MongoDB分片集群搭建
----前言
mongodb分片
一般用得比较少,需要较多的服务器,还有三种的角色
一般把mongodb的副本集应用得好就足够用了,可搭建多套mongodb复本集
mongodb分片技术
mongodb副本集可以解决数据备份、读性能的问题,但由于mongodb副本集是每份数据都一模一样的,无法解决数据量过大问题
mongodb分片技术能够把数据分成两份存储,假如shijiange.myuser里面有1亿条数据,分片能够实现5千万左右存储在data1,5千万左右存储在data2
data1、data2需要使用副本集的形式,预防数据丢失
mongodb分片集群三种角色介绍
router角色 #mongodb的路由,提供入口,使得分片集群对外透明。router不存储数据
configsvr角色 #mongodb的配置角色,存储元数据信息。分片集群后端有多份存储,读取数据该去哪个存储上读取,依赖于配置角色。配置角色建议使用副本集
shardsvr角色 #mongodb的存储角色,存储真正的数据,建议使用副本集
依赖关系
当用户通过router角色插入数据时,需要从configsvr知道这份数据插入到哪个节点,然后执行插入动作插入数据到sharedsvr
当用户通过router角色获取数据时,需要从configsvr知道这份数据是存储在哪个节点,然后再去sharedsvr获取数据
mongodb分片集群的搭建说明
使用同一份mongodb二进制文件
修改对应的配置就能实现分片集群的搭建
--第一步,分片集群搭建-configsvr
mongodb分片集群实战环境搭建说明
configsvr #使用28017,28018,28019三个端口来搭建
router #使用27017,27018,27019三个端口来搭建
shardsvr #使用29017,29018,29019,29020四个端口来搭建,两个端口一个集群,生产环境肯定是要三个端口
资源有限,就三台服务器,我的分配情况是
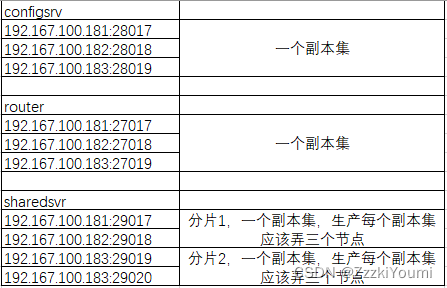
mongodb配置角色的搭建,配置文件路径/data/mongodb-fenpiancluster/28017,另外两节点改下路径、端口、IP
systemLog:
destination: file
logAppend: true
path: /data/mongodb-fenpiancluster/28017/mongodb.log
storage:
dbPath: /data/mongodb-fenpiancluster/28017
journal:
enabled: true
processManagement:
fork: true
net:
port: 28017
bindIp: 127.0.0.1,192.167.100.181
replication:
replSetName: zmhconf
sharding:
clusterRole: configsvr
mongodb配置服务集群的启动跟单例的启动方式一致,都是使用mongod
分片集群的配置角色副本集搭建
config = { _id:"zmhconf",
configsvr: true,
members:[
{_id:0,host:"192.167.100.181:28017"},
{_id:1,host:"192.167.100.182:28018"},
{_id:2,host:"192.167.100.183:28019"}
]
}
rs.initiate(config)
验证是否搭建成功
/usr/local/mongodb/bin/mongo 192.167.100.181:28017
rs.status()
--第二步,分片集群搭建-router
router说明
mongodb中的router角色只负责提供一个入口,不存储任何的数据
router角色的搭建,配置文件/data/mongodb-fenpiancluster/27017/mongodb.conf
systemLog:
destination: file
logAppend: true
path: /data/mongodb-fenpiancluster/27017/mongodb.log
processManagement:
fork: true
net:
port: 27017
bindIp: 192.167.100.181
sharding:
configDB: zmhconf/192.167.100.181:28017,192.167.100.182:28018,192.167.100.183:28019
router最重要的配置
指定configsvr的地址,使用副本集id+ip端口的方式指定
配置多个router,任何一个都能正常的获取数据
router的启动
/usr/local/mongodb/bin/mongos -f /data/mongodb-fenpiancluster/27017/mongodb.conf
/usr/local/mongodb/bin/mongos -f /data/mongodb-fenpiancluster/27018/mongodb.conf
/usr/local/mongodb/bin/mongos -f /data/mongodb-fenpiancluster/27019/mongodb.conf
router的验证
需要等到数据角色搭建完才能够进行验证
--第三步,分片集群搭建-sharedsvr
数据角色
分片集群的数据角色里面存储着真正的数据,所以数据角色一定得使用副本集
多个数据角色
mongodb的数据角色搭建,配置文件/data/mongodb-fenpiancluster/29017/mongodb.conf,另外三台也这么写,由于资源不足,把zmhdata2的副本集都放在了192.167.100.183上。
systemLog:
destination: file
logAppend: true
path: /data/mongodb-fenpiancluster/29017/mongodb.log
storage:
dbPath: /data/mongodb-fenpiancluster/29017
journal:
enabled: true
processManagement:
fork: true
net:
port: 29017
bindIp: 192.167.100.181
replication:
replSetName: zmhdata1
sharding:
clusterRole: shardsvr
systemLog:
destination: file
logAppend: true
path: /data/mongodb-fenpiancluster/29019/mongodb.log
storage:
dbPath: /data/mongodb-fenpiancluster/29019
journal:
enabled: true
processManagement:
fork: true
net:
port: 29019
bindIp: 192.167.100.183
replication:
replSetName: zmhdata2
sharding:
clusterRole: shardsvr
数据服务两个集群说明
29017、29018数据角色zmhdata1
29019、29020数据角色zmhdata2
在各自节点分别启动四个数据实例
/usr/local/mongodb/bin/mongod -f /data/mongodb-fenpiancluster/29017/mongodb.log
/usr/local/mongodb/bin/mongod -f /data/mongodb-fenpiancluster/29018/mongodb.log
/usr/local/mongodb/bin/mongod -f /data/mongodb-fenpiancluster/29019/mongodb.log
/usr/local/mongodb/bin/mongod -f /data/mongodb-fenpiancluster/29020/mongodb.log
在各自副本集的节点上写入节点信息(任意找一个副本集内的节点操作):
数据角色zmhdata1
config = { _id:"zmhdata1",
members:[
{_id:0,host:"192.167.100.181:29017"},
{_id:1,host:"192.167.100.182:29018"}
]
}
rs.initiate(config)
数据角色zmhdata2
config = { _id:"zmhdata2",
members:[
{_id:0,host:"192.167.100.183:29019"},
{_id:1,host:"192.167.100.183:29020"}
]
}
rs.initiate(config)
--第四步,分片集群添加数据节点
分片集群添加数据角色,连接到路由角色里面配置,数据角色为副本集的方式
/usr/local/mongodb/bin/mongo 192.167.100.181:27017
sh.addShard("zmhdata1/192.167.100.181:29017,192.167.100.182:29018")
sh.addShard("zmhdata2/192.167.100.183:29019,192.167.100.183:29020")
sh.status()
默认添加数据没有分片存储,操作都是在路由角色里面
use shijiange
for(i=1; i<=500;i++){
db.myuser.insert( {name:'mytest'+i, age:i} )
}
db.dropDatabase() #验证完后删除
经验证发现,新建的数据会随机分配到一个分片中,而不会均分到所有分片。
针对某个数据库的某个表使用hash分片存储,分片存储就会同一个colloection分配两个数据角色(MongoDB的分片是基于集合的,就算有分片集群不等于数据会自动分片,需要实现分片表首先需要启用数据库分片)
use admin
db.runCommand( { enablesharding :"shijiange"});
db.runCommand( { shardcollection : "shijiange.myuser",key : {_id: "hashed"} } )
或者也可以这样的语句来启用分片:
mongos> sh.enableSharding("shijiange")
mongos> sh.shardCollection("shijiange.myuser",{_id: "hashed"});
插入数据校验,分布在两个数据角色上
use shijiange
for(i=1; i<=500;i++){
db.myuser.insert( {name:'mytest'+i, age:i} )
}
配置角色如果挂掉一台会不会有影响
验证mongos多个入口是否能够正常使用
相关文章:
MongoDB分片集群搭建
----前言 mongodb分片 一般用得比较少,需要较多的服务器,还有三种的角色 一般把mongodb的副本集应用得好就足够用了,可搭建多套mongodb复本集 mongodb分片技术 mongodb副本集可以解决数据备份、读性能的问题,但由于mongodb副本集是…...

modbus报文
MODBUS规约报文解析-CSDN博客...

flutter报错: library “libflutter.so“ not found
修改android/app/build.gradle defaultConfig { // TODO: Specify your own unique Application ID (https://developer.android.com/studio/build/application-id.html). applicationId "cn.rentsoft.flutter.openim.consumer" // You can update the …...

MR混合现实情景实训教学系统模拟历史情景
二、应用场景 1. 古代战争场景:通过MR混合现实情景实训教学系统,学生可以亲身体验古代战争的场景,如战场布置、战术运用等。这不仅有助于学生更好地理解古代战争的特点,还能够培养他们的团队协作和战略思维能力。 2. 历史文化古…...
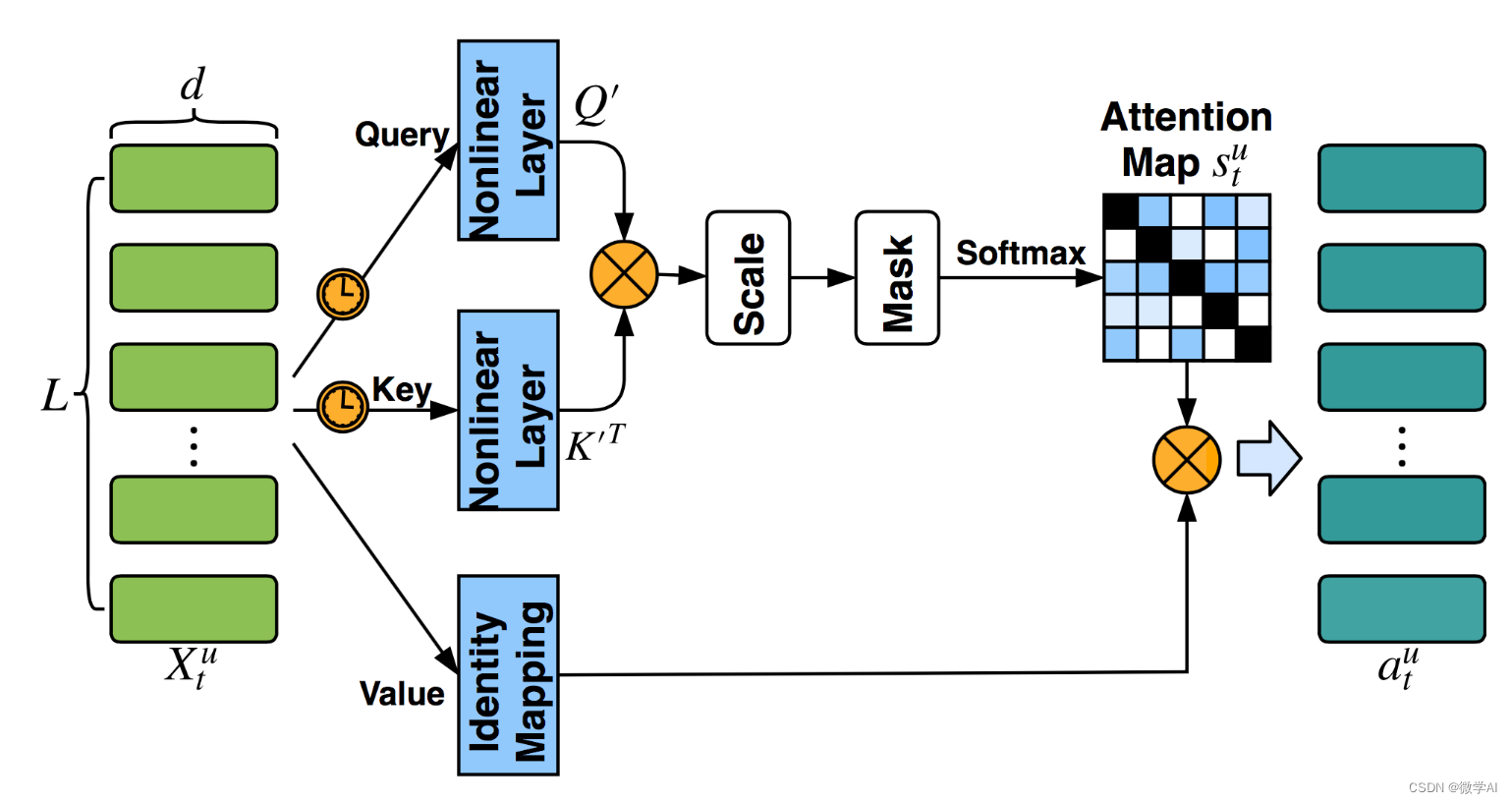
计算机视觉的应用16-基于pytorch框架搭建的注意力机制,在汽车品牌与型号分类识别的应用
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用16-基于pytorch框架搭建的注意力机制,在汽车品牌与型号分类识别的应用,该项目主要引导大家使用pytorch深度学习框架,并熟悉注意力机制模型的搭建,这个…...

Flutter 实现 Android CollapsingToolbarLayout折叠布局效果
Flutter 是通过Tabbar TabbarView 来实现 类似Android Viewpager 页面切换的效果的。我个人觉得Flutter 的tab 切换实现过程要比Android的实现过程要简单容易不是一星半点,哈哈哈哈 ,因为她所用到的widget 都是google 官方封装好的,用起来代…...

数据库管理-第116期 Oracle Exadata 06-ESS-下(202301114)
数据库管理-第116期 Oracle Exadata 06-ESS-下(202301114) 距离上一次正儿八经的技术分享又过了整整一周了,距离上一期Exadata专题文章也过了11天了,今天一鼓作气把ESS写完,毕竟明天又要飞北京了。 1 Smart Scan 其…...

阿里云C++二面面经
1.智能指针 1、shared_ptr 原理:shared_ptr是基于引用计数的智能指针,用于管理动态分配的对象。无论 std::shared_ptr 存储在堆区还是栈区,它所指向的内存块始终存储在堆区。这是因为 std::shared_ptr 是用于管理动态分配的内存的智能指针,它需要存储在堆区,以便进行引用…...
Ubuntu 20.04编译Chrome浏览器
本文记录chrome浏览器编译过程,帮助大家避坑qaq 官网文档:https://chromium.googlesource.com/chromium/src//main/docs/linux/build_instructions.md 一.系统要求 一台64位的英特尔机器,至少需要8GB的RAM。强烈推荐超过16GB。至少需要100…...
大文件分片上传、断点续传、秒传
小文件上传 后端:SpringBootJDK17 前端:JavaScriptsparkmd5.min.js 一、依赖 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.2</ve…...

DAY53 1143.最长公共子序列 + 1035.不相交的线 + 53. 最大子序和
1143.最长公共子序列 题目要求:给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列的长度。 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删…...

短剧App开发:个性化的内容推荐
随着移动互联网的普及和用户需求的多样化,短剧App作为一种新兴的内容消费模式,受到了越来越多用户的青睐。在短剧App开发中,个性化的内容推荐是一个重要的功能,它能够根据用户的兴趣偏好和行为数据,为他们提供更精准、…...
互斥量保护资源
一、概念 在多数情况下,互斥型信号量和二值型信号量非常相似,但是从功能上二值型信号量用于同步, 而互斥型信号量用于资源保护。 互斥型信号量和二值型信号量还有一个最大的区别,互斥型信号量可以有效解决优先级反转现 象。 …...
天机学堂-1、项目搭建,微服务架构设计
1.学习背景 各位同学大家好,经过前面的学习我们已经掌握了《微服务架构》的核心技术栈。相信大家也体会到了微服务架构相对于项目一的单体架构要复杂很多,你的脑袋里也会有很多的问号: 微服务架构该如何拆分? 到了公司中我需要自…...
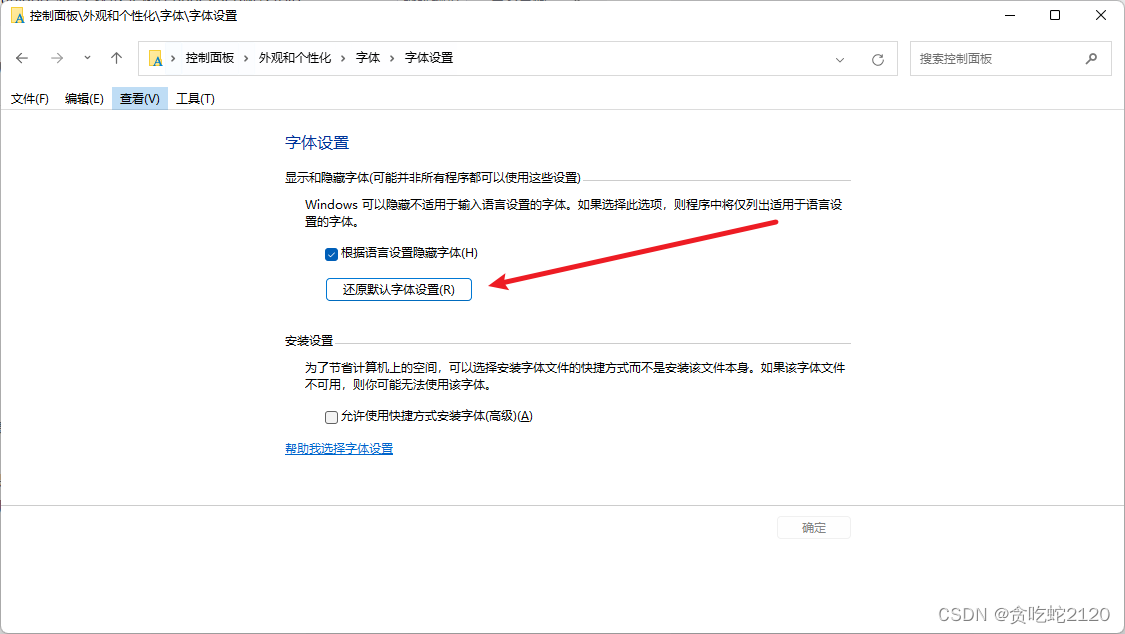
windows 电脑删除不了.TTF的文件
出现这个问题,首先检查,你的.ttf文件是不是在哪个软件中打开了。 如果是,先关掉,然后在删一遍试试。 如果这个还是不行试着打开控制面板>外观和个性化> 字体 > 字体设置>还原默认字体设置勾选,然后重启一下…...
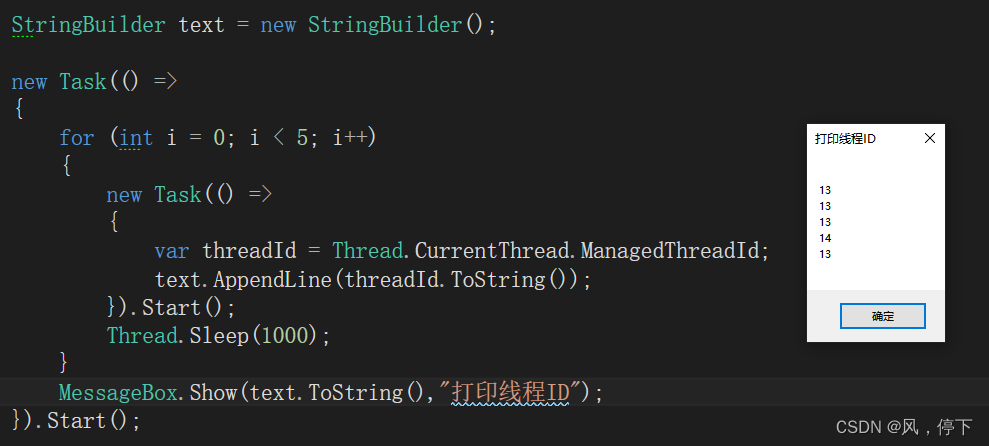
C#多线程的操作
文章目录 1 使用线程意义2 C#线程开启的四种方式2.1 异步委托开启线程2.2 通过Thread类开启线程2.3 通过线程池开启线程2.4 通过任务Task开启线程 3 前台线程和后台线程简述3.1 前台线程3.2 后台线程 4 简述Thread和Task开启线程的区别4.1 Thread效果展示4.2 Task效果展示4.3 区…...

MyBatis Plus—CRUD 接口
Service CRUD 接口 说明: 通用 Service CRUD 封装IService (opens new window)接口,进一步封装 CRUD 采用 get 查询单行 remove 删除 list 查询集合 page 分页 前缀命名方式区分 Mapper 层避免混淆,泛型 T 为任意实体对象建议如果存在自定义通用 Servi…...
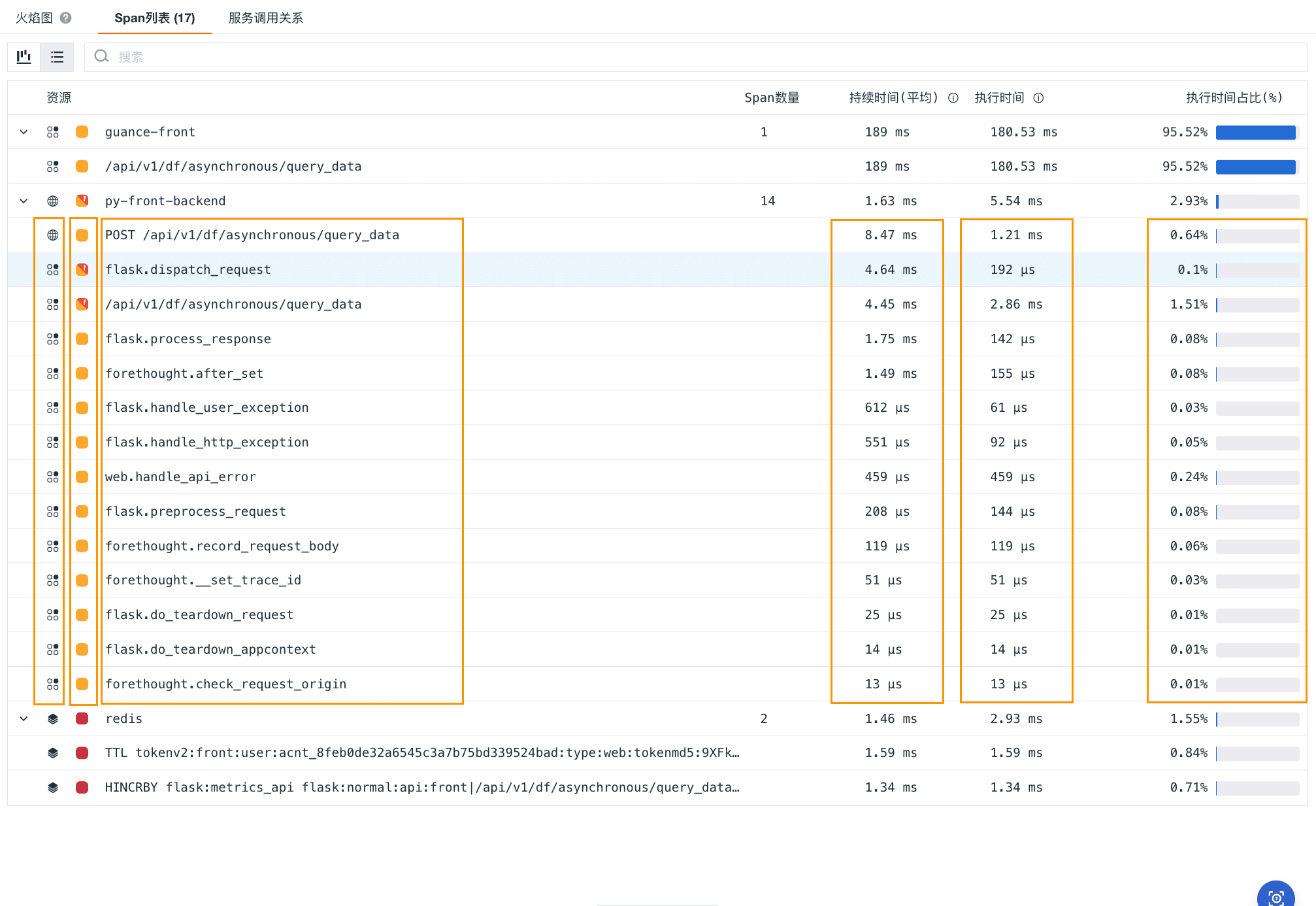
火焰图:链路追踪分析的可视化利器
什么是火焰图? 火焰图用于可视化分布式链路追踪,通过使用持续时间和不同颜色的水平条形来表示请求执行路径中的每个服务调用。分布式跟踪的火焰图包括错误、延迟数据等详情,帮助开发人员识别和解决应用程序中的瓶颈问题。 链路追踪与 Span …...
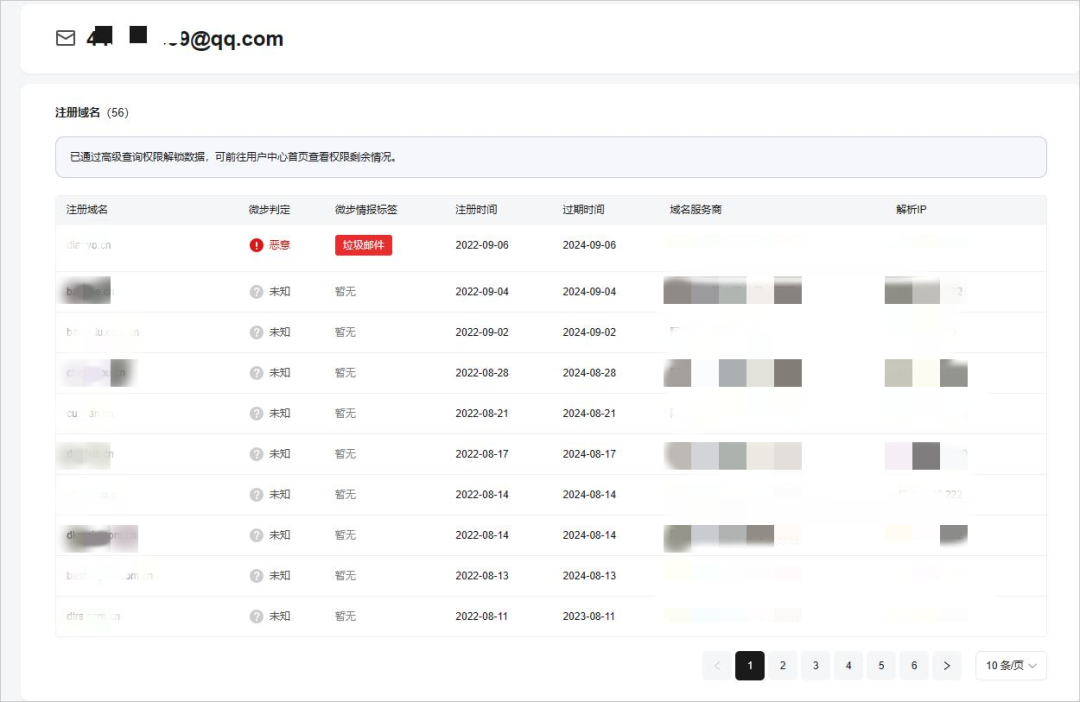
中睿天下Coremail | 2023年Q3企业邮箱安全态势观察报告
10月25日,北京中睿天下信息技术有限公司联合Coremail邮件安全发布《2023年第三季度企业邮箱安全性研究报告》。2023年第三季度企业邮箱安全呈现出何种态势?作为邮箱管理员,我们又该如何做好防护? 以下为精华版阅读,如需…...
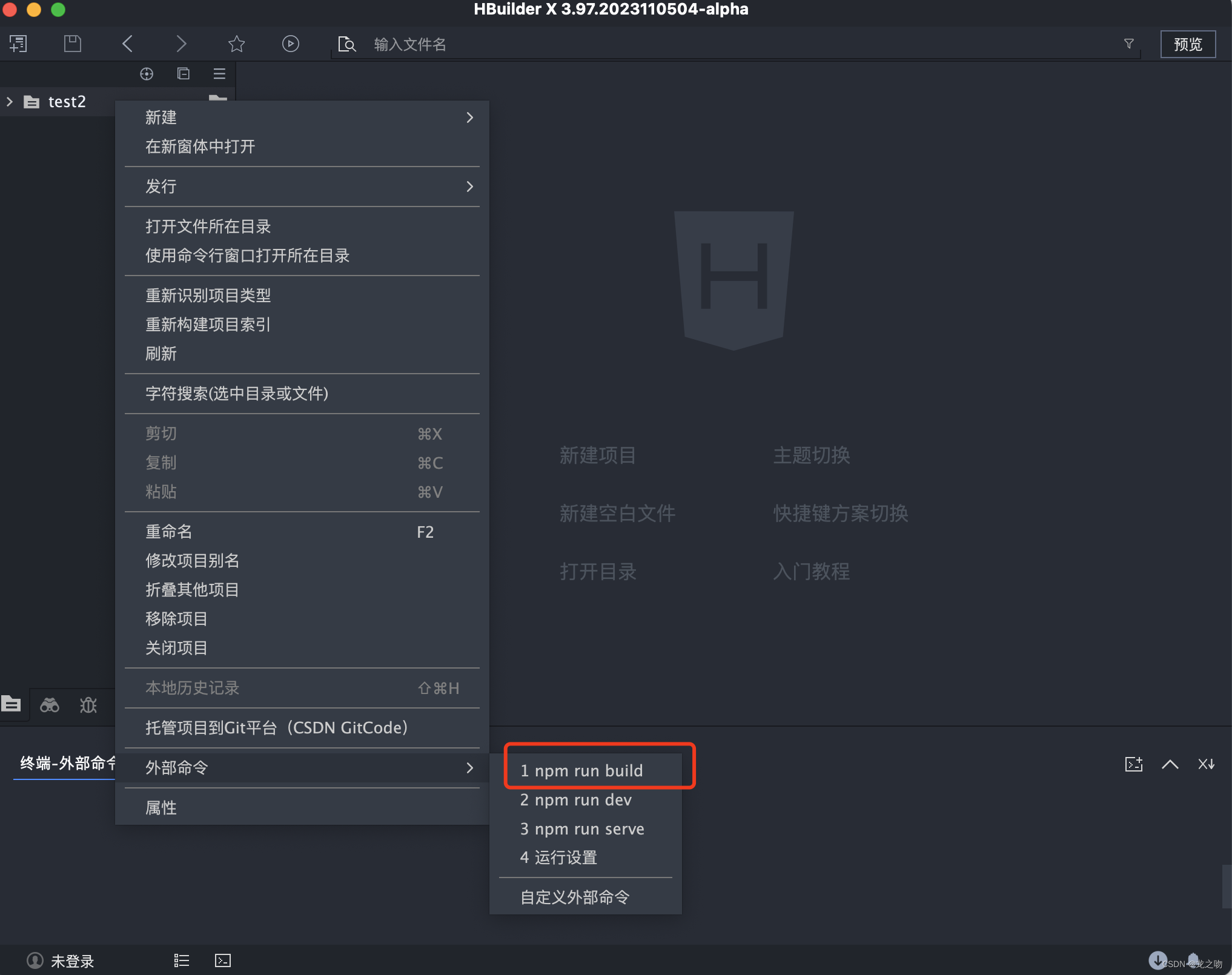
HBuilderX vue项目打包上传到服务器
完成后有个’dist’目录,把真个目录通过FTP 上传到服务器,Mac电脑使用cyberduck 上传 服务器使用‘宝塔’进行一件部署,基本上就是傻瓜式的点击下一步...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...

GEP协议深度解读:AI智能体自我进化的基因工程
OpenAI 官宣全面支持MCP协议,标志着AI应用架构的"连接标准"已定。如果说MCP是AI时代的USB-C,解决了模型与工具的连接问题,那么GEP(Genome Evolution Protocol,基因组进化协议)则正在解决另一个更本质的问题——智能体的自我进化与生命周期管理。 作为下一代AI基…...

终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题
终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也经历过这样的…...

反向海淘站点常见配置故障复盘与数据一致性优化方案
摘要反向海淘独立站运行过程中,容易出现价格换算异常、页面语种错乱、商品同步失败、订单状态停滞、运费计算偏差等问题。多数故障并非系统底层缺陷,而是配置逻辑理解偏差、数据规范不统一引发。本文结合实际运维场景,汇总高频故障成因&#…...