kafka+ubuntu20.04+docker配置
记录一次配置过程
安装docker
参加下面链接的第一部分
Ubuntu20.04使用docker安装kafka服务-CSDN博客
安装zookeeper
docker run -d --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime wurstmeister/zookeeper
安装kafka服务
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=[你的IP地址]:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://[你的IP地址]:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka改成我自己的本机的就是:
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.147.131:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.147.131:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka进入docker
执行docker ps -a命令,查看结果如下:

注意上述结果显示kafka和zookeeper都是已关闭状态,需要开启,使用下面的命令:docker start 容器id,即
docker start a01c
docker start c0c7注意要先启动父容器(或者说是依赖项zookeeper),再启动子容器kafka,容器id输入前几位有区分即可,不必全部输入,也不必补全(tab不会给你补全)
执行docker ps -a命令,再次查看结果如下:

ok这就启动成功了
然后执行命令进入docker
docker exec -it [container-id] /bin/sh #container-id就是上图中c0c7这一串数字,执行命令时只需要输入前几个数字/字母即可
cd /opt/kafka/bin #跳转到kafka目录下的bin目录,这下面有一些可执行脚本换成我的本机就是执行下面的命令:
docker exec -it c0c7 /bin/sh #container-id就是上图中41b8e4db352f这一串数字,执行命令时只需要输入前几个数字/字母即可
cd /opt/kafka/bin #跳转到kafka目录下的bin目录,这下面有一些可执行脚本得到下面的结果:

生产者消费者模式初体验
启动生产者
注意下面的ip:192.168.147.131要和你本机ip一致,使用ifconfig命令查看
./kafka-console-producer.sh --broker-list 192.168.147.131:9092 --topic wxj打开另一个终端,启动消费者
注意ip要一致,topic要一致
docker exec -it c0c7 /bin/sh
cd /opt/kafka/bin
./kafka-console-consumer.sh --bootstrap-server 192.168.147.131:9092 --topic wxj运行效果如下:
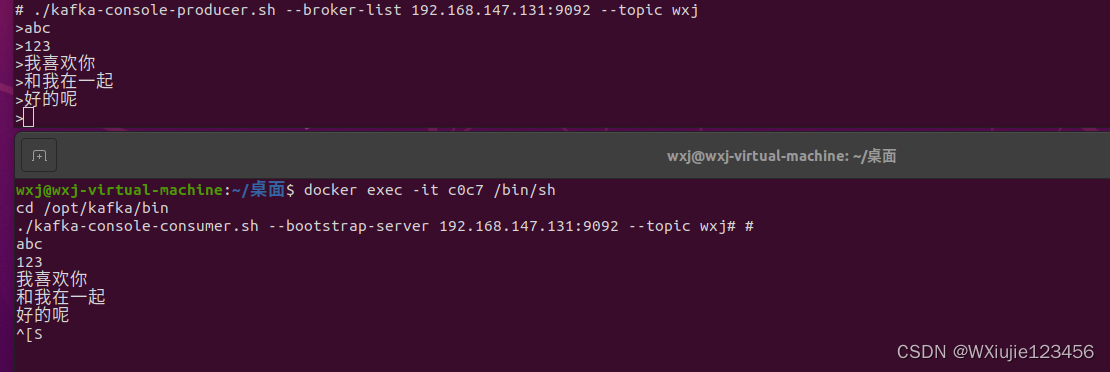
其他一点别的,就是常识啦,比如如何退出生产者消费者的环境,ctrl+c,ctrl+d都试试,如何退出容器,可以试试输入exit命令
ok 完事了,还是去探索腾讯云的kafka服务吧
常用命令行命令
首先进入kafka容器的环境中
docker exec -it c0c7 /bin/sh
cd /opt/kafka/binkafka-topics.sh
对主题topic进行增删改查的工具
常用选项如下:
--bootstrap-server:kafka服务器ip:port,需要查询指定的topic或者topic列表,必须指定这个量
--create:创建主题
--delete:删除主题
--describe:描述主题
--list:查看主题列表
--alter:修改主题的 partitions等
--topic <String: topic>:主题名
--topic-id <String: topic-id>:主题id
--partitions <Integer: # of partitions>:主题的partition
新增
命令
kafka-topics.sh --bootstrap-server=127.0.0.1:9092 --create --topic wxj2效果
![]()
查看topic列表
命令
kafka-topics.sh --bootstrap-server=127.0.0.1:9092 --list
效果

查看topic详情(描述)
命令
kafka-topics.sh --bootstrap-server=127.0.0.1:9092 --describe --topic wxj2
效果

修改
命令
以修改主题partiion数量为例
kafka-topics.sh --bootstrap-server=127.0.0.1:9092 --alter --topic wxj2 --partitions 3
再次查看topic的描述发现分区完成

删除
命令
kafka-topics.sh --bootstrap-server=127.0.0.1:9092 --delete --topic wxj2kafka-console-producer.sh
标准输入读数据,发送到Kafka的工具
常用选项如下:
--bootstrap-server:kafka服务器ip:port,必须的
--topic <String: topic> :Kafka主题,必须的
--sync:同步发送
--compression-codec [String: compression-codec] :压缩方式,‘none’,‘gzip’, ‘snappy’, ‘lz4’, , ‘zstd’,默认gzip.
使用示例
kafka-topics.sh --bootstrap-server=127.0.0.1:9092 --create --topic demo
kafka-console-producer.sh --bootstrap-server=127.0.0.1:9092 --topic demo
kafka-console-consumer.sh
常用选项如下:
--bootstrap-server:kafka服务器ip:port,必须的
--topic <String: topic> :Kafka主题,必须的
--group <String: consumer group id>:消费者组id
--key-deserializer <String: deserializer for key>:key反序列化,默认是org.apache.kafka.common.serialization.StringDeserializer
--value-deserializer <String: deserializer for values>:value反序列化,默认是org.apache.kafka.common.serialization.StringDeserializer
--offset <String: consume offset>:消费的offset
--partition <Integer: partition>:消费的分区
使用示例
kafka-console-consumer.sh --bootstrap-server=127.0.0.1:9092 --topic demo
kafka-console-consumer.sh --bootstrap-server=127.0.0.1:9092 --topic demo --partition 0 --offset 2
上述命令的使用方法是进入到了docker容器kafka中了,要是不想进入环境直接运行命令的示例是
docker exec -it c0c7 /opt/kafka/bin/kafka-topics.sh --bootstrap-server=127.0.0.1:9092 --create --topic demo
效果:

相关文章:
kafka+ubuntu20.04+docker配置
记录一次配置过程 安装docker 参加下面链接的第一部分 Ubuntu20.04使用docker安装kafka服务-CSDN博客 安装zookeeper docker run -d --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime wurstmeister/zookeeper安装kafka服务 docker run -d --name kafka …...

遍历一个对象,并得出所对应的值
var dates {//定义的对象year:now.getFullYear(),month:now.getMonth()1,date:now.getDate(),hour:now.getHours(),minute:now.getMinutes(),second:now.getSeconds() }//开始遍历循环 var val; for (val in dates){console.log(对象名称:val-对象的值:…...

WGCLOUD的特点整理
做运维工作很多年了,项目中用过不少的运维软件工具,今天整理下WGCLOUD的特点(优点) 首先WGCLOUD是完全免费的 部署使用:部署简单方便,上手容易,几乎没有学习成本,对新手友好 文档…...
新版软考高项试题分析精选(三)
请点击↑关注、收藏,本博客免费为你获取精彩知识分享!有惊喜哟!! 1、项目整体管理要综合考虑项目各个相关过程,围绕整体管理特点,以下说法中,( )是不正确的。 A.项目的…...
从申请服务器到Docker部署Java项目至最后运行完结
目录 1.申请服务器篇 2.配置安全组篇 3.Docker安装篇 4.代码编写打包篇 目录结构 Maven Controller DockerFile 开始打包 5.所需文件上传及镜像构建篇 上传准备 上传jar包及DockerFile文件 指令构建 验证 6.镜像启动服务验证篇 启动镜像 使用云服务器地址进行…...

解决 requests.post 数据字段编码问题的方法
问题背景 在进行网络请求时,我们通常会使用requests库的post方法来发送POST请求。然而,当我们尝试发送包含特殊字符(如中文字符)的数据时,可能会遇到数据字段被编码的问题。这可能会导致请求失败或者服务器无法正确解…...
)
安全运维:cmd命令大全(108个)
1、calc:启动计算器 2、appwiz.cpl:程序和功能 3、certmgr.msc:证书管理实用程序 4、charmap:启动字符映射表 5、chkdsk.exe:Chkdsk磁盘检查(管理员身份运行命令提示符) 6、cleanmgr: 打开磁盘清理工具 7、clico…...
构建Docker基础镜像(ubuntu20.04+python3.9.10+pytorch-gpu-cuda11.8)
文章目录 一、前置条件1.创建 ubuntu 镜像源文件【sources.list】2.下载 python 安装包【Python-3.9.10.tgz】 二、构建方法1.构建目录2.创建DockerFile3.打包镜像 一、前置条件 配置一下 ubuntu 的镜像源下载 python 安装包 1.创建 ubuntu 镜像源文件【sources.list】 内容…...

Flowable自定义Id生成器
内置ID生成器 Flowable内置DbIdGenerator(数据库自增ID)、StrongUuidGenerator(UUID),Flowable默认使用的StrongUuidGenerator看起来太长不好观察数据,可以修改成DbIdGenerator。 Configuration public class FlowableConfig implements EngineConfigu…...

怎样正确选择等保测评机构开展等保测评工作?
随着大家对网络安全的重视,越来越多的企业需要做等保测评了。很多小伙伴想知道怎样正确选择等保测评机构开展等保测评工作?这里就给大家简单说说。 怎样正确选择等保测评机构开展等保测评工作? 【回答】:正确选择等保测评机构开展…...

【论文阅读笔记】Detecting AI Trojans Using Meta Neural Analysis
个人阅读笔记,如有错误欢迎指出! 会议:2021 S&P Detecting AI Trojans Using Meta Neural Analysis | IEEE Conference Publication | IEEE Xplore 问题: 当前防御方法存在一些难以实现的假设,或者要求直…...

【PyTorch教程】如何使用PyTorch分布式并行模块DistributedDataParallel(DDP)进行多卡训练
本期目录 1. 导入核心库2. 初始化分布式进程组3. 包装模型4. 分发输入数据5. 保存模型参数6. 运行分布式训练7. DDP完整训练代码 本章的重点是学习如何使用 PyTorch 中的 Distributed Data Parallel (DDP) 库进行高效的分布式并行训练。以提高模型的训练速度。 1. 导入核心库 D…...

Istio学习笔记-体验istio
参考Istio 入门(三):体验 Istio、微服务部署、可观测性 - 痴者工良 - 博客园 (cnblogs.com) 在本章中,我们将会学习到如何部署一套微服务、如何使用 Istio 暴露服务到集群外,并且如何使用可观测性组件监测流量和系统指标。 本章教程示例使用…...

fastjson 系列漏洞
目录 1、 fastjson 1.2.22-1.2.24 版本 1.1 TemplatesImpl (Feature.SupportNonPublicField) 1.2 JNDI && JdbcRowSetImpl 利⽤链 2、fastjson 1.2.41 3、fastjson 1.2.42/1.2.43 4、fastjson 1.2.44-1.2.45 5、fastjson 1.2.46-1.2.47版本反序列化漏洞 jackson…...

odoo前端js对象的扩展方法
odoo前端js对象的扩展方法 在 Odoo 中,你可以使用两种方法来扩展 JavaScript 对象:extends 和 patch。这两种方法在功能上有一些区别。 extends 方法: 使用 extends 方法可以创建一个新的 JavaScript 对象,并继承自现有的对象。这…...
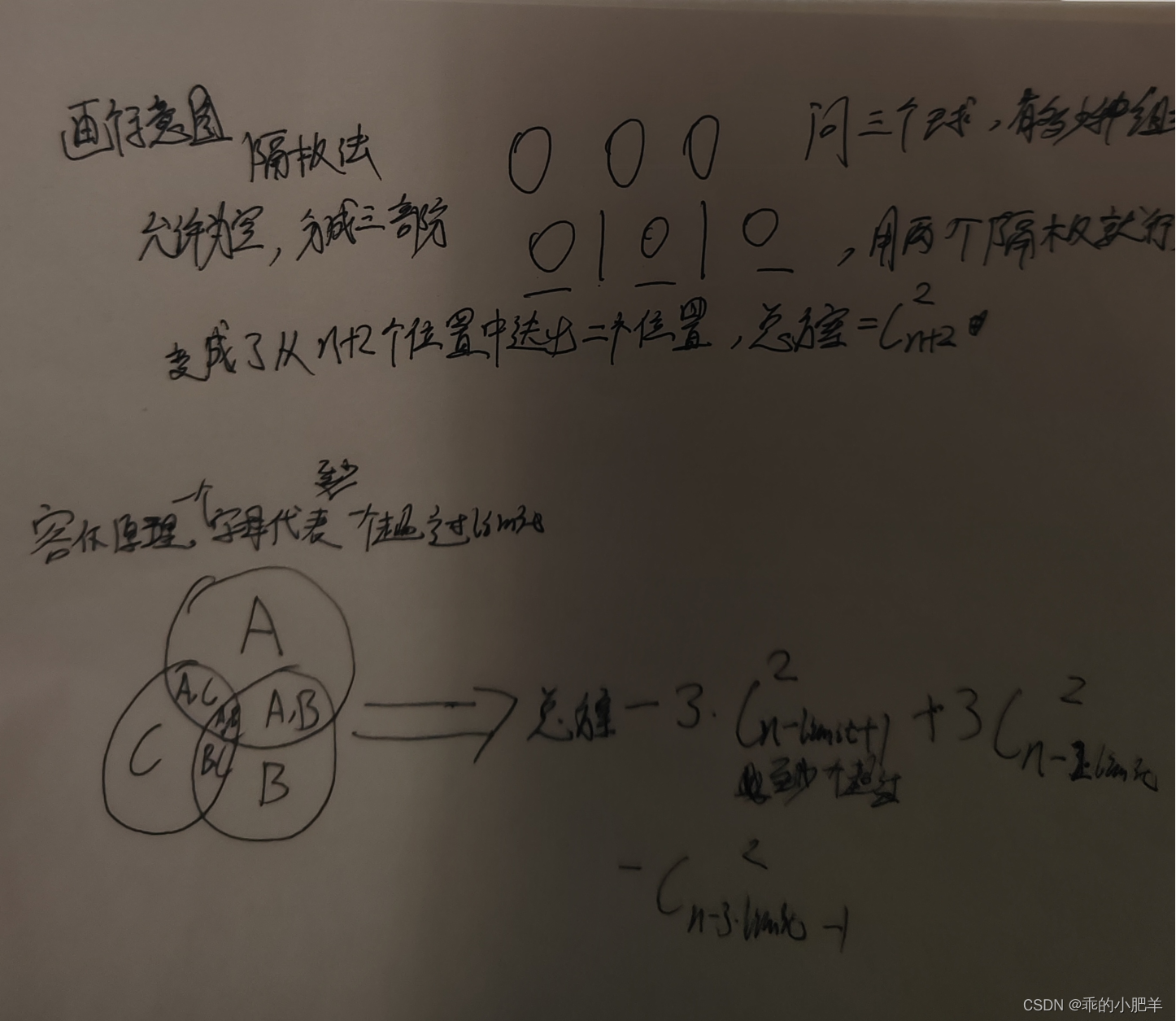
力扣双周赛 -- 117(容斥原理专场)
class Solution { public:long long c2(long long n){return n > 1? n * (n - 1) / 2 : 0;}long long distributeCandies(int n, int limit) {return c2(n 2) - 3 * c2(n - limit 1) 3 * c2(n - 2 * limit) - c2(n - 3 * limit - 1);} };...
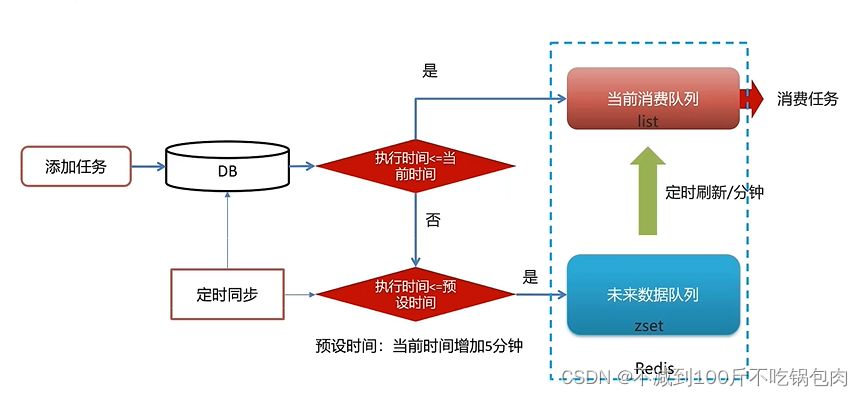
基于Rabbitmq和Redis的延迟消息实现
1 基于Rabbitmq延迟消息实现 支付时间设置为30,未支付的消息会积压在mq中,给mq带来巨大压力。我们可以利用Rabbitmq的延迟队列插件实现消息前一分钟尽快处理 1.1定义延迟消息实体 由于我们要多次发送延迟消息,因此需要先定义一个记录消息…...
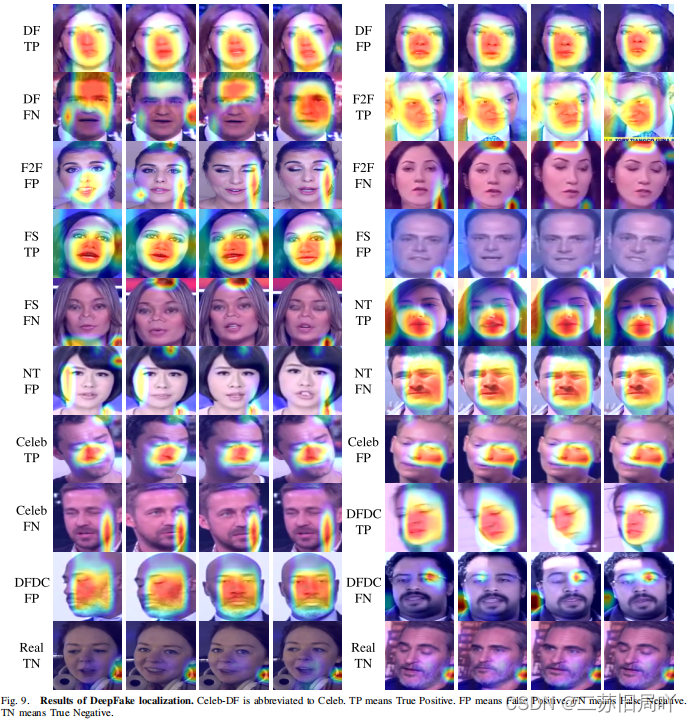
Masked Relation Learning for DeepFake Detection
一、研究背景 1.现有deepfake检测方法大多关注于局部伪影或面部不协调,较少挖掘局部区域间的关系。 2.现有关系挖掘类的工作往往忽略了关系信息的传播。 3.遮挡建模在减轻信息冗余的同时促进高级语义信息(诱导性偏差较小)的挖掘,有…...

R语言爬虫程序自动爬取图片并下载
R语言本身并不适合用来爬取数据,它更适合进行统计分析和数据可视化。而Python的requests,BeautifulSoup,Scrapy等库则更适合用来爬取网页数据。如果你想要在R中获取网页内容,你可以使用rvest包。 以下是一个简单的使用rvest包爬取…...

2023年10月国产数据库大事记-墨天轮
本文为墨天轮社区整理的2023年10月国产数据库大事件和重要产品发布消息。 目录 10月国产数据库大事记 TOP1010月国产数据库大事记(时间线)产品/版本发布兼容认证代表厂商大事记厂商活动排行榜新增数据库相关资料 10月国产数据库大事记 TOP10 10月国产…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

【DeepSeek测试用例生成实战指南】:20年QA专家亲授5大高覆盖率生成模式与3个避坑红线
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的核心价值与适用边界 DeepSeek系列大模型在代码理解与生成任务中展现出显著的上下文建模能力,其测试用例生成功能并非通用“黑盒测试器”,而是聚焦于**单元级、函…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...