【PyTorch教程】如何使用PyTorch分布式并行模块DistributedDataParallel(DDP)进行多卡训练

本期目录
- 1. 导入核心库
- 2. 初始化分布式进程组
- 3. 包装模型
- 4. 分发输入数据
- 5. 保存模型参数
- 6. 运行分布式训练
- 7. DDP完整训练代码
- 本章的重点是学习如何使用 PyTorch 中的 Distributed Data Parallel (DDP) 库进行高效的分布式并行训练。以提高模型的训练速度。
1. 导入核心库
-
DDP 多卡训练需要导入的库有:
库 作用 torch.multiprocessingas mp原生Python多进程库的封装器 from torch.utils.data.distributed import DistributedSampler上节所说的DistributedSampler,划分不同的输入数据到GPU from torch.nn.parallel import DistributedDataParallel as DDP主角,核心,DDP 模块 from torch.distributed import init_process_group, destroy_process_group两个函数,前一个初始化分布式进程组,后一个销毁分布式进程组
2. 初始化分布式进程组
-
Distributed Process Group 分布式进程组。它包含在所有 GPUs 上的所有的进程。因为 DDP 是基于多进程 (multi-process) 进行并行计算,每个 GPU 对应一个进程,所以必须先创建并定义进程组,以便进程之间可以互相发现并相互通信。
-
首先来写一个函数
ddp_setup():import torch import os from torch.utils.data import Dataset, DataLoader# 以下是分布式DDP需要导入的核心库 import torch.multiprocessing as mp from torch.utils.data.distributed import DistributedSampler from torch.nn.parallel import DistributedDataParallel as DDP from torch.distributed import init_process_group, destroy_process_group# 初始化DDP的进程组 def ddp_setup(rank, world_size):os.environ["MASTER_ADDR"] = "localhost"os.environ["MASTER_PORT"] = "12355"init_process_group(backend="nccl", rank=rank, world_size=world_size) -
其包含两个入参:
入参 含义 rank 进程组中每个进程的唯一 ID,范围是[0, world_size-1]world_size 一个进程组中的进程总数 -
在函数中,我们首先来设置环境变量:
环境变量 含义 MASTER_ADDR 在rank 0进程上运行的主机的IP地址。单机训练直接写 “localhost” 即可 MASTER_PORT 主机的空闲端口,不与系统端口冲突即可 之所以称其为主机,是因为它负责协调所有进程之间的通信。
-
最后,我们调用
init_process_group()函数来初始化默认分布式进程组。其包含的入参如下:入参 含义 backend 后端,通常是 nccl ,NCCL 是Nvidia Collective Communications Library,即英伟达集体通信库,用于 CUDA GPUs 之间的分布式通信 rank 进程组中每个进程的唯一ID,范围是[0, world_size-1]world_size 一个进程组中的进程总数 -
这样,进程组的初始化函数就准备好了。
【注意】
- 如果你的神经网络模型中包含
BatchNorm层,则需要将其修改为SyncBatchNorm层,以便在多个模型副本中同步BatchNorm层的运行状态。(你可以调用torch.nn.SyncBatchNorm.convert_sync_batchnorm(model: torch.nn.Module)函数来一键把神经网络中的所有BatchNorm层转换成SyncBatchNorm层。)
3. 包装模型
-
训练器的写法有一处需要注意,在开始使用模型之前,我们需要使用 DDP 去包装我们的模型:
self.model = DDP(self.model, device_ids=[gpu_id]) -
入参除了
model以外,还需要传入device_ids: List[int] or torch.device,它通常是由 model 所在的主机的 GPU ID 所组成的列表,
4. 分发输入数据
-
DistributedSampler在所有分布式进程中对输入数据进行分块,确保输入数据不会出现重叠样本。 -
每个进程将接收到指定
batch_size大小的输入数据。例如,当你指定了batch_size为 32 时,且你有 4 张 GPU ,那么有效的 batch size 为:
32 × 4 = 128 32 \times 4 = 128 32×4=128train_loader = torch.utils.data.DataLoader(dataset=train_set,batch_size=32,shuffle=False, # 必须关闭洗牌sampler=DistributedSampler(train_set) # 指定分布式采样器 ) -
然后,在每轮 epoch 的一开始就调用
DistributedSampler的set_epoch(epoch: int)方法,这样可以在多个 epochs 中正常启用 shuffle 机制,从而避免每个 epoch 中都使用相同的样本顺序。def _run_epoch(self, epoch: int):b_sz = len(next(iter(self.train_loader))[0])self.train_loader.sampler.set_epoch(epoch) # 调用for x, y in self.train_loader:...self._run_batch(x, y)
5. 保存模型参数
-
由于我们前面已经使用
DDP(model)包装了模型,所以现在self.model指向的是 DDP 包装的对象而不是 model 模型对象本身。如果此时我们想读取模型底层的参数,则需要调用model.module。 -
由于所有 GPU 进程中的神经网络模型参数都是相同的,所以我们只需从其中一个 GPU 进程那儿保存模型参数即可。
ckp = self.model.module.state_dict() # 注意需要添加.module ... ... if self.gpu_id == 0 and epoch % self.save_step == 0: # 从gpu:0进程处保存1份模型参数self._save_checkpoint(epoch)
6. 运行分布式训练
-
包含 2 个新的入参
rank(代替device) 和world_size。 -
当调用
mp.spawn时,rank参数会被自动分配。 -
world_size是整个训练过程中的进程数量。对 GPU 训练来说,指的是可使用的 GPU 数量,且每张 GPU 都只运行 1 个进程。def main(rank: int, world_size: int, total_epochs: int, save_step: int):ddp_setup(rank, world_size) # 初始化分布式进程组train_set, model, optimizer = load_train_objs()train_loader = prepare_dataloader(train_set, batch_size=32)trainer = Trainer(model=model,train_loader=train_loader,optimizer=optimizer,gpu_id=rank, # 这里变了save_step=save_step)trainer.train(total_epochs)destroy_process_group() # 最后销毁进程组if __name__ == "__main__":import systotal_epochs = int(sys.argv[1])save_step = int(sys.argv[2])world_size = torch.cuda.device_count()mp.spawn(main, args=(world_size, total_epochs, save_step), nprocs=world_size) -
这里调用了
torch.multiprocessing的spawn()函数。该函数的主要作用是在多个进程中执行指定的函数,每个进程都在一个独立的 Python 解释器中运行。这样可以避免由于 Python 全局解释器锁 (GIL) 的存在而限制多线程并发性能的问题。在分布式训练中,通常每个 GPU 或计算节点都会运行一个独立的进程,通过进程之间的通信实现模型参数的同步和梯度聚合。 -
可以看到调用
spawn()函数时,传递args参数时并没有传递rank,这是因为会自动分配,详见下方表格fn入参介绍。入参 含义 fn: function 每个进程中要执行的函数。该函数会以 fn(i, *args)的形式被调用,其中i是由系统自动分配的唯一进程 ID ,args是传递给该函数的参数元组args: tuple 要传递给函数 fn的参数nprocs: int 要启动的进程数量 join: bool 是否等待所有进程完成后再继续执行主进程 (默认值为 True) daemon: bool 是否将所有生成的子进程设置为守护进程 (默认为 False)
7. DDP完整训练代码
首先,创建了一个训练器 Trainer 类。
import torch
import os
from torch.utils.data import Dataset, DataLoader# 以下是分布式DDP需要导入的核心库
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group# 初始化DDP的进程组
def ddp_setup(rank: int, world_size: int):"""Args:rank: Unique identifier of each process.world_size: Total number of processes."""os.environ["MASTER_ADDR"] = "localhost"os.environ["MASTER_PORT"] = "12355"init_process_group(backend="nccl", rank=rank, world_size=world_size)class Trainer:def __init__(self,model: torch.nn.Module,train_loader: DataLoader,optimizer: torch.optim.Optimizer,gpu_id: int,save_step: int # 保存点(以epoch计)) -> None:self.gpu_id = gpu_id,self.model = DDP(model, device_ids=[self.gpu_id]) # DDP包装模型self.train_loader = train_loader,self.optimizer = optimizer,self.save_step = save_stepdef _run_batch(self, x: torch.Tensor, y: torch.Tensor):self.optimizer.zero_grad()output = self.model(x)loss = torch.nn.CrossEntropyLoss()(output, y)loss.backward()self.optimizer.step()def _run_epoch(self, epoch: int):b_sz = len(next(iter(self.train_loader))[0])self.train_loader.sampler.set_epoch(epoch) # 调用set_epoch(epoch)洗牌print(f'[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_loader)}')for x, y in self.train_loader:x = x.to(self.gpu_id)y = y.to(self.gpu_id)self._run_batch(x, y)def _save_checkpoint(self, epoch: int):ckp = self.model.module.state_dict()torch.save(ckp, './checkpoint.pth')print(f'Epoch {epoch} | Training checkpoint saved at ./checkpoint.pth')def train(self, max_epochs: int):for epoch in range(max_epochs):self._run_epoch(epoch)if self.gpu_id == 0 and epoch % self.save_step == 0:self._save_checkpoint(epoch)
然后,构建自己的数据集、数据加载器、神经网络模型和优化器。
def load_train_objs():train_set = MyTrainDataset(2048)model = torch.nn.Linear(20, 1) # load your modeloptimizer = torch.optim.SGD(model.parameters(), lr=1e-3)return train_set, model, optimizerdef prepare_dataloader(dataset: Dataset, batch_size: int):return DataLoader(dataset=dataset,batch_size=batch_size,shuffle=False, # 必须关闭pin_memory=True,sampler=DistributedSampler(dataset=train_set) # 指定DistributedSampler采样器)
最后,定义主函数。
def main(rank: int, world_size: int, total_epochs: int, save_step: int):ddp_setup(rank, world_size) # 初始化分布式进程组train_set, model, optimizer = load_train_objs()train_loader = prepare_dataloader(train_set, batch_size=32)trainer = Trainer(model=model,train_loader=train_loader,optimizer=optimizer,gpu_id=rank, # 这里变了save_step=save_step)trainer.train(total_epochs)destroy_process_group() # 最后销毁进程组if __name__ == "__main__":import systotal_epochs = int(sys.argv[1])save_step = int(sys.argv[2])world_size = torch.cuda.device_count()mp.spawn(main, args=(world_size, total_epochs, save_step), nprocs=world_size)
至此,你就已经成功掌握了 DDP 分布式训练的核心用法了。
相关文章:
【PyTorch教程】如何使用PyTorch分布式并行模块DistributedDataParallel(DDP)进行多卡训练
本期目录 1. 导入核心库2. 初始化分布式进程组3. 包装模型4. 分发输入数据5. 保存模型参数6. 运行分布式训练7. DDP完整训练代码 本章的重点是学习如何使用 PyTorch 中的 Distributed Data Parallel (DDP) 库进行高效的分布式并行训练。以提高模型的训练速度。 1. 导入核心库 D…...

Istio学习笔记-体验istio
参考Istio 入门(三):体验 Istio、微服务部署、可观测性 - 痴者工良 - 博客园 (cnblogs.com) 在本章中,我们将会学习到如何部署一套微服务、如何使用 Istio 暴露服务到集群外,并且如何使用可观测性组件监测流量和系统指标。 本章教程示例使用…...

fastjson 系列漏洞
目录 1、 fastjson 1.2.22-1.2.24 版本 1.1 TemplatesImpl (Feature.SupportNonPublicField) 1.2 JNDI && JdbcRowSetImpl 利⽤链 2、fastjson 1.2.41 3、fastjson 1.2.42/1.2.43 4、fastjson 1.2.44-1.2.45 5、fastjson 1.2.46-1.2.47版本反序列化漏洞 jackson…...

odoo前端js对象的扩展方法
odoo前端js对象的扩展方法 在 Odoo 中,你可以使用两种方法来扩展 JavaScript 对象:extends 和 patch。这两种方法在功能上有一些区别。 extends 方法: 使用 extends 方法可以创建一个新的 JavaScript 对象,并继承自现有的对象。这…...
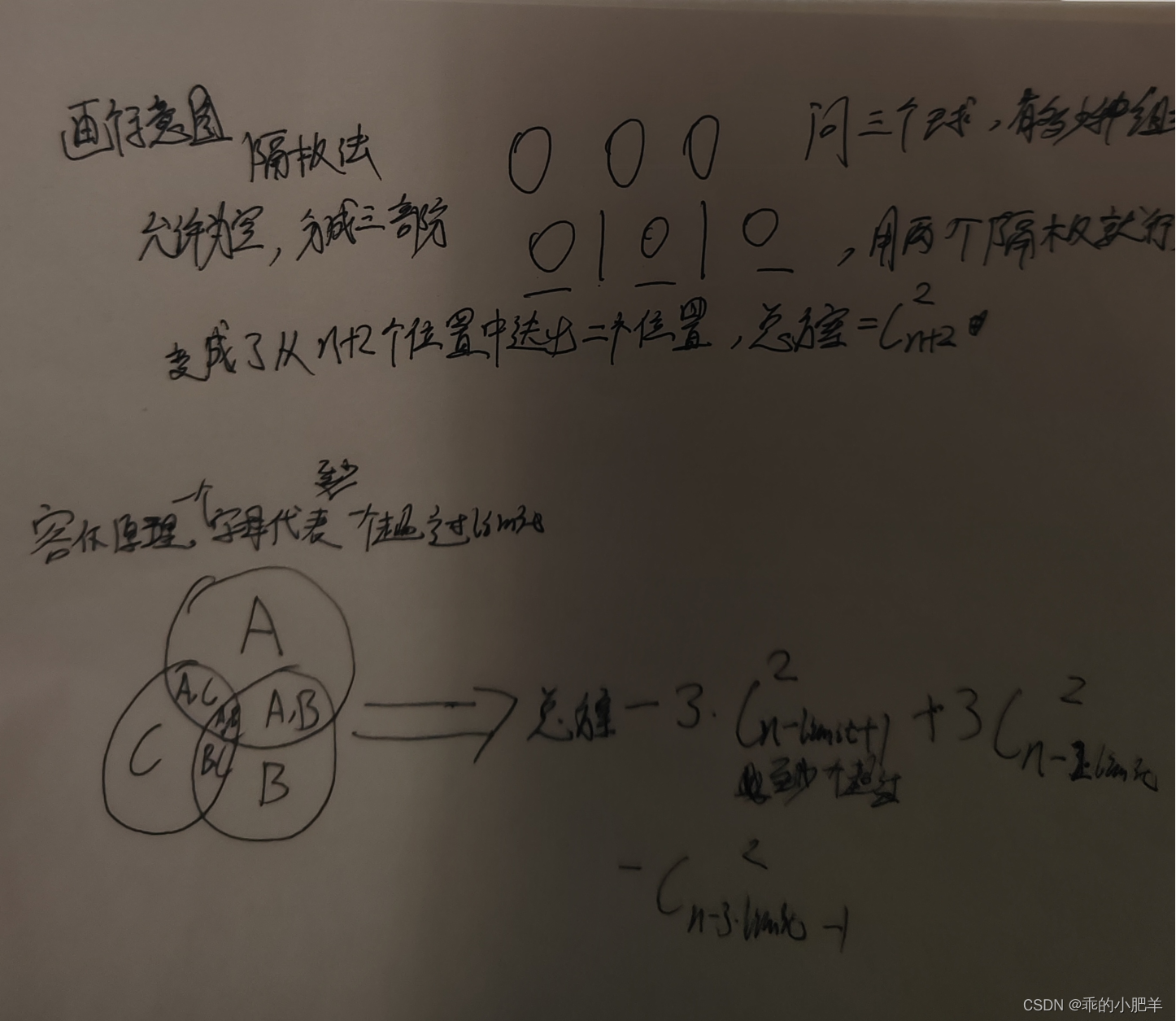
力扣双周赛 -- 117(容斥原理专场)
class Solution { public:long long c2(long long n){return n > 1? n * (n - 1) / 2 : 0;}long long distributeCandies(int n, int limit) {return c2(n 2) - 3 * c2(n - limit 1) 3 * c2(n - 2 * limit) - c2(n - 3 * limit - 1);} };...
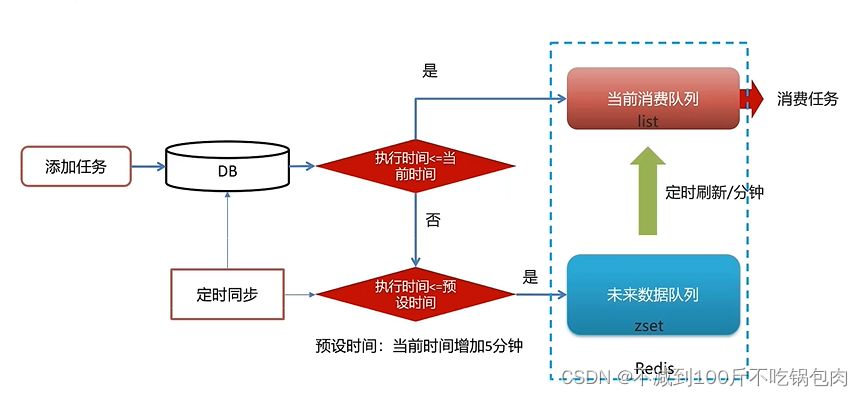
基于Rabbitmq和Redis的延迟消息实现
1 基于Rabbitmq延迟消息实现 支付时间设置为30,未支付的消息会积压在mq中,给mq带来巨大压力。我们可以利用Rabbitmq的延迟队列插件实现消息前一分钟尽快处理 1.1定义延迟消息实体 由于我们要多次发送延迟消息,因此需要先定义一个记录消息…...
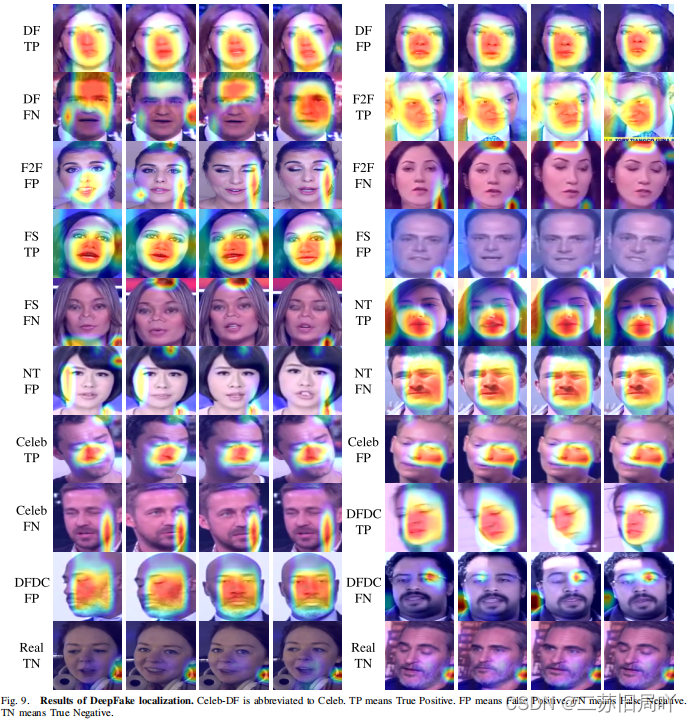
Masked Relation Learning for DeepFake Detection
一、研究背景 1.现有deepfake检测方法大多关注于局部伪影或面部不协调,较少挖掘局部区域间的关系。 2.现有关系挖掘类的工作往往忽略了关系信息的传播。 3.遮挡建模在减轻信息冗余的同时促进高级语义信息(诱导性偏差较小)的挖掘,有…...

R语言爬虫程序自动爬取图片并下载
R语言本身并不适合用来爬取数据,它更适合进行统计分析和数据可视化。而Python的requests,BeautifulSoup,Scrapy等库则更适合用来爬取网页数据。如果你想要在R中获取网页内容,你可以使用rvest包。 以下是一个简单的使用rvest包爬取…...

2023年10月国产数据库大事记-墨天轮
本文为墨天轮社区整理的2023年10月国产数据库大事件和重要产品发布消息。 目录 10月国产数据库大事记 TOP1010月国产数据库大事记(时间线)产品/版本发布兼容认证代表厂商大事记厂商活动排行榜新增数据库相关资料 10月国产数据库大事记 TOP10 10月国产…...
--内存管理之malloc、free 实现原理)
Linux内核分析(十四)--内存管理之malloc、free 实现原理
目录 一、引言 二、malloc实现方式 ------>2.1、动态内存分配的系统调用:brk / sbrk ------>2.2、malloc实现思路 ------------>2.2.1、最佳适应法 ------------>2.2.2、最差适应法 ------------>2.2.3、首次适应法 ------------>2.2.4、下一个适应…...

Hive函数
1. Hive 内置运算符 整体上,Hive 支持的运算符可以分为三大类:关系运算、算术运算、逻辑运算。 官方参考文档:LanguageManual UDF - Apache Hive - Apache Software Foundation 也可以使用下述方式查看运算符的使用方式: -- 显…...

教资笔记(目录)
目录 中小学教资笔记总结中学教资小学教资小学中学科一《综合素质》(通用):考情分析:学习笔记 小学科二《教育知识与能力》:考情分析:学习笔记: 中小学教资笔记总结 2023.9.16教资考试 笔试成绩…...
的注意事项)
np.repeat()的注意事项
对于一个shape为(3, 2)的矩阵a, b a.repeat(9, axis1)。 那b[:, :9]是相同的,b[:, 9:]是相同的,意见 a np.random.rand(3, 2) b a.repeat(9, axis1) np.all(b[:, 0] b[:, 1]), np.all(b[:, 0] b[:, 9]) Out: (Tr…...

239. 滑动窗口最大值
239. 滑动窗口最大值 原题链接:完成情况:解题思路:参考代码:错误经验吸取 原题链接: 239. 滑动窗口最大值 https://leetcode.cn/problems/sliding-window-maximum/description/ 完成情况: 解题思路&…...

c++ barrier 使用详解
c barrier 使用详解 std::barrier c20 头文件 #include <barrier>。作用:一般被用来协调多个线程,在所有线程都到达屏障点之后,才允许它们继续执行,对于需要线程间同步的并行算法和任务来说非常有用。使用步骤:…...

c# 接口
c#接口 namespace demo1 {/// <summary>/// 接口使用interface关键字进行定义/// 接口中只能声明方法不能定义,也就是说声明的方法不能有方法体。/// 接口不能包含常量、字段、运算符、实例构造函数、析构函数或类型,不能包含静态成员。由于不能有…...
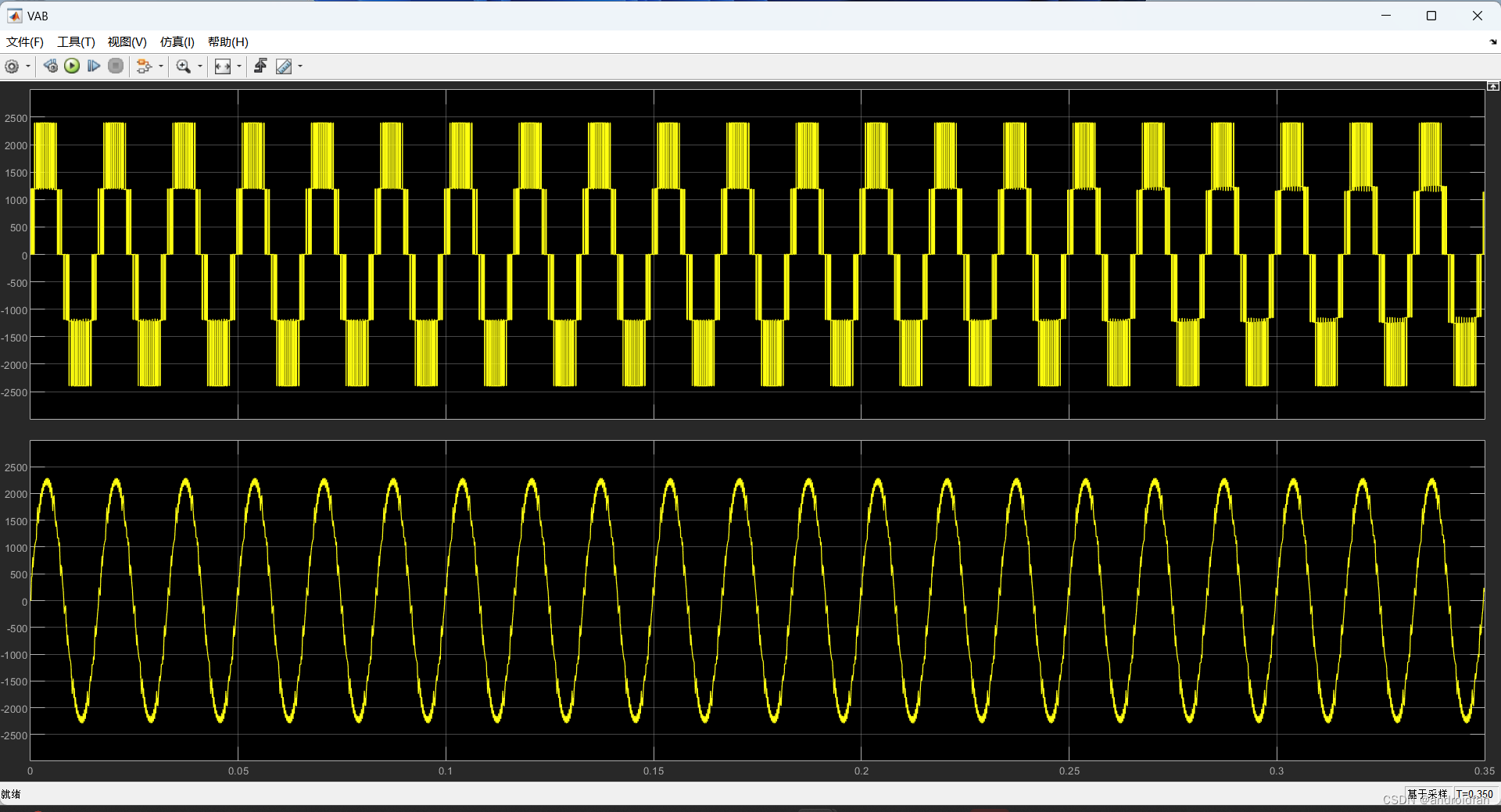
1、NPC 三电平SVPWM simulink仿真
1、SVPWM时间计算函数,是从matlab的SVPWM3L_TimingCalculation.p文件中反汇编出来的函数: function [TgABC_On ,TgABC_Off ,Sn ]SVPWM3L_TimingCalculation_frompfile (Vref ,DeltaVdc ,Fsw ) %#codegen %coder .allowpcode (plain ); TgABC_On [0 ,0 ,…...

JAVA对象列表强转失败,更好的方法
JAVA将无法强转的list泛型对象使用JSON工具类转换为list类 List<DiskUseRateVo> list JSON.parseArray(JSON.toJSONString(httpGet(url).getContent()), DiskUseRateVo.class);之前一直强转发现后续list.get(0)报错,用JSON解决了问题。...

2023最新版本 从零基础入门C++与QT(学习笔记) -5- 动态内存分配(new)
🎏C的动态内存要比C方便 🎄注意C申请内存的时候可以直接的初始化!!! 🎄格式(申请一块内存) 🎈new(关键字) 变量类型 🎄格式(申请多块内存&am…...
asp.net校园招聘管理系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio
一、源码特点 asp.net 校园招聘管理系统是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为vs2010,数据库为sqlserver2008,使用c#语言开发 应用技术:asp.net c#s…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...

机器学习与深度学习在社交媒体心理健康检测中的权衡与选择
1. 项目概述:当AI遇见心灵,社交媒体心理健康检测的技术十字路口在社交媒体成为我们数字生活延伸的今天,海量的文本数据无意中记录着用户的情感波动与心理状态。作为一名长期混迹于数据科学和自然语言处理(NLP)一线的从…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点 在团队协作或管理多个AI应用项目时,一个常见的痛点是每个…...

3分钟快速上手:bilibili-parse视频解析API终极指南
3分钟快速上手:bilibili-parse视频解析API终极指南 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse bilibili-parse是一款高效专业的B站视频解析工具,为开发者和内容创作者提供…...