将随机数设成3407,让你的深度学习模型再涨一个点!文再附3种随机数设定方法
随机数重要性
深度学习已经在计算机视觉领域取得了巨大的成功,但我们是否曾想过为什么同样的模型在不同的训练过程中会有不同的表现?为什么使用同样的代码,就是和别人得到的结果不一样?怎么样才能保证自己每次跑同一个实验得到的结果都是一样的?
其中一个可能的原因就是随机数的选择。在本文中,我们将着重探讨如何通过合理设置随机数来提高深度学习模型的准确性(涨点大法)。以及如何固定随机数来保证实验的可重复性
arxiv上有篇极其离谱又很有深意的文章
torch.manual seed(3407) is all you need: On the influence of random seeds in deep learning architectures for computer vision. 论文链接
是的,你没看错,文章标题就言简意赅告诉你torch.manual seed(3407) is all you need
而且我发现很多群友已经用上了魔法(是我out了🙃)

这篇文章做了很多实验,就解决了三个问题:
-
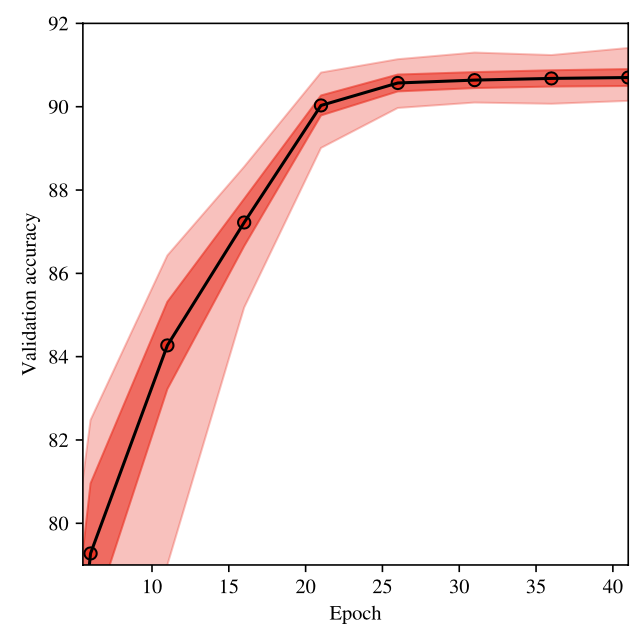
关于随机种子选择的分数分布是什么?答:随机种子变化时的精度分布相对尖锐,这意味着结果相当集中于平均值。一旦模型收敛,这种分布就相对稳定,这意味着有些种子本质上比其他种子好。
-
是否有黑天鹅,即有些种子会产生截然不同的结果?答:是。在对10000个种子的扫描中,作者获得了接近2%的最大和最小精度差异,这高于计算机视觉社区通常使用的重要阈值。(随机数设置的对,没准能涨2个点!)
-
对较大数据集的预处理是否减轻了种子选择引起的差异?答:是,它当然减少了由于使用不同种子而产生的差异,但并没有抹去这种差异,在Imagenet上,最大和最小准确度之间的差异仍然有0.5%
全文总结:随机数的选择很重要,当你涨点无果时,试下3407,没准儿有奇效~
随机数设定
那随机数怎么设置,在哪里设置呢?3种设定方法任你选,最后一种最简单!
1.pytorch中设定随机数👇
import numpy as np
import torch
import random
import osseed_value = 3407 # 设定随机数种子np.random.seed(seed_value)
random.seed(seed_value)
os.environ['PYTHONHASHSEED'] = str(seed_value) # 为了禁止hash随机化,使得实验可复现。torch.manual_seed(seed_value) # 为CPU设置随机种子
torch.cuda.manual_seed(seed_value) # 为当前GPU设置随机种子(只用一块GPU)
torch.cuda.manual_seed_all(seed_value) # 为所有GPU设置随机种子(多块GPU)torch.backends.cudnn.deterministic = True
以上代码放在所有使用随机数前就行。我习惯性放在import之后,在做事情前先把随机数设定好,比较安全。
下面进行简单地分析。愿意多看一点的继续,忙的直接粘贴复制上面代码即可。
上述代码的随机数主要是三个方面的设定。
1. python 和 numpy 随机数的设定
np.random.seed(seed_value)
random.seed(seed_value)
os.environ['PYTHONHASHSEED'] = str(seed_value) # 为了禁止hash随机化,使得实验可复现。
如果读取数据的过程采用了随机预处理(如RandomCrop、RandomHorizontalFlip等),那么对python、numpy的随机数生成器也需要设置种子。
2. pytorch 中随机数的设定
torch.manual_seed(seed_value) # 为CPU设置随机种子
torch.cuda.manual_seed(seed_value) # 为当前GPU设置随机种子(只用一块GPU)
torch.cuda.manual_seed_all(seed_value) # 为所有GPU设置随机种子(多块GPU)
pytorch中,会对模型的权重等进行初始化,因此也要设定随机数种子
3. Cudnn 中随机数的设定
cudnn中对卷积操作进行了优化,牺牲了精度来换取计算效率。如果需要保证可重复性,可以使用如下设置:
torch.backends.cudnn.deterministic = True
另外,也有人提到说dataloder中,可能由于读取顺序不同,也会造成结果的差异。这主要是由于dataloader采用了多线程(num_workers > 1)。目前暂时没有发现解决这个问题的方法,但是只要固定num_workers数目(线程数)不变,基本上也能够重复实验结果。
2.为随机数设定代码添加活动模板
这么长的代码,每次都要敲一遍,或者粘贴复制也很麻烦。因此,可以在pycharm里面设定一个模板,就可以快捷输入了。大致过程如下:
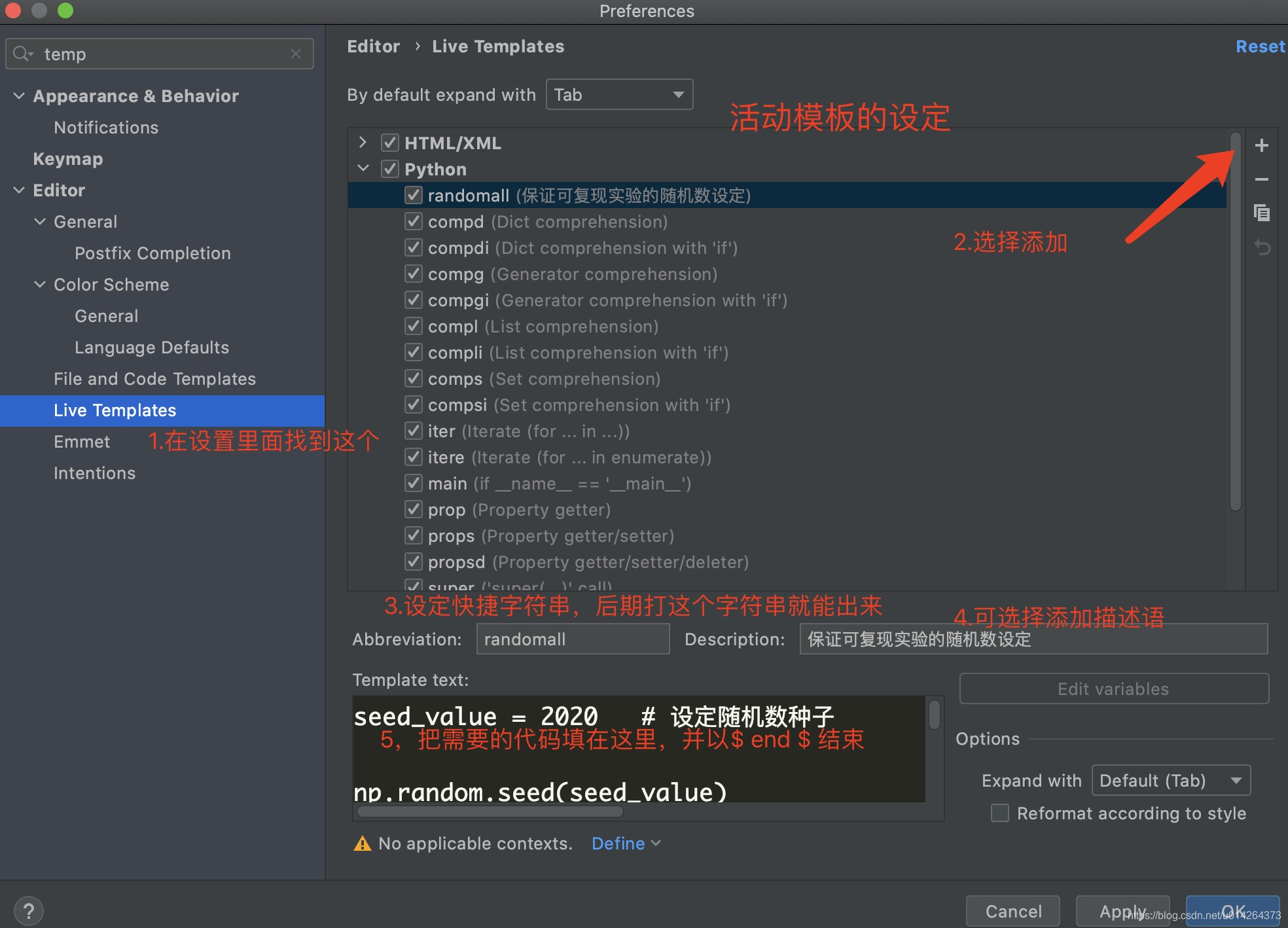
想要细节描述的可以百度 pycharm 活动模板的设定。
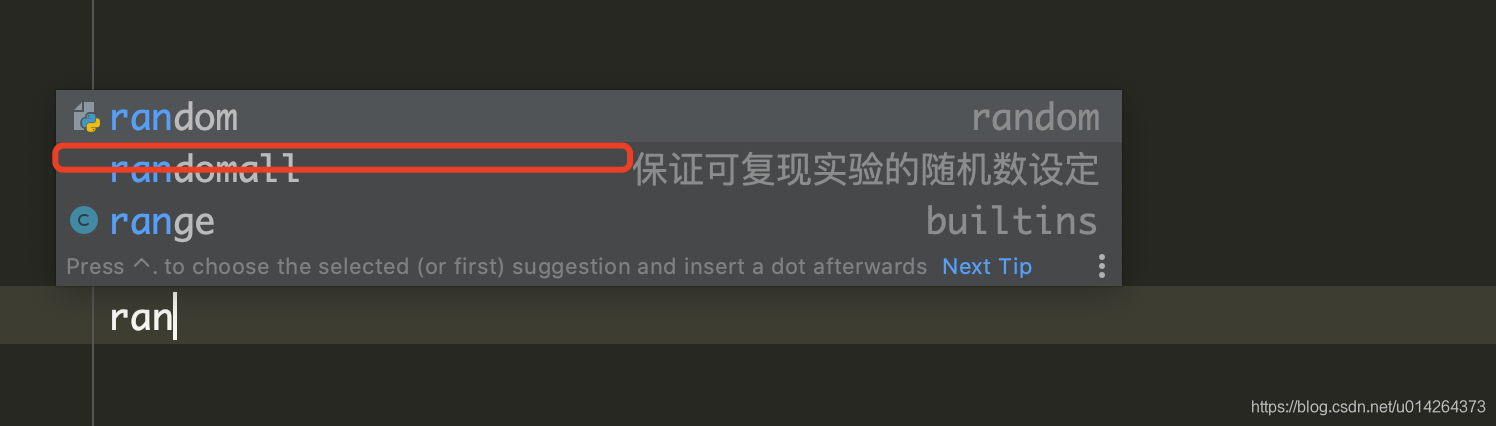
当我要使用这段代码的时候,敲自己定义的快捷字符串就可以了
3 MONAI框架随机数设定
Monai 对随机数的设定,一行代码就搞定了
from monai.utils import set_determinism
set_determinism(seed=3407)
和pytorch中使用方法是一样的,这个函数就是已经设定好了各种各样的随机数。使用起来更方便。亲测有用。
文章持续更新,可以关注微公【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持以实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连

相关文章:
将随机数设成3407,让你的深度学习模型再涨一个点!文再附3种随机数设定方法
随机数重要性 深度学习已经在计算机视觉领域取得了巨大的成功,但我们是否曾想过为什么同样的模型在不同的训练过程中会有不同的表现?为什么使用同样的代码,就是和别人得到的结果不一样?怎么样才能保证自己每次跑同一个实验得到的…...

Spring后端HttpClient实现微信小程序登录
这是微信官方提供的时序图。我们需要关注的是前后端的交互,以及服务端如何收发网络请求。 小程序端 封装基本网络请求 我们先封装一个基本的网络请求。 const baseUrl"localhost:8080" export default{sendRequsetAsync } /* e url:目标页…...

Linux下部署MySQL-MHA环境
目前的环境如下:centos7 有四台虚拟机,20,21,22,23 20为master,21,22,23 为20的从库,21 为管理节点。 搭建MySQL主从复制的,可以参考我之前的文章 MHA&#…...
开发笔记 20231114-阿里云mysql外部访问)
DaoWiki(基于Django)开发笔记 20231114-阿里云mysql外部访问
文章目录 创建mysql用户,用户远程访问配置阿里云安全策略下载安装mysql workbench 创建mysql用户,用户远程访问 创建用户 CREATE USER dao_wiki% IDENTIFIED BY password;授权访问dao_wiki数据库 GRANT ALL PRIVILEGES ON dao_wiki.* TO dao_wiki%; F…...
【UE5】 虚拟制片教程
目录 效果 步骤 一、下载素材 二、将视频转成PNG序列 三、开始虚拟制片 效果 步骤 一、下载素材 首先下载绿幕视频素材 链接:百度网盘 请输入提取码 提取码:jyfk 二、将视频转成PNG序列 打开“Adobe Premiere Pro”,导入素材 …...
集成Line、Facebook、Twitter、Google、微信、QQ、微博、支付宝的三方登录sdk
下载地址: https://githubfast.com/anerg2046/sns_auth 安装方式建议使用composer进行安装 如果linux执行composer不方便的话,可以在本地新建个文件夹,然后执行上面的composer命令,把代码sdk和composer文件一起上传到项目适当位…...

2022年09月 Python(五级)真题解析#中国电子学会#全国青少年软件编程等级考试
Python等级考试(1~6级)全部真题・点这里 一、单选题(共25题,每题2分,共50分) 第1题 已知字符串:s=“语文,数学,英语”,执行print(s.split(“,”))语句后结果是?( ) A: [‘语文’, ‘数学’, ‘英语’] B: [语文, 数学, 英语] C: [‘语文, 数学, 英语’] D: [‘语…...

C. Number of Pairs
time limit per test 2 seconds memory limit per test 256 megabytes input standard input output standard output You are given an array a� of n� integers. Find the number of pairs (i,j)(�,�) (1≤i<j≤n1≤…...
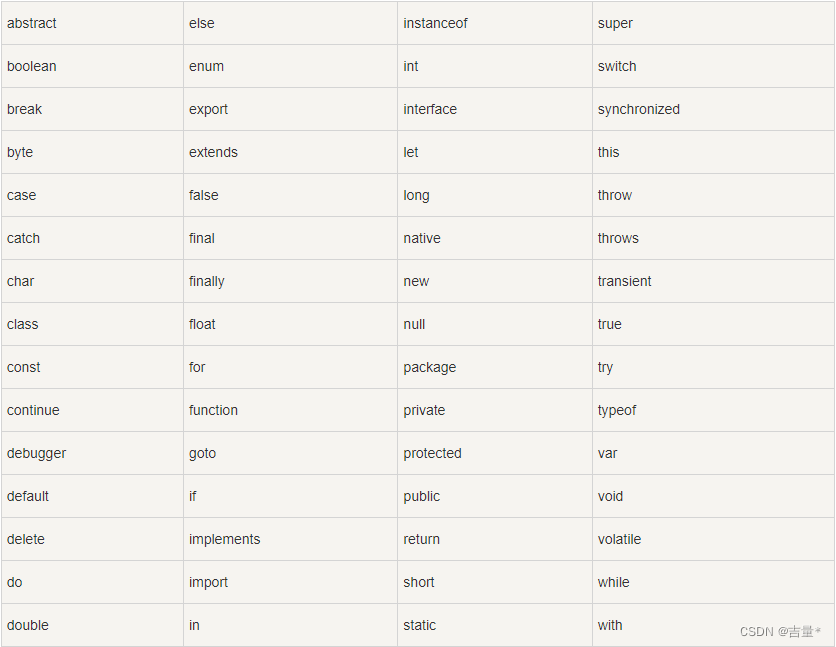
Js 保留关键字
JavaScript 关键字用于标识要执行的操作,和其他任何编程语言一样,JavaScript 保留了一些关键字为自己所用;这些关键字有些在目前的版本中可能没有使用,但在以后 JavaScript 扩展中会用到。 以下是JS中最重要的保留关键字…...

nodejs+vue+python+PHP+微信小程序-安卓-房产中介管理信息系统的设计与实现-计算机毕业设计
目 录 摘 要 I ABSTRACT II 目 录 II 第1章 绪论 1 1.1背景及意义 1 1.2 国内外研究概况 1 1.3 研究的内容 1 第2章 相关技术 3 2.1 nodejs简介 4 2.2 express框架介绍 6 2.4 MySQL数据库 4 第3章 系统分析 5 3.1 需求分析 5 3.2 系统可行性分析 5 3.2.1技术可行性:…...

【系统架构设计】架构核心知识: 3.5 Redis和ORM
目录 一 Redis 1 Redis与MemCache 2 Redis分布式存储方案 3 Redis集群切片的方式 4 Redis数据分片...

linux时间同步
搭建集群时,都会先设置时间同步,否则会出现多种问题。 方式一: 1.安装ntp软件 yum install -y ntp 2.更新时区 删除原有时区:sudo rm -f /etc/localtime 加载新时区:sudo ln -s /usr/share/zoneinfo/Asia/Shangh…...

mysql++库connected与ping方法的区别
mysql库connected与ping方法的区别 前段时间开发公司代码的时候,我写了一个多线程调用数据库的函数,每个线程都是要连接数据库的,为了防止在查找数据之前,线程连接数据库断开,我使用定时器每20s检测一下线程连接数据库…...

拆位线段树 E. XOR on Segment
Problem - E - Codeforces 区间求和,区间异或的操作跟线段树的区间求和、区间相见相似,考虑用线段树。 发现数组初始值最多是1e6,有不到25位,可以知道异或最大值是这些位数全是1的情况。 发现可以对每一位进行运算就和。 我们开…...
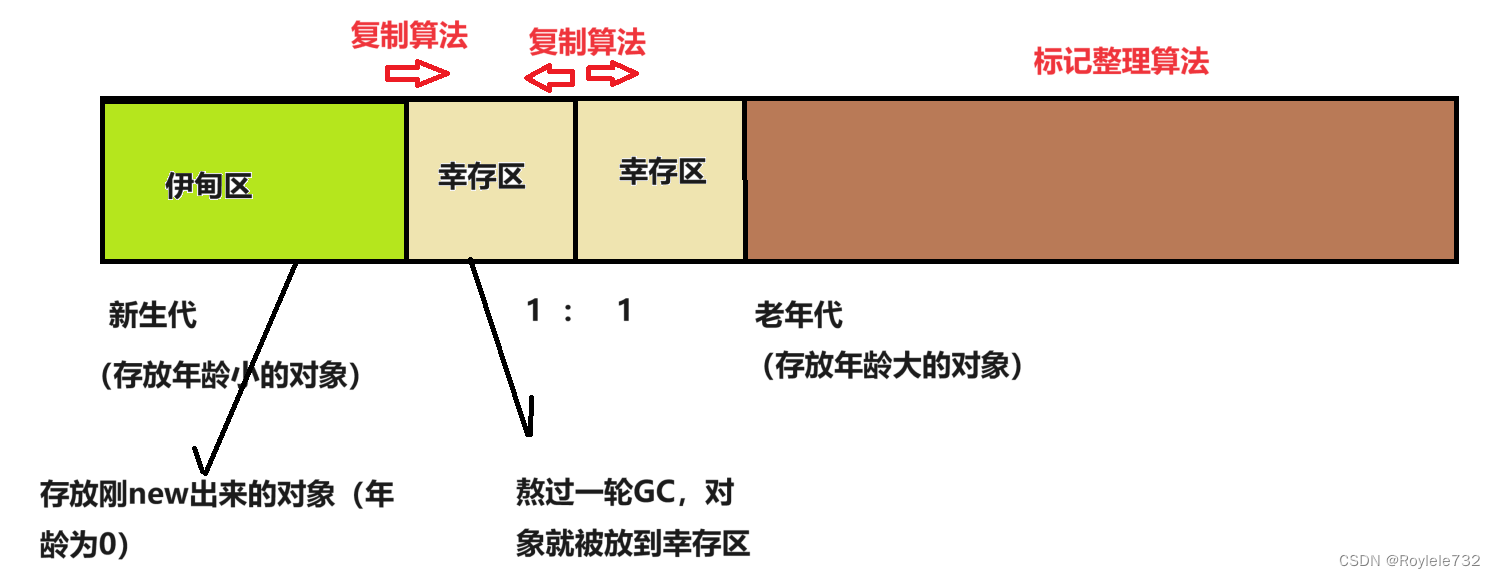
JVM及其垃圾回收机制(GC)
目录 一.JVM内存区域划分 二.JVM类加载机制 类加载过程 类加载的时机 双亲委派模型 三.JVM垃圾回收机制(GC) GC工作过程 1.找到垃圾/判断垃圾 (1)引用计数【python/PHP】 (2)可达性分析【Java】 2.对象释放…...

友元的三种实现
友元的三种实现 全局函数做友元类做友元成员函数做友元 #include <iostream> #include <string> using namespace std;//友元的三种实现 // //* 全局函数做友元 //* 类做友元 //* 成员函数做友元class Building {//告诉编译器 goodGay全局函数 是 Building类的好…...

聊聊logback的DuplicateMessageFilter
序 本文主要研究一下logback的DuplicateMessageFilter TurboFilter ch/qos/logback/classic/turbo/TurboFilter.java public abstract class TurboFilter extends ContextAwareBase implements LifeCycle {private String name;boolean start false;/*** Make a decision …...
WordPress 文档主题模板Red Line -v0.2.2
此主题作为框架,做承载第三方页面之用,例如飞书文档等, 您可以将视频图片等资源放第三方文档上,通过使用此主题做目录用。 此主题使用前后端分离开发,也使用了一些技术尽量不影响正常的SEO,还望注意。 源码…...

网络和Linux网络_1(网络基础)网络概念+协议概念+网络通信原理
目录 1. 网络简介 1.1 独立模式和互联网络模式 1.2 局域网LAN和广域网WAN 2. 协议和协议分层 2.1 协议的作用 2.2 协议分层 2.3 OSI七层模型 3.2 TCP/IP四层(五层)模型 3. 网络通信原理 3.1 协议报头 3.2 局域网和解包分用 3.3 广域网和跨网络 4. 网络中的地址 4…...
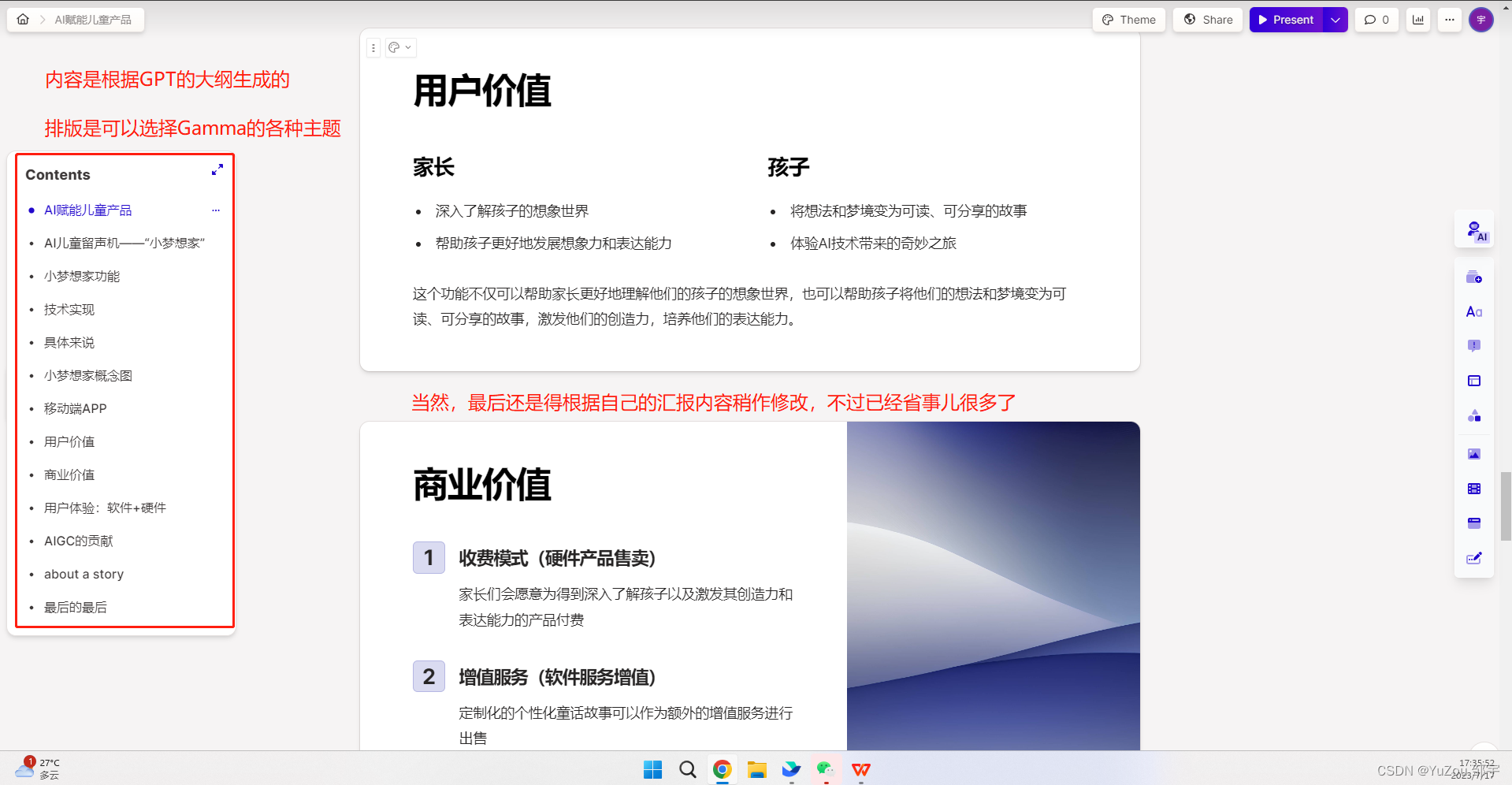
AI生成PPT工具——Gamma,结合GPT生成不错的效果
AI生成PPT工具——Gamma,结合GPT生成不错的效果 先告诉GPT我现在要参加一个比赛,请他帮忙梳理一下内容。当然整个过程需要不断调整,GPT生成的内容也不是一次就是最好的 不断调整之后让其列出提纲即可,如下: 紧接着我们…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...
)
别再纠结了!给激光焊接新手讲透单模和多模激光到底怎么选(附M²因子解读)
激光焊接设备选型指南:单模与多模激光的实战抉择 当你第一次站在激光焊接设备采购的十字路口,面对"单模"和"多模"这两个专业术语时,那种迷茫感我深有体会。五年前,我作为产线技术负责人,需要为汽车…...
)
YOLOv8道路交通信号标志识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 道路交通信号标志的自动检测是智能驾驶与交通管理系统中的核心环节。本文基于YOLOv8目标检测算法,构建了一个涵盖21类常见交通信号标志的检测系统,包括禁令标志、指示标志、警告标志及信号灯等。模型在包含1376张训练图像、488张验证图像和229张测…...

Midjourney V6锐化失控?3步诊断+5组--sref/--stylize协同参数公式,立竿见影修复模糊与锯齿
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6锐化失控的本质归因 Midjourney V6 引入的全新扩散架构与隐式细节增强机制,导致图像生成过程中高频纹理被过度强化,其根本原因并非参数误配,而是模型在…...
:从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界)
DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界 选择适配业务场景的DeepSeek模型&am…...
)
DeepSeek代码审查配置避坑清单:12个被99%团队忽略的关键参数(含生产环境校验脚本)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码审查功能概览 DeepSeek 提供的代码审查(Code Review)能力基于其大语言模型对编程语义、安全规范与工程实践的深度理解,支持多语言静态分析、漏洞识别、可…...