阿里达摩院开源DAMO-YOLO
1.简介
DAMO-YOLO是一个兼顾速度与精度的目标检测框架,其效果超越了目前的一众YOLO系列方法,在实现SOTA的同时,保持了很高的推理速度。DAMO-YOLO是在YOLO框架基础上引入了一系列新技术,对整个检测框架进行了大幅的修改。具体包括:基于NAS搜索的新检测backbone结构,更深的neck结构,精简的head结构,以及引入蒸馏技术实现效果的进一步提升。模型之外,DAMO-YOLO还提供高效的训练策略以及便捷易用的部署工具,能够快速解决工业落地中的实际问题!
使用入口:
https://modelscope.cn/models/damo/cv_tinynas_object-detection_damoyolo/summary
代码地址:GitHub - tinyvision/damo-yolo
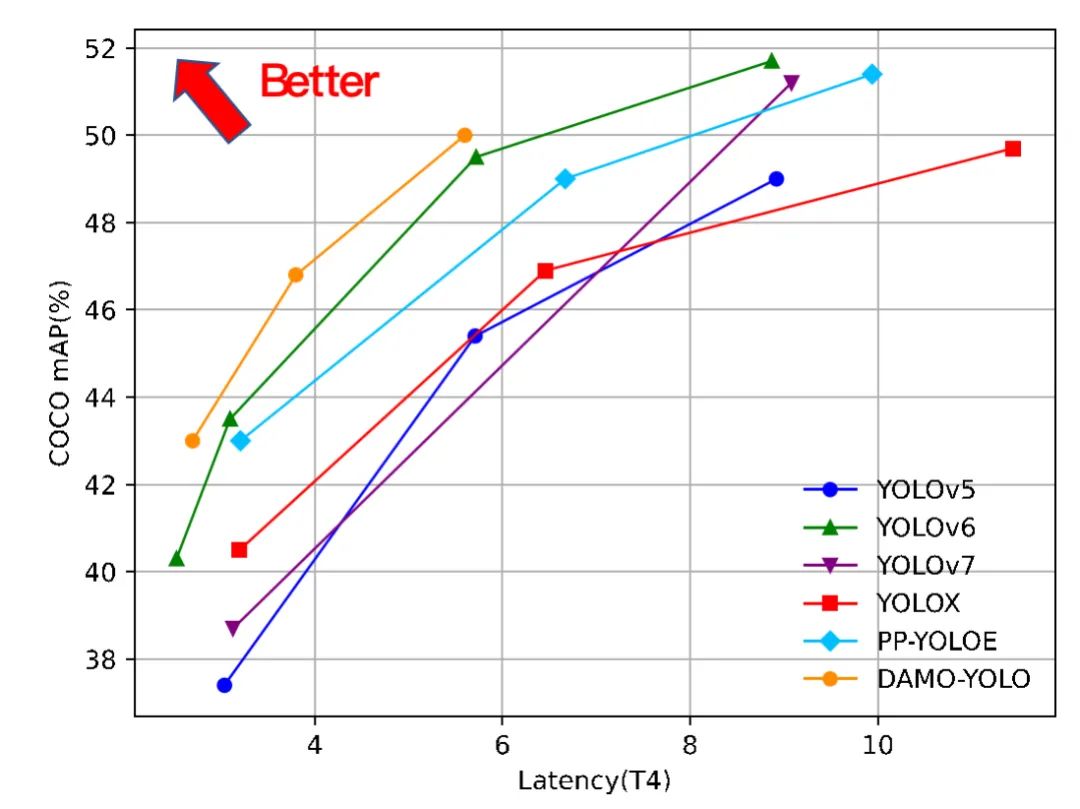
图1 DAMO-YOLO和其他YOLO系列方法的性能对比结果
2. 关键技术
2.1. NAS backbone: MAE-NAS
Backbone的网络结构在目标检测中起着重要的作用。DarkNet在早期YOLO系列中一直占据着主导地位。最近,一些工作也开始探索其他对检测有效的网络结构,比如YOLOv6和YOLOv7。然而,这些网络仍然是人工设计的。随着神经网络结构搜索技术(NAS)的发展,出现了许多可以用于检测任务的NAS网络结构,并且相比于传统手动设计的网络,NAS网络结构可以达到能好的检测效果。因此,我们利用NAS技术搜索出合适的网络结构作为我们的DAMO-YOLO的backbone。这里我们采用的是阿里自研的MAE-NAS(开源链接)。MAE-NAS是一种启发式和免训练的NAS搜索方法,可以用于快速大范围搜索各种不同规模的骨干网络结构。
MAE-NAS利用信息论理论从熵的角度去评测初始化网络,评测过程不需要任何训练过程,从而解决了之前NAS搜索方法需要训练再评测的弊端。实现短时间内大范围的网络搜索,降低搜索成本的同时,也提高了可以找到的潜在更优网络结构的可能性。特别值得注意的是,在MAE-NAS搜索中,我们使用K1K3作为基本搜索模块。同时,受YOLOv6启发,我们直接使用GPU推理延迟Latency,而不是 Flops,作为目标预算。搜索后,我们将空间金字塔池化和焦点模块应用到最后的骨干。
下表1中列出了不同的主干的性能对比结果。可以看到MAE-NAS骨干网络的效果要明显优于DarkNet网络结构。
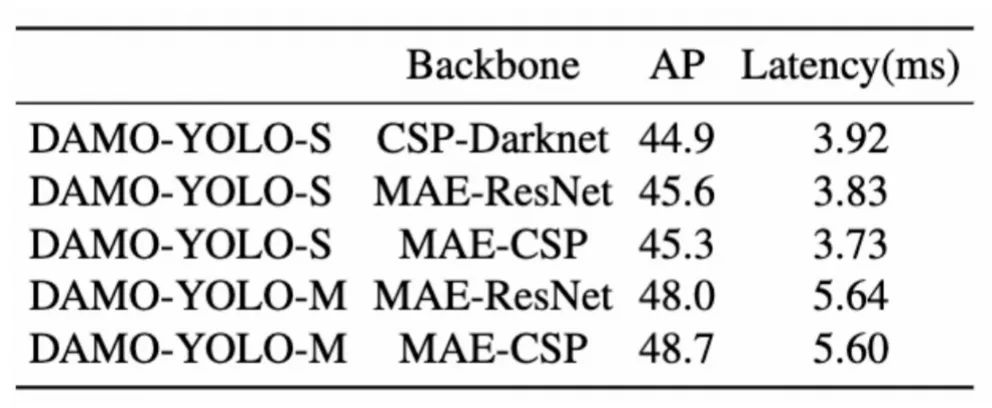
表1 MAE-NAS网络结构和DarkNet对比
2.2. Large Neck: RepGFPN
在FPN(Feature Pyramid Network)中,多尺度特征融合旨在对从backbone不同stage输出的特征进行聚合,从而增强输出特征的表达能力,提升模型性能。传统的FPN引入top-to-down的路径来融合多尺度特征。考虑到单向信息流的限制,PAFPN增加了一个额外的自底向上的路径聚合网络,然而增加了计算成本。为了降低计算量,YOLO系列检测网络选择带有CSPNet的PAFPN来融合来自backbone输出的多尺度特征。
我们在ICLR2022的工作GiraffeDet中提出了新颖的Light-Backbone Heavy-Neck结构并达到了SOTA性能,原因在于给出的neck结构GFPN(Generalized FPN)能够充分交换高级语义信息和低级空间信息。在GFPN中,多尺度特征融合发生在前一层和当前层的不同尺度特征中,此外,log_2(n)的跨层连接提供了更有效的信息传输,可以扩展到更深的网络。
因此,我们尝试将GFPN引入到DAMO-YOLO中,相比于PANet,我们取得了更高的精度,这是在预期之中的。然而与之同时,GFPN带来了模型推理时延的增加,使得精度/时延的权衡并未取得较大的优势。通过对原始GFPN结构的分析,我们将原因归结为以下几个方面:(1)不同尺度特征共享相同通道数,导致难以给出一个最优通道数来保证高层低分辨率特征和低层高分辨率特征具有同样丰富的表达能力;(2)GFPN采用Queen-Fusion强化特征之间的融合,而Queen-Fusion包含大量的上采样和下采样操作来实现不同尺度特征的融合,极大影响推理速度;(3)GFPN中使用的3x3卷积进行跨尺度特征融合的效率不高,不能满足轻量级计算量的需求,需要进一步优化。
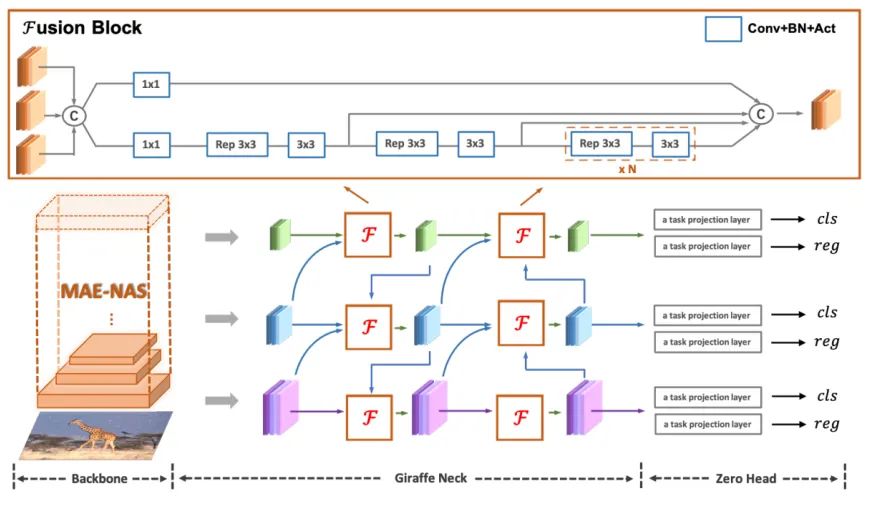
图2 DAMO-YOLO整体框架图
经过上述分析后,我们在GFPN的基础上提出了新的Efficient-RepGFPN来满足实时目标检测中neck的设计,主要包括以下改进:(1)不同尺度特征使用不同的通道数,从而在轻量级计算量约束下,灵活控制高层特征和低层特征的表达能力;(2)删除了Queen-Fusion中的额外的上采样操作,在精度下降较少的情况下,较大降低模型推理时延;(3)将原始基于卷积的特征融合改进为CSPNet连接,同时引入重参数化思想和ELAN连接,在不增加更多计算量的同时,提升模型的精度。最终的Efficient-RepGFPN网络结构如上图2所示。
Efficient-RepNGFPN的消融实验见下表2。
从表2-(1)可以看到,灵活控制不同尺度特征图的通道数,我们能够取得相比于所有尺度特征图共享相同通道数更高的精度,表明灵活控制高层特征和低层特征的表达能力能够带来更多收益。同时,通过控制模型在同一计算量级别,我们也做了Efficient-RepGFPN中depth/width的权衡对比,当depth=3,width=(96,192,384)时,模型取得了最高精度。表2-(2)对Queen-Fusion连接进行了消融实验对比,当不增加额外的上采样及下采样算子时,neck结构为PANet连接。我们尝试了只增加上采样算子和只增加下采样算子以及完整的Queen-Fusion结构,模型精度均取得了提升。然而,只增加上采样算子带来了0.6ms的推理时间增加,精度仅提升0.3,远远低于只增加额外下采样算子的精度/时延收益,因此在最终设计上我们摒弃了额外的上采样算子。
表2-(3)中,我们对多尺度特征融合方式进行了实验对比,从表中可以看到,在低计算量约束下,CSPNet的特征融合方式要远优于基于卷积的融合方式,同时,引入重参数化思想及ELAN的连接能够在Latency少量增加的情况下,带来大的精度提升。

表2 (1)不同“尺度-通道数”组合结果;(2)Queen-Fusion中上下采样的影响;(3)CSP中重采样和ELAN的影响
2.3. Small Head: ZeroHead
在这个小节,我们主要介绍DAMO-YOLO中的检测头(ZeroHead)。目前目标检测方法中,比较常见的是采用Decouple Head来作为检测头。Decouple Head可以实现了更高的 AP,但会一定程度上增加模型的计算时间。为了平衡模型速度和性能,我们进行了下表3的实验来选择合适的neck和head比重。

表3 Neck和Head不同比重对训练结果的影响
从表2中我们可以发现“大neck,小head”的结构会获得更好的性能。因此,我们丢弃了之前方法中常使用的Decouple Head,只保留了用于分类和回归任务的一层线性投影层,我们称其为ZeroHead。ZeroHead可以最大限度地压缩检测头的计算量,从而省出更大的空间给更复杂的Neck,比如我们的RepGFPN neck。值得注意的是ZeroHead 本质上可以被认为是一种Couple Head,这也是和之前方法所采样的Decouple Head的一个明显不同。
2.4. Label Assignment: AlignOTA
标签分配(label assignment)是物体检测中的一个关键组件,以往的静态分配方法往往只考虑anchor与ground truth的IoU,这类分配方法容易导致分类任务的失焦,如图3左图所示,手的检测框要用玩偶熊身上的点去做预测,这对模型来说是不合理的为难,理想中的标签如图3右图所示。另外,此类方法依赖anchor先验,在工业应用中,被检物体尺度变化多端,要找到一个最合适的anchor先验十分繁琐。

图3 静态和动态分配差异
为了克服以上的问题,学术界涌现了一批利用模型的分类和回归预测值进行动态分配的标签分配方法,该类方法消除了标签分配对anchor的依赖,并且在分配时同时考虑分类和回归的影响,一定程度上消除失焦问题。OTA 是其中的一个经典工作,其根据模型的分类和回归预测值计算分配cost,并且使用Sinkhorn-Knopp算法求解全局最优匹配,在复杂分配场景下性能优异,因此这里我们采用OTA作为我们的匹配策略。
但是OTA本身也存在一定的问题,在计算匹配时,并不能保证同时兼顾到分类和回归对匹配的影响。换句话说,存在分类回归不对齐的问题。针对这个问题,我们对匹配分数的计算方式进行了修改,如下面公式所示。
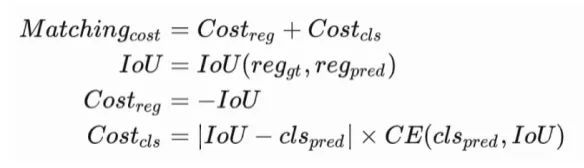
其中, |IoU−clspred| 用来调节分类和回归的匹配程度, CE(clspred,IoU) 用来将分类的硬标签转化为基于IOU的软数值。
表4给出了改进后的AlignOTA和原OTA的比较,可以看到AlignOTA在效果上有着明显的提升。
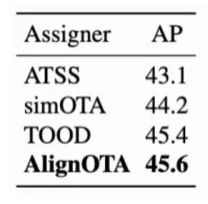
表4 AlignOTA和原OTA效果比较
2.5. Distillation Enhancement
模型蒸馏是提升模型效果的一种有效手段。YOLOv6尝试在其large模型中使用自蒸馏技术提升模型效果。但整体来说目前在YOLO系列的工作中,蒸馏的应用还不是很普遍,特别是小模型上的蒸馏。我们针对DAMO-YOLO做了专门的研究,最终实用蒸馏技术在DAMO-YOLO的各尺度模型上实现了效果的提升。
DAMO-YOLO的训练过程分为两阶段,第一阶段是基于强马赛克增强的训练,共284ep,第二阶段是关闭马赛克增强的训练,共16ep。我们发现在第一阶段使用蒸馏技术,可以实现更快速的收敛,达到更高的效果;但是第二阶段继续使用蒸馏却无法进一步提升效果。我们认为,第二阶段数据分布和第一阶段相比已经出现了比较大的偏差,第二阶段的知识蒸馏会一定程度上破坏第一阶段已经学到的知识分布。而第二阶段过短的训练时间,使得模型无法从第一阶段知识分布充分过度到第二阶段知识分布。但如果强行拉长训练周期或者提高学习率,一方面增加了训练成本和时间,另一方面也会弱化第一阶段蒸馏所带来的效果。因此,这里我们在第二阶段关闭蒸馏操作,只进行第一阶段蒸馏。
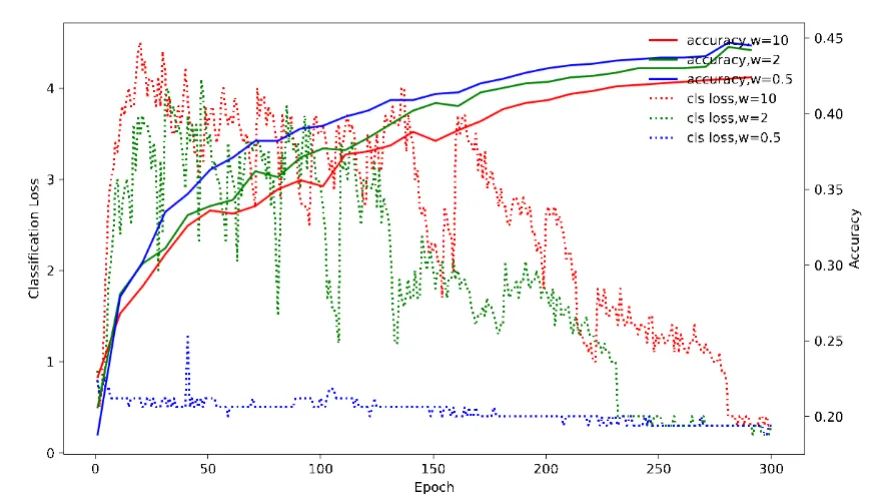
图4 不同蒸馏权重下分类loss和准确率的变化关系
其次,我们在蒸馏中引入了两个技术,一个是对齐模块,用于把teacher和student的特征图大小进行对齐。另一个是归一化操作,用于弱化teacher和student之间数值尺度波动所造成影响,起作用可以看成是一种用于KL loss的动态温度系数。
除此之外,我们还发现蒸馏的loss权重和head大小对蒸馏效果也有着很大影响。如上图4所示,当蒸馏loss权重变大时,分类loss收敛变慢,且出现很大波动。我们知道,分类loss对检测影响非常大。其过晚的收敛会导致模型优化不够充分,从而影响最终的检测效果。因此不同于之前蒸馏的经验,在DAMO-YOLO中,我们采用很小的蒸馏权重来控制蒸馏loss(weight=0.5),弱化了蒸馏loss和分类loss之间的冲突。而且,针对蒸馏loss收敛速度快于分类loss的特点,我们用cosine weight代替constant weight,来提升蒸馏loss在训练初期的主导作用。
同时,为了进一步提升分类loss和蒸馏loss优化时的一致性,我们采用更小的Head来训练检测,这里使用的是ZeroHead。ZeroHead只包含了一个用于任务投影的线性层。因此,相当于是蒸馏loss和分类loss同时在优化同一个特征空间。随着训练的进行,学习到的空间可以同时满足蒸馏和分类两者的优化。最终我们还是实验了不同蒸馏方法,结果如下表5。发现CWD蒸馏可以达到更好的效果,Bravo CWD。
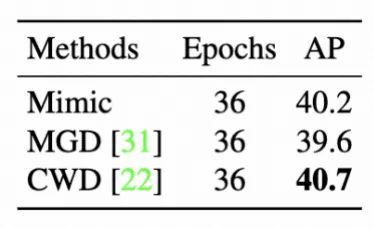
表5 不同蒸馏方法的结果对比
3. 性能对比
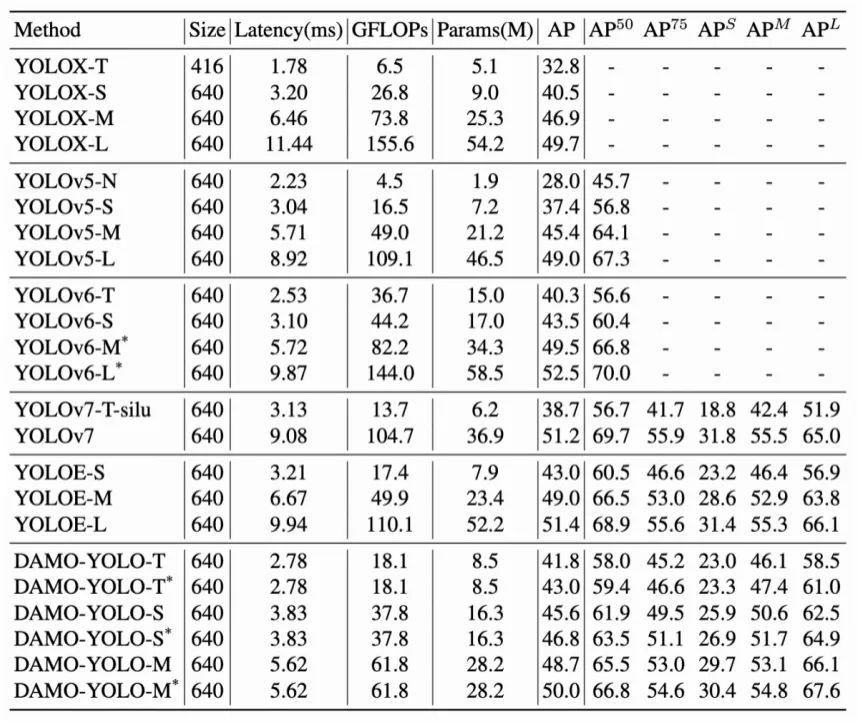
Damo-YOLO团队在MSCOCO val集上验证了DAMO-YOLO的性能。可以看到,结合上述的改进点,DAMO-YOLO在严格限制Latency的情况下精度取得了显著的提升,创造了新SOTA。
相关文章:
阿里达摩院开源DAMO-YOLO
1.简介 DAMO-YOLO是一个兼顾速度与精度的目标检测框架,其效果超越了目前的一众YOLO系列方法,在实现SOTA的同时,保持了很高的推理速度。DAMO-YOLO是在YOLO框架基础上引入了一系列新技术,对整个检测框架进行了大幅的修改。具体包括…...

【异常检测小集】
目录 【2018 ICLR】DAGMM:Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection【2021 TNNLS】无名:Feature Encoding with AutoEncoders for Weakly-supervised Anomaly Detection 【2018 ICLR】DAGMM:Deep Autoen…...

Mybatis-Plus的IPage和Page
Mybatis-Plus 中的分页查询接口主要有两个:IPage 和 Page。 IPage 接口: IPage 是 Mybatis-Plus 中的分页结果集接口,它继承了 Mybatis 的 RowBounds 接口,提供了一系列的分页查询方法。该接口主要用于返回分页后的数据结果。 Pa…...

jupyter lab常用插件集合
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

centos 6.10 安装 boost 1.78.0
下载地址 找到对应的版本,下载源码,而不是二进制文件。 解压文件 cd boost_1_78_0 ./bootstrap.sh ./b2 install -perfix /usr/local/boost1.78.0/...

Vue 3.0 + vite + axios+PHP跨域问题的解决办法
最后一个Web项目,采用前后端分离。 前端:Vue 3.0 viteelement plus 后端:PHP 运行时前端和后端是两个程序,前端需要时才向后端请求数据。由于是两个程序,这就会出现跨域问题。 比如前端某个地方需要请求的接口如下…...
软件外包开发的开发文档
软件开发文档是一个重要的工具,用于记录和传达项目信息,帮助开发团队和利益相关者理解项目的各个方面。以下是一般性的软件开发文档编写格式,不同组织和项目可能有所不同,但这些通用准则可以帮助确保文档的清晰性和易读性…...

如何清理C盘文件
设置-系统-存储 在里面处理 搜索磁盘清理 然后选择系统文件,清理windows old等乱七八糟的东西 转移虚拟内存 关闭系统休眠功能 【管理员:命令提示符】窗口,输入命令:powercfg -h off,然后回车就可以关闭系统休眠…...

从测试的角度看待南航机票bug事件
事件描述 11月8日晚间,多名消费者反映南方航空多条成都进出港航线票价(不含机建燃油费)低至10元、20元、30元不等。上述超低价机票不仅在南方航空App可以购买,多家在线旅游平台也都能抢到。 11月9日,南航官方发布公告…...

通过 dump 虚拟机线程方法栈和堆内存来分析 Android 卡顿和 OOM 问题
作者:Tans5 Android 中的性能问题无非就是卡顿和 OOM,虽然总体就这两种,但是造成这两种性能问题的原因却是非常多,需要具体的原因具体分析,而且这是非常复杂的。本篇文章只是简单介绍如何找到造成这些问题的直接原因的…...

layui 框架的upload上传文件的data参数传到后端的方法
因为特殊性,upload.render初始化的data:{id:"sss"}不能传参到后台。 经过大量测试及参数网上方法,才发现,需要特殊处理: 1、如果直接给{id:"sss"}无效,但如果在before里,this.data.i…...

Java虚拟机的垃圾回收机制
Java虚拟机的垃圾回收机制 Java语言会对程序运行过程中产生的垃圾进行自动回收,不需要我们手动地写语句主动地对垃圾进行回收。 什么是垃圾? 在C语言中不再被使用的内存空间被称为垃圾,因为在C语言中如果我们使用到一些自定义类型的结构体&am…...

时间序列基础->数据标签、数据分割器、数据加载器的定义和讲解(零基础入门时间序列)
一、本文介绍 各位小伙伴好,最近在发时间序列的实战案例中总是有一些朋友问我时间序列中的部分对数据的操作是什么含义,我进行了挺多的介绍和讲解但是问的人越来越多,所以今天在这里单独发一篇文章来单独的讲一下时间序列中对数据的处理操作…...

【图论】最小生成树(python和cpp)
文章目录 一、声明二、简介三、代码C代码Python代码 一、声明 本帖持续更新中如有纰漏望指正! 二、简介 (a)点云建立的k近邻图(b)k近邻图上建立的最小生成树 最小生成树 (Minimum Spanning Tree,简称 M…...
【亚马逊云科技】使用Amazon Lightsail快速建站
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成…...

使用字典树实现一个可以自动补全的输入框
说在前面 平时我们在终端输入命令的时候是不是都可以通过tab键来进行快速补全?那么有没有想过怎么去实现这个自动补全的功能呢?今天让我们一起来使用字典树实现一个可以自动补全的输入框。 效果展示 体验地址 http://jyeontu.xyz/jvuewheel/#/JAutoComp…...

edge/chrome浏览器favicon.ico缓存问题
解决办法来源于How do I force a favicon refresh? - Stack Overflow <head><link rel"icon" href"favcion.ico" type"image/x-icon"></link> </head> 遇到的问题: 第一次设置了faccion.ico 后 再一次修…...

长虹智能电视使用123
1、开机 在接通电源的情况下,长虹智能电视开机有两种方式。 方式1: 按电视右下角开机按钮 方式2: 按电视遥控器开机按钮 长虹智能电视开机后会进入其操作系统(安卓)。 屏幕左右双箭头图表,手指点击会…...
Java基于itextPDF实现pdf动态导出
Java基于itextPDF实现pdf动态导出 1、制作PDF导出模板2 、集成itextpdf3 、编写实体4 、编写主要代码5、编写controller并测试补充:踩坑记录 现在的业务越来越复杂了,有些业务场景已经不能满足与EXCEL导出和WORD导出了,例如准考证打印&#x…...

【Liunx】配置IP地址与MAC地址绑定
配置IP地址与MAC地址绑定 A.查询MAC地址B.绑定前的准备1.资源:(1) 服务器Server1:192.168.122.1(2) 服务器Server1:192.168.122.2 2. Server1按照dhcp服务 C.开始绑定操作1.修改dhcp配置文件2.生效 A.查询MAC地址 点击这里查看【如何查询服务器IP与MAC地址】 B.绑定…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

【DeepSeek架构评审功能深度解密】:20年架构师亲授3大避坑指南与5步落地 checklist
更多请点击: https://kaifayun.com 第一章:DeepSeek架构评审功能全景概览 DeepSeek架构评审功能是一套面向大模型系统设计与工程落地的自动化分析框架,聚焦于模型结构合理性、计算图优化潜力、内存访问模式、算子兼容性及部署约束等多维度评…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...

在数据预处理与分析流水线中集成大模型API进行智能标注与摘要
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在数据预处理与分析流水线中集成大模型API进行智能标注与摘要 对于数据工程师而言,处理海量非结构化文本数据是一项常见…...

观察Token消耗明细,Taotoken用量看板如何帮助控制预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Token消耗明细,Taotoken用量看板如何帮助控制预算 对于个人开发者或项目管理者而言,在使用大模型API时…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...

如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南
如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重新焕发活力&a…...

从SIM800到BK A7670E:4G Cat.1模块硬件平替转接板设计全解析
1. 项目概述:从2G到4G的硬件平替升级 手头有个老项目,用的还是SIM800这种经典的2G模块,现在网络环境变了,2G退网是大势所趋,信号覆盖越来越差,项目得活下去,升级到4G成了刚需。但问题来了&#…...

《关于 AI Agent 基础设施的一些奇思妙想》
目录 目录 目录 一、AI Agent 容器 问题背景 想法思路:API 中转站模式 多 Agent 切换 二、手机端操控 AI Agent(手机与电脑互联) 三、AI 开发依赖管理工具 总结 最近 AI Agent 越来越火,我作为一个重度使用者,…...