MySQL--主从复制和读写分离
MySQL主从复制和读写分离相关知识
1.什么是读写分离
读写分离,基本的原理是让主数据库处理事务性增、改、删操作( INSERT、UPDATE、DELETE) ,而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
2.为什么要读写分离?
1.数据库在写入数据的时候比较耗时(10000条数据 大概要4分钟)
2.数据库在读写的时候速度很快(10000条 大概5 秒左右)
读写分离之后,数据的写入和读取是分开的,哪怕写入的数据量比较大,但是不影响查询的效率
3.什么场景下需要读写分离?
数据库不是一定需要读写分离。只是在某些程序在使用数据库过程中,更新少,但是查询较多,这种情况可以考虑读写分离。
生产库一般都会做读写分离。
测试库一般不管。
在工作中,数据库的读写不会在同一个库中完成,这样既不安全,也不能满足高可用,也不能实现高并发。工作中都会做读写分离。
4.主从复制的优点
-
数据分布:通过复制将数据分布到不同地理位置
-
负载均衡:读写分离以及将读负载到多台从库
-
备份:可作为实时备份
-
高可用性:利用主主复制实现高可用
5. mysql支持的复制类型
(1) STATEMENT:基于语句的复制。在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制(5.7版本之前),执行效率高。高并发的情况可能会出现执行顺序的误差,事务的死锁。
(2)ROW:基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一 遍。精确,但效率低,保存的文件会更大。(5.7版本之后默认采用ROW模式)
(3)MIXED:混合类型的复制。默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。更智能,所以大部分情况下使用MIXED。
三者区别
1.STATEMENT(基于sql):高并发会导致数据丢失,顺序有误
2.ROW(基于行):精准匹配,但恢复数据时,效率低
3.MIXED:一般情况用sql,高并发自动切换row
6.mysql主从复制的过程
主从复制基于主mysql服务器和从mysql服务器的三个线程和两个日志展开进行的:
两个日志:二进制日志(bin log) 、中继日志(Relay log)
三个线程:I/O线程、dump线程、SQL线程
7.主从复制的工作过程:
1、 主节点的数据记录发生变化都会记录在二进制日志
2、 slave节点会在一定时间内对主库的二进制文件进行探测。探测是否发生变化。如果有变化从库会开启一个IO的线程。请求主库的二进制事件。
3、 主库会给每一个I/O的线程启动一个dump线程,用于发送二进制事件给从库。从库通过I/O线程获取跟新,slave_sql负责将更新写入到从库本地,实现主从一致。
8.主从复制的问题:
1、 只能在主库上发生变化,然后同步到从。从库的更新不会同步到主
2、复制的过程是串行化过程,在从库上复制是串行的。主库的并行更新不能在从库上并行操作。
3、 主从复制的设计目的:就是为了在主库上写,在从库上查。读写分离,实现高可用。
MySQL主从复制的模式
1.异步复制:
MySQL的默认复制就算异步复制。只要执行完之后,客户端提交事务,主MySQL会立即把结果返回给服务器,主MySQL并不关心从MySQL是否已经接受,并且处理。
异步:不用等待返回结果(udp )
主一旦崩溃,主MySQL的事务可能没有传到从MySQL,这个时候强行把从提升为主,可能到新的主MySQL数据不完整(很少见)
2.全同步复制,
主库执行完成一个事务,所有的从库都执行了该事务之后才会返回客户端。因为需要等待所有从库全部执行完成,性能必然下降。(对数据一致性,和数据完整要求很好的场景)
3.半同步复制:
介于异步复制和全同步复制之间。主库执行完一个客户端提交的事务之后,至少等待一个从库接受并处理完成之后才会返回给客户端。半同步在一定程度上提高了数据的安全性。也会有一定的延迟。
这个延迟一般是一个tcp/ip的往返时间(从发送到接受的时间,单位是毫秒)。半同步复制最好在电视的网络中使用。
时间<1ms:round-trip-time RTT
如何实现主从复制
mysql 1 主 20.0.0.100
MySQL 2 从 20.0.0.110
MySQL 3 从 20.0.0.10
test1 读写分离的服务器 20.0.0.140
test2 客户端关闭防火墙
systemctl stop firewalld
setenforce 0MySQL1
yum -y install ntp
vim /etc/ntp.conf末
server 127.127.233.0
fudge 127.127.233.0 stratum 8
//数字越小。时间精确度越高。设置fudge 8,时间层级是8,最高为(15),设在中间即可,从本地获取时间源同步,不从网络获取systemctl restart ntpd
mysql2,3
systemctl restart ntpdmysql2,3
/usr/sbin/ntodate 192.168.233.21crontab -e -u root
*/30 * * * * /usr/sbin/ntpdate 192.168.233.21date 查看时间MySQL1
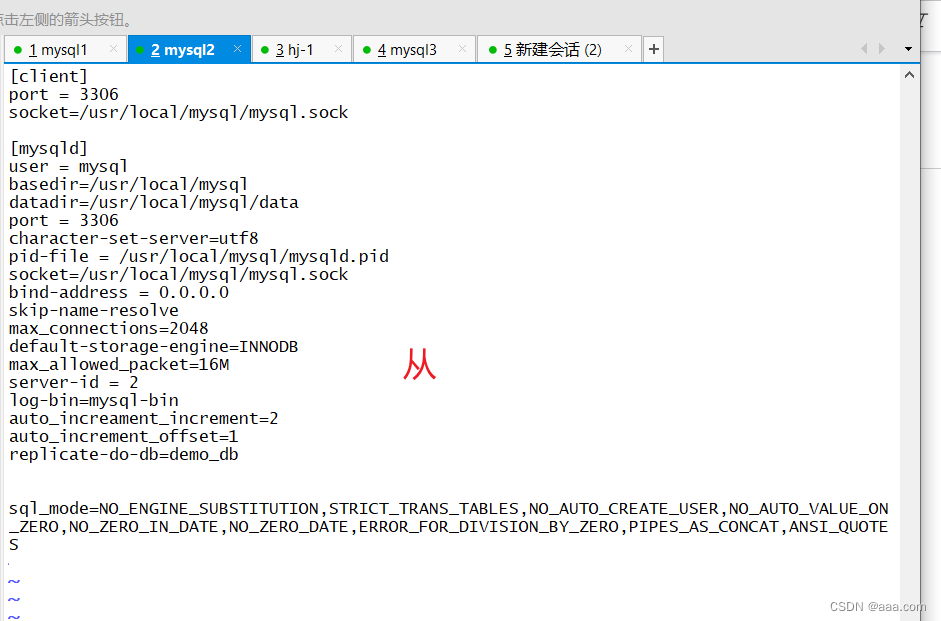
vim /etc/my.cnfserver-id = 1
log-bin=master-bin
//打开二进制日志
binlog_format=MIXED
//处理方式
log_slave-updates=true
//允许从服务器复制数据时,可以从主的二进制日志写到自己的二进制日止当中
wqsystemctl restart mysqldmysql -uroot -p123456
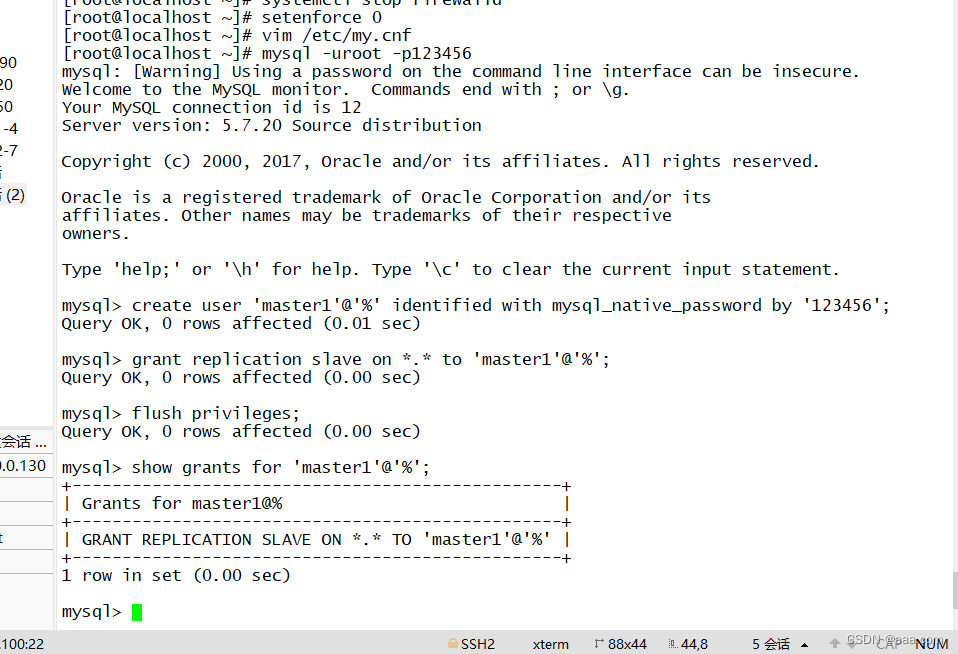
grant replication slave on *.* to 'mysqlslave'@'20.0.0.%' identified by '123456';flush privilieges;show master status;从库MySQL2
vim /etc/my.cnf
server-id = 2
relay-log=relay-log-bin
relay-log-index=slave-relay-bin.index
// 设置索引文件
relay_log_recovery=1
//默认是0,1开启中继日志的护肤,从服务器出现异常或者崩溃时systemctl restart mysqldmysql3
vim /etc/my.cnf
server-id = 3
relay-log=relay-log-bin
relay-log-index=slave-relay-bin.index
relay_log_recovery=1
wq
systemctl restart mysqldmysql2
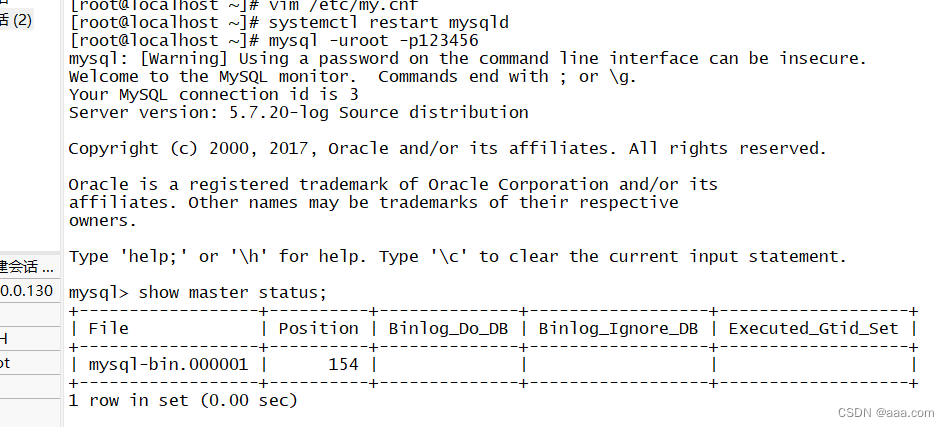
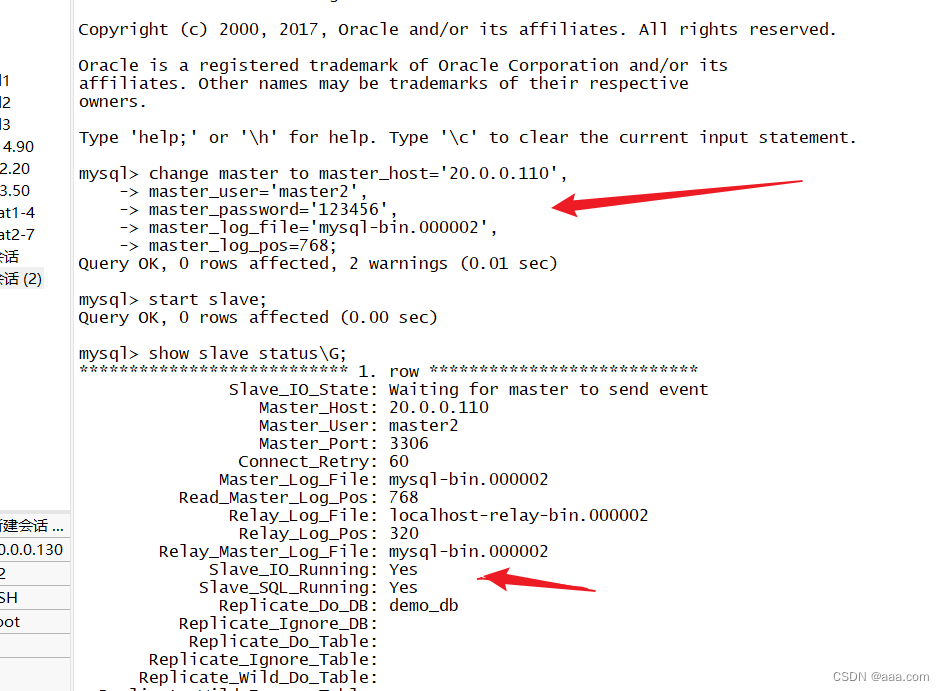
mysql -uroot -p123456CHANGE master to master_host='20.0.0.100',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=599;
//同步start slave;
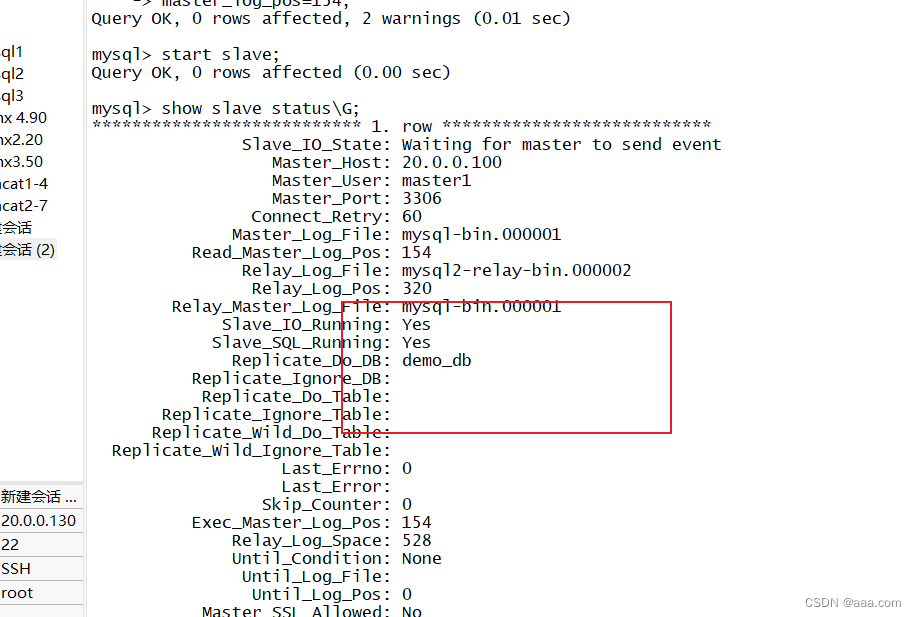
show slave status\G;mysql3
mysql -u root -p 123456CHANGE master to master_host='20.0.0.100',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=599;
//同步
start slave;打开终端
MySQL1
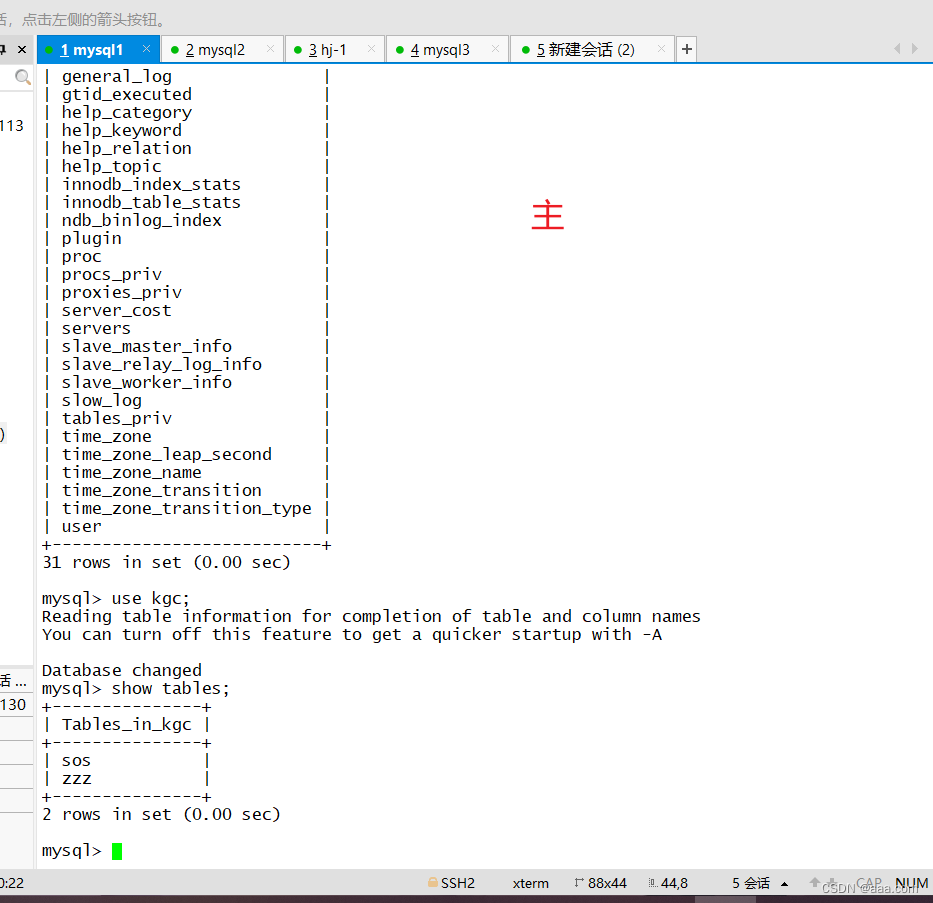
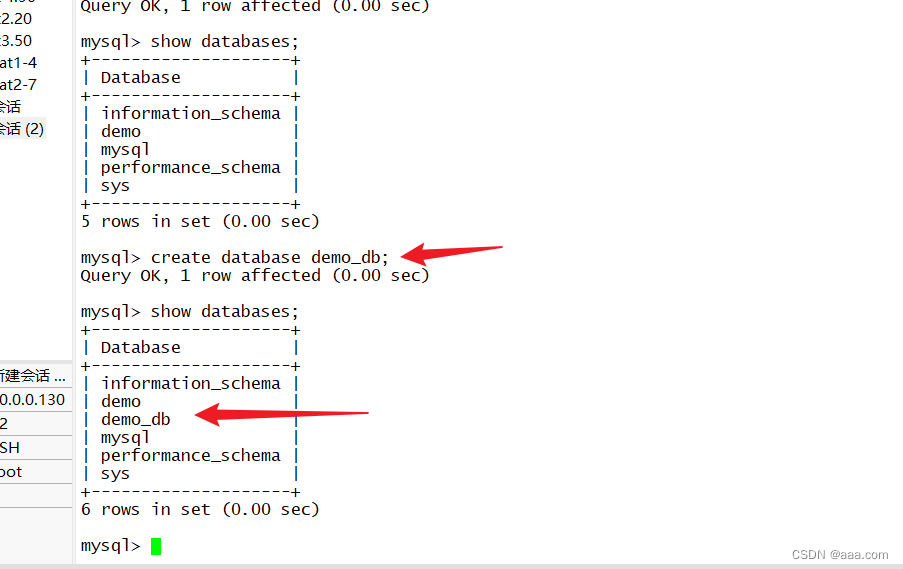
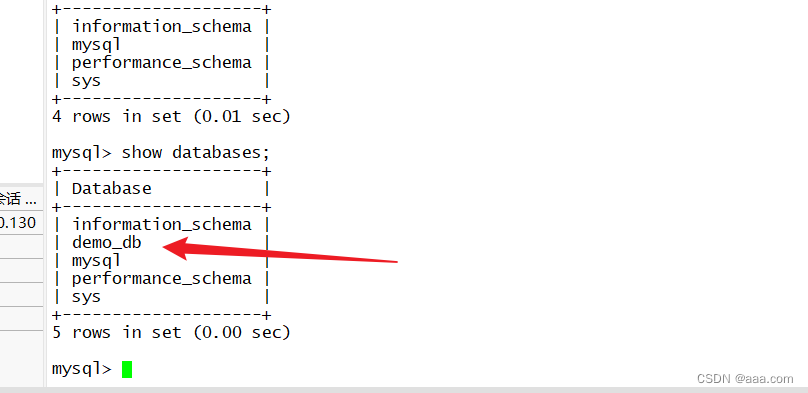
create database kgc;MySQL2,3查看是否有kgc的库MySQL1
create table test ();
给表插入数据Slave_IO_Running:Yes 负责和主库的IO通信
//位置偏移量不对,防火墙没关,配置文件不对
Slave SQL Running:Yes
//负责自己的slave MySQL进程
slave io running no 的原因
1.网络问题
2.my.cnf 配置文件写错了
3.CHANGE master to master_host='192.168.233.21',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=604; 文件名写错了,位置偏移量不对
4.防火墙和安全机制的问题
**位置偏移量要和主服务器上 show master status;中内容一致
主从复制延迟的问题
1.网络延迟
2.主从硬件设备(CPU主频,内存I/O,硬件I/O)
3.同步复制而不是异步复制
解决方案:
1.硬件方面:主库一般来说不需要动的太多,从库的硬件配置变更好。提升随机写的性能,硬盘可以考虑缓存固态。升级cpu的核数,扩展一下内存。尽量使用物理机(不要使用云服务器)。四核8G,硬盘
2.网络层面,主从服务器都配置在一个局域网内,尽量避免跨网段,跨机房。
架构方面:做读写分离把写入控制在主库,从库负责读,降低从库的压力
4.配置方面mysql配置,从配置文件的角度实现性能最大化
追求安全性配置:
innodb flush_log_at_trx_commit=1
//每次啊hi去提交时都会刷新事务日志,已确保持久性,最高级别的数据安全性,但是会影响性能,默认是1
0 就是事务提交是不会立即刷新,而是每秒刷新。可以提高性能,但是发送故障会导致数据丢失
2 事务提交时,事务日志不会写入硬盘而是保存在系统缓存,不会进行刷新,一定的安全性和性能,内存要求比较高。
sunc_binlog=1
1 也是默认值,每次提交事务之后,直接把二进制刷新到硬盘,以确保日志的持久性,占用比较高的性能,但是安全
0 二进制日志写入缓存,也不会刷新日志文件。故障发送也会发发
读写分离配置
要实现读写分离,首先必须要实现主从复制。
读写分离:所有的写入操作都在主库,从库只负责读。(select)。如果有更新,是从主库复制到从库。
Mysql读写分离的原理:
1.根据脚本实现。在代码中实现路由分类。select insert进行路由分类。这种方式是最多的。
特点:性能号,在代码中就能实现,不需要额外的硬件设备
缺点:门槛高,开发实现。如果大型的复制的应用,设计改动的代码非常多。
2.基于中间层代理实现
mysql-proxy自带的开源项目。基于自带的lua脚本不是现成的,要自己写,不熟悉他的内置变量是写不出来的 atlas 360内部自己使用的代理工具。每天的读写请求承载量可以到几十亿条,支持事务,支持存储过程
Amoeba 陈思儒,之前在阿里就职。是由java开发的一个开源软件,不支持事务,也不支持存储过程。但是Amoeba也是用的最广
mycat也可以实现
安装部署mycat
(1)主机上安装java(mycat基于java)
#yum安装java
[root@localhost ~]#yum install java -y
#确认安装成功
[root@localhost ~]#java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)(2)切换至opt目录,下载mycat安装包
[root@localhost ~]#cd /opt
[root@localhost ~]#wget http://dl.mycat.org.cn/1.6.7.6/20210303094759/Mycat-server-1.6.7.6-release-20210303094759-linux.tar.gz(3)创建/apps文件夹,并解压mycat包至/apps下
[root@localhost ~]#mkdir /apps
[root@localhost ~]#tar zxvf Mycat-server-1.6.7.6-release-20210303094759-linux.tar.gz -C /apps/(4)设置变量环境
[root@localhost ~]#echo 'PATH=/apps/mycat/bin:$PATH' > /etc/profile.d/mycat.sh
[root@localhost ~]#source /etc/profile.d/mycat.sh(5)启动mycat,查看日志文件,最后可以看到启动成功
[root@localhost ~]#mycat start
#注意内存小于2G 起不来
Starting Mycat-server...[root@localhost ~]#tail -f /apps/mycat/logs/wrapper.log
#启动成功日志末尾会出现successfully
STATUS | wrapper | 2021/12/09 21:04:10 | --> Wrapper Started as Daemon
STATUS | wrapper | 2021/12/09 21:04:10 | Launching a JVM...
INFO | jvm 1 | 2021/12/09 21:04:11 | Wrapper (Version 3.2.3) http://wrapper.tanukisoftware.org
INFO | jvm 1 | 2021/12/09 21:04:11 | Copyright 1999-2006 Tanuki Software, Inc. All Rights Reserved.
INFO | jvm 1 | 2021/12/09 21:04:11 |
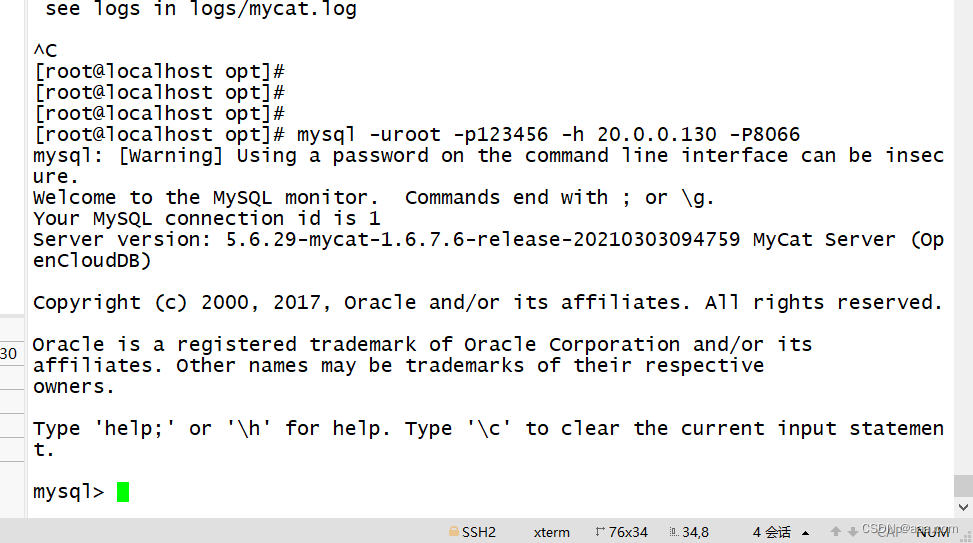
INFO | jvm 1 | 2021/12/09 21:04:12 | MyCAT Server startup successfully. see logs in logs/mycat.log(6)客户端连接数据库
#这里密码初始为123456 需要加端口
[root@localhost bin]#mysql -uroot -p123456 -h 192.168.59.114 -P8066
修改 mycat 配置文件 /apps/mycat/conf/server.xml
[root@localhost ~]#vim /apps/mycat/conf/server.xml#去掉44行行注释,对应的在51行行末注释,删除50行行末注释,5 * 60 * 1000L; //连接空> 闲检查#修改45行端口号为3306
45 <property name="serverPort">3306</property>#配置Mycat的连接信息(账号密码),在110 和111行, 可以修改,这边不修改了
修改 mycat 配置文件/apps/mycat/conf/schema.xml
[root@localhost ~]#vim /apps/mycat/conf/schema.xml
#删除所有内容,重新写入以下
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">#schema标签:数据库设置,此数据库为逻辑数据库,name与server.xml中schema对应。#name:逻辑数据库名,与server.xml中的schema对应;#checkSQLschema: 数据库前缀相关设置,这里为false;#sqlMaxLimit: select时默认的limit,避免查询全表,否则可能会遇到查询量特别大的情况造成卡 死;#dataNode:表存储到哪些节点,多个节点用逗号分隔。节点为下文dataNode设置的name
</schema><dataNode name="dn1" dataHost="localhost1" database="hellodb" />#dataNode标签: 定义mycat中的数据节点,也是通常说的数据分片,也就是分库相关配置#name: 定义数据节点的名字,与table中dataNode对应#datahost: 物理数据库名,与datahost中name对应,该属性用于定义该分片属于哪个数据库实例#database: 物理数据库中数据库名,该属性用于定义该分片属性哪个具体数据库实例上的具体库<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"#dataHost标签: 物理数据库,真正存储数据的数据库#name: 物理数据库名,与dataNode中dataHost对应#maxCon属性指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的writeHost、readHost标 签都会使用这个属性的值来实例化出连接池的最大连接数#minCon属性指定每个读写实例连接池的最小连接,初始化连接池的大小#balance: 均衡负载的方式writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">#writeType: 写入方式#dbType: 数据库类型#dbDriver指定连接后端数据库使用的 Driver,目前可选的值有 native 和 JDBC。用 native 的话,因为这个值执行的是二进制的 mysql 协议,所以可以使用 mysql 和maridb。其他类型的数据库则需要使用 JDBC 驱动来支持。#switchType: “-1” 表示不自动切换; “1” 默认值,自动切换; “2” 基于 MySQL主从同步的状态决定是否切换心跳语句为 show slave status; “3” 基于 MySQL galary cluster 的切换机制(适合集群)(1.4.1)心跳语句为 show status like ‘wsrep%’.<heartbeat>select user()</heartbeat>#heartbeat: 心跳检测语句,注意语句结尾的分号要加<writeHost host="host1" url="192.168.59.113:3306" user="root" password="123456">#host:用于标识不同实例,一般 writeHost 我们使用*M1,readHost 我们用*S1。#url:后端实例连接地址。Native:地址:端口 JDBC:jdbc的url#user:后端存储实例需要的用户名字#password:后端存储实例需要的密码<readHost host="host2" url="192.168.59.112:3306" user="root" password="123456"/></writeHost></dataHost>
</mycat:schema>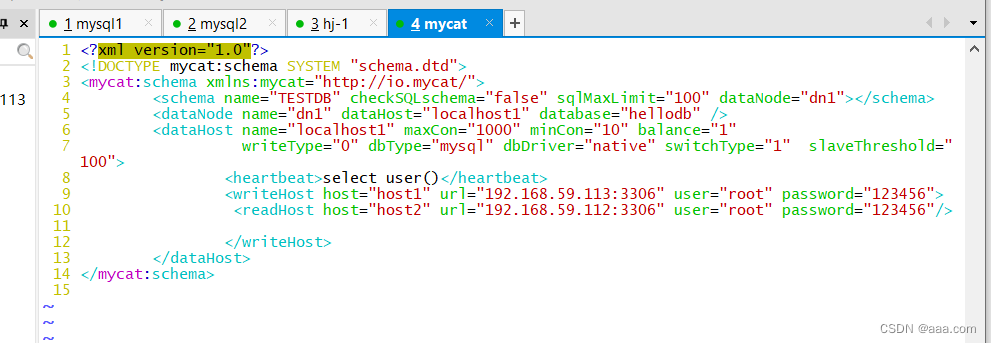
<dataNode name="主服务器的主机名">
<database="指定主服务器的数据库名">
<writeHost host="host1" url="主服务器的IP">
<readHost host="host1" url="从服务器的IP">
主服务器上授权
[root@localhost ~]#mysql -uroot -p123123
#授权
GRANT ALL ON *.* TO 'root'@'192.168.59.%' IDENTIFIED BY '123456';
flush privileges;#查看创建成功
use mysql;
select user,host from user;GRANT ALL ON *.* TO 'root'@'192.168.59.%' IDENTIFIED BY '123456';
flush privileges;
此处一定要刷新权限,否则接下来配置无法成功启动!!!!
重启mycat服务,客户机连接mycat
在mycat服务器上,重启mycat服务,查看启动日志,文末出现successfully[root@localhost ~]#mycat restart [root@localhost ~]#tail -f /apps/mycat/logs/wrapper.logINFO | jvm 1 | 2021/12/09 21:15:40 |
INFO | jvm 1 | 2021/12/09 21:15:40 | MyCAT Server startup successfully. see logs in logs/mycat.log
STATUS | wrapper | 2021/12/09 21:16:38 | TERM trapped. Shutting down.
STATUS | wrapper | 2021/12/09 21:16:39 | <-- Wrapper Stopped
STATUS | wrapper | 2021/12/09 21:16:40 | --> Wrapper Started as Daemon
STATUS | wrapper | 2021/12/09 21:16:40 | Launching a JVM...
INFO | jvm 1 | 2021/12/09 21:16:40 | Wrapper (Version 3.2.3) http://wrapper.tanukisoftware.org
INFO | jvm 1 | 2021/12/09 21:16:40 | Copyright 1999-2006 Tanuki Software, Inc. All Rights Reserved.
INFO | jvm 1 | 2021/12/09 21:16:40 |
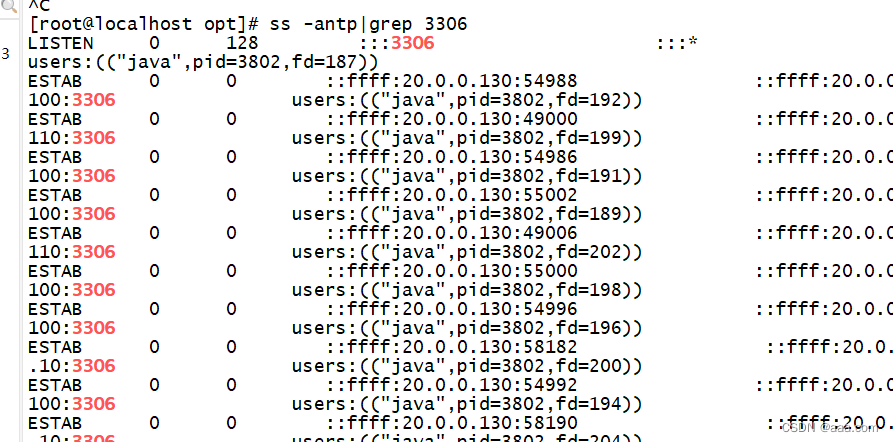
INFO | jvm 1 | 2021/12/09 21:16:41 | MyCAT Server startup successfully. see logs in logs/mycat.l查看3306端口,可以监听到主从服务器
ss -antp|grep 3306此处必须得是 user:(("java".......))
才算成功。同时,如果本机有mysql,一定得关闭mysql服务,否则会因为端口被占从而服务搭建失败
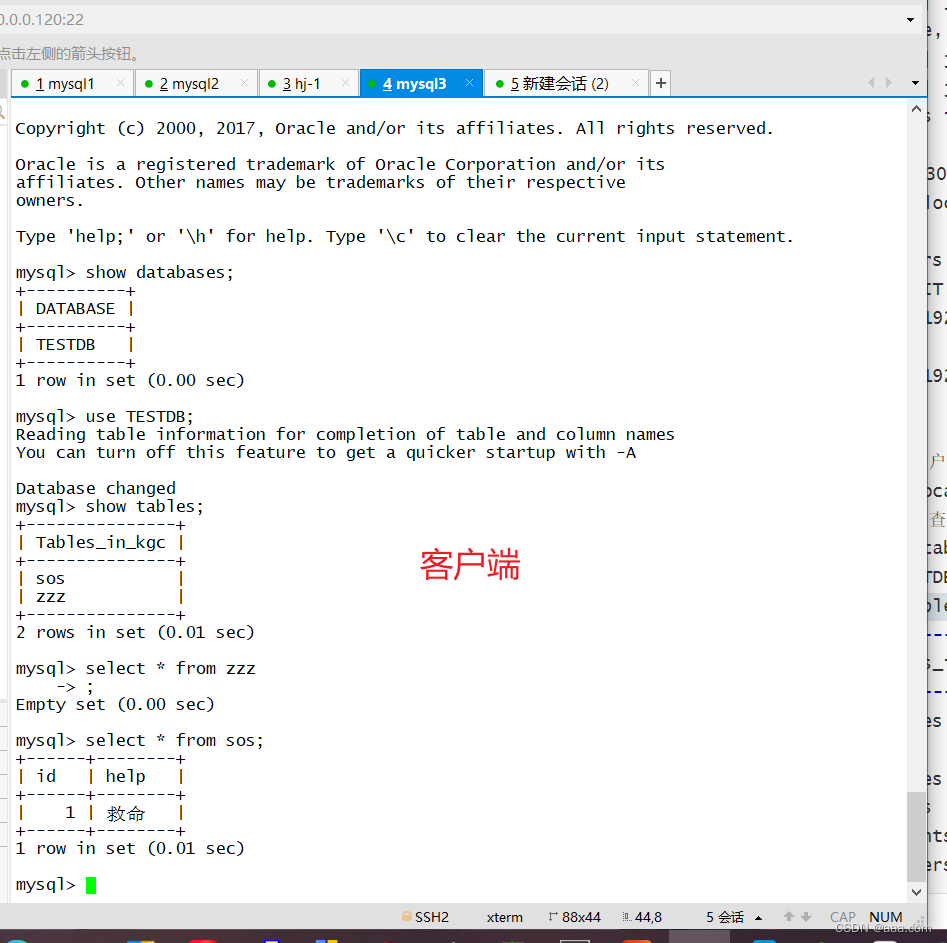
在客户机上登录mycat,这时可以不加端口直接进入数据库了

如何实现完全同步
完全同步其实就是主主同步。

相关文章:
MySQL--主从复制和读写分离
MySQL主从复制和读写分离相关知识 1.什么是读写分离 读写分离,基本的原理是让主数据库处理事务性增、改、删操作( INSERT、UPDATE、DELETE) ,而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。 2.为什么要…...

JavaScript使用webcomponent的简单示例
官方网站: Web Component - Web API 接口参考 | MDN 1. 给一个html文件的路径字符串path, 存储对应path下的template,script,style数据 1) 传入path 2) 使用fetch将path字符串所在的文件找到并返回内容 const res await fetch(path).then(res > res.text()); 3) 使用…...
LeetCode(10)跳跃游戏 II【数组/字符串】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 45. 跳跃游戏 II 1.题目 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nu…...

浅谈数据结构之递归
1. 递归的定义 递归是一种在解决问题时使用自身的特殊方法。在计算机科学和数据结构中,递归是一种通过将问题分解成更小的、相似的子问题来解决复杂问题的方法。递归可以直接或间接地调用自身,将大问题转化为规模较小的子问题,直到达到基本情…...

在CentOS7环境下安装Mysql
1.卸载已有的不需要的环境 使用如下命令,查看系统中是否已经存在mysql和mariadb(mysql的一个子分支) ps ajx | grep mariadb ps ajx | grep mysql 如果显示与我相同,则代表系统中已经存在这些环境并且已经停止 如果不相同则需要…...
苍穹外卖-day10
苍穹外卖-day10 课程内容 Spring Task订单状态定时处理WebSocket来单提醒客户催单 功能实现:订单状态定时处理、来单提醒和客户催单 订单状态定时处理: 来单提醒: 客户催单: 1. Spring Task 1.1 介绍 Spring Task 是Spring框…...

牛客网刷题笔记131111 Python实现LRU+二叉树先中后序打印+SQL并列排序
从学校步入职场一年多,已经很久没刷过题了,为后续稍微做些提前的准备,还是重新开始刷刷题。 从未做过计划表,这回倒是做了个计划表,希望能坚持吧。 刷题比较随性且量级不大,今天就写了2个算法2个sql&#x…...
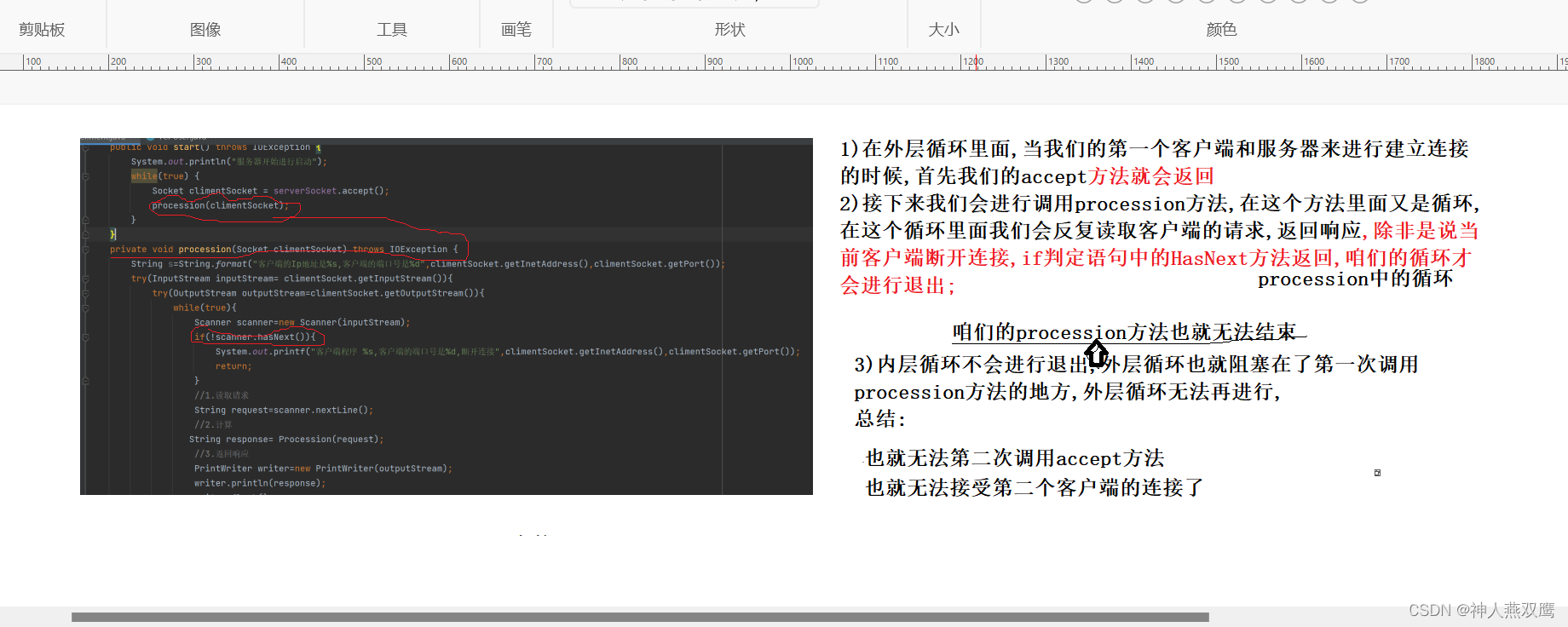
TCP网络编程
一)TCP Socket介绍: 1)TCP和UDP有着很大的不同,TCP想要进行网络通信的话首先需要通信双方建立连接以后然后才可以进行通信,TCP进行网络编程的方式和文件中的读写字节流类似,是以字节为单位的流进行传输 2)针对于TCP的套接字来说,J…...
K8S知识点(九)
(1)Pod详解-结构和定义 一级属性有下面这些:前两个属性是字符串,上面有定义 kind:Pod version:v1 下面的属性是object 还可以继续查看子属性:二级属性 还可以继续查看三级属性: 通…...
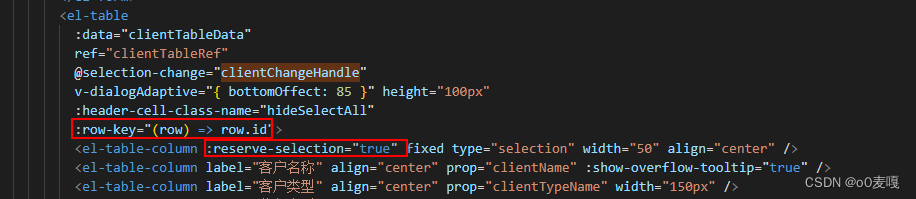
el-table实现单选和隐藏全选框和回显数据
0 效果 1 单选 <el-table ref"clientTableRef" selection-change"clientChangeHandle"><el-table-column fixed type"selection" width"50" align"center" /><el-table-column label"客户名称" a…...

香港科技大学广州|智能制造学域机器人与自主系统学域博士招生宣讲会—中国科学技术大学专场
🏠地点:中国科学技术大学西区学生活动中心(一楼)报告厅 【宣讲会专场1】让制造更高效、更智能、更可持续—智能制造学域 🕙时间:2023年11月16日(星期四)18:00 报名链接:…...

[P7885][Android13] 解决5G信号良好状态栏信号只有两格的问题
文章目录 开发平台基本信息问题描述解决方法 开发平台基本信息 芯片: 展锐P7885 版本: Android 13 kernel: kernel-5.15 问题描述 最近有一款预研设备使用的是展锐 P7885 的5G 智能模组;经过天线厂调试天线后,各项指标都达到了标准,正常待…...

老版本goland无法调试新版本go问题处理
背景 无法调试1.20版本b 报错如下: No goroutine selected 懒人不想升级goland版本。 处理方法 1.安装最新的dlv工具 go install github.com/go-delve/delve/cmd/dlvlatest 2.找到刚刚安装的dlv工具,并复制 # 位于$GOPATH的bin目录下,如…...
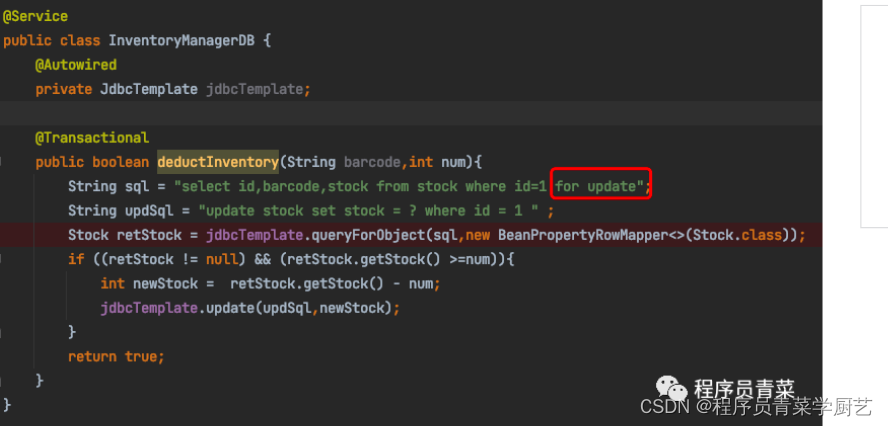
Redis应用之二分布式锁2
一、前言 前一篇 Redis应用之二分布式锁 我们介绍了使用SETNX来实现分布式锁,并且还遗留了一个Bug,今天我们对代码进行优化,然后介绍一下Redisson以及数据库的乐观锁悲观锁怎么用。 二、SetNX分布式锁优化后代码 RedisService.java Inven…...

打印字符(C++)
系列文章目录 进阶的卡莎C++_睡觉觉觉得的博客-CSDN博客数1的个数_睡觉觉觉得的博客-CSDN博客双精度浮点数的输入输出_睡觉觉觉得的博客-CSDN博客足球联赛积分_睡觉觉觉得的博客-CSDN博客大减价(一级)_睡觉觉觉得的博客-CSDN博客小写字母的判断_睡觉觉觉得的博客-CSDN博客纸币(…...
)
React函数组件的使用(Hooks)
目录 Hooks概念理解 1. 什么是hooks 2. Hooks解决了什么问题 useState 1. 基础使用 2. 状态的读取和修改 3. 组件的更新过程 4. 使用规则 useEffect 1. 理解函数副作用 2. 基础使用 3. 依赖项控制执行时机 4. 清理副作用 Hooks概念理解 本节任务: 能够理解hooks的…...

一篇博客读懂队列——Queue
目录 一、队列的概念和结构 二、队列的实现 2.1队列的初始化QueueInit 2.2队列的摧毁QueueDestroy 2.3插入结点QueuePush 2.4删除结点QueuePop 2.5返回队头QueueFront 2.6返回队尾QueueBack 2.7判断队列为空QueueEmpty 2.8统计队列数目QueueSize 一、队列的概念和…...
Effective C++ 系列和 C++ Core Guidelines 如何选择?
Effective C 系列和 C Core Guidelines 如何选择? 如果一定要二选一,我会选择C Core Guidelines。因为它是开源的,有300多个贡献者,而且还在不断更新,意味着它归纳总结了最新的C实践经验。最近很多小伙伴找我ÿ…...

Sandbox: bash(5613) deny(1) file-write-create 错误解决
Showing Recent Errors Only Sandbox: bash(5613) deny(1) file-write-create /Users/xx/Dev/UniappLearn/MSLUniappDemo/Pods/resources-to-copy-MSLUniappDemo.txt image.png 解决方法 build setting搜索ENABLE_USER_SCRIPT_SANDBOXING,YES(默认&…...
腾讯云标准型S5服务器五年优惠价格表(4核8G和2核4G)
腾讯云服务器网整理五年云服务器优惠活动 txyfwq.com/go/txy 配置可选2核4G和4核8G,公网带宽可选1M、3M或5M,系统盘为50G高性能云硬盘,标准型S5实例CPU采用主频2.5GHz的Intel Xeon Cascade Lake或者Intel Xeon Cooper Lake处理器,…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了
AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了2026年真正值得重视的AI底层能力,是让模型知道该信谁 你有没有发现一个很扎心的变化。 以前我们用AI,最怕它不会。 现在我们用AI,最怕它太会了。 它能写…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...

Raspberry Pi Debug Probe:RP2040嵌入式开发的调试利器与实战指南
1. 项目概述:为什么你需要一个Raspberry Pi Debug Probe?如果你玩过树莓派Pico或者任何基于RP2040芯片的开发板,肯定遇到过这样的场景:写好的代码,点一下“上传”,然后……就没有然后了。板子上的LED没按你…...

如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南
如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 如果你正在玩《鸣潮》却频繁遭遇帧率波动、画面卡顿或操作延迟,那…...