时间序列基础->数据标签、数据分割器、数据加载器的定义和讲解(零基础入门时间序列)

一、本文介绍
各位小伙伴好,最近在发时间序列的实战案例中总是有一些朋友问我时间序列中的部分对数据的操作是什么含义,我进行了挺多的介绍和讲解但是问的人越来越多,所以今天在这里单独发一篇文章来单独的讲一下时间序列中对数据的处理操作和如何定义时间序列特有的数据加载器和对数据打上标签的操作。(发现最近研究时间序列的人越来越多基本上都是为了发论文,感叹大家的论文压力都好大)
适用对象->本文适合那些零基础的时间序列的学习者
目录
一、本文介绍
二、 时间序列中的标签
三、时间序列中的窗口分割器
四、时间序列的数据加载器
五、测试流程代码
五、总结
二、 时间序列中的标签
在开始讲解具体的操作含义之前,我们需要明白一个问题,时间序列中的标签是什么?如果你了解过图像领域,那么你应该知道在目标检测领域的数据集中的图像会有一个标签(标记一个物体是猫还是狗或者是其它的物体),那么我们时间序列的领域标签是什么呢?咱们预测的时候,大家都会选择预测未来多少条数据,假设我们16条数据,选择其中的6条数据为窗口大小来预测未来的2条数据,那么我们的标签就是这2条数据(假设我们的特征数1即你是单元预测,那么我们这16条数据会送入到模型内部进行训练,模型会输出2条数据,输出的2条数据会和我们的标签求一个损失用于反向传播)
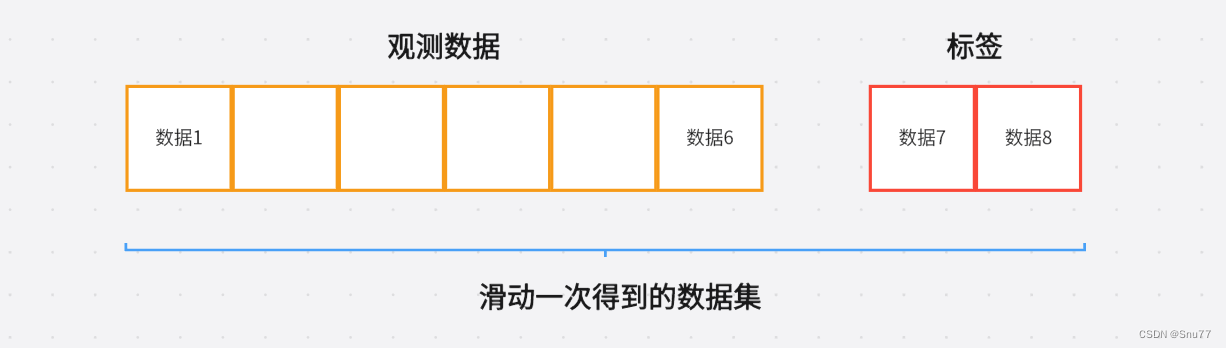
三、时间序列中的窗口分割器
在时间序列中特有的就是窗口分割器,利用一个滑动的窗口(类似于卷积操作)沿着数据的方向进行滑动从而产生用于训练时间序列的数据和标签。大家看上面的图片,我们的蓝色和粉色就是滑动的窗口,一个用于滑动训练数据一个用于滑动标签,最后滑动到数据的结尾。我们可以计算我们能够得到的训练数据的多少,其中数据为16条滑动窗口为6标签为2那么我们最后能够得到的训练加载器中的数据大小就为16 - ( 6 + 2 - 1) = 9,所以最后我们就能得到9个数据。

每一个数据的内容如下面的图片所示->
import numpy as np# 定义参数
total_data_points = 16 # 总数据点数
window_size = 6 # 窗口大小
predict_length = 2 # 预测长度# 随机生成一个数据集
data_set = np.random.rand(total_data_points)# 分割数据集的函数
def create_inout_sequences(input_data, tw, pre_len):# 创建时间序列数据专用的数据分割器inout_seq = []L = len(input_data)for i in range(L - tw):train_seq = input_data[i:i + tw]if (i + tw + pre_len) > len(input_data):breaktrain_label = input_data[i + tw:i + tw + pre_len]inout_seq.append((train_seq, train_label))return inout_seq# 使用函数分割数据
X = create_inout_sequences(data_set, window_size, predict_length)print("Input sequences (X):")
print(X)大家可以复制上面的代码进行运行来实际了解这一个过程,其中的create_inout_sequences就是数据分割器我自己定义的一个,运行以上的结果输出如下->
 可以看上面的代码输出的X就正如我们设想的一样,输出了九条数据。
可以看上面的代码输出的X就正如我们设想的一样,输出了九条数据。
四、时间序列的数据加载器
经过上面的数据分割器处理之后,我们得到了一个样本数为9的数据集,一般用list在外侧内部为tuple元组保存训练数据和标签,这样list就包含九个数据点,每个 数据点内包含一个大的元组,大的元组内包含两个小的元组一个是储存训练集一个储存标签。
[(('训练数据'),('标签')),(('训练数据'),('标签')),(('训练数据'),('标签')),....]之后我们就要用这个list来生成数据加载器了,我们一般也用下面的加载器进行定义,
from torch.utils.data import DataLoader但是用它进行定义数据加载器之前需要输入的数据格式是dataset的格式,时间序列的dataset和其它领域的不太一样,下面我们来讲解一下->
一般的数据的dataset需要两个数据的输入但是我们的数据只有一个,所以我们需要自己定义一个定义dataset的类来实现这个功能。
class TimeSeriesDataset(Dataset):def __init__(self, sequences):self.sequences = sequencesdef __len__(self):return len(self.sequences)def __getitem__(self, index):sequence, label = self.sequences[index]return torch.Tensor(sequence), torch.Tensor(label)上面这个就是一个基本的Dataset的定义, 通过这个类的定义我们将数据集输入到这个类里转化为Dataset格式,再将其输入到Dataloader里就形成了一个数据加载器。
# 创建数据集
train_dataset = TimeSeriesDataset(X)# 创建 DataLoader
batch_size = 2 # 你可以根据需要调整批量大小
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
上面的代码就是定义一个数据加载器的方法,其中我们设置了batch_size=2就是我们的批次大小, shuffle代表的含义是从我们定义的九条数据里随机的取,drop_last代表丢掉不满足条件的数据,类似于我们的数据大部分都是6条但是最后一条数据不足6,此时如果将其输入到模型里就会报错,所以这个参数就是将其丢弃掉。
if Train:losss = []lstm_model.train() # 训练模式for i in range(epochs):start_time = time.time() # 计算起始时间for seq, labels in train_loader:lstm_model.train()optimizer.zero_grad()y_pred = lstm_model(seq)single_loss = loss_function(y_pred, labels)single_loss.backward()optimizer.step()print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')losss.append(single_loss.detach().numpy())torch.save(lstm_model.state_dict(), 'save_model.pth')print(f"模型已保存,用时:{(time.time() - start_time) / 60:.4f} min")这段代码之间省略了挺多代码包括模型的定义优化器定义什么的这和本文内容无关我就不讲了,后面会放一个完整的代码给大家测试,可以看到代码调用了train_loader这就是我们前面调用的数据加载器,它会调用我们前面定义的class TimeSeriesDataset(Dataset):这个方法,从数据中随机选取一个数据进行加载,分别将训练数据赋值给seq,标签赋值给labels,其中seq会输入到模型的内部进行训练,其中的seq的维度的维度定义应该如下->

可以看到其中的维度是(2,6,1)这其中的含义是[batch_size,window_size,features],我在来描述一下第一个维度是批次大小,第二个维度是你定义的观测窗口大小,第三个维度是你数据的维度,(本次的讲解我们用的是一维的,如果你的特征数是三个那么这里就是三)。这就是一个标准的时间序列输入三个维度。
labels维度如下,和上面的含义是一致的我就不重复了。
![]()
我们将seq输入的模型内部,得到如下输出->

其和labels的形状需要一致用于损失的计算,并用于反向传播。
五、测试流程代码
下面给大家一个测试的代码,我建议大家还是自己debug一下看下其中的具体通道数的变化情况。
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import DataLoader
import torch
from torch.utils.data import Dataset# 随机数种子
np.random.seed(0)class TimeSeriesDataset(Dataset):def __init__(self, sequences):self.sequences = sequencesdef __len__(self):return len(self.sequences)def __getitem__(self, index):sequence, label = self.sequences[index]return torch.Tensor(sequence), torch.Tensor(label)def calculate_mae(y_true, y_pred):# 平均绝对误差mae = np.mean(np.abs(y_true - y_pred))return mae"""
数据定义部分
"""
true_data = pd.read_csv('ETTh1.csv') # 填你自己的数据地址,自动选取你最后一列数据为特征列target = 'OT' # 添加你想要预测的特征列
test_size = 0.15 # 训练集和测试集的尺寸划分
train_size = 0.85 # 训练集和测试集的尺寸划分
pre_len = 4 # 预测未来数据的长度
train_window = 32 # 观测窗口# 这里加一些数据的预处理, 最后需要的格式是pd.series
true_data = np.array(true_data[target])# 定义标准化优化器
scaler_train = MinMaxScaler(feature_range=(0, 1))
scaler_test = MinMaxScaler(feature_range=(0, 1))# 训练集和测试集划分
train_data = true_data[:int(train_size * len(true_data))]
test_data = true_data[-int(test_size * len(true_data)):]
print("训练集尺寸:", len(train_data))
print("测试集尺寸:", len(test_data))# 进行标准化处理
train_data_normalized = scaler_train.fit_transform(train_data.reshape(-1, 1))
test_data_normalized = scaler_test.fit_transform(test_data.reshape(-1, 1))# 转化为深度学习模型需要的类型Tensor
train_data_normalized = torch.FloatTensor(train_data_normalized)
test_data_normalized = torch.FloatTensor(test_data_normalized)def create_inout_sequences(input_data, tw, pre_len):# 创建时间序列数据专用的数据分割器inout_seq = []L = len(input_data)for i in range(L - tw):train_seq = input_data[i:i + tw]if (i + tw + 4) > len(input_data):breaktrain_label = input_data[i + tw:i + tw + pre_len]inout_seq.append((train_seq, train_label))return inout_seq# 定义训练器的的输入
train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len)
test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len)# 创建数据集
train_dataset = TimeSeriesDataset(train_inout_seq)
test_dataset = TimeSeriesDataset(test_inout_seq)# 创建 DataLoader
batch_size = 32 # 你可以根据需要调整批量大小
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)class GRU(nn.Module):def __init__(self, input_dim=1, hidden_dim=32, num_layers=1, output_dim=1, pre_len= 4):super(GRU, self).__init__()self.pre_len = pre_lenself.num_layers = num_layersself.hidden_dim = hidden_dim# 替换 LSTM 为 GRUself.gru = nn.GRU(input_dim, hidden_dim,num_layers=num_layers, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)self.relu = nn.ReLU()self.dropout = nn.Dropout(0.1)def forward(self, x):h0_gru = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)out, _ = self.gru(x, h0_gru)out = self.dropout(out)# 取最后 pre_len 时间步的输出out = out[:, -self.pre_len:, :]out = self.fc(out)out = self.relu(out)return outlstm_model = GRU(input_dim=1, output_dim=1, num_layers=2, hidden_dim=train_window, pre_len=pre_len)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.005)
epochs = 20
Train = True # 训练还是预测if Train:losss = []lstm_model.train() # 训练模式for i in range(epochs):start_time = time.time() # 计算起始时间for seq, labels in train_loader:lstm_model.train()optimizer.zero_grad()y_pred = lstm_model(seq)single_loss = loss_function(y_pred, labels)single_loss.backward()optimizer.step()print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')losss.append(single_loss.detach().numpy())torch.save(lstm_model.state_dict(), 'save_model.pth')print(f"模型已保存,用时:{(time.time() - start_time) / 60:.4f} min")else:# 加载模型进行预测lstm_model.load_state_dict(torch.load('save_model.pth'))lstm_model.eval() # 评估模式results = []reals = []losss = []for seq, labels in test_loader:pred = lstm_model(seq)mae = calculate_mae(pred.detach().numpy(), np.array(labels)) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)for j in range(batch_size):for i in range(pre_len):reals.append(labels[j][i][0].detach().numpy())results.append(pred[j][i][0].detach().numpy())reals = scaler_test.inverse_transform(np.array(reals).reshape(1, -1))[0]results = scaler_test.inverse_transform(np.array(results).reshape(1, -1))[0]print("模型预测结果:", results)print("预测误差MAE:", losss)plt.figure()plt.style.use('ggplot')# 创建折线图plt.plot(reals, label='real', color='blue') # 实际值plt.plot(results, label='forecast', color='red', linestyle='--') # 预测值# 增强视觉效果plt.grid(True)plt.title('real vs forecast')plt.xlabel('time')plt.ylabel('value')plt.legend()plt.savefig('test——results.png')
五、总结
到此本文就都讲解完成了,本文的内容是针对于时间序列预测的新手,可能不太了解时间序列的数据处理流程,最近问的人有点多大家都说不理解,所以单独开了这么一篇文章给大家讲解,内容可能很简单,全文全手打,希望能够帮助到各位~
最后分享我的其他博客给大家,可以方便大家阅读完本文进行实战(本专栏平均质量分98分,并且免费阅读)~
概念理解
15种时间序列预测方法总结(包含多种方法代码实现)
数据分析
时间序列预测中的数据分析->周期性、相关性、滞后性、趋势性、离群值等特性的分析方法
机器学习——难度等级(⭐⭐)
时间序列预测实战(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
深度学习——难度等级(⭐⭐⭐⭐)
时间序列预测实战(五)基于Bi-LSTM横向搭配LSTM进行回归问题解决
时间序列预测实战(七)(TPA-LSTM)结合TPA注意力机制的LSTM实现多元预测
时间序列预测实战(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
时间序列预测实战(十一)用SCINet实现滚动预测功能(附代码+数据集+原理介绍)
时间序列预测实战(十二)DLinear模型实现滚动长期预测并可视化预测结果
时间序列预测实战(十五)PyTorch实现GRU模型长期预测并可视化结果
Transformer——难度等级(⭐⭐⭐⭐)
时间序列预测模型实战案例(八)(Informer)个人数据集、详细参数、代码实战讲解
时间序列预测模型实战案例(一)深度学习华为MTS-Mixers模型
时间序列预测实战(十三)定制化数据集FNet模型实现滚动长期预测并可视化结果
时间序列预测实战(十四)Transformer模型实现长期预测并可视化结果(附代码+数据集+原理介绍)
个人创新模型——难度等级(⭐⭐⭐⭐⭐)
时间序列预测实战(十)(CNN-GRU-LSTM)通过堆叠CNN、GRU、LSTM实现多元预测和单元预测
传统的时间序列预测模型(⭐⭐)
时间序列预测实战(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
时间序列预测实战(六)深入理解ARIMA包括差分和相关性分析
融合模型——难度等级(⭐⭐⭐)
时间序列预测实战(九)PyTorch实现融合移动平均和LSTM-ARIMA进行长期预测
时间序列预测实战(十六)PyTorch实现GRU-FCN模型长期预测并可视化结果

相关文章:
时间序列基础->数据标签、数据分割器、数据加载器的定义和讲解(零基础入门时间序列)
一、本文介绍 各位小伙伴好,最近在发时间序列的实战案例中总是有一些朋友问我时间序列中的部分对数据的操作是什么含义,我进行了挺多的介绍和讲解但是问的人越来越多,所以今天在这里单独发一篇文章来单独的讲一下时间序列中对数据的处理操作…...

【图论】最小生成树(python和cpp)
文章目录 一、声明二、简介三、代码C代码Python代码 一、声明 本帖持续更新中如有纰漏望指正! 二、简介 (a)点云建立的k近邻图(b)k近邻图上建立的最小生成树 最小生成树 (Minimum Spanning Tree,简称 M…...
【亚马逊云科技】使用Amazon Lightsail快速建站
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成…...

使用字典树实现一个可以自动补全的输入框
说在前面 平时我们在终端输入命令的时候是不是都可以通过tab键来进行快速补全?那么有没有想过怎么去实现这个自动补全的功能呢?今天让我们一起来使用字典树实现一个可以自动补全的输入框。 效果展示 体验地址 http://jyeontu.xyz/jvuewheel/#/JAutoComp…...

edge/chrome浏览器favicon.ico缓存问题
解决办法来源于How do I force a favicon refresh? - Stack Overflow <head><link rel"icon" href"favcion.ico" type"image/x-icon"></link> </head> 遇到的问题: 第一次设置了faccion.ico 后 再一次修…...

长虹智能电视使用123
1、开机 在接通电源的情况下,长虹智能电视开机有两种方式。 方式1: 按电视右下角开机按钮 方式2: 按电视遥控器开机按钮 长虹智能电视开机后会进入其操作系统(安卓)。 屏幕左右双箭头图表,手指点击会…...
Java基于itextPDF实现pdf动态导出
Java基于itextPDF实现pdf动态导出 1、制作PDF导出模板2 、集成itextpdf3 、编写实体4 、编写主要代码5、编写controller并测试补充:踩坑记录 现在的业务越来越复杂了,有些业务场景已经不能满足与EXCEL导出和WORD导出了,例如准考证打印&#x…...

【Liunx】配置IP地址与MAC地址绑定
配置IP地址与MAC地址绑定 A.查询MAC地址B.绑定前的准备1.资源:(1) 服务器Server1:192.168.122.1(2) 服务器Server1:192.168.122.2 2. Server1按照dhcp服务 C.开始绑定操作1.修改dhcp配置文件2.生效 A.查询MAC地址 点击这里查看【如何查询服务器IP与MAC地址】 B.绑定…...

Mybatis-Plus最新教程
目录 原理:MybatisPlus通过扫描实体类,并基于反射获取实体类信息作为数据库信息。 编辑1.添加依赖 2.常用注解 3.常见配置: 4.条件构造器 5.QueryWrapper 6.UpdateWrapper 7.LambdaQueryWrapper:避免硬编码 8.自定义SQL 9.Iservic…...

【Shell脚本11】Shell 函数
Shell 函数 linux shell 可以用户定义函数,然后在shell脚本中可以随便调用。 shell中函数的定义格式如下: [ function ] funname [()]{action;[return int;]}说明: 1、可以带function fun() 定义,也可以直接fun() 定义,不带任何…...

STM32中独立看门狗和窗口看门狗的使用方法
独立看门狗(Independent Watchdog,IWDG)和窗口看门狗(Window Watchdog,WWDG)是STM32微控制器中提供的两种看门狗定时器。看门狗定时器是一种硬件计时器,用于监视系统的运行状态,并在…...
)
刷题笔记(第七天)
1.找出对象 obj 不在原型链上的属性(注意这题测试例子的冒号后面也有一个空格~) 返回数组,格式为 key: value结果数组不要求顺序 输入: var C function() {this.foo ‘bar’; this.baz ‘bim’;}; C.prototype.bop ‘bip’; iterate(new C()); 输出…...
:计分)
python3.7 + pygame1.9.3实现小游戏《外星人入侵》(五):计分
本小节首先在游戏画面中添加一个Play按钮,用于根据需要启动游戏,为此在game_stats.py中输入以下代码: class GameStats():def __init__(self,ai_settings):# 初始化统计信息self.ai_settings ai_settingsself.reset_stats()#让游戏一开始处…...

[量化投资-学习笔记014]Python+TDengine从零开始搭建量化分析平台-Python知识点汇总
以下内容总结了之前章节涉及到的 Python 知识点,看过之前的章节同学,就不用打开了。 1. Restful 访问 TDengine 数据库 知识点: 发送给 TDengine 的 HTTP Body 里面是 SQL 明文,请求方式为 POST。TDenging 返回的结果是 JSON 格…...
[论文分享] Never Mind the Malware, Here’s the Stegomalware
Never Mind the Malware, Here’s the Stegomalware [IEEE Security & Privacy 2022] Luca Caviglione | National Research Council of Italy Wojciech Mazurczyk | Warsaw University of Technology and FernUniversitt in Hagen 近年来,隐写技术已逐渐被观…...

代号:408 —— 1000道精心打磨的计算机考研题
文章目录 📋前言🎯计算机科学与技术专业介绍(14年发布)🧩培养目标🧩毕业生应具备的知识和能力🧩主要课程 🎯代号:408🔥文末送书🧩有什么优势&…...

《QT从基础到进阶·十六》QT实现客户端和服务端的简单交互
QT版本:5.15.2 VS版本:2019 客户端程序主要包含三块:连接服务器,发送消息,关闭客户端 服务端程序主要包含三块:打开消息监听,接收消息并反馈,关闭服务端 1、先打开服务端监听功能 …...
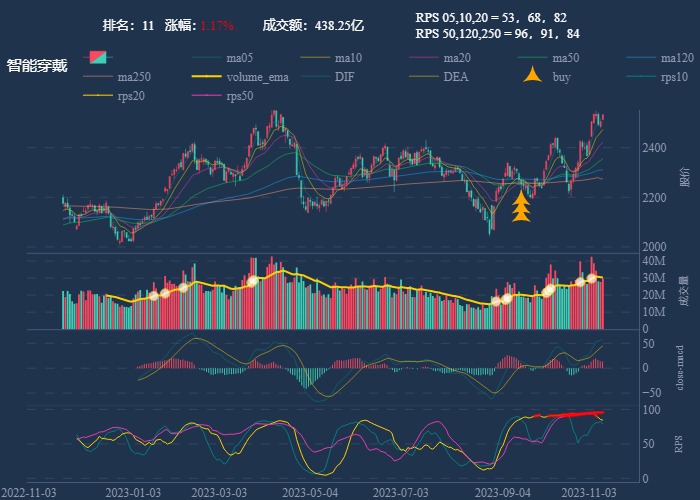
行业追踪,2023-11-13
自动复盘 2023-11-13 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...
开放领域对话系统架构
开放领域对话系统是指针对非特定领域或行业的对话系统,它可以与用户进行自由的对话,不受特定领域或行业的知识和规则的限制。开放领域对话系统需要具备更广泛的语言理解和生成能力,以便与用户进行自然、流畅的对话。 与垂直领域对话系统相比…...

终端神器:tmux
安装tmux简单使用自己的理解(小白专属) 使用的初衷: 在Linux终端下,由于session(会话)和windows(窗口)是绑定一起的,你打开一个终端的黑窗口就是打开一个会话,…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

Jetson Orin Nano 升级jetpack5.1.2刷机过程记录
一.刷机起因 orin nano 接了个IMX477的摄像头,用 命令行DISPLAY:0.0 nvgstcapture-1.0 显示的画面有撕裂,让卖家查问题,卖家测试没有撕裂,对比环境,orin nano出厂默认的是jetpack5.1.1,卖家用的jetpack5.1.2版本,为了解决差异,要升级jetpack版本,前后搞了2天半,记录一下. 另外…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

Simulink中Repeating Sequence锯齿波显示恒为0解决方案
锯齿波设置如图1时,其示波器显示恒为0(如图2)。图1图2于是新建模型,只添加Repeating Sequence模块,采用原始设置发现可以正常输出锯齿波,于是调整时间参数,发现当时间设置为≥[0 0.06]时可以正常…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

解决Claude Code Token不足问题并享受Taotoken活动价
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code Token不足问题并享受Taotoken活动价 应用场景类,聚焦于使用Claude Code时遇到Token配额紧张的开发者&…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...