【深度学习】pytorch——常用工具模块
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~
深度学习专栏链接:
http://t.csdnimg.cn/dscW7
pytorch——常用工具模块
- 数据处理 torch.utils.data模块
- Dataset
- DataLoader
- sampler
- torch.utils.data的使用
- 计算机视觉工具包 torchvision
- torchvision.datasets模块
- torchvision.transforms模块
- torchvision.models模块
- 可视化工具 Visdom
- 两个重要概念
- Visdom的使用
- vis.image
- vis.text
数据处理 torch.utils.data模块
在解决深度学习问题的过程中,往往需要花费大量的精力去处理数据,包括图像、文本、语音或其它二进制数据等。数据的处理对训练神经网络来说十分重要,良好的数据处理不仅会加速模型训练,更会提高模型效果。考虑到这点,PyTorch提供了几个高效便捷的工具,以便使用者进行数据处理或增强等操作,同时可通过并行化加速数据加载。
- Dataset 类:用于表示数据集,可以通过继承这个类来创建自定义的数据集。
- DataLoader 类:用于批量加载数据,可以指定批量大小、是否打乱数据等参数。
Dataset
在PyTorch中,数据加载可通过自定义的数据集对象。数据集对象被抽象为Dataset类,实现自定义的数据集需要继承Dataset,并实现两个Python魔法方法:
__getitem__:返回一条数据,或一个样本。obj[index]等价于obj.__getitem__(index)__len__:返回样本的数量。len(obj)等价于obj.__len__()
DataLoader
要创建一个 DataLoader,我们需要指定以下参数:
- 数据集实例:这通常是你自定义的数据集类的实例,例如 CustomDataset。
- 批量大小(batch_size):用于指定每个批量包含的样本数量。
- 是否打乱数据(shuffle):指定是否在每个 epoch 开始时对数据进行打乱,通常在训练过程中会打乱数据,而在验证或测试过程中不会。
- 多线程加载(num_workers):指定用于数据加载的线程数,可以加快数据加载速度。
sampler
在 PyTorch 中,torch.utils.data.sampler 模块包含了多种用来对数据进行采样的类,例如 SequentialSampler、RandomSampler、SubsetRandomSampler 等。这些采样器可以用于创建自定义的数据采样策略,以满足不同的训练需求。
下面是一些常用采样器的用法举例:
- SequentialSampler:顺序采样器,在每个 epoch 中按顺序遍历整个数据集。
from torch.utils.data import DataLoader, SequentialSampler# 创建顺序采样器
sampler = SequentialSampler(dataset)# 使用采样器创建数据加载器
data_loader = DataLoader(dataset, batch_size=32, sampler=sampler)
- RandomSampler:随机采样器,每个 epoch 随机对数据集进行采样。
from torch.utils.data import DataLoader, RandomSampler# 创建随机采样器
sampler = RandomSampler(dataset, replacement=True, num_samples=100)# 使用采样器创建数据加载器
data_loader = DataLoader(dataset, batch_size=32, sampler=sampler)
- SubsetRandomSampler:从给定索引中随机采样子集。
from torch.utils.data import SubsetRandomSampler# 创建一个索引列表
indices = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]# 使用随机子集采样器创建数据加载器
sampler = SubsetRandomSampler(indices)
data_loader = DataLoader(dataset, batch_size=32, sampler=sampler)
- WeightedRandomSampler:加权随机采样,允许根据每个样本的权重来进行采样,从而更灵活地处理不平衡的数据集。这在处理类别不平衡、稀有事件或其他特定情况下非常有用。
from torch.utils.data import DataLoader, WeightedRandomSampler# 假设有一个数据集和对应的样本权重
dataset = YourDataset()
weights = [0.1, 0.5, 0.8, 0.3, 0.6] # 每个样本的权重# 创建加权随机采样器
sampler = WeightedRandomSampler(weights, num_samples=10, replacement=True)# 使用采样器创建数据加载器
data_loader = DataLoader(dataset, batch_size=32, sampler=sampler)
在这个示例中,WeightedRandomSampler 接受一个权重列表作为输入,并可以指定采样的样本数目和是否使用放回抽样(replacement=True 表示可以重复采样同一个样本)。
这些示例展示了如何使用不同的采样器来创建数据加载器,并指定不同的采样策略。可以根据具体的训练需求选择合适的采样器,并结合数据加载器来灵活地管理数据的采样和训练过程。
torch.utils.data的使用
假设有一个包含图像数据和对应标签的数据集,将创建一个自定义的数据集类来加载这些数据,并使用 DataLoader 来批量加载数据供模型训练使用。
import torch
from torch.utils.data import Dataset, DataLoader# 假设你有图像数据和对应标签的数据集
class CustomDataset(Dataset):def __init__(self, data, targets, transform=None):self.data = dataself.targets = targetsself.transform = transformdef __len__(self):return len(self.data)def __getitem__(self, index):x = self.data[index]y = self.targets[index]if self.transform:x = self.transform(x)return x, y# 创建数据集实例
# 假设 data 和 targets 是你的图像数据和对应标签
custom_dataset = CustomDataset(data, targets, transform=your_transforms)# 使用 DataLoader 批量加载数据
batch_size = 32
shuffle = True
num_workers = 4 # 可以加快数据加载速度的线程数data_loader = DataLoader(custom_dataset, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers)# 遍历数据加载器,获取批量数据
for inputs, labels in data_loader:# 在这里执行模型训练或推理pass- 创建了一个自定义的数据集类 CustomDataset,该类继承自 torch.utils.data.Dataset,并实现了 len 和 getitem 方法。
- 创建了数据集实例 custom_dataset,并使用 DataLoader 实例 data_loader 批量加载数据。
- 通过遍历数据加载器,可以获取批量的输入数据和对应的标签,用于模型的训练或推理过程。
计算机视觉工具包 torchvision
PyTorch 的计算机视觉工具包 torchvision 提供了一系列用于图像处理和计算机视觉任务的工具和数据集。它包含了常用的数据集(如 ImageNet、CIFAR10、COCO 等)、图像变换操作、模型架构以及预训练的模型等功能,方便用户快速构建和训练计算机视觉模型。
以下是 torchvision 中一些常用的功能和模块:
-
数据集和数据加载器:
torchvision.datasets模块提供了常用的图像数据集,例如 CIFAR, COCO, MNIST 等,并且可以通过torchvision.transforms模块中的图像变换操作对数据进行预处理。同时,torchvision.transforms还提供了各种图像变换操作,如裁剪、缩放、翻转等,用于数据增强和预处理。 -
模型架构和预训练模型:
torchvision.models模块包含了一些经典的计算机视觉模型,如 ResNet、VGG、AlexNet 等,同时还提供了这些模型在 ImageNet 数据集上预训练的参数。这些预训练模型可以用于迁移学习或者基准测试。 -
图像工具函数:
torchvision.utils模块中提供了一些图像操作的工具函数,比如保存图像、绘制边界框、可视化图像等功能。
使用 torchvision 可以大大简化计算机视觉任务的开发过程,提高开发效率,特别是在处理图像数据、构建模型、模型评估等方面提供了很多便利。
torchvision.datasets模块
torchvision.datasets 模块是 PyTorch 中用于加载和处理常见图像数据集的模块。这个模块提供了许多流行的图像数据集,使得用户可以轻松地获取这些数据集并用于模型训练和评估。
一些常见的数据集包括:
-
MNIST: 包含手写数字图片的数据集,常用于图像分类任务。
-
CIFAR10 和 CIFAR100: 分别包含 10 个类别和 100 个类别的彩色图片数据集,也用于图像分类任务。
-
ImageNet: 包含数百万张图片,涵盖了数千个类别,常用于大规模图像分类和目标检测任务。
-
COCO (Common Objects in COntext): 包含了大量的标注的图像,用于目标检测、实例分割等任务。
torchvision.datasets 不仅提供了这些数据集的接口,还提供了数据加载器(data loader),从而可以方便地将数据集加载到模型中进行训练和测试。
使用 torchvision.datasets,我们可以通过几行简单的代码来加载这些数据集,并且可以对数据进行预处理、数据增强等操作,为模型训练提供方便。
例如,以下是使用 torchvision.datasets 加载 CIFAR-10 数据集的示例代码:
import torchvision
import torchvision.transforms as transforms# 定义数据转换操作
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 加载训练集和测试集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)
这样就可以轻松地获取 CIFAR-10 数据集,并且进行相应的数据预处理,为模型训练做准备。
torchvision.transforms模块
transforms 模块是 PyTorch 中 torchvision 库的一部分,它提供了各种图像预处理和数据增强的函数,用于在训练神经网络时对图像数据进行处理。
以下是 transforms 模块中常用的一些函数:
-
Pad(padding, fill=0, padding_mode='constant'):对图像进行填充。 -
ToTensor():将 PIL 图像或 ndarray 转换为 tensor,并且将数值范围缩放到 [0, 1] 或 [-1, 1]。 -
Normalize(mean, std):对 tensor 进行标准化,减去均值然后除以标准差。这个操作通常用于对输入数据进行归一化处理。 -
Resize(size):调整图像大小为指定的尺寸。 -
RandomHorizontalFlip():随机水平翻转图像,用于数据增强。 -
RandomVerticalFlip():随机垂直翻转图像,用于数据增强。 -
RandomRotation(degrees):随机旋转图像一定角度,用于数据增强。 -
RandomCrop(size):随机裁剪图像到指定的尺寸,用于数据增强。 -
ColorJitter(brightness=0, contrast=0, saturation=0, hue=0):随机改变图像的亮度、对比度、饱和度和色相,用于数据增强。 -
ToPILImage():将张量(tensor)转换为 PIL 图像格式
这些函数可以通过 transforms.Compose() 组合在一起,构成一个图像预处理流水线,然后应用于加载的图像数据上,以便在训练神经网络时进行数据处理和增强。
import torchvision.transforms as transforms
from PIL import Image# 加载图像
image_path = "data/dogcat/cat.12484.jpg"
image = Image.open(image_path)
image.show()# 定义图像变换操作
transform = transforms.Compose([transforms.Pad(padding=10, fill=0, padding_mode='constant'), # 填充操作transforms.Resize(256), # 调整图像大小为 256x256transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.RandomVerticalFlip(), # 随机垂直翻转transforms.RandomRotation(degrees=45), # 随机旋转图像最多45度transforms.RandomCrop(224), # 随机裁剪图像到224x224#transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 颜色增强transforms.ToTensor(), # 转换为张量#transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]), # 标准化
])# 应用图像变换操作
transformed_image = transform(image)# 显示处理后的图像
transforms.ToPILImage()(transformed_image).show()

torchvision.models模块
torchvision.models 模块提供了在 PyTorch 中使用的一系列经典的预训练模型,例如 ResNet、VGG、AlexNet、GoogLeNet 等。这些预训练模型可以用于图像分类、目标检测、语义分割等任务,并且方便用户进行迁移学习或微调。
使用 torchvision.models 模块,我们可以轻松地访问这些经典模型,并且可以加载预训练的权重参数,从而在自己的数据集上进行模型训练或推理。
以下是一些常用的预训练模型:
-
ResNet: 包括 ResNet-18、ResNet-34、ResNet-50 等不同深度的 ResNet 模型,用于图像分类任务。
-
VGG: 包括 VGG-11、VGG-16、VGG-19 等不同深度的 VGG 模型,也用于图像分类任务。
-
AlexNet: AlexNet 是一个较早期的深度卷积神经网络模型,也常用于图像分类任务。
-
GoogLeNet: GoogLeNet 是由 Google 提出的深度卷积神经网络,适用于图像分类和目标检测任务。
-
DenseNet: 密集连接网络(DenseNet)是另一个流行的卷积神经网络结构,适用于图像分类和其他计算机视觉任务。
通过 torchvision.models,我们可以很方便地加载这些模型,并且可以直接用于自己的任务,或者进行进一步的微调以适应特定的数据集和任务需求。
以下是一个示例,展示了如何使用 torchvision.models 加载预训练的 ResNet-18 模型:
import torchvision.models as models# 加载预训练的 ResNet-18 模型
resnet18 = models.resnet18(pretrained=True)# 对模型进行微调或者用于推理
可视化工具 Visdom
Visdom 官方文档(https://github.com/fossasia/visdom)
Visdom 是一个用于创建实时交互式可视化的工具,最初是由 Facebook 的人工智能研究团队开发的,其开源于2017年3月,用于支持深度学习模型的可视化和监控。它提供了一个基于 Web 的用户界面,允许用户在浏览器中实时查看和操作可视化结果。Visdom 主要针对 PyTorch 和 Torch 等深度学习框架,但也可以与其他框架集成使用。
Visdom 的主要特点包括:
-
实时交互式可视化:Visdom 支持实时更新可视化结果,并且允许用户通过简单的交互方式进行操作,如缩放、平移、标注等,从而更好地理解数据和模型的行为。
-
多种类型的可视化:Visdom 提供了多种类型的可视化工具,包括折线图、条形图、散点图、热力图、直方图、图像等,满足了不同类型数据的可视化需求。
-
多用户支持:Visdom 支持多用户共享可视化结果,多个用户可以同时查看和操作可视化数据,这在团队协作以及教学研究方面非常有用。
-
语言无关性:Visdom 可以与多种编程语言进行集成,尤其是在 Python 和 Lua 等语言中应用较为广泛。
-
灵活的部署方式:Visdom 可以作为一个独立的服务器运行,也可以嵌入到现有的 Python 代码中,使得可视化过程更加灵活和定制化。
总的来说,Visdom 是一个功能强大、易于使用的可视化工具,特别适用于深度学习模型的训练过程监控、结果展示以及模型行为分析。通过实时交互式的可视化,用户可以更好地理解和优化他们的深度学习模型。
两个重要概念
在 Visdom 中,有两个重要的概念:窗口(window)和环境(environment)。
-
窗口(Window):
在 Visdom 中,窗口是指用户界面中的一个可视化区域,用于展示特定类型的数据可视化结果,比如折线图、散点图、图像等。每个窗口都有一个唯一的标识符,可以通过这个标识符来更新或关闭窗口中的内容。用户可以在同一环境下创建多个窗口,用于同时展示不同类型的数据可视化结果,比如训练损失曲线、模型预测结果等。 -
环境(Environment):
环境是 Visdom 中用于组织窗口的概念,可以理解为一个命名空间,用于区分不同类型或不同任务的可视化结果。不同环境的可视化结果相互隔离,互不影响,在使用时如果不指定env,默认使用main。不同用户、不同程序一般使用不同的env。
这两个概念的引入使得 Visdom 在展示和组织数据可视化结果时更加灵活和清晰,同时也方便用户对不同类型的数据进行管理和交互操作。
Visdom的使用
要使用 Visdom 进行可视化,您需要按照以下步骤进行设置和操作:
-
安装 Visdom:
首先,您需要在您的环境中安装 Visdom。可以使用以下命令使用 pip 安装 Visdom 库:pip install visdom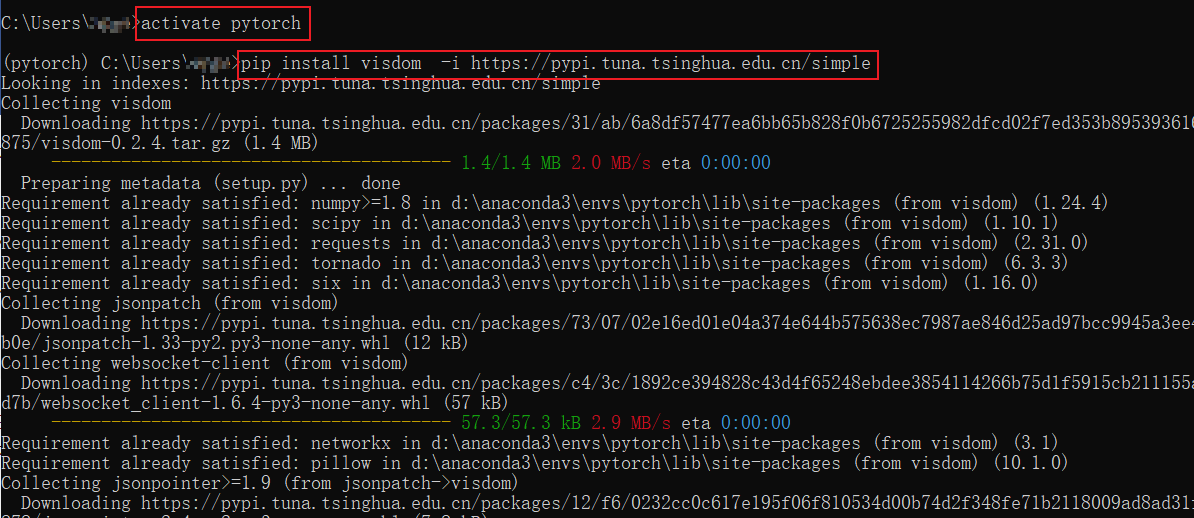
-
启动 Visdom 服务器:
在安装完成后,您需要启动 Visdom 服务器。可以在终端中运行以下命令启动服务器:python -m visdom.server这将在本地启动一个 Visdom 服务器,并显示服务器的 URL 地址,默认为 http://localhost:8097。

-
连接到 Visdom 服务器:
在您的 Python 脚本中,您需要导入 Visdom 库并连接到正在运行的 Visdom 服务器。可以使用以下代码片段连接到服务器:import visdom# 创建 Visdom 客户端对象 vis = visdom.Visdom()此时,您的客户端将通过默认的本地连接地址连接到 Visdom 服务器。
-
创建窗口并显示数据:
您可以使用 Visdom 客户端对象创建窗口,并将数据显示在窗口中。以下是一个简单的示例,展示如何在折线图窗口中显示一些数据:import visdom# 创建 Visdom 客户端对象 vis = visdom.Visdom()# 创建折线图窗口并显示数据 vis.line(Y=[0], X=[0], win='my_plot', opts=dict(title='My Plot')) vis.line(Y=[4, 2, 3], X=[1, 2, 3], win='my_plot', update='append')这将创建一个名为 “my_plot” 的折线图窗口,并在窗口中显示数据点 (1, 4),(2, 2),(3, 3)。之后,您可以通过不断更新数据来更新窗口中的图表。

这只是一个简单的使用示例,Visdom 还提供了许多其他类型的窗口和选项,用于展示和操作各种类型的数据。
import torch as t
import visdom# 新建一个连接客户端
# 指定env = u'test1',默认端口为8097,host是‘localhost'
vis = visdom.Visdom(env=u'test1',use_incoming_socket=False)x = t.arange(1, 30, 0.01)
y = t.sin(x)
vis.line(X=x, Y=y, win='sinx', opts={'title': 'y=sin(x)'})

-
vis = visdom.Visdom(env=u’test1’),用于构建一个客户端,客户端除指定env之外,还可以指定host、port等参数。
-
vis作为一个客户端对象,可以使用常见的画图函数,包括:
- line:类似Matlab中的
plot操作,用于记录某些标量的变化,如损失、准确率等 - image:可视化图片,可以是输入的图片,也可以是GAN生成的图片,还可以是卷积核的信息
- text:用于记录日志等文字信息,支持html格式
- histgram:可视化分布,主要是查看数据、参数的分布
- scatter:绘制散点图
- bar:绘制柱状图
- pie:绘制饼状图
- line:类似Matlab中的
Visdom同时支持PyTorch的tensor和Numpy的ndarray两种数据结构,但不支持Python的int、float等类型,因此每次传入时都需先将数据转成ndarray或tensor。上述操作的参数一般不同,但有两个参数是绝大多数操作都具备的:
- win:用于指定pane的名字,如果不指定,visdom将自动分配一个新的pane。如果两次操作指定的win名字一样,新的操作将覆盖当前pane的内容,因此建议每次操作都重新指定win。
- opts:选项,接收一个字典,常见的option包括
title、xlabel、ylabel、width等,主要用于设置pane的显示格式。
往往我们在训练网络的过程中需不断更新数值,如损失值等,这时就需要指定参数update='append'来避免覆盖之前的数值。
import torch as t
import visdom# 新建一个连接客户端
# 指定env = u'test1',默认端口为8097,host是‘localhost'
vis = visdom.Visdom(env=u'test1',use_incoming_socket=False)# append 追加数据
for ii in range(0, 10):# y = xx = t.Tensor([ii])y = xvis.line(X=x, Y=y, win='polynomial',name='Trace', update='append' if ii>0 else None)# updateTrace 新增一条线
x = t.arange(0, 9, 0.1)
y = (x ** 2) / 9
vis.line(X=x, Y=y, win='polynomial', name='this is a new Trace',update='new')
vis.image
image接收一个二维或三维向量, H × W H\times W H×W或 3 × H × W 3 \times H\times W 3×H×W,前者是黑白图像,后者是彩色图像。images接收一个四维向量 N × C × H × W N\times C\times H\times W N×C×H×W, C C C可以是1或3,分别代表黑白和彩色图像。可实现类似torchvision中make_grid的功能,将多张图片拼接在一起。images也可以接收一个二维或三维的向量,此时它所实现的功能与image一致。
import torch as t
import visdom# 新建一个连接客户端
# 指定env = u'test1',默认端口为8097,host是‘localhost'
vis = visdom.Visdom(env=u'test',use_incoming_socket=False)# 可视化一个随机的黑白图片
vis.image(t.randn(64, 64).numpy())# 随机可视化一张彩色图片
vis.image(t.randn(3, 64, 64).numpy(), win='random2')# 可视化36张随机的彩色图片,每一行6张
vis.images(t.randn(36, 3, 64, 64).numpy(), nrow=6, win='random3', opts={'title':'random_imgs'})

vis.text
在 Visdom 的 vis.text 函数中,可以使用 HTML 标签来自定义文本的样式和布局。以下是一个示例,展示如何在 vis.text 中使用不同的 HTML 标签和属性:
import visdom# 连接到 Visdom 服务器
viz = visdom.Visdom()# 创建一个文本窗口,并使用 HTML 标签来设置样式和布局
html_content = """
<h1 style="color: red;">这是一个标题</h1>
<p style="font-size: 20px;">这是一个段落</p>
<ul><li>列表项1</li><li>列表项2</li><li>列表项3</li>
</ul>
"""viz.text(html_content)
在这个示例中,我们使用 HTML 标签和属性来设置文本的样式和布局。通过使用 <h1> 标签,我们将文本设置为红色的标题。使用 <p> 标签,我们将文本设置为字体大小为 20px 的段落。使用 <ul> 和 <li> 标签,我们创建了一个无序列表。
当调用 viz.text 并传入带有 HTML 标签的文本内容时,Visdom 会解析该内容并相应地显示在文本窗口中。
请注意,有些 HTML 标签和属性可能在 Visdom 中不被完全支持,或者显示效果可能会因浏览器兼容性而有所区别。

相关文章:
【深度学习】pytorch——常用工具模块
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ 深度学习专栏链接: http://t.csdnimg.cn/dscW7 pytorch——常用工具模块 数据处理 torch.utils.data模块DatasetDataLoadersamplertorch.utils.data的使用 计算机视觉工具包 torchvisiontorchvision.d…...

【Android】统一系统动画
需求:除panel动画效果为弹出之外,其余的应用效果为渐入渐出 从系统层面统一把控动画效果,而不是单个应用自己处理 Android系统版本:9.0 代码地址 \frameworks\base\core\res\res\values\styles.xml 当时看注释,以为…...
京东数据运营与分析:如何全面获取电商销售数据?
随着电商行业的快速发展,数据分析成为了电商运营中一个非常重要的环节,这一环往往能够帮助品牌方来提升销售业绩和管理效率。然而,如何获取到电商平台中详细、全面的销售数据是很多电商品牌方所关心的问题,事实上,第三…...

du_命令可以像find_命令那样列出最大的文件吗
【赠送】IT技术视频教程,白拿不谢!思科、华为、红帽、数据库、云计算等等_厦门微思网络的博客-CSDN博客文章浏览阅读418次。风和日丽,小微给你送福利~如果你是小微的老粉,这里有一份粉丝福利待领取...如果你是新粉关注到了小微&am…...

asp.net blazor集成TinyMCE.Blazor
asp.net blazor项目添加TinyMCE.Blazor nuget包 在blazor页面中添加,可以通过ScriptSrc参数配置自定义TinyMCE.Blazor js <EditForm class"mb-3" Model"Model" OnValidSubmit"HandleValidSubmit"><div class"form-gro…...
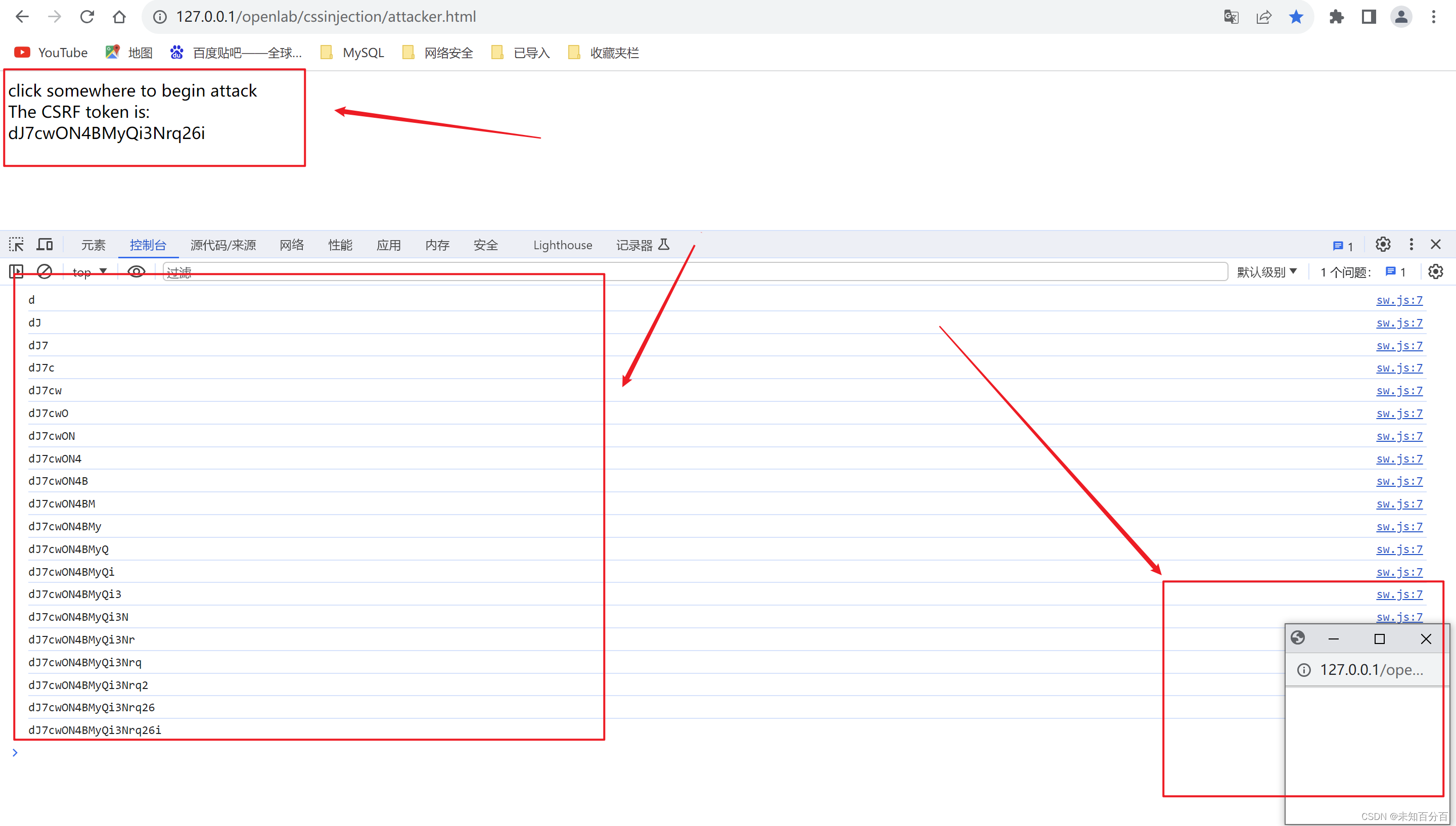
CSS注入的四种实现方式
目录 CSS注入窃取标签属性数据 简单的一个实验: 解决hidden 方法1:jsnode.js实现 侧信道攻击 方法2:对比波兰研究院的方案 使用兄弟选择器 方法3:jswebsocket实现CSS注入 实验实现: 方法4:window…...

突然消失的桌面文件如何恢复?详细教程让你轻松解决问题!
桌面文件突然消失,对于很多人来说,可能是个令人头疼的问题。这些文件可能包含重要的信息,也可能是数日甚至数周的努力成果。那么,当这种情况发生时,我们如何恢复丢失的文件呢?本文将提供一些实用的建议。 1…...

Springboot+Dubbo+Nacos 集成 Sentinel(入门)
Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。Sentinel 官网 1.版本选择 参考 SpringClou…...
ARPG----C++学习记录05 Section10 武器类,IK重定向,装备和捡起武器,动画蓝图
代码更新 11.13 BAOfanTing/ARPG_Game_Code7ab54d2 GitHub 武器类 基于item类,创建一个weapon的C类,基于它创建一个蓝图,刀剑的网格体给它。在蓝图里调动之前在C写好的sin函数添加到世界偏移量里,得到一把悬浮刀 在item把重叠函…...
CSRF跨站请求伪造
CSRF CSRF(Cross-Site Request Forgery,跨站请求伪造)是通过诱导用户执行操作,利用用户在网站上的登录状态,以用户的身份在网站上执行恶意操作。 以下是CSRF攻击的一些关键特征: 用户身份:CSR…...

修改kernel驱动配置文件
对于内核分析,使用CONFIG_KPROBESy和CONFIG_KPROBE_EVENTSy来启用内核动态跟踪,而CONFIG_FRAME_POINTERy用于基于帧指针的内核堆栈。对于用户级分析,CONFIG_UPROBESy和CONFIG_UROBE_EVENTSy用于用户级动态跟踪。 添加位置在 kernel/.config...

采集摄像头数据的Golang应用
引言 如今,我们生活在一个信息爆炸的时代,数字化的发展给我们带来了无限的便利。在生活中,我们经常需要使用摄像头来进行图像采集,比如监控系统、人脸识别系统等。本文将介绍如何使用Golang语言来采集摄像头数据,并进…...
Axure9学习
产品经理零基础入门(四)Axure 原型图教程,2小时学会_哔哩哔哩_bilibili 1. ① 页面对应页面个数,概要对应每个页面的具体内容 ② 文件类型 ③ 备用间隔改为5分钟 ④ 当多个元件重叠,想把在下面的元件b直接拖出来&…...
使用gitflow时如何合并hotfix
前言 在使用 git flow 流程时, 对于项目型的部署项目经常会遇到一个问题, 就是现场项目在使用历史版本时发现的一些问题需要修复, 但升级可能会有很大的风险或客户不愿意升级, 这时就要求基于历史版本进行 hotfix 修复. 基于历史发布版本的缺陷修复方式不同于最新发布版本的补…...
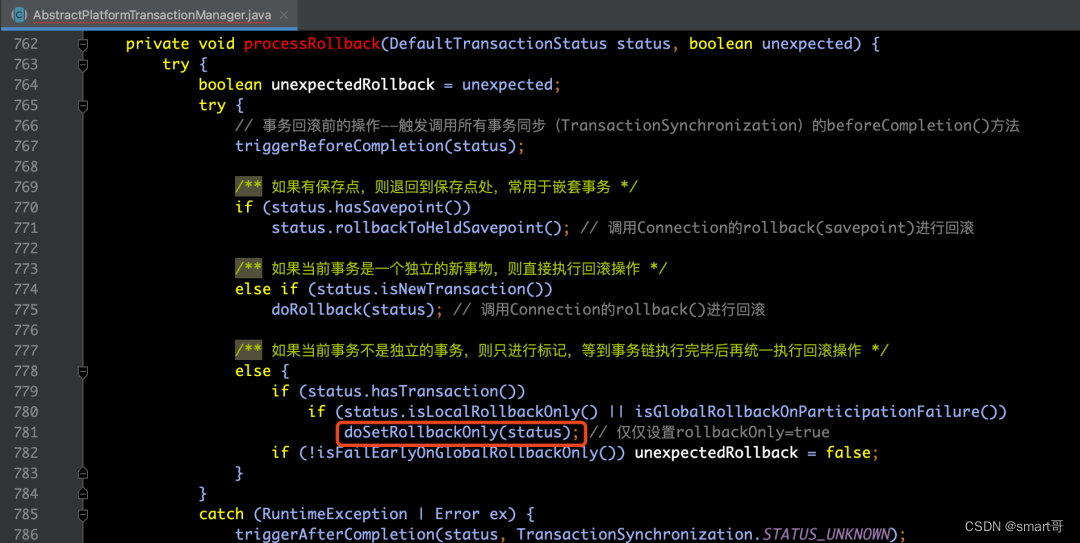
(七)Spring源码解析:Spring事务
对于事务来说,是我们平时在基于业务逻辑编码过程中不可或缺的一部分,它对于保证业务及数据逻辑原子性立下了汗马功劳。那么,我们基于Spring的声明式事务,可以方便我们对事务逻辑代码进行编写,那么在开篇的第一部分&…...

Stable Diffusion 是否使用 GPU?
在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 3D数字孪生场景编辑器 Stable Diffusion 已迅速成为最流行的生成式 AI 工具之一,用于通过文本到图像扩散模型创建图像。但是,它需…...

DevOps平台两种实现模式
我们需要一个DevOps平台 要讨论DevOps平台的实现模式,似乎就必须讨论它们的概念定义。然而,当大家要讨论它们的定义时,就像在讨论薛定谔的猫。 A公司认为它不过是自动化执行Shell脚本的平台,有些人认为它是一场运动,另…...

Java 简单实现一个 UDP 回显服务器
文章目录 UDP 服务端UDP 客户端实现效果UDP 服务端(实现字典功能)总结 UDP 服务端 package network;import java.io.IOException; import java.net.DatagramPacket; import java.net.DatagramSocket; import java.net.SocketException;public class UdpEchoServer {private Da…...
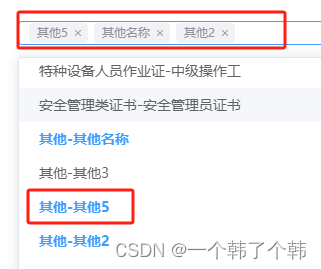
element ui中Select 选择器,自定义显示内容
正常情况下,下拉框选项展示内容,就是选择后展示的label内容 如图所示: 但是要想自定义选项内容,但是展示内容不是选项label的内容,可以在el-option标签内增加div进行自定义选项label展示,但选择后结果展示…...

机器视觉行业,日子不过了吗?都进入打折潮,双11只是一个借口,打广告出新招,日子不好过是真的
我就不上图了,大家注意各个机器视觉公司公众号,为什么打折?打广告也只是宣传手段,进入打折潮,内卷严重,价格战变成白刃战,肯定日子不好过了。...

AI智能体架构设计:从成本黑洞到价值引擎的解耦之道
1. 从成本黑洞到价值引擎:为什么你的AI智能体架构正在吞噬预算又到了季度技术复盘会,财务那边递过来的云账单和工程人力成本,是不是又让你倒吸一口凉气?你看着报表上那个名为“AI智能体平台”的项目,它的资源消耗曲线几…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

Kerberos身份认证原理与实战排错指南
1. 为什么今天还要花时间搞懂 Kerberos?——一个被低估的“老协议”正在悄悄支撑着你的日常你每天登录公司内网查邮件、访问财务系统提交报销、用 Jenkins 构建代码、甚至在 Windows 域环境中打开一台同事的共享文件夹……这些看似顺滑的操作背后,大概率…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

Sora 2 MOV导出画质崩坏真相:HDR10元数据丢失、BT.2020色域截断、帧率标志位误写——3大隐性缺陷紧急修复方案
更多请点击: https://intelliparadigm.com 第一章:Sora 2 MOV导出画质崩坏的系统性认知 Sora 2 在生成高保真视频后,导出为 MOV 格式时频繁出现色度抽样失真、动态范围压缩、帧间伪影加剧等现象,其本质并非单一环节失效ÿ…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...