大模型的全面回顾,看透大模型 | A Comprehensive Overview of Large Language Models
大模型的全面回顾:A Comprehensive Overview of Large Language Models
返回论文和资料目录
论文地址
1.导读
相比今年4月的中国人民大学发表的大模型综述,这篇综述角度更侧重于大模型的实现,更加硬核,更适合深入了解大模型的一些细节。
2.介绍
下图给出了近几年开源或闭源的大模型趋势图。可以看到除了2023年闭源的大模型工作下降了,这些年的大模型不管开源,闭源,还是总量都是稳步提升。不过这篇论文还有很多大模型工作没有考虑到,例如,百川大模型、ChatGLM3和浦育大模型等等。今年以来,真实场景是百模大战!

下图给出了作者看到近几年代表性大模型的时间轴。

下图是大模型的全面回顾结构图,包括1. 训练 2. 推理 3. 评估 4. 应用 5. 挑战。

3.相关基础
1.Tokenization(词元编码)
Tokenization做的事情是把正常的文本转化为输入大模型的id列表list,是一个必要的预处理步骤。读者可以参考这个博客进行学习。
2. Attentions(注意力机制)
Self-Attention:原Transformer的注意力机制。
Cross Attention:Cross-attention的输入来自不同的序列,Self-attention的输入来自同序列。例如,可以讲图片编码后信息得到Q,文本编码后得到K,V。然后和Self-attention一样的方式计算得到结果。
Full Attention:原Transformer的注意力机制,与Self-attention一样。
Sparse Attention:原本self-attention中会得到一个full-attentions的score矩阵,表示了每个词与其他词之间的关系。在Sparse Attention中会把一些词与词之间的score置为0,通过这种方式可以扩展模型的上下文长度。例如可以进行下面这种方式处理。

其中
Flash Attention:注意力机制原理和Self-Attention一样,没有变化。改变的是Attention在gpu中的计算方式,可以减少访问内存的数据量。计算结果是一样的。
3. Encoding Positions(位置编码)
在tokenization后模型给输入文本加入位置编码,这步是必需要的(虽然最近也有研究说不重要)。有两种思路:
- 绝对的:这是添加序列顺序信息的最直接的方法,通过在将其传递给注意模块之前,为序列的每个位置分配一个唯一的标识符。例如Alibi
- 相对编码:为了传递在序列中不同位置出现的不同标记的相对依赖性信息,通过某种学习来计算相对位置编码。两种著名的相对编码类型是RoPE
4.Activation Functions(激活函数)
常见的激活函数如下:
- ReLU:ReLU(x) = max(0, x)
- GeLU:是ReLU, Dropout和Zoneout的组合,是在LLM中最广泛使用的。
- GLU:LLM会使用GLU(x, W, V, b, c) = (xW + b) ⊗ σ(xV + c) 的变体,包括 1. ReGLU(x, W, V, b, c) = max(0, xW + b)⊗, 2. GEGLU(x, W, V, b, c) = GELU(xW + b) ⊗ (xV + c) , 3. SwiGLU(x, W, V, b, c, β) = Swishβ(xW + b) ⊗ (xV + c)
5.Layer Normalization(正则化)
-
LayerNorm:和BatchNorm不同的维度。其中 n n n是 l l l层中神经元的数量, a i l a^l_i ail是 l l l层中 i i i个神经元的输入之和。
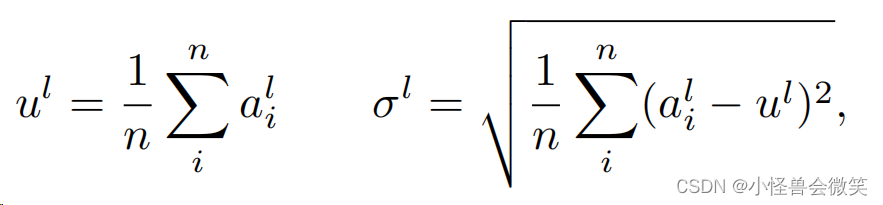
-
RMSNorm:基于LayerNorm变化而来,提出通过使用一种计算效率高的快速交换重定中心不变性的标准化技术,可以获得与LayerNorm相同的性能效益。
LayerNorm给出了对第 l l l层的归一化求和输入,如下所述

其中 g i l g^l_i gil是增益参数。RMSNorm将一个 l i l_i li修改为

-
Pre-Norm and Post-Norm:注意这两个不是一个Normalization技术,而是指在残差连接前还是连接后进行Normalization。通常称原本在Transformer中提出的在res后的叫Post-Norm: x t + 1 = N o r m ( x t + F t ( x t ) ) x_{t+1}=Norm(x_t+F_t(x_t)) xt+1=Norm(xt+Ft(xt)),顺序如下图所示。

最近发现在顺序变为Pre-Norm: x t + 1 = x t + F t ( N o r m ( x t ) ) x_{t+1}=x_t+F_t(Norm(x_t)) xt+1=xt+Ft(Norm(xt)),可以训练更稳定,顺序如下图所示,需要注意的是这里res连接的是LN前的输出和attention的输出。

-
DeepNorm:解决早期的层比底部有更大的梯度的问题。
6. Distributed LLM Training(LLM分布式训练)
在多机多卡上训练过大模型的应该了解,如何分布式并行训练是门学问!
假设我们有8个gpu,一个batch为16条数据,模型主要有8层decoder结构,decoder的隐藏层维度是512。
-
数据并行(Data Parallelism)
在数据并行中,我们将整个训练数据划分成多个小批次,每个GPU负责计算其中一部分数据的梯度。具体来说,对于8个GPU和一个batch size为16的情况,每个GPU将处理2条数据。在计算完成后,梯度将被汇总,模型参数将被更新。这样一来,整个batch的计算过程被分散到各个GPU上,加速了训练过程。 -
张量并行(Tensor Parallelism)
张量并行是一种将模型的权重划分到不同的GPU上进行计算的策略。在我们的例子中,8层decoder结构中的权重可以被分割到不同的GPU上。每个GPU负责计算其中一部分权重对应的梯度。这样的划分可以在较小的GPU上运行大型模型。 -
管道并行(Pipeline Parallelism)
管道并行将模型的不同部分分配给不同的GPU,每个GPU负责处理整个模型中的一部分。在我们的例子中,每个GPU计算一个decoder层的结果,然后将其传递给下一个GPU。这样的流水线处理可以减小每个GPU上的模型规模,从而使得更大的模型能够适应有限的GPU内存。 -
模型并行(Model Parallelism)
模型并行是张量和管道并行的结合。在这种策略中,模型被分解成多个部分,每个部分分配给不同的设备进行计算。这种策略通常用于较大的模型,其中一个GPU无法容纳整个模型。 -
3D并行(3D Parallelism)
3D并行是一种结合数据并行、模型并行以及时间并行(通常用于处理序列数据)的综合并行策略。在我们的例子中,可以考虑在时间维度上(例如,序列的不同时间步)进行并行化,进一步提高训练速度。 -
优化器并行(Optimizer Parallelism)
优化器并行,也称为零冗余优化器,实现了优化器状态、梯度和参数在设备之间的划分,以降低内存消耗,同时尽可能地降低通信成本。这种策略在处理大型模型时尤为有用。
7.常用库
训练
- Transformers
Transformers 是Hugging Face开发的一款强大的自然语言处理(NLP)库。它提供了各种预训练的模型,涵盖了从文本生成到情感分析等多个任务,为NLP社区提供了丰富的资源。
- DeepSpeed
DeepSpeed 是由Microsoft Research开发的深度学习训练库,旨在提高大规模模型的训练速度和效率。其特点包括混合精度训练、模型并行化和数据并行化等。
- Megatron-LM
Megatron-LM 是NVIDIA Research开发的一个大规模深度学习库,专注于大型语言模型的训练。它支持模型并行和数据并行,并针对多GPU系统进行了优化。
- JAX
JAX 是由Google Research推出的一个数值计算库,它能够自动求导并进行高性能的GPU/TPU加速。JAX的特点在于其简洁的API和对函数式编程的支持。
- Colossal-AI
Colossal-AI 是一款面向大规模模型的深度学习训练库。它支持分布式训练、模型并行和数据并行,旨在解决训练大型模型时的性能瓶颈。
- BMTrain
BMTrain 是一个用于医学图像分割任务的深度学习训练库。它提供了一套专门设计的工具,以应对医学领域中数据复杂性和任务特殊性。
- FastMoE
FastMoE 是慕尼黑大学的研究团队推出的深度学习库,专注于快速的深度模型训练。它使用了Mixture-of-Experts(MoE)结构,以提高训练速度。
框架
- MindSpore
MindSpore 是华为开发的深度学习框架,支持数据并行和模型并行,同时提供了易用的Python API和图模式训练。
- PyTorch
PyTorch 是由Facebook开发的深度学习框架,以其动态计算图和直观的API而闻名。PyTorch广泛应用于学术界和工业界,支持动态图和静态图。
- TensorFlow
TensorFlow 是由Google开发的深度学习框架,支持静态图和动态图,广泛用于深度学习研究和实际应用。
- MXNet
MXNet 是一个开源的深度学习框架,具有动态图和静态图的优势。MXNet支持多种编程语言,并在训练大型模型时表现出色。
8.Data PreProcessing(数据预处理)
- 质量过滤:方法①基于分类的,训练一个模型判断质量好坏②基于启发的,人工确定一些规则进行过滤,比如语言、指标、统计数据和关键字。
- 重复数据删除
- 隐私减少
9. Architectures(架构)
- Encoder Decoder:transformer
- Causal Decoder:decoder-only
- Prefix Decoder:先encoder,再decoder
10.模型微调
模型微调框架如下图所示:

对齐微调
在大规模语言模型(LLMs)的生成过程中,存在生成错误、有偏见和有害文本的问题。为了使这些模型更加有益、真实和无害,研究人员通过人类反馈来进行模型对齐。对齐包括让LLMs生成意外的响应,然后通过更新它们的参数来避免这些响应,从而确保模型生成的文本符合人类的意图和价值观。
Criteria for Aligned Models: HHH - Helpful, Honest, Harmless:一个被定义为“对齐”的模型必须符合三个标准,即有帮助(Helpful)、真实(Honest)和无害(Harmless),或者称之为“HHH”标准。这确保了LLMs的操作符合人类的意图和价值观。
Reinforcement Learning with Human Feedback (RLHF) for Alignment:研究人员采用强化学习与人类反馈(RLHF)来进行模型对齐。在RLHF中,通过对演示进行微调的模型进一步通过奖励建模(RM)和强化学习(RL)进行训练。下面我们简要讨论RLHF中的RM和RL流程。
Reward Modeling (RM):奖励建模训练一个模型,根据人类的偏好使用分类目标对生成的响应进行排名。为了训练分类器,人类根据HHH标准对LLMs生成的响应进行注释。
Reinforcement Learning (RL):结合奖励模型,RL在下一个阶段用于对齐。之前训练过的奖励模型将LLMs生成的响应分为首选和不首选,然后使用近端策略优化(PPO)将模型与之对齐。这个过程迭代重复直到收敛。
通过RLHF,研究人员可以有效地对齐LLMs,确保其生成的文本更符合人类期望,同时保持帮助性、真实性和无害性。这一对齐过程对于确保大型语言模型的实际应用中不会产生潜在的问题至关重要。
高效参数微调方法
在训练大型语言模型(LLMs)时,需要庞大的内存和计算资源。为了在使用更少资源的情况下进行训练,研究人员提出了各种参数高效微调技术,通过更新少量参数来实现微调,可以是添加新参数到模型或更新现有参数。以下是一些常用的方法:
Prompt Tuning
Prompt Tuning是一种引入可训练的提示token嵌入的技术。通过将提示token嵌入作为前缀或自由样式添加到输入token嵌入中,仅对这些嵌入参数进行微调,而保持其余权重冻结。在下游任务的微调过程中,只有这些嵌入参数被训练,其余权重保持不变。这种方法有助于在使用有限资源的情况下更有效地微调语言模型。
Prefix Tuning
Prefix Tuning是另一种参数高效微调方法,它引入了任务特定的可训练前缀向量到Transformer层中。在这种方法中,只有前缀参数被微调,而模型的其余部分保持冻结。输入序列的token可以关注这些前缀,充当虚拟令牌。这样一来,在微调中只需要训练前缀参数,从而实现了对资源的更有效利用。
Adapter Tuning
Adapter Tuning引入了一个编码器-解码器结构,被放置在Transformer块中的注意力和前馈层之后,或并行注意力和前馈层。在这种方法中,只有这些层被微调,而模型的其余部分被保持冻结。通过保持大部分模型参数冻结,
这些参数高效微调方法在资源受限的情况下变得尤为重要。通过针对模型的特定部分进行微调,研究人员能够最大限度地提高性能而不牺牲资源效率。
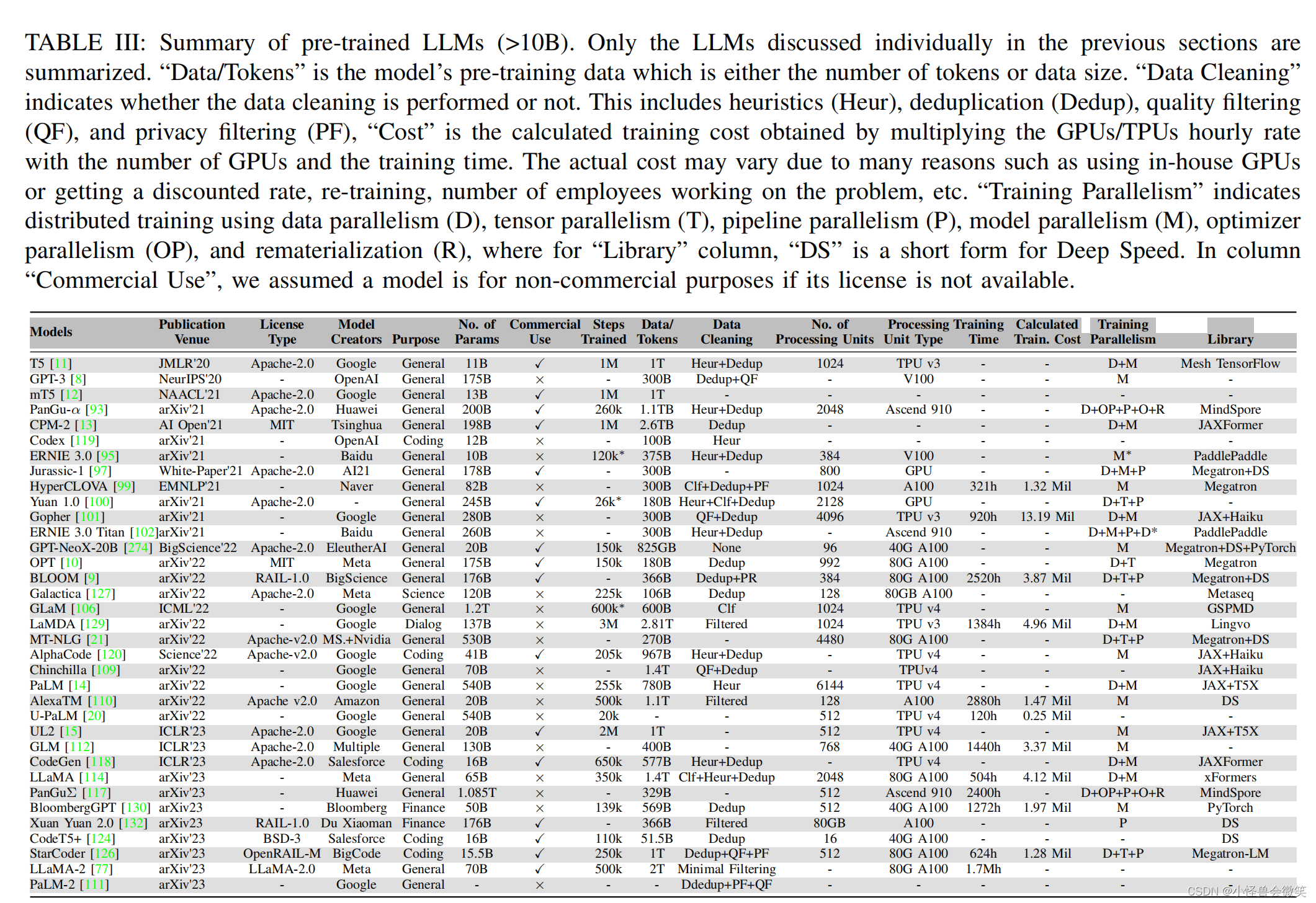
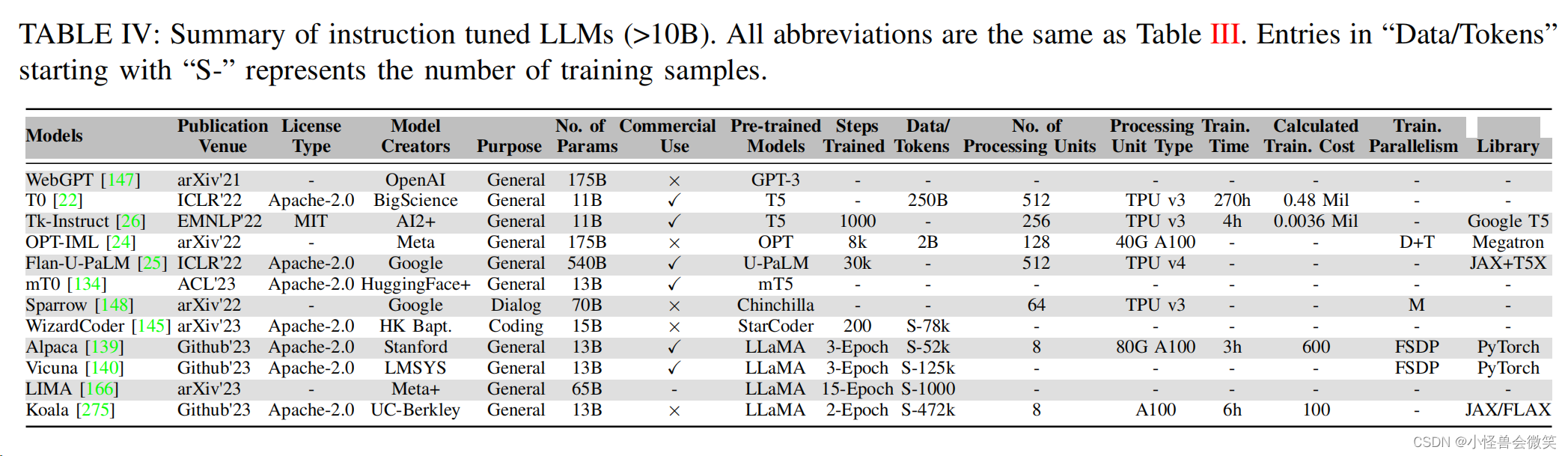
3.大模型
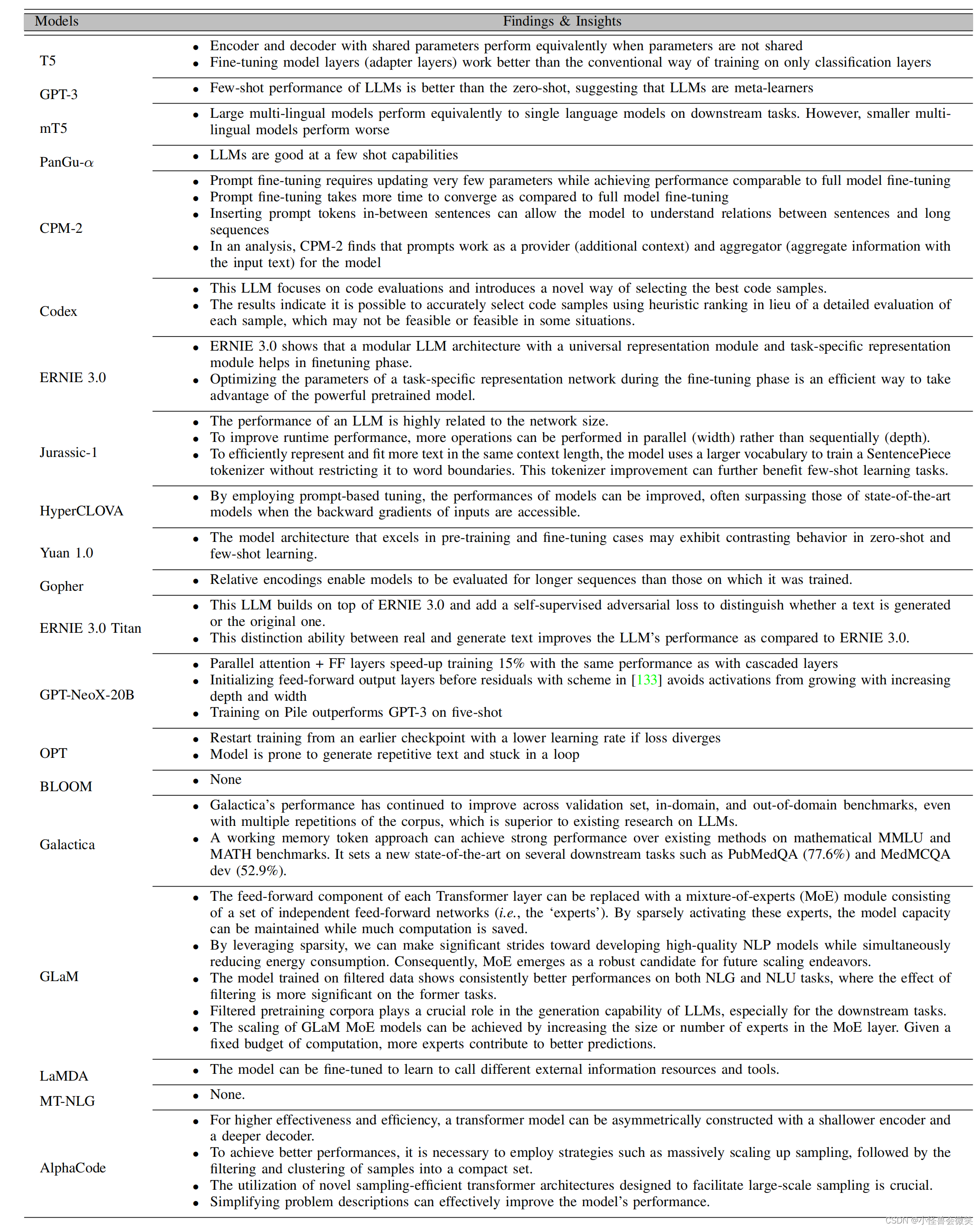
1.常见预训练模型

2.大模型微调
- 人工制作数据集微调
- LLM生成数据集微调
- 对齐人类偏好:RLHF,RLAIF(RL from AI feedback)
- 持续地预训练
3.增加上下文窗口
- 插入位置编码
- 使用高效注意机制
- 不训练进行扩展:参考 LM-Infinite 和 PCW。
4.机器人
被用于计划/规划、操作/行动和导航/走路。
5.多模态
MLLM可以参考另外一篇多模态综述。
6.工具增强的LLM
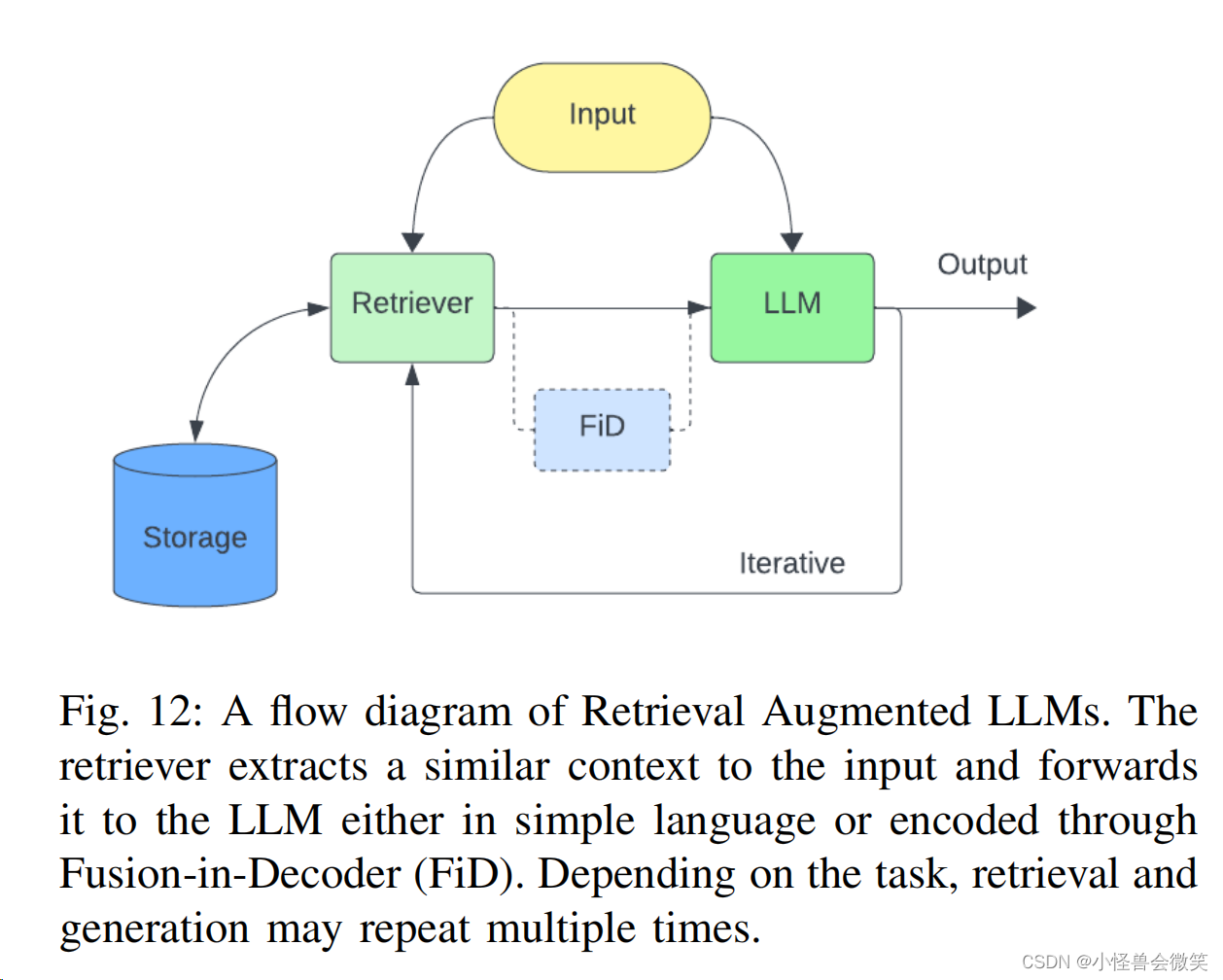
- 检索增强:基于数据库等工具,增强LLM的能力。因为这个比较重要,单独列了个小点。
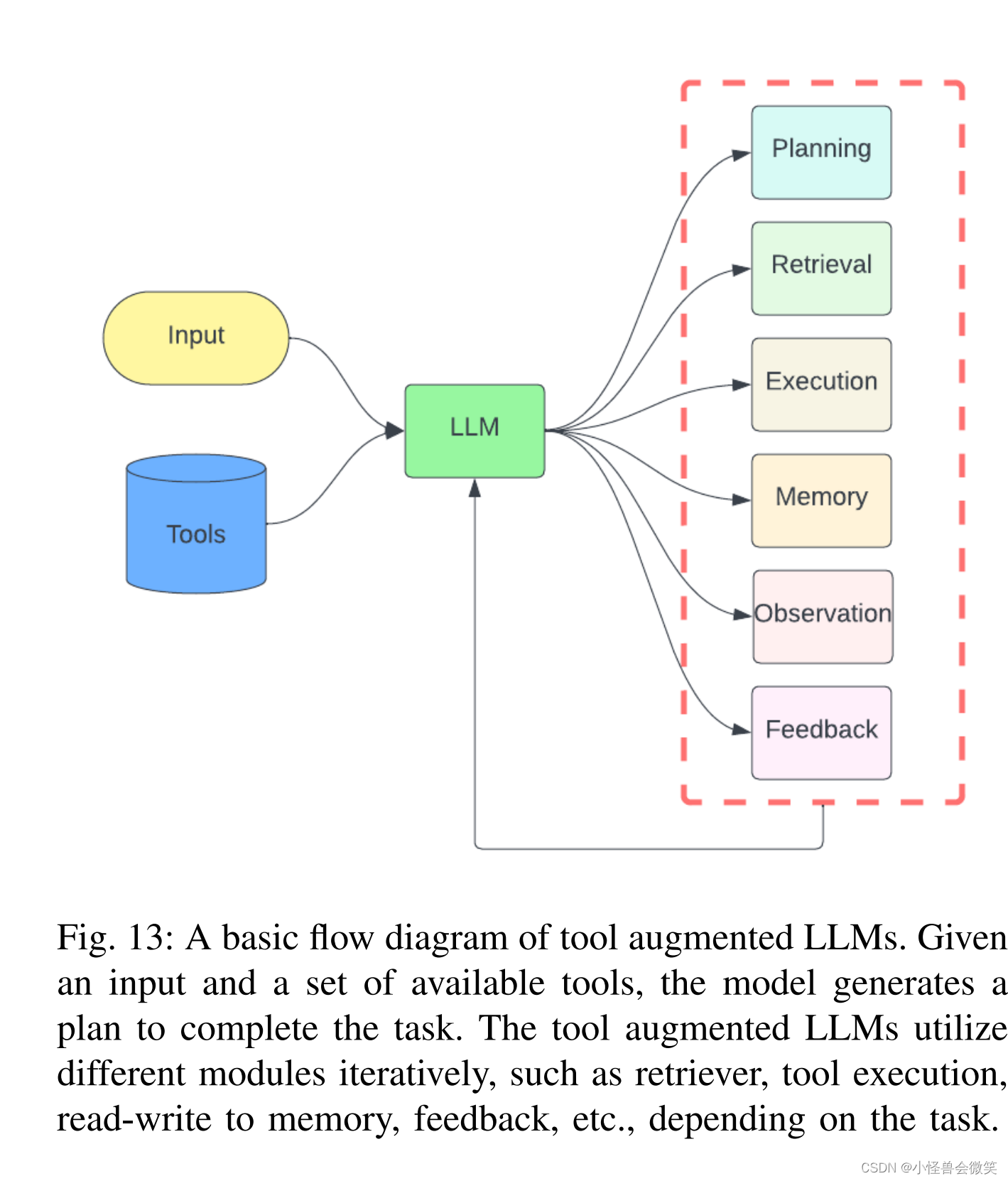
2. 工具增强: 借助外部工具增强。这部分很多花活了。
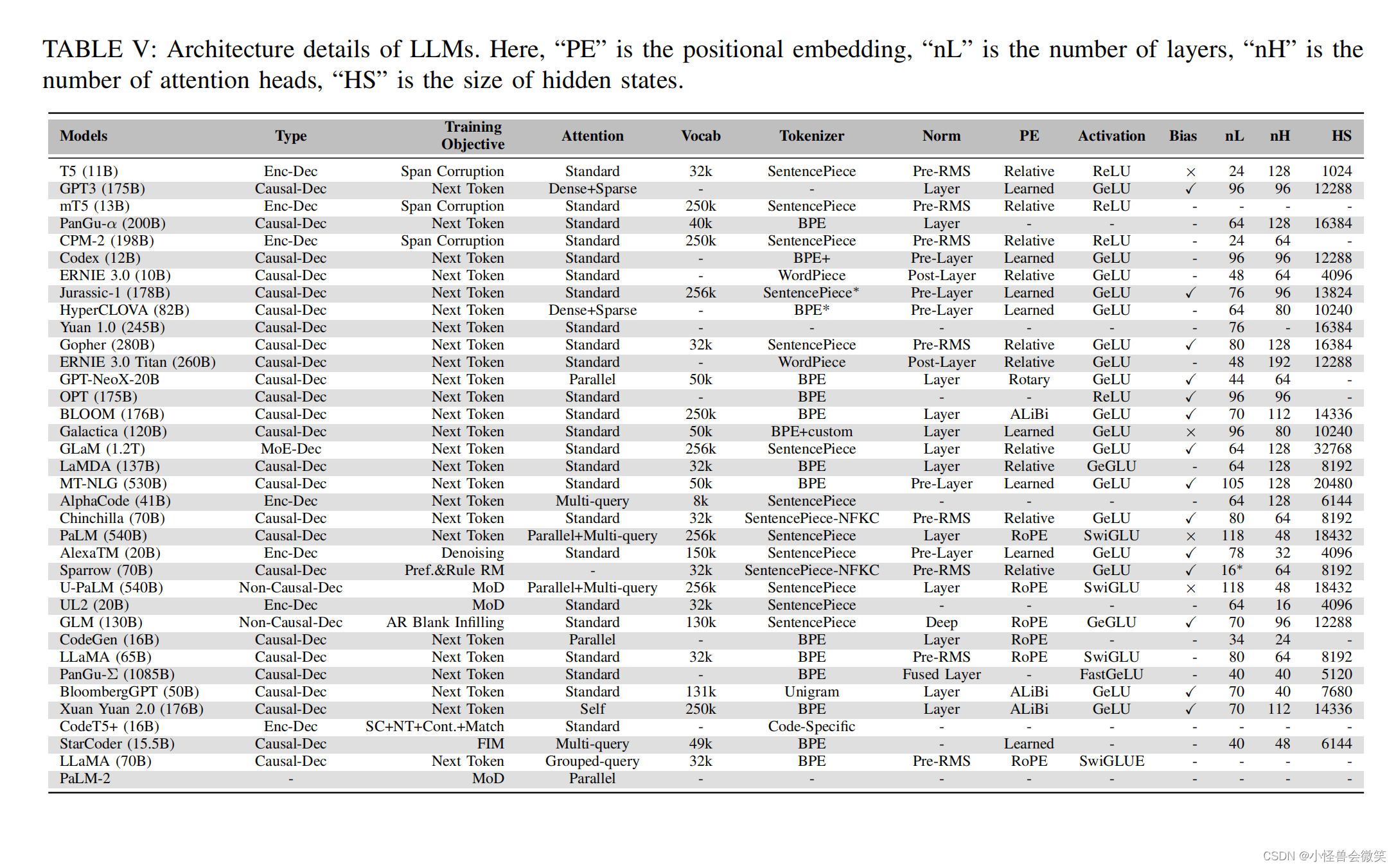
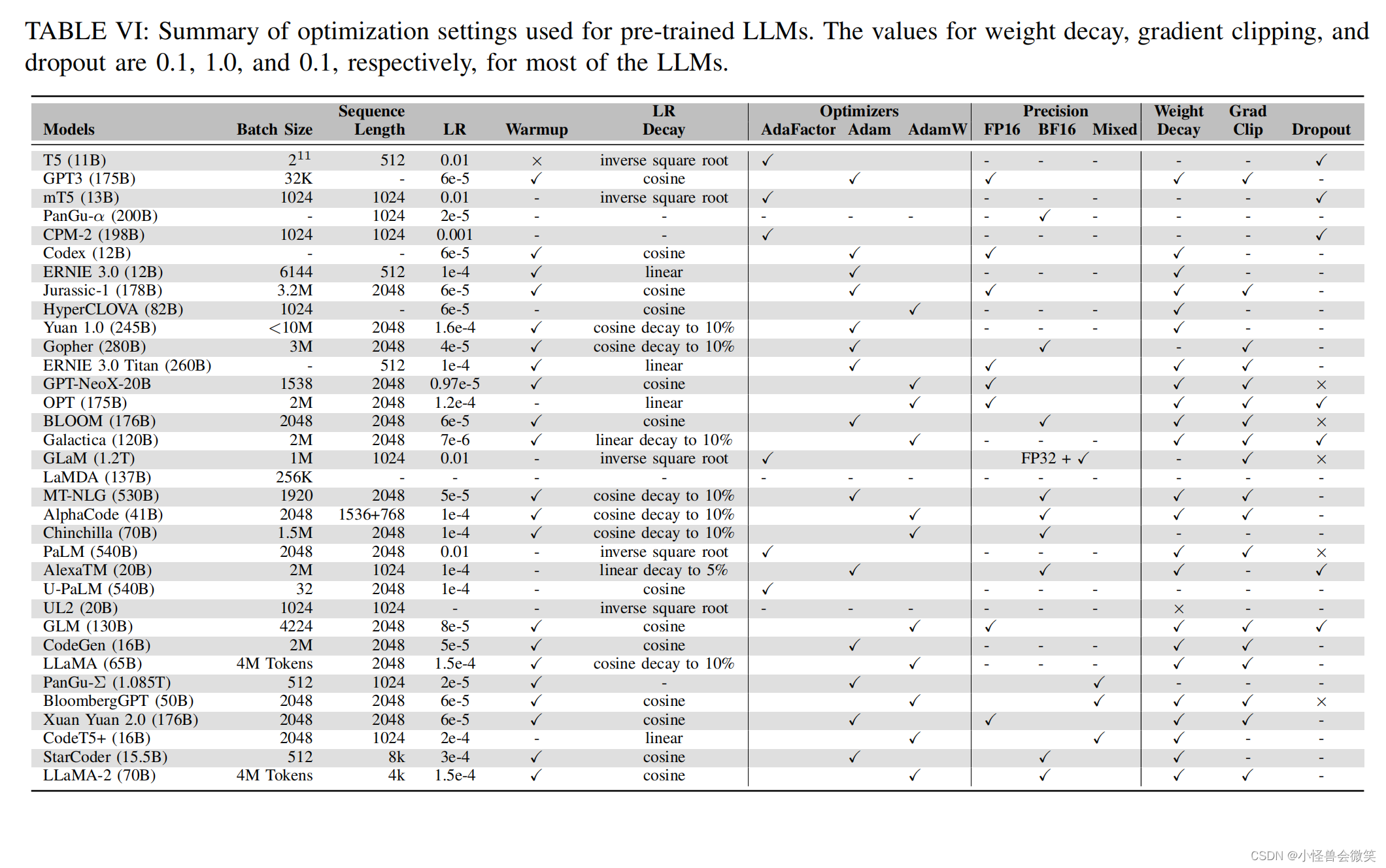
4.模型配置
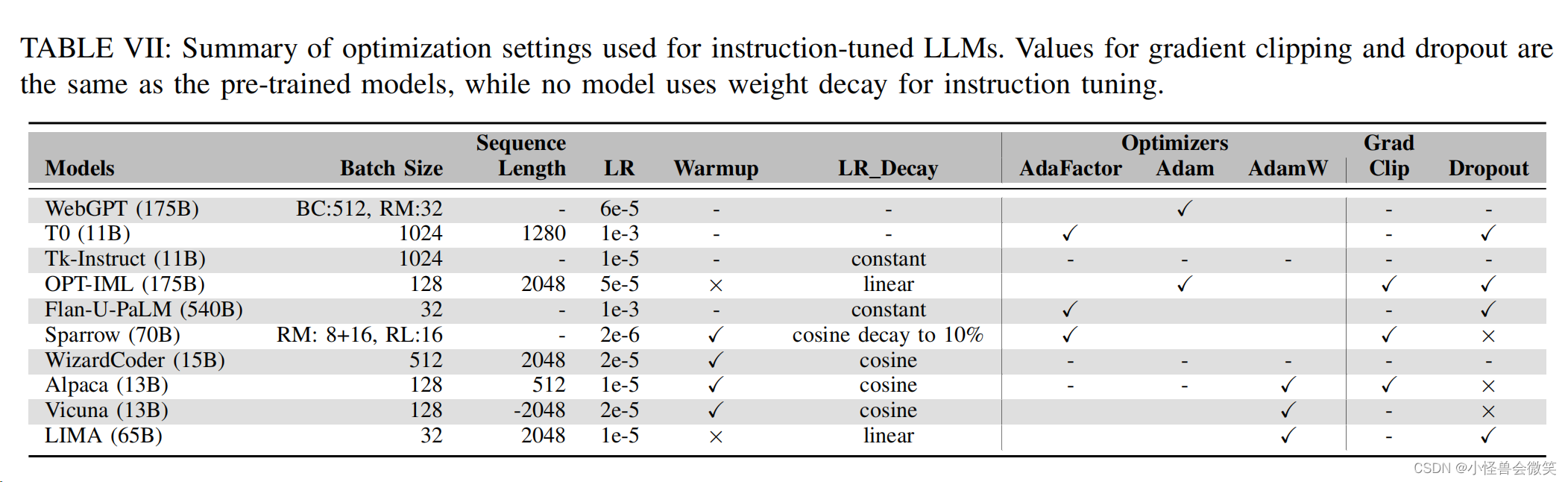
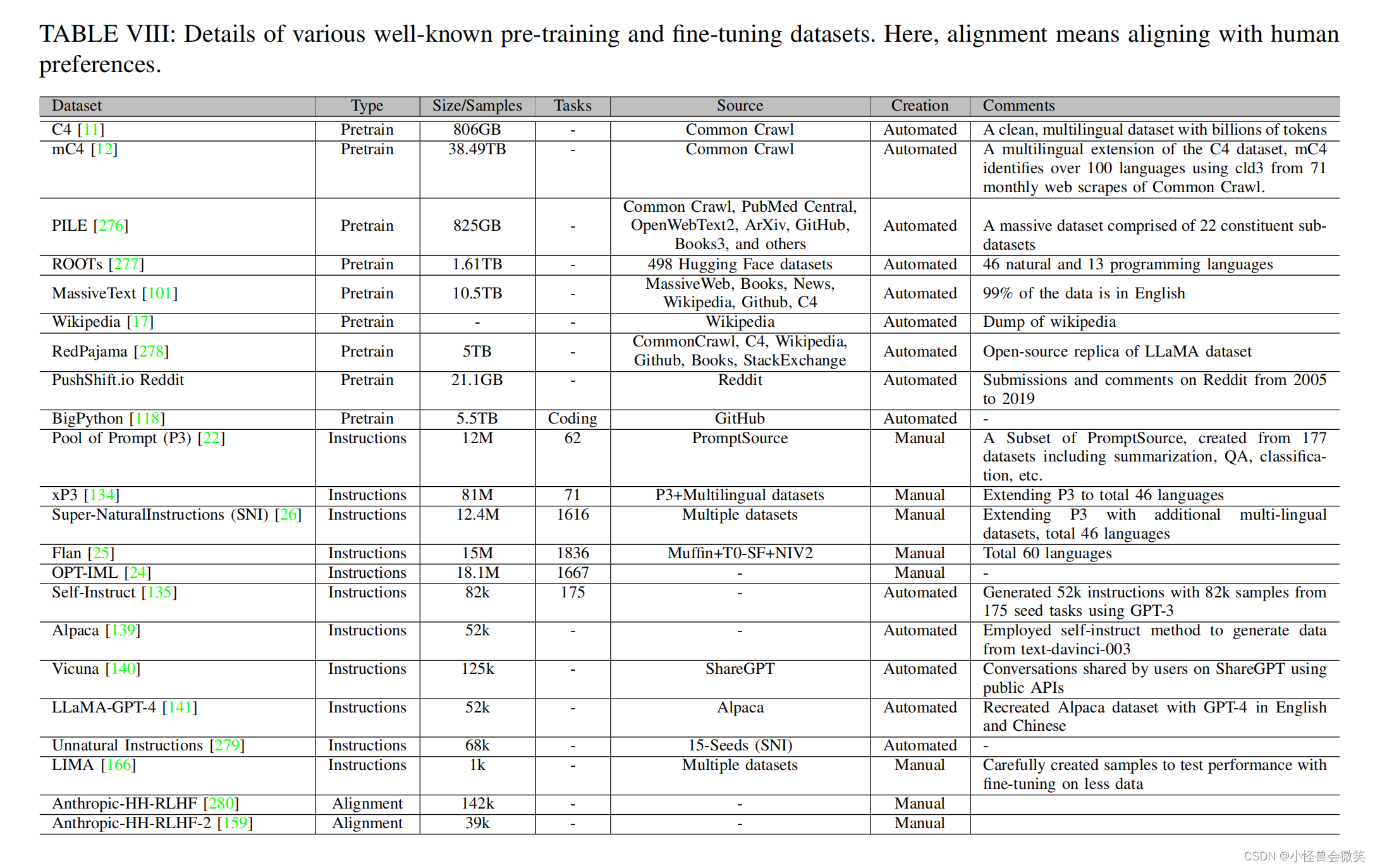
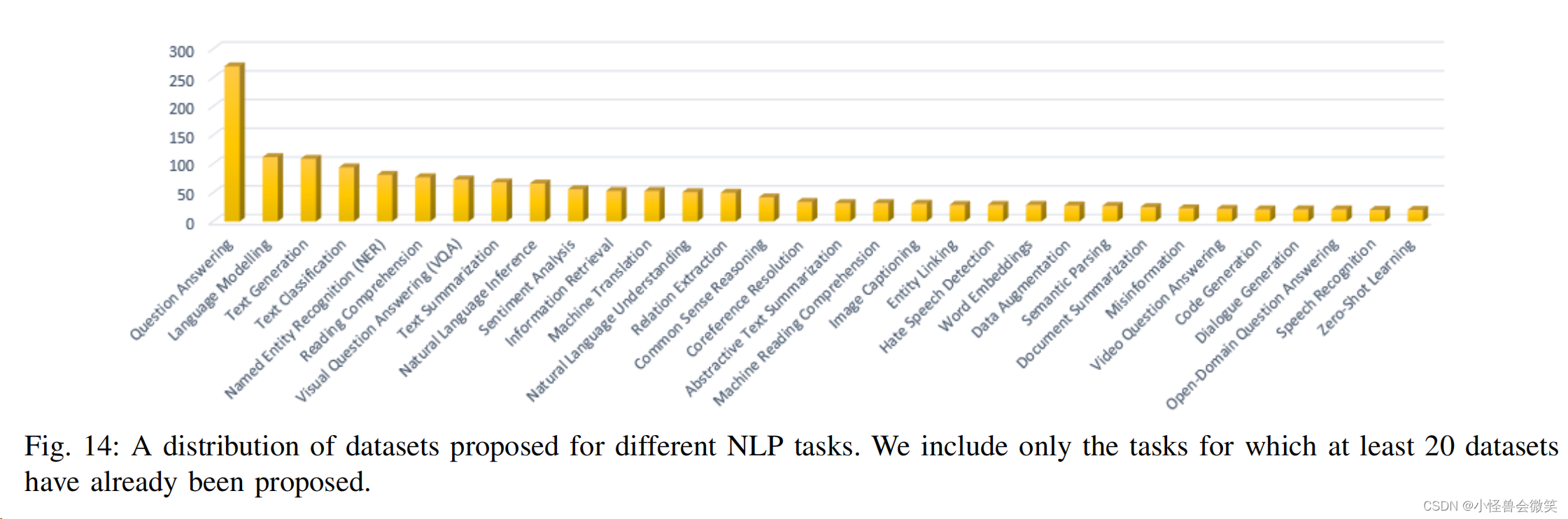
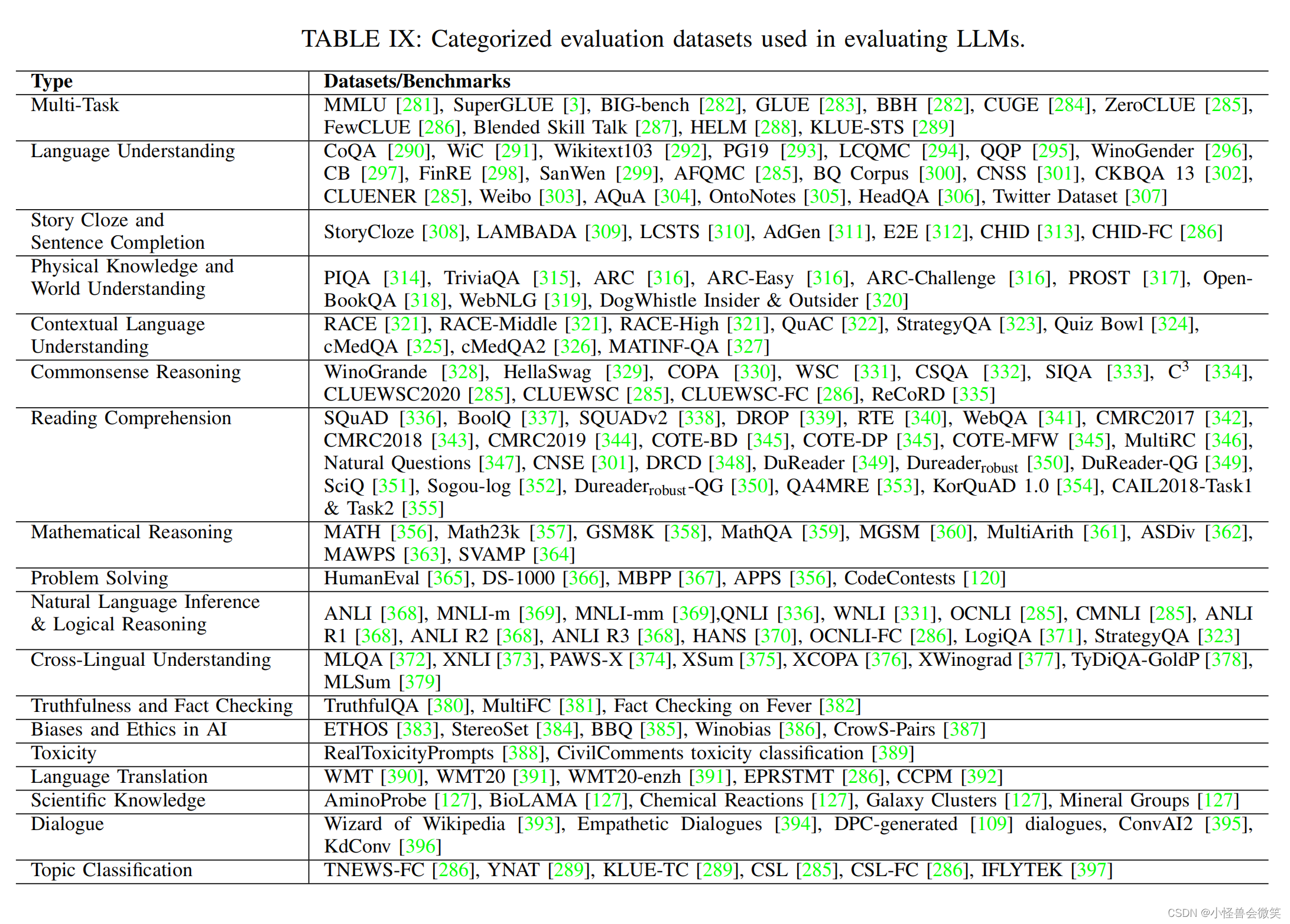
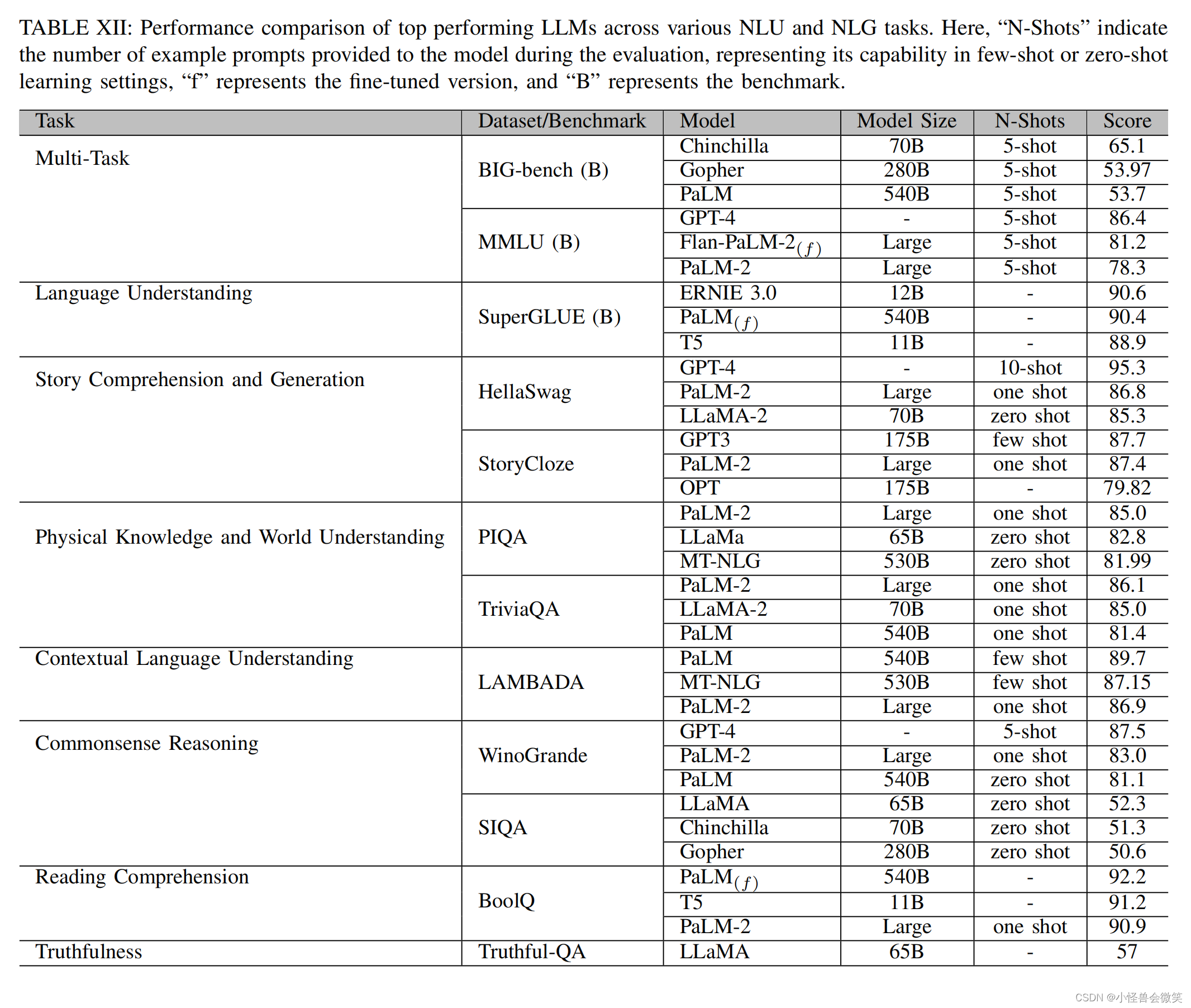
5.数据集和评估
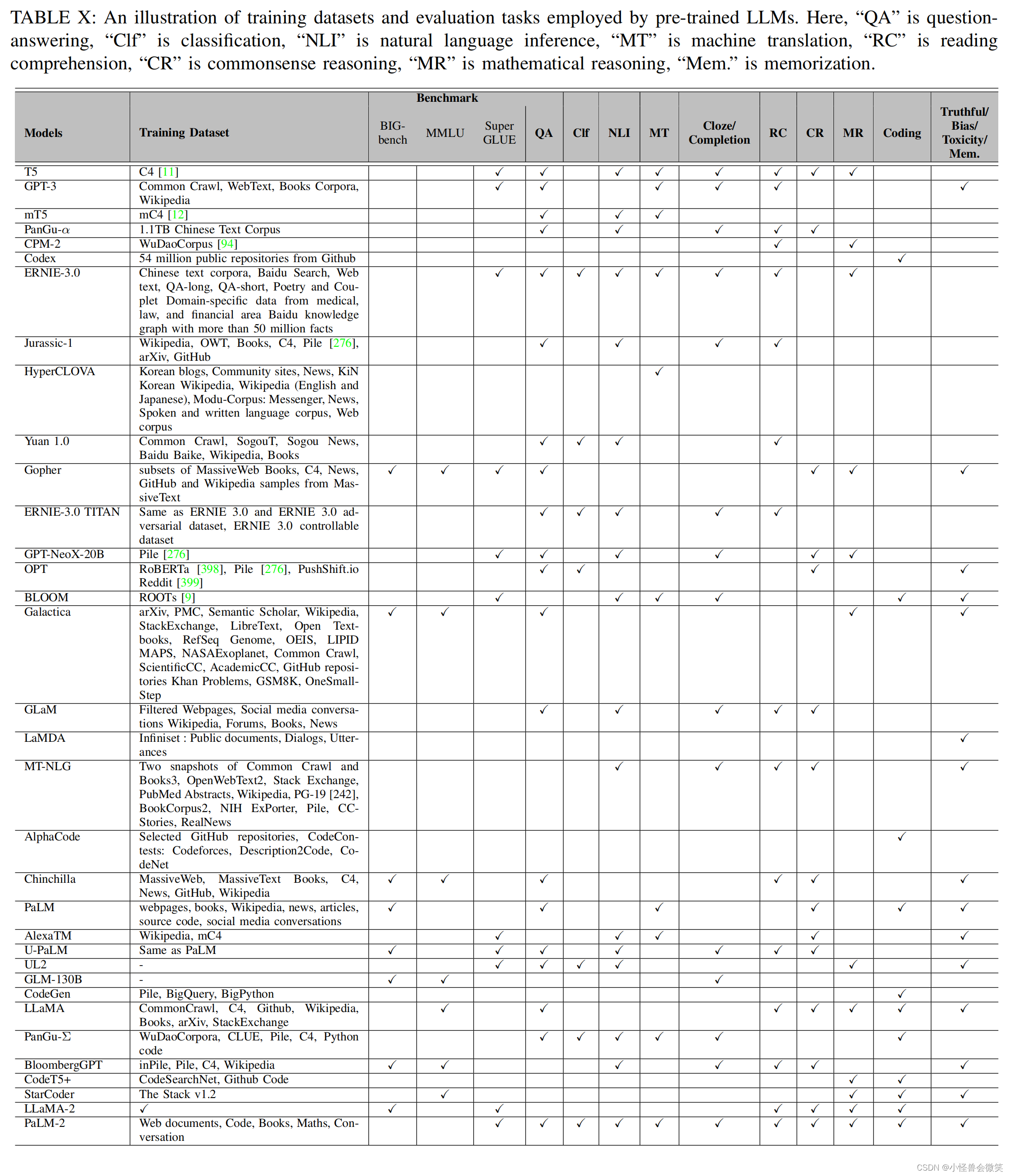
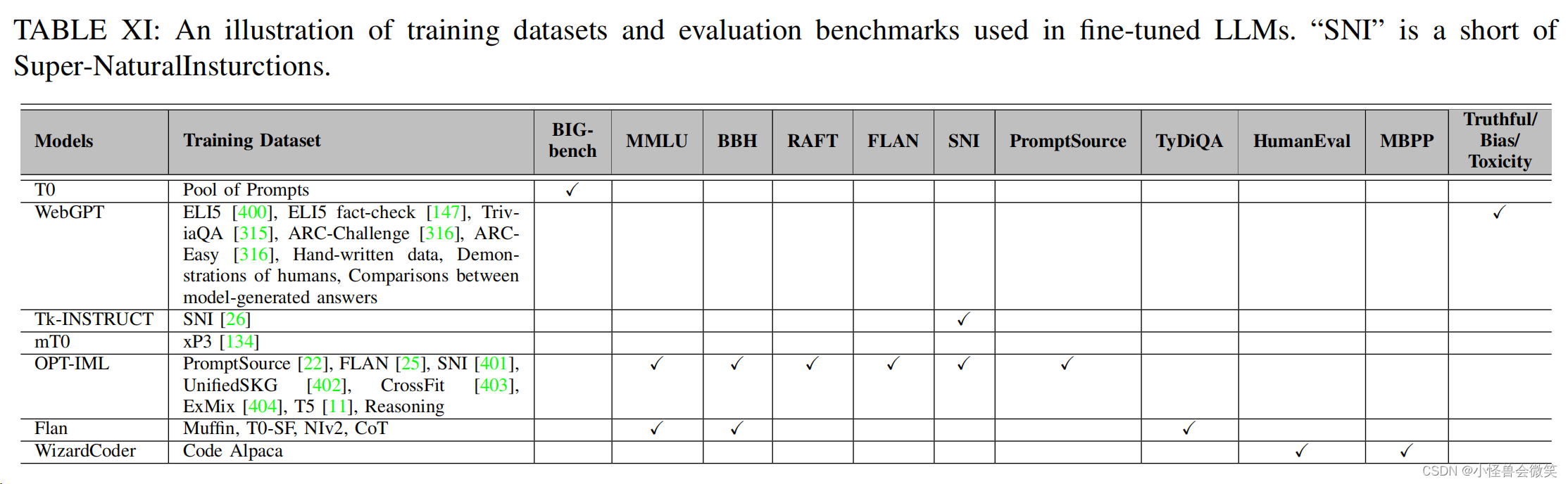
6.总结
未完待续。。。
相关文章:
大模型的全面回顾,看透大模型 | A Comprehensive Overview of Large Language Models
大模型的全面回顾:A Comprehensive Overview of Large Language Models 返回论文和资料目录 论文地址 1.导读 相比今年4月的中国人民大学发表的大模型综述,这篇综述角度更侧重于大模型的实现,更加硬核,更适合深入了解大模型的一…...

【瑞禧分享】碳化硅纳米线 SiC纳米线 <100nm SiC晶须 SiC短纤维
碳化硅纳米线 规格或纯度:线/晶须含量:99% 供应商:西安瑞禧生物 英文名称:SiC Nanowire 别名:碳化硅纳米线,SiC晶须,SiC短纤维,SiC纳米线 英文别名:SiC Nanowire,SiC whiskers,SiC fiber 介绍&#x…...
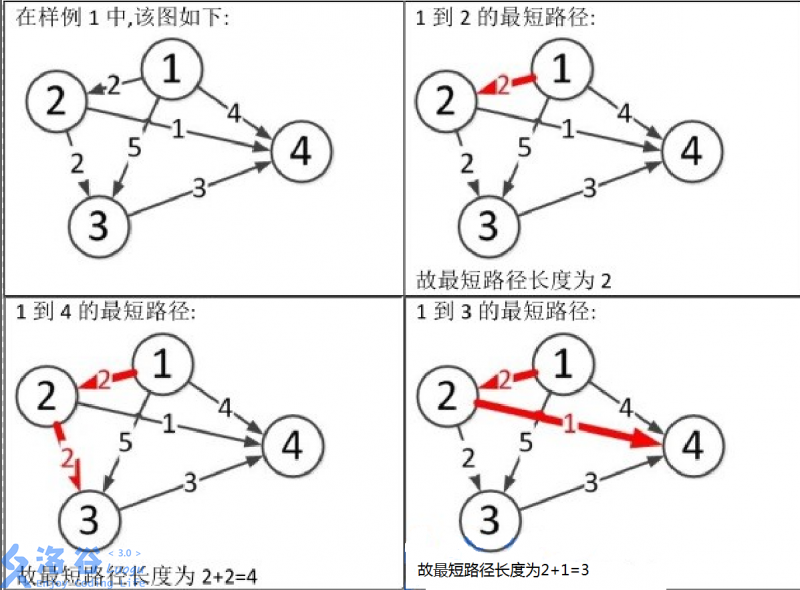
P3371 【模板】单源最短路径(弱化版)
【模板】单源最短路径(弱化版) 题目背景 本题测试数据为随机数据,在考试中可能会出现构造数据让SPFA不通过,如有需要请移步 P4779。 题目描述 如题,给出一个有向图,请输出从某一点出发到所有点的最短路…...
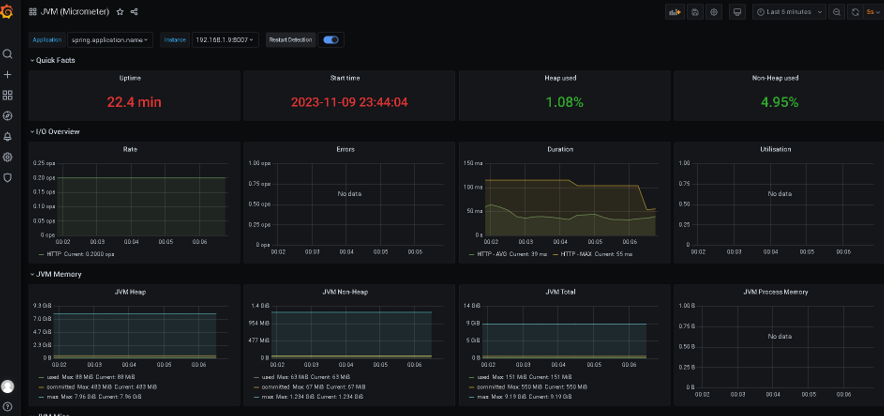
一文入门Springboot+actuator+Prometheus+Grafana
环境介绍 技术栈 springbootmybatis-plusmysqloracleactuatorPrometheusGrafana 软件 版本 mysql 8 IDEA IntelliJ IDEA 2022.2.1 JDK 1.8 Spring Boot 2.7.13 mybatis-plus 3.5.3.2 本地主机应用 192.168.1.9:8007 PrometheusGrafana安装在同一台主机 http://…...
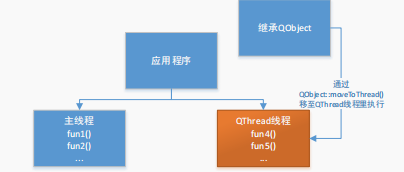
基于Qt 多线程(继承 QObject 的线程)
继承 QThread 类是创建线程的一种方法,另一种就是继承QObject 类。继承 QObject 类更加灵活。它通过 QObject::moveToThread()方法,将一个 QObeject的类转移到一个线程里执行。恩,不理解的话,我们下面也画个图捋一下。 通过上面的图不难理解,首先我们写一个类继承 QObj…...
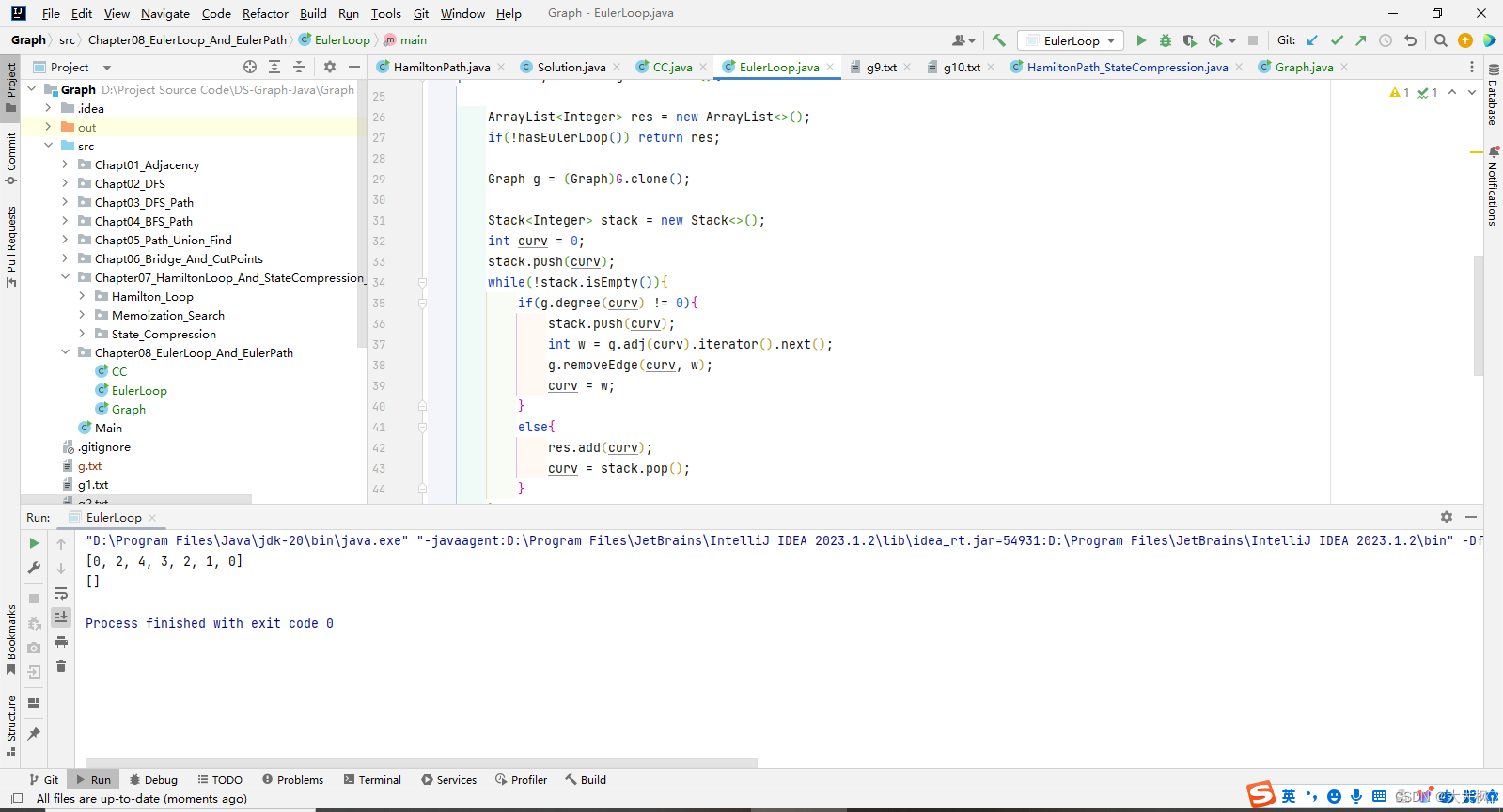
图论11-欧拉回路与欧拉路径+Hierholzer算法实现
文章目录 1 欧拉回路的概念2 欧拉回路的算法实现3 Hierholzer算法详解4 Hierholzer算法实现4.1 修改Graph,增加API4.2 Graph.java4.3 联通分量类4.4 欧拉回路类 1 欧拉回路的概念 2 欧拉回路的算法实现 private boolean hasEulerLoop(){CC cc new CC(G);if(cc.cou…...
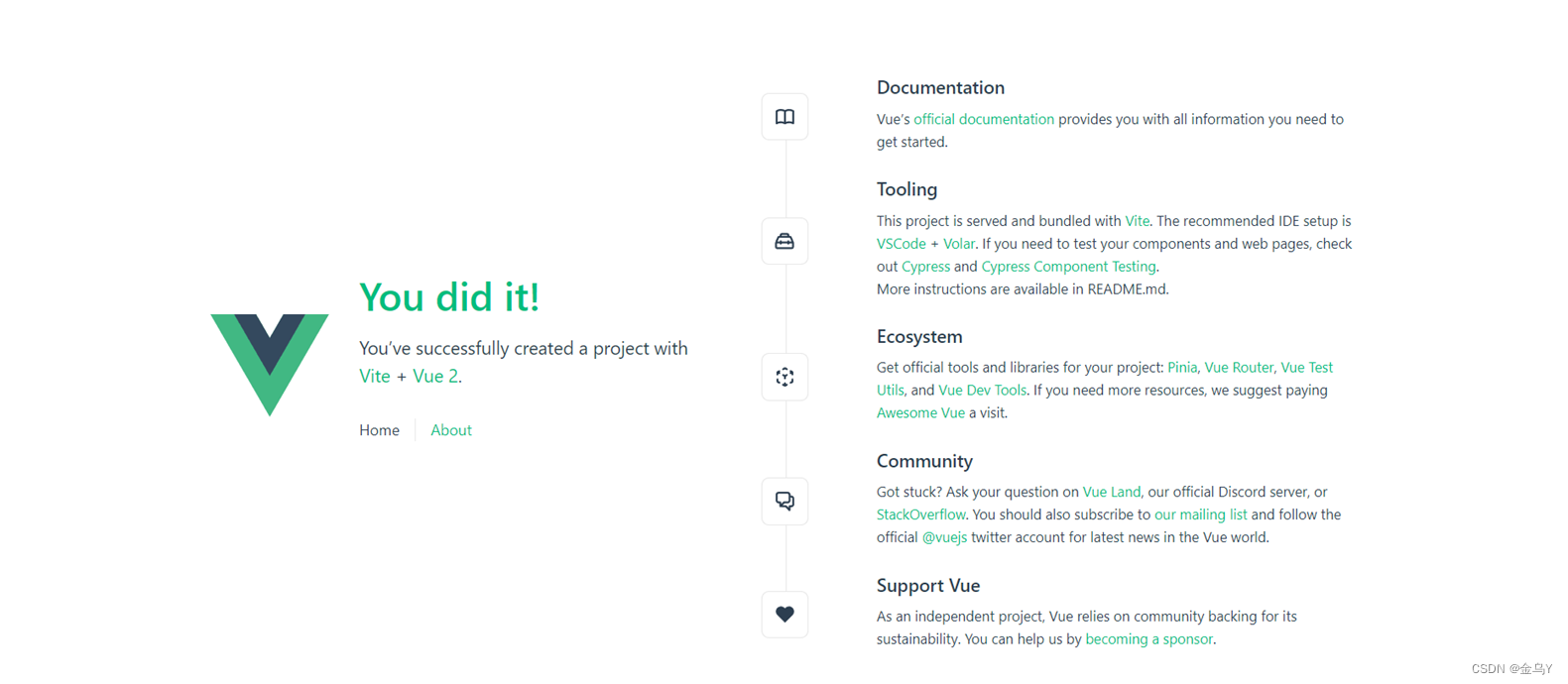
(一)什么是Vite——vite介绍与使用
什么是Vite Vite(法语意为 "快速的",发音 /vit/,发音同 "veet")是一种新型前端构建工具,能够显著提升前端开发体验。 它主要由两部分组成: 一个开发服务器,它基于 原生 …...

直流电动机四象限运行控制变流器设计
摘 要 节能和效率是工业经济发展的主题,电机在各行各业都是主要的动力来源, 直流电机以其控制简单,效率高,功率密度大等优势脱颖而出。基于直流电动机四象限运行控制变流器应用广泛,比如电子设备、电机控制、工业等行…...
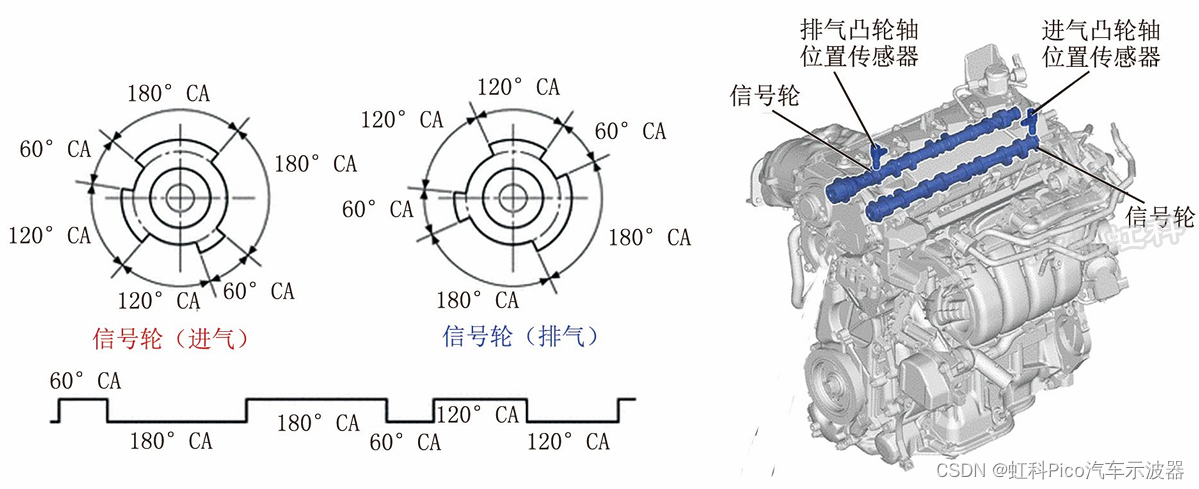
虹科示波器 | 汽车免拆检修 | 2021款广汽丰田威兰达PHEV车发动机故障灯异常点亮
一、故障现象 一辆2021款广汽丰田威兰达PHEV车,搭载A25D-FXS发动机和动力蓄电池系统(额定电压为355.2V,额定容量为45.0Ah),累计行驶里程约为1万km。车主反映,高速行驶时发动机突然抖动,且发动机…...

机器学习和深度学习领域的算法和模型
机器学习和深度学习领域有许多算法和模型,以下是一些常见的算法和模型: 线性回归(Linear Regression)逻辑回归(Logistic Regression)决策树(Decision Tree)随机森林(Ran…...

减轻关键基础设施网络安全风险的 3 种方法
物理安全和网络安全之间存在相当大的重叠,特别是在保护关键基础设施方面。防止基础设施被篡改需要在物理安全方面进行大量投资,但任何连接到互联网的设备都代表着更广泛网络的潜在攻击点。 缺乏足够保护的设备可能会给这些对手在网络中提供立足点&#…...

Redis的特性以及使用场景
分布式发展历程参考 陈佬 http://t.csdnimg.cn/yYtWK 介绍redis Redis(Remote Dictionary Server)是一个基于客户端-服务器架构的在内存中存储数据的中间件,属于NoSQL的一种。它可以用作数据库、缓存/会话存储以及消息队列。 作为一种内存数…...
【python后端】- 初识Django框架
Django入门 😄生命不息,写作不止 🔥 继续踏上学习之路,学之分享笔记 👊 总有一天我也能像各位大佬一样 🌝分享学习心得,欢迎指正,大家一起学习成长! 文章目录 Django入门…...

队列与堆栈:原理、区别、算法效率和应用场景的探究
队列与堆栈:原理、区别、算法效率和应用场景的探究 前言原理与应用场景队列原理应用场景: 堆栈原理应用场景递归原理和堆栈在其中的作用递归原理堆栈作用 队列与堆栈区别队列堆栈算法效率 前言 本文主要讲解数据结构中队列和堆栈的原理、区别以及相关的…...
数据结构与算法【链表:一】Java实现
目录 链表 单向链表 哨兵链表 双向链表 环形链表 链表 链表是数据元素的线性集合,其每个元素都指向下一个元素,元素存储上并不连续。 随机访问性能 根据 index 查找,时间复杂度 O(n) 插入或删除性能 起始位置:O(1)结束位…...
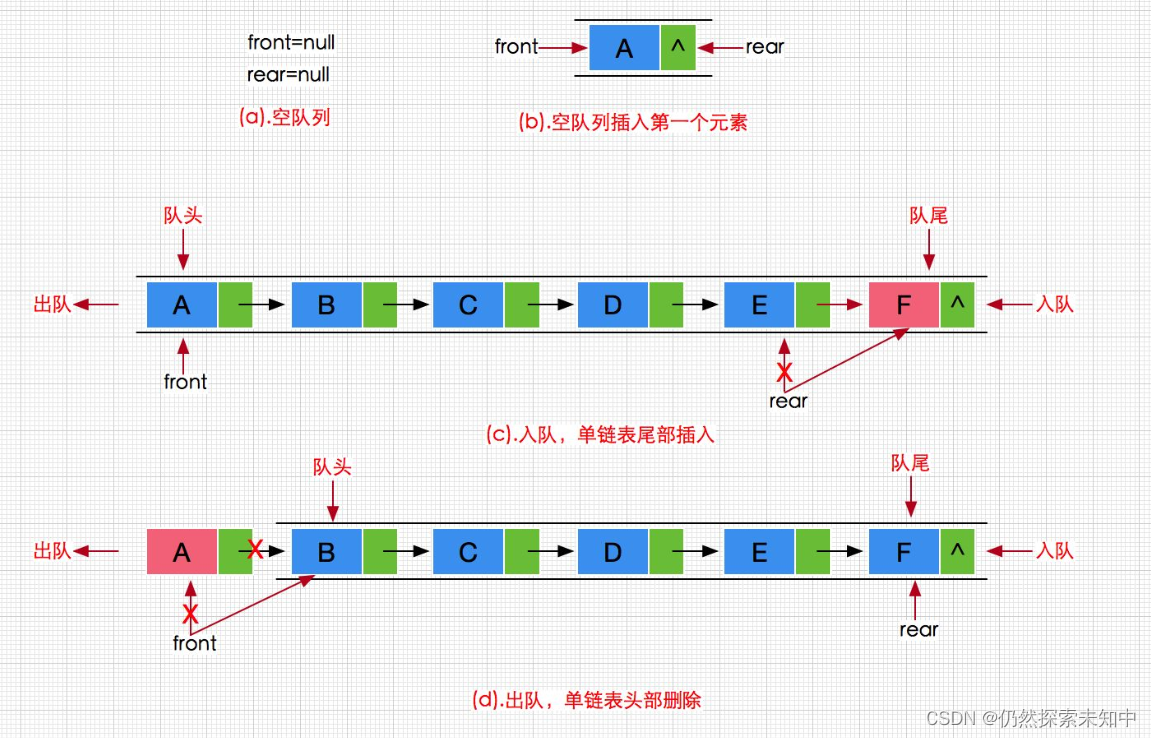
数据结构 | 队列的实现
数据结构 | 队列的实现 文章目录 数据结构 | 队列的实现队列的概念及结构队列的实现队列的实现头文件,需要实现的接口 Queue.h初始化队列队尾入队列【重点】队头出队列【重点】获取队列头部元素获取队列队尾元素获取队列中有效元素个数检测队列是否为空销毁队列 Que…...

flutter 集成 高德地图,退出界面闪退
android:allowNativeHeapPointerTagging"false"应用尝试释放系统堆分配器未分配的指针。 应用中的某个部分修改了指针的顶部字节。不能修改指针的顶部字节,您需要更改代码来修复此问题。 指针的顶部字节被错误使用或修改的示例包括: 指向特定…...
数据结构----链式栈的操作
链式栈的定义其实和链表的定义是一样的,只不过在进行链式栈的操作时要遵循栈的规则----即“先进后出”。 1.链式栈的定义 typedef struct StackNode {SElemType data;struct StackNode *next; }StackNode,*LinkStack; 2.链式栈的初始化 Status InitStack(LinkSta…...

识别伪装IP的网络攻击方法
识别伪装IP的网络攻击可以通过以下几种方法: 观察IP地址的异常现象。攻击者在使用伪装IP地址进行攻击时,往往会存在一些异常现象,如突然出现的未知IP地址、异常的流量等。这些现象可能是攻击的痕迹,需要对此加以留意。 检查网络通…...
C 语言指针
C 语言指针 在本教程中,您将学习指针。什么是指针,如何使用它们以及在示例的帮助下使用它们时可能遇到的常见错误。 指针是 C和C 编程的强大功能。在学习指针之前,让我们学习一下C语言编程中的地址。 C 语言地址 如果程序中有变量var&am…...

四旋翼变形控制:RL与MPC在混合动力学中的对比
1. 四旋翼变形控制的技术挑战与解决方案四旋翼变形控制(Quadrotor Morpho-Transition)是当前机器人领域最具挑战性的前沿技术之一。这项技术使机器人能够在空中完成形态变换,实现从飞行模式到地面模式的平滑切换。想象一下,一架四…...

DMA-330地址空间限制与扩展方案解析
1. DMA-330地址空间限制解析DMA-330作为Arm CoreLink系列中的直接内存访问控制器,其物理寻址能力直接由AxADDR信号宽度决定。这个32位地址总线宽度意味着它原生仅支持4GB(2^32字节)的物理地址空间访问。在实际嵌入式系统设计中,这…...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...

AI算力要上天?别笑,太空数据中心真能干翻地球电费!
前言你有没有算过,训练一个大模型,相当于烧掉多少吨煤?如今AI狂飙突进,算力需求指数级增长,可地球上的电——不够用了!更别说建个数据中心还得跟地方政府“斗智斗勇”,抢地皮、配储能、扛审批&a…...

神经网络与深度学习 第3周课程总结
深度学习视觉应用课程总结 一、常用计算机视觉数据集数据集名称发布方/年份规模图像规格类别数主要用途核心特点MNIST美国国家标准与技术研究院60k训练10k测试2828灰度图10类(0-9手写数字)入门级图像分类最经典的手写数字识别基准数据集Fashion-MNISTZalando(2017)60k训练10k测…...