OpenAI 上线新功能力捧 RAG,开发者真的不需要向量数据库了?
近期, OpenAI 的开发者大会迅速成为各大媒体及开发者的热议焦点,有人甚至发出疑问“向量数据库是不是失宠了?”
这并非空穴来风。的确,OpenAI 在现场频频放出大招,宣布推出 GPT-4 Turbo 模型、全新 Assistants API 和一系列增强功能。其中,王炸功能 Assistants API 的内置工具支持了代码解释器、知识库检索以及函数调用,允许接入外部知识(文档)、使用更长的提示和集成各种工具。它能够帮助开发者分担繁重的工作,并构建高质量的 AI 应用。
乍一看,OpenAI Assistants 自带的检索功能十分强大,但如果对行业足够了解,便会发现其仍存在诸多限制。OpenAI Assistants 检索严格限制了数据规模,且缺乏定制化的能力。因此,搭建高效的应用还需要使用自定义的检索器。所幸,OpenAI 的函数调用能力允许开发者无缝接入自定义的检索器,从而打破对于知识库数据量的限制,更好地适应多样化的用例。
今天我们就来聊聊 OpenAI Assistants 内置检索功能的限制及其解决方案——用 Milvus 向量数据库实现自定义检索功能。
01.OpenAI Assistants 检索存在局限性?试试自定义检索
OpenAI Assistants 内置的检索工具突破了模型固有知识库的限制,支持用户通过额外数据(如内部产品信息或用户提供的文档)来增强大模型。但是,OpenAI Assistants 检索仍然具有局限性。
限制 1: 可扩展性
OpenAI Assistants 内置检索对文件大小和数量都有限制。这些限制不利于大型文档仓库:
-
每个 Assistant 最多支持 20 个文件
-
每个文件最大为 512 MB
-
我们在测试中发现了关于 Token 的隐藏限制——每个文件最多 200 万个 Token
-
每个企业账号下文件大小总和最多 100 GB
上述限制会严重限制拥有大量数据的组织机构。在此情况下,就需要使用一套可以摆脱存储上限、支持灵活扩展的解决方案——集成 Milvus(https://zilliz.com/what-is-milvus)或 Zilliz Cloud(https://cloud.zilliz.com.cn/signup)这样的向量数据库检索更大体量的知识库。
限制 2: 无法定制检索
虽然 OpenAI Assistants 的内置检索是一套开箱即用的解决方案,但它无法根据每个应用的特殊需求(如:搜索延时、索引算法)进行定制。使用第三方向量数据库,可以帮助开发者灵活配置、调优检索过程,从而满足生产环境中的各种需求,提升应用的整体效率。
限制3 :缺乏多租户支持
OpenAI Assistants 中内置的检索功能绑定 Assistant,每个知识库产生的费用按 Assistant 个数成倍增长。如果开发者的应用需要为数百万用户提供共享文档,或者为特定用户提供私人化的信息,OpenAI Assistants 的内置检索功能就无法满足需求了。
下表显示了在 OpenAI Assistants 中存储文档的成本:

根据上表的定价计算,其代价十分高昂——每月每 GB 的存储需要花费 6 美元。(参考 AWS S3 的收费仅为 0.023 美元。)具体 Assistants API 定价可在此 (https://openai.com/pricing)获取。如果将共享文档复制到每个 Assistant 中,会显著增加存储成本,所以在 OpenAI 上存储重复的文档是一种不现实的方案。但是,如果让所有用户都共享同一个 Assistant,那么将无法支持用户检索自己的私有文档。
因此,对于需要检索大量数据集的应用来说,选择一个可扩展、高效、具有高性价比的检索器显得尤为重要。
值得庆幸的是,OpenAI 灵活的函数调用功能支持开发者在 OpenAI Assistants 中无缝集成自定义的检索器 。这套解决方案一方面保留了 OpenAI 出色的 AI 能力,另一方面又可以满足应用可扩展性的需求。
02.使用 Milvus 实现 OpenAI Assistants 检索定制化
Milvus 是一款高度灵活、可扩展的开源向量数据库,毫秒内即可实现十亿级别向量的存储和检索。由于优秀的扩展性和超低的查询延时,Milvus 是定制 OpenAI Assistants 检索的首选。
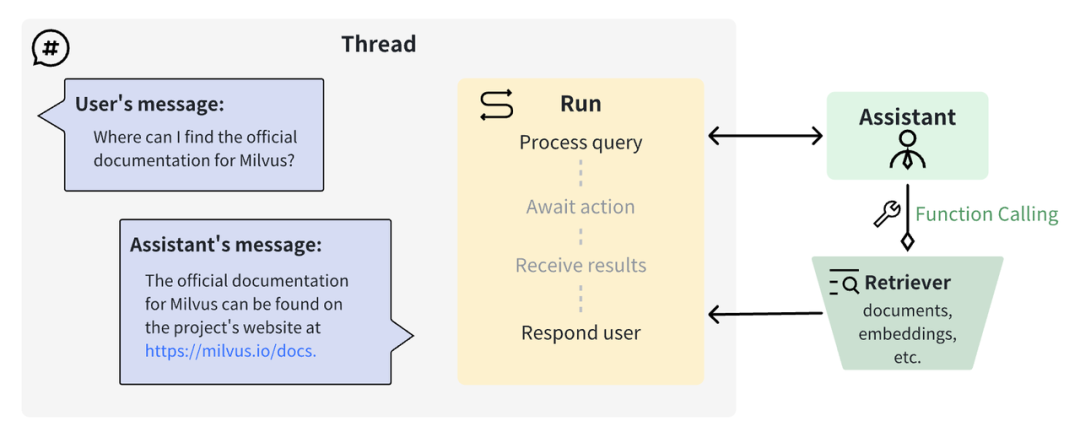 |OpenAI Assistant 函数调用的工作原理
|OpenAI Assistant 函数调用的工作原理
用 OpenAI 函数调用和 Milvus 向量数据库搭建自定义检索器
在接下来的教程中,我们将展示构建自定义检索器、并将其集成到 OpenAI Assistants 的具体步骤。
-
配置环境。
pip install openai==1.2.0
pip install langchain==0.0.333
pip install pymilvus
export OPENAI_API_KEY=xxxx # Enter your OpenAI API key here
-
使用向量数据库构建自定义检索器。我们选择 Milvus 作为向量数据库、 LangChain 作为调用框架。
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
# Prepare retriever
vector_db = Milvus(
embedding_function=OpenAIEmbeddings(),
connection_args = {'host': 'localhost', 'port': '19530'}
)
retriever = vector_db.as_retriever(search_kwargs={'k': 5}) # change top_k here
-
将文档导入 Milvus。LangChain 会解析文档、将其切分成片段,并转换为向量。随后这些文档片段和相应的向量会被导入 Milvus 向量数据库。当然,我们也可以自定义每个步骤,进一步提高检索质量。
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Parsing and chunking the document.
filepath = 'path/to/your/file'
doc_data = TextLoader(filepath).load_and_split(
RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
)
# Embedding and insert chunks into the vector database.
vector_db.add_texts([doc.page_content for doc in doc_data])
至此,一个自定义的检索器已经搭建完成,可以支持私有数据下的语义搜索。接下来,我们需要将这个检索器集成到 OpenAI Assistants,从而实现内容生成。
-
使用 OpenAI 的函数调用功能创建一个 Assistant,并提示 Assistant 在回应请求时使用名为 CustomRetriever的函数工具。
import os
from openai import OpenAI
# Setup OpenAI client.
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
# Create an Assistant.
my_assistant = client.beta.assistants.create(
name='Chat with a custom retriever',
instructions='You will search for relevant information via retriever and answer questions based on retrieved information.',
tools=[
{
'type': 'function',
'function': {
'name': 'CustomRetriever',
'description': 'Retrieve relevant information from provided documents.',
'parameters': {
'type': 'object',
'properties': {'query': {'type': 'string', 'description': 'The user query'}},
'required': ['query']
},
}
}
],
model='gpt-4-1106-preview', # Switch OpenAI model here
)
-
Assistant 采用异步方式调用函数工具。首先开启线程并调用 Assistant,其状态存储在名为Run 的对象中。在运行过程中,如果 Assistant 认为有必要调用CustomRetriever函数,会暂停运行等待异步提交函数调用结果。通过轮询来获取Assistant 发出调用的命令。
QUERY = 'ENTER YOUR QUESTION HERE'
# Create a thread.
my_thread = client.beta.threads.create(
messages=[
{
'role': 'user',
'content': QUERY,
}
]
)
# Invoke a run of my_assistant on my_thread.
my_run = client.beta.threads.runs.create(
thread_id=my_thread.id,
assistant_id=my_assistant.id
)
# Wait until my_thread halts.
while True:
my_run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=my_run.id)
if my_run.status != 'queued':
break
-
当查询到 Assistant 正在等待函数调用结果,即可对查询语句进行向量搜索并通过 Run 提交结果至 Assistant,让其继续进行内容生成。
# Conduct vector search and parse results when OpenAI Run ready for the next action
if my_run.status == 'requires_action':
tool_outputs = []
for tool_call in my_run.required_action.submit_tool_outputs.tool_calls:
if tool_call.function.name == 'Custom Retriever':
search_res = retriever.get_relevant_documents(QUERY)
tool_outputs.append({
'tool_call_id': tool_call.id,
'output': ('\n\n').join([res.page_content for res in search_res])
})
# Send retrieval results to your Run service
client.beta.threads.runs.submit_tool_outputs(
thread_id=my_thread.id,
run_id=my_run.id,
tool_outputs=tool_outputs
)
-
最终,提取并解析与 OpenAI Assistant 的完整对话。
messages = client.beta.threads.messages.list(thread_id=my_thread.id)
for m in messages:
print(f'{m.role}: {m.content[0].text.value}\n')
至此,我们已成功实现用自定义的检索功能来增强 OpenAI Assistant 的回答能力。

03.总结
看到这里,相信大家对于【是否需要向量数据库】已经有了答案:虽然 OpenAI Assistants 的内置检索工具令人眼前一亮,但它仍旧存在诸多存储限制,如:可扩展性较差,无法满足多样的、定制化的用户需求等。可以这样理解,OpenAI Assistants 适用于个人用户,但无法满足数据量更大、业务更复杂的应用需求。
如果想要克服 OpenAI Assistants 的种种限制和不利因素,开发者可以考虑使用例如 Milvus 或 Zilliz Cloud 等向量数据库搭建自定义检索功能,从而实现更灵活的问答应用。
做一波预告!在后续的文章中,我们将继续测评 OpenAI Assistants 内置检索和基于外部向量数据库的方案,从性能、成本和功能等维度进行详细比较。届时亦会发布一系列的性能测试结果,敬请关注!
本文由 mdnice 多平台发布
相关文章:
OpenAI 上线新功能力捧 RAG,开发者真的不需要向量数据库了?
近期, OpenAI 的开发者大会迅速成为各大媒体及开发者的热议焦点,有人甚至发出疑问“向量数据库是不是失宠了?” 这并非空穴来风。的确,OpenAI 在现场频频放出大招,宣布推出 GPT-4 Turbo 模型、全新 Assistants API 和一…...
PyCharm鼠标控制字体缩放
File->Settings->Keymap 右边搜索栏输入increase(放大),可以看到下面出现increase Font Size(放大字体尺寸),双击。 双击后出现几个选项,选择Add Mouse Shortcut,会出现一个页面给录入动作。 按住Ctrl同时鼠标向上滚动,该动…...

NI USRP RIO软件无线电
NI USRP RIO软件无线电 NI USRP RIO是SDR游戏规则的改变者,它为无线通信设计人员提供了经济实惠的SDR和前所不高的性能,可帮助开发下一代5G无线通信系统。“USRP RIO”是一个术语,用于描述包含FPGA的USRP软件定义无线电设备,例如…...

kicad源代码研究:symbol properties窗口中为SCH_SYMBOL添加或删除一个sch_field
向grid中添加一个sch_field FIELDS_GRID_TABLE<SCH_FIELD>* m_fields; WX_GRID* m_fieldsGrid; simEnableFieldRow (int) m_fields->size(); m_fields->emplace_back( VECTOR2I( 0, 0 ), simEnableFieldRow, m_symbol, SIM_ENABLE_FIELD ); // notify the grid w…...

httpClient超时时间详解与测试案例
使用httpclient作为http请求的客户端时,我们一般都会设置超时时间,这样就可以避免因为接口长时间无响应或者建立连接耗时比较久导致自己的系统崩溃。通常它里面设置的几个超时时间如下: RequestConfig config RequestConfig.custom().setCo…...

后端接口性能优化分析-数据库优化
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码🔥如果感觉博主的文章还不错的话,请👍三连支持&…...

都很忙,哪里寻找时间?
最近忙不? 多久未联系的朋友发来信息。 我感觉就是一坑。 说忙吧,显得自己很重要,可说不忙吧,又显得没价值。 有事说事,不要上来就说“在不?忙不?有时间不?空不?”等…...
【经验记录】Ubuntu系统安装xxxxx.tar.gz报错ImportError: No module named setuptools
最近在Anaconda环境下需要离线状态(不能联网的情况)下安装一个xxxxx.tar.gz格式的包,将对应格式的包解压后,按照如下命令进行安装 sudo python setup.py build # 编译 sudo python setup.py install # 安装总是报错如下信息&am…...

SDL2 消息循环和事件响应
1.简介 SDL事件可以是用户输入、系统通知或窗口管理事件等。SDL事件可以通过SDL_PollEvent和SDL_WaitEvent函数来获取。在SDL中,事件是通过SDL_Event结构体表示的,其中包含事件类型以及与该类型相关的具体数据。 下面是一些常见的SDL事件类型和相关的事…...
技巧篇:Mac 环境PyCharm 配置 python Anaconda
Mac 中 PyCharm 配置 python Anaconda环境 在 python 开发中我们最常用的IDE就是PyCharm,有关PyCharm的优点这里就不在赘述。在项目开发中我们经常用到许多第三方库,用的最多的命令就是pip install 第三方库名 进行安装。现在你可以使用一个工具来帮你解…...
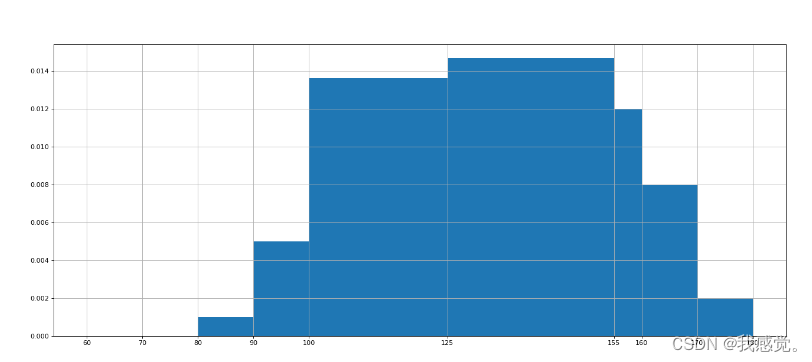
matplotlib绘图
介绍 在官网上有更多种类的图型的绘制方法 matpoltlib中文官方文档:例子_Matplotlib 中文网 matpoltlib英文官方文档:Examples — Matplotlib 3.8.1 documentation 分类 一、折线图 1、要实现的功能: 2、实例: # 导入包 from…...
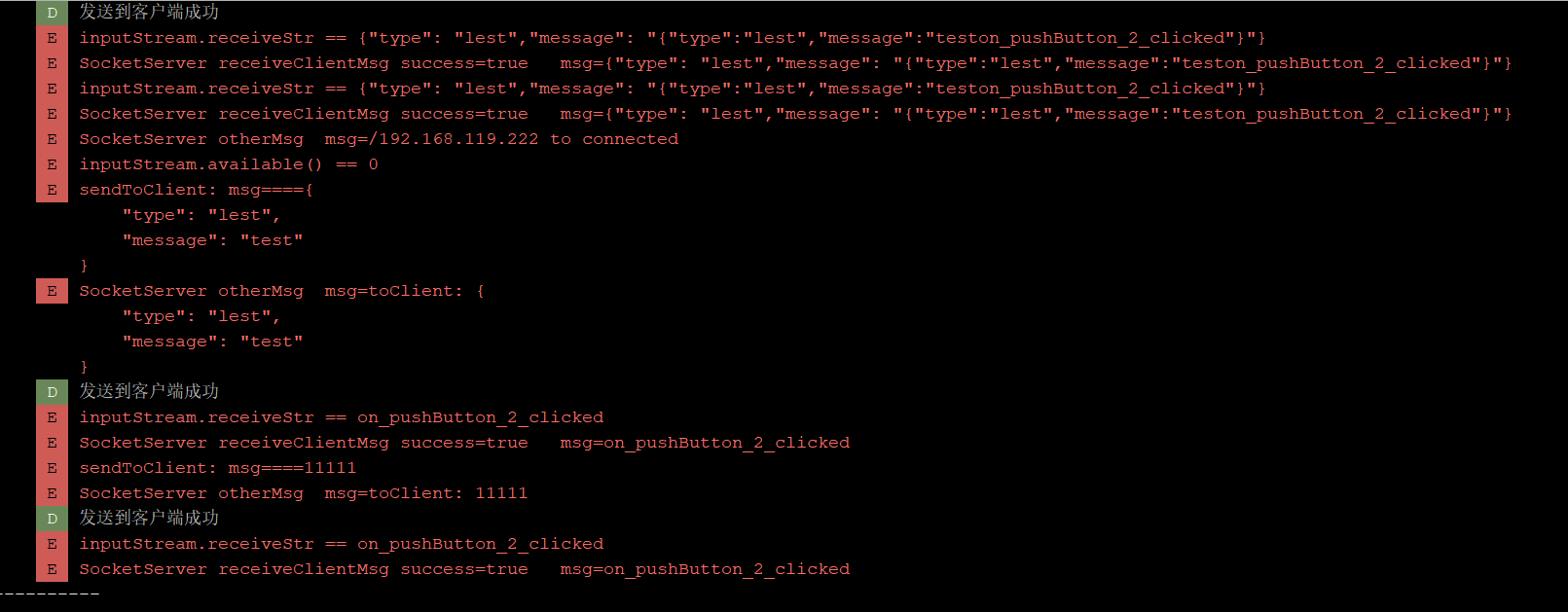
QT使用Socket与安卓Socket互发消息
背景:安卓设备通过usb网络共享给Linux,此时安卓设备与linux处于同一网络环境,符合使用socket的条件,linux做客户端,安卓做服务端 1.QT使用Socket (1).在工程文件中加入 QT network (2).导包以及写一些槽函数用做数据传输与状态接收 #ifndef MAINWINDOW_H #define MAINWINDOW…...
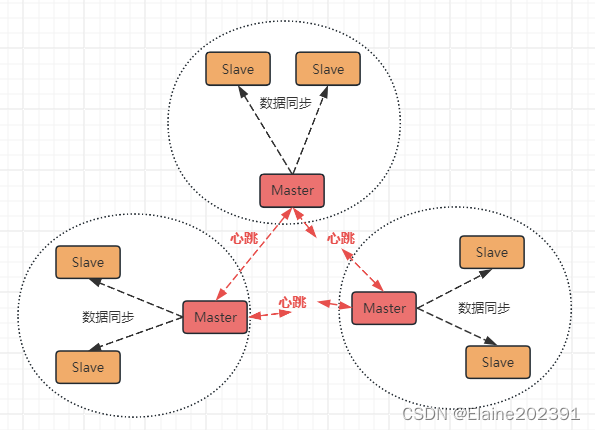
Redis05-集群方案
目录 Redis集群方案 主从复制 主从复制的基本原理 主从复制的工作流程 乐观复制 主从复制的优势 哨兵机制 哨兵的关键作用 服务状态监控 哨兵选举Master规则 分片集群 分片集群中的数据读写 数据写入 数据读取 一致性哈希和客户端分片 Redis集群方案 微服务时代…...

故障演练的关键要素及重要性
故障演练是一种有计划的、模拟真实生产环境故障的活动。通过故意引入故障、模拟系统组件失效或模拟其他异常条件,团队可以观察并评估系统在这些情况下的反应。这有助于发现潜在的问题、改进应急响应和提高系统整体的可用性。 一、故障演练的关键要素 计划性…...

11月15日,每日信息差
今天是2023年11月15日,以下是为您准备的12条信息差 第一、去哪儿正式启动鸿蒙原生应用开发 第二、最高支持千亿向量规模,腾讯云向量数据库全面升级,同时和信通院一起联合50多家企业共同发布了国内首个向量数据库标准,推进向量数…...

java-关于alibaba的JSON.parseArray注意事项
String resultStr dataStrJosnObject.get("result").toString();JSONArray resultArray JSON.parseArray(resultStr);resultStr 格式是[{},{},{}] resultArray 的size是3 获取第一个{}字符串,使用resultArray.get(0) 获取第二哥个{}字符串,使…...
软文推广中媒体矩阵的优势在哪儿
咱们日常生活中是不是经常听到一句俗语,不要把鸡蛋放在同一个篮子里,其实在广告界这句话也同样适用,媒介矩阵是指企业在策划广告活动时,有目的、有计划的利用多种媒体进行广告传播,触达目标用户。今天媒介盒子就来和大…...

xss总结
xss注入总结 漏洞描述 XSS(跨站脚本攻击)是一种常见的网络安全漏洞,攻击者利用该漏洞在网页中插入恶意脚本,以获取用户的敏感信息或执行恶意操作。 XSS中文叫做跨站脚本攻击(Cross-site scripting)&…...

【MySQL学习】常见命令
数据库操作 (1)查询所有数据库名字 show databases;(2)常见数据库 create database db_name; //create if exist create database if exists databaseName;(3)删除数据库 drop database db_name;表格操…...
汽车ECU的虚拟化技术初探(二)
目录 1.概述 2.U2A虚拟化方案概述 3.U2A的虚拟化功能概述 4.虚拟化辅助功能的使能 5.留坑 1.概述 在汽车ECU的虚拟化技术初探(一)-CSDN博客里,我们聊到虚拟化技术比较关键的就是vECU的虚拟地址翻译问题,例如Cortex-A77就使用MMU来进行虚实地址的转换…...

混合求解器:用神经网络增强传统微分方程数值方法
1. 项目概述:当数值方法遇到机器学习在科学计算和工程仿真领域,求解常微分方程(ODE)和偏微分方程(PDE)是绕不开的核心任务。无论是模拟电路中的电流变化、预测天气系统的演变,还是分析机械结构的…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...