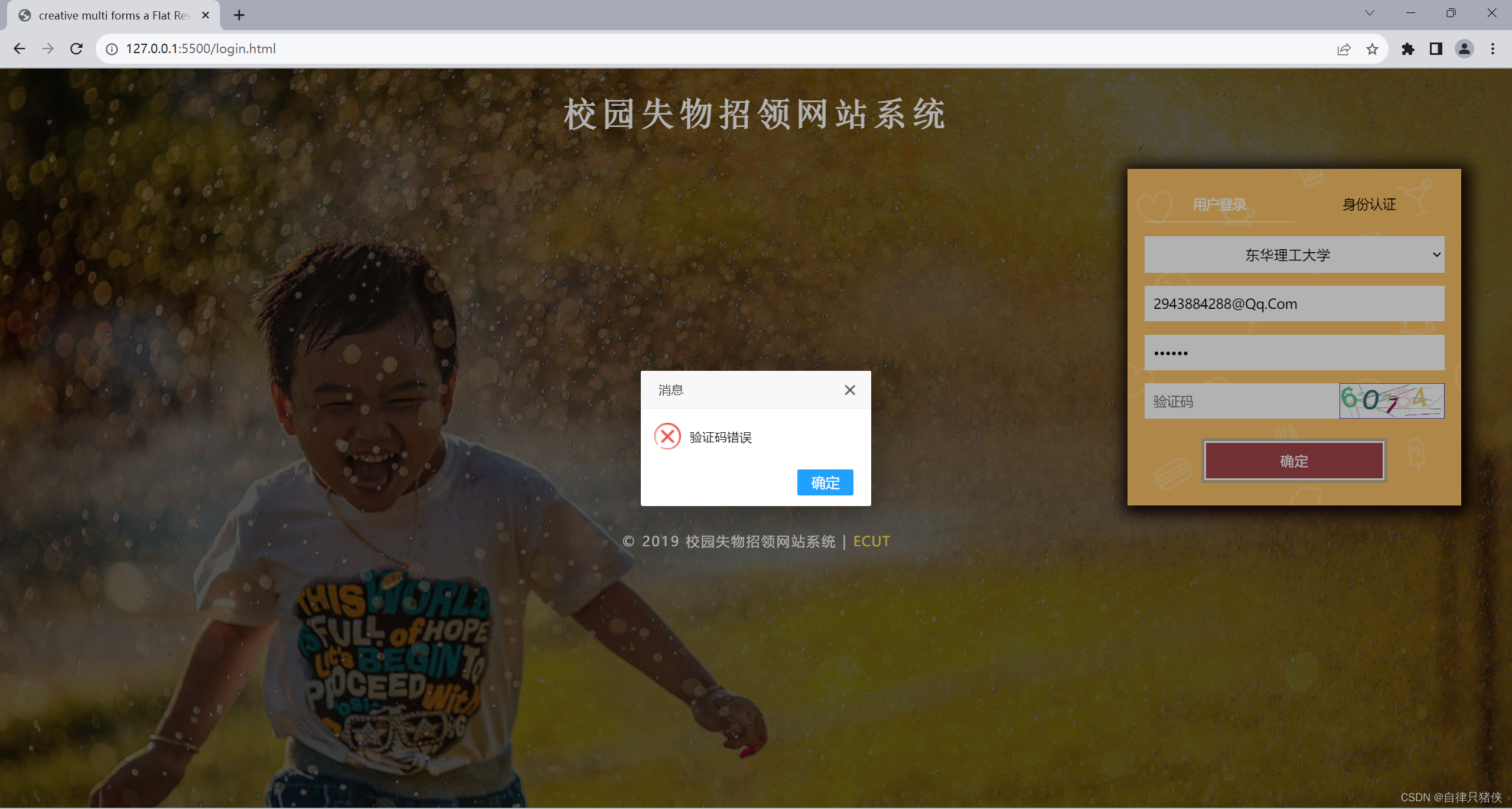
关于session的不断变化问题
今天在帮同学解决一个小问题,差点阴沟翻船。 问题再现:他从github上拉了一个项目下来跑,结果发生跑不通问题出现在验证码一直不对。 我一看项目源码,验证码生成后存储再session中了,等用户发送请求验证的时候sessionI…...
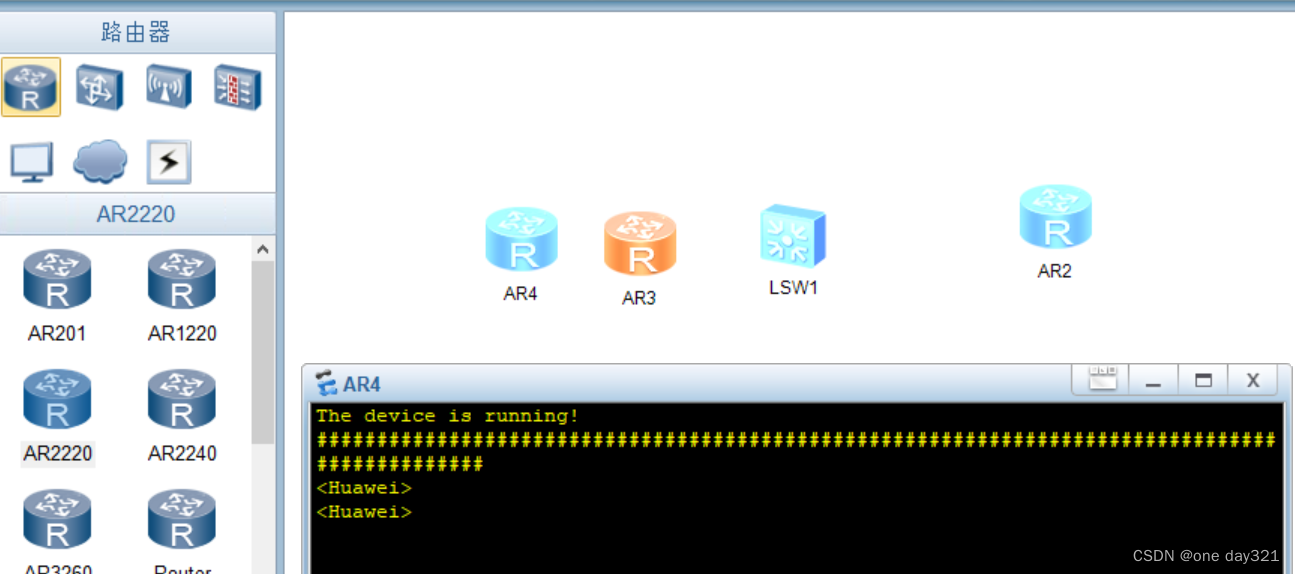
eNSP启动路由器一直出#号、以为是安装配置winpcap的问题。。。。(以为是win10安装winpcap失败的问题。。。)
问题描述:eNSP启动一直出#号的一种参考方法_ensp一直#_Hong的博客-CSDN博客 原因是看了这篇博客,觉得ensp启动路由器的时候一直出现#号是因为winpcap安装的时候出现的问题。查看自己的winpcap安装成功之后的目录是: 然后因为那篇…...

时间序列预测:深度学习、机器学习、融合模型、创新模型实战案例(附代码+数据集+原理介绍)
本文介绍->给大家推荐一下我的时间序列预测实战专栏,本专栏平均质量分98分,而且本专栏目前免费阅读。其中涉及机器学习、深度学习、融合模型、个人创新模型、数据分析等一系列有关时间序列的内容,其中的实战案例不仅有简单的模型类似于机器…...
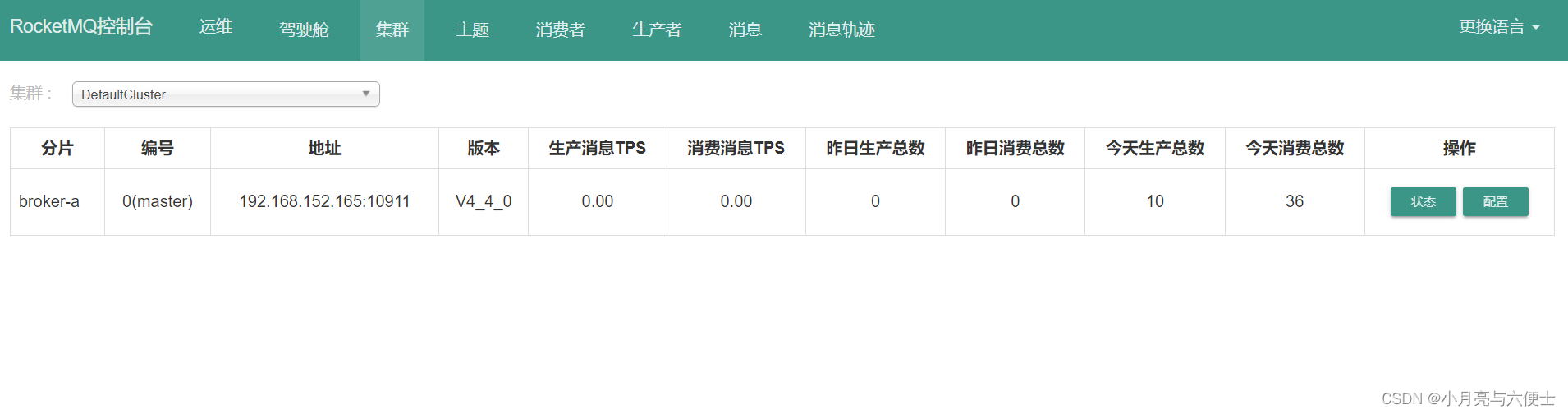
docker安装RocketMQ
1、RocketMQ基本概念 1.1 消息模型(Message Model) RocketMQ主要由Producer、Broker、Consumer三部分组成,其中Producer负责生产消息,Consumer负责消费消息,Broker负责存储消息。Broker在实际部署过程中对应一台服务…...
优秀智慧园区案例 - 珠海华发智慧园区,万字长文解析先进智慧园区建设方案经验
一、项目背景 珠海华发产业园运营管理有限公司(简称“产业园公司”)是2016年起连续五年跻身“中国企业500强”、国务院国企改革“双百企业”的珠海华发集团旗下的实体产业发展载体运营平台,依托“四园一基地”:中以国际产业园、信…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...

抖音批量下载助手:一键构建你的专属视频素材库
抖音批量下载助手:一键构建你的专属视频素材库 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为手动保存抖音视频而烦恼吗?想要批量获取心仪创作者的精彩内容却无从下手&#x…...

MT-R1-Zero:基于强化学习的机器翻译范式革新与实战指南
1. 项目概述:当强化学习遇上机器翻译 在机器翻译这个老牌的自然语言处理任务里,我们似乎已经习惯了“数据驱动”的剧本:收集海量的双语平行句对,用它们来监督训练模型,让模型学会从源语言到目标语言的映射。这套方法&a…...

免费解锁八大网盘限速!LinkSwift直链下载助手终极指南
免费解锁八大网盘限速!LinkSwift直链下载助手终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...