7、线性数据结构-切片
切片slice
- 容器容量可变,所以长度不能定死
- 长度可变,元素个数可变
- 底层必须依赖数组,可以理解它依赖于顺序表,表现也像个可变容量和长度顺序表
- 引用类型,和值类型有区别
定义切片
var s1 []int //长度、容量为0的切片,零值
var s2 = []int{} //长度、容量为0的切片,字面量定义
var s3 = []int{1,3,5} //字面量定义,长度、容量都是3
var s4 = make([]int,0) //长度、容量都为0的切片,make([]T,length)
var s5 = make([]int,3,5) //长度为3,容量为5,底层数组长度为5,元素长度为3,所以显示[0,0,0]
使用切片要关注容量cap和长度len两个属性
内存模型
切片本质是对底层数组一个连续片段的引用。此片段可以是整个底层数组,也可以是由起始和终止索引标识的一些项的子集。
因为下面是底层数组,所以数组的容量是不可以改变的。元素内容能变的。
理解:切片保存的就是标头值,该值包括,指向的实际存储的地址,实际长度和容量的长度
由上图可知,pointer的实际地址和底层数组的地址是不同的
// https://github.com/golang/go/blob/master/src/runtime/slice.go
// slice header 或 descriptor
type slice struct {array unsafe.Pointer 指向底层数组的指针len int 切片访问的元素的个数(即长度)cap int 切片允许增长到的元素个数(即容量)
}
注意上面三个结构体的属性都是小写,所以包外不可见。len函数取就是len属性,cap函数取cap属性。func main() {var s1 = make([]int, 3, 5)fmt.Printf("s1 %p %p %d", &s1, &s1[0], s1)}
s1 0xc000008078 0xc00000e450 [0 0 0]分析结果:&s1指的是标头值的地址 表示切片的地址,header这个结构体的地址&s1[0] 指的是实际存储的起始元素的地址, 第一个元素的地址,由于第一个元素存在底层数组中,数组的第一个元素地址就是数组的地址指针可以通过取底层数组的第一个元素的地址,即切片第一个元素的地址
追加
append:在切片的尾部追加元素,长度加1。
增加元素后,有可能超过当前容量,导致切片扩容。
切片扩容就是底层数组会出现起始一段地址
长度和容量
func main() {s1 := []int{100}fmt.Printf("s1 %p %p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s1 = make([]int, 2, 5)fmt.Printf("s1 %p %p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)
}s1 0xc000008078 0xc00001a098,1,1,[100]
s1 0xc000008078 0xc0000103f0,2,5,[0 0]结论:s1被重新复制了,但是S1的地址没有变化,底层数组的地址发生了变化
追加
func main() {s1 := make([]int, 2, 5) //定义了一个长度为2,容量为5的切片,fmt.Printf("s1 %p %p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s1 = append(s1, 200) // append返回新的header信息,覆盖fmt.Printf("s1 %p %p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)
}s1 0xc000008078 0xc0000103f0,2,5,[0 0]
s1 0xc000008078 0xc0000103f0,3,5,[0 0 200]
结论: s1的地址和底层数组的地址都没有发生变化,这是因为没有超过容量,底层共用同一个数组,但是,对底层数组使用的片段不一样。
func main() {s1 := make([]int, 2, 5)fmt.Printf("s1 %p %p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s1 = append(s1, 200)fmt.Printf("s1 %p %p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s2 := append(s1, 1, 2) // append返回新的header信息,使用新的变量存储fmt.Printf("s2 %p %p,%d,%d,%v\n", &s2, &s2[0], len(s2), cap(s2), s2)
}
s1 0xc000008078 0xc0000103f0,2,5,[0 0]
s1 0xc000008078 0xc0000103f0,3,5,[0 0 200]
s2 0xc0000080c0 0xc0000103f0,5,5,[0 0 200 1 2]
结论:我们发现有新的header值,因为切片的重新赋值,所以s2有新的地址,但是s2指向的底层数组还是一样的,因为容量还没有超出。
func main() {s1 := make([]int, 2, 5)fmt.Printf("s1 %p %p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s2 := append(s1, 1, 2)fmt.Printf("s2 %p %p,%d,%d,%v\n", &s2, &s2[0], len(s2), cap(s2), s2)s3 := append(s1, -1)fmt.Printf("s3 %p %p, %d,%d,%v\n", &s3, &s3[0], len(s3), cap(s3),s3)
}
s1 0xc000008078 0xc0000103f0,2,5,[0 0]
s2 0xc0000080a8 0xc0000103f0,4,5,[0 0 1 2]
s3 0xc0000080d8 0xc0000103f0, 3,5,[0 0 -1]结论:目前三个切片底层用同一个数组,只不过长度不一样
func main() {s1 := make([]int, 2, 5)fmt.Printf("s1 %p %p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s2 := append(s1, 1, 2)fmt.Printf("s2 %p %p,%d,%d,%v\n", &s2, &s2[0], len(s2), cap(s2), s2)s3 := append(s1, -1)fmt.Printf("s3 %p, %p, %d,%d,%v\n", &s3, &s3[0], len(s3), cap(s3), s3)s4 := append(s3, 3, 4, 5, 6)fmt.Printf("s4 %p, %p, %d,%d,%v\n", &s4, &s4[0], len(s4), cap(s4), s4)}
s1 0xc000008078 0xc0000103f0,2,5,[0 0]
s2 0xc0000080a8 0xc0000103f0,4,5,[0 0 1 2]
s3 0xc0000080d8, 0xc0000103f0, 3,5,[0 0 -1]
s4 0xc000008108, 0xc0000142d0, 7,10,[0 0 -1 3 4 5 6]结论:底层数组变了,容量也增加了 ,底层数组的起始地址也发生了变化,相当于重新在内存中开辟了一块地址,并且容量变成了之前的2倍
结论:
- append一定返回一个新的切片,但本质上来说返回的是新的Header
- append可以增加若干元素
- 如果增加元素时,当前长度 + 新增个数 <= cap则不扩容
- 原切片使用原来的底层数组,返回的新切片也使用这个底层数组
- 返回的新切片有新的长度
- 原切片长度不变
- 如果增加元素时,当前长度 + 新增个数 > cap则需要扩容
- 生成新的底层数组,新生成的切片使用该新数组,将旧元素复制到新数组,其后追加新元素
- 原切片底层数组、长度、容量不变
- 如果增加元素时,当前长度 + 新增个数 <= cap则不扩容
扩容策略
(老版本)实际上,当扩容后的cap<1024时,扩容翻倍,容量变成之前的2倍;当cap>=1024时,变成
之前的1.25倍。
(新版本1.18+)阈值变成了256,当扩容后的cap<256时,扩容翻倍,容量变成之前的2倍;当
cap>=256时, newcap += (newcap + 3*threshold) / 4 计算后就是 newcap = newcap +newcap/4 + 192 ,即1.25倍后再加192。
扩容是创建新的底层数组,把原内存数据拷贝到新内存空间,然后在新内存空间上执行元素追加操作。
切片频繁扩容成本非常高,所以尽量早估算出使用的大小,一次性给够,建议使用make。常用make([]int, 0, 100) 。
子切片
选取当前切片的一段等到一个新的切片,共用底层数据(因为不扩容),但是header中的三个属性会变,切片可以通过指定索引区间获得一个子切片,格式为slice[start:end],规则就是前包后不包。
package mainimport "fmt"func main() {s1 := []int{10, 30, 50, 70, 90}for i := 0; i < len(s1); i++ {fmt.Printf("%d : addr = %p\n", i, &s1[i])}
}
0 : addr = 0xc00013a060
1 : addr = 0xc00013a068
2 : addr = 0xc00013a070
3 : addr = 0xc00013a078
4 : addr = 0xc00013a080
func main() {s1 := []int{10, 30, 50, 70, 90}fmt.Printf("s1 %p,%p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s2 := s1 //共用一个底层数组fmt.Printf("s2 %p,%p,%d,%d,%v\n", &s2, &s2[0], len(s2), cap(s2), s2)}
s1 0xc000008078,0xc0000103f0,5,5,[10 30 50 70 90]
s2 0xc0000080a8,0xc0000103f0,5,5,[10 30 50 70 90]结论:s2复制s1的标头值,但是s2也被重新赋值了
func main() {s1 := []int{10, 30, 50, 70, 90}fmt.Printf("s1 %p,%p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s2 := s1fmt.Printf("s2 %p,%p,%d,%d,%v\n", &s2, &s2[0], len(s2), cap(s2), s2)s3 := s1[:]fmt.Printf("s3 %p,%p,%d,%d,%v\n", &s3, &s3[0], len(s3), cap(s3), s3)
}
s1 0xc000008078,0xc0000103f0,5,5,[10 30 50 70 90]
s2 0xc0000080a8,0xc0000103f0,5,5,[10 30 50 70 90]
s3 0xc0000080d8,0xc0000103f0,5,5,[10 30 50 70 90]
结论:s3 := s1[:] 这个代表的就是从头到尾的元素都要,和s1共用一个底层数组
func main() {s1 := []int{10, 30, 50, 70, 90}fmt.Printf("s1 %p,%p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s4 := s1[1:]fmt.Printf("s4 %p,%p,%d,%d,%v\n", &s4, &s4[0], len(s4), cap(s4), s4)
}
s1 0xc000008078,0xc0000103f0,5,5,[10 30 50 70 90]
s4 0xc0000080a8,0xc0000103f8,4,4,[30 50 70 90]结论: s4 := s1[1:] 掐头,从1开始容量长度都发生变化 首地址偏移了一位,因此长度len=end-start=4 cap=原cap-start=4
func main() {s1 := []int{10, 30, 50, 70, 90}fmt.Printf("s1 %p,%p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s5 := s1[1:4]fmt.Printf("s5 %p,%p,%d,%d,%v\n", &s5, &s5[0], len(s5), cap(s5), s5)
}
s1 0xc000092060,0xc0000be060,5,5,[10 30 50 70 90]
s5 0xc000092090,0xc0000be068,3,4,[30 50 70]
结论:s5 := s1[1:4] 掐头去尾,但是前包后不包 就是1的位置的元素包含在里,4的位置的元素不在
len=end-start=3 cap=start的这个位置到容器的最大位置=4
func main() {s1 := []int{10, 30, 50, 70, 90}fmt.Printf("s1 %p,%p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s6 := s1[:4]fmt.Printf("s6 %p,%p,%d,%d,%v\n", &s6, &s6[0], len(s6), cap(s6), s6)
}
s1 0xc000008078,0xc0000103f0,5,5,[10 30 50 70 90]
s6 0xc0000080a8,0xc0000103f0,4,5,[10 30 50 70]
结论:s6 := s1[:4] 去尾,后不包 len=4-0=4 容量=第一个位置到最大的容量值=5 cap=原cap-start 首地址还不变
func main() {s1 := []int{10, 30, 50, 70, 90}fmt.Printf("s1 %p,%p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s7 := s1[1:1]fmt.Printf("s7 %p,%d,%d,%v\n", &s7, len(s7), cap(s7), s7)
}
s1 0xc000008078,0xc0000103f0,5,5,[10 30 50 70 90]
s7 0xc0000080a8,0,4,[]结论:首地址偏移1个元素,长度为0,cap=原cap-start 容量为4,共用底层数组 由于长度为0,所以不能s7[0]报错
为s7增加一个元素,s1、s7分别是什么?
func main() {s1 := []int{10, 30, 50, 70, 90}fmt.Printf("s1 %p,%p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s7 := s1[1:1]s7 = append(s7, 100)fmt.Printf("s7 %p,%p,%d,%d,%v\n", &s7, &s7[0], len(s7), cap(s7), s7)fmt.Printf("s1 %p,%p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)}
s1 0xc000008078,0xc0000103f0,5,5,[10 30 50 70 90]
s7 0xc0000080a8,0xc0000103f8,1,4,[100]
s1 0xc000008078,0xc0000103f0,5,5,[10 100 50 70 90]
结论:s7操作的也是在底层数组中,所以s7在1新增了100 底层数组s1的1位置30修改为了100
func main() {s1 := []int{10, 30, 50, 70, 90}fmt.Printf("s1 %p,%p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s8 := s1[4:4]fmt.Printf("s8 %p,%d,%d,%v\n", &s8, len(s8), cap(s8), s8)}
s1 0xc000008078,0xc0000103f0,5,5,[10 30 50 70 90]
s8 0xc0000080a8,0,1,[]
// 首地址偏移4个元素,长度为0,容量为1,因为最后一个元素没在切片中,共用底层数组
func main() {s1 := []int{10, 30, 50, 70, 90}fmt.Printf("s1 %p,%p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s9 := s1[5:5]fmt.Printf("s9 %p,%d,%d,%v\n", &s9, len(s9), cap(s9), s9)
}
s1 0xc000008078,0xc0000103f0,5,5,[10 30 50 70 90]
s9 0xc0000080a8,0,0,[]增加元素会怎么样?s1、s9分别是什么?func main() {s1 := []int{10, 30, 50, 70, 90}fmt.Printf("s1 %p,%p,%d,%d,%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s9 := s1[5:5]fmt.Printf("s9 %p,%d,%d,%v\n", &s9, len(s9), cap(s9), s9)s9 = append(s9, 100)fmt.Printf("s9 %p,%p,%d,%d,%v\n", &s9, &s9[0], len(s9), cap(s9), s9)
}
s1 0xc000008078,0xc0000103f0,5,5,[10 30 50 70 90]
s9 0xc0000080a8,0,0,[]
s9 0xc0000080a8,0xc00001a0e8,1,1,[100]
切片总结:
- 使用slice[start:end]表示切片,切片长度为end-start,前包后不包
- start缺省,表示从索引0开始
- end缺省,表示取到末尾,包含最后一个元素,特别注意这个缺省值是len(slice)即切片长度,不是容量
- a1[5:]相当于a1[5:len(a1)]
- start和end都缺省,表示从头到尾
- start和end同时给出,要求end >= start
- start、end最大都不可以超过容量值
- 假设当前容量是8,长度为5,有以下情况
- a1[:],可以,共用底层数组,相当于对标头值的拷贝,也就是指针、长度、容量都一样
- a1[:8],可以,end最多写成8(因为后不包),a1[:9]不可以。该切片长度、容量都为8,
这8个元素都是原序列的,一旦append就扩容 - a1[8:],不可以,end缺省为当前长度5,等价于a1[8:5]
- a1[8:8],可以,但这个切片容量和长度都为0了。注意和a1[:8]的区别
- a1[7:7],可以,但这个切片长度为0,容量为1
- a1[0:0],可以,但这个切片长度为0,容量为8
- a1[1:5],可以,这个切片长度为4,容量为7,相当于跳过了原序列第一个元素
- 切片刚产生时,和原序列(数组、切片)开始共用同一个底层数组,但是每一个切片都自己独立保存着指针、cap和len
- 一旦一个切片扩容,就和原来共用一个底层数组的序列分道扬镳,从此陌路
后不包),a1[:9]不可以。该切片长度、容量都为8,
这8个元素都是原序列的,一旦append就扩容
- a1[8:],不可以,end缺省为当前长度5,等价于a1[8:5]
- a1[8:8],可以,但这个切片容量和长度都为0了。注意和a1[:8]的区别
- a1[7:7],可以,但这个切片长度为0,容量为1
- a1[0:0],可以,但这个切片长度为0,容量为8
- a1[1:5],可以,这个切片长度为4,容量为7,相当于跳过了原序列第一个元素
- 切片刚产生时,和原序列(数组、切片)开始共用同一个底层数组,但是每一个切片都自己独立保存着指针、cap和len
- 一旦一个切片扩容,就和原来共用一个底层数组的序列分道扬镳,从此陌路
相关文章:

7、线性数据结构-切片
切片slice 容器容量可变,所以长度不能定死长度可变,元素个数可变底层必须依赖数组,可以理解它依赖于顺序表,表现也像个可变容量和长度顺序表引用类型,和值类型有区别 定义切片 var s1 []int //长度、容量为0的切片&…...
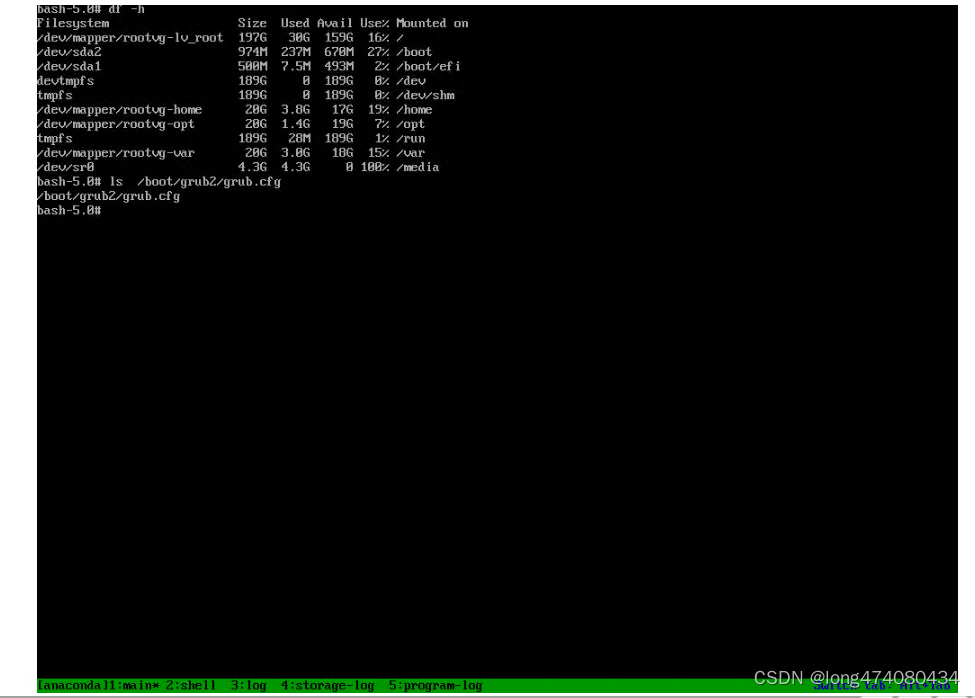
linux grub2 不引导修复 grub2-install:error:/usr/lib/grub/x86_64-efi/modinfo.sh
系统部署在物理机上,开机后一直pxe不进系统,怀疑GRUB丢失。 查看bios 里 采用uefi 启动方式, 无硬盘系统引导选项, 且BMC设置为硬盘永久启动也无效。 挂载光驱ISO进入救援模式,sda为系统盘,重装grub报错 grub2-inst…...

建筑楼宇智慧能源管理系统,轻松解决能源管理问题
随着科技的进步与人们节能减排意识的不断增强,建筑楼宇是当下节能减排的重要工具。通过能源管理平台解决能效管理、降低用能成本、一体化管控、精细化管理和服务提供有力支撑。 建筑楼宇智慧能源管理系统是一种利用先进手段,采用微服务架构,…...

【洛谷算法题】P5711-闰年判断【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5711-闰年判断【入门2分支结构】🌏题目描述🌏输入格式&a…...
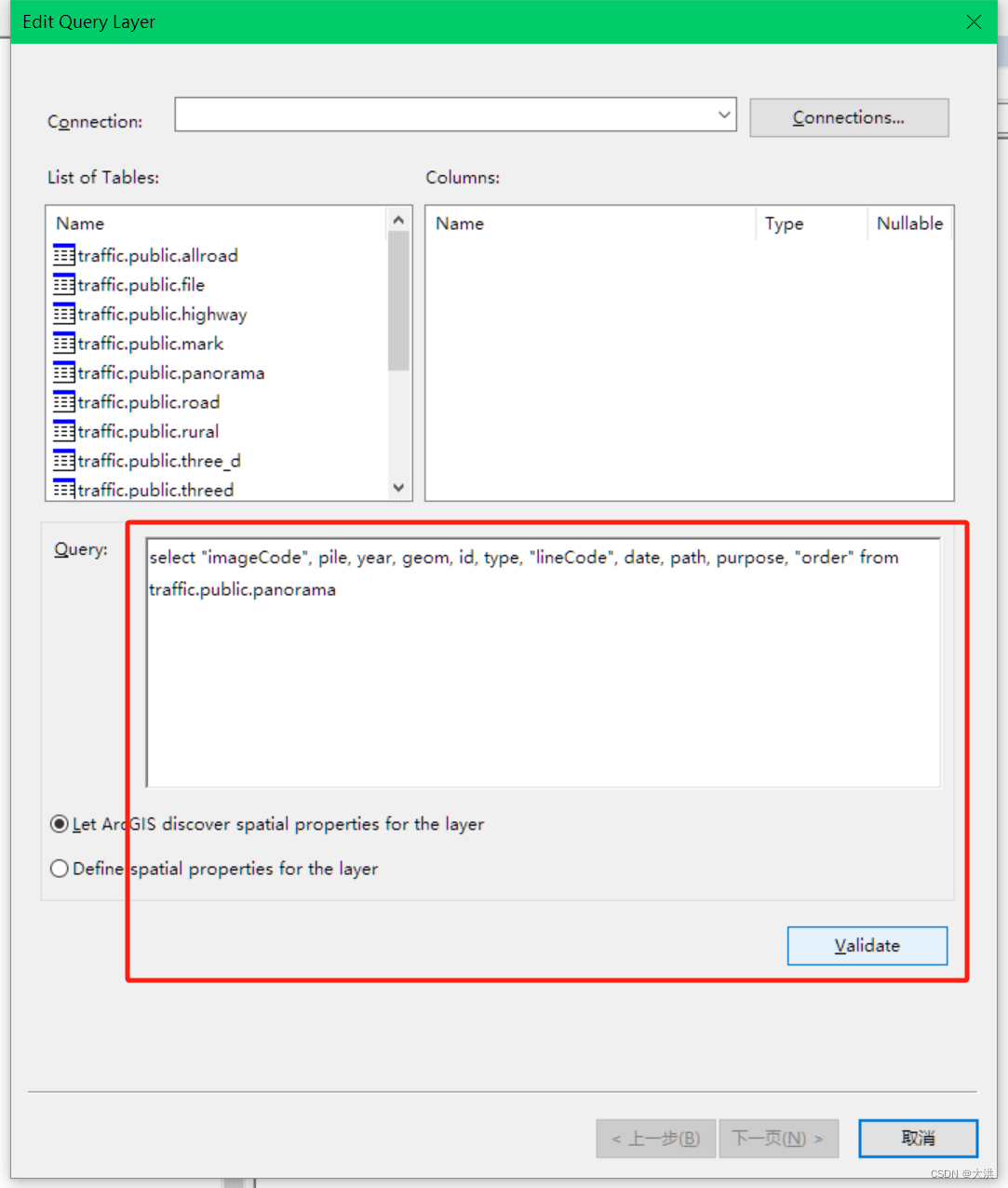
ArcGIS10.8 连接 PostgreSQL 及遇到的两个问题
前提 以前同事用过我的电脑连PostgreSQL,失败了。当时不知道原因,只能使用GeoServer来发布数据了。现在终于搞明白了,原因是ArcGIS10.2版本太老,无法连接PostgreSQL9.4。参考这里 为了适应时代的发展,那我就用新的Ar…...
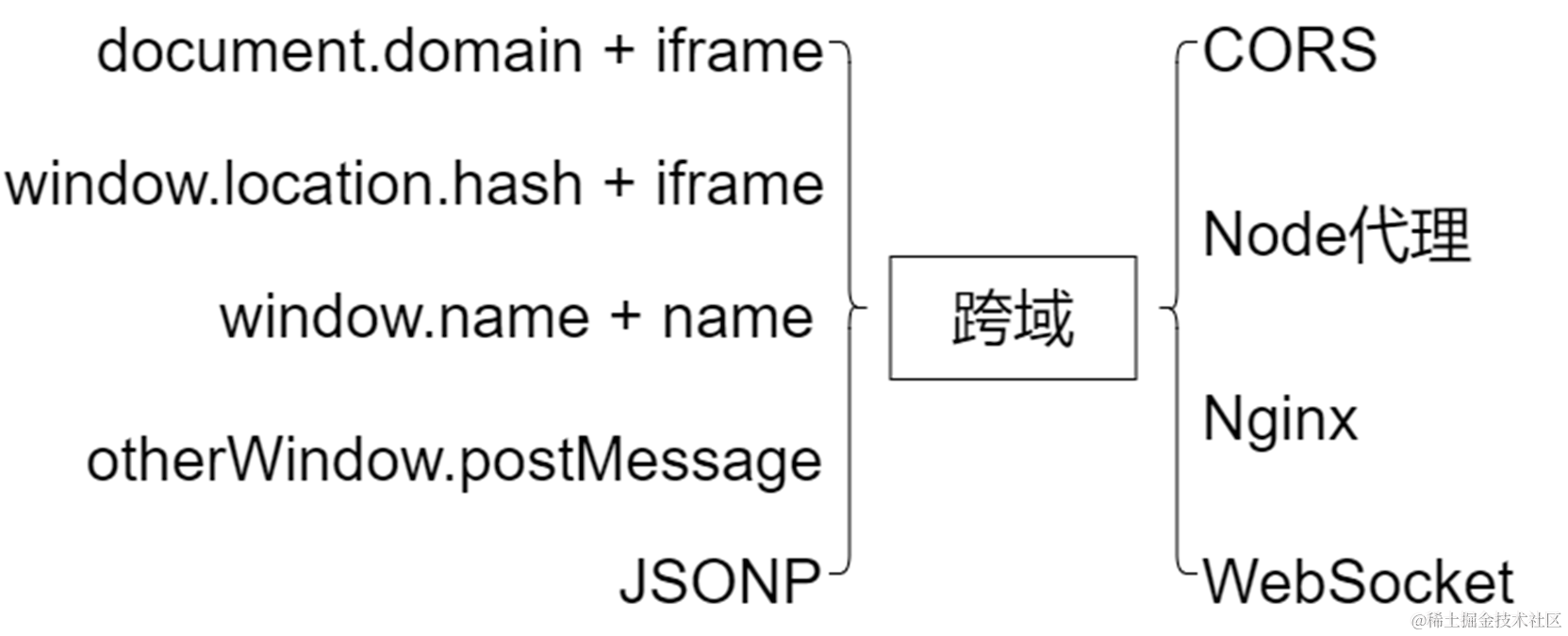
深入跨域 - 从初识到入门 | 京东物流技术团队
前言 跨域这两个字就像一块狗皮膏药一样黏在每一个前端开发者身上,无论你在工作上或者面试中无可避免会遇到这个问题。如果在网上搜索跨域问题,会出现许许多多方案,这些方案有好有坏,但是对于阐述跨域的原理和在什么情况下需要用…...
WebSocket真实项目总结
websocket websocket是什么? websocket是一种网络通讯协议。 websocket 是HTML5开始提供的一种在单个TCP链接上进行全双工通讯的协议。 为什么需要websocket? 初次接触websocket,都会带着疑惑去学习,既然已经有了HTTP协议,为什么还需要另一…...

Python 如何实现解释器(Interpreter)设计模式?什么是解释器设计模式?
什么是解释器(Interpreter)设计模式? 解释器(Interpreter)设计模式是一种行为型设计模式,它定义了一种语言文法的表示,并提供了一个解释器,用于解释语言中的句子。该模式使得可以定…...
单片机与PLC的区别有哪些?
单片机与PLC的区别有哪些? 什么是单片机? 单片机(Microcontroller,缩写MCU)是一种集成了中央处理器(CPU)、存储器和输入/输出接口等功能模块的微型计算机系统。它通常被用于嵌入式系统和控制系统中&#x…...

修改浏览器滚动条样式--ios同款
::-webkit-scrollbar{width: 5px;height: 5px; } ::-webkit-scrollbar-thumb{border-radius: 1em;background-color: rgba(50,50,50,.3); } ::-webkit-scrollbar-track{border-radius: 1em;background-color: rgba(50,50,50,.1); } 修改滚动条样式用到的CSS伪类: :…...
python自动化测试selenium核心技术3种等待方式详解
这篇文章主要为大家介绍了python自动化测试selenium的核心技术三种等待方式示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步早日升职加薪 UI自动化测试过程中,可能会出现因测试环境不稳定、网络慢等情况&a…...
苹果手机照片如何导入电脑?无损快速的传输办法分享!
前些天小编的朋友联系到我,说是自己苹果手机里面的照片太多,有好几千张,不知道该怎么快而无损地传到电脑。我想遇到这种情况的不止是小编的朋友,生活中遇到手机照片导入电脑的同学不在少数。不管是苹果手机还是安卓手机࿰…...

csh 脚本批量处理文件并将文件扔给程序
文章目录 前言程序批量造 case 并将 cmd 扔给程序运行批量收集数据汇总 前言 Linux下我们经常会写一些shell脚本来辅助我们学习或者工作,从而提高效率。 之前就写过一篇博客:Linux下利用shell脚本批量产生内容有规律变化的文件 程序 批量造 case 并将…...

程序员技能成长树,程序员的曙光
一、背景 初创的计算机公司,主要低市场占有率和日益增长的市场规模之间的矛盾,此时只有一件事情,那就是快速抢占市场,在面对计算机飞速发展的时期,企业广泛的招聘计算机人才进行信息化项目建设,随着公司业…...
灰度图处理方法
做深度学习项目图像处理的时候常常涉及到灰度图处理,这里对自己处理灰度图的方式做一个记录,后续有更新的话会在此更新 一,多维数组可视化 将多维数组可视化为灰度图 img_gray Image.fromarray(img, modeL) # 实现array到image的转换,m…...
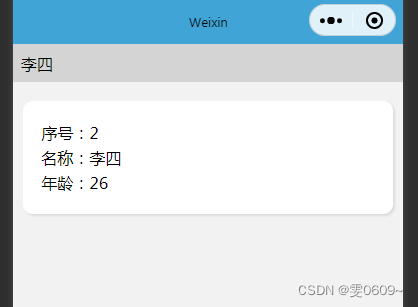
微信小程序:仅前端实现对象数组的模糊查询
效果 核心代码 //对数组进行过滤,返回数组中每一想满足name值包括变量query的 let result array.filter(item > { return item.name.includes(query); }); 完整代码 wxml <input type"text" placeholder"请输入名称" placeholder-styl…...

【done】剑指offer63:股票的最大利润
力扣188,https://leetcode.cn/problems/gu-piao-de-zui-da-li-run-lcof/description/(注意:本题与主站 121 题相同:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock/) 动态规划思路; 方…...
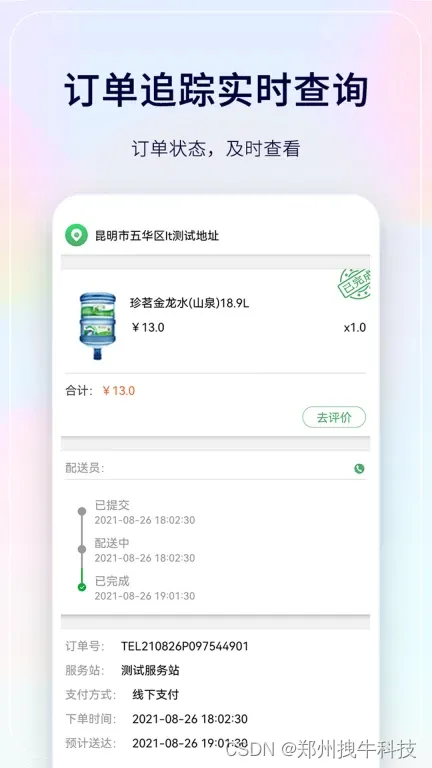
桶装水订水小程序app,线上预约订水更便捷
桶装水订水小程序app,线上预约订水更便捷。设置好地址,一键订水,工作人员送水到家。还能配送新鲜果蔬,绿色健康有保证。送水软件手机版,提供各种品牌桶装水,在线发起订水服务,由服务人员送水到家…...
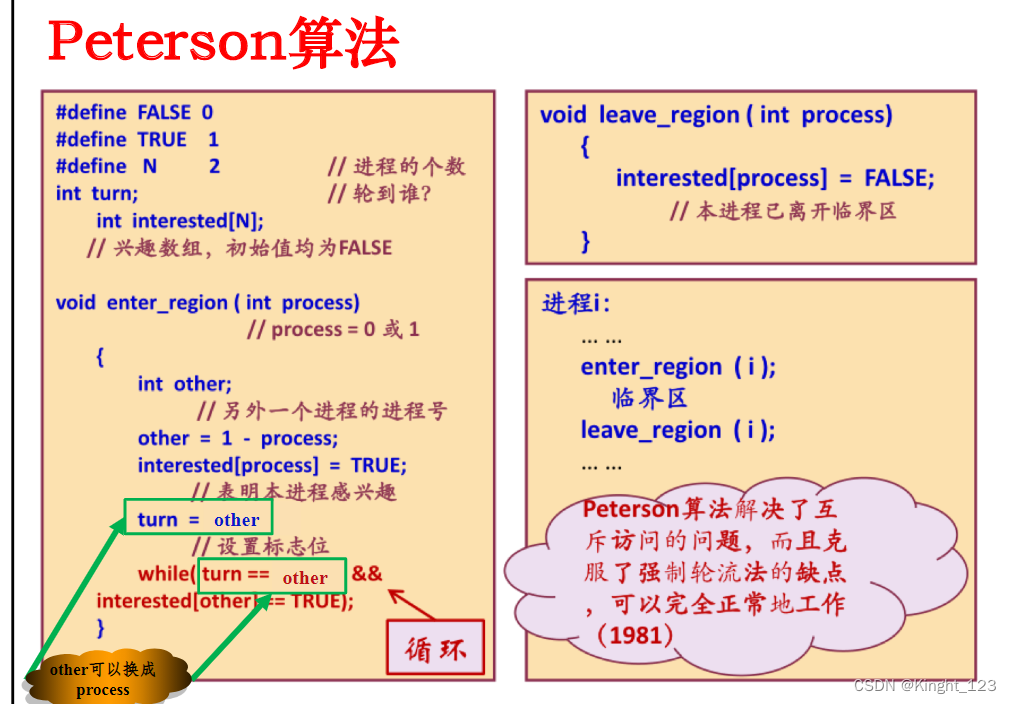
解决进程同步与互斥的Dekker算法与Peterson算法
1. Dekker算法 2. Peterson算法...
confluence无法打开空间目录
confluence无法打开空间目录,打开空间目录后无法显示项目 查看项目的类别信息都在 问题原因 由于索引损坏导致; This issue is caused by acorrupted index. Confluence is trying to fetch information about the spacesfrom the available index, …...

AI智能体到底强在哪?为什么大家开始从“养龙虾”转向“养马”
那么AI智能体的核心能力是什么? 1、理解需求 它能分析你的真实意图,而不是只看表面的文字,比如让它整理这个月的消费情况,它明白之后,会读取账单,做分类统计,生成总结,最后输出图表。…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

Vue3 图片标框功能实现方案
基于 Vue3 组合式 API 的图片标框(画框、标注、选框)完整实现,核心逻辑封装在 GetBoxes 组件里,复制就能用 一、功能说明 ✅ 在图片上鼠标拖拽画矩形框 ✅ 实时显示框坐标(x, y, width, height) ✅ 支持多…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

从游戏引擎到仿真平台:手把手教你用AirSim+UE4搭建你的第一个无人机/自动驾驶仿真环境
从游戏引擎到仿真平台:构建AirSimUE4无人机与自动驾驶仿真环境实战指南当游戏引擎遇上机器人算法测试,会碰撞出怎样的火花?微软开源的AirSim项目将虚幻引擎(Unreal Engine)从游戏开发领域引入到自动驾驶和无人机研究的…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

如何快速解锁中兴光猫权限:zteOnu工具完整使用指南
如何快速解锁中兴光猫权限:zteOnu工具完整使用指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 中兴光猫作为家庭网络的核心设备,其强大的硬件性能常常被默认…...