45 深度学习(九):transformer
文章目录
- transformer
- 原理
- 代码的基础准备
- 位置编码
- Encoder block
- multi-head attention
- Feed Forward
- 自定义encoder block
- Deconder block
- Encoder
- Decoder
- transformer
- 自定义loss 和 学习率
- mask生成函数
- 训练
- 翻译
transformer
这边讲一下这几年如日中天的新的seq2seq模式的transformer,这个模型解决了RNN训练时不能并行训练的慢,提出了self-attention机制,并关注到了注意力机制,也为之后的发展引领了新的时尚。
原理
我们首先看一下transformer这个的结构图,然后根据这个结构图进行实现代码
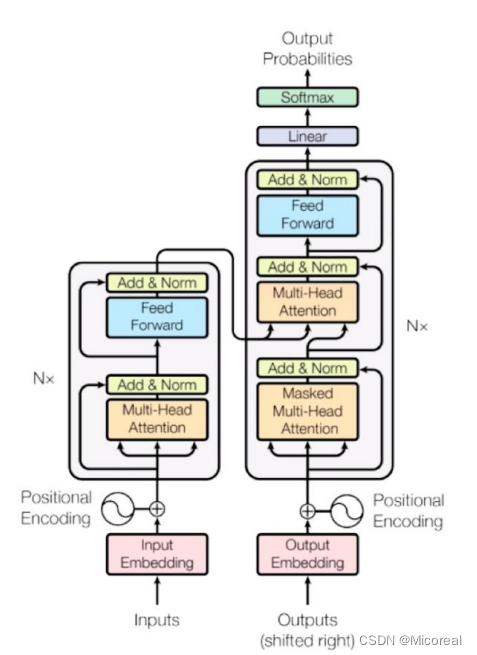
代码的基础准备
import numpy as np
import pandas as pd
import tensorflow as tf
import unicodedata
import re
from sklearn.model_selection import train_test_split
# 数据处理,主要和业务相关,当工作的时候绝大多数也就是将业务和代码相连接,这是十分重要的
# -----------------------------------------------------------------------------
# 数据预处理 去除重读的因子 和带空格以及特殊标点符号的东西
def preprocess_sentence(i):# NFD是转换方法,把每一个字节拆开,Mn是重音,所以去除i = ''.join(c for c in unicodedata.normalize('NFD',i) if unicodedata.category(c)!='Mn')# 把英文或者西班牙文变成纯小写,翻译与大写小写无关,降低影响,并且去掉头尾的空格i = i.lower().strip()# 在单词与跟在其后的标点符号之间插入一个空格i = re.sub(r"([?.!,¿])", r" \1 ", i)# 因为可能有多余空格,所以处理一下i = re.sub(r'[" "]+', " ", i)# 除了 (a-z, A-Z, ".", "?", "!", ","),将所有字符替换为空格i = re.sub(r"[^a-zA-Z?.!,¿]+", " ", i)i = i.rstrip().strip()i = '<start> ' + i + ' <end>'return idef load_dataset(path, num_examples):# lines就是读取之后的每一行的数据列表lines = open(path, encoding='UTF-8').read().strip().split('\n')# i就是一个样本,一个英文样本或者一个西班牙的样本word_pairs = [[preprocess_sentence(i) for i in line.split('\t')]for line in lines[:num_examples]]# 我们这边想要拿英文翻译成西班牙文,而我们查看data当中发现英语在左侧 西班牙语在右侧,所以英语左边应该是inputinputs,targets =zip(*word_pairs)# Tokenizer帮我们把词语式的转换为id式的,filters是黑名单 英语和西班牙语的需要额外自己分别训练inputs_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')targets_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')# 训练词袋inputs_tokenizer.fit_on_texts(inputs)targets_tokenizer.fit_on_texts(targets)# 把英文或西班牙文转化为数字 sparseinputs_tensor = inputs_tokenizer.texts_to_sequences(inputs)targets_tensor = targets_tokenizer.texts_to_sequences(targets)# 还需要补长或者截断 没有maxlen 就是自动取最长的进行补0inputs_tensor = tf.keras.preprocessing.sequence.pad_sequences(inputs_tensor, padding='post')targets_tensor = tf.keras.preprocessing.sequence.pad_sequences(targets_tensor, padding='post')return inputs_tensor, targets_tensor, inputs_tokenizer, targets_tokenizerdata_path = './data_spa_en/spa.txt'
# 需要训练的数据量 这边取全部,如果觉得训练太久,这边就选小一点
num_examples = 118964
# inp_lang targ_lang 是tokenizer
input_tensor, target_tensor, input_tokenizer, target_tokenizer = load_dataset(data_path, num_examples)
# 这边就不定义测试集了,对于nlp领域来说准确性一般没有什么作用
input_tensor_train, input_tensor_val, target_tensor_train, target_tensor_val = train_test_split(input_tensor, target_tensor, test_size=0.2)
batch_size = 64
embedding_dim = 256
units = 1024
# 训练集
dataset = tf.data.Dataset.from_tensor_slices((input_tensor_train,target_tensor_train)).shuffle(len(input_tensor_train))
dataset = dataset.batch(batch_size,drop_remainder=True)max_input_length = max(len(t) for t in input_tensor)
max_target_length = max(len(t) for t in target_tensor)
input_tokenizer_length = len(input_tokenizer.word_index)
target_tokenizer_length = len(target_tokenizer.word_index)
# -----------------------------------------------------------------------------
这个和之前的那个seq2seq的实现是完全一致的,这边就不细说。
位置编码
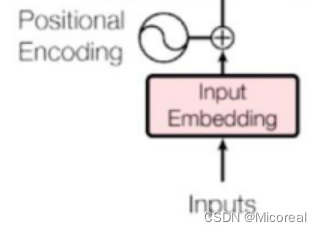
然后我们先实现的是这个位置编码这一部分,首先我们知道的是,我们的inputs的输入会先经过embedding层形状变成(batch-size,num-steps,embedding-dim),然后我们需要加上一个关于位置的矩阵,这个位置矩阵,包含着就是位置的信息,我们这边采用比较常见的sin-cos的方法去构建:
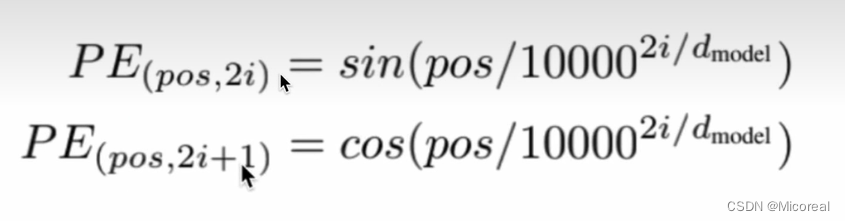
pos的意思就是一句话当中的第几个字,而i代表的就是这个字我们不是经过了embedding之后的第几个维度,也就对应着我们上面的那个输入经过了embedding之后的形状,而这个位置编码实际上就是为了满足让后面的元素和前面的元素相构成关系,也就是前面几个元素的关系和可以推出下一个元素,这样的道理。
具体的数学证明见下:

这边就不细说了,这还是很简单的。
理解了上面,关于如何提取出位置编码,这边就需要有相关的小技巧,我们使用切片的方式进行进行调整。
# 这一步完成的是位置编码
# -----------------------------------------------------------------------------
# # PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
# # PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
def get_position_embedding(sentence_length, d_model):# sentense_length就是句子的长度num-step d_model就是embedding_dim# 首先我们知道位置编码生成之后需要和外面的embedding后的数据进行相加 形成带有位置信息的数据# 而外面的embedding的data的形状是(batch-size,num-step,embedding-dim)# 所以相对应的生成就可以得到# 先根据公式来写 pos就是对应的哪一个字 i对应的就是第几个embedding-dim dmodel就是embedding-dim# pos先不考虑batch-size那一维度,先扩展维度,从(num-step)变成(num-step,1)pos = np.arange(sentence_length).reshape(-1,1)i = np.arange(d_model).reshape(1,-1)x = pos / np.power(10000,(2 * (i // 2)) / np.float32(d_model))# 利用切片得到相对应的sin 和 cossinx = np.sin(x[:, 0::2])cosx = np.cos(x[:, 1::2])# 凑成sin cos sin cos 的格式position_embedding = np.zeros((sentence_length,d_model))position_embedding[:, 0::2] = sinxposition_embedding[:, 1::2] = cosx# 最后就是维度扩展,方便后续的相加position_embedding = position_embedding.reshape(1,sentence_length,d_model)return tf.cast(position_embedding, dtype=tf.float32)position_embedding = get_position_embedding(5, 4)
print(position_embedding.shape)
print(position_embedding)
# -----------------------------------------------------------------------------
当然也可以封装到一个类当中,这边你们可以自己去实现一下
然后关于评价一下这个位置编码,我们这边使用绘制热力图进行展示:
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline# 评估位置编码
# -----------------------------------------------------------------------------
position_embedding = get_position_embedding(50, 256)
print(position_embedding.shape)
print(position_embedding)
def plot_position_embedding(position_embedding):plt.pcolormesh(position_embedding[0], cmap = 'RdBu')plt.xlabel('Depth')plt.xlim((0, 256))plt.ylabel('Position')plt.colorbar()plt.show()
# -----------------------------------------------------------------------------
plot_position_embedding(position_embedding)
输出:
(1, 50, 256)
图片1
图片1:
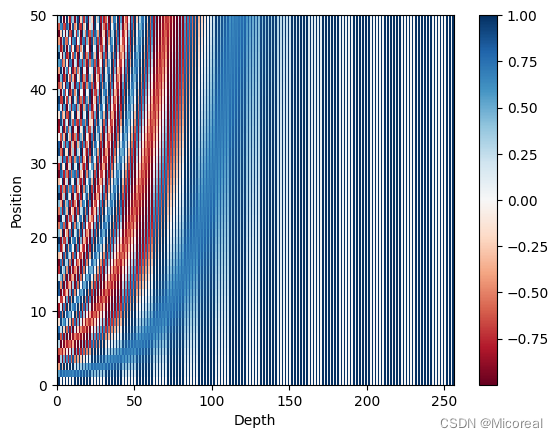
我们可以发现对于每一个字来说他的对应的值都是不一样的,这就很有效,不过对于sin cos 这种方式的实现来说,我们取的embedding的大小还会导致位置编码是否有效,这需要作为参数方程进行查看。
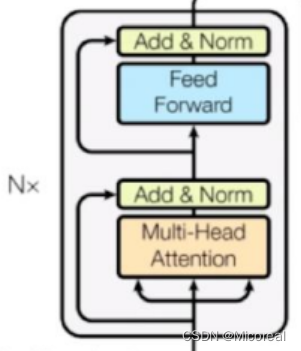
Encoder block
原理图:
multi-head attention
首先需要实现就是这个多头注意力机制,multi-head attention:
先看一下self-attention的数学实现方式:
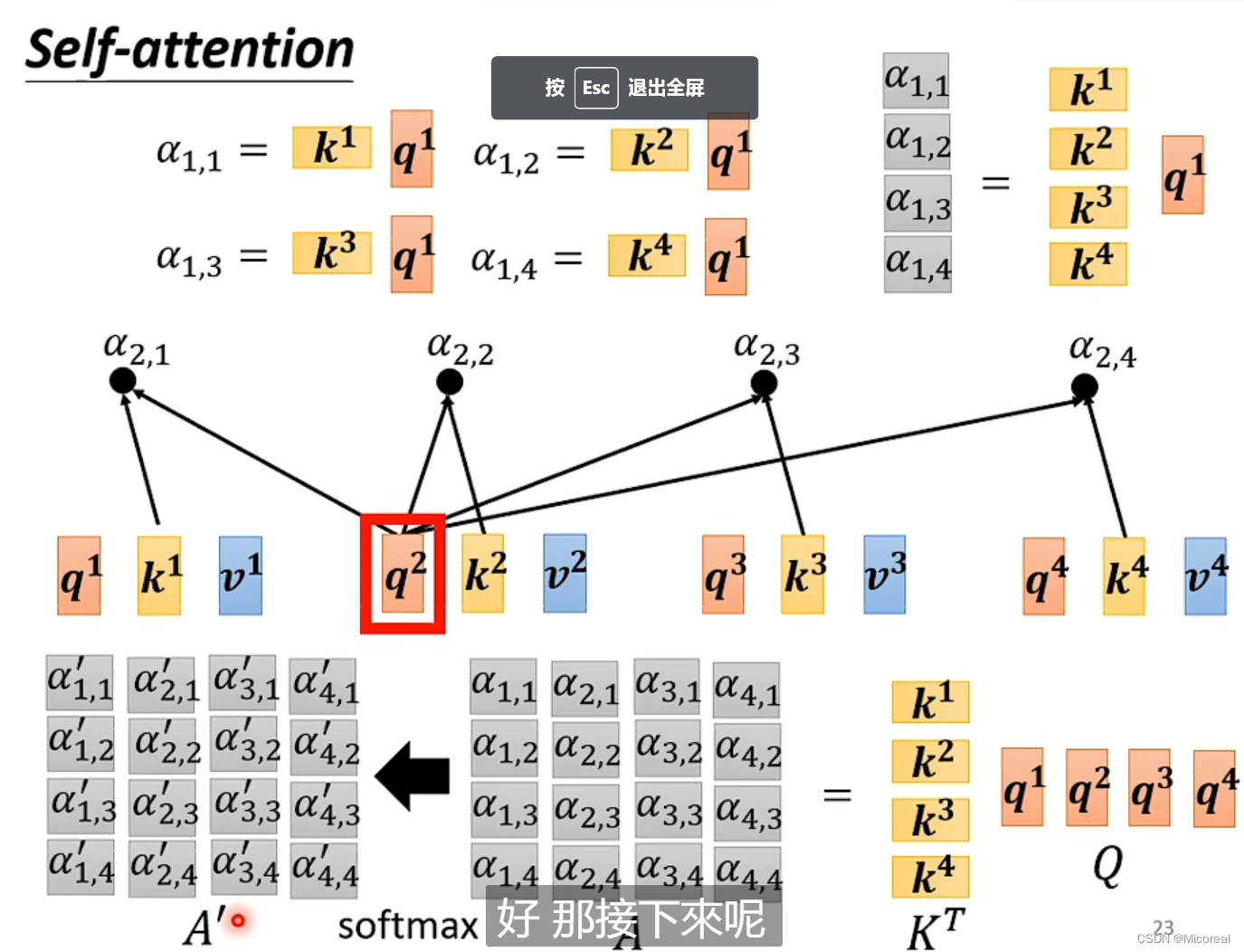
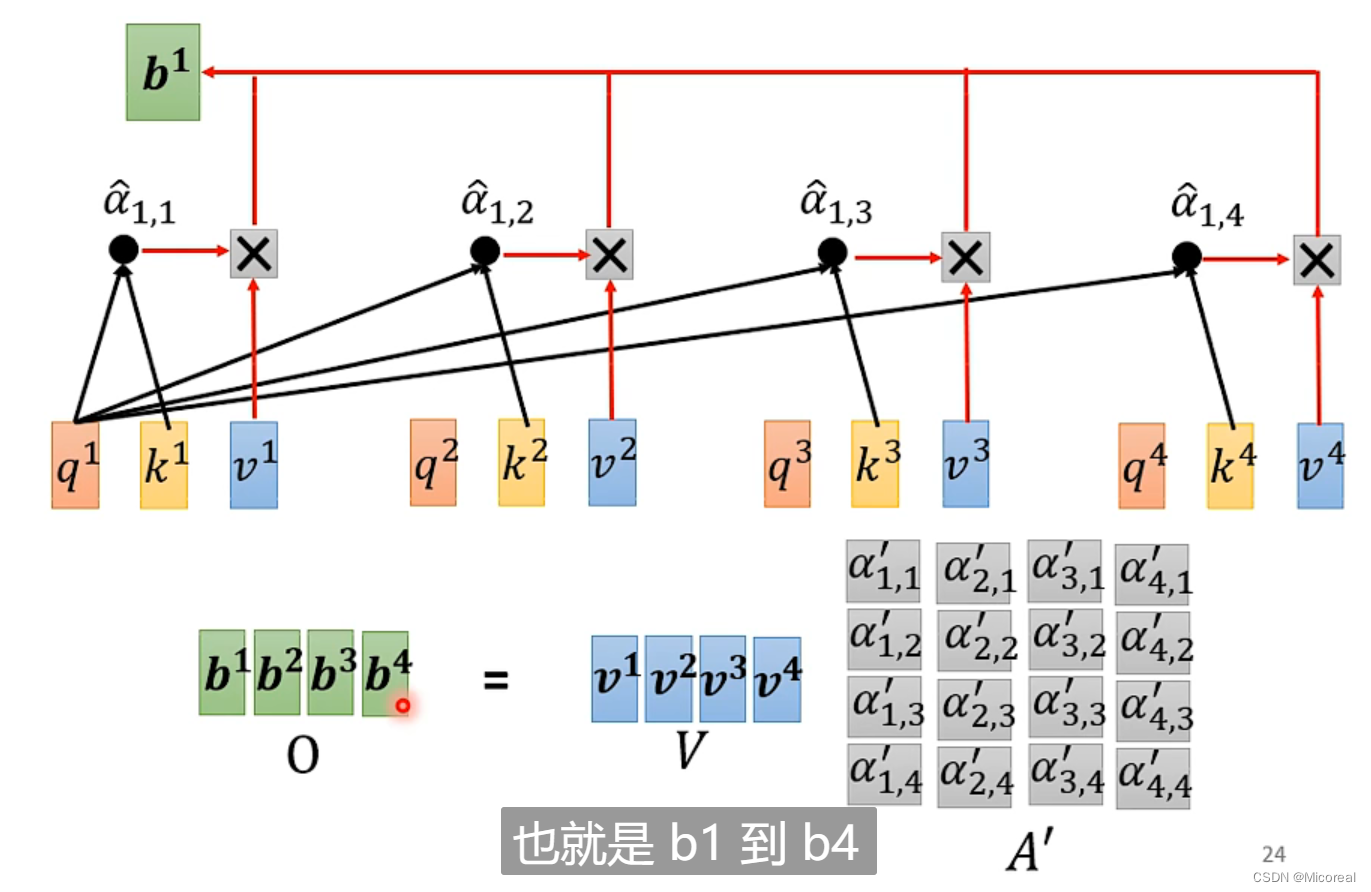
总结:
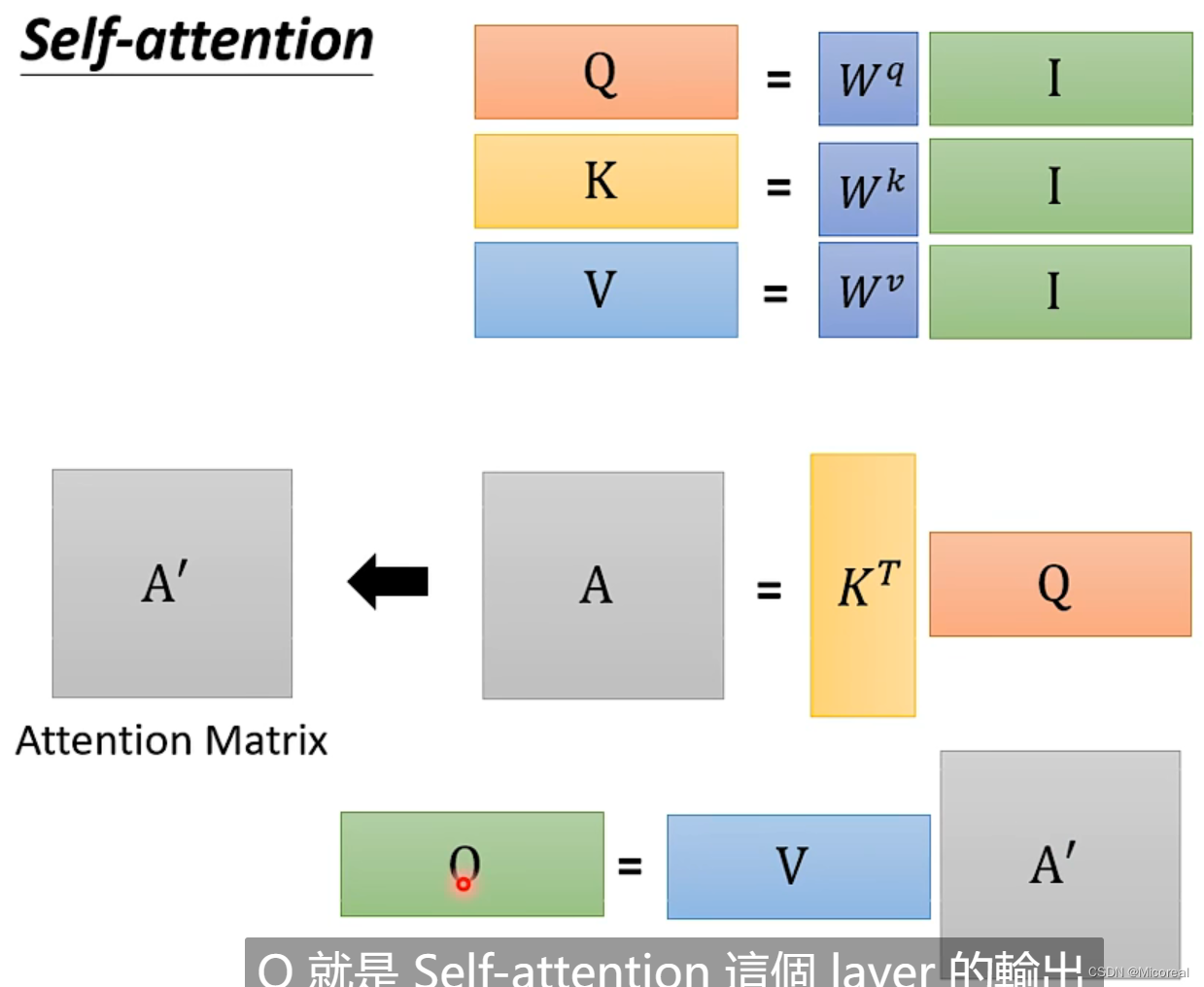
而关于多头就是实现几次的样式:
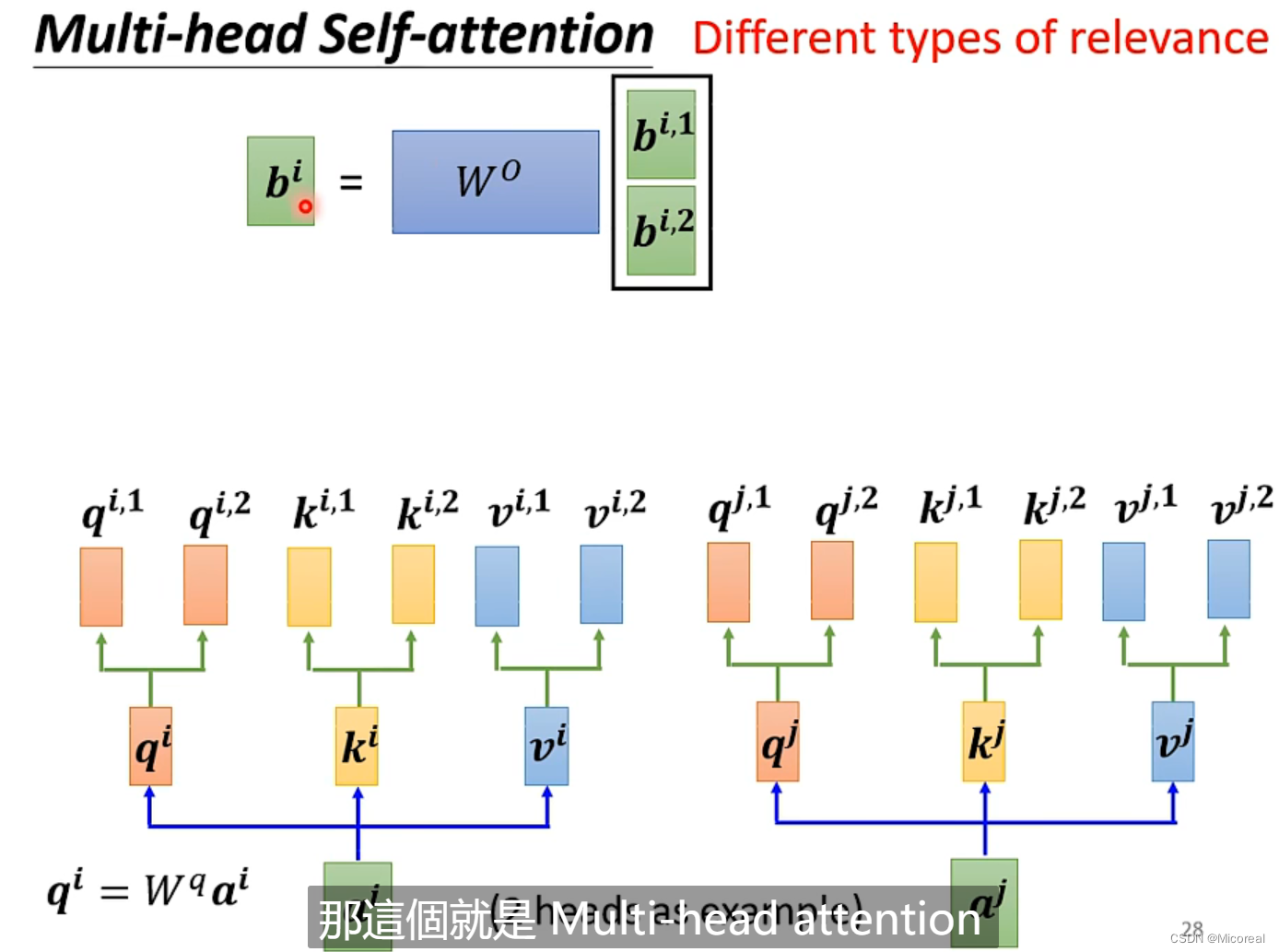
这边的原理讲解有点复杂,之后会另开专栏进行讲解,这边理解数学即可,只需要理解我们这边的注意力机制计算的是我们的输入的词语与词语之间的关系。
# 多头注意力的实现
# -----------------------------------------------------------------------------
# 定义多头注意力机制
class MultiHeadAttention(keras.layers.Layer):def __init__(self,d_model,num_heads):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.WQ = keras.layers.Dense(self.d_model)self.WK = keras.layers.Dense(self.d_model)self.WV = keras.layers.Dense(self.d_model)self.dense = keras.layers.Dense(self.d_model)# 这边下面就需要进行分头计算 为了让头变多的同时 计算代价和参数代价不会随之增长,这边采用除法的操作assert self.d_model % self.num_heads == 0self.depth = self.d_model // self.num_headsdef call(self,q,k,v,mask):# 输入的input实际上是embedding之后加上位置编码之后的数据,形状就是(batch-size,step-nums,embedding-dim)# 首先就是先生成q,k,vq = self.WQ(q)k = self.WK(k)v = self.WV(v)# 这边进行分头 然后已知qkv的形状是(batch-size,step-nums,d_model)# 然后将其形状都变成(batch-size,nums-head,step-nums,depth),也就是由于batch-size和step-num都有其含义,这边我们不能进行拆解,所以就把d_model拆解成一个代表第几个头 一个代表的就是参数# 而为什么需要拆解成(batch-size,nums-head,step-nums,depth) 而不是(batch-size,step-nums,nums-head,depth)# 原因就是我们后面的计算明显是要用相同的nums-head的情况下去运算,这样子方便# 还有这边需要使用轴滚动 不能直接使用reshape直接进行调换形状 二者的原理不一样q = tf.reshape(q,(tf.shape(q)[0],-1,self.num_heads,self.depth))q = tf.transpose(q,[0,2,1,3])k = tf.reshape(k, (tf.shape(k)[0], -1, self.num_heads, self.depth))k = tf.transpose(k, [0, 2, 1, 3])v = tf.reshape(v, (tf.shape(q)[0], -1, self.num_heads, self.depth))v = tf.transpose(v, [0, 2, 1, 3])# 开始计算缩放点积运算 此时q k 的形状(batch-size,nums-head,step-nums,depth)# 计算得到的Matrix_kq形状就是(batch-size,nums-head,step-nums,step-nums)Matrix_kq = tf.matmul(q,k,adjoint_b=True)if mask is not None:# 带有mask多头的注意力机制 后面再来解析Matrix_kq += (mask * (-1e9))# 然后这边两个数据相乘之后,数据太大了,这边可以做一个softmax 你用relu也可以# 不过需要注意的是,我们需要对于行做softmax,取决于我们对于k的理解Matrix_kq = tf.nn.softmax(Matrix_kq,axis=-1)output = tf.transpose(tf.matmul(Matrix_kq, v),[0,2,1,3])# 再对于注意力机制进行合并 生成的数据就是(batch-size,nums-step,d_model)的数据output = tf.reshape(output,(tf.shape(output)[0],-1,self.d_model))return output
# -----------------------------------------------------------------------------
Feed Forward
前馈网络:实际上就是两层全连接层,这边就只给出代码了
# 前馈网络
# -----------------------------------------------------------------------------
class FeedForward(keras.layers.Layer):def __init__(self,d_model, dim):super().__init__()self.dense1 = keras.layers.Dense(dim,activation='relu')self.dense2 = keras.layers.Dense(d_model)def call(self,x):return self.dense2(self.dense1(x))
# -----------------------------------------------------------------------------
自定义encoder block
# 自定义encoder block
# -----------------------------------------------------------------------------
class EncoderBlock(keras.layers.Layer):def __init__(self,d_model, num_heads, feed_dim, rate=0.1):super().__init__()self.attention = MultiHeadAttention(d_model,num_heads)self.feed = FeedForward(d_model, feed_dim)# 做的是layer的标准化和之前采用的batch标准化不一样,batch针对的是不同特征的,layer针对的是相同特征的self.layer_norm1 = keras.layers.LayerNormalization(epsilon=1e-6)self.layer_norm2 = keras.layers.LayerNormalization(epsilon=1e-6)# 下面两个层次用了做dropout,每次有10%的几率被drop掉self.dropout1 = keras.layers.Dropout(rate)self.dropout2 = keras.layers.Dropout(rate)def call(self,x,training,encoding_padding_mask):# x代表的就是训练的数据# training代表的是是否对于train状态下进行dropout,填入的是true or false# encoding_padding_mask代表的是将padding标识为不重要,避免注意力机制去关心那一块out1 = self.attention(x,x,x, encoding_padding_mask)out1 = self.dropout1(out1, training=training)# Resnet相加 很重要x = self.layer_norm1(x+out1)out2 = self.feed(x)out2 = self.dropout2(out2, training=training)output = self.layer_norm2(x+out2)return output
# -----------------------------------------------------------------------------
#来测试,结果和我们最初的输入维度一致,相当于做了两次残差连接
sample_encoder_layer = EncoderBlock(512, 8, 2048)
sample_input = tf.random.uniform((64, 50, 512))
sample_output = sample_encoder_layer(sample_input, False, None)
print(sample_output.shape)
Deconder block
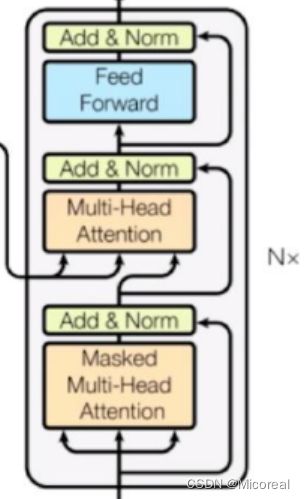
代码见下:
# 自定义decoder block
# -----------------------------------------------------------------------------
class DecoderBlock(keras.layers.Layer):def __init__(self,d_model, num_heads, feed_dim, rate = 0.1):super().__init__()self.attention1 = MultiHeadAttention(d_model, num_heads)self.attention2 = MultiHeadAttention(d_model, num_heads)self.feed = FeedForward(d_model, feed_dim)self.layer_norm1 = keras.layers.LayerNormalization(epsilon=1e-6)self.layer_norm2 = keras.layers.LayerNormalization(epsilon=1e-6)self.layer_norm3 = keras.layers.LayerNormalization(epsilon=1e-6)self.dropout1 = keras.layers.Dropout(rate)self.dropout2 = keras.layers.Dropout(rate)self.dropout3 = keras.layers.Dropout(rate)def call(self, x, encoding_outputs, training, decoder_mask, encoder_decoder_padding_mask):# x就是下面传来的东西 encoding_outputs 就是encoding的输出 training同上# decoder_mask 就是遮住前面看过的东西和遮住padding的mask# encoder_decoder_padding_mask这个就是对应的maskout1 = self.attention1(x,x,x,decoder_mask)out1 = self.dropout1(out1,training=training)x = self.layer_norm1(x+out1)out2 = self.attention2(encoding_outputs,encoding_outputs,x, encoder_decoder_padding_mask)out2 = self.dropout2(out2, training=training)x = self.layer_norm2(x+out2)out3 = self.feed(x)out3 = self.dropout3(out3,training=training)output = self.layer_norm3(x+out3)return output
# -----------------------------------------------------------------------------# 测试一下
sample_decoder_layer = DecoderBlock(512, 8, 2048)
sample_decoder_input = tf.random.uniform((64, 50, 512))
sample_decoder_output= sample_decoder_layer(sample_decoder_input, sample_output, False, None, None)
print(sample_decoder_output.shape)
Encoder
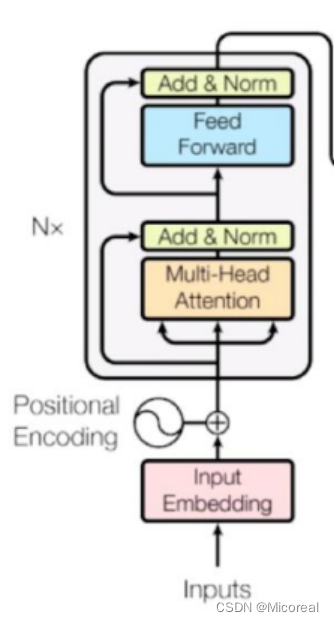
样例代码:
# 定义Encoder
# -----------------------------------------------------------------------------
class Encoder(keras.layers.Layer):def __init__(self,num_layers, input_vocab_size, max_length,d_model, num_heads, feed_dim, rate=0.1):super().__init__()self.d_model = d_modelself.num_layers = num_layersself.max_length = max_lengthself.embedding = keras.layers.Embedding(input_vocab_size,self.d_model)self.position_embedding = get_position_embedding(max_length,self.d_model)self.dropout = keras.layers.Dropout(rate)self.encoder_blocks = [EncoderBlock(self.d_model,num_heads,feed_dim,rate) for _ in range(self.num_layers)]def call(self, x, training, encoder_padding_mask):# 一开始输入进去x的形状是(batch-size,num-step)embedding_x = self.embedding(x)# 因为位置编码值在-1和1之间,因此嵌入值乘以嵌入维度的平方根进行缩放,然后再与位置编码相加。embedding_x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))# 因为x长度比position_embedding可能要小,因此embedding切片后和x相加posotion_and_embedding_x = embedding_x + self.position_embedding[:, :tf.shape(x)[1], :]posotion_and_embedding_x = self.dropout(posotion_and_embedding_x, training=training)# 得到的x不断作为下一层的输入for i in range(self.num_layers):posotion_and_embedding_x = self.encoder_blocks[i](posotion_and_embedding_x, training, encoder_padding_mask)# x最终shape如下# x.shape: (batch_size, input_seq_len, d_model)return posotion_and_embedding_x
# -----------------------------------------------------------------------------
# 测试
sample_encoder_model = Encoder(2,8500,50,512, 8, 2048)
sample_encoder_model_input = tf.random.uniform((64, 37))
sample_encoder_model_output = sample_encoder_model(sample_encoder_model_input, False, encoder_padding_mask = None)
print(sample_encoder_model_output.shape)
Decoder

样例代码:
# 定义Decoder
# -----------------------------------------------------------------------------
class Decoder(keras.layers.Layer):def __init__(self, num_layers, target_vocab_size, max_length,d_model, num_heads, feed_dim, rate=0.1):super().__init__()self.d_model = d_modelself.num_layers = num_layersself.max_length = max_lengthself.embedding = keras.layers.Embedding(target_vocab_size, self.d_model)self.position_embedding = get_position_embedding(max_length, self.d_model)self.dropout = keras.layers.Dropout(rate)self.decoder_blocks = [DecoderBlock(self.d_model, num_heads, feed_dim, rate) for _ in range(self.num_layers)]def call(self, x, encoding_outputs, training,decoder_mask, encoder_decoder_padding_mask):embedding_x = self.embedding(x)embedding_x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))posotion_and_embedding_x = embedding_x + self.position_embedding[:, :tf.shape(x)[1], :]posotion_and_embedding_x = self.dropout(posotion_and_embedding_x, training=training)for i in range(self.num_layers):posotion_and_embedding_x= self.decoder_blocks[i](posotion_and_embedding_x, encoding_outputs, training,decoder_mask, encoder_decoder_padding_mask)return posotion_and_embedding_x# -----------------------------------------------------------------------------
# 测试
sample_decoder_model = Decoder(2, 8000,50,512, 8, 2048)
sample_decoder_model_input = tf.random.uniform((64, 37))
sample_decoder_model_output= sample_decoder_model(sample_decoder_model_input,sample_encoder_model_output,training = False, decoder_mask = None,encoder_decoder_padding_mask = None)print(sample_decoder_model_output.shape)
transformer

样例代码:
# 定义transformer
# -----------------------------------------------------------------------------
class Transformer(keras.Model):def __init__(self,num_layers, input_vocab_size, target_vocab_size,max_length, d_model, num_heads, feed_dim, rate=0.1):super().__init__()self.encoder = Encoder(num_layers,input_vocab_size,max_length,d_model,num_heads,feed_dim,rate)self.decoder = Decoder(num_layers,target_vocab_size,max_length,d_model,num_heads,feed_dim,rate)self.final_layer = keras.layers.Dense(target_vocab_size)def call(self, input, target, training, encoder_padding_mask,decoder_mask, encoder_decoder_padding_mask):encoder_output = self.encoder(input,training,encoder_padding_mask)decoder_output = self.decoder(target,encoder_output,training,decoder_mask,encoder_decoder_padding_mask)predict = self.final_layer(decoder_output)return predict# -----------------------------------------------------------------------------
# 测试
sample_transformer = Transformer(2, 8500, 8000, 50,512, 8, 2048, rate = 0.1)
temp_input = tf.random.uniform((64, 26))
temp_target = tf.random.uniform((64, 26))# 得到输出
predictions = sample_transformer(temp_input, temp_target, training = False,encoder_padding_mask = None,decoder_mask = None,encoder_decoder_padding_mask = None)
# 输出shape
print(predictions.shape)
自定义loss 和 学习率
# 自定义的学习率调整设计实现
# -----------------------------------------------------------------------------
class CustomizedSchedule(keras.optimizers.schedules.LearningRateSchedule):def __init__(self, d_model, warmup_steps=4000):super().__init__()self.d_model = tf.cast(d_model, tf.float32)self.warmup_steps = warmup_stepsdef __call__(self, step):step = tf.cast(step,tf.float32)arg1 = tf.math.rsqrt(step)arg2 = step * (self.warmup_steps ** (-1.5))arg3 = tf.math.rsqrt(self.d_model)return arg3 * tf.math.minimum(arg1, arg2)learning_rate = CustomizedSchedule(d_model)
optimizer = keras.optimizers.Adam(learning_rate,beta_1=0.9,beta_2=0.98,epsilon=1e-9)loss_object = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')
def loss_function(real, pred):# 损失做了掩码处理,是padding的地方不计算损失mask = tf.math.logical_not(tf.math.equal(real, 0))loss_ = loss_object(real, pred)mask = tf.cast(mask, dtype=loss_.dtype)loss_ *= maskreturn tf.reduce_mean(loss_)
# -----------------------------------------------------------------------------
mask生成函数
def create_mask(input,target):encoder_padding_mask = tf.cast(tf.math.equal(input, 0), tf.float32)[:, tf.newaxis, tf.newaxis, :]encoder_decoder_padding_mask = encoder_padding_mask# 创建下三角型look_ahead_mask = (1 - tf.linalg.band_part(tf.ones((tf.shape(target)[1], tf.shape(target)[1])), -1, 0))decoder_padding_mask = tf.cast(tf.math.equal(target, 0), tf.float32)[:, tf.newaxis, tf.newaxis, :]decoder_mask = tf.maximum(look_ahead_mask, decoder_padding_mask)return encoder_padding_mask, decoder_mask, encoder_decoder_padding_mask
训练
# 训练
# -----------------------------------------------------------------------------
train_loss = keras.metrics.Mean(name = 'train_loss')
train_accuracy = keras.metrics.SparseCategoricalAccuracy(name = 'train_accuracy')
@tf.function
def train_step(input, target):tar_inp = target[:, :-1] # 没带endtar_real = target[:, 1:] # 没有startencoder_padding_mask, decoder_mask, encoder_decoder_padding_mask = create_mask(input, tar_inp)with tf.GradientTape() as tape:predictions = transformer(input, tar_inp, True,encoder_padding_mask,decoder_mask,encoder_decoder_padding_mask)loss = loss_function(tar_real, predictions)gradients = tape.gradient(loss, transformer.trainable_variables)optimizer.apply_gradients(zip(gradients, transformer.trainable_variables))train_loss(loss)train_accuracy(tar_real, predictions)epochs = 200
for epoch in range(epochs):start = time.time()# reset后就会从零开始累计train_loss.reset_states()train_accuracy.reset_states()for (batch, (input, target)) in enumerate(dataset.take(batch_size)):train_step(input, target)if batch % 100 == 0:print('Epoch {} Batch {} Loss {:.4f} Accuracy {:.4f}'.format(epoch + 1, batch, train_loss.result(),train_accuracy.result()))print('Epoch {} Loss {:.4f} Accuracy {:.4f}'.format(epoch + 1, train_loss.result(), train_accuracy.result()))print('Time take for 1 epoch: {} secs\n'.format(time.time() - start))# loss是一个正常的指标,accuracy只是机器翻译的一个参考指标,可以看趋势
# -----------------------------------------------------------------------------
翻译
# 预测
# -----------------------------------------------------------------------------
def translate(inp_sentence):# 对输入的语言做和训练时同样的预处理后,再进行word转idsentence = preprocess_sentence(inp_sentence)# text到id的转换inputs = [input_tokenizer.word_index[i] for i in sentence.split(' ')]# 加paddinginputs = keras.preprocessing.sequence.pad_sequences([inputs], maxlen=50, padding='post')# 转换为tf张量encoder_input = tf.convert_to_tensor(inputs)decoder_input = tf.expand_dims([target_tokenizer.word_index['<start>']], 1)result = ''for i in range(max_length):# 产生mask并传给transformerencoder_padding_mask, decoder_mask, encoder_decoder_padding_mask = create_mask(encoder_input, decoder_input)predictions= transformer(encoder_input,decoder_input,False,encoder_padding_mask,decoder_mask,encoder_decoder_padding_mask)# print('-'*20)# print(predictions)# 预测值就是概率最大的那个的索引,那最后一个维度中最大的那个值predicted_id = tf.argmax(predictions[0][0]).numpy()result += target_tokenizer.index_word[predicted_id] + ' '# 如果等于end id,预测结束if target_tokenizer.index_word[predicted_id] == '<end>':break# 如果predicted_id不是end id,添加到新的decoder_input中decoder_input = tf.expand_dims([predicted_id], 1)print('Input: %s' % (sentence))print('Predicted translation: {}'.format(result))translate(u'happy')
# -----------------------------------------------------------------------------
相关文章:
45 深度学习(九):transformer
文章目录 transformer原理代码的基础准备位置编码Encoder blockmulti-head attentionFeed Forward自定义encoder block Deconder blockEncoderDecodertransformer自定义loss 和 学习率mask生成函数训练翻译 transformer 这边讲一下这几年如日中天的新的seq2seq模式的transform…...

java中用javax.servlet.ServletInputStream.readLine有什么安全问题吗?怎么解决实例?
使用 javax.servlet.ServletInputStream.readLine 方法在处理 Servlet 请求时可能存在以下安全问题,以及相应的解决方案: 缓冲区溢出:readLine 方法会将数据读取到一个缓冲区中,并根据换行符分隔成行。如果输入流中包含过长的行或…...
面试官问 Spring AOP 中两种代理模式的区别?很多面试者被问懵了
面试官问 Spring AOP 中两种代理模式的区别?很多初学者栽了跟头,快来一起学习吧! 代理模式是一种结构性设计模式。为对象提供一个替身,以控制对这个对象的访问。即通过代理对象访问目标对象,并允许在将请求提交给对象前后进行一…...
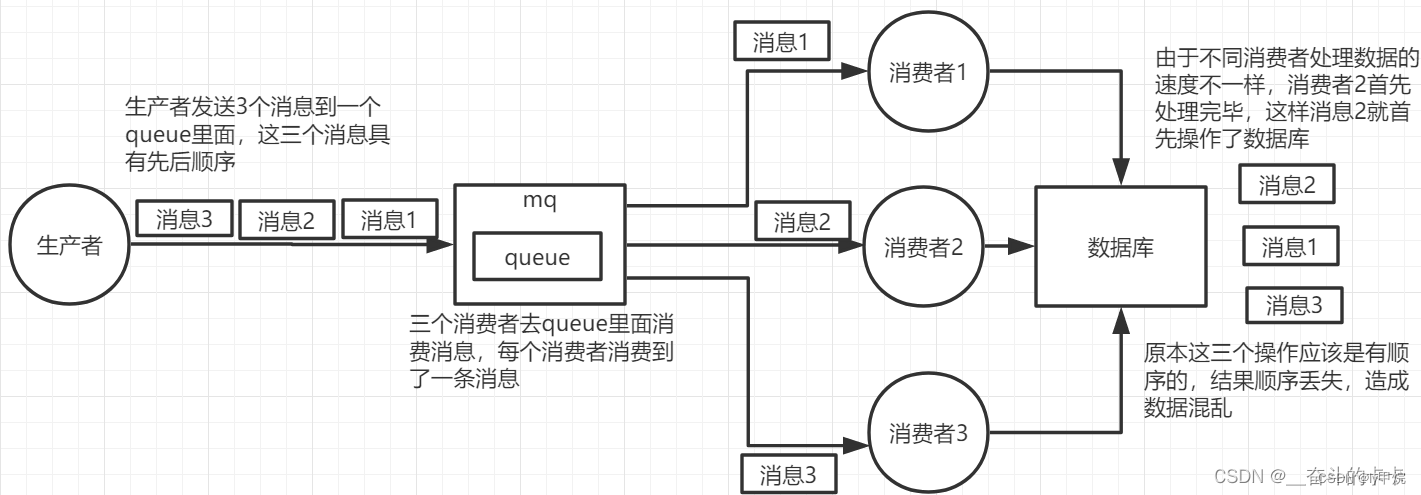
MQ四大消费问题一锅端:消息不丢失 + 消息积压 + 重复消费 + 消费顺序性
RabbitMQ-如何保证消息不丢失 生产者把消息发送到 RabbitMQ Server 的过程中丢失 从生产者发送消息的角度来说,RabbitMQ 提供了一个 Confirm(消息确认)机制,生产者发送消息到 Server 端以后,如果消息处理成功ÿ…...

Python爬虫——入门爬取网页数据
目录 前言 一、Python爬虫入门 二、使用代理IP 三、反爬虫技术 1. 间隔时间 2. 随机UA 3. 使用Cookies 四、总结 前言 本文介绍Python爬虫入门教程,主要讲解如何使用Python爬取网页数据,包括基本的网页数据抓取、使用代理IP和反爬虫技术。 一、…...
爬虫,TLS指纹 剖析和绕过
当你欲爬取某网页的信息数据时,发现通过浏览器可正常访问,而通过代码请求失败,换了随机ua头IP等等都没什么用时,有可能识别了你的TLS指纹做了验证。 解决办法: 1、修改 源代码 2、使用第三方库 curl-cffi from curl…...

Linux shell编程学习笔记25:tty
1 tty的由来 在 1830 年代和 1840 年代,开发了称为电传打字机(teletypewriters)的机器,这些机器可以将发件人在键盘上输入的消息“沿着线路”发送在接收端并打印在纸上。 电传打字机的名称由teletypewriters, 缩短为…...
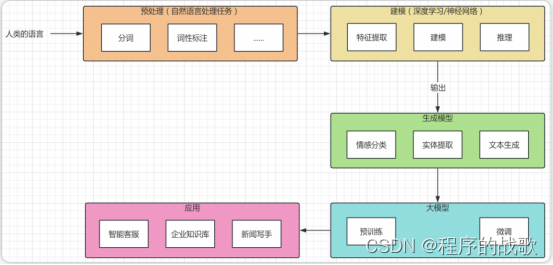
AIGC大模型-初探
大语⾔模型技术链 1. ⾃然语⾔处理 2. 神经⽹络 3. ⾃注意⼒机制 4. Transformer 架构 5. 具体模型 - GPT6. 预训练,微调 7. ⼤模型应⽤ - LangChain 大语⾔模型有什么用? 利⽤⼤语⾔模型帮助我们理解⼈类的命令,从⽽处理⽂本分析…...
Postman for Mac(HTTP请求发送调试工具)v10.18.10官方版
Postman for mac是一个提供在MAC设备上功能强大的开发,监控和测试API的绝佳工具。非常适合开发人员去使用。此版本通过Interceptor添加了对请求捕获的支持,修正了使用上下文菜单操作未复制响应正文的问题和预请求脚本的垂直滚动条与自动完成下拉列表重叠…...

SpringBoot 项目优雅实现读写分离 | 京东云技术团队
一、读写分离介绍 当使用Spring Boot开发数据库应用时,读写分离是一种常见的优化策略。读写分离将读操作和写操作分别分配给不同的数据库实例,以提高系统的吞吐量和性能。 读写分离实现主要是通过动态数据源功能实现的,动态数据源是一种通过…...
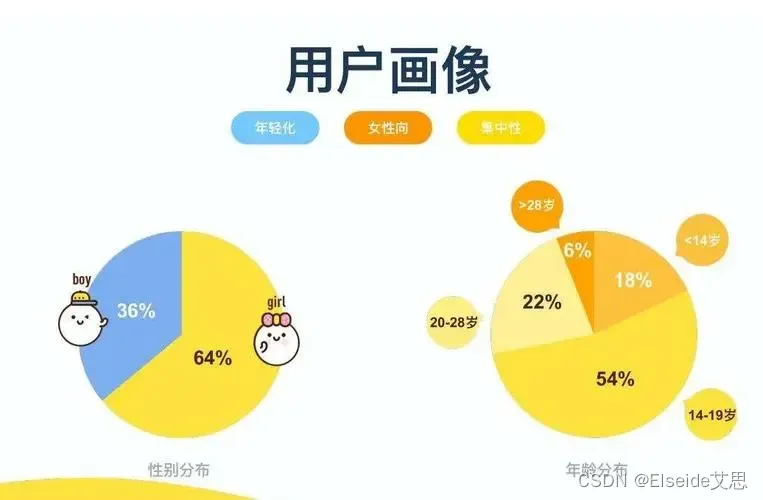
企业如何利用好用户画像对客户进行精准营销?提高营销转化?
随着市场竞争的加剧,企业对于客户的需求和行为越来越关注,如何利用好用户画像对客户进行精准营销,提高营销转化,成为企业关注的焦点。 一、了解用户需求和行为 首先,企业需要了解客户的需求和行为,包括客户…...

acwing算法基础之搜索与图论--匈牙利算法求二分图的最大匹配数
目录 1 基础知识2 模板3 工程化 1 基础知识 二分图中的最大匹配数:从二分图中选择一些边(这些边连接集合A和集合B,集合A中结点数目为n1,集合B中结点数目为n2),设为集合S,其中任意两条边不共用一…...

优化重复冗余代码的8种方式
文章目录 前言1、抽取公用方法2、抽工具类3、反射4、泛型5、继承与多态6、使用设计模式7、自定义注解(或者说AOP面向切面)8、函数式接口和Lambda表达式 前言 日常开发中,我们经常会遇到一些重复代码。大家都知道重复代码不好,它主要有这些缺点ÿ…...
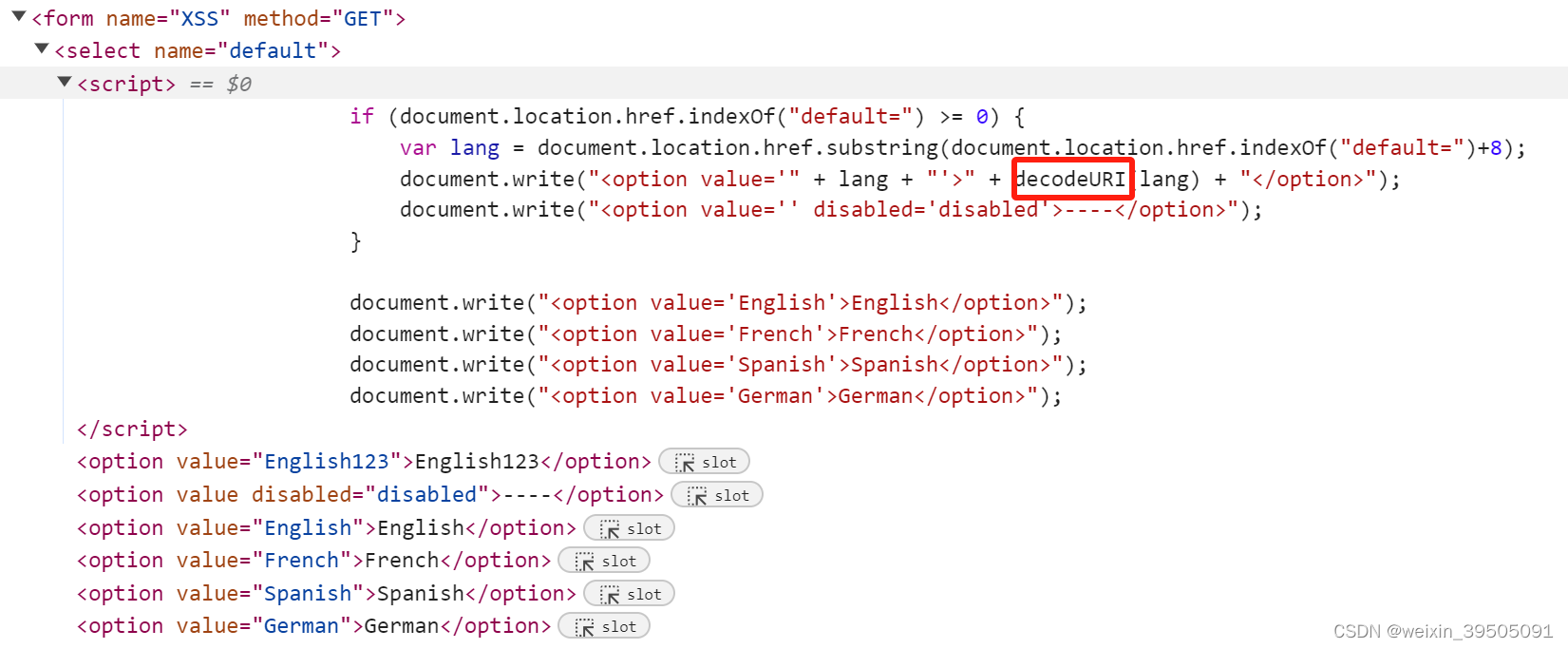
DVWA - 3
文章目录 XSS(Dom)lowmediumhighimpossible XSS(Dom) XSS 主要基于JavaScript语言进行恶意攻击,常用于窃取 cookie,越权操作,传播病毒等。DOM全称为Document Object Model,即文档对…...

android studio离线tips
由于种种原因(你懂的,导致我们使用android studio会有很多坑,这里记录一下遇到的问题以及解决方案 环境问题 无法下载gradle 因为android studio采用gradle作为构建工具,国内gradle没有镜像下载非常慢,并且大概率失…...
)
JWT概念(登录代码实现)
JWT (JSON Web Token)是一种开放标准,用于在网络应用程序之间安全地传输信息。JWT是一种基于JSON的轻量级令牌,包含了一些声明和签名,可以用于认证和授权。 JWT主要由三部分组成:头部、载荷和签名。 头部包含了使用的算法和类型…...
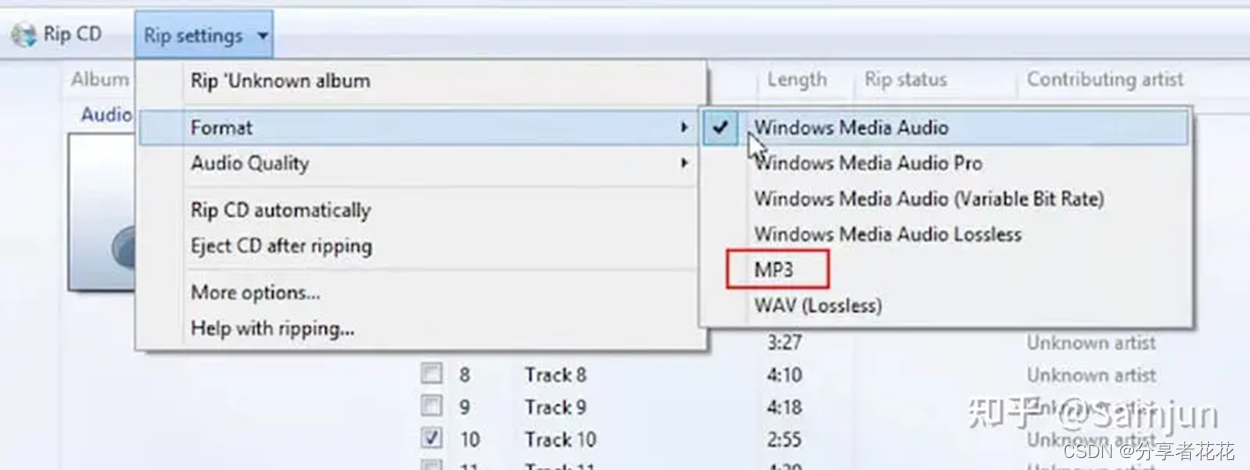
如何在 Windows 10/11 上高质量地将 WAV 转换为 MP3
WAV 几乎完全准确地存储了录音硬件所听到的内容,这使得它变得很大并占用了更多的存储空间。因此,WAV 格式在作为电子邮件附件发送、保存在便携式音频播放器上、通过蓝牙或互联网从一台设备传输到另一台设备等时可能无法正常工作。 如果您遇到 WAV 问题&…...
)
详解FreeRTOS:FreeRTOS消息队列(高级篇—1)
目录 1、队列简介 2、队列的运行机制 3、队列的阻塞机制 4、队列结构体 5、创建队列...

Vue3 + ts+ elementUi 实现后台数据渲染到下拉框选项中,滑动加载更多数据效果
前言 功能需求:下拉框中分页加载后端接口返回的人员数据,实现滑动加载更多数据效果,并且可以手动搜索定位数据,此项目使用Vue3 ts elementUi 实现 实现 把此分页滑动加载数据功能封装成vue中的hooks,文件命名为use…...

Elasticsearch 索引库操作与 Rest API 使用详解
1. 引入 Elasticsearch 依赖 在开始之前,确保你的 Maven 或 Gradle 项目中已经引入了 Elasticsearch 的 Java 客户端库。你可以使用以下 Maven 依赖: xml <dependency> <groupId>org.elasticsearch.client</groupId> <ar…...

tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南
tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南 【免费下载链接】tools Assorted useful tools, almost entirely generated using LLMs 项目地址: https://gitcode.com/gh_mirrors/tools23/tools tools.simonwillison.net图像处理工具集是一…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

免费抓包工具选型指南:Wireshark、Fiddler、mitmproxy、Charles实战对比
1. 抓包工具不是“黑科技”,而是网络世界的显微镜很多人第一次听说“抓包”,脑子里立刻浮现出黑客电影里满屏滚动的绿色代码、键盘敲得噼啪作响、三秒破解银行防火墙的画面。其实完全不是这样——抓包(Packet Capture)本质上就是把…...

render_async嵌套渲染:构建复杂异步界面的完整解决方案
render_async嵌套渲染:构建复杂异步界面的完整解决方案 【免费下载链接】render_async render_async lets you include pages asynchronously with AJAX 项目地址: https://gitcode.com/gh_mirrors/re/render_async 在现代Web开发中,页面加载速度…...

如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍
如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器加载缓慢、操作卡顿而烦恼吗?HiveWE作为一款专注于速…...

C语言有符号和无符号在内存中的存储方式区别小结
在 C 语言中,有符号类型(如 signed char、signed int)和无符号类型(如 unsigned char、unsigned int)在内存中的存储方式本质上没有区别——它们都是以二进制位的形式存储数值的。两者的核心差异体现在对二进制位的解…...

如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练
如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练 【免费下载链接】SoundMind We introduce the Audio Logical Reasoning (ALR) dataset, consisting of 6,446 text-audio annotated samples specifically designed for complex reasoning tasks. Building o…...