AdaBoost:提升机器学习的力量
一、介绍
机器学习已成为现代技术的基石,为从推荐系统到自动驾驶汽车的一切提供动力。在众多机器学习算法中,AdaBoost(Adaptive Boosting的缩写)作为一种强大的集成方法脱颖而出,为该领域的成功做出了重大贡献。AdaBoost 是一种提升算法,旨在通过将弱学习者的预测组合到一个强大而准确的模型中来提高他们的表现。在本文中,我们将探讨 AdaBoost 的基本概念、工作原理和应用,重点介绍其在机器学习领域的重要性。

AdaBoost:将机器学习提升到新的高度。
二、基本概念
- 弱学习者:AdaBoost 主要使用一类称为“弱学习器”的算法。弱学习器是性能略好于随机猜测的模型,但仍远未成为准确的分类器。这些可能是决策树桩(具有单个拆分的简单决策树)、线性模型或其他简单算法。
- 集成学习:AdaBoost 属于集成学习类别。集成方法结合了多个机器学习模型,以创建比其任何单个组件更强大、更准确的模型。AdaBoost 通过迭代训练弱学习者并根据他们的表现为他们分配权重来实现这一目标。
三、AdaBoost 的工作原理
AdaBoost 在一系列迭代或轮次中运行,以构建强大的分类器。以下是 AdaBoost 工作原理的分步概述:
- 初始化权重:在第一轮中,所有训练样本的权重相等。目标是对这些示例进行正确分类。
- 训练一个弱的学习者:AdaBoost 选择一个较弱的学习器,并根据训练数据对其进行训练,从而对上一轮错误分类的示例给予更多权重。
- 计算误差:训练后,AdaBoost 会计算弱学习器的误差。误差是错误分类示例的权重之和除以总权重。
- 更新权重:AdaBoost 增加了错误分类示例的权重,使它们在下一轮中更加重要。这更加强调以前具有挑战性的数据点。
- 迭代:步骤 2 至 4 重复预定义的轮数或直到达到一定的精度水平。
- 结合弱学习者: 最后,AdaBoost 通过根据每个学习者的表现为每个学习者分配权重来结合弱学习者的预测。更强的学习者获得更高的权重,对最终预测的贡献更大。
- 进行预测:为了对新数据进行预测,AdaBoost 会计算弱学习者预测的加权总和,每个学习者的权重由其在训练期间的表现决定。
四、AdaBoost的应用
AdaBoost 已在广泛的领域得到应用,包括:
- 人脸检测:AdaBoost 广泛用于计算机视觉中的人脸检测,有助于准确识别图像和视频中的人脸。
- 文本分类: 在自然语言处理中,AdaBoost 用于文本分类任务,例如垃圾邮件检测和情绪分析。
- 生物信息学:AdaBoost已应用于生物数据分析,包括基因表达谱分析和蛋白质功能预测。
- 医学诊断:在医疗保健行业,AdaBoost 协助医疗诊断任务,例如根据患者数据检测疾病。
- 异常检测:AdaBoost 用于各个领域的异常检测,包括网络安全和欺诈检测。
五、代码
下面是 AdaBoost 的完整 Python 代码示例,其中包含数据集和绘图。在此示例中,我们将使用著名的鸢尾花数据集,这是一个多类分类问题。
# Import necessary libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# Create an AdaBoostClassifier
clf = AdaBoostClassifier(n_estimators=50, random_state=42)# Fit the classifier to the training data
clf.fit(X_train, y_train)# Make predictions on the test data
y_pred = clf.predict(X_test)# Plot the decision boundary using the first two features
feature1 = 0 # Choose the feature indices you want to plot
feature2 = 1# Extract the selected features from the dataset
X_subset = X[:, [feature1, feature2]]# Create an AdaBoostClassifier
clf = AdaBoostClassifier(n_estimators=50, random_state=42)# Fit the classifier to the training data
clf.fit(X_train[:, [feature1, feature2]], y_train)# Make predictions on the test data
y_pred = clf.predict(X_test[:, [feature1, feature2]])# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")# Plot the decision boundary
x_min, x_max = X_subset[:, 0].min() - 1, X_subset[:, 0].max() + 1
y_min, y_max = X_subset[:, 1].min() - 1, X_subset[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X_subset[:, 0], X_subset[:, 1], c=y, marker='o', s=25)
plt.xlabel(f"Feature {feature1 + 1}")
plt.ylabel(f"Feature {feature2 + 1}")
plt.title("AdaBoost Classifier Decision Boundary")
plt.show()在此代码中:
- 我们导入必要的库,包括 NumPy、Matplotlib、scikit-learn 的数据集、AdaBoostClassifier、train_test_split 和 accuracy_score。
- 我们加载 Iris 数据集并将其拆分为训练集和测试集。
- 我们创建一个具有 50 个基本估计器的 AdaBoostClassifier(您可以根据需要调整此数字)。
- 我们将分类器拟合到训练数据中,并对测试数据进行预测。
- 我们计算分类器的准确性。
- 我们创建一个网格网格来绘制决策边界,并使用它来可视化分类器的决策区域。
- 最后,我们绘制决策边界和数据点。
Accuracy: 0.73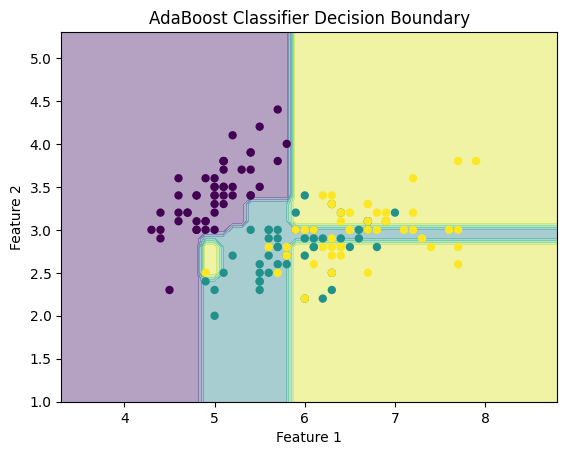
请确保在 Python 环境中安装了 scikit-learn 和其他必要的库,以便成功运行此代码。您可以使用 安装 scikit-learn。pip install scikit-learn
六、结论
AdaBoost 是机器学习工具包中的一项出色算法,展示了集成方法在提高模型准确性方面的强大功能。它能够将弱学习者转化为强分类器,使其成为解决不同领域复杂分类问题的宝贵资产。随着技术的不断进步,AdaBoost的适应性和有效性可能会确保其在不断发展的机器学习和人工智能领域中成为重要工具的地位。
相关文章:
AdaBoost:提升机器学习的力量
一、介绍 机器学习已成为现代技术的基石,为从推荐系统到自动驾驶汽车的一切提供动力。在众多机器学习算法中,AdaBoost(Adaptive Boosting的缩写)作为一种强大的集成方法脱颖而出,为该领域的成功做出了重大贡献。AdaBoo…...
Pikachu(皮卡丘靶场)初识XSS(常见标签事件及payload总结)
目录 1、反射型xss(get) 2、反射性xss(post) 3、存储型xss 4、DOM型xss 5、DOM型xss-x XSS又叫跨站脚本攻击,是HTML代码注入,通过对网页注入浏览器可执行代码,从而实现攻击。 1、反射型xss(get) Which NBA player do you like? 由…...
一则DNS被重定向导致无法获取MySQL连接处理
同事反馈xwik应用端报java exception 获取MySQL连接超时无法连接到数据库实例 经过告警日志发现访问进来的IP地址数据库端无法被解析,这里可以知道问题出现在Dns配置上了 通过以上报错检查/etc/resolve.conf 发现namesever 被重定向设置成了114.114.114.114 域名 …...

Vue3中如何使用this
import { getCurrentInstance, ComponentInternalInstance } from vuesetup() {// as ComponetInternalInstance表示类型断言,ts时使用。否则报错,proxy为nullconst { proxy } getCurrentInstance() as ComponetInternalInstanceproxy.$parentproxy.$re…...
7.jvm对象内存布局
目录 概述对象里的三个区对象头验证代码控制台输出分析 验证2代码控制台输出 实例数据对其填充 访问对象结束 概述 jvm对象内存布局详解。 相关文章在此总结如下: 文章地址jvm基本知识地址jvm类加载系统地址双亲委派模型与打破双亲委派地址运行时数据区地址运行时数…...
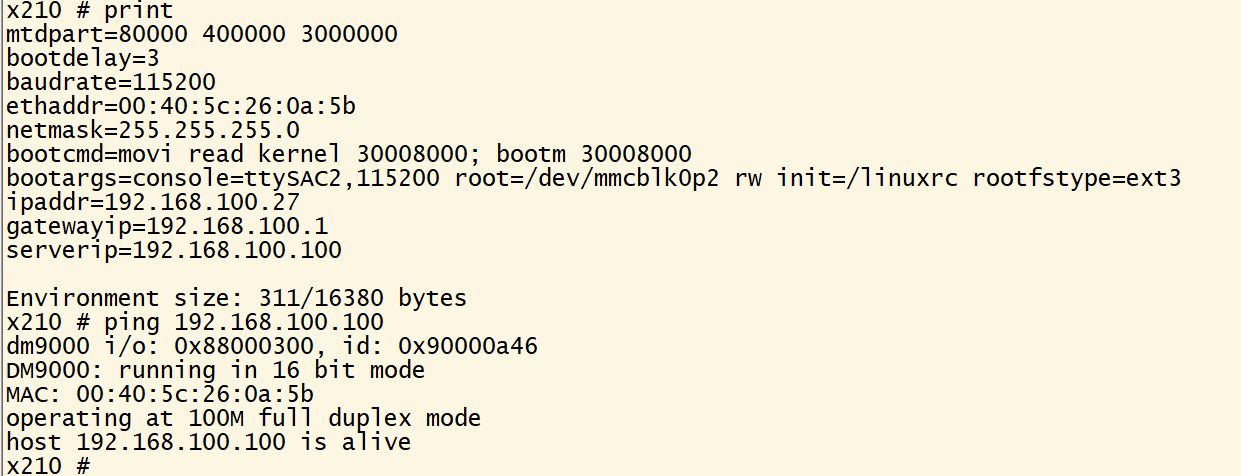
U-boot(一):Uboot命令和tftp
本文主要基于S5PV210探讨uboot。 uboot 部署:uboot(180~400K的裸机程序)在Flash(可上电读取)、OS在FLash(nand) 启动过程:上电后先执行uboot、uboot初始化DDR和Flash,将OS从Flash中读到DDR中启动OS,uboot结束 特点:…...
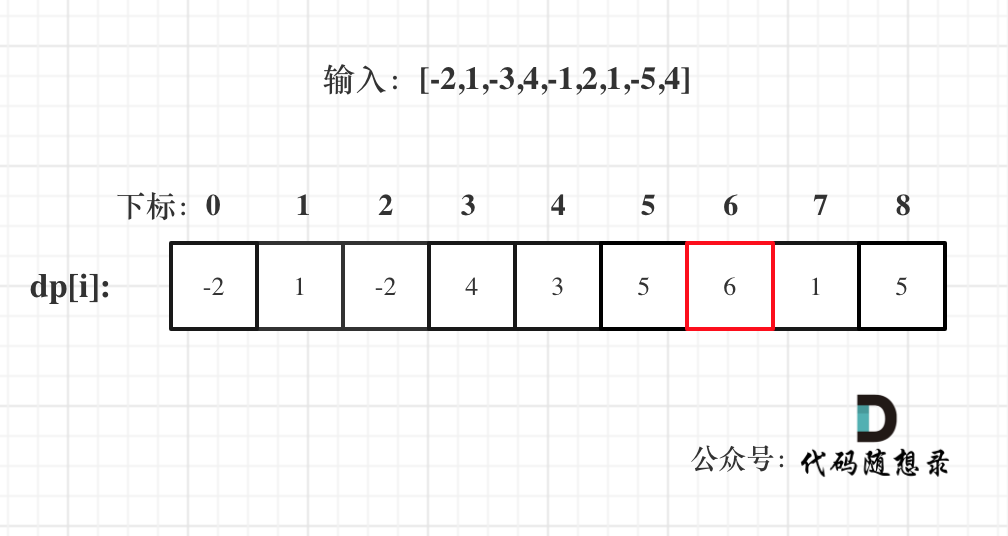
代码随想录算法训练营第五十三天丨 动态规划part14
1143.最长公共子序列 思路 本题和动态规划:718. 最长重复子数组 (opens new window)区别在于这里不要求是连续的了,但要有相对顺序,即:"ace" 是 "abcde" 的子序列,但 "aec" 不是 &quo…...
pdf增强插件 Enfocus PitStop Pro 2022 mac中文版功能介绍
Enfocus PitStop Pro mac是一款 Acrobat 插件,主要用于 PDF 预检和编辑。这个软件可以帮助用户检查和修复 PDF 文件中的错误,例如字体问题、颜色设置、图像分辨率等。同时,Enfocus PitStop Pro 还提供了丰富的编辑工具,可以让用户…...
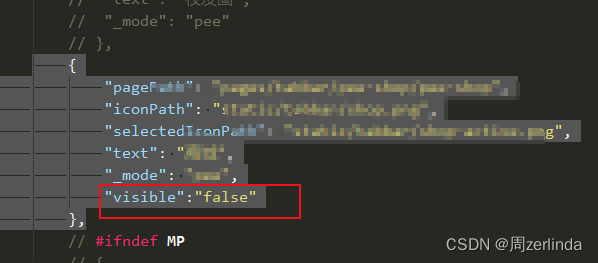
uniapp app tabbar 页面默认隐藏
1.在page.json 中找到tabbar visible 默认为true,设为false则是不显示 uni.setTabBarItem({ index: 1, //列表索引 visible:true //显示或隐藏 })...

深度学习 YOLO 实现车牌识别算法 计算机竞赛
文章目录 0 前言1 课题介绍2 算法简介2.1网络架构 3 数据准备4 模型训练5 实现效果5.1 图片识别效果5.2视频识别效果 6 部分关键代码7 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于yolov5的深度学习车牌识别系统实现 该项目较…...
:IM安全相关文章(Part12) [共15篇])
即时通讯技术文集(第23期):IM安全相关文章(Part12) [共15篇]
为了更好地分类阅读 52im.net 总计1000多篇精编文章,我将在每周三推送新的一期技术文集,本次是第23 期。 [- 1 -] 理论联系实际:一套典型的IM通信协议设计详解(含安全层设计) [链接] http://www.52im.net/thread-283-…...

为什么UI自动化难做?—— 关于Selenium UI自动化的思考
在快速迭代的产品、团队中,UI自动化通常是一件看似美好,实际“鸡肋”(甚至绝大部分连鸡肋都算不上)的工具。原因不外乎以下几点: 1 效果有限 通常只是听说过,就想去搞UI自动化的团队,心里都认…...

Python小白之“没有名称为xlwings‘的模块”
题外话:学习和安装Python的第一个需求就是整理一个Excel,需要读取和写入Excel 背景:取到的模板代码,PyCharm本地运行报错:没有名称为xlwings的模块 解决办法:这类报模板找不到的错,即是模块缺…...

RK3588 学习教程1——获取linux sdk
上手rk3588前,需要先拥有一块开发板,这样可以少走很多弯路。个人推荐买一块itx3588j的板子。挺好用,接口丰富,可玩性高。 sdk可以直接在firefly官网下载,不用管什么版本,下载下来后直接更新即可࿰…...
保护您的Google账号安全:检查和加固措施
简介:随着我们在日常生活中越来越依赖于Google账号,我们的个人信息和敏感数据也变得越来越容易受到威胁。为了确保您的Google账号的安全性,本文将介绍一些简单但有效的方法,帮助您检查和加固您的Google账号。 --- 在数字时代&am…...

「Verilog学习笔记」优先编码器Ⅰ
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 分析 分析编码器的功能表: 当使能El1时,编码器工作:而当E10时,禁止编码器工作,此时不论8个输入端为何种状态&…...
服务端-客户端)
java实现TCP通信(socket)服务端-客户端
我在写的时候,我的需求就很简单,写一个服务端,去让别人进行请求,借鉴了很多聊天室什么的,越搞越复杂。 期间也使用到了 BufferedReader中readLine()方法,进行获取客户端传来的数据&…...
企业信息模糊搜索API的使用及应用场景
前言 随着企业数据的不断增加,如何高效地搜索和管理这些数据成为了企业管理者关注的重要问题。而企业信息模糊搜索API的出现,为企业提供了一种高效的解决方案。本文将介绍企业信息模糊搜索API的使用及应用场景。 一、什么是企业信息模糊搜索API&#x…...

.net6+aspose.words导出word并转pdf
本文使用net6框架,aspose.word破解激活并兼容net6,导出word模板并兼容识别html并给其设置字体,前端直接浏览器下载,后端保存文件并返回文件流,还有批量导出并压缩zip功能 1、安装Aspose.Words的nuget包选择21.8.0 版本…...

深度学习 植物识别算法系统 计算机竞赛
文章目录 0 前言2 相关技术2.1 VGG-Net模型2.2 VGG-Net在植物识别的优势(1) 卷积核,池化核大小固定(2) 特征提取更全面(3) 网络训练误差收敛速度较快 3 VGG-Net的搭建3.1 Tornado简介(1) 优势(2) 关键代码 4 Inception V3 神经网络4.1 网络结构 5 开始训练5.1 数据集…...

智能检索新范式,让AIAgent自主决策,提升RAG效率100%!
市面上的 RAG 系统,不管叫什么名字,本质上只有两种做法: 第一种,一次性检索。把用户的 query 向量化,从语料库里捞出 Top-K 个文档片段,拼成一个大 prompt 塞给模型。GraphRAG、HippoRAG、LightRAG 都属于…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

美团外卖mtgsig与waimai_sign双层签名逆向解析
1. 这不是“爬虫教程”,而是一份反向工程现场笔记你搜到这篇内容,大概率正卡在某个调试窗口前:抓包看到mtgsig和waimai_sign两个参数像两堵墙,无论怎么改请求头、换UA、清缓存,返回永远是{"code":403,"…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...

LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案
LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirror…...

想深耕网络安全行业,这些必备条件缺一不可
网络空间的攻防对抗日益激烈,网络安全已成为企业生存和国家安全的命脉,它负责构筑数字世界的坚固防线,保护核心资产与用户隐私免受侵害。 想要成为一名优秀的网络安全专家,除了敏锐的安全意识和高度的责任感,更需要锤…...

XXPermissions:Android权限管理框架的架构设计与最佳实践
XXPermissions:Android权限管理框架的架构设计与最佳实践 【免费下载链接】XXPermissions Android Permissions Framework, Adapt to Android 16 项目地址: https://gitcode.com/GitHub_Trending/xx/XXPermissions 在Android应用开发中,权限管理一…...

如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制
如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web…...