Elasticsearch:ES|QL 快速入门
警告:此功能处于技术预览阶段,可能会在未来版本中更改或删除。 Elastic 将努力解决任何问题,但技术预览版中的功能不受官方 GA 功能的支持 SLA 的约束。目前的最新发行版为 Elastic Stack 8.11。
Elasticsearch 查询语言 (ES|QL) 提供了一种强大的方法来过滤、转换和分析存储在 Elasticsearch 中以及未来其他运行时中的数据。 它旨在易于最终用户、SRE 团队、应用程序开发人员和管理员学习和使用。
用户可以编写 ES|QL 查询来查找特定事件、执行统计分析并生成可视化效果。 它支持广泛的命令和功能,使用户能够执行各种数据操作,例如过滤、聚合、时间序列分析等。
Elasticsearch 查询语言 (ES|QL) 使用 “管道”(|) 逐步操作和转换数据。 这种方法允许用户组合一系列操作,其中一个操作的输出成为下一个操作的输入,从而实现复杂的数据转换和分析。
ES|QL 计算引擎
ES|QL 不仅仅是一种语言:它代表了对 Elasticsearch 内新计算功能的重大投资。 为了同时满足 ES|QL 的功能和性能要求,有必要构建全新的计算架构。 ES|QL 搜索、聚合和转换功能直接在 Elasticsearch 本身内执行。 查询表达式不会转换为查询 DSL 来执行。 这种方法使 ES|QL 具有极高的性能和多功能性。
新的 ES|QL 执行引擎在设计时充分考虑了性能 - 它一次对块(block)而不是对每行进行操作,以向量化和缓存局部性为目标,并支持专业化和多线程。 它是一个独立于现有 Elasticsearch 聚合框架的组件,具有不同的性能特征。
让我们开始吧
在接下来的部分我们将展示了如何使用 ES|QL 查询和聚合数据。
前提条件
我们必须安装 Elastic Stack 8.11 及以上版本。
要遵循下面的查询,首先使用以下请求提取一些示例数据:
PUT sample_data
{"mappings": {"properties": {"client.ip": {"type": "ip"},"message": {"type": "keyword"}}}
}PUT sample_data/_bulk
{"index": {}}
{"@timestamp": "2023-10-23T12:15:03.360Z", "client.ip": "172.21.2.162", "message": "Connected to 10.1.0.3", "event.duration": 3450233}
{"index": {}}
{"@timestamp": "2023-10-23T12:27:28.948Z", "client.ip": "172.21.2.113", "message": "Connected to 10.1.0.2", "event.duration": 2764889}
{"index": {}}
{"@timestamp": "2023-10-23T13:33:34.937Z", "client.ip": "172.21.0.5", "message": "Disconnected", "event.duration": 1232382}
{"index": {}}
{"@timestamp": "2023-10-23T13:51:54.732Z", "client.ip": "172.21.3.15", "message": "Connection error", "event.duration": 725448}
{"index": {}}
{"@timestamp": "2023-10-23T13:52:55.015Z", "client.ip": "172.21.3.15", "message": "Connection error", "event.duration": 8268153}
{"index": {}}
{"@timestamp": "2023-10-23T13:53:55.832Z", "client.ip": "172.21.3.15", "message": "Connection error", "event.duration": 5033755}
{"index": {}}
{"@timestamp": "2023-10-23T13:55:01.543Z", "client.ip": "172.21.3.15", "message": "Connected to 10.1.0.1", "event.duration": 1756467}我们有两种方法可以运行查询:
- 在 Dev Tools 中运行
- 在 Discover 中运行
在 Dev Tools 中运行查询
我们需要在 Kibana 的界面中,进入到 Dev Tools。通常一个 ES|QL query API 的命令格式是这样的:
POST /_query?format=txt
{"query": """"""
}在两组 """ """之间输入实际的 ES|QL 查询。 例如:
POST /_query?format=txt
{"query": """FROM sample_data"""
}
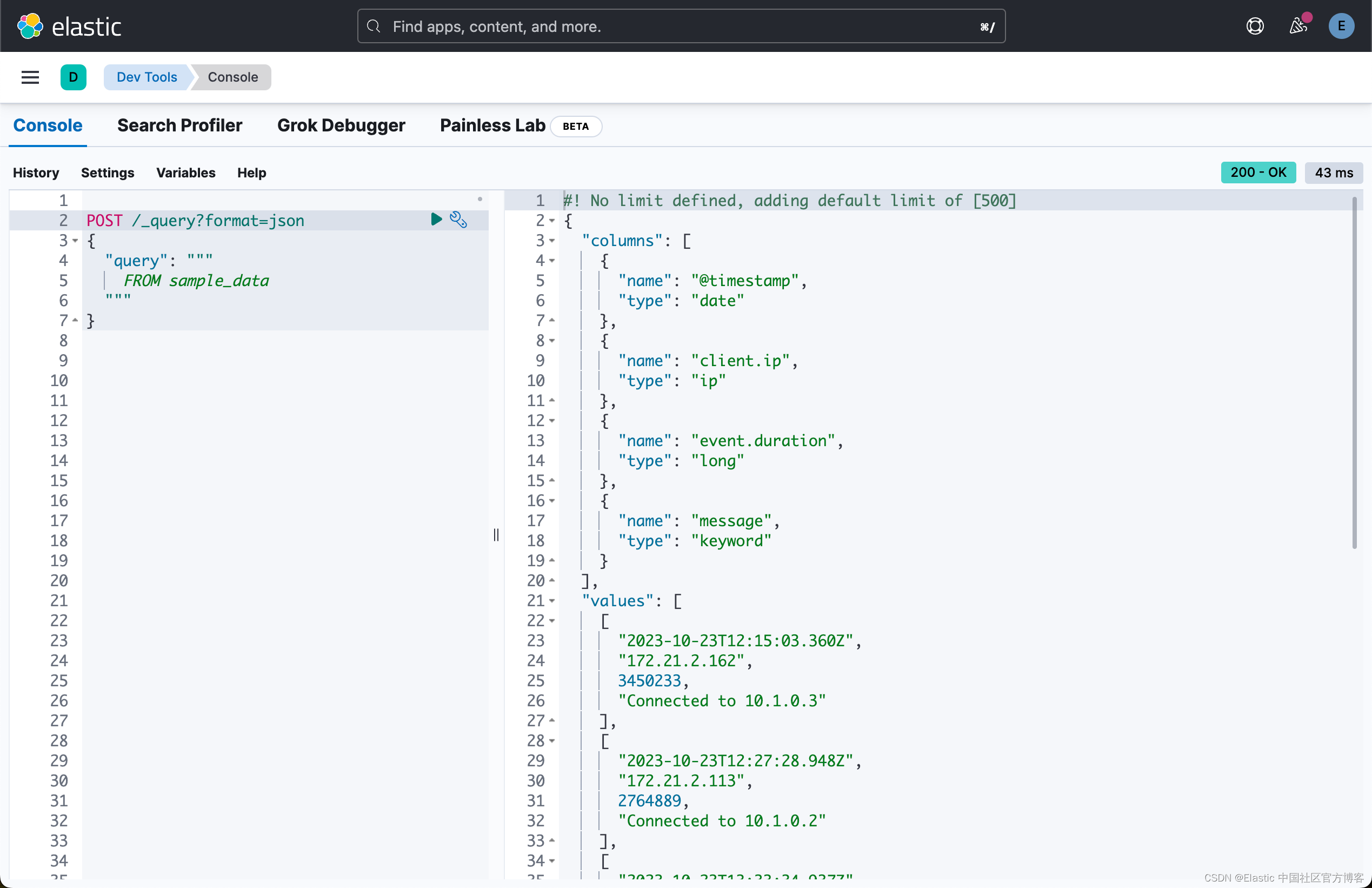
我们也可以使用 JSON 的格式来返回结果:
POST /_query?format=json
{"query": """FROM sample_data"""
}
在 Discover 中使用 ES|QL
我们首先为 sample_data 这个索引创建一个 data view:
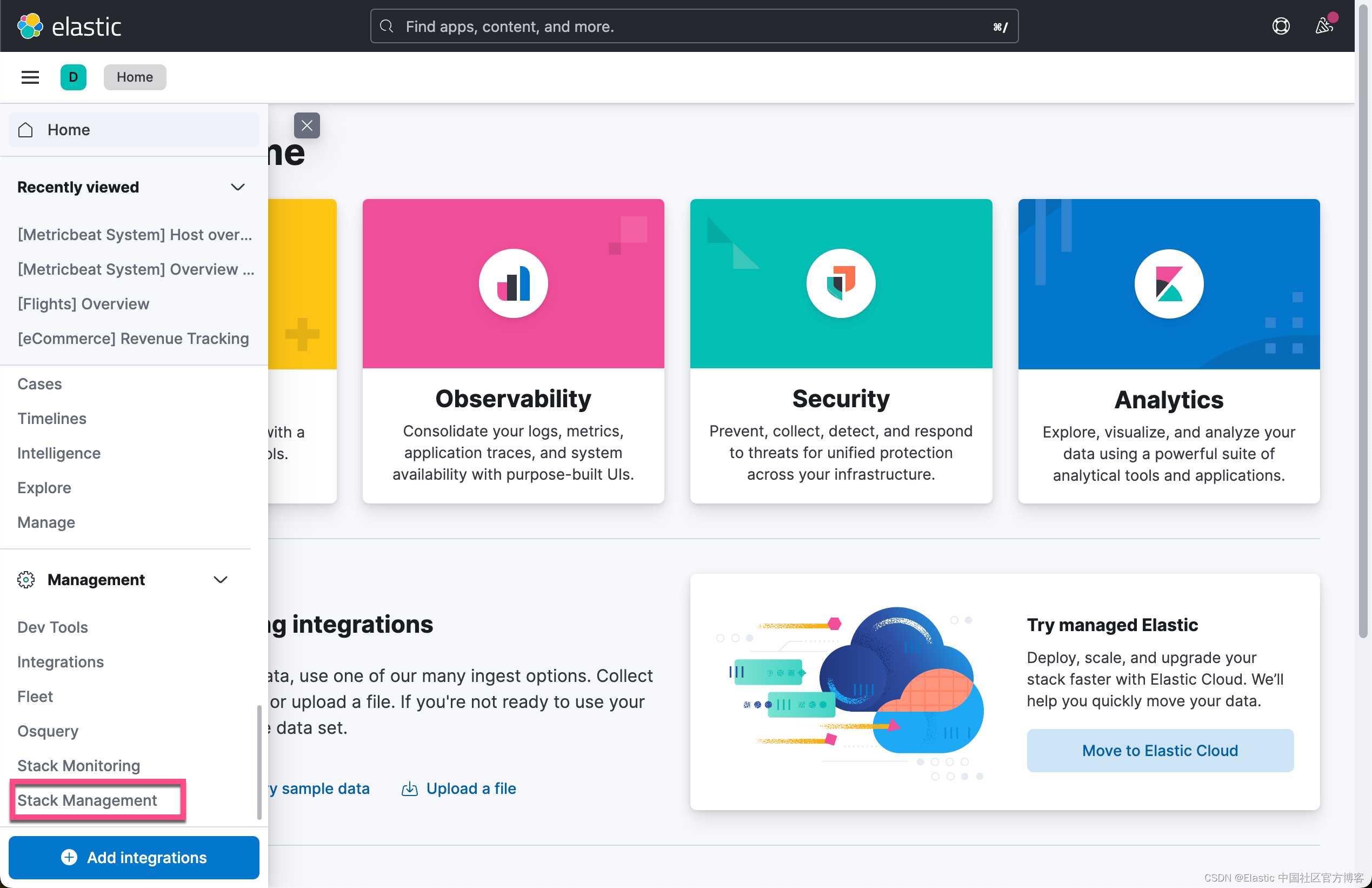
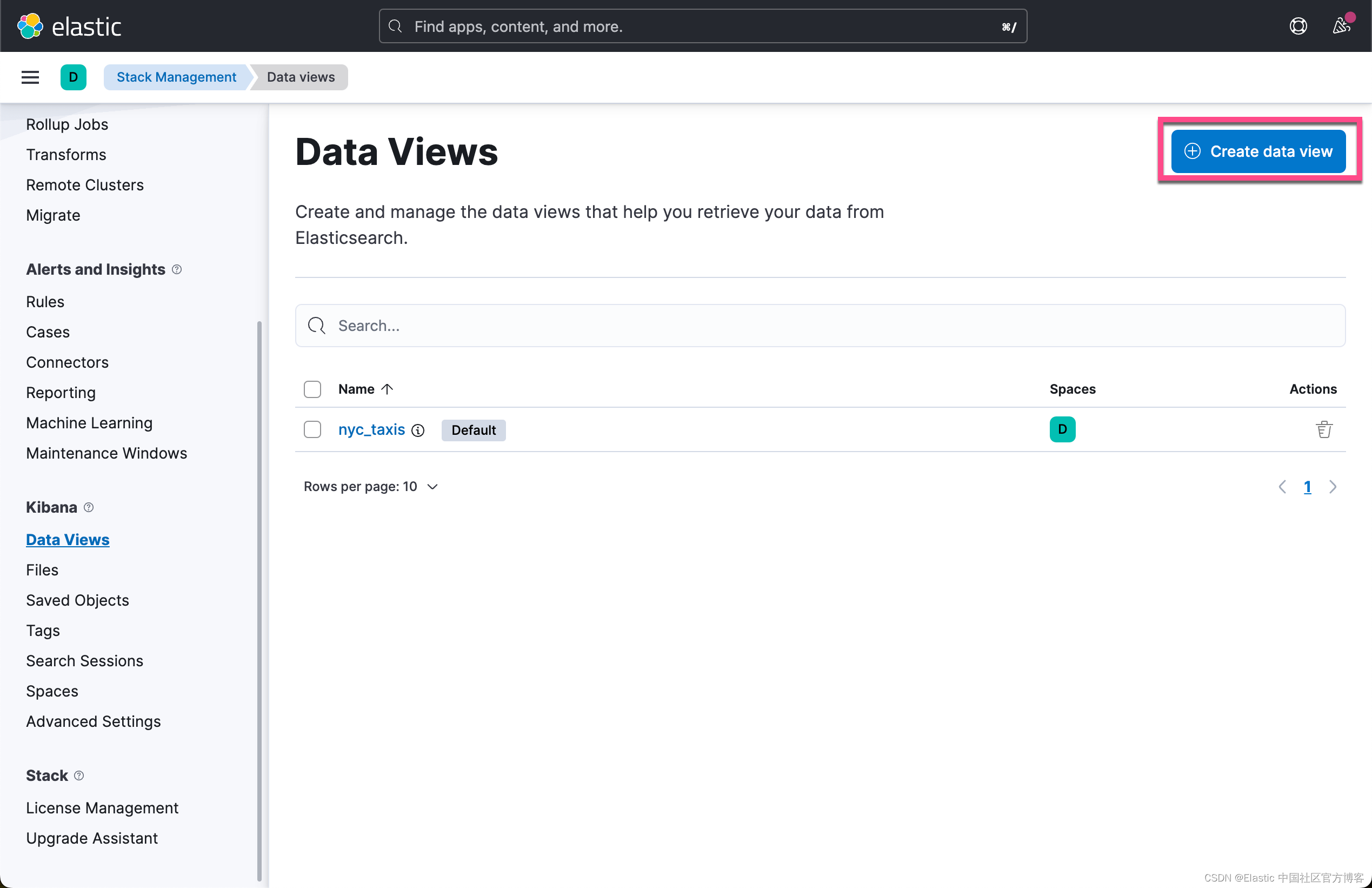
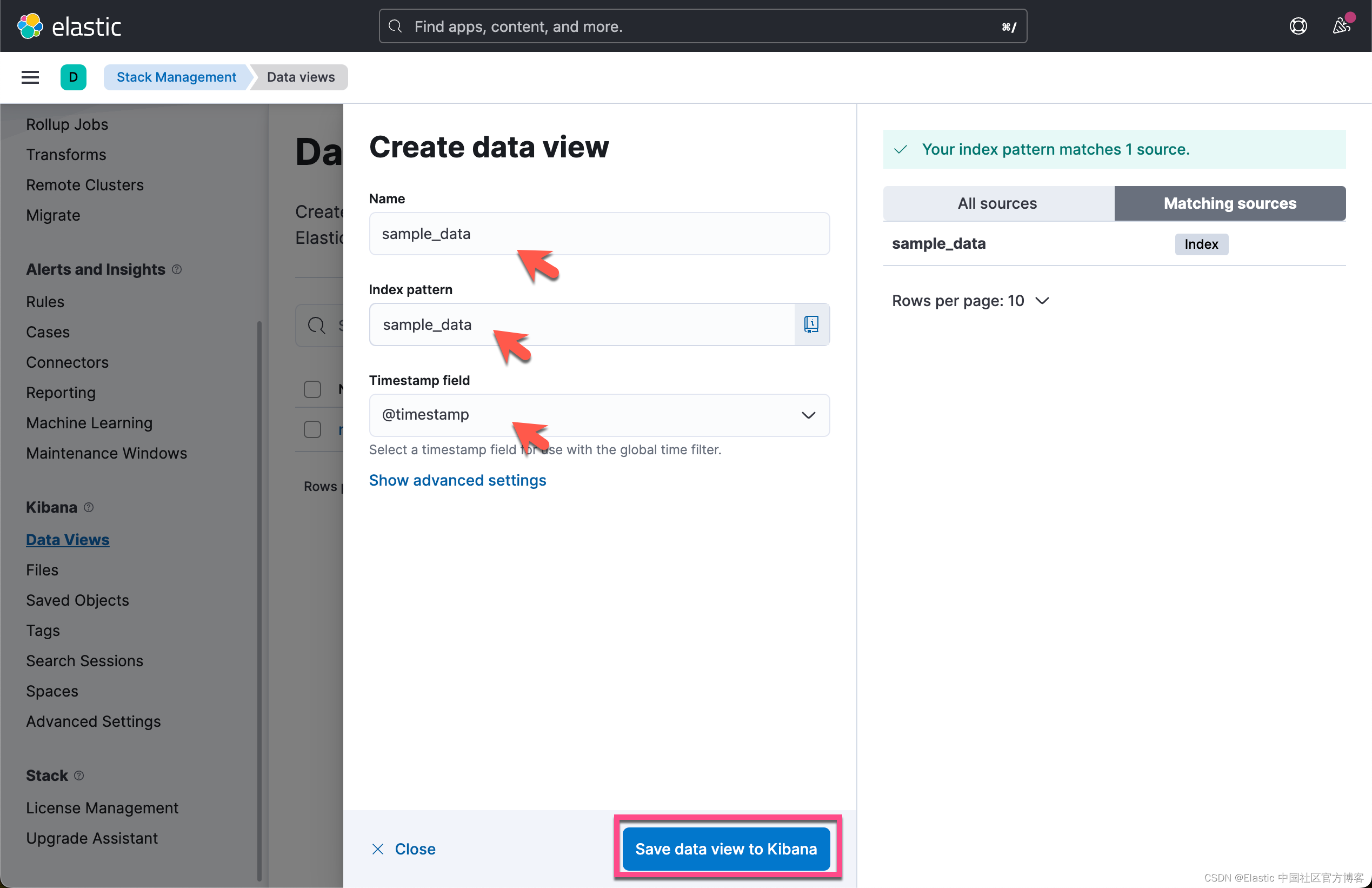

这样我们就创建了一个 sample_data 的 data view。
我们打开 Discover 界面:
我们首先选中 sample_data,然后选中合适的时间窗口:
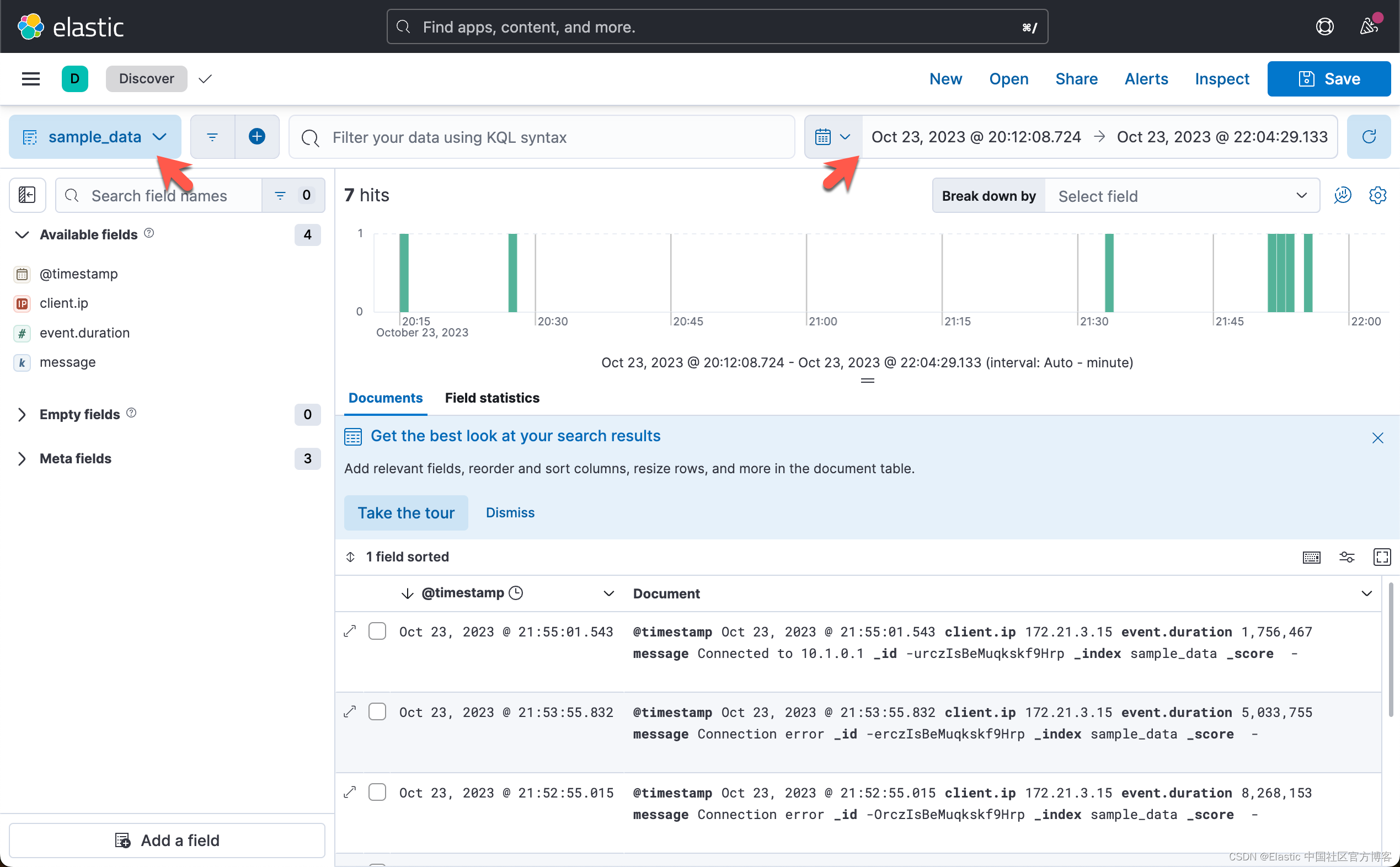

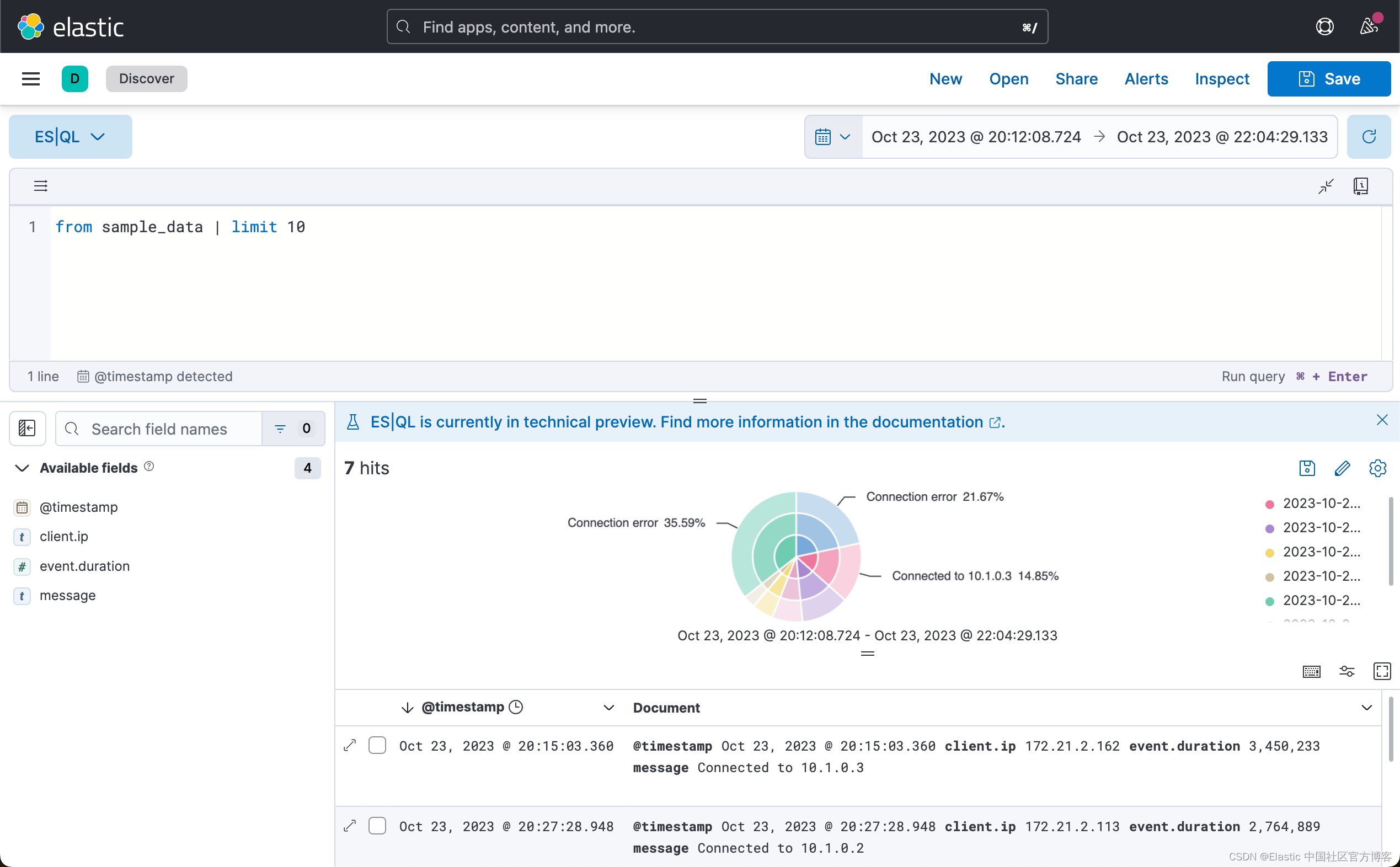
在默认的情况下,它显示 10 个文档。我们也可以看到一个可视化图。为了更方便地编写多行查询,请单击双头箭头按钮(![]() )来展开查询栏:
)来展开查询栏:
我们的第一个 ES|QL 查询
每个 ES|QL 查询都以源 (source) 命令开头。 源命令会生成一个表,通常包含来自 Elasticsearch 的数据。
FROM source 命令返回一个表,其中包含来自数据流、索引或别名的文档。 结果表中的每一行代表一个文档。 此查询从 sample_data 索引中返回最多 500 个文档:
FROM sample_data每列对应一个字段,并且可以通过该字段的名称进行访问。
提示:ES|QL 关键字不区分大小写。 以下查询与前一个查询相同:
from sample_data
处理命令
源命令后面可以跟一个或多个处理命令,用竖线字符分隔:|。 处理命令通过添加、删除或更改行和列来更改输入表。 处理命令可以执行过滤、投影、聚合等。
例如,你可以使用 LIMIT 命令来限制返回的行数,最多为 10,000 行:
FROM sample_data
| LIMIT 3提示:为了便于阅读,你可以将每个命令放在单独的行上。 但是,你不必这样做。 以下查询与前一个查询相同:
FROM sample_data | LIMIT 3
对表格进行排序
另一个处理命令是 SORT 命令。 默认情况下,FROM 返回的行没有定义的排序顺序。 使用 SORT 命令对一列或多列上的行进行排序:
FROM sample_data
| SORT @timestamp DESC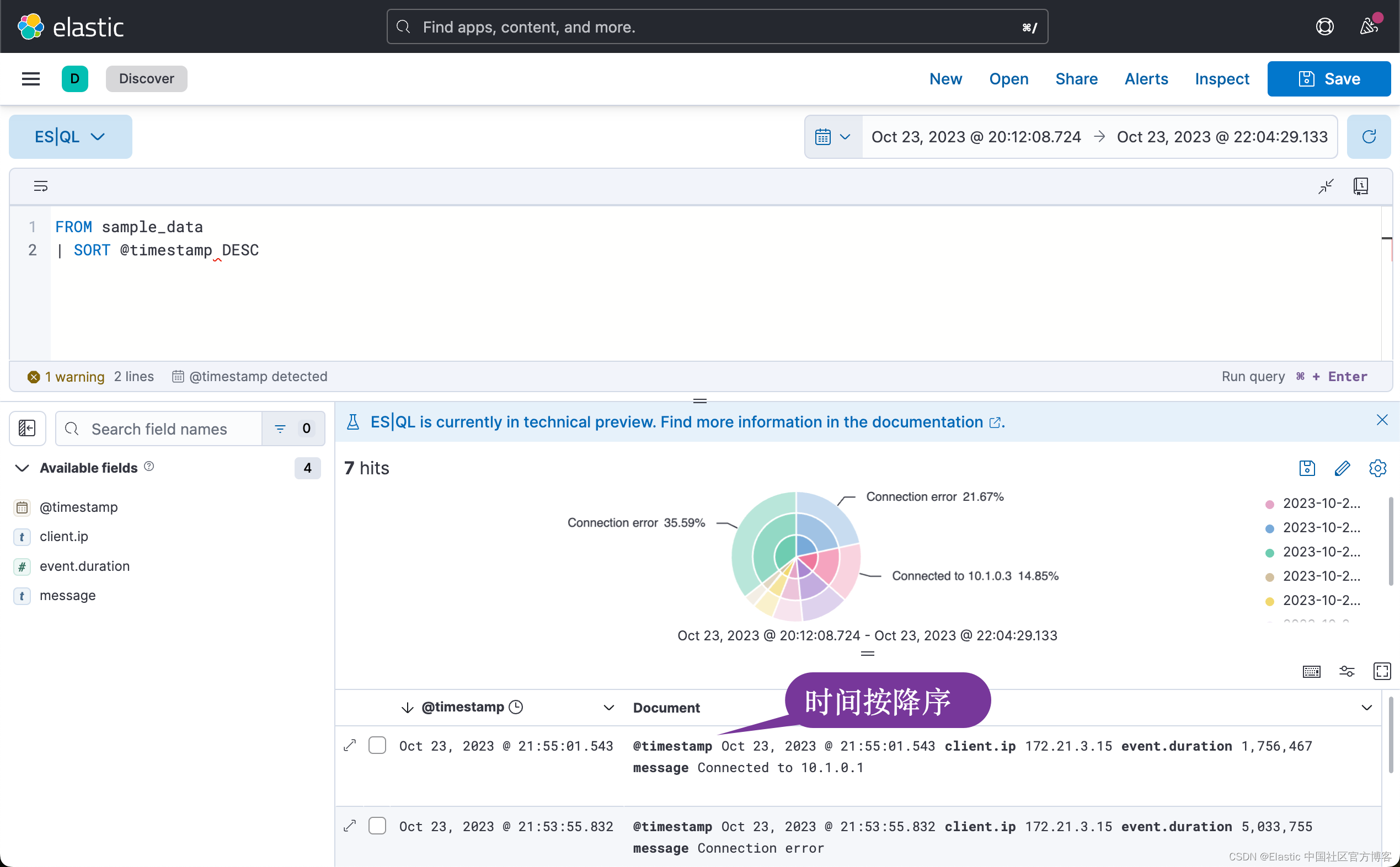
查询数据
使用 WHERE 命令来查询数据。 例如,要查找持续时间超过 5 毫秒的所有事件:
FROM sample_data
| WHERE event.duration > 5000000WHERE 支持多个运算符。 例如,你可以使用 LIKE 对消息列运行通配符查询:
FROM sample_data
| WHERE message LIKE "Connected*"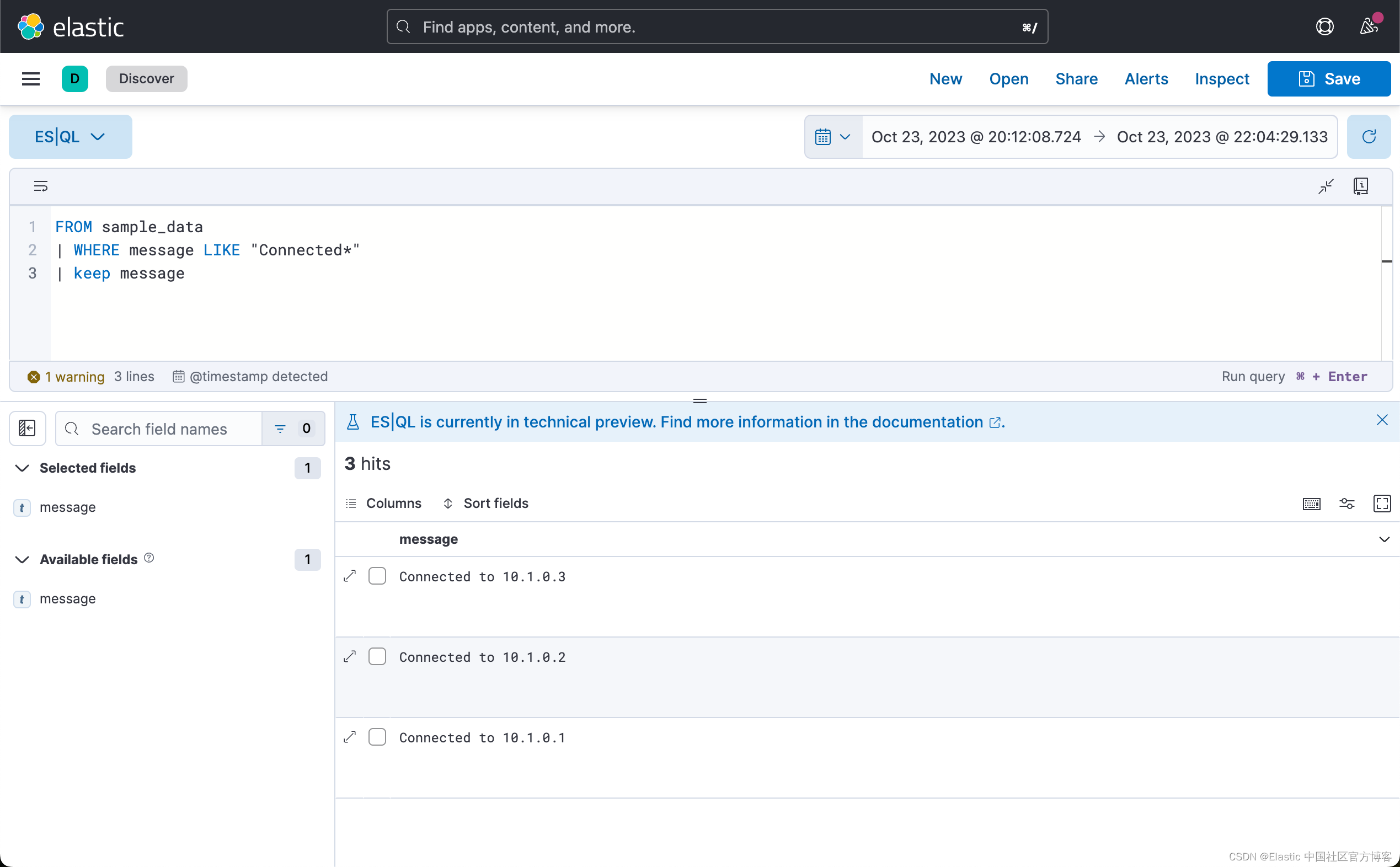
更多处理命令
还有许多其他处理命令,例如用于保留或删除列的 KEEP 和 DROP、用于使用 Elasticsearch 中索引的数据丰富表的 ENRICH 以及用于处理数据的 DISSECT 和 GROK。 有关所有处理命令的概述,请参阅 “Elasticsearch:ES|QL 查询语言简介”。
链式处理命令
你可以链接处理命令,并用竖线字符分隔:|。 每个处理命令都作用于前一个命令的输出表。 查询的结果是最终处理命令生成的表。
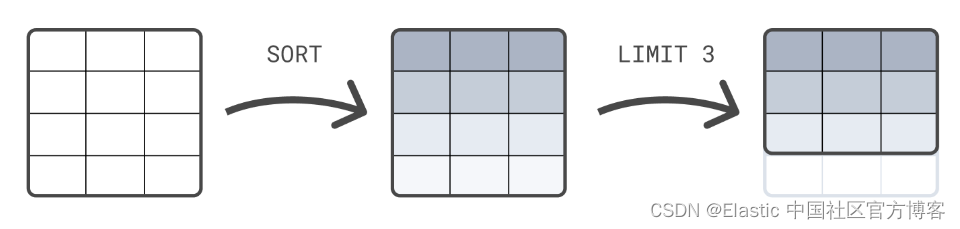
以下示例首先根据 @timestamp 对表进行排序,然后将结果集限制为 3 行:
FROM sample_data
| SORT @timestamp DESC
| LIMIT 3注意:处理命令的顺序很重要。 首先将结果集限制(LIMIT)为 3 行,然后再对这 3 行进行排序,很可能会返回与此示例不同的结果,其中排序在 LIMIT 之前。
计算值
使用 EVAL 命令将包含计算值的列追加到表中。 例如,以下查询附加一个 duration_ms 列。 该列中的值是通过将 event.duration 除以 1,000,000 计算得出的。 换句话说: event.duration 从纳秒转换为毫秒。
FROM sample_data
| EVAL duration_ms = event.duration / 1000000.0
EVAL 支持多种 functions。 例如,要将数字四舍五入为最接近指定位数的数字,请使用 ROUND 函数:
FROM sample_data
| EVAL duration_ms = ROUND(event.duration / 1000000.0, 1)计算统计数据
ES|QL 不仅可以用来查询你的数据,你还可以使用它来聚合你的数据。 使用 STATS ... BY 命令计算统计数据。 例如,中位持续时间:
FROM sample_data
| STATS median_duration = MEDIAN(event.duration)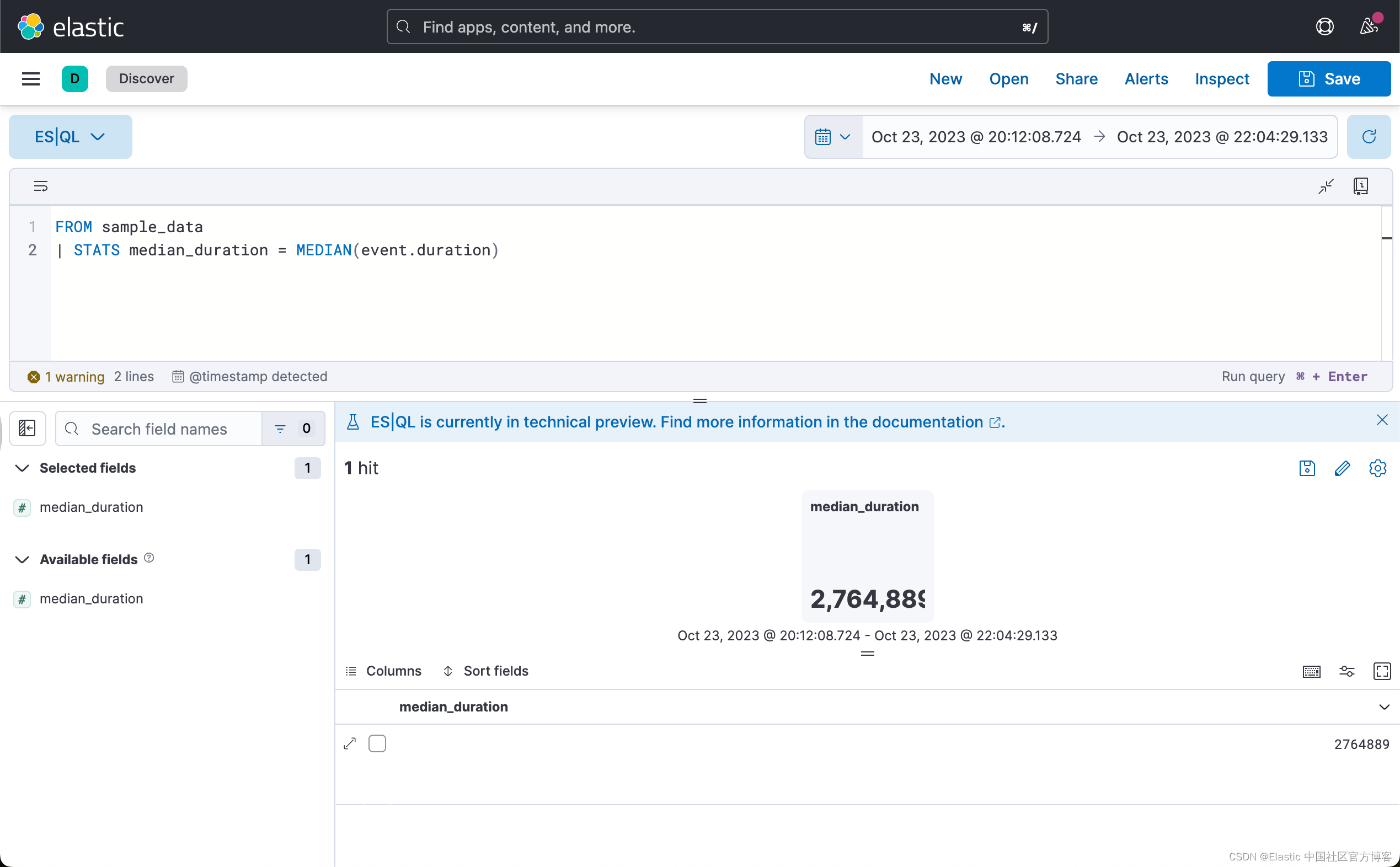
你可以使用一个命令计算多个统计数据:
FROM sample_data
| STATS median_duration = MEDIAN(event.duration), max_duration = MAX(event.duration)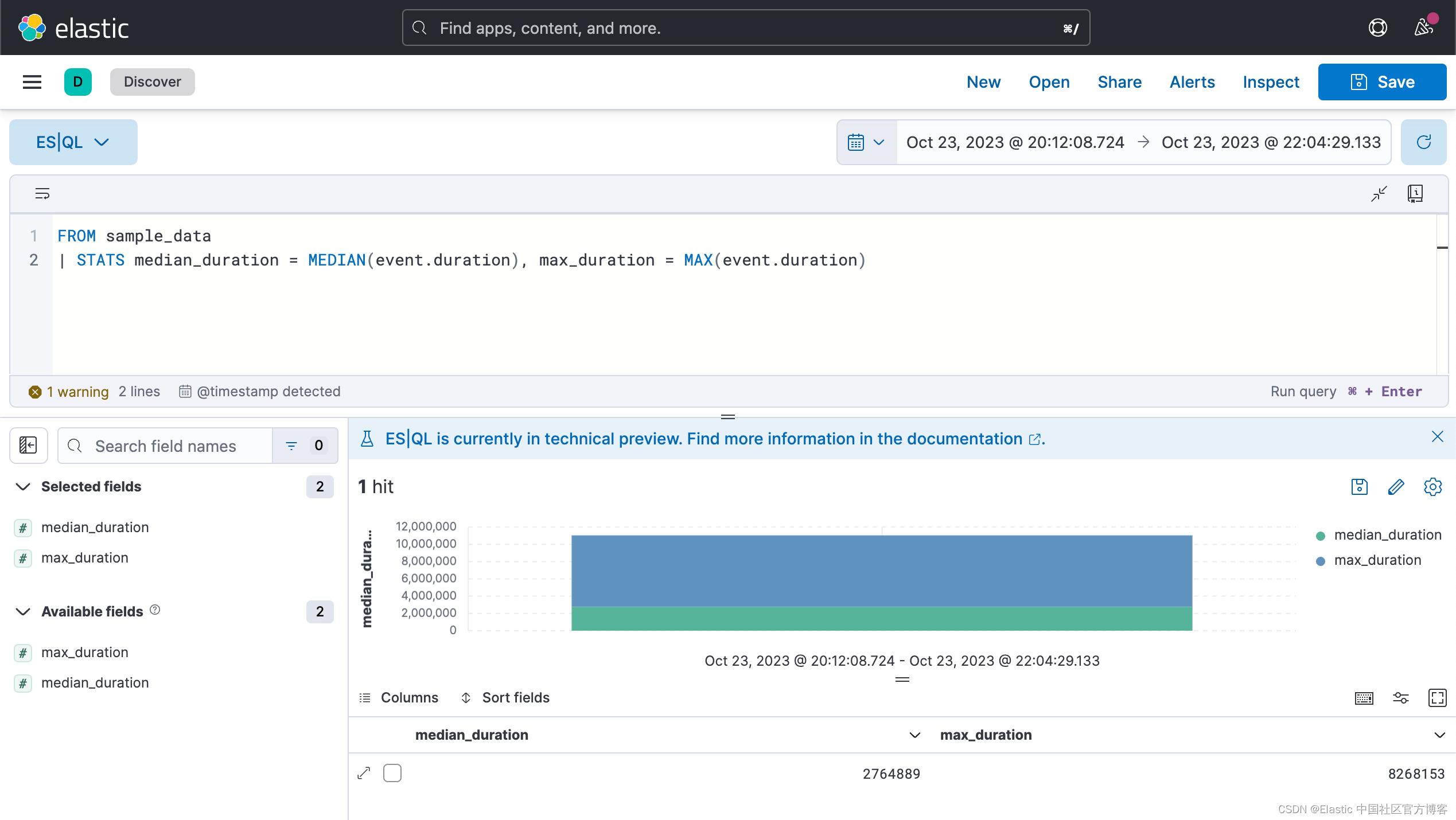
使用 BY 按一列或多列对计算的统计数据进行分组。 例如,要计算每个客户端 IP 的中位持续时间:
FROM sample_data
| STATS median_duration = MEDIAN(event.duration) BY client.ip
创建直方图
为了跟踪一段时间内的统计数据,ES|QL 允许你使用 AUTO_BUCKET 函数创建直方图。 AUTO_BUCKET 创建人性化的存储桶大小,并为每行返回一个与该行所属的结果存储桶相对应的值。
例如,要为 10 月 23 日的数据创建每小时存储桶:
FROM sample_data
| KEEP @timestamp
| EVAL bucket = AUTO_BUCKET (@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")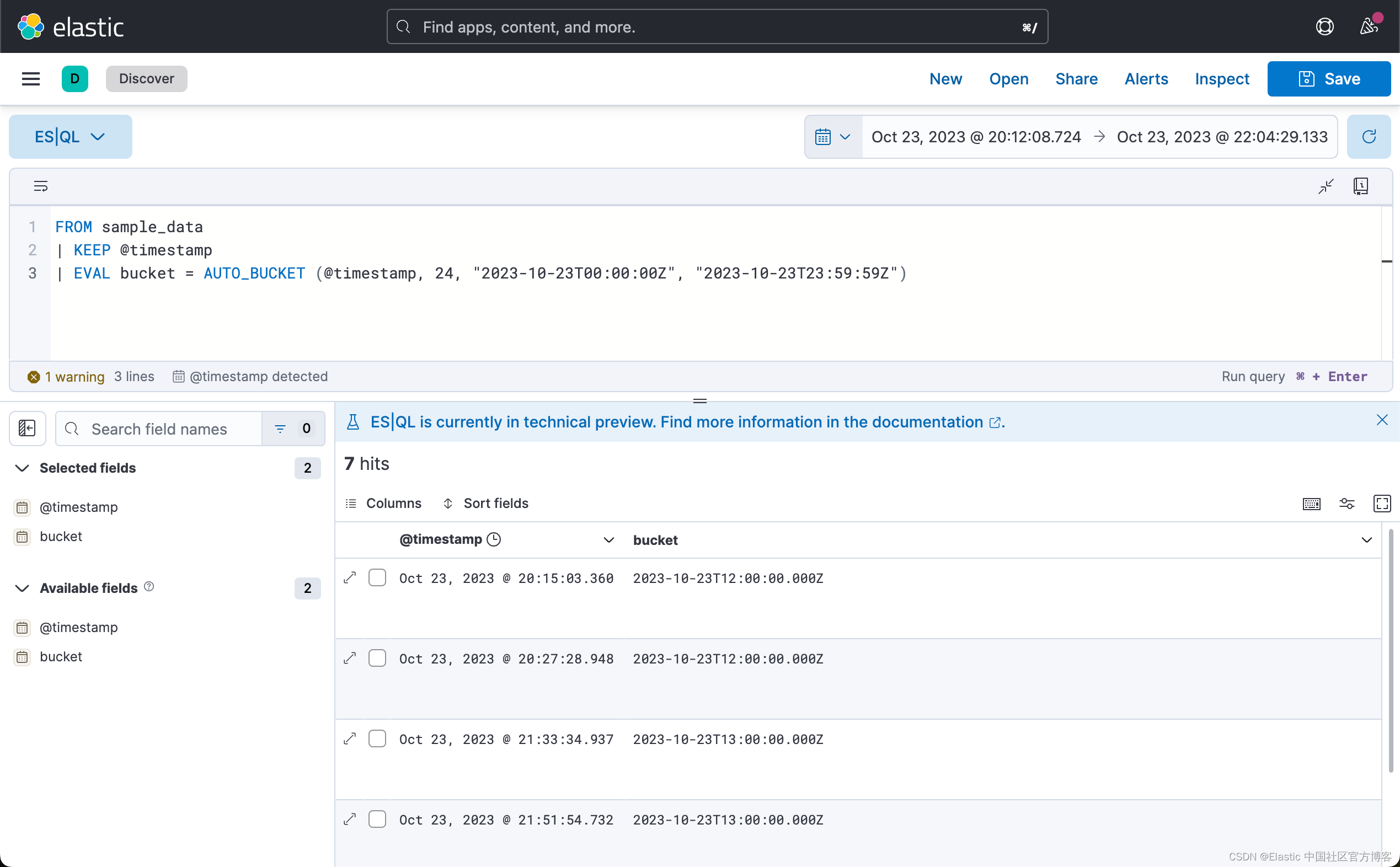
将 AUTO_BUCKET 与 STATS ... BY 结合起来创建直方图。 例如,要计算每小时的事件数:
FROM sample_data
| KEEP @timestamp, event.duration
| EVAL bucket = AUTO_BUCKET (@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
| STATS COUNT(*) BY bucket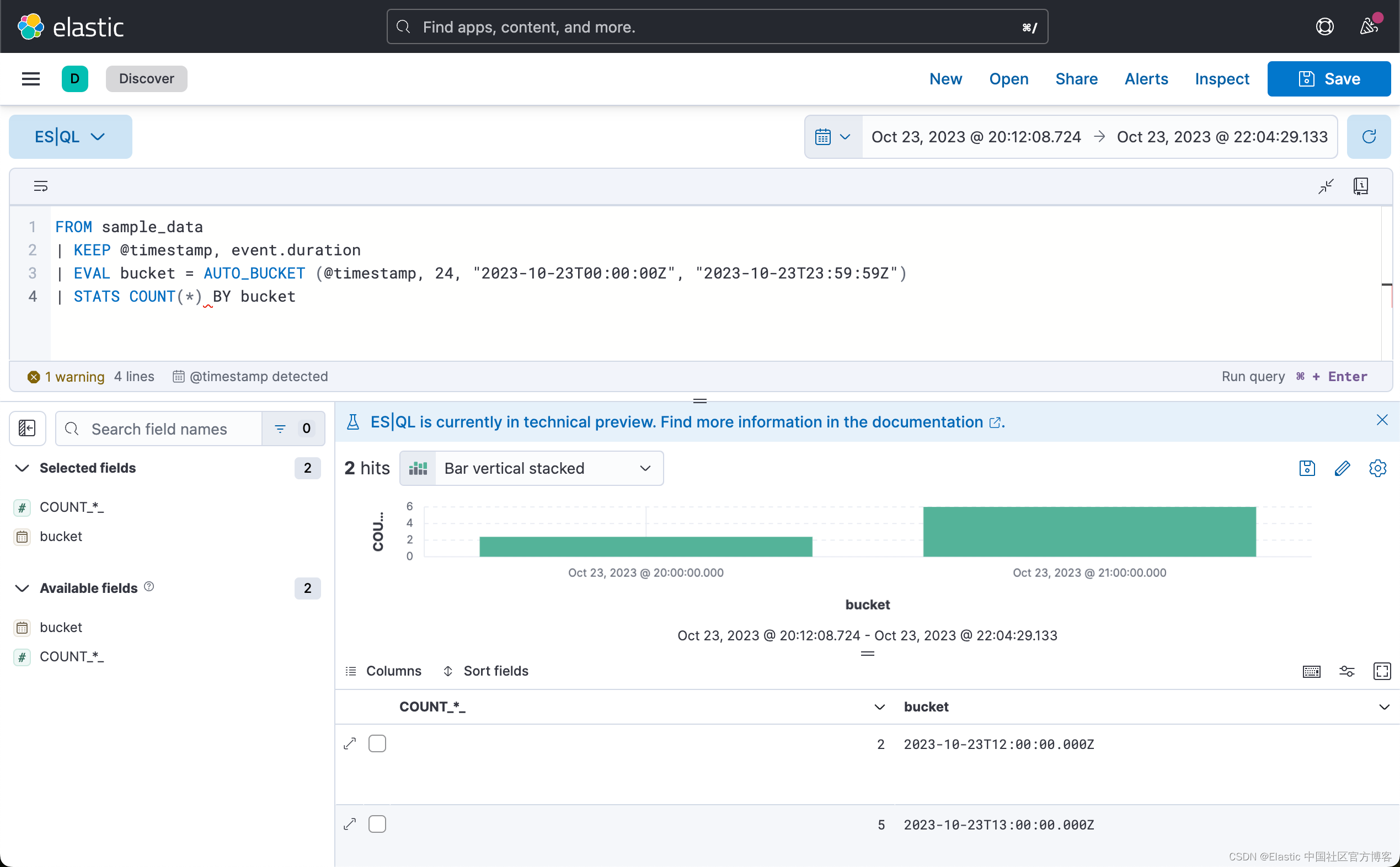
或每小时的中位持续时间:
FROM sample_data
| KEEP @timestamp, event.duration
| EVAL bucket = AUTO_BUCKET (@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
| STATS median_duration = MEDIAN(event.duration) BY bucket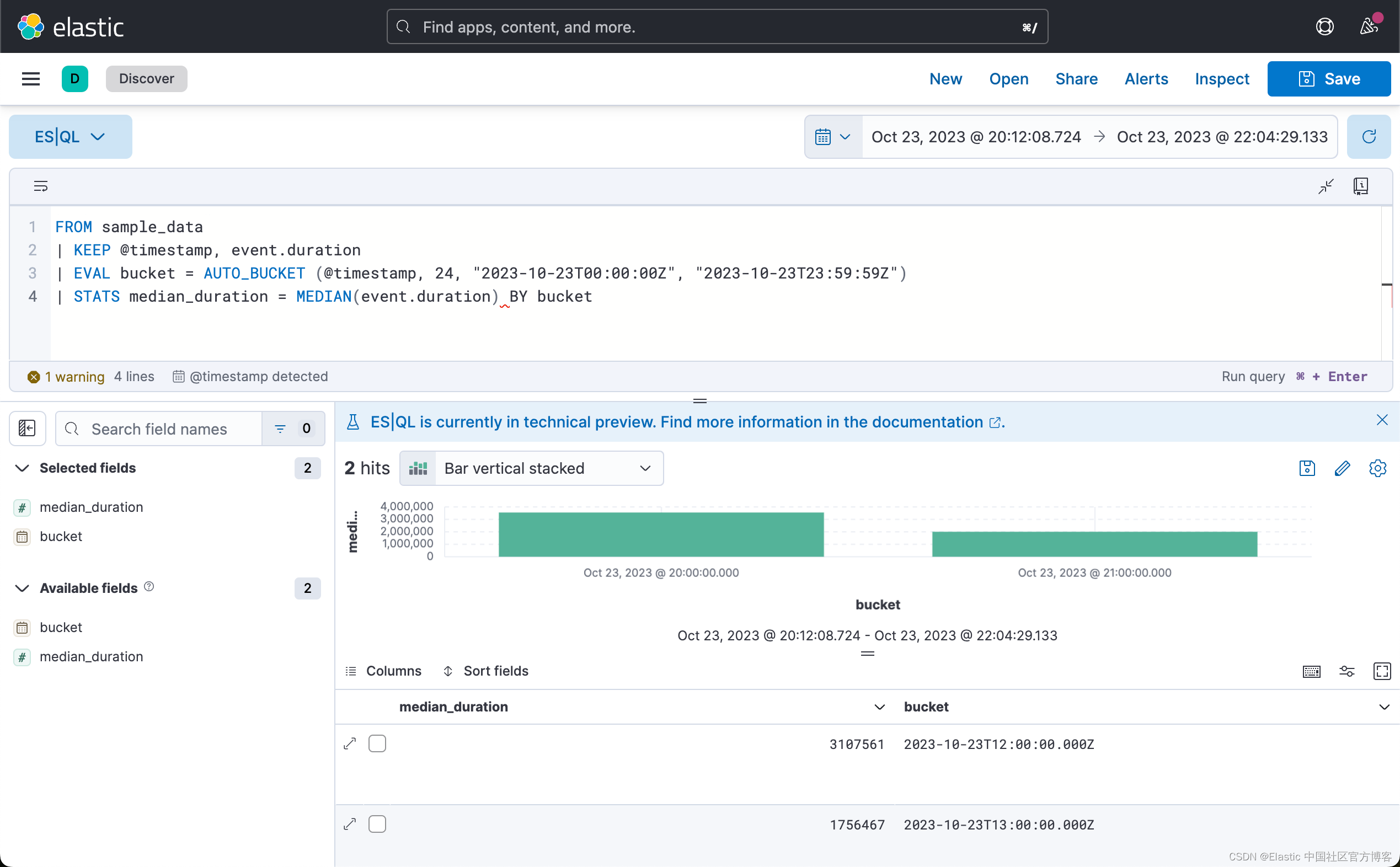
丰富数据
ES|QL 使你能够使用 ENRICH 命令使用 Elasticsearch 中索引的数据来丰富表。
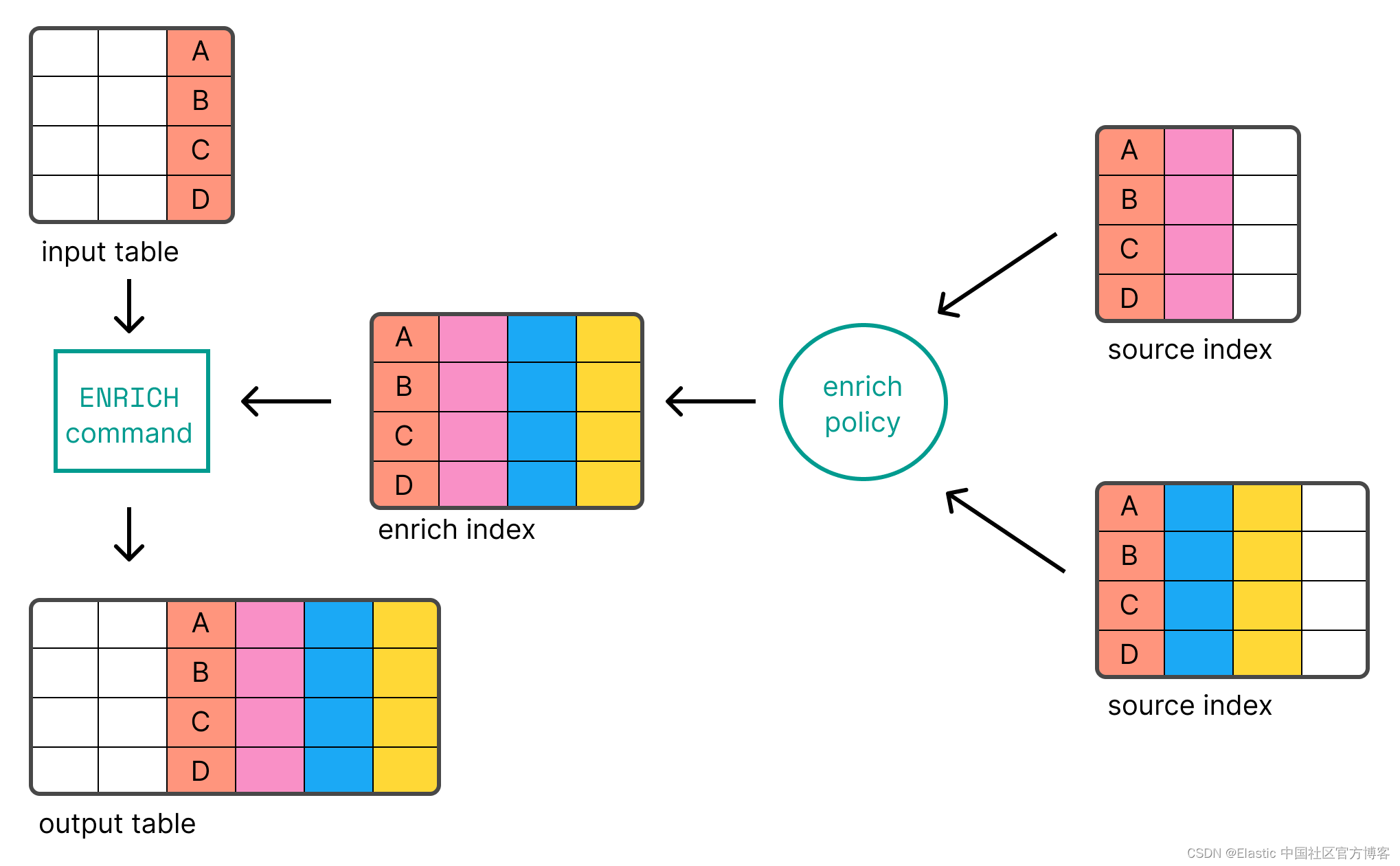
在使用 ENRICH 之前,你首先需要 create 并 execute 你的 enrich policy。 以下请求创建并执行将 IP 地址链接到环境(“Development”、“QA” 或 “Production”)的策略:
PUT clientips
{"mappings": {"properties": {"client.ip": {"type": "keyword"},"env": {"type": "keyword"}}}
}PUT clientips/_bulk
{ "index" : {}}
{ "client.ip": "172.21.0.5", "env": "Development" }
{ "index" : {}}
{ "client.ip": "172.21.2.113", "env": "QA" }
{ "index" : {}}
{ "client.ip": "172.21.2.162", "env": "QA" }
{ "index" : {}}
{ "client.ip": "172.21.3.15", "env": "Production" }
{ "index" : {}}
{ "client.ip": "172.21.3.16", "env": "Production" }PUT /_enrich/policy/clientip_policy
{"match": {"indices": "clientips","match_field": "client.ip","enrich_fields": ["env"]}
}PUT /_enrich/policy/clientip_policy/_execute创建并执行策略后,你可以将其与 ENRICH 命令一起使用:
FROM sample_data
| KEEP @timestamp, client.ip, event.duration
| EVAL client.ip = TO_STRING(client.ip)
| ENRICH clientip_policy ON client.ip WITH env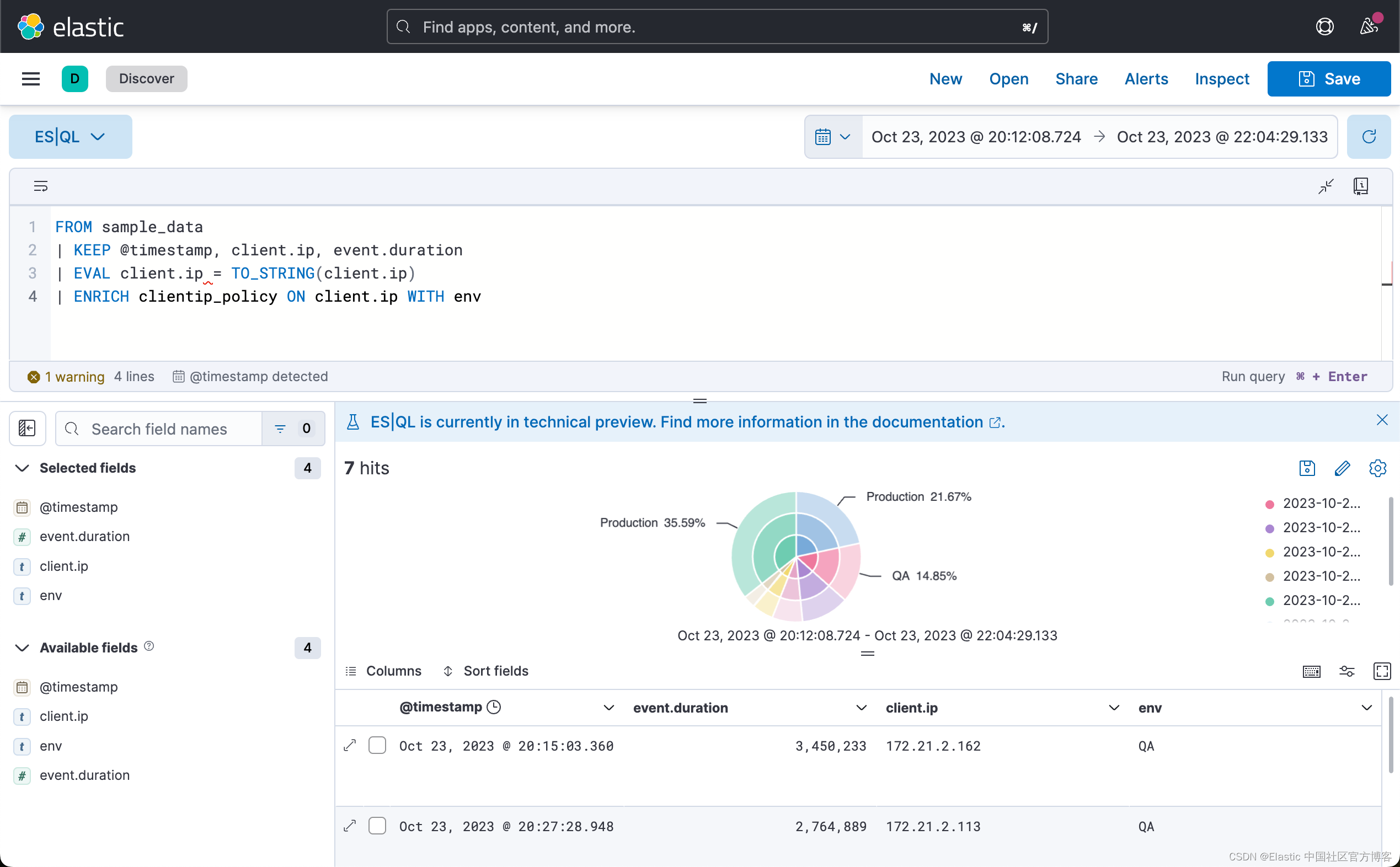
你可以在后续命令中使用 ENRICH 命令添加的新 env 列。 例如,要计算每个环境的中位持续时间:
FROM sample_data
| KEEP @timestamp, client.ip, event.duration
| EVAL client.ip = TO_STRING(client.ip)
| ENRICH clientip_policy ON client.ip WITH env
| STATS median_duration = MEDIAN(event.duration) BY env有关使用 ES|QL 进行数据丰富的更多信息,请参阅 “ES|QL 中的数据丰富”。
处理数据
你的数据可能包含非结构化字符串,你希望将其结构化以便更轻松地分析数据。 例如,示例数据包含如下日志消息:
"Connected to 10.1.0.3"通过从这些消息中提取 IP 地址,你可以确定哪个 IP 接受了最多的客户端连接。
要在查询时构建非结构化字符串,你可以使用 ES|QL DISSECT 和 GROK 命令。 DISSECT 的工作原理是使用基于分隔符的模式分解字符串。 GROK 的工作原理类似,但使用正则表达式。 这使得 GROK 更强大,但通常也更慢。
在这种情况下,不需要正则表达式,因为 message 很简单:“Connected to ”,后跟服务器 IP。 要匹配此字符串,你可以使用以下 DISSECT 命令:
FROM sample_data
| DISSECT message "Connected to %{server.ip}"这会将 server.ip 列添加到具有与此模式匹配的消息的那些行。 对于其他行,server.ip 的值为空。
你可以在后续命令中使用 DISSECT 命令添加的新 server.ip 列。 例如,要确定每个服务器已接受多少个连接:
FROM sample_data
| WHERE STARTS_WITH(message, "Connected to")
| DISSECT message "Connected to %{server.ip}"
| STATS COUNT(*) BY server.ip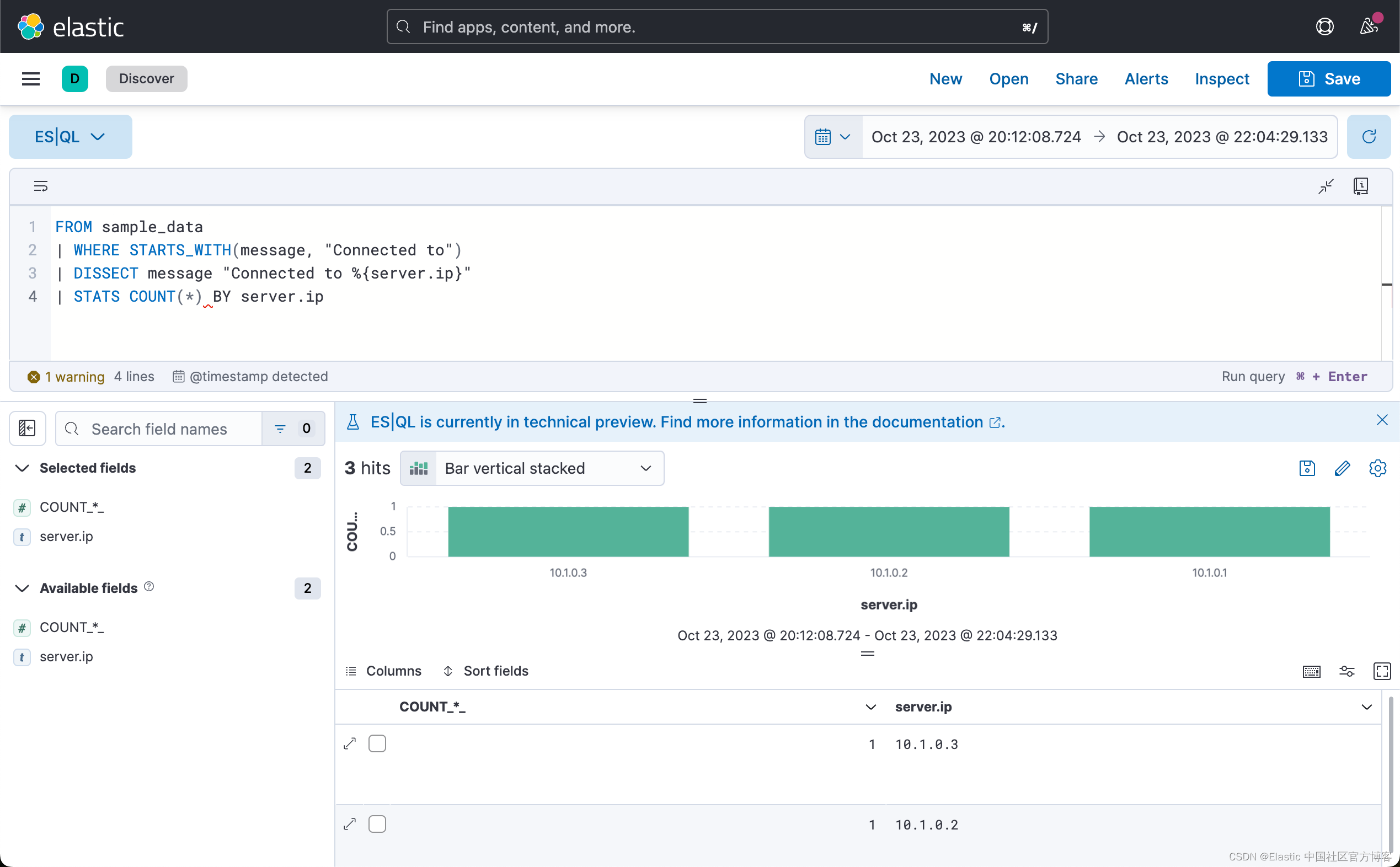
有关使用 ES|QL 进行数据处理的更多信息,请参阅使用 DISSECT 和 GROK 进行数据处理。
相关文章:
Elasticsearch:ES|QL 快速入门
警告:此功能处于技术预览阶段,可能会在未来版本中更改或删除。 Elastic 将努力解决任何问题,但技术预览版中的功能不受官方 GA 功能的支持 SLA 的约束。目前的最新发行版为 Elastic Stack 8.11。 Elasticsearch 查询语言 (ES|QL) 提供了一种强…...

7-1 进步排行榜
7-1 进步排行榜 分数 10 作者 黄龙军 单位 绍兴文理学院 假设每个学生信息包括“用户名”、“进步总数”和“解题总数”。解题进步排行榜中,按“进步总数”及“解题总数”生成排行榜。要求先输入n个学生的信息;然后按“进步总数”降序排列;若…...
解决删除QT后Qt VS Tools中Qt Options中未删除的错误
在Qt VS Tools的Qt Options已经配置好Qt Versions后如果删除QT程序之后会出现Default Qt/Win version任然存在,这是如果再添加一个话就不能出现重名了,如果新建一个其他名字的话其实在vs中还是不能正常运行qt,会出现点击ui文件vs会无故重启或…...
Django(五、视图层)
文章目录 一、视图层1.视图函数返回值的问题2.三板斧的使用结论:在视图文件中写视图函数的时候不能没有返回值,默认返回的是None,但是页面上会报错,用来处理请求的视图函数都必须返回httpResponse对象。 二、JsonReponse序列化类的…...
Git 工作流程、工作区、暂存区和版本库
目录 Git 工作流程 Git 工作区、暂存区和版本库 基本概念 Git 工作流程 本章节我们将为大家介绍 Git 的工作流程。 一般工作流程如下: 克隆 Git 资源作为工作目录。在克隆的资源上添加或修改文件。 如果其他人修改了,你可以更新资源。在提交前查看…...

PLSQL使用技巧
欲善其事,必先利其器,最近研究了一下各种编程工具的使用,发掘了不少新功能,能够大大提升我们日常的工作效率,下面是转载的一篇PLSQL使用技巧,个人感觉很有用,分享一下。 1、PL/SQL Developer记…...

DEC 深度编码聚类函数
2. 辅助目标函数 要使用输入 (bt, groups, embed_dim) 计算 DEC 模型的目标分布,关键部分是使用软分配 q ,其形状为 (bt, groups, max_cluster) 。这里, max_cluster 是您要定位的集群数量。当您沿该维度执行聚类时,需要跨 group…...
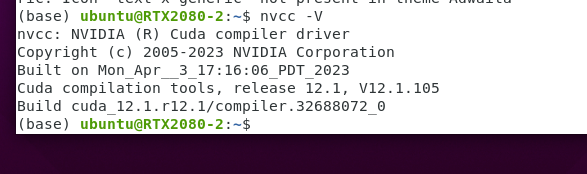
ubuntu中cuda12.1配置(之前存在11.1版本的cuda)(同时配置两个版本)
ubuntu中cuda12.1配置 由于YOLOv8项目中Pytorch版本需要cuda12.1版本 在官网下载12.1版本的deb包 官网地址 sudo dpkg -i cuda-keyring_1.0-1_all.deb sudo apt-get update sudo apt-get -y install cuda然后需要修改bashrc文件(隐藏文件) 添加 exp…...
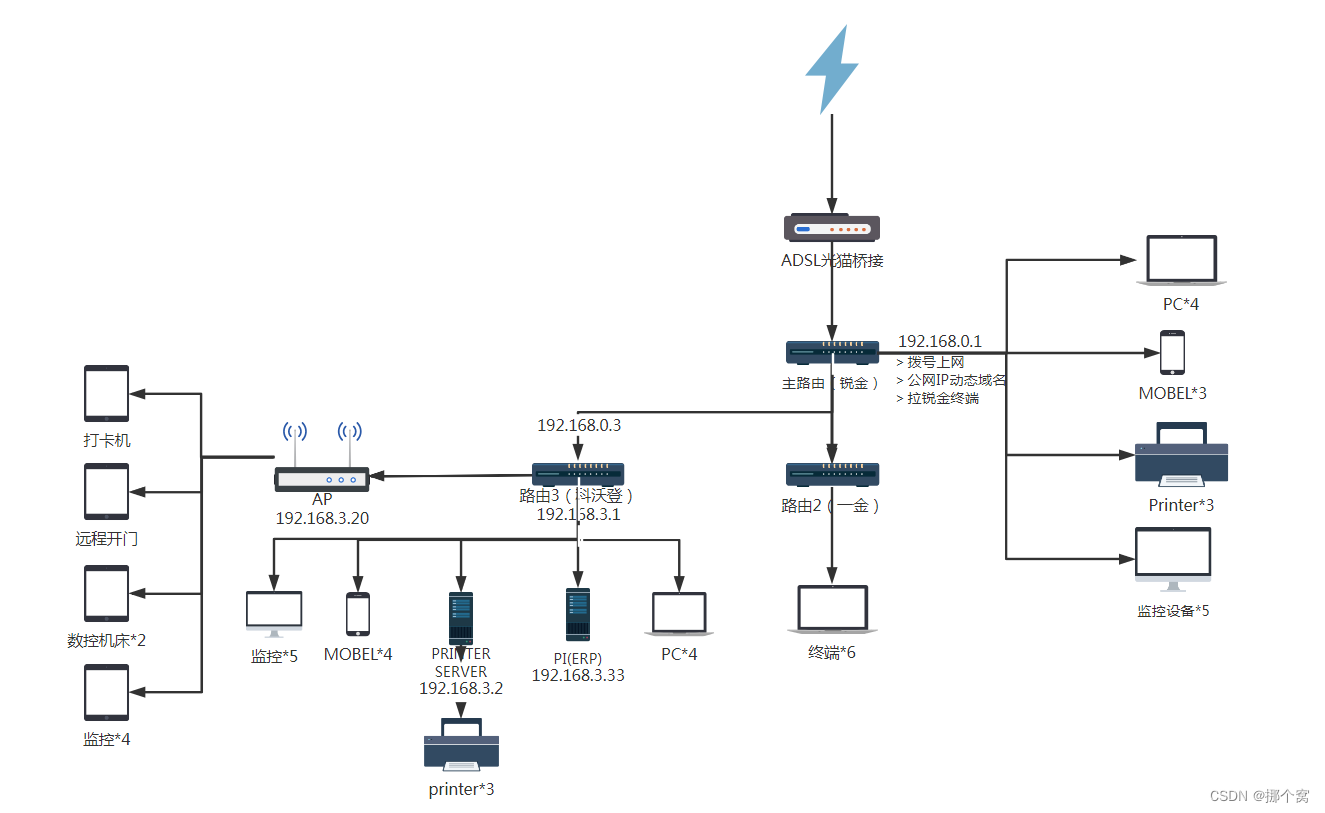
千兆路由只有200M,原来是模式选择不对,也找到了内网不能通过动态域名访问内部服务的原因
本来1000M的宽带接入的,但是一测试发现只有200M,把电信叼了过来, 一测试发现宽带没问题,网线正常,网卡正常,只有可能是路由器的问题了,尴尬了,赶紧给满意好评放他走。回头好好研究一…...

【10】maven打包报错 spring-boot-maven-plugin 与spring-boot 版本的不一致
报错信息 org/springframework/boot/maven/RepackageMojo has been compiled by a more recent version of the Java Runtime (class file version 61.0), this version of the Java Runtime only recognizes class file versions up to 52.0 解决方法 是因为pring-boot-mav…...

SQLAlchemy 在 Flask 应用中的使用和最佳实践
SQLAlchemy 在 Flask 应用中的使用和最佳实践 [TOC](SQLAlchemy 在 Flask 应用中的使用和最佳实践) 模型的编写**SQLAlchemy 中建立关联****利用 SQLAlchemy 中的关联进行查询****实现示例** backref与back_populates?**backref反向引用****back_populates后填充** …...
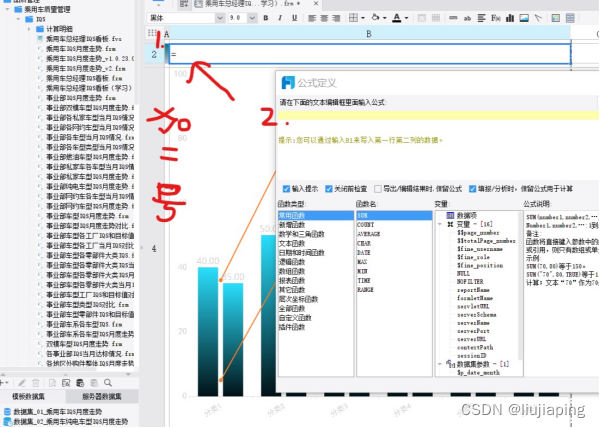
FineReport -问题学习图表设计图表类型-单元格扩展父子格-报表预览
1,问:为什么本地每次预览都要填帐号密码?答:模板认证关闭一下及可 2.单元格扩展与父子格----左父格-扩展方向-箭头往那个方向就往那个方向 1)数据集参数 在定义数据集时,通过使用if函数判断参数的值是否为空,若为空就不过滤参数,若不为空就进行参数过滤。SELECT * FROM…...
微信小程序广告banner、滚动屏怎么做?
使用滑块视图容器swiper和swiper-item可以制作滚动屏,代码如下: wxml: <swiper indicator-dots indicator-color"rgba(255,255,255,0.5)" indicator-active-color"white" autoplay interval"3000"><swiper-ite…...

Network(一)计算机网络介绍
一 计算机网络 1 概述 什么是计算机网络? 硬件方面:通过线缆将网络设备和计算机连接起来 软件方面:操作系统,应用软件,应用程序通过通信线路互连 实现资源共享、信息传递、增加可靠性、提高系统处理能力 2 网络与云计算 3 计算机网…...

【数据结构】堆(Heap):堆的实现、堆排序、TOP-K问题
目录 堆的概念及结构 编辑 堆的实现 实现堆的接口 堆的初始化 堆的打印 堆的销毁 获取最顶的根数据 交换 堆的插入(插入最后) 向上调整(这次用的是小堆) 堆的删除(删除根) 向下调整(这次用的…...

保护数字前沿:下一代防火墙如何塑造网络安全的未来
下一代防火墙通过提供先进的威胁检测、精细控制和云安全功能,正在重塑网络安全的未来。随着数字环境的不断发展,组织必须采用这些创新解决方案来保护其数字资产并维护安全的数字前沿。 在当今互联的世界中,网络威胁变得越来越复杂,…...

深入理解Java中的String.join方法
在 Java 编程中,字符串操作是非常常见的需求。在 Java 8 中引入了一个方便的字符串连接方法 String.join,它能够简洁而高效地将多个字符串连接起来。本篇博客将深入介绍 String.join 方法的使用和原理。 什么是String.join方法? String.join…...

【MySQL系列】 第三章 · 函数
写在前面 Hello大家好, 我是【麟-小白】,一位软件工程专业的学生,喜好计算机知识。希望大家能够一起学习进步呀!本人是一名在读大学生,专业水平有限,如发现错误或不足之处,请多多指正࿰…...

微信小程序wxss定位/选择/查找元素的几种方式
wxss定位、选择、查找元素的几种方式与css类似,下面介绍常用的几种: 选择器样例样例描述.class.intro选择所有拥有 class"intro" 的组件#id#firstname选择拥有 id"firstname" 的组件elementview选择所有 view 组件element, element…...

Canvas—从入门到案例实现
文章目录 Canvas—从入门到案例实现一、设置canvas环境1.1 <canvas>元素1.2 渲染上下文context 二、形状与路径的绘制2.1 形状绘制2.2 路径绘制2.3 绘制一个笑脸 三、使用样式和颜色四、绘制文本五、使用图像5.1 图片源5.2 获取页面内的图片5.3 缩放Scaling5.4 切片Slici…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

3分钟掌握HashCalculator:你的文件完整性守护专家
3分钟掌握HashCalculator:你的文件完整性守护专家 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/ha/HashCalculator …...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...

DeepSeek重复代码识别失效了?5个被90%团队忽略的AST解析盲区及修复清单
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测失效的真相与影响 DeepSeek-R1 模型在代码理解任务中表现出色,但其内置的代码重复检测机制在特定场景下存在系统性失效。根本原因在于模型对语义等价但语法结构差异显著的代…...

Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析
Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析 【免费下载链接】Autodesk-Fusion-360-for-Linux This is a project, where I give you a way to use Autodesk Fusion 360 on Linux! 项目地址: https://gitcode.com/gh_mirrors/au/Autodesk-Fusion-360-for-Linu…...