头哥实践平台之MapReduce基础实战
一. 第1关:成绩统计
编程要求
使用MapReduce计算班级每个学生的最好成绩,输入文件路径为/user/test/input,请将计算后的结果输出到/user/test/output/目录下。
先写命令行,如下:
一行就是一个命令
touch file01
echo Hello World Bye World
cat file01
echo Hello World Bye World >file01
cat file01
touch file02
echo Hello Hadoop Goodbye Hadoop >file02
cat file02
start-dfs.sh
hadoop fs -mkdir /usr
hadoop fs -mkdir /usr/input
hadoop fs -ls /usr/output
hadoop fs -ls /
hadoop fs -ls /usr
hadoop fs -put file01 /usr/input
hadoop fs -put file02 /usr/input
hadoop fs -ls /usr/input代码段部分:
import java.util.StringTokenizer;import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class WordCount {/********** Begin **********///Mapper函数public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();private int maxValue = 0;public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString(),"\n");while (itr.hasMoreTokens()) {String[] str = itr.nextToken().split(" ");String name = str[0];one.set(Integer.parseInt(str[1]));word.set(name);context.write(word,one);}//context.write(word,one);}}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {int maxAge = 0;int age = 0;for (IntWritable intWritable : values) {maxAge = Math.max(maxAge, intWritable.get());}result.set(maxAge);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = new Job(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);String inputfile = "/user/test/input";String outputFile = "/user/test/output/";FileInputFormat.addInputPath(job, new Path(inputfile));FileOutputFormat.setOutputPath(job, new Path(outputFile));job.waitForCompletion(true);/********** End **********/}
}二. 第2关:文件内容合并去重
编程要求
接下来我们通过一个练习来巩固学习到的MapReduce知识吧。
对于两个输入文件,即文件file1和文件file2,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件file3。
为了完成文件合并去重的任务,你编写的程序要能将含有重复内容的不同文件合并到一个没有重复的整合文件,规则如下:
第一列按学号排列;
学号相同,按x,y,z排列;
输入文件路径为:/user/tmp/input/;
输出路径为:/user/tmp/output/。
注意:输入文件后台已经帮你创建好了,不需要你再重复创建。
请先启动Hadoop再点击评测!
所以要先在命令行输入下面启动命令
start-dfs.sh
import java.io.IOException;import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class Merge {/*** @param args* 对A,B两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C*///在这重载map函数,直接将输入中的value复制到输出数据的key上 注意在map方法中要抛出异常:throws IOException,InterruptedExceptionpublic static class Map extends Mapper<Object, Text, Text, Text>{/********** Begin **********/public void map(Object key, Text value, Context content) throws IOException, InterruptedException { Text text1 = new Text();Text text2 = new Text();StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {text1.set(itr.nextToken());text2.set(itr.nextToken());content.write(text1, text2);}} /********** End **********/} //在这重载reduce函数,直接将输入中的key复制到输出数据的key上 注意在reduce方法上要抛出异常:throws IOException,InterruptedExceptionpublic static class Reduce extends Reducer<Text, Text, Text, Text> {/********** Begin **********/public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {Set<String> set = new TreeSet<String>();for(Text tex : values){set.add(tex.toString());}for(String tex : set){context.write(key, new Text(tex));}} /********** End **********/}public static void main(String[] args) throws Exception{// TODO Auto-generated method stubConfiguration conf = new Configuration();conf.set("fs.default.name","hdfs://localhost:9000");Job job = Job.getInstance(conf,"Merge and duplicate removal");job.setJarByClass(Merge.class);job.setMapperClass(Map.class);job.setCombinerClass(Reduce.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);String inputPath = "/user/tmp/input/"; //在这里设置输入路径String outputPath = "/user/tmp/output/"; //在这里设置输出路径FileInputFormat.addInputPath(job, new Path(inputPath));FileOutputFormat.setOutputPath(job, new Path(outputPath));System.exit(job.waitForCompletion(true) ? 0 : 1);}}三. 第3关:信息挖掘 - 挖掘父子关系
编程要求
你编写的程序要能挖掘父子辈关系,给出祖孙辈关系的表格。规则如下:
孙子在前,祖父在后;
输入文件路径:/user/reduce/input;
输出文件路径:/user/reduce/output。
请先启动Hadoop再点击评测!
所以要先在命令行输入下面启动命令
start-dfs.sh
import java.io.IOException;
import java.util.*;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class simple_data_mining {public static int time = 0;/*** @param args* 输入一个child-parent的表格* 输出一个体现grandchild-grandparent关系的表格*///Map将输入文件按照空格分割成child和parent,然后正序输出一次作为右表,反序输出一次作为左表,需要注意的是在输出的value中必须加上左右表区别标志public static class Map extends Mapper<Object, Text, Text, Text>{public void map(Object key, Text value, Context context) throws IOException,InterruptedException{/********** Begin **********/String line = value.toString();String[] childAndParent = line.split(" ");List<String> list = new ArrayList<>(2);for (String childOrParent : childAndParent) {if (!"".equals(childOrParent)) {list.add(childOrParent);} } if (!"child".equals(list.get(0))) {String childName = list.get(0);String parentName = list.get(1);String relationType = "1";context.write(new Text(parentName), new Text(relationType + "+"+ childName + "+" + parentName));relationType = "2";context.write(new Text(childName), new Text(relationType + "+"+ childName + "+" + parentName));}/********** End **********/}}public static class Reduce extends Reducer<Text, Text, Text, Text>{public void reduce(Text key, Iterable<Text> values,Context context) throws IOException,InterruptedException{/********** Begin **********///输出表头if (time == 0) {context.write(new Text("grand_child"), new Text("grand_parent"));time++;}//获取value-list中value的child
List<String> grandChild = new ArrayList<>();//获取value-list中value的parentList<String> grandParent = new ArrayList<>();//左表,取出child放入grand_childfor (Text text : values) {String s = text.toString();String[] relation = s.split("\\+");String relationType = relation[0];String childName = relation[1];String parentName = relation[2];if ("1".equals(relationType)) {grandChild.add(childName);} else {grandParent.add(parentName);}}//右表,取出parent放入grand_parentint grandParentNum = grandParent.size();int grandChildNum = grandChild.size();if (grandParentNum != 0 && grandChildNum != 0) {for (int m = 0; m < grandChildNum; m++) {for (int n = 0; n < grandParentNum; n++) {//输出结果context.write(new Text(grandChild.get(m)), new Text(grandParent.get(n)));}}}/********** End **********/}}public static void main(String[] args) throws Exception{// TODO Auto-generated method stubConfiguration conf = new Configuration();Job job = Job.getInstance(conf,"Single table join");job.setJarByClass(simple_data_mining.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);String inputPath = "/user/reduce/input"; //设置输入路径String outputPath = "/user/reduce/output"; //设置输出路径FileInputFormat.addInputPath(job, new Path(inputPath));FileOutputFormat.setOutputPath(job, new Path(outputPath));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}相关文章:

头哥实践平台之MapReduce基础实战
一. 第1关:成绩统计 编程要求 使用MapReduce计算班级每个学生的最好成绩,输入文件路径为/user/test/input,请将计算后的结果输出到/user/test/output/目录下。 先写命令行,如下: 一行就是一个命令 touch file01 echo Hello World Bye Wor…...

Linux基础知识——tmux和vim
Linux基础知识——tmux和vim 文章目录 Linux基础知识——tmux和vim一、tmux1. 功能2. 结构3. 操作 二、vim功能模式操作 一、tmux tmux配置:~/.tmux.conf修改为如下 set-option -g status-keys vi setw -g mode-keys visetw -g monitor-activity on# setw -g c0-cha…...
Java Web——TomcatWeb服务器
目录 1. 服务器概述 1.1. 服务器硬件 1.2. 服务器软件 2. Web服务器 2.1. Tomcat服务器 2.2. 简单的Web服务器使用 1. 服务器概述 服务器指的是网络环境下为客户机提供某种服务的专用计算机,服务器安装有网络操作系统和各种服务器的应用系统服务器的具有高速…...
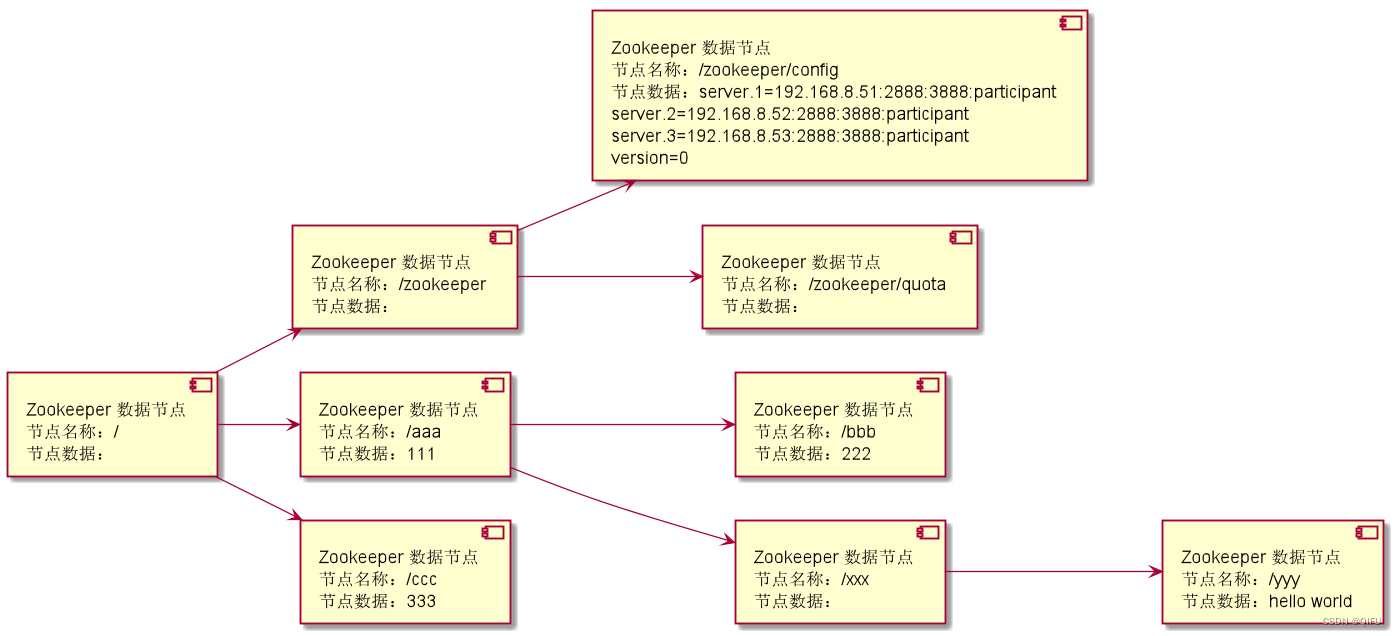
Zookeeper 命令使用和数据说明
文章目录 一、概述二、命令使用2.1 登录 ZooKeeper2.2 ls 命令,查看目录树(节点)2.3 create 命令,创建节点2.4 delete 命令,删除节点2.5 set 命令,设置节点数据2.6 get 命令,获取节点数据 三、数…...

索尼RSV文件怎么恢复为MP4视频
索尼相机RSV是什么文件? 如果您的相机是索尼SONY A7S3,A7M4,FX3,FX3,FX6,或FX9等,有时录像会产生一个RSV文件,而没有MP4视频文件。RSV其实是MP4的前期文件,经我对RSV文件…...
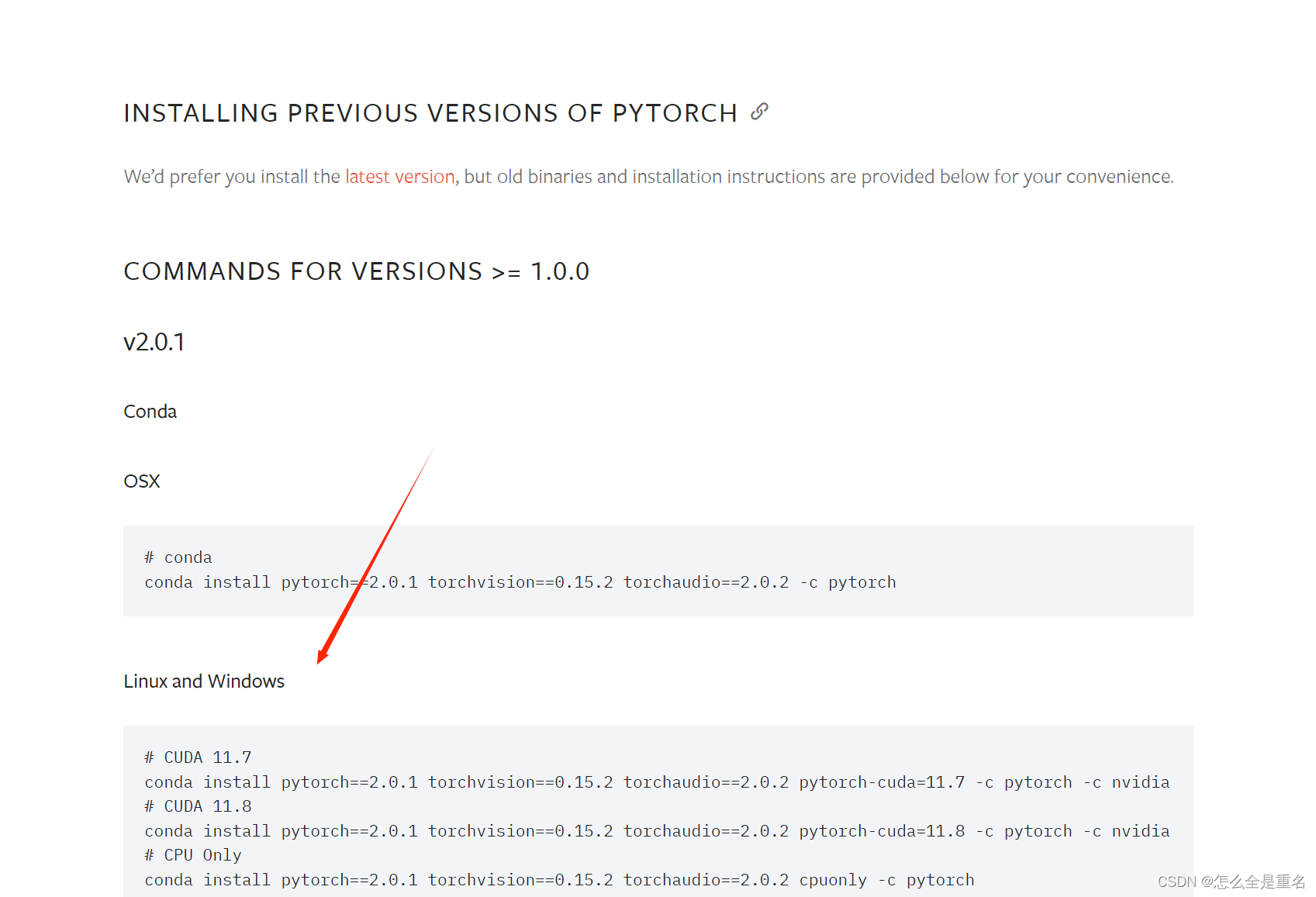
pytorch-gpu(Anaconda3+cuda+cudnn)
文章目录 下载Anaconda3安装,看着点next就行比较懒所以自动添加path测试 cuda安装的时候不能改路径如果出现报错,关闭杀毒软件一直下一步就好取消勾选“CUDA”中的“Visual Studio Intergration”一直下一步即可测试安装成功 cudnn解压后将这三个文件夹复…...
解析数据洁净之道:BI中数据清理对见解的深远影响
本文由葡萄城技术团队发布。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。 前言 随着数字化和信息化进程的不断发展,数据已经成为企业的一项不可或缺的重要资源。然而,这…...
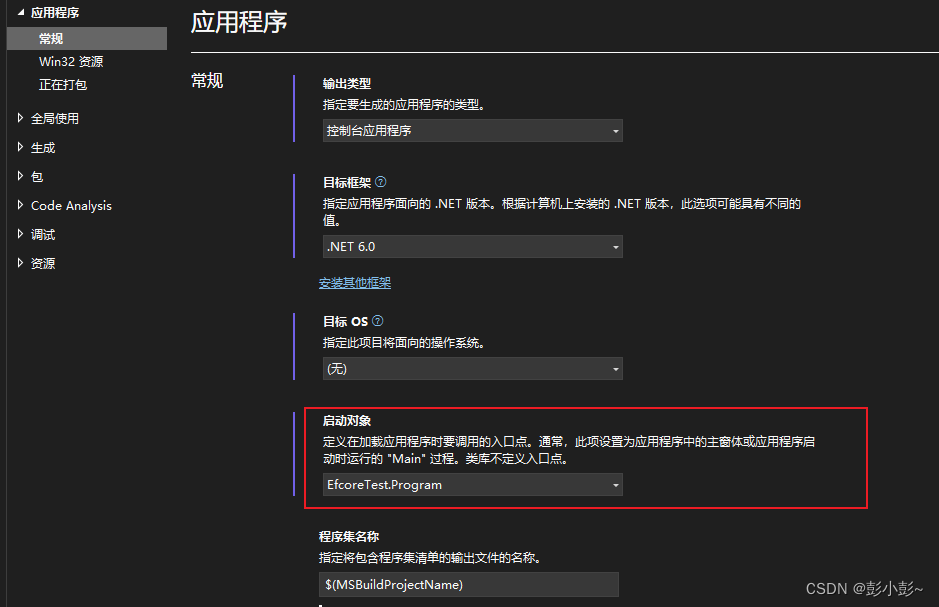
efcore反向共工程,单元测试
1.安装efcore需要的nuget <PackageReference Include"Microsoft.EntityFrameworkCore" Version"6.0.24" /> <PackageReference Include"Microsoft.EntityFrameworkCore.SqlServer" Version"6.0.24" /> <PackageRefere…...

利用IP风险画像强化金融行业网络安全防御
在数字化时代,金融行业日益依赖互联网和技术创新,但这也使得金融机构成为网络攻击的主要目标。为了应对日益复杂的网络威胁,金融机构迫切需要采用先进的安全技术和工具。其中,IP风险画像技术成为提升网络安全的一项重要策略。 1.…...
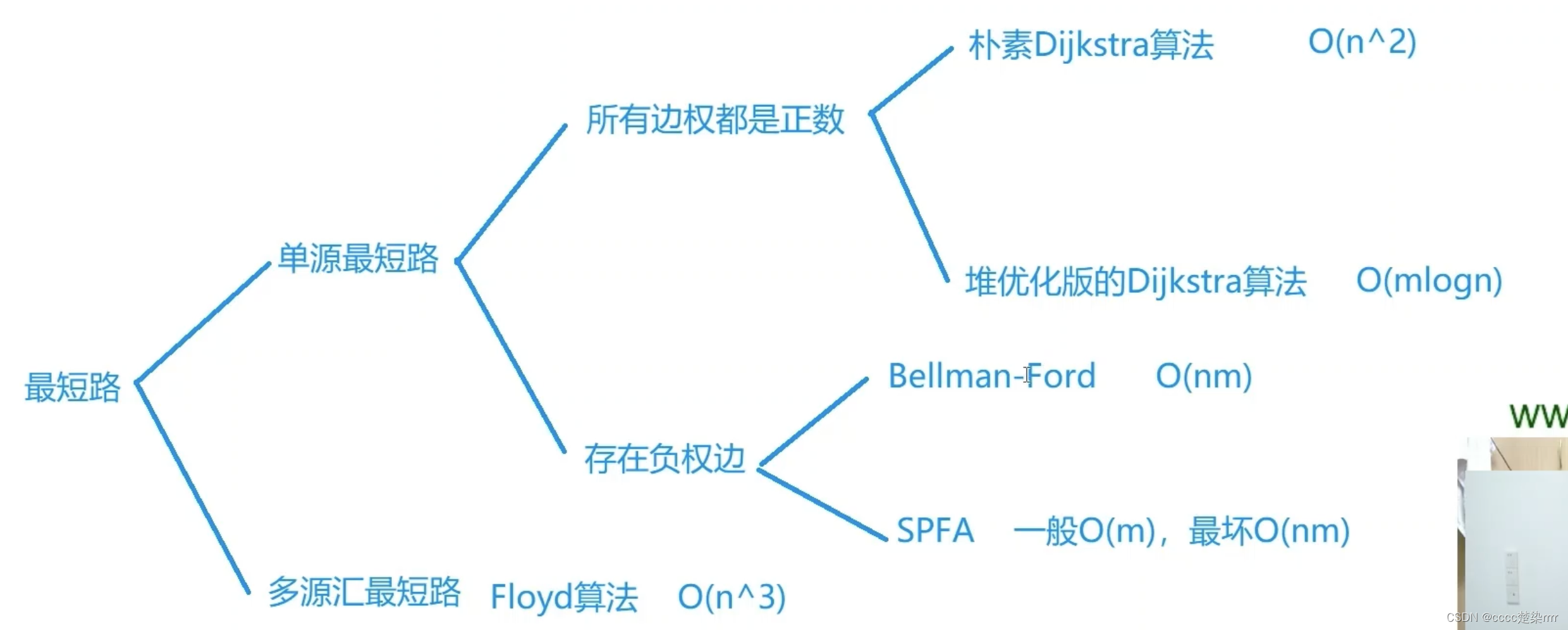
1334. 阈值距离内邻居最少的城市
分析题目两点“阈值距离”、“邻居最少”。 “阈值距离”相当于定了个上界,求节点之间的最短距离。 “邻居最少”相当于能连接的点的数量。 求节点之间的最短距离有以下几种方法: 在这道题当中,n的范围是100以内,所以可以考虑O(n…...

Live800:客服行业的发展历程及未来前景
随着信息技术和互联网的高速发展,客服行业也在不断变革和发展。客服行业是一个服务型的行业,其发展历程也与人们对服务需求的变化密切相关。本文将介绍客服行业的发展历程和未来前景。 客服行业的发展历程 20世纪70年代,客服行业主要以电话服…...
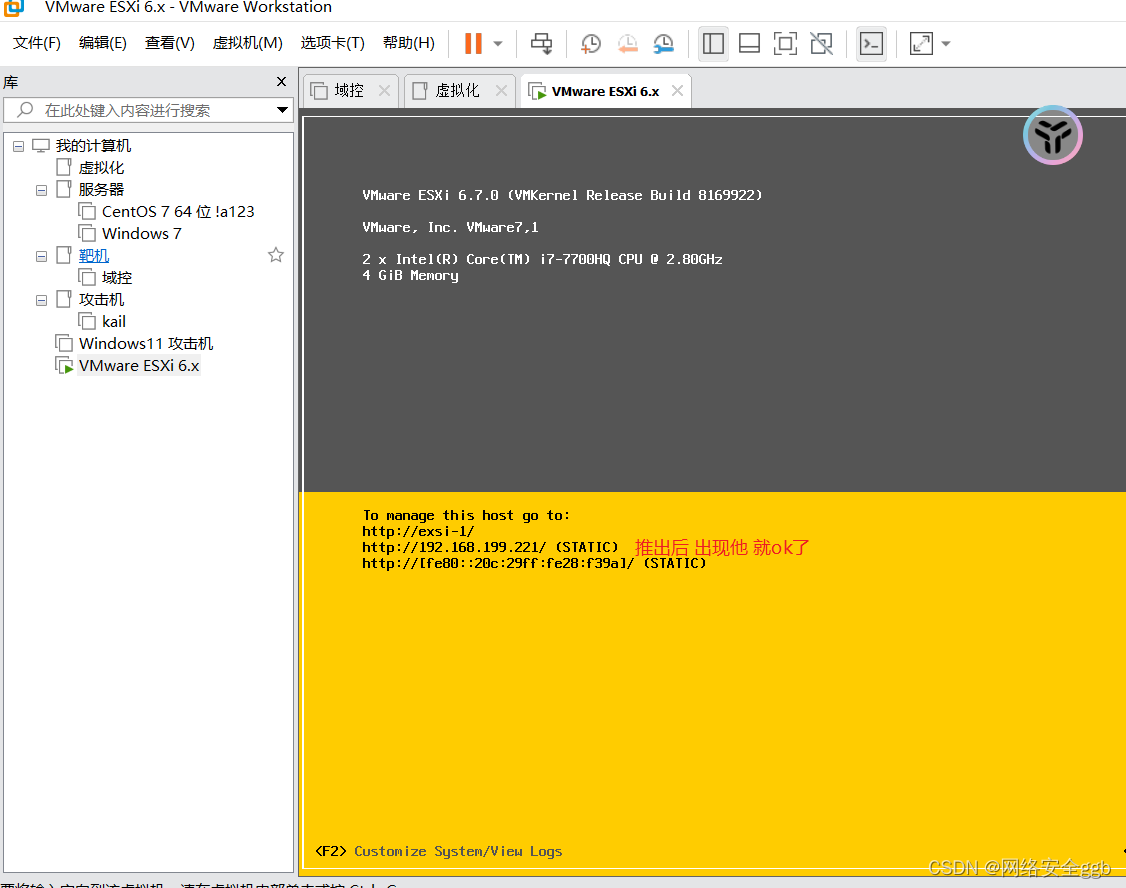
exsi的安装和配置
直接虚拟真实机 vcent server 管理大量的exsi SXI原生架构模式的虚拟化技术,是不需要宿主操作系统的,它自己本身就是操作系统。因此,装ESXI的时候就等同于装操作系统,直接拿iso映像(光盘)装ESXI就可以了。 VMware vCente…...
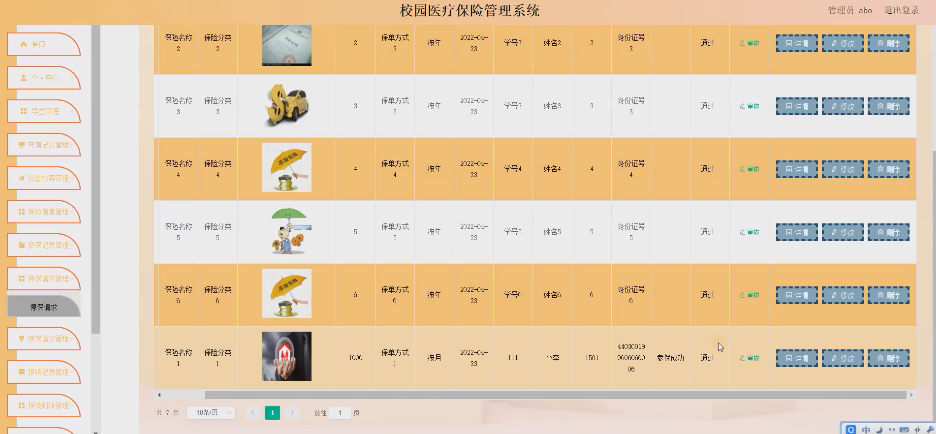
基于springboot实现校园医疗保险管理系统【项目源码】
基于springboot实现校园医疗保险管理系统演示 系统开发平台 在线校园医疗保险系统中,Eclipse能给用户提供更多的方便,其特点一是方便学习,方便快捷;二是有非常大的信息储存量,主要功能是用在对数据库中查询和编程。其…...
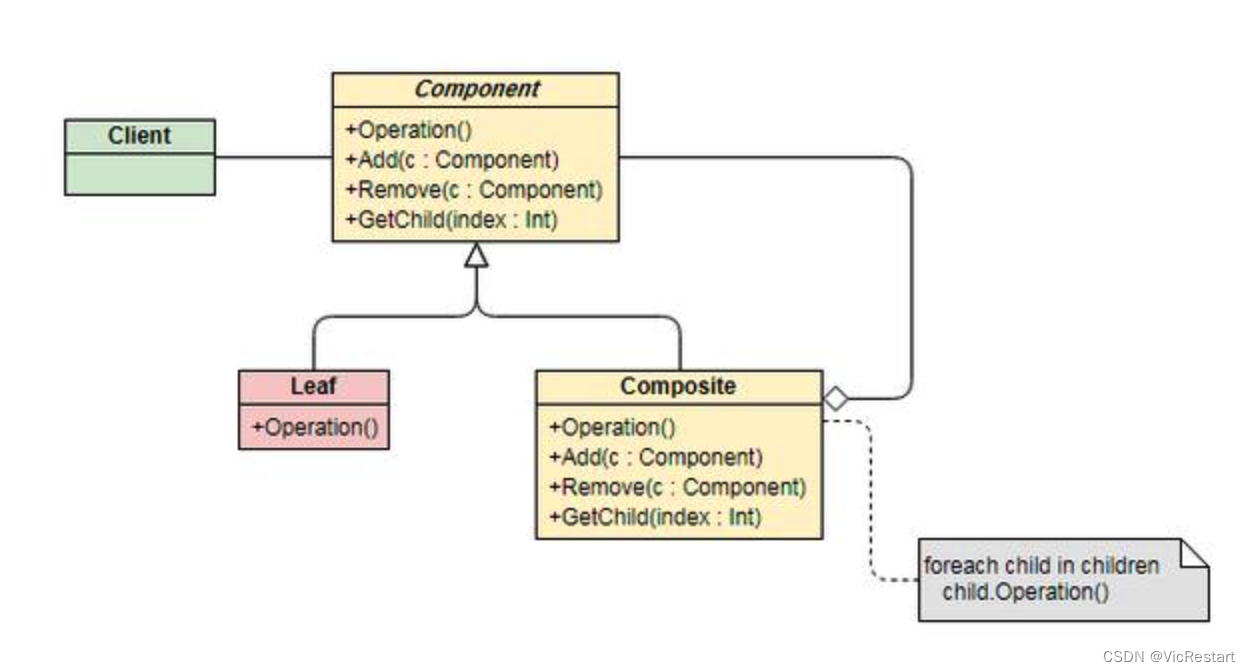
Python 如何实现组合(Composite)设计模式?什么是组合设计模式?
什么是组合(Composite)设计模式? 组合(Composite)设计模式是一种结构型设计模式,它允许客户端使用单一对象和组合对象(对象的组合形成树形结构)同样的方式处理。这样,客…...
编辑器vim和编译器gcc/g++
目录 一、编辑器vim 1、概念 2、基本操作 1、进入vim 2、模式切换 3、命令行模式 4、插入模式 5、底行模式 6、vim 的配置 二、编译器gcc/g 1、概念 2、背景知识 3、gcc/g中的编译链接 1、预处理 2、编译 3、汇编 4、链接 4、函数库 1、静态库 2、动态库 一…...
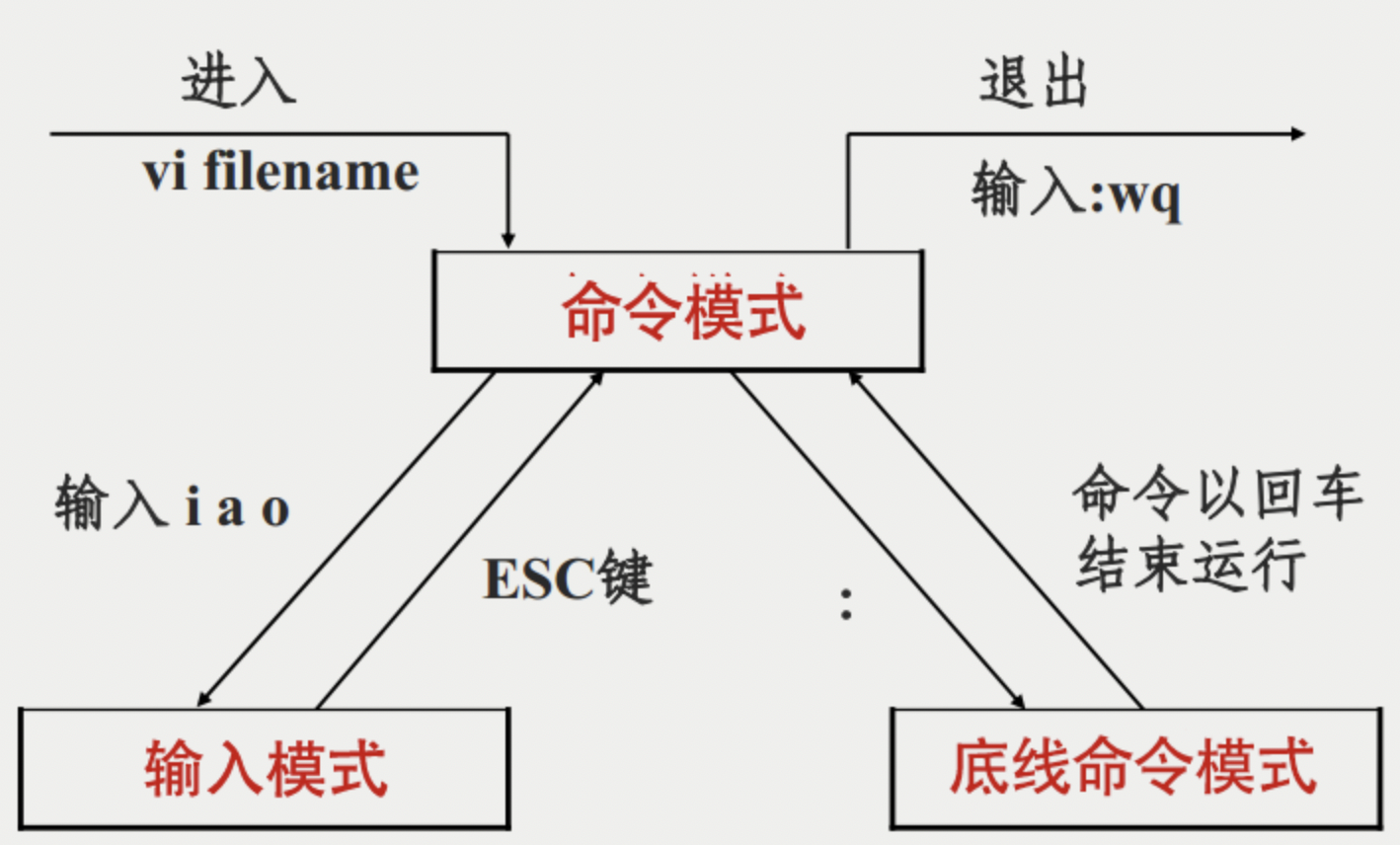
linux 系统下文本编辑常用的命令
一、是什么 Vim是从 vi 发展出来的一个文本编辑器,代码补全、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。 简单的来说, vi 是老式的字处理器,不过功能已经很齐全了,但是还是有可以进步的地方 而…...

3D Gaussian Splatting文件的压缩【3D高斯泼溅】
在上一篇文章中,我开始研究高斯泼溅(3DGS:3D Gaussian Splatting)。 它的问题之一是数据集并不小。 渲染图看起来不错。 但“自行车”、“卡车”、“花园”数据集分别是一个 1.42GB、0.59GB、1.35GB 的 PLY 文件。 它们几乎按原样…...
Spring Boot 整合xxl-job实现分布式定时任务
xxl-job介绍 XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。 xxl是xxl-job的开发者大众点评的许雪里名称的拼音开头。 设计思想 将调度行为抽象形成“调度…...

16.最接近的三数之和
题目来源: leetcode题目,网址:16. 最接近的三数之和 - 力扣(LeetCode) 解题思路: 对数组排序后,枚举第一个值,利用双指针在第一个值固定时的第二三个值。 解题代码:…...

php 插入排序算法实现
插入排序是一种简单直观的排序算法,它的基本思想是将一个数据序列分为有序区和无序区,每次从无序区选择一个元素插入到有序区的合适位置,直到整个序列有序为止 5, 3, 8, 2, 0, 1 HP中可以使用以下代码实现插入排序算法: functi…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低 在构建依赖多个大语言模型的应用时,…...

机器学习与深度学习在社交媒体心理健康检测中的权衡与选择
1. 项目概述:当AI遇见心灵,社交媒体心理健康检测的技术十字路口在社交媒体成为我们数字生活延伸的今天,海量的文本数据无意中记录着用户的情感波动与心理状态。作为一名长期混迹于数据科学和自然语言处理(NLP)一线的从…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

Java网络编程基础分享
在学习 Java 的过程中,网络编程是非常重要的一环。无论是后端开发、分布式系统、即时通讯、文件传输,还是游戏服务、物联网设备,都离不开网络通信一、计算机网络基础1.1 什么是计算机网络把不同地理位置、具有独立功能的计算机,通…...

终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式
终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常在多个窗口间来回切换,浪费宝…...

Windows多显示器DPI缩放终极解决方案:告别模糊显示,享受清晰视觉体验
Windows多显示器DPI缩放终极解决方案:告别模糊显示,享受清晰视觉体验 【免费下载链接】SetDPI 项目地址: https://gitcode.com/gh_mirrors/se/SetDPI 你是不是曾经遇到过这样的困扰?连接多个显示器时,文字和图标大小不一&…...

为 Node.js 后端服务配置 Taotoken 作为大模型统一网关
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 Node.js 后端服务配置 Taotoken 作为大模型统一网关 在构建基于大语言模型的 Node.js 后端服务时,直接对接多个模型…...

后端开发者体验 AI 前端:用 TinyVue 做一个智能业务表单 Demo
摘要 作为 Java 后端开发者,我平时更多关注接口、SQL 和业务逻辑,但后台系统里也绕不开表单、列表和报表页面。本文结合 OpenTiny NEXT 学习体验,用 TinyVue 做一个智能业务表单 Demo,聊聊 AI 前端对后端开发者到底有没有实际帮助…...