Zookeeper学习笔记(1)—— 基础知识
Zookeeper概述
Zookeeper 是一个开源的分布式的,为分布式框架提供协调服务的 Apache 项目
工作机制
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注 册,一旦这些数据的状态发生变化,Zookeeper就 将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应
Zookeeper=文件系统+通知机制
其主要功能为:数据存储+通知更新
以服务器上下线为例:
1.服务端启动,到zookeeper集群中注册信息
2.客户端从zookeeper集群中获取到当前服务器的列表并注册监听
3.服务器节点下线
4.zookeeper集群将服务器节点下线事件通知到客户端
5.客户端重新获取服务器列表,并注册监听
特点
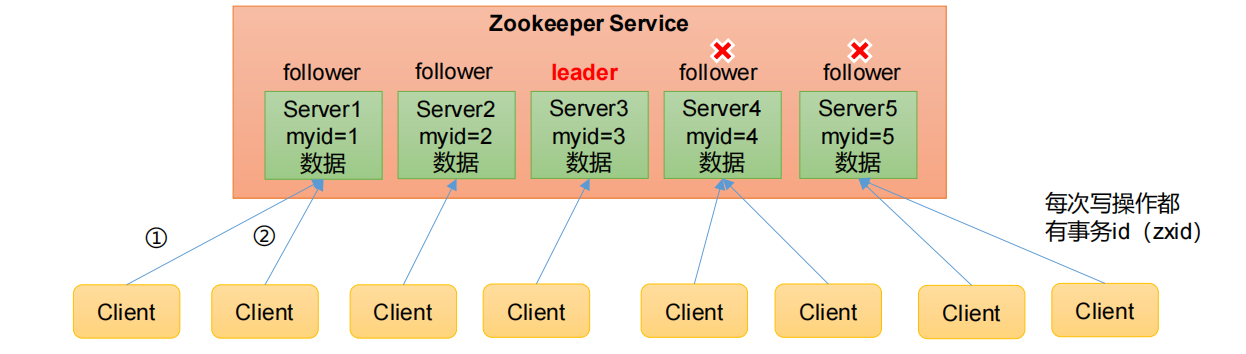
1)Zookeeper是一个领导者(Leader),多个跟随者(Follower)组成的集群
2)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所 以Zookeeper适合安装奇数台服务器
偶数台服务器并不能提升zookeeper的性能
3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的
4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行
5)数据更新原子性,一次数据更新要么成功,要么失败
6)实时性,在一定时间范围内,Client能读到最新数据
数据结构
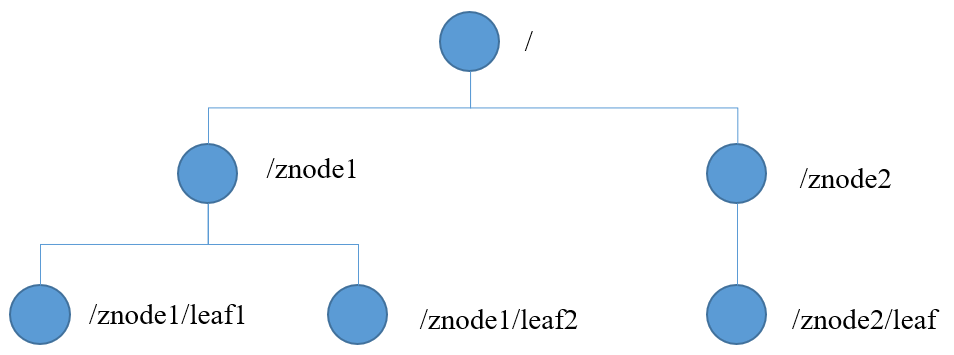
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个节点称做一个 ZNode。每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识
ZNode结构决定了ZooKeeper只适合存储一些简单的配置文件,不适合存储海量数据
应用场景
Zookeeper提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等
统一命名服务

统一配置管理
分布式环境下经常有各个节点配置信息一致的要求,因此对配置文件修改后,希望能快速同步到各个节点上;

zookeeper进行统一配置管理的简单流程:
(1)可将配置信息写入ZooKeeper上的一个Znode
(2)各个客户端服务器监听这个Znode
(3)一旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器
统一集群管理
将节点信息写入zookeeper的ZNode中,然后监听该ZNode即可获取集群节点的实时状态变化;

服务器动态上下线
客户端能实时洞察到服务器上下线的变化:
1.服务端启动,到zookeeper集群中注册信息
2.客户端从zookeeper集群中获取到当前服务器的列表并注册监听
3.服务器节点下线
4.zookeeper集群将服务器节点下线事件通知到客户端
5.客户端重新获取服务器列表,并注册监听
软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求

Zookeeper集群搭建
安装包下载
官网地址:Apache ZooKeeper
进入下载界面:

选择tar包:

安装流程
集群一共使用在三台服务器上部署zookeeper,服务器名称分别为hadoop102-hadoop104
1.上传安装包到服务器上,使用tar -zxvf进行解压到/opt/module/路径下(自定义的路径)
2.将解压后的apache-zookeeper-3.5.7-bin重命名为zookeeper-3.5.7
3.配置服务器编号:
在/opt/module/zookeeper-3.5.7/这个目录下创建 zkData
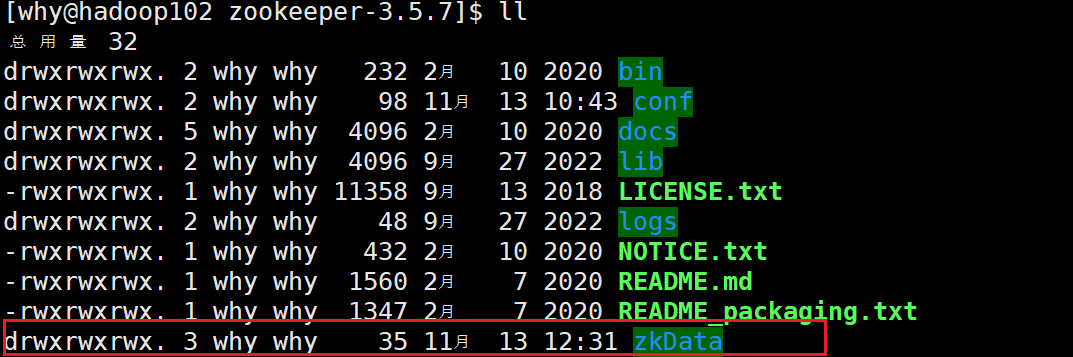
然后在该目录下创建一个名为myid的文件
文件名称是固定的,因为源码中读取的文件名称就是myid
然后在文件中添加与server 对应的编号(三台服务器的编号分别为2、3、4)
4.配置zoo.cfg文件:
重命名/opt/module/zookeeper-3.5.7/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
然后打开 zoo.cfg:
①修改数据存储路径dataDir:dataDir=/opt/module/zookeeper-3.5.7/zkData
②增加集群配置:
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888配置参数格式:
server.A=B:C:DA 是一个数字,表示这个是第几号服务器;集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个 server
B 是这个服务器的地址;
C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口(2888);
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口(3888)
5.将myid及zoo.cfg的配置分发到所有服务器上(注意服务器编号要修改)
集群启动
进入zookeeper路径下:
启动:bin/zkServer.sh start
停止:bin/zkServer.sh stop
查看状态:bin/zkServer.sh status
(附)zoo.cfg配置参数解读
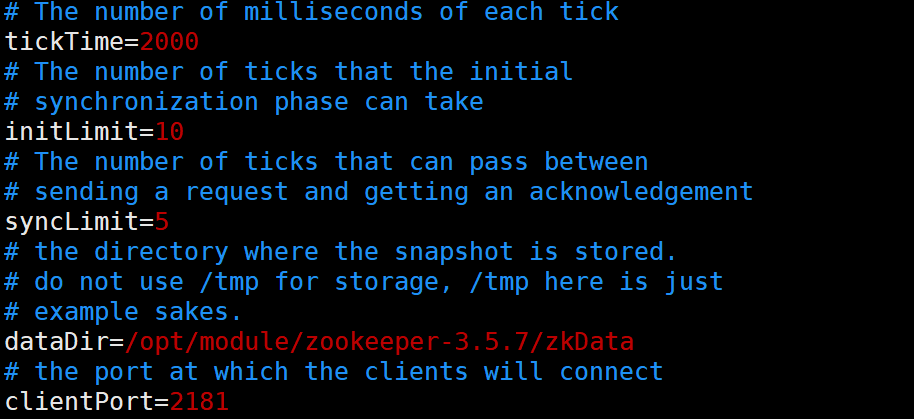
1.tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端通信心跳时间,单位为毫秒
2.initLimit = 10:LF初始通信时限(Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量))
当前配置下,tickTime = 2000,initLimit = 10,则如果Leader和Follower20s内未建立连接,就认为通信失败
3.syncLimit = 5:LF同步通信时限
Leader和Follower之间通信时间如果超过
syncLimit * tickTime(也就是10s),Leader认为Follwer挂掉,从服务器列表中删除Follwer
4.dataDir:Zookeeper中数据存储的路径

不建议使用默认的tmp目录,可能会被linux定期删除
5.clientPort = 2181:客户端连接端口,通常不做修改
(附)集群启停脚本
在/home/username/bin(如/home/why/bin)路径下新建zk.sh文件:
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
doecho ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;"stop"){
for i in hadoop102 hadoop103 hadoop104
doecho ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;"status"){
for i in hadoop102 hadoop103 hadoop104
doecho ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;esac
即将
bin/zkServer.sh start、bin/zkServer.sh stop、bin/zkServer.sh status等指令封装起来添加权限:
chmod u+x zk.sh这样就可以通过
zk.sh start、zk.sh stop进行集群的启停了
Zookeeper选举机制
第一次启动
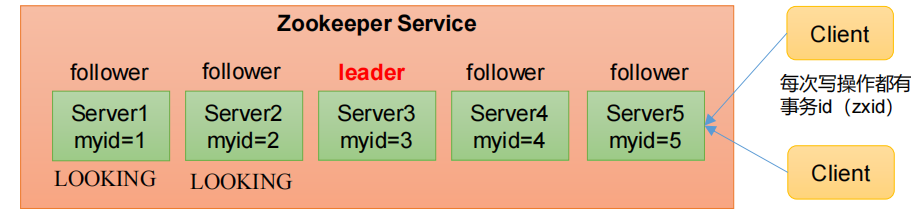
假设集群中一共有5台服务器:
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
根据myid进行投票选择
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,与服务器4相同
集群中产生leader之后不再继续选举
非第一次启动
当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
- 服务器初始化启动
- 服务器运行期间无法和Leader保持连接
而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
- 集群中本来就已经存在一个Leader。
对于第一种已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可
- 集群中确实不存在Leader
此时的选举规则如下:
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举
SID为1、2、4的机器投票情况:(EPOCH,ZXID,SID )
(1,8,1) (1,8,2) (1,7,4)
选举Leader规则:
①EPOCH大的直接胜出
②EPOCH相同,事务id大的胜出
③事务id相同,服务器id大的胜出
参数说明:
● SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
● ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑有关。
● Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加
Zookeeper 命令行操作
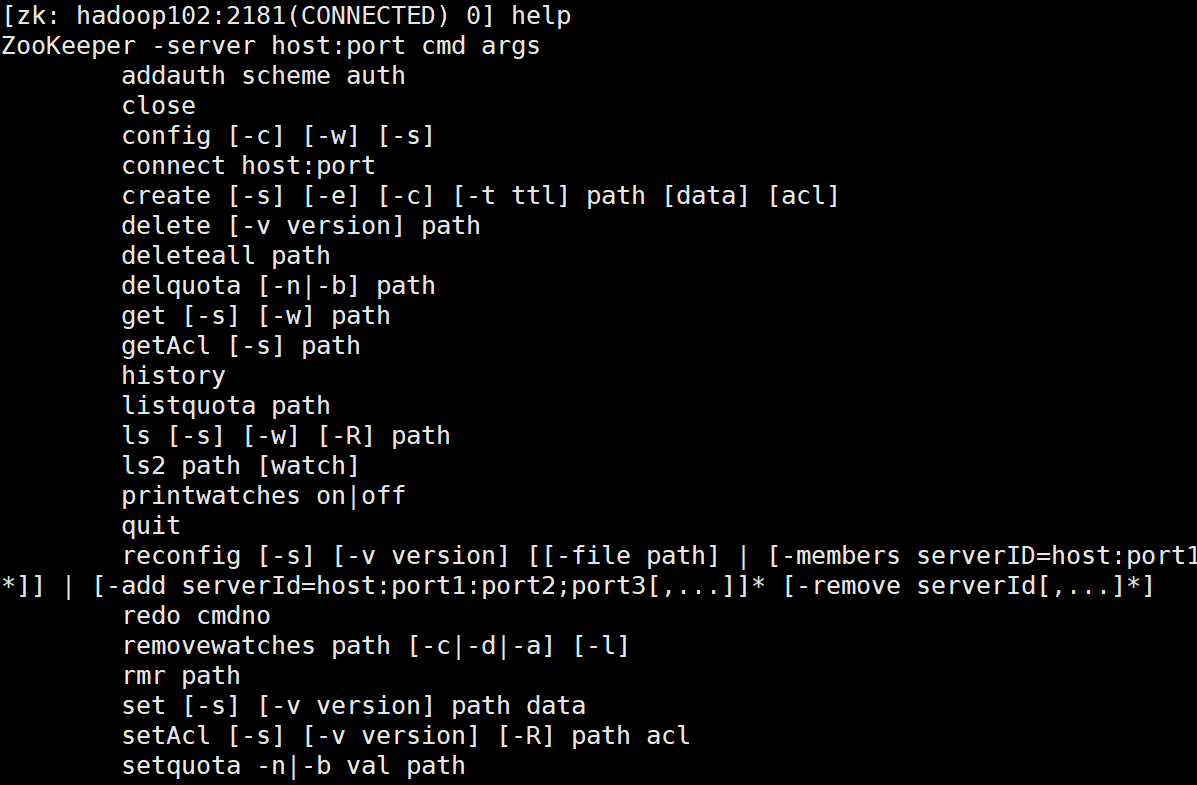
命令行语法
| 命令基本语法 | 功能描述 |
| help | 显示所有操作命令 |
| ls path | 使用 ls 命令来查看当前 znode 的子节点 [可监听] -w 监听子节点变化 -s 附加次级信息 |
| create | 普通创建znode节点 -s 含有序列 -e 临时(重启或者超时消失) |
| get path | 获得节点的值 [可监听] -w 监听节点内容变化 -s 附加次级信息 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| deleteall | 递归删除节点 |
命令行实操
首先启动zookeeper集群
然后进入zookeeper安装路径下,启动客户端:
bin/zkCli.sh -server hadoop102:2181help
使用help查看帮助:
节点数据信息(ls)
ls /:查看zookeeper中所有的znode节点

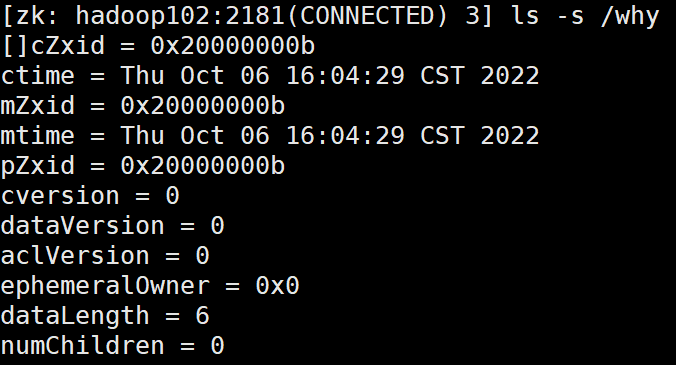
ls -s /:查看更多节点信息

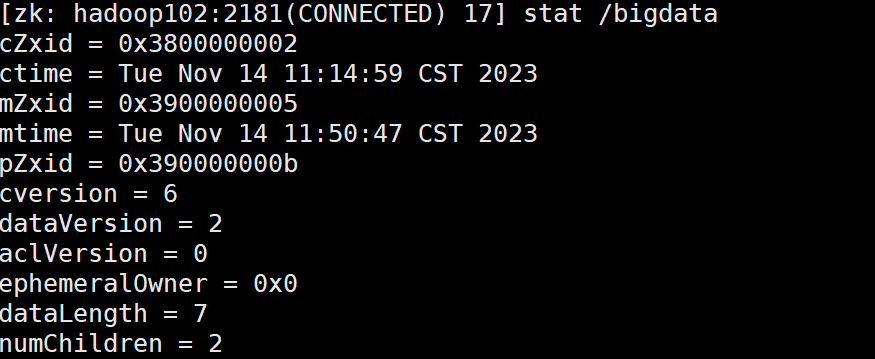
(1)czxid:创建节点的事务 zxid
每次修改 ZooKeeper 状态都会产生一个 ZooKeeper 事务 ID。事务 ID 是 ZooKeeper 中所有修改总的次序。每次修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2 之前发生
(2)ctime:znode 被创建的毫秒数(从 1970 年开始)
(3)mzxid:znode 最后更新的事务 zxid
(4)mtime:znode 最后修改的毫秒数(从 1970 年开始)
(5)pZxid:znode 最后更新的子节点 zxid
(6)cversion:znode 子节点变化号,znode 子节点修改次数
(7)dataversion:znode 数据变化号
(8)aclVersion:znode 访问控制列表的变化号
(9)ephemeralOwner:如果是临时节点,这个是 znode 拥有者的 session id。如果不是临时节点则是0
(10)dataLength:znode 的数据长度
(11)numChildren:znode 子节点数量
注意,使用ls -s /查看的是整个znode树的根节点
即是该根节点下面所有的子节点,要想查看子节点的具体信息,使用具体路径即可;
例如:
ls -s /why:
节点类型(create/get/set)
节点类型主要分为以下四种:
(1)持久化目录节点:客户端与Zookeeper断开连接后,该节点依旧存在
(2)持久化顺序编号目录节点:客户端与Zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
(3)临时目录节点:客户端与Zookeeper断开连接后,该节点被删除
(4)临时顺序编号目录节点:客户端与 Zookeeper 断开连接后 , 该节点被删除 , 只 是Zookeeper给该节点名称进行顺序编号。
顺序编号的含义:
创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
创建普通节点(永久节点 + 不带序号)
1.create /bigdata "bigdata":create普通节点,/bigdata是路径,"bigdata"是节点值
zookeeper创建节点时需要赋值
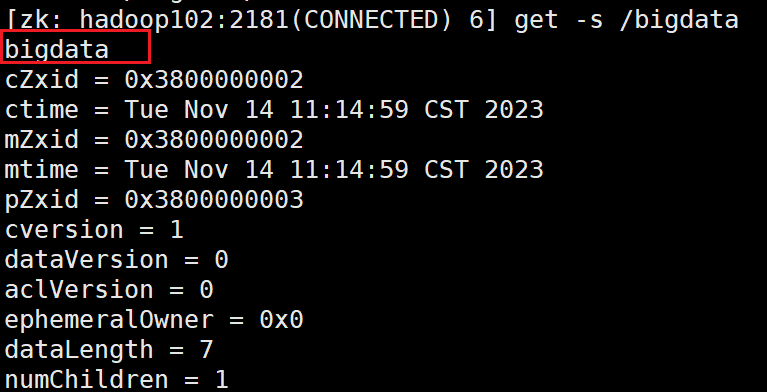
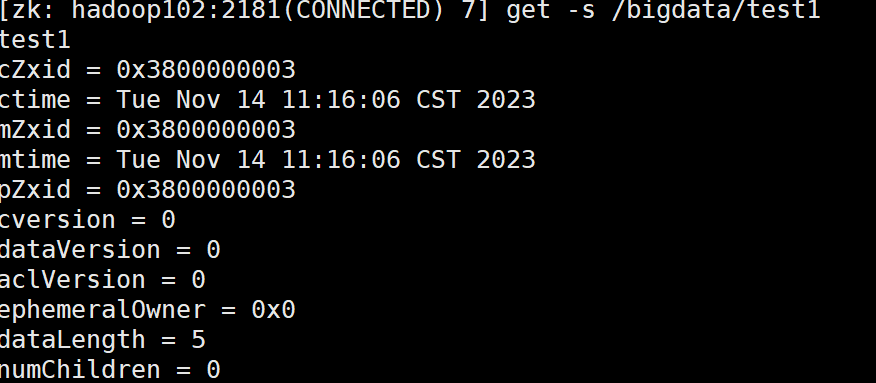
2.create /bigdata/test1 "test1"
查看节点的值:
get -s /bigdata
get -s /bigdata/test1
创建带序号的节点(永久节点 + 带序号)
首先创建一个节点:create /bigdata/test2 "test2"
然后在该节点下创建带序号的永久节点(通过 -s 创建)

如果原来没有序号节点,序号从 0 开始依次递增。如果原节点下已有 2 个节点,则再排序时从 2 开始,以此类推
创建短暂节点
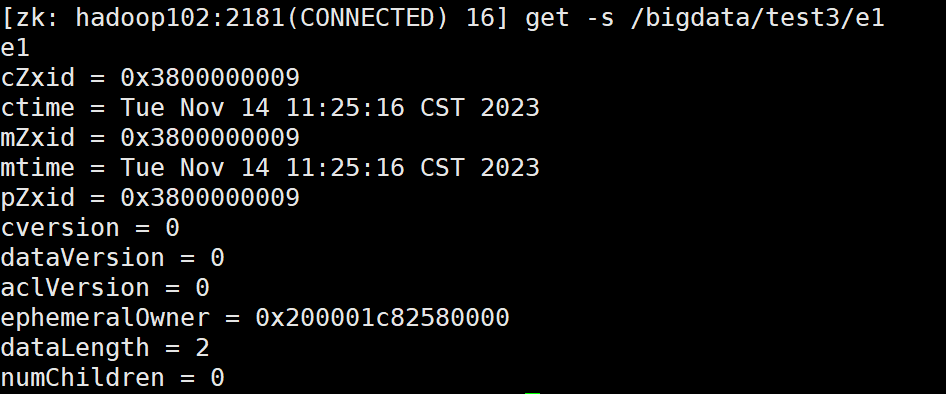
首先创建一个节点:create /bigdata/test3 "test3"
然后在该节点下创建短暂节点(通过 -e 创建):create -e /bigdata/test3/e1 "e1"
可以查看该节点:
接下来退出客户端,重启zookeeper集群,之后重新进入客户端去查看该节点:

可以看到该短暂节点已经不存在了;
修改节点的值
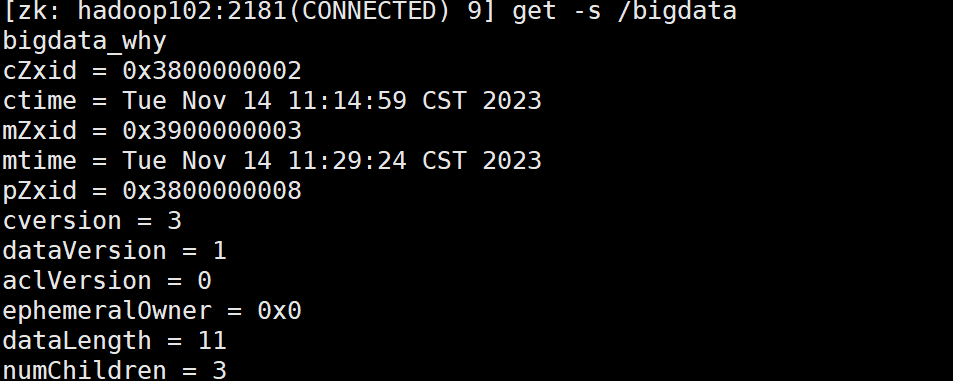
使用set指令:
set /bigdata "bigdata_why"
监听器原理
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目录节点增加删除)时,ZooKeeper 会通知客户端。监听机制保证 ZooKeeper 保存的任何的数据的任何改变都能快速的响应到监听了该节点的应用程序
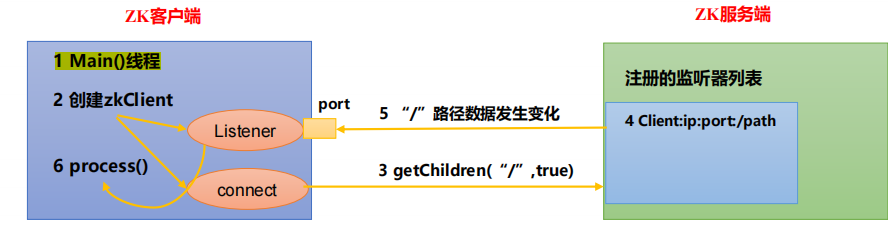
工作流程
1)首先要有一个main()线程
2)在main线程中创建Zookeeper客户端,这时就会创建两个线程,一个负责网络连接通信(connet),一个负责监听(listener)
3)通过connect线程将注册的监听事件发送给Zookeeper
4)在Zookeeper的注册监听器列表中将注册的监听事件添加到列表中
5)Zookeeper监听到有数据或路径变化,就会将这个消息发送给listener线程
6)listener线程内部调用了process()方法,将变化通知到客户端
常见的监听
1)监听节点数据的变化:get path [watch]
2)监听子节点增减的变化:ls path [watch]
节点的值变化
监听bigdata节点的变化:get -w /bigdata
可以看到节点当前的值:
![]()
在hadoop103上修改节点的值:
![]()
在hadoop102中即可监听到节点数据的变化:

节点的子节点变化监听
在hadoop102中:
ls -w /bigdata:监听bigdata节点
在hadoop103中新建子节点:

在hadoop102中即可监听到子节点的变化

节点删除与状态查看
删除节点:delete /bigdata/test4
递归删除:deleteall /bigdata/test2

可以看到删除成功
查看节点状态:stat /bigdata
相关文章:
Zookeeper学习笔记(1)—— 基础知识
Zookeeper概述 Zookeeper 是一个开源的分布式的,为分布式框架提供协调服务的 Apache 项目 工作机制 Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受…...
mp4视频批量截取!!!
mp4视频批量截取!!! 问题:如果我们想截取一个mp4视频中的多个片段,一个一个截会很麻烦! 可以将想要截取的开始时间和结束时间保存到 excel表 中,进行批量截取。 1、对一个视频,记…...
 和 post() 方法)
jQuery - AJAX get() 和 post() 方法
jQuery - AJAX get() 和 post() 方法 jQuery get() 和 post() 方法用于通过 HTTP GET 或 POST 请求从服务器请求数据。 HTTP 请求:GET vs POST 两种在客户端和服务器端进行请求-响应的常用方法是:GET 和 POST。 GET - 从指定的资源请求数据 POST - 向…...
设计模式(4)-行为型模式
行为型模式 行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。 行为型模式分为类行为模式和对象行为模式,前者采用继承机制来在类间…...

JavaScript概述
一、JavaScript简介: JavaScript是互联网上流行的脚本语言,可用于HTML和web,可广泛应用于服务器、PC、笔记本、平板电脑和智能手机等设备。 JavaScript是一种轻量级的编程语言,可插入HTML页面的编程代码,插入HTML页面后…...
Solidity案例详解(四)投票智能合约
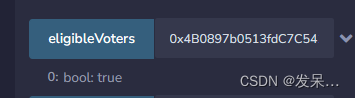
该合约为原创合约,功能要求如下 在⼀定时间能进⾏投票超过时间投票截⽌,并投赞同票超过50%则为通过。 使⽤safeMath库,使⽤Owner 第三⽅库拥有参与投票权的⽤户在创建合约时确定Voter 结构 要有时间戳、投票是否同意等;struct 结构…...
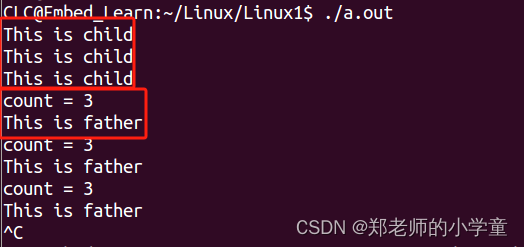
Linux系统编程——进程中vfork函数
函数原型 pid_t vfork(void);//pid_t是无符号整型 所需头文件 #include <sys/types.h> #include <unistd.h> 功能 vfork() 函数和 fork() 函数一样都是在已有的进程中创建一个新的进程,但它们创建的子进程是有区别的。 返回值 成功子进程中返回 …...

敏感数据是什么?包含哪些?如何保障安全?
最近看到不少小伙伴在问,敏感数据是什么?包含哪些?如何保障安全?这里我们小编就给大家一一解答一下,仅供参考哦! 敏感数据是什么? 敏感数据,是指泄漏后可能会给社会或个人带来严重危…...
Leadshop开源商城小程序源码 – 支持公众号H5
Leadshop是一款出色的开源电商系统,具备轻量级、高性能的特点,并提供持续更新和迭代服务。该系统采用前后端分离架构(uniappyii2.0),以实现最佳用户体验为目标。 前端部分采用了uni-app、ES6、Vue、Vuex、Vue Router、…...
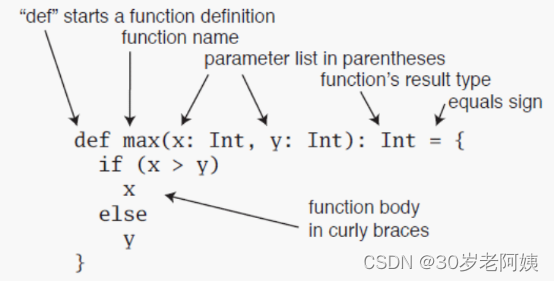
Scala---方法与函数
一、Scala方法的定义 有参方法&无参方法 def fun (a: Int , b: Int) : Unit {println(ab) } fun(1,1)def fun1 (a: Int , b: Int) ab println(fun1(1,2)) 注意点: 方法定义语法 用def来定义可以定义传入的参数,要指定传入参数的类型方法可以写返…...
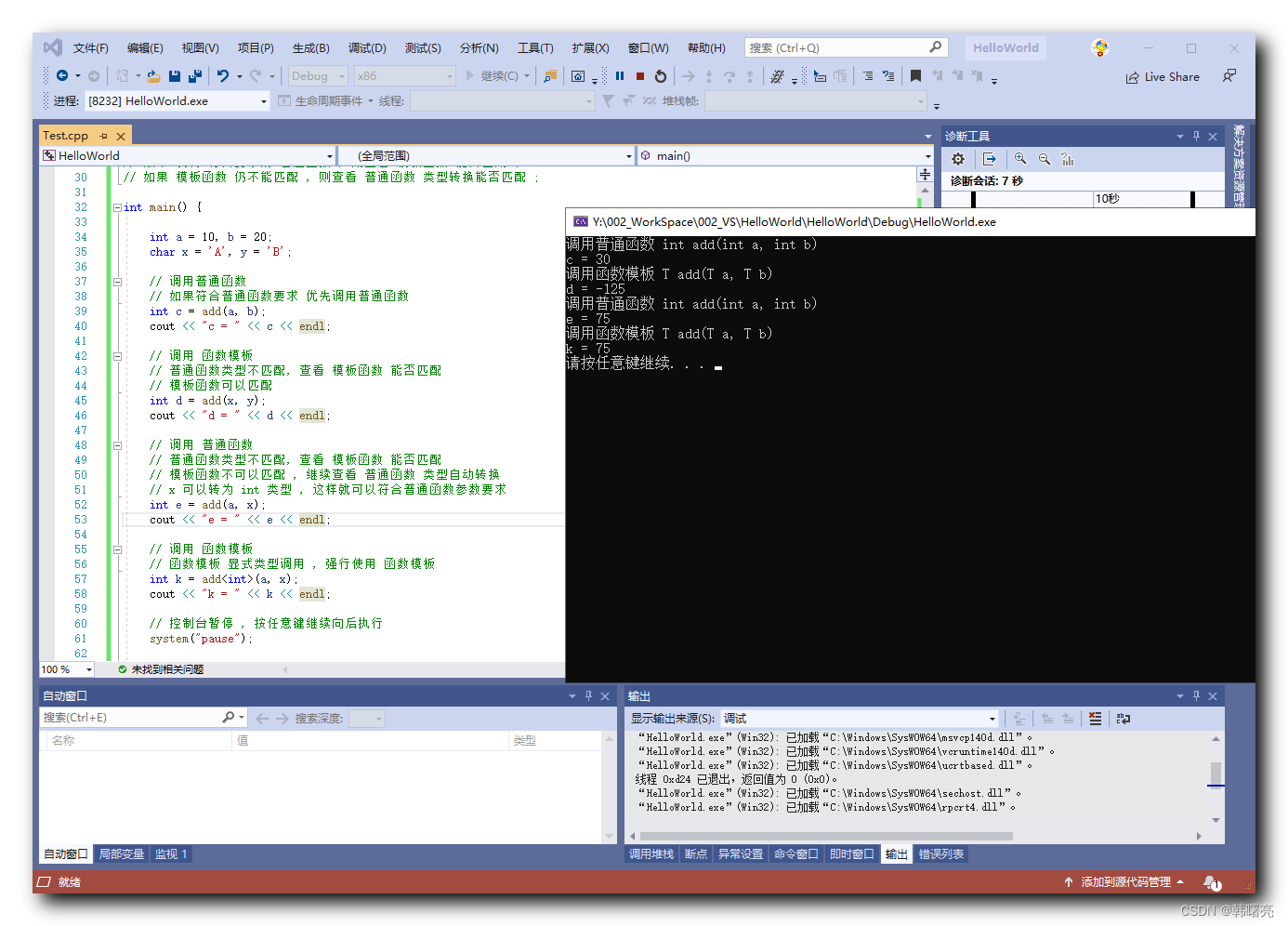
【C++】泛型编程 ④ ( 函数模板 与 普通函数 调用规则 | 类型自动转换 | 类型自动转换 + 显式指定泛型类型 )
文章目录 一、普通函数 与 函数模板 的调用规则 - 类型自动转换1、函数模板和重载函数2、类型自动转换3、代码示例 - 类型自动转换 二、普通函数 与 函数模板 的调用规则 - 类型自动转换 显式指定泛型类型1、类型自动转换 显式指定泛型类型2、代码示例 - 类型自动转换 显式指…...

基于ChatGPT的文本生成艺术框架—WordArt Designer
WordArt Designer是一个基于gpt-3.5 turbo的艺术字生成框架,包含四个关键模块:LLM引擎、SemTypo、Styltypo和TextTypo模块。由gpt-3.5 turbo驱动的LLM引擎可以解释用户输入,从而将抽象概念转化为具体的设计。 SemTypo模块使用语义概念优化字体设计&…...
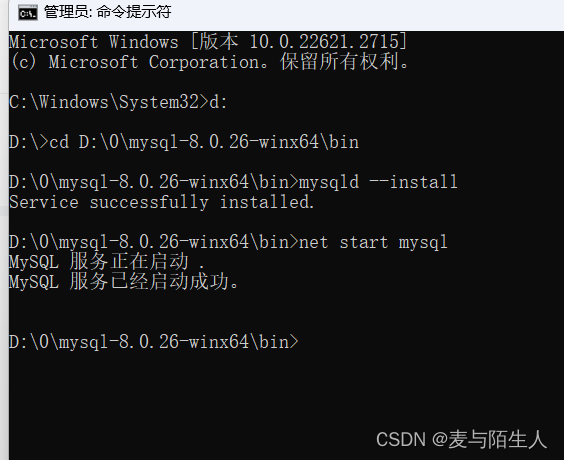
服务名无效。 请键入 NET HELPMSG 2185以获得更多的帮助
遇到的问题是MySQL服务没有。 因为net start 服务名,启动的是win下注册的服务。此时,我系统中并没有注册mysql到服务中。即下面没有mysql服务。 mysqld --install net start mysql...

UE5——C++编译MSB3073报错
报错: C:\Program Files\Microsoft Visual Studio\2022\Professional\MSBuild\Microsoft\VC\v170\Microsoft.MakeFile.Targets(50,5): error MSB3073: 命令“D:\0_Game\EpicGame\UE_5.1\Engine\Build\BatchFiles\Rebuild.bat DigitalVisualizationEditor Win64 Deve…...

自己动手实现一个深度学习算法——六、与学习相关的技巧
文章目录 1.参数的更新1)SGD2)Momentum3)AdaGrad4)Adam5)最优化方法的比较6)基于MNIST数据集的更新方法的比较 2.权重的初始值1)权重初始值不能为02)隐藏层的激活值的分布3ÿ…...

Maven间接依赖
目录 背景 依赖标签 依赖的作用域 Maven仲裁机制 场景示例 多个pom树合并打包...

Java架构师分布式搜索数据准确性解决方案
目录 1 Elasticsearch内置分词器1.1 Standard(标准分词器)1.2 Simple(简单分词器)1.3 Whitespace(空格分词器)1.4 Stop(停止分词器)1.5 Keyword(关键字分词器)1.6 Pattern(模板分词器)1.7 Language(语言分词器)1.8 Fingerprint(指纹分词器)2 Es 模糊查询 match…...

Clickhouse学习笔记
学习内容参考:一套上手ClickHouse-OLAP分析引擎,囊括Prometheus与Grafana_哔哩哔哩_bilibili 下为笔记链接,以及全套笔记pdf版本 Clickhouse学习笔记(1)—— ClickHouse的安装启动_clickhouse后台启动_THE WHY的博客-C…...

vim——“Linux”
各位CSDN的uu们好呀,今天,小雅兰的内容是Linux的开发工具——vim。下面,我们一起进入Linux的世界吧!!! Linux编辑器-vim使用 vim的基本概念 vim的基本操作 vim正常模式命令集 vim末行模式命令集 vim操…...

【QT深入理解】QT中的几种常用的排序函数
第一章:排序函数的概述 排序函数是一种在编程中常用的函数,它可以对一个序列(如数组,列表,向量等)中的元素进行排序,使其按照一定的顺序排列。排序函数可以根据不同的排序算法,如冒…...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...
)
保姆级避坑指南:在Ubuntu 22.04上搞定ROS2 Humble、PX4与Gazebo的联合仿真(附Empy版本降级)
保姆级避坑指南:Ubuntu 22.04下ROS2 Humble与PX4联合仿真的21个关键陷阱当你在Ubuntu 22.04上第一次尝试搭建ROS2 Humble、PX4与Gazebo的联合仿真环境时,可能会遇到比预期更多的挑战。这不是一个简单的"复制粘贴命令就能完成"的任务——版本冲…...

WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件
WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸3》这…...

如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南
如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重新焕发活力&a…...

终极Windows风扇控制指南:FanControl让你的电脑安静又高效
终极Windows风扇控制指南:FanControl让你的电脑安静又高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案
VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网…...

Linux CPU性能优化:D状态和Z状态排查与处理
文章目录一、Linux进程五大基本状态1. 运行状态(R,Running / Runnable)2. 可中断睡眠状态(S,Interruptible Sleep)3. 不可中断睡眠状态(D,Uninterruptible Sleep)4. 停止…...

机器学习在宇宙中微子快味转换检测中的实践:从逻辑回归到天体物理模拟集成
1. 项目概述:当机器学习遇见宇宙深处的“幽灵粒子” 在宇宙最狂暴的舞台——核心坍缩超新星(CCSN)和双中子星并合(NSM)事件的中心,上演着一场肉眼无法观测的微观物理盛宴。这里的主角是中微子,这…...
)
【Sora 2 HDR生成黄金公式】:曝光补偿系数×动态范围压缩阈值×时域一致性权重=可商用HDR帧率(附Python验证脚本)
更多请点击: https://codechina.net 第一章:Sora 2 HDR视频生成黄金公式的提出与商业意义 Sora 2 的HDR视频生成能力不再依赖传统多曝光融合或后期调色管线,而是通过一个端到端可微分的物理感知渲染公式实现原生高动态范围建模。该公式被业界…...