Accelerate 0.24.0文档 二:DeepSpeed集成
文章目录
- 一、 DeepSpeed简介
- 二、DeepSpeed集成(Accelerate 0.24.0)
- 2.1 DeepSpeed安装
- 2.2 Accelerate DeepSpeed Plugin
- 2.2.1 ZeRO Stage-2
- 2.2.2 ZeRO Stage-3 with CPU Offload
- 2.2.3 accelerate launch参数
- 2.3 DeepSpeed Config File
- 2.3.1 ZeRO Stage-2
- 2.3.2 ZeRO Stage-3 with CPU offload
- 2.4 优化器和调度器( DeepSpeed Config File)
- 2.5 协调DeepSpeed Config File与accelerate config
- 2.5.1 配置冲突
- 2.5.2 使用deepspeed_config_file配置具体参数
- 2.5.3 命令行配置具体参数
- 2.6 模型的保存和加载
- 2.7 DeepSpeed ZeRO Inference
- 三、相关资源
一、 DeepSpeed简介
ZeRO论文:《ZeRO:Memory Optimizations Toward Training Trillion Parameter Models》ZeRO-Offload论文:《ZeRO-Offload:Democratizing Billion-Scale Model Training.》NVMe技术论文:《 ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning》- 《Hugging Face高效训练技术二:大模型分布式训练策略——ZeRO、FSDP》、《Hugging Face高效训练技术三:huggingface DeepSpeed文档》
ZeRO(Zero Redundancy Optimizer)是一种用于优化大规模深度学习模型训练的技术。它的主要目标是降低训练期间的内存占用、通信开销和计算负载,从而使用户能够训练更大的模型并更高效地利用硬件资源。
ZERO论文首先分析了模型训练中内存主要消耗在两个方面:
model states:模型状态,包括包括优化器参数(例如Adam的动量和方差)、梯度、模型参数residual states:剩余状态,包括包括激活函数、临时缓冲区、内存碎片

参数解释:
Baseline:未优化的基线Ψ:模型大小,上图假设模型参数为Ψ=75亿K:存储优化器状态要消耗的内存倍数,对于混合精度的Adam优化器而言,K=12- N d N_d Nd:数据并行度。基于Adam优化器的混合精度训练,数据并行度为Nd=64(即64个GPU)
ZeRO分别使用ZeRO-DP和ZeRO-R来优化model states和residual states。如上图所示,ZeRO-DP包括三个阶段。
ZeRO-Infinity是ZeRO的一个扩展版本,它允许将模型参数存储在CPU内存或NVMe存储上,而不是全部存储在GPU内存中,最终在有限资源下能够训练前所未有规模的模型(在单个NVIDIA DGX-2节点上微调具有1万亿参数的模型),而无需对模型代码进行重构。
NVMe协议是专门为固态硬盘设计的,以满足高性能、低延迟和并发读写的需求。相较于SATA和AHCI,NVMe具有更高的数据传输速率和更低的通信延迟。
DeepSpeed实现了上述ZeRO论文中描述的所有内容。目前,它完全支持以下功能:
- 优化器状态分区(ZeRO阶段1)
- 梯度分区(ZeRO阶段2)
- 参数分区(ZeRO阶段3)
- 自定义混合精度训练处理
- 一系列基于快速CUDA扩展的优化器
- ZeRO-Offload到CPU和磁盘/NVMe:ZeRO-Infinity(ZeRO的进阶实现)中的功能,它允许将模型参数存储在CPU内存或NVMe存储上,而不是全部存储在GPU内存中
- 包括Optimizer Offload和Param Offload
- 从技术上讲ZeRO可以Offload到任何磁盘,但具有NVME的磁盘才能获得不错的速度。
详细原理可参考ZeRO论文,或者我之前的帖子《Hugging Face高效训练技术二:大模型分布式训练策略——ZeRO、FSDP》
二、DeepSpeed集成(Accelerate 0.24.0)
- 本章参考《 DeepSpeed(Accelerate)》
- 有关Accelerate库的使用,可参考我的博客《Accelerate 0.24.0文档 一:两万字极速入门》
DeepSpeed ZeRO-2主要仅用于训练,因为推理时不需要优化器和梯度。DeepSpeed ZeRO-3也可用于推断,因为它允许将庞大的模型加载到多个GPU上(参数分区)。
通过2种选项,Accelerate集成了DeepSpeed:
-
通过在
accelerate config中使用deepspeed config file集成DeepSpeed功能。您只需提供自定义配置文件或使用我们的模板。这支持DeepSpeed的所有核心功能,并为用户提供了很大的灵活性,用户只需要根据配置做一些更改。 -
通过
deepspeed_plugin集成。这种集成方式支持DeepSpeed的一部分功能,对于其余配置使用默认选项。这种方式无需进行复杂的代码修改,集成更加简便,适用于对DeepSpeed的大多数默认设置满意的用户。
2.1 DeepSpeed安装
无论哪种方式,使用前先安装DeepSpeed,安装方式有两种:pip安装和本地构建。
-
pip安装
# 两种方式任选其一 pip install deepspeed # 安装deepspeed库 pip install transformers[deepspeed] # 通过transformers的extras选项安装 -
本地构建
pip安装通常会使用默认配置,适合绝大多数用户。如果您需要自定义DeepSpeed的配置,比如修改全局配置文件或在代码中进行相应的配置更改,可以克隆DeepSpeed项目到本地来自定义构建。git clone https://github.com/microsoft/DeepSpeed/ cd DeepSpeed rm -rf build # 移除旧的构建目录 # 针对所需GPU架构进行本地构建:(需替换相应GPU架构) TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \ --global-option="build_ext" --global-option="-j8" --no-cache -v \ --disable-pip-version-check 2>&1 | tee build.log
有关安装部分更详细内容,请查看官方文档。
2.2 Accelerate DeepSpeed Plugin
首先运行accelerate config,这将启动一个配置向导,询问您是否要使用DeepSpeed的配置文件。您应该回答"no",然后继续回答后续问题,以生成一个基本的DeepSpeed配置(包含一系列默认选项)。
运行以下命令,使用生成的DeepSpeed配置文件(yaml格式)启动训练脚本:
accelerate launch my_script.py --args_to_my_script
下面介绍使用 DeepSpeed Plugin运行 NLP的示例(examples/nlp_example.py)
2.2.1 ZeRO Stage-2
accelerate配置文件:
compute_environment: LOCAL_MACHINE
deepspeed_config:gradient_accumulation_steps: 1gradient_clipping: 1.0offload_optimizer_device: noneoffload_param_device: nonezero3_init_flag: truezero_stage: 2
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
启动:
accelerate launch examples/nlp_example.py --mixed_precision fp16
2.2.2 ZeRO Stage-3 with CPU Offload
accelerate 配置文件:
compute_environment: LOCAL_MACHINE
deepspeed_config:gradient_accumulation_steps: 1gradient_clipping: 1.0offload_optimizer_device: cpuoffload_param_device: cpuzero3_init_flag: truezero3_save_16bit_model: truezero_stage: 3
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
启动:
accelerate launch examples/nlp_example.py --mixed_precision fp16
2.2.3 accelerate launch参数
Accelerate 支持通过CLI进行以下配置:
`zero_stage`: [0] Disabled, [1] optimizer state partitioning, [2] optimizer+gradient state partitioning and [3] optimizer+gradient+parameter partitioning
`gradient_accumulation_steps`: Number of training steps to accumulate gradients before averaging and applying them.
`gradient_clipping`: Enable gradient clipping with value.
`offload_optimizer_device`: [none] Disable optimizer offloading, [cpu] offload optimizer to CPU, [nvme] offload optimizer to NVMe SSD. Only applicable with ZeRO >= Stage-2.
`offload_param_device`: [none] Disable parameter offloading, [cpu] offload parameters to CPU, [nvme] offload parameters to NVMe SSD. Only applicable with ZeRO Stage-3.
`zero3_init_flag`: Decides whether to enable `deepspeed.zero.Init` for constructing massive models. Only applicable with ZeRO Stage-3.
`zero3_save_16bit_model`: Decides whether to save 16-bit model weights when using ZeRO Stage-3.
`mixed_precision`: `no` for FP32 training, `fp16` for FP16 mixed-precision training and `bf16` for BF16 mixed-precision training.
2.3 DeepSpeed Config File
为了能更灵活的配置DeepSpeed功能,推荐使用DeepSpeed config file。运行accelerate config,这将启动一个配置向导,询问您是否要使用DeepSpeed的配置文件。您应该回答"yes"并提供 deepspeed 配置文件的路径,回答完毕后,这将生成一个配置文件来正确设置默认选项。
accelerate launch my_script.py --args_to_my_script
下面介绍如何使用 DeepSpeed 配置文件运行 NLP 示例(examples/by_feature/deepspeed_with_config_support.py )
2.3.1 ZeRO Stage-2
- accelerate 配置文件:
compute_environment: LOCAL_MACHINE
deepspeed_config:deepspeed_config_file: /home/ubuntu/accelerate/examples/configs/deepspeed_config_templates/zero_stage2_config.jsonzero3_init_flag: true
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
- zero_stage2_config.json :
{"fp16": {"enabled": true,"loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"optimizer": {"type": "AdamW","params": {"lr": "auto","weight_decay": "auto","torch_adam": true,"adam_w_mode": true}},"scheduler": {"type": "WarmupDecayLR","params": {"warmup_min_lr": "auto","warmup_max_lr": "auto","warmup_num_steps": "auto","total_num_steps": "auto"}},"zero_optimization": {"stage": 2,"allgather_partitions": true,"allgather_bucket_size": 2e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": "auto","contiguous_gradients": true},"gradient_accumulation_steps": 1,"gradient_clipping": "auto","steps_per_print": 2000,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","wall_clock_breakdown": false
}
- 使用accelerate launch进行启动
accelerate launch examples/by_feature/deepspeed_with_config_support.py \
--config_name "gpt2-large" \
--tokenizer_name "gpt2-large" \
--dataset_name "wikitext" \
--dataset_config_name "wikitext-2-raw-v1" \
--block_size 128 \
--output_dir "./clm/clm_deepspeed_stage2_accelerate" \
--learning_rate 5e-4 \
--per_device_train_batch_size 24 \
--per_device_eval_batch_size 24 \
--num_train_epochs 3 \
--with_tracking \
--report_to "wandb"\
2.3.2 ZeRO Stage-3 with CPU offload
- accelerate 配置文件:
compute_environment: LOCAL_MACHINE
deepspeed_config:deepspeed_config_file: /home/ubuntu/accelerate/examples/configs/deepspeed_config_templates/zero_stage3_offload_config.jsonzero3_init_flag: true
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
- zero_stage3_offload_config.json
{"fp16": {"enabled": true,"loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"optimizer": {"type": "AdamW","params": {"lr": "auto","weight_decay": "auto"}},"scheduler": {"type": "WarmupDecayLR","params": {"warmup_min_lr": "auto","warmup_max_lr": "auto","warmup_num_steps": "auto","total_num_steps": "auto"}},"zero_optimization": {"stage": 3,"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},"overlap_comm": true,"contiguous_gradients": true,"reduce_bucket_size": "auto","stage3_prefetch_bucket_size": "auto","stage3_param_persistence_threshold": "auto","sub_group_size": 1e9,"stage3_max_live_parameters": 1e9,"stage3_max_reuse_distance": 1e9,"stage3_gather_16bit_weights_on_model_save": "auto"},"gradient_accumulation_steps": 1,"gradient_clipping": "auto","steps_per_print": 2000,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","wall_clock_breakdown": false
}
- 使用accelerate launch进行启动
accelerate launch examples/by_feature/deepspeed_with_config_support.py \
--config_name "gpt2-large" \
--tokenizer_name "gpt2-large" \
--dataset_name "wikitext" \
--dataset_config_name "wikitext-2-raw-v1" \
--block_size 128 \
--output_dir "./clm/clm_deepspeed_stage3_offload_accelerate" \
--learning_rate 5e-4 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--num_train_epochs 3 \
--with_tracking \
--report_to "wandb"\
2.4 优化器和调度器( DeepSpeed Config File)
在《Hugging Face高效训练技术三:huggingface DeepSpeed文档(Trainer)》6.2节优化器章节介绍过,当不启用offload_optimizer(优化器卸载)功能时,可以混合使用HF和DS的优化器和迭代器,组合情况如下:(只是不能同时使用deepspeed 优化器和huggingface的调度器)
| 组合 | HF Scheduler | DS Scheduler |
|---|---|---|
| HF Optimizer | Yes | Yes |
| DS Optimizer | No | Yes |
DeepSpeed 的主要优化器是 Adam、AdamW、OneBitAdam 和 Lamb。 这些已通过 ZeRO 进行了彻底测试,建议使用。但如果您有特殊需求,也可以从 torch 导入其他优化器,详见文档。
本文介绍的是Accelerate集成DeepSpeed 的情况,情况也是类似:
- DS Optim + DS Scheduler:当 DeepSpeed 配置文件中同时定义了 optimizer 和 scheduler 的时候,用户需要使用
accelerate.utils.DummyOptim和accelerate.utils.DummyScheduler来替换代码中的 PyTorch/自定义优化器和调度器。以下是 examples/by_feature/deepspeed_with_config_support.py 中显示这一情况的代码片段:
from accelerate.utils import DummyOptim, DummyScheduler, set_seed
...
# 如果 config file定义了Optimizer则创建Dummy Optimizer,否则创建Adam Optimizer
optimizer_cls = (torch.optim.AdamWif accelerator.state.deepspeed_plugin is Noneor "optimizer" not in accelerator.state.deepspeed_plugin.deepspeed_configelse DummyOptim
)
optimizer = optimizer_cls(optimizer_grouped_parameters, lr=args.learning_rate)# 如果 config file定义了scheduler则创建Dummy Scheduler,否则创建`args.lr_scheduler_type` Scheduler
if (accelerator.state.deepspeed_plugin is Noneor "scheduler" not in accelerator.state.deepspeed_plugin.deepspeed_config
):lr_scheduler = get_scheduler(name=args.lr_scheduler_type,optimizer=optimizer,num_warmup_steps=args.num_warmup_steps,num_training_steps=args.max_train_steps,)
else:lr_scheduler = DummyScheduler(optimizer, total_num_steps=args.max_train_steps, warmup_num_steps=args.num_warmup_steps)
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(model, optimizer, train_dataloader, eval_dataloader, lr_scheduler)
...
Custom Optim + Custom Scheduler:DeepSpeed 配置文件中没有定义optimizer 和 scheduler,则代码保持不变,通过 DeepSpeed Plugin使用集成时就是这种情况。Custom Optim + DS Scheduler:DeepSpeed 配置文件中仅定义 scheduler的情况,此时,用户必须使用accelerate.utils.DummyScheduler替换代码中的 PyTorch/Custom Scheduler。DS Optim + Custom Scheduler:DeepSpeed 配置文件中仅定义 optimizer 的情况,此时会报错。
上述内容展开来说就是:
- 用户代码中的优化器,无论是直接实例化的(自定义的)还是通过 Accelerate 封装的,只要是
DeepSpeed Config File中定义了优化器,就会被替换为DummyOptim。 - 实际的优化过程会由 DeepSpeed 中的 optimizer 处理,为避免与用户代码中的优化器发生冲突,需要用这个
DummyOptim对象进行替换。DummyOptim是一个虚拟的优化器对象,不执行任何实际的优化运算,仅作为一个占位符存在,所以不会对模型参数执行优化。 DummyScheduler是虚拟的学习率调度器,其用法一样Accelerate不会自动帮用户代码中原有的Optimizer和Scheduler替换成 Dummy,需要用户自己手动替换,比如:
import accelerate# 原优化器
optimizer = torch.optim.Adam(model.parameters())
optimizer = accelerate.DistributedOptimizer(optimizer, name='adam')
from accelerate.utils import DummyOptim# 使用 DummyOptim 替换 Accelerate 封装的优化器
optimizer = DummyOptim()
另外需要注意,上述示例的DeepSpeed配置文件中的 auto 值,会根据传递给 prepare 方法的模型、数据加载器、虚拟优化器和虚拟调度器自动处理,其余的必须由用户显式指定。
2.5 协调DeepSpeed Config File与accelerate config
2.5.1 配置冲突
在使用 deepspeed_config_file 时,如果某些变量在 accelerate 中也进行了配置,那么这些变量的配置可能会发生冲突或重复,为了避免这种情况,最好将它们全部配置在 deepspeed_config_file 中。以下是可能会产生冲突的变量列表:
gradient_accumulation_stepsgradient_clippingzero_stageoffload_optimizer_deviceoffload_param_devicezero3_save_16bit_modelmixed_precision
下面是一个更具体的例子:
- Code test.py:
from accelerate import Accelerator
from accelerate.state import AcceleratorStatedef main():accelerator = Accelerator()accelerator.print(f"{AcceleratorState()}")if __name__ == "__main__":main()
- accelerate config
command_file: null
commands: null
compute_environment: LOCAL_MACHINE
deepspeed_config:gradient_accumulation_steps: 1gradient_clipping: 1.0offload_optimizer_device: 'cpu'offload_param_device: 'cpu'zero3_init_flag: truezero3_save_16bit_model: truezero_stage: 3deepspeed_config_file: 'ds_config.json'
distributed_type: DEEPSPEED
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
gpu_ids: null
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
megatron_lm_config: {}
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_name: null
tpu_zone: null
use_cpu: false
- ds_config.json :
{"bf16": {"enabled": true},"zero_optimization": {"stage": 3,"stage3_gather_16bit_weights_on_model_save": false,"offload_optimizer": {"device": "none"},"offload_param": {"device": "none"}},"gradient_clipping": 1.0,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","gradient_accumulation_steps": 10,"steps_per_print": 2000000
}
此时运行accelerate launch test.py,会产生以下报错:
ValueError: When using `deepspeed_config_file`, the following accelerate config variables will be ignored:
['gradient_accumulation_steps', 'gradient_clipping', 'zero_stage', 'offload_optimizer_device', 'offload_param_device',
'zero3_save_16bit_model', 'mixed_precision'].
Please specify them appropriately in the DeepSpeed config file.
If you are using an accelerate config file, remove others config variables mentioned in the above specified list.
The easiest method is to create a new config following the questionnaire via `accelerate config`.
It will only ask for the necessary config variables when using `deepspeed_config_file`.
2.5.2 使用deepspeed_config_file配置具体参数
为了解决这个问题,建议通过运行 accelerate config 来创建一个新的配置文件。此命令将通过一系列问题询问用户,仅在使用 deepspeed_config_file 时要求用户提供必要的配置变量,以确保配置的一致性。
$ accelerate config
-------------------------------------------------------------------------------------------------------------------------------
In which compute environment are you running?
This machine
-------------------------------------------------------------------------------------------------------------------------------
Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]: yes
Do you want to specify a json file to a DeepSpeed config? [yes/NO]: yes
Please enter the path to the json DeepSpeed config file: ds_config.json
Do you want to enable `deepspeed.zero.Init` when using ZeRO Stage-3 for constructing massive models? [yes/NO]: yes
How many GPU(s) should be used for distributed training? [1]:4
accelerate configuration saved at ds_config_sample.yaml
accelerate config:
compute_environment: LOCAL_MACHINE
deepspeed_config:deepspeed_config_file: ds_config.jsonzero3_init_flag: true
distributed_type: DEEPSPEED
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
use_cpu: false
此时运行accelerate launch test.py,会输出:
Distributed environment: DEEPSPEED Backend: nccl
Num processes: 4
Process index: 0
Local process index: 0
Device: cuda:0
Mixed precision type: bf16
ds_config: {'bf16': {'enabled': True}, 'zero_optimization': {'stage': 3, 'stage3_gather_16bit_weights_on_model_save': False, 'offload_optimizer': {'device': 'none'}, 'offload_param': {'device': 'none'}}, 'gradient_clipping': 1.0, 'train_batch_size': 'auto', 'train_micro_batch_size_per_gpu': 'auto', 'gradient_accumulation_steps': 10, 'steps_per_print': inf, 'fp16': {'enabled': False}}
2.5.3 命令行配置具体参数
- 新的ds_config.json文件中,将与DeepSpeed accelerate launch命令相关的参数设置为“auto”
{"bf16": {"enabled": "auto"},"zero_optimization": {"stage": "auto","stage3_gather_16bit_weights_on_model_save": "auto","offload_optimizer": {"device": "auto"},"offload_param": {"device": "auto"}},"gradient_clipping": "auto","train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","gradient_accumulation_steps": "auto","steps_per_print": 2000000
}
- 在命令行使用具体参数来启动
accelerate launch test.py
--mixed_precision="fp16" \
--zero_stage=3 \
--gradient_accumulation_steps=5 \
--gradient_clipping=1.0 \
--offload_param_device="cpu" \
--offload_optimizer_device="nvme" \
--zero3_save_16bit_model="true" \
Distributed environment: DEEPSPEED Backend: nccl
Num processes: 4
Process index: 0
Local process index: 0
Device: cuda:0
Mixed precision type: fp16
ds_config: {'bf16': {'enabled': False}, 'zero_optimization': {'stage': 3, 'stage3_gather_16bit_weights_on_model_save': True, 'offload_optimizer': {'device': 'nvme'}, 'offload_param': {'device': 'cpu'}}, 'gradient_clipping': 1.0, 'train_batch_size': 'auto', 'train_micro_batch_size_per_gpu': 'auto', 'gradient_accumulation_steps': 5, 'steps_per_print': inf, 'fp16': {'enabled': True, 'auto_cast': True}}
注意:
- 所有剩余的"auto"值会在
accelerator.prepare()调用中处理,也就是由代码逻辑自动确定。例如 当gradient_accumulation_steps被设置为"auto"时,通过Accelerator(gradient_accumulation_steps=k)创建加速器对象时传入的gradient_accumulation_steps参数才会生效 - 当 DeepSpeed 和 Accelerator 同时设置了 gradient_accumulation_steps 时,DeepSpeed 的配置优先级更高,会覆盖 Accelerator 的配置。
2.6 模型的保存和加载
在 ZeRO Stage-1 和 Stage-2 下,保存和加载模型的方式不变。在 ZeRO Stage-3 下,由于模型权重被分区到多个GPU上,state_dict 只包含空占位符。Stage-3 有两种保存方式:
- 将完整的16位模型权重保存下来,一会直接用
model.load_state_dict(torch.load(pytorch_model.bin))加载。
这种情况需要在DeepSpeed Config file中设置zero_optimization.stage3_gather_16bit_weights_on_model_save 为True,或者在DeepSpeed Plugin中设置zero3_save_16bit_model 为True。注意,这需要在单GPU上合并权重,可能较慢且耗内存,仅在需要时使用。下面是examples/by_feature/deepspeed_with_config_support.py中的示例片段:
上述代码中,unwrapped_model = accelerator.unwrap_model(model) # 解包模型# Saves the whole/unpartitioned fp16 model when in ZeRO Stage-3 to the output directory if # `stage3_gather_16bit_weights_on_model_save` is True in DeepSpeed Config file or # `zero3_save_16bit_model` is True in DeepSpeed Plugin. # For Zero Stages 1 and 2, models are saved as usual in the output directory. # The model name saved is `pytorch_model.bin` unwrapped_model.save_pretrained(args.output_dir,is_main_process=accelerator.is_main_process,save_function=accelerator.save,state_dict=accelerator.get_state_dict(model), )args.output_dir为保存目录,is_main_process表示只在主进程上执行保存,accelerator.save为保存函数,最后通过accelerator.get_state_dict(model)获取模型的状态字典。这样就可以保存下来完整的 16 位权重模型,之后直接加载使用。 - 32位权重的保存和加载,代码示例来自examples/by_feature/deepspeed_with_config_support.py 。
-
首先通过
model.save_checkpoint()保存检查点。这将在检查点目录下创建分区后的ZeRO模型和优化器,以及zero_to_fp32.py脚本。可以使用该脚本进行脱机合并得到完整的32位权重。 -
合并脚本简单易用,不需要DeepSpeed的配置文件,还可以在CPU上运行
success = model.save_checkpoint(PATH, ckpt_id, checkpoint_state_dict) status_msg = "checkpointing: PATH={}, ckpt_id={}".format(PATH, ckpt_id) if success:logging.info(f"Success {status_msg}") else:logging.warning(f"Failure {status_msg}")$ cd /path/to/checkpoint_dir $ ./zero_to_fp32.py . pytorch_model.bin Processing zero checkpoint at global_step1 Detected checkpoint of type zero stage 3, world_size: 2 Saving fp32 state dict to pytorch_model.bin (total_numel=60506624) -
如果只需要得到state_dict,可以使用如下代码:
from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpointstate_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir) -
如果要加载此32位权重进行推理,可以使用如下代码:
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpointunwrapped_model = accelerator.unwrap_model(model) fp32_model = load_state_dict_from_zero_checkpoint(unwrapped_model, checkpoint_dir) -
这些操作大约需要原始检查点大小2倍的内存
-
2.7 DeepSpeed ZeRO Inference
ZeRO Inference 支持 ZeRO stage 3 和 ZeRO-Infinity,它使用与训练相同的 ZeRO 协议,但不使用优化器和学习率调度器,所以只有 ZeRO stage 3 对推理有用。使用时,你只需要按照下面所示准备模型和数据加载器:
model, eval_dataloader = accelerator.prepare(model, eval_dataloader)
注意事项:
- 不支持 DeepSpeed Pipeline Parallelism: 当前的集成不支持 DeepSpeed 的 Pipeline Parallelism(管道并行)。
- 不支持 mpu: 当前集成不支持 mpu,从而限制了在 Megatron-LM 中支持的张量并行性。
- 不支持多模型: 当前集成不支持多个模型。
三、相关资源
- Accelerate DeepSpeed API文档《Utilities for DeepSpeed》
- DeepSpeed GitHub、DeepSpeed官方教程、DeepSpeed官方API文档
- DeepSpeed4Science及其介绍《Announcing the DeepSpeed4Science Initiative: Enabling large-scale scientific discovery through sophisticated AI system technologies》
- 微软deepspeed相关博客:
- 《ZeRO 和 Fastest BERT:提高 DeepSpeed 深度学习训练的规模和速度》
- 《DeepSpeed 推理模型实现 (MII)》
- 《DeepSpeed ZeRO++: A leap in speed for LLM and chat model training with 4X less communication》
最后,请记住,🤗 Accelerate 仅集成了 DeepSpeed,因此如果您在使用 DeepSpeed 过程中遇到任何问题或有任何疑问,请在 DeepSpeed GitHub 上提交问题。
相关文章:
Accelerate 0.24.0文档 二:DeepSpeed集成
文章目录 一、 DeepSpeed简介二、DeepSpeed集成(Accelerate 0.24.0)2.1 DeepSpeed安装2.2 Accelerate DeepSpeed Plugin2.2.1 ZeRO Stage-22.2.2 ZeRO Stage-3 with CPU Offload2.2.3 accelerate launch参数 2.3 DeepSpeed Config File2.3.1 ZeRO Stage-…...

【系统架构设计】架构核心知识: 2.3 UML图
目录 一 UML 1 用例图 2 类图/对象图关系 3 活动图 4 顺序图 5 通信图...
等级考试试卷(三级))
2023年09月青少年软件编程(C语言)等级考试试卷(三级)
青少年软件编程(C语言)等级考试试卷(三级) 谁是你的潜在朋友 “臭味相投”——这是我们描述朋友时喜欢用的词汇。两个人是朋友通常意味着他们存在着许多共同的兴趣。然而作为一个宅男,你发现自己与他人相互了解的机会…...

SQLite3 数据库学习(一):数据库和 SQLite 基础
参考引用 SQL 必知必会SQLite 权威指南(第二版)关系型数据库概述 1. 数据库基础 1.1 什么是数据库 数据库(database):保存有组织的数据的容器(通常是一个文件或一组文件) 可以将其想象为一个文…...
上机4KNN实验4
目录 编程实现 kNN 算法。一、步骤二、实现代码三、总结知识1、切片2、iloc方法3、归一化4、MinMaxScale()5、划分测试集、训练集6、KNN算法 .py 编程实现 kNN 算法。 1、读取excel表格存放的Iris数据集。该数据集有5列,其中前4列是条件属性…...

产品经理如何保持核心竞争力?学会这些方法
如今,内卷的风已经吹到各行各业,产品经理也不例外。想要在内卷日益严重的环境中生存下来,产品经理就需要学会保持自己的核心竞争力。那么,产品经理要如何才能在内卷时代持续保持自己的核心竞争力呢? 1、建立快速学习的…...

终知人生苦短,何必自我为难
不是少年比他当年的那个目标更强,也不是他完全丧失了冲关过坎的勇气,而是他知道了自己能力的边界和极限,迫切需要外界的帮助。 不再自我设限,不再自我挑战,而是想用最简便、最快捷、最省精力的路径,解决掉困…...

C++阶段复习‘‘‘‘总结?【4w字。。。】
文章目录 前言类和对象C类定义和对象定义类成员函数C 类访问修饰符公有(public)成员私有(private)成员受保护(protected)成员 继承中的特点类的构造函数和析构函数 友元函数内联函数this指针指向类的指针类…...
嵌入式行业算青春饭吗?
今日话题,嵌入式行业算青春饭吗?嵌入式行业的技术要求确实非常广泛,需要深厚的知识广度和深度。这意味着入行门槛较高,我们需要了解不仅是软件和硬件,还要熟悉底层接口和硬件信号的处理方式,了解数据在计算…...
【C++】非类型模板参数 | array容器 | 模板特化 | 模板为什么不能分离编译
目录 一、非类型模板参数 二、array容器 三、模板特化 为什么要对模板进行特化 函数模板特化 补充一个问题 类模板特化 全特化与偏特化 全特化 偏特化 四、模板为什么不能分离编译 为什么 怎么办 五、总结模板的优缺点 一、非类型模板参数 模板参数分两类&#x…...

解决 Django 开发中的环境配置问题:Windows 系统下的实战指南20231113
简介: 在本文中,我想分享一下我最近在 Windows 环境下进行 Django 开发时遇到的一系列环境配置问题,以及我是如何一步步解决这些问题的。我的目标是为那些可能遇到类似困难的 Django 开发者提供一些指导和帮助。 问题描述: 最近…...
C语言仅凭自学能到什么高度?
今日话题,C语言仅凭自学能到什么高度?学习C语言的决定我确实非常推荐,毕竟它是编程领域的“通用工具”,初学者可以尝试并在发现编程的乐趣后制定长期学习计划。至于能够达到何种高度,这实在无法准确回答。即使是经验丰…...

Python爬虫过程中DNS解析错误解决策略
在Python爬虫开发中,经常会遇到DNS解析错误,这是一个常见且也令人头疼的问题。DNS解析错误可能会导致爬虫失败,但幸运的是,我们可以采取一些策略来处理这些错误,确保爬虫能够正常运行。本文将介绍什么是DNS解析错误&am…...

vue devtools 调试工具安装配置
方式一:在谷歌商店下载安装 打开Google Chrome浏览器 --> 右上角三个点图标 --> 更多工具 --> 扩展程序 --> 在 Chrome 应用商店中查找扩展程序和主题背景 方式二:下载插件安装包自行配置 下载devtools安装包 使用git下载,内含…...
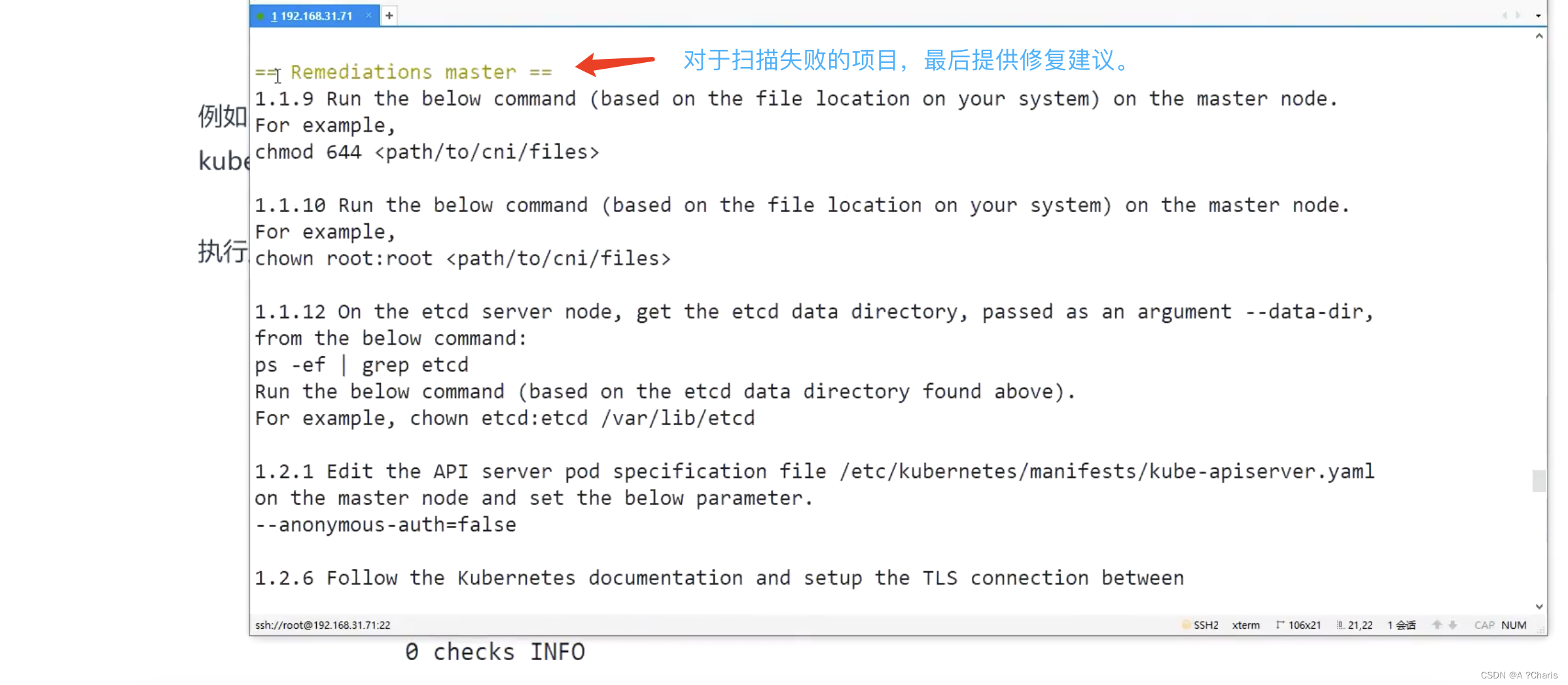
kube-bench-CIS基准的自动化扫描工具学习
仓库地址:GitHub - aquasecurity/kube-bench: Checks whether Kubernetes is deployed according to security best practices as defined in the CIS Kubernetes Benchmark kube-bench,检查 Kubernetes 是否根据 CIS Kubernetes 基准中定义的安全最佳实践部署,下载…...
)
springboot(ssm 拍卖行系统 在线拍卖平台 Java(codeLW)
springboot(ssm 拍卖行系统 在线拍卖平台 Java(code&LW) 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0)…...

go语言rpc初体验
go语言rpc初体验 package mainimport ("net""net/rpc" )// 注册一个接口进来 type HelloService struct { }func (s *HelloService) Hello(request string, replay *string) error {//返回值是通过修改replay的值*replay "hello " requestret…...
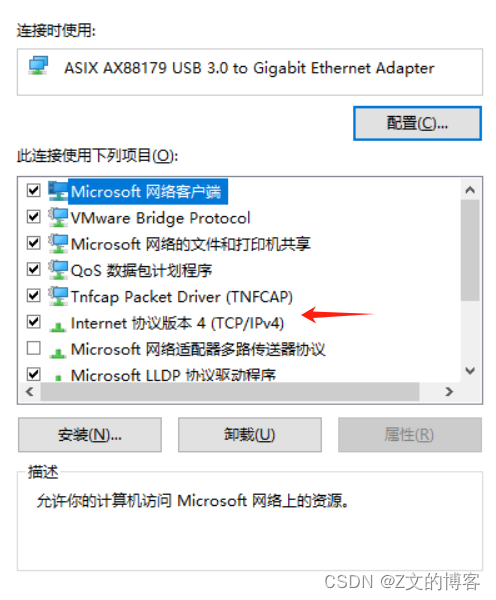
嵌入式LINUX——环境搭建 windows、虚拟机、开发板 互ping
摘要: 本文包含,如果设置linux开发板和虚拟机、windows 互ping成功 以及设置过程中出现的虚拟机、开发板查询不到eth0 windows ping开发板出项丢包等问题的解决方式。 windows端设置 windows端插入USB转网卡 打开windows桌面下右下角的网络标识 打开“更改适配器选项”…...
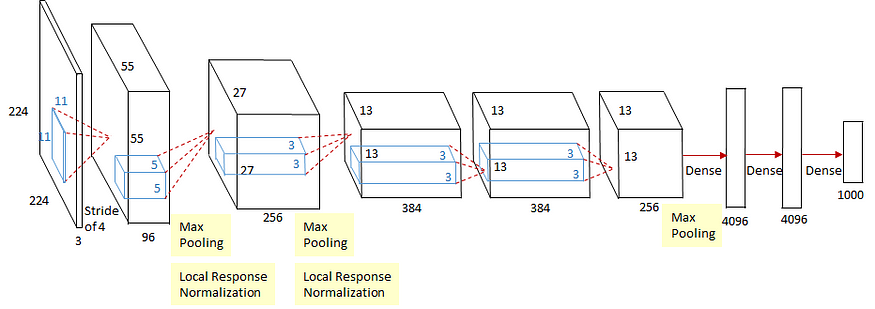
评论:AlexNet和CaffeNet有何区别?
一、说明 在这个故事中,我们回顾了AlexNet和CaffeNet。AlexNet 是2012 年ILSVRC(ImageNet 大规模视觉识别竞赛)的获胜者,这是一项图像分类竞赛。而CaffeNet是AlexNet的单GPU版,因此,我们平时在普通电脑的Al…...

什么是 IT 资产管理(ITAM),以及它如何简化业务
IT 资产管理对任何企业来说都是一项艰巨的任务,但使用适当的工具可以简化这项任务,例如,IT 资产管理软件可以为简化软件和硬件的管理提供巨大的优势。 什么是 IT 资产管理 IT 资产管理(ITAM)是一组业务实践ÿ…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...

Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析
Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析 【免费下载链接】Autodesk-Fusion-360-for-Linux This is a project, where I give you a way to use Autodesk Fusion 360 on Linux! 项目地址: https://gitcode.com/gh_mirrors/au/Autodesk-Fusion-360-for-Linu…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...

终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代
终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为电脑无法直接运行手机应用…...

基于ESP8266与RGBDigit的Wi-Fi网络时钟:硬件设计、物联网集成与DIY实践
1. 项目概述:一个能感知环境的网络时钟如果你和我一样,对复古又带点科技感的显示设备没有抵抗力,同时又是个喜欢动手折腾的极客,那么这个项目绝对能让你在工作室或家里多一个既实用又炫酷的玩意儿。我说的就是这款基于RGBDigit数码…...

3步搞定B站缓存视频转换:m4s转MP4的终极解决方案
3步搞定B站缓存视频转换:m4s转MP4的终极解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的视频&a…...