MySQL 社区开源备份工具 Xtrabackup 详解
文章目录
- 前言
- 1. Xtrabackup 介绍
- 1.1 物理备份与逻辑备份区别
- 1.2 Xtrabackup 系列版本
- 2. Xtrabackup 部署
- 2.1 下载安装包
- 2.2 二进制部署
- 2.3 程序文件介绍
- 2.4 备份需要的权限
- 3. Xtrabackup 使用场景
- 3.1 本地全量备份
- 3.2 本地压缩备份
- 3.3 全量流式备份
- 3.3.1 备份到远程主机
- 3.3.2 gzip 本地压缩备份
- 3.3.2 gzip 远程压缩备份
- 3.3.2 远程备份限速
- 3.4 全量备份恢复数据
- 3.5 增量备份与恢复
- 3.5.1 增量备份
- 3.5.2 增量备份恢复
前言
数据库备份恢复是 DBA 的 “保命” 技能,生产业务不仅要保证有合适的备份策略,也要定期验证备份的有效性和恢复演练流程,因为数据恢复和验证可能会涉及多方合作,演练可以让灾难真正发生时,多方配合有条不紊的将数据恢复,从而尽可能的减少 RTO 让业务快速恢复。
Xtrabackup 是 MySQL 社区唯一一款开源物理热备工具,本篇文章将详细介绍 DBA 如何使用它,以及备份恢复的详细步骤。
官方文档地址:https://www.percona.com/software/documentation
1. Xtrabackup 介绍
1.1 物理备份与逻辑备份区别
1.2 Xtrabackup 系列版本
目前 Xtrabackup 活跃的大版本有三个:
- Xtrabackup 2.4 适用于 MySQL 5.6 和 MySQL 5.7。
- Xtrabackup 8.0 适用于 MySQL 8.0。
- Xtrabackup 8.1 适用于 MySQL 8.1。
注意,三个版本不能混用,因为 MySQL 8.0 版本 redo log 和数据字典格式都发生了变化,可能会出现不兼容的情况。
2. Xtrabackup 部署
2.1 下载安装包
从下方链接中,可以获得 Percona 所有产品的安装包:
https://www.percona.com/downloads

这里可以选择 Xtrabackup 对应的系列版本。版本号规则,例如 Percona XtraBackup 8.0.30-23 的版本号定义了以下信息:
- 基础版本 - 最左边的数字表示用作基础的 MySQL 8.0 版本。
- 次要版本 - 表示软件版本的内部编号。
| 8.0.30 | -23 |
|---|---|
| Base version | Minor build version |
需要注意的是 Percona XtraBackup 编号在 8.0.14 版本之后发生了变化,以使 Percona XtraBackup 版本与 MySQL 保持一致。
所以在备份前,请确保 Percona XtraBackup 的版本等于或高于正在备份的数据库版本。
推荐阅读:Aligning Percona XtraBackup Versions with Percona Server for MySQL
2.2 二进制部署
下载二进制的 Xtrabackup 压缩包,开箱即用:
# 解压缩
tar -zxvf percona-xtrabackup-8.0.34-29-Linux-x86_64.glibc2.17.tar.gz
# 移动目录
mv percona-xtrabackup-8.0.34-29-Linux-x86_64.glibc2.17 /usr/local/xtrabackup-8.0.34
# 配置软链接
ln -sf /usr/local/xtrabackup-8.0.34/bin/* /usr/bin/
完成以上三步,输入 xtrabackup --version 就可以看到版本信息。
xtrabackup version 8.0.34-29 based on MySQL server 8.0.34 Linux (x86_64) (revision id: 5ba706ee)
2.3 程序文件介绍
接下来看看 bin 目录下,各文件的具体作用:
- xbcloud:与流式备份相结合,可将备份存储到 OSS 对象存储上。
- xbcloud_osenv:对 xbcloud 的二次封装,
- xbcrypt:用来加密解密。
- xbstream:用来解压流式备份集。
- xtrabackup:备份的主程序,备份和恢复的工具。
在 xtrabackup 2.4 版本中,还有 innobackupex 文件,不过它只是 xtrabackup 的一个软链。
在 xtrabackup 2.3 版本之前,xtrabackup 只支持 innodb 表的备份,MyISAM 等非事务引擎的表的备份是通过 innobackupex 来实现的。它是使用 Perl 脚本编写的,而 xtrabackup 是使用 C++ 程序编译的二进制文件。
xtrabackup 来备份事务引擎的表,innobackupex 备份非事务引擎的表,两个程序协作完成最终的备份一致性。但既然是两个不同的工具协同处理一个任务,就必然涉及到两个工具之间,信息的交互。当时信息交互的方案,是通过创建和删除临时文件彼此交互。但这种方式存在风险,例如在备份过程中,临时文件被误删等。
于是从 xtrabackup 2.3 开始,Percona 用 C 语言重写了 innobackupex,并将其作为 xtrabackup 的一个软链。它依然支持之前的语法,但不会增加新特性,所有的新特性只会集成在 xtrabackup 中。
xtrabackup 8.0 中,innobackupex 被移除了,所以建议从 xtrabackup 2.3 开始,只使用 xtrabackup 二进制程序进行备份恢复操作。
本篇文章的所有演示也只会使用 xtrabackup。
2.4 备份需要的权限
Xtrabackup 备份工具,备份时用户需要有以下权限。
- Reload:用于执行 FLUSH TABLES WITH REDO LOCK 和 FLUSH NO_WRITE_TO_BINLOG TABLES 是必需权限。
- Replication client:用于执行 SHOW MASTER STATUS 和 SHOW SLAVE STATUS 查看位点信息,是必需权限。
- BACKUP_ADMIN:用于执行 LOCK INSTANCE FOR BACKUP,是必需权限。
- Process:用于执行 SHOW ENGINE INNODB STATUS 和 SHOW PROCESSLIST 是必需权限。
- SYSTEM_VARIABLES_ADMIN:用于在增量备份时执行 SET GLOBAL mysqlbackup.backupid = xxx 操作,是非必需权限。
- SUPER:在指定 --kill-long-queries-timeout 需要杀掉慢查询,和从库备份指定 --safe-slave-backup 需要重启复制,需要用到该权限。
- SHOW VIEW:确认是否有非 INNODB 引擎表。
- 如果使用 Page Tracking 进行增量备份,还需要 mysql.component 表的查询权限。
- 如果指定 --history 还需要 performance_schema.xtraback_history 的 SELECT、INSERT、CREATE、ALTER 权限。
以下是 MySQL 8.0 以上版本的完整授权示例:
CREATE USER 'bkpuser'@'localhost' IDENTIFIED BY 's3cr%T';
GRANT BACKUP_ADMIN, PROCESS, RELOAD, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'bkpuser'@'localhost';
GRANT SELECT ON performance_schema.log_status TO 'bkpuser'@'localhost';
GRANT SELECT ON performance_schema.keyring_component_status TO bkpuser@'localhost';
GRANT SELECT ON performance_schema.replication_group_members TO bkpuser@'localhost';
以下是 MySQL 5.7 版本的完整授权示例:
CREATE USER 'bkpuser'@'localhost' IDENTIFIED BY 's3cret';
GRANT RELOAD, LOCK TABLES, PROCESS, REPLICATION CLIENT ON *.* TO 'bkpuser'@'localhost';
参考:Connection and Privileges Needed
3. Xtrabackup 使用场景
Xtrabackup 备份恢复有三个阶段,第一阶段是备份阶段,将物理文件拷贝到备份目录。第二阶段是 Prepare 阶段,应用 redo log 将数据文件恢复到备份结束时的一致性状态。第三阶段是恢复阶段,就是将备份文件拷贝到 MySQL 数据目录下面,除了使用 Xtrabackup 命令拷贝,我们也可以手动拷贝。
3.1 本地全量备份
xtrabackup --backup --slave-info -u root -H 127.0.0.1 -P3306 -p'YouPassword' --parallel=5 --target-dir=/data/backup/bakup_`date +"%F_%H_%M_%S"` 2>/tmp/xtrabackup.log
关键参数介绍:
- –backup:发起全量备份。
- -u, -H, -P, -p:连接 mysql 实例,用户名、主机 IP、端口、密码。
- –slave-info:记录 slave 复制位点信息,一般备份从库需要指定该参数。
- –target-dir:备份文件的存放路径。
- –parallel:并发拷贝的线程数。
- 2>/tmp/xtrabackup.log:将备份过程中的日志重定向到 /tmp/xtrabackup.log 文件中。
Tips:Xtrabackup 备份成功后,日志最后一行会输出 completed OK!
备份出来的文件中,除了数据文件,还有以下额外的文件:
- backup-my.cnf:该文件不是 MySQL 参数文件的备份,只是记录了一些 Innodb 引擎的参数,会在 Prepare 阶段用到。
- xtrabackup_logfile:该文件用来保存拷贝的 redo log。
- xtrabackup_binlog_info:binlog 位点信息和 GTID 信息。使用该备份恢复后,需要从该 binlog 位点进行增量恢复。
- xtrabackup_slave_info:如果是对从库进行备份,指定
--slave-info该文件会记录主节点的位点信息,取自 SHOW SLAVE STATUS 中的 Relay_Master_Log_File 和 Exec_Master_Log_Pos。如果是给主库备份,该文件为空。 - xtrabackup_checkpoints:该文件记录了备份类型和 LSN 信息。
- xtrabackup_info:该文件中,记录备份的详细信息。
- xtrabackup_tablespaces:记录备份集中表空间的信息。
3.2 本地压缩备份
压缩备份通过 --compress 指定压缩算法,具体命令如下:
xtrabackup --backup --slave-info -u root -H 127.0.0.1 -P3306 -p'YouPassword' --compress --parallel=5 --target-dir=/data/backup/bakup_`date +"%F_%H_%M_%S"`
Xtrabackup 8.0 支持两种压缩算法 zstd(默认) 和 lz4 算法,Xtrabackup 5.7 仅支持 quicklz 算法。
其中 zstd 在解压缩时依赖 zstd 需要安装才能进行解压。quicklz 算法依赖 qpress 也需要安装后才能进行解压。
在 Prepare 阶段之前,必须要先进行解压,命令如下:
xtrabackup --decompress --parallel=5 --target-dir=/data/backup/bakup_2023-11-13_14_44_55/
在解压过程中,需要注意:
-
解压过程中,同样可以指定
--parallel参数,进行并行解压。 -
解压后,默认不会删除压缩文件。如果需要删除,可以指定
--remove-original参数。 -
即便压缩文件没有被删除,当使用
--copy-back将备份拷贝到数据目录时,默认也不会拷贝这些压缩文件。
使用 compress 压缩只支持几种限定的算法,如果想要使用其他算法,就需要结合流式备份。
3.3 全量流式备份
流式备份指将备份数据通过流的方式输出到 STDOUT,而不是备份文件中。结合管道,可将多个功能组合在一起,如压缩、加密、流控等。
在 xtrabackup 2.4 版中支持 tar 和 xbstream 流格式,但 tar 格式不支持并行备份。
在 xtrabackup 8.0 中,仅支持 xbstream 流格式,不再支持 tar 格式。
3.3.1 备份到远程主机
使用下方命令通过管道组合,实现本地不落盘,将备份保存到远程主机。
xtrabackup --backup --slave-info -u root -H 127.0.0.1 -P3306 -p'YouPassword' \--stream=xbstream --target-dir=/data/backup/bakup_`date +"%F_%H_%M_%S"` 2>/data/backup/xtrabackup.log \| ssh root@172.16.104.7 "cat - > /data/backup/backup.xbstream"
远程恢复的时候,需要先使用 xbstream 命令进行解压:
xbstream -x --parallel=10 -C /data/backup/20231113 < ./backup.xbstream
xbstream 中的 -x 表示解压,–parallel 表示并行度,-C 指定解压的目录,最后一级目录必须存在。
3.3.2 gzip 本地压缩备份
使用流式备份,配合管道使用 gzip 命令对备份在本地进行压缩。
xtrabackup --backup --slave-info -u root -H 127.0.0.1 -P3306 -p'YouPassword' \--stream=xbstream --target-dir=/data/backup/bakup_`date +"%F_%H_%M_%S"` \| gzip - > /data/backup/backup1.gz
恢复时需要先使用 gunzip 解压,再使用 xbstream 解压,才能进行 Prepare 阶段。
# gzip 解压
gunzip backup1.gz# xbstream 解压
xbstream -x --parallel=10 -C /data/backup/backup_full < ./backup1
3.3.2 gzip 远程压缩备份
使用流式备份,配合管道将备份 ssh 到远程进行压缩。
xtrabackup --backup --slave-info -u root -H 127.0.0.1 -P3306 -p'YouPassword' \--stream=xbstream --target-dir=/data/backup/bakup_`date +"%F_%H_%M_%S"` \| ssh root@172.16.104.7 "gzip - > /data/backup/backup1.gz"
Tips:恢复解压时的步骤与 3.3.2 相同。
3.3.2 远程备份限速
直接备份到远程服务器,如果担心备份会占用较大的网络带宽,可以使用 pv 命令限速。
下面是 pv 工具的安装方法:
wget https://www.ivarch.com/programs/sources/pv-1.8.0.tar.gz
tar xzf pv-1.8.0.tar.gz
cd pv-1.8.0
sh ./configure
make
sudo make install
下方命令表示限速 10MB 将备份发送到远程服务器压缩保存。
xtrabackup --backup --slave-info -u root -H 127.0.0.1 -P3306 -p'YouPassowrd' \--stream=xbstream --target-dir=/data/backup/bakup_`date +"%F_%H_%M_%S"` \
| pv -q -L10m | ssh root@172.16.104.7 "cat - > /data/backup/backup.xbstream"
pv 命令中,-q 是指 quiet 不输出进度信息,-L 是指传输速率 10m 指 10MB。
Tips:恢复解压时的步骤与 3.3.1 相同。
3.4 全量备份恢复数据
前面 3 个小节,介绍的都是全量备份阶段,本小节将介绍如何恢复全量备份。
首先要进行 Prepare 阶段,在该阶段 Xtrabackup 会启动一个嵌入的 InnoDB 实例来进行 Crash Recovery。该实例的缓冲池的大小由 --use-memory 参数指定,默认为 100MB。如果有充足的内存,通过设置较大的 memory 可以减少 Prepare 阶段花费的时间。
# 进入到备份目录执行该命令
xtrabackup --prepare --use-memory=2G --target-dir=./
Prepare 阶段执行完成后,备份目录下才会生成 redo log 文件,可据此判断备份文件是否执行过 Prepare 阶段。
Prepare 阶段完成后,下面进入恢复阶段,可以手动拷贝文件到数据目录,也可以使用 xtrabackup 工具进行拷贝。
# 进入到备份目录执行该命令
xtrabackup --defaults-file=/etc/my.cnf --copy-back --parallel=10 --target-dir=./
命令中 --copy-back 表示将备份数据文件拷贝到 MySQL 数据目录下。如果在存储空间不足的情况下,可以使用 --move-back 表示移动备份文件。
另外,恢复实例的数据目录必须为空,所以在恢复前,我们需要清空 MySQL 数据目录,或者将其 mv 备份后,重新创建同名目录。数据文件拷贝到目标目录后,需要修改文件属组。
chown -R mysql:mysql /data/mysql_80/
至此,备份就恢复完成了,直接启动 MySQL 即可。
mysqld_safe --defaults-file=/etc/my.cnf &
3.5 增量备份与恢复
xtrabackup 支持增量备份。在做增量备份之前,需要先做一个全量备份。xtrabackup 会基于 innodb page 的 lsn 号来判断是否需要备份一个 page。如果 page lsn 大于上次备份的 lsn 号,就需要备份该 page。
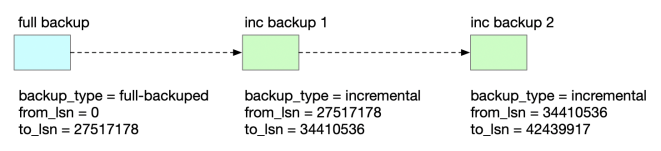
3.5.1 增量备份
先进行一次全量备份。
# 先创建全量备份的目录
mkdir /data/backup/full
xtrabackup --backup --slave-info -u root -H 127.0.0.1 -P3306 \-p'YouPassword' --stream=xbstream --target-dir /data/backup/full \--extra-lsndir=/data/backup/full \2>/data/backup/full/backup_full.log | gzip - > /data/backup/full/backup_full.gz
备份命令加上 了–extra-lsndir 选项,将 xtrabackup_checkpoints 单独输出到文件。增量备份时需要根据 xtrabackup_checkpoints中的 lsn。以下是相关文件。
# ls -l /data/backup/full
-rw-r--r-- 1 root root 3014835 6月 25 16:35 backup_full.gz
-rw-r--r-- 1 root root 40313 6月 25 16:35 backup_full.log
-rw-r--r-- 1 root root 134 6月 25 16:35 xtrabackup_checkpoints
-rw-r--r-- 1 root root 673 6月 25 16:35 xtrabackup_info
现在,发起增量备份。
# 先创建增量备份的目录
mkdir /data/backup/inc1
xtrabackup --backup --slave-info -u root -H 127.0.0.1 -P3306 \-p'YouPassword' --stream=xbstream --target-dir /data/backup/inc1 \--extra-lsndir=/data/backup/inc1 \--incremental-basedir=/data/backup/full \2>/data/backup/inc1/backup_inc1.log | gzip - > /data/backup/inc1/backup_inc1.gz
–incremental-basedir:全量备份或上一次增量备份 xtrabackup_checkpoints 文件所在目录。
增量备份也可以在上一次增量备份的基础上进行:
# 先创建增量备份的目录
mkdir /data/backup/inc2
xtrabackup --backup --slave-info -u root -H 127.0.0.1 -P3306 \-p'YouPassword' --stream=xbstream --target-dir /data/backup/inc2 \--extra-lsndir=/data/backup/inc2 \--incremental-basedir=/data/backup/inc1 \2>/data/backup/inc2/backup_inc2.log | gzip - > /data/backup/inc2/backup_inc2.gz
3.5.2 增量备份恢复
恢复增量备份时,需要先对基础全量备份进行恢复,然后再依次按增量备份的时间进行恢复。
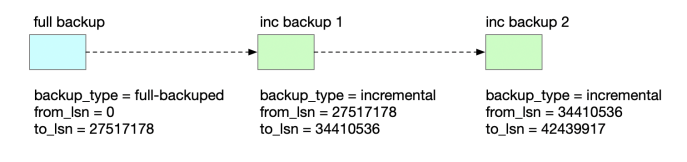
这个例子中,相关备份文件的目录结构如下:
/data/backup
├── full
│ ├── backup_full
│ ├── backup_full.log
│ ├── xtrabackup_checkpoints
│ └── xtrabackup_info
├── inc1
│ ├── backup_inc1.gz
│ ├── backup_inc1.log
│ ├── xtrabackup_checkpoints
│ └── xtrabackup_info
├── inc2
│ ├── backup_inc2.gz
│ ├── backup_inc2.log
│ ├── xtrabackup_checkpoints
│ └── xtrabackup_info
首先,恢复全量备份。
cd /data/backup/fullgunzip backup_full.gz# 需要先删除这两个文件,否则 xbstream 提取文件时有冲突
rm xtrabackup_checkpoints xtrabackup_infoxbstream -x -v < backup_fullxtrabackup --prepare --apply-log-only --target-dir=. > prepare_full.log 2>&1
恢复全量备份时,需要加上 apply-log-only 参数。如果不加上 apply-log-only 参数,执行 prepare 的最后阶段,会回滚未提交的事务,但是这些事务可能在下一次增量备份时已经提交了。
查看日志,确认这一步骤执行成功(最后一行日志显示“completed OK!”):
[Note] [MY-011825] [Xtrabackup] completed OK!
接下来,恢复第一个增量备份。
cd /data/backup/inc1gunzip backup_inc1.gz# 需要先删除这两个文件,否则 xbstream 提取文件时有冲突
rm xtrabackup_checkpoints xtrabackup_info# 提取文件
xbstream -x -v < backup_inc1# 恢复增量备份时,切换到全量备份的目录执行
cd /data/backup/full
xtrabackup --prepare --apply-log-only --incremental-dir=/data/backup/inc1 --target-dir=.
恢复增量备份时,加上 apply-log-only 参数,参数 --incremental-dir 设置为增量备份文件所做目录。日主输出 completed OK! 表示任务运行成功。
接下来,恢复第二个增量备份,也就是最后一个增量备份。
cd /data/backup/inc2gunzip backup_inc2.gz# 需要先删除这两个文件,否则xbstream提取文件时有冲突
rm xtrabackup_checkpoints xtrabackup_info# 提取文件
xbstream -x -v < backup_inc2# 恢复增量备份时,切换到全量备份的目录执行
cd /data/backup/full
xtrabackup --prepare --incremental-dir=/data/backup/inc2 --target-dir=.
恢复最后一个增量备份时,不需要再加上 --apply-log-only。这一步执行完成后,xtrabackup_checkpoints文件内容如下:
# cat xtrabackup_checkpoints
backup_type = full-prepared
from_lsn = 0
to_lsn = 42439917
last_lsn = 52717010
flushed_lsn = 52617342
redo_memory = 0
redo_frames = 0
backup_type 为 full-prepared,表示 Prepare 阶段已经完成。后面操作和恢复全量备份基本一样。复制文件启动数据库即可。
参考:YunChe MySQL运维实战之备份和恢复(8.4)xtrabackup恢复全量备份
相关文章:
MySQL 社区开源备份工具 Xtrabackup 详解
文章目录 前言1. Xtrabackup 介绍1.1 物理备份与逻辑备份区别1.2 Xtrabackup 系列版本 2. Xtrabackup 部署2.1 下载安装包2.2 二进制部署2.3 程序文件介绍2.4 备份需要的权限 3. Xtrabackup 使用场景3.1 本地全量备份3.2 本地压缩备份3.3 全量流式备份3.3.1 备份到远程主机3.3.…...
【仿真】ruckig在线轨迹生成器示例
该场景说明了使用 CoppeliaSim 中提供的 Ruckig 在线轨迹生成功能的各种方法: 1. 在线程脚本内使用单个阻塞函数(红色) 2. 在线程脚本中使用多个非阻塞函数(黄色) 3. 在非线程脚本中使用多个非阻塞函数(…...

LeetCode 面试题 16.22. 兰顿蚂蚁
文章目录 一、题目二、C# 题解 一、题目 一只蚂蚁坐在由白色和黑色方格构成的无限网格上。开始时,网格全白,蚂蚁面向右侧。每行走一步,蚂蚁执行以下操作。 (1) 如果在白色方格上,则翻转方格的颜色,向右(顺时针)转 90 度…...
Docker安装详细步骤及相关环境安装配置(mysql、jdk、redis、自己的私有仓库Gitlab 、C和C++环境以及Nginx服务代理)
目录 一、从空白系统中克隆Centos7系统 二、使用xshell连接docker_tigerhhzz虚拟机编辑 三、在CentOS7基础上安装Docker容器 四、在Docker中进行安装Portainer 4.1、在Docker中安装MySQL 4.2、在Docker中安装JDK8,安装Java环境 4.3、Docker安装redis&#…...
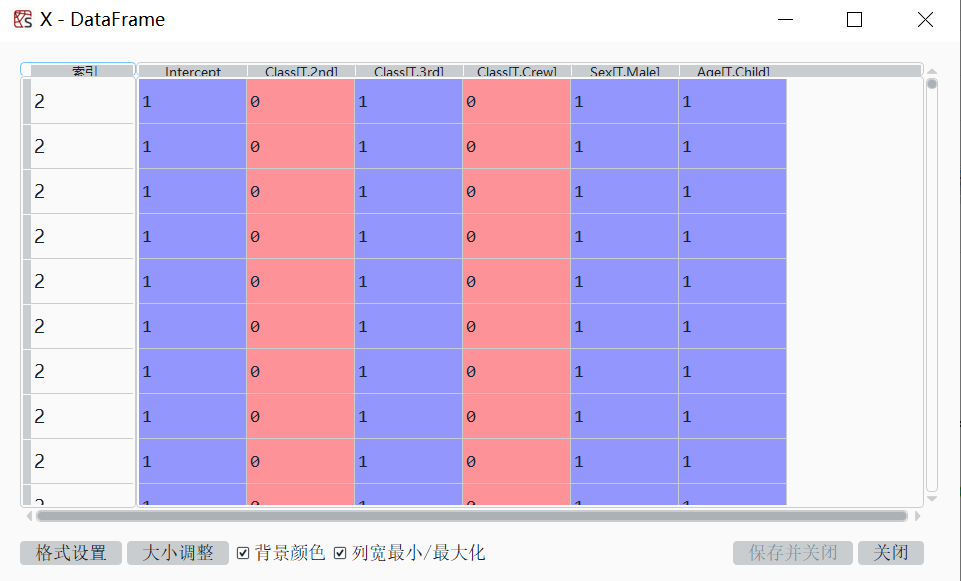
科研学习|研究方法——Python计量Logit模型
一、离散选择模型 莎士比亚曾经说过:To be, or not to be, that is the question,这就是典型的离散选择模型。如果被解释变量时离散的,而非连续的,称为“离散选择模型”。例如,消费者在购买汽车的时候通常会比较几个不…...

灵活运用Vue指令:探究v-if和v-for的使用技巧和注意事项
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 ⭐ 专栏简介 📘 文章引言 一、作…...

nvidia-docker部署pytorch服务【GPU工作站】
文章目录 一、安装 Docker二、安装 NVIDIA Container Toolkit三、宿主机安装 cuda 和 nvidia-driver四、测试一、安装 Docker 可以参考这篇文章 https://blog.csdn.net/weixin_43721000/article/details/124237932 二、安装 NVIDIA Container Toolkit 参考nvidia官方 https:/…...
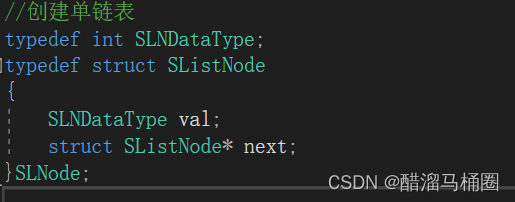
单链表的实现
CSDN主页:醋溜马桶圈_C语言进阶,初始C语言,数据结构-CSDN博客 Gitee主页:mnxcc (mnxcc) - Gitee.com 专栏:数据结构_醋溜马桶圈的博客-CSDN博客 目录 1.认识单链表 2.创建单链表 3.单链表的操作 3.1打印单链表 3.2开辟新空间 3.3尾插 3.4头插…...
)
【python】面向对象(类型定义魔法方法)
目录 一、引言 二、类型定义 1、什么是类型的定义? 2、案例 三、魔法方法 1、什么是魔法方法 2、基础部分 3、比较操作 4、容器类型 5、属性管理 6、封装 7、方法拓展 8、继承 9、多态 一、引言 Python是一种面向对象的语言,它支持类&#…...
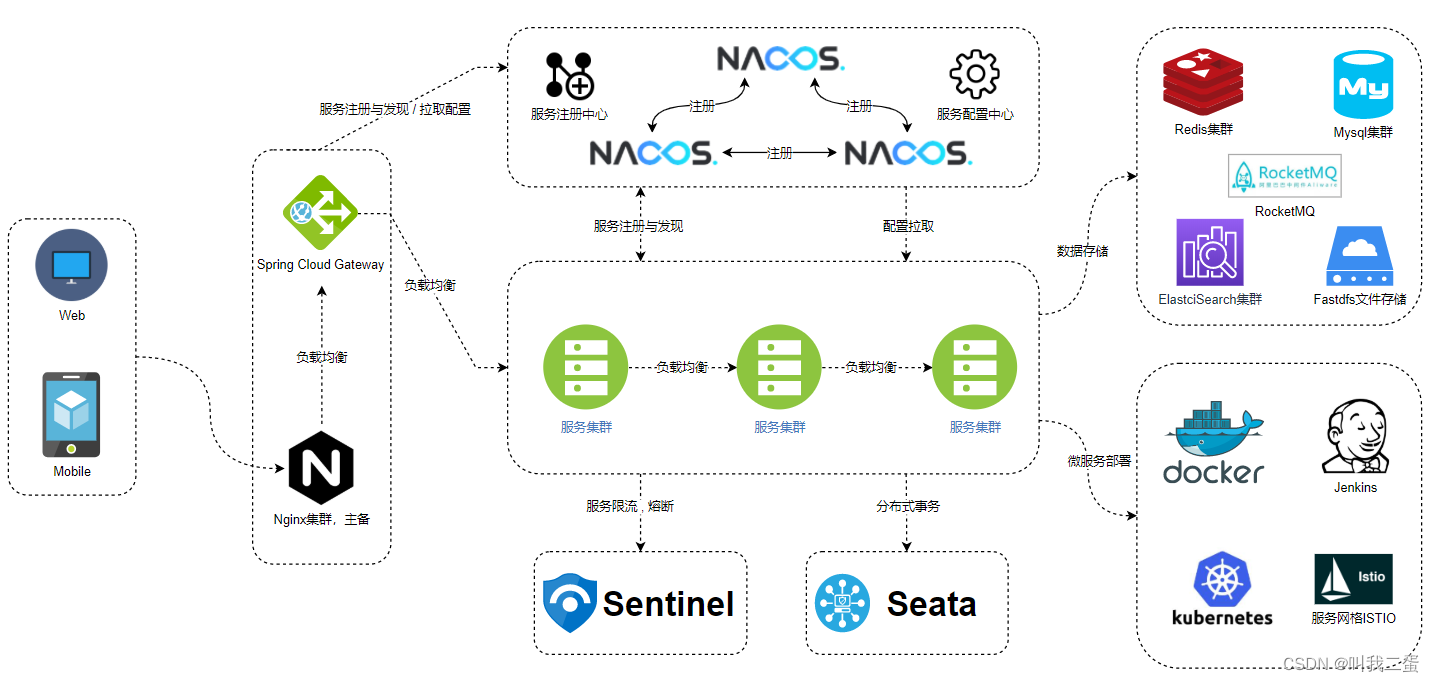
1.微服务与SpringCloud
微服务和SpringCloud 文章目录 微服务和SpringCloud1.什么是微服务2.SpringCloud3. 微服务 VS SpringCloud4. SpringCloud 组件5.参考文档6.版本要求 1.什么是微服务 微服务是将一个大型的、单一的应用程序拆分成多个小型服务,每个服务实现特定的业务功能ÿ…...
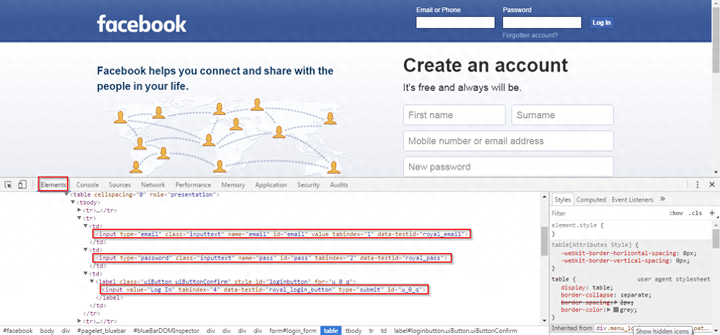
【2023全网最全最火】Selenium WebDriver教程(建议收藏)
在本教程中,我将向您介绍 Selenium Webdriver,它是当今市场上使用最广泛的自动化测试框架。它是开源的,可与所有著名的编程语言(如Java、Python、C#、Ruby、Perl等)一起使用,以实现浏览器活动的…...
)
dimp 导入dmp文件报错:无效的模式名(DM8:达梦数据库)
dimp 导入dmp文件报错:无效的模式名-DM8:达梦数据库 环境介绍1 搭建A1 数据库52361.1 A1数据库5236创建模式名,表,测试数据1.2 从A1数据库5236导出dmp文件 2 搭建A2数据库52372.1 创建 数据用户ABC2311152.2 在A2 数据库5237 导入DMP(报错无效的模式名)2.3 使用REMAP_SCHEMAABC…...
)
宿主机无法连接docker里的redis问题解决(生产环境慎用)
宿主机无法连接docker里的redis问题解决(生产环境慎用) 问题描述解决方案 问题描述 1.连接超时 2.连接能连上但马上断开并报错 3.提示保护模式什么的 (error) DENIED Redis is running in protected mode because protected mode is enabled链接redis …...
给女朋友开发个小程序低价点外卖吃还能赚钱
前言 今天又是无聊的一天,逛了下GitHub,发现一个库里面介绍美团饿了吗外卖红包外卖优惠券,先领红包再下单。外卖红包优惠券,cps分成,别人领红包下单,你拿佣金。哇靠,那我岂不是可以省钱还可以赚钱,yyds。。。。想想都美好哈哈哈!!! 回到正题,这个是美团饿了么分销…...

外贸客户管理系统是什么?推荐的管理软件?
外贸客户管理系统哪个好用?海洋建站如何选管理系统? 外贸客户管理系统,是一款专为外贸企业设计的客户关系管理系统,旨在帮助外贸企业建立与维护客户关系,提高客户满意度和忠诚度,提升企业业绩。海洋建站将…...

数据挖掘:分类,聚类,关联关系,回归
数据挖掘: 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle,尤其sql要学&…...

力扣labuladong一刷day10一网打尽股票买卖问题共6题
力扣labuladong一刷day10股票买卖问题共6题 一、121. 买卖股票的最佳时机 题目链接:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/ 思路:只能买入1次,定义dp[i][0]数组表示第i天持有股票时手中的最大金额 数,…...

微信小程序手写table表格
wxml <view class"table"><view class"tr bg-w"><view class"th">张三</view><view class"th" style"color: #409eff;">李四</view><view class"th ">王五</view&…...
UE5 - UI Material Lab 学习笔记
1、学习资料收集 UI Material Lab : https://www.unrealengine.com/marketplace/zh-CN/product/ui-material-lab 视频1:https://www.bilibili.com/video/BV1Hm4y1t7Kn/?spm_id_from333.337.search-card.all.click&vd_source707ec8983cc32e6e065d5496a7f79ee6 视…...

oracle删除重复的数据
去除重复数据: group by 对要比对的字段进行查询是否重复 CREATE TABLE 临时表 AS (select 字段1,字段2,count(*) from 表名 group by 字段1,字段2 having count(*) > 1) 上面这句话就是建立了临时表,并将查询到的数据插入其中。 下面就可以进行…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

Unity动态自然系统:Forest Environment-Dynamic Nature深度解析
1. 这不是“贴图堆砌”,而是自然系统级建模:Forest Environment-Dynamic Nature 的真实定位你有没有试过在Unity里拖进几棵树、铺点草、加个天空盒,然后发现场景像一张静止的风景明信片——风不动、叶不摇、雨不落、雾不散?我做过…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

通过TaotokenCLI工具一键配置开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境接入参数 对于需要接入多个大模型服务的开发者而言,手动配置每个项目的API密钥、…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...

Godot 4.2 + C# 避坑指南:手把手教你打包发布你的第一个2D游戏到Steam
Godot 4.2 C# 避坑指南:从开发到Steam发布的完整实战手册当你终于完成心爱的2D游戏开发,准备向全世界展示你的作品时,打包发布这个看似简单的环节往往会成为独立开发者最大的噩梦。特别是使用Godot 4.2搭配C#的项目,从导出设置到…...
:从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界)
DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界 选择适配业务场景的DeepSeek模型&am…...