【QT深入理解】QT中的几种常用的排序函数
第一章:排序函数的概述
排序函数是一种在编程中常用的函数,它可以对一个序列(如数组,列表,向量等)中的元素进行排序,使其按照一定的顺序排列。排序函数可以根据不同的排序算法,如冒泡排序,选择排序,插入排序,快速排序,归并排序,堆排序等,实现不同的排序效果。排序函数的作用有以下几点:
- 提高查找效率。当一个序列中的元素是有序的,就可以使用一些高效的查找算法,如二分查找,插值查找,斐波那契查找等,来快速地找到目标元素。
- 方便数据分析。当一个序列中的元素是有序的,就可以方便地进行一些数据分析,如求最大值,最小值,中位数,众数,分位数,频率分布,直方图等。
- 增加数据可读性。当一个序列中的元素是有序的,就可以增加数据的可读性,使其更容易被人理解和比较。
QT是一个跨平台的应用程序开发框架,它提供了一些常用的排序函数,可以对QT中的一些容器类(如QList,QVector,QMap,QSet等)中的元素进行排序。QT中提供的排序函数有以下几种:
- qSort:这是一个通用的排序函数,它使用快速排序算法,可以对任何可随机访问的序列进行排序。它可以指定一个比较函数或者一个比较对象,来自定义排序的规则。它的排序结果是不稳定的,也就是说,如果序列中有相等的元素,它们的相对位置可能会改变。
- qStableSort:这是一个稳定的排序函数,它使用归并排序算法,可以对任何可随机访问的序列进行排序。它可以指定一个比较函数或者一个比较对象,来自定义排序的规则。它的排序结果是稳定的,也就是说,如果序列中有相等的元素,它们的相对位置不会改变。
- qPartialSort:这是一个部分排序函数,它使用堆排序算法,可以对任何可随机访问的序列进行部分排序。它可以指定一个范围,只对序列中的这个范围内的元素进行排序,而不影响其他元素。它可以指定一个比较函数或者一个比较对象,来自定义排序的规则。它的排序结果是不稳定的。
- qHeapSort:这是一个堆排序函数,它使用堆排序算法,可以对任何可随机访问的序列进行排序。它可以指定一个比较函数或者一个比较对象,来自定义排序的规则。它的排序结果是不稳定的。它的特点是,它可以在不使用额外空间的情况下,对序列进行原地排序,也就是说,它不需要创建一个新的序列来存储排序结果,而是直接在原序列上进行操作。
- qLowerBound和qUpperBound:这不是排序函数,而是查找函数,它们可以在一个有序的序列中,查找一个给定的元素的下界和上界。下界是指序列中第一个不小于给定元素的位置,上界是指序列中第一个大于给定元素的位置。它们可以指定一个比较函数或者一个比较对象,来自定义查找的规则。它们的查找效率是对数级别的,也就是说,它们使用二分查找算法,每次查找都可以将查找范围缩小一半。
第二章:qSort函数
qSort函数是QT中提供的一个通用的排序函数,它使用快速排序算法,可以对任何可随机访问的序列进行排序。快速排序算法的基本思想是,选择一个基准元素,将序列分为两个子序列,一个子序列中的元素都小于或等于基准元素,另一个子序列中的元素都大于基准元素,然后对这两个子序列递归地进行快速排序,最后将两个子序列合并成一个有序的序列。快速排序算法的平均时间复杂度是O(nlogn),最坏情况下的时间复杂度是O(n^2),空间复杂度是O(logn)。
qSort函数的函数原型如下
template <typename RandomAccessIterator>
void qSort(RandomAccessIterator begin, RandomAccessIterator end);template <typename RandomAccessIterator, typename LessThan>
void qSort(RandomAccessIterator begin, RandomAccessIterator end, LessThan lessThan);
qSort函数的功能参数
对从begin到end(不包括end)的元素进行排序。
第一个参数begin是指向序列开始位置的迭代器
第二个参数end是指向序列结束位置的迭代器
第三个参数lessThan是一个比较函数或者一个比较对象,它可以自定义排序的规则,它接受两个元素作为参数,返回一个布尔值,表示第一个元素是否小于第二个元素。如果没有指定第三个参数,qSort函数会使用默认的比较规则,即使用元素的<运算符进行比较。
qSort函数的用法示例
- 如果要对一个数组进行排序,可以直接传入数组的首地址和尾地址作为参数,例如:
int arr[] = {5, 3, 7, 1, 9, 4, 6, 8, 2};
qSort(arr, arr + 9); // 对arr数组进行升序排序
- 如果要对一个QList或者QVector进行排序,可以使用它们的begin()和end()方法来获取迭代器,例如:
QList<int> list;
list << 5 << 3 << 7 << 1 << 9 << 4 << 6 << 8 << 2;
qSort(list.begin(), list.end()); // 对list进行升序排序
- 如果要对一个QMap或者QSet进行排序,可以使用它们的keys()或者values()方法来获取一个QList,然后对QList进行排序,例如:
QMap<QString, int> map;
map["Alice"] = 90;
map["Bob"] = 80;
map["Charlie"] = 85;
map["David"] = 95;
QList<QString> names = map.keys(); // 获取map的键的列表
qSort(names.begin(), names.end()); // 对names进行升序排序
- 如果要自定义排序的规则,可以传入一个比较函数或者一个比较对象作为第三个参数,例如:
// 定义一个比较函数,按照字符串的长度进行比较
bool compareByLength(const QString &a, const QString &b)
{return a.length() < b.length();
}// 定义一个比较对象,按照学生的成绩进行比较
struct compareByScore
{bool operator()(const Student &a, const Student &b){return a.score > b.score; // 降序排序}
};QList<QString> words;
words << "apple" << "banana" << "orange" << "pear" << "grape";
qSort(words.begin(), words.end(), compareByLength); // 按照单词的长度进行升序排序QList<Student> students;
students << Student("Alice", 90) << Student("Bob", 80) << Student("Charlie", 85) << Student("David", 95);
qSort(students.begin(), students.end(), compareByScore()); // 按照学生的成绩进行降序排序
qSort函数注意事项
- begin和end必须指向同一个序列,否则会导致未定义的行为。
- begin和end之间的元素必须能够被交换,否则会导致编译错误。
- begin和end之间的元素必须能够被比较,否则会导致编译错误或者运行时错误。
- lessThan必须是一个严格弱序关系,也就是说,它必须满足以下条件:
- 对于任何元素x,lessThan(x, x)必须返回false。
- 如果lessThan(x, y)返回true,那么lessThan(y, x)必须返回false。
- 如果lessThan(x, y)和lessThan(y, z)都返回true,那么lessThan(x, z)也必须返回true。
- qSort函数的排序结果是不稳定的,也就是说,如果序列中有相等的元素(即lessThan(x, y)和lessThan(y, x)都返回false),它们的相对位置可能会改变。
以上就是qSort函数的介绍,下面我们将介绍qStableSort函数。
第三章:qStableSort函数
qStableSort函数是QT中提供的一个稳定的排序函数,它使用归并排序算法,可以对任何可随机访问的序列进行排序。归并排序算法的基本思想是,将序列分为两个子序列,对这两个子序列分别进行归并排序,然后将两个有序的子序列合并成一个有序的序列。归并排序算法的时间复杂度是O(nlogn),空间复杂度是O(n)。
qStableSort函数的函数原型如下
template <typename RandomAccessIterator>
void qStableSort(RandomAccessIterator begin, RandomAccessIterator end);template <typename RandomAccessIterator, typename LessThan>
void qStableSort(RandomAccessIterator begin, RandomAccessIterator end, LessThan lessThan);
qStableSort函数的功能参数
对从begin到end(不包括end)的元素进行排序
第一个参数begin是指向序列开始位置的迭代器
第二个参数end是指向序列结束位置的迭代器
第三个参数lessThan是一个比较函数或者一个比较对象,它可以自定义排序的规则,它接受两个元素作为参数,返回一个布尔值,表示第一个元素是否小于第二个元素。如果没有指定第三个参数,qStableSort函数会使用默认的比较规则,即使用元素的<运算符进行比较。
qStableSort函数的用法示例
qStableSort函数的用法和qSort函数的用法基本相同,只是qStableSort函数的排序结果是稳定的,也就是说,如果序列中有相等的元素(即lessThan(x, y)和lessThan(y, x)都返回false),它们的相对位置不会改变。这一点在一些场景中是很重要的,例如,如果要对一个学生的列表按照姓名进行排序,然后再按照成绩进行排序,如果使用qSort函数,那么姓名相同的学生的成绩顺序可能会被打乱,而如果使用qStableSort函数,那么姓名相同的学生的成绩顺序会保持不变。
代码示例:
#include <QList>
#include <QString>
#include <QDebug>// 定义一个学生类,包含姓名和成绩两个属性
class Student
{
public:Student(const QString &name, int score) : name(name), score(score) {}QString name; // 姓名int score; // 成绩
};// 定义一个比较函数,按照姓名进行升序排序
bool compareByName(const Student &a, const Student &b)
{return a.name < b.name;
}// 定义一个比较函数,按照成绩进行降序排序
bool compareByScore(const Student &a, const Student &b)
{return a.score > b.score;
}// 创建一个学生的列表QList<Student> students;students << Student("Alice", 90) << Student("Bob", 80) << Student("Charlie", 85) << Student("David", 95) << Student("Alice", 88) << Student("Bob", 82);// 使用qStableSort函数按照姓名进行排序qStableSort(students.begin(), students.end(), compareByName);// 打印排序后的结果qDebug() << "Sorted by name:";for (const Student &s : students){qDebug() << s.name << s.score;}// 使用qStableSort函数按照成绩进行排序qStableSort(students.begin(), students.end(), compareByScore);// 打印排序后的结果qDebug() << "Sorted by score:";for (const Student &s : students){qDebug() << s.name << s.score;}运行这段代码,可以得到以下输出:
Sorted by name:
Alice 90
Alice 88
Bob 80
Bob 82
Charlie 85
David 95
Sorted by score:
David 95
Alice 90
Alice 88
Charlie 85
Bob 82
Bob 80
可以看到,qStableSort函数的排序结果是稳定的,也就是说,姓名相同的学生的成绩顺序没有改变,而是保持了原来的顺序。这样就可以方便地对数据进行分组或者分析。
qStableSort函数注意事项
- begin和end必须指向同一个序列,否则会导致未定义的行为。
- begin和end之间的元素必须能够被交换,否则会导致编译错误。
- begin和end之间的元素必须能够被比较,否则会导致编译错误或者运行时错误。
- lessThan必须是一个严格弱序关系,也就是说,它必须满足以下条件:
- 对于任何元素x,lessThan(x, x)必须返回false。
- 如果lessThan(x, y)返回true,那么lessThan(y, x)必须返回false。
- 如果lessThan(x, y)和lessThan(y, z)都返回true,那么lessThan(x, z)也必须返回true。
- qStableSort函数的排序结果是稳定的,也就是说,如果序列中有相等的元素,它们的相对位置不会改变。
以上就是qStableSort函数的介绍,下面我们将介绍qPartialSort函数
第四章:qPartialSort函数
qPartialSort函数是QT中提供的一个部分排序函数,它使用堆排序算法,可以对任何可随机访问的序列进行部分排序。堆排序算法的基本思想是,将序列视为一个完全二叉树,然后构建一个最大堆或者最小堆,也就是说,每个节点的值都大于或者小于它的子节点的值。然后,将堆的根节点(也就是最大或者最小的元素)与堆的最后一个节点交换,然后将堆的大小减一,再调整堆的结构,重复这个过程,直到堆的大小等于指定的范围。堆排序算法的时间复杂度是O(nlogn),空间复杂度是O(1)。
qPartialSort函数的函数原型
template <typename RandomAccessIterator>
void qPartialSort(RandomAccessIterator begin, RandomAccessIterator middle, RandomAccessIterator end);template <typename RandomAccessIterator, typename LessThan>
void qPartialSort(RandomAccessIterator begin, RandomAccessIterator middle, RandomAccessIterator end, LessThan lessThan);
qPartialSort函数的功能参数
对从begin到end(不包括end)的元素进行部分排序,使得从begin到middle(不包括middle)的元素是最小的或者最大的,而且是有序的,而从middle到end的元素是无序的。
第一个参数begin是指向序列开始位置的迭代器
第二个参数middle是指向序列中间位置的迭代器
第三个参数end是指向序列结束位置的迭代器
第四个参数lessThan是一个比较函数或者一个比较对象,它可以自定义排序的规则,它接受两个元素作为参数,返回一个布尔值,表示第一个元素是否小于第二个元素。如果没有指定第四个参数,qPartialSort函数会使用默认的比较规则,即使用元素的<运算符进行比较。
qPartialSort函数的用法示例
- 如果要对一个数组进行部分排序,可以直接传入数组的首地址,中间地址和尾地址作为参数,例如:
int arr[] = {5, 3, 7, 1, 9, 4, 6, 8, 2};
qPartialSort(arr, arr + 3, arr + 9); // 对arr数组进行部分排序,使得前三个元素是最小的,并且是有序的
- 如果要对一个QList或者QVector进行部分排序,可以使用它们的begin()和end()方法来获取迭代器,例如:
QList<int> list;
list << 5 << 3 << 7 << 1 << 9 << 4 << 6 << 8 << 2;
qPartialSort(list.begin(), list.begin() + 3, list.end()); // 对list进行部分排序,使得前三个元素是最小的,并且是有序的
- 如果要对一个QMap或者QSet进行部分排序,可以使用它们的keys()或者values()方法来获取一个QList,然后对QList进行部分排序,例如:
QMap<QString, int> map;
map["Alice"] = 90;
map["Bob"] = 80;
map["Charlie"] = 85;
map["David"] = 95;
QList<int> scores = map.values(); // 获取map的值的列表
qPartialSort(scores.begin(), scores.begin() + 2, scores.end()); // 对scores进行部分排序,使得前两个元素是最小的,并且是有序的
- 如果要自定义排序的规则,可以传入一个比较函数或者一个比较对象作为第四个参数,例如:
// 定义一个比较函数,按照字符串的长度进行比较
bool compareByLength(const QString &a, const QString &b)
{return a.length() < b.length();
}// 定义一个比较对象,按照学生的成绩进行比较
struct compareByScore
{bool operator()(const Student &a, const Student &b){return a.score > b.score; // 降序排序}
};QList<QString> words;
words << "apple" << "banana" << "orange" << "pear" << "grape";
qPartialSort(words.begin(), words.begin() + 2, words.end(), compareByLength); // 按照单词的长度进行部分排序,使得前两个元素是最短的,并且是有序的QList<Student> students;
students << Student("Alice", 90) << Student("Bob", 80) << Student("Charlie", 85) << Student("David", 95);
qPartialSort(students.begin(), students.begin() + 2, students.end(), compareByScore()); // 按照学生的成绩进行部分排序,使得前两个元素是最高的,并且是有序的
qPartialSort函数注意事项
- begin,middle和end必须指向同一个序列,否则会导致未定义的行为。
- begin,middle和end之间的元素必须能够被交换,否则会导致编译错误。
- begin,middle和end之间的元素必须能够被比较,否则会导致编译错误或者运行时错误。
- lessThan必须是一个严格弱序关系,也就是说,它必须满足以下条件:
- 对于任何元素x,lessThan(x, x)必须返回false。
- 如果lessThan(x, y)返回true,那么lessThan(y, x)必须返回false。
- 如果lessThan(x, y)和lessThan(y, z)都返回true,那么lessThan(x, z)也必须返回true。
- qPartialSort函数的排序结果是不稳定的,也就是说,如果序列中有相等的元素,它们的相对位置可能会改变。
以上就是qPartialSort函数的介绍,下面我们将介绍qHeapSort函数。
第五章:qHeapSort函数
qHeapSort函数是QT中提供的一个堆排序函数,它使用堆排序算法,可以对任何可随机访问的序列进行排序。堆排序算法的基本思想是,将序列视为一个完全二叉树,然后构建一个最大堆或者最小堆,也就是说,每个节点的值都大于或者小于它的子节点的值。然后,将堆的根节点(也就是最大或者最小的元素)与堆的最后一个节点交换,然后将堆的大小减一,再调整堆的结构,重复这个过程,直到堆的大小为零。堆排序算法的时间复杂度是O(nlogn),空间复杂度是O(1)。
qHeapSort函数的函数原型
template <typename RandomAccessIterator>
void qHeapSort(RandomAccessIterator begin, RandomAccessIterator end);template <typename RandomAccessIterator, typename LessThan>
void qHeapSort(RandomAccessIterator begin, RandomAccessIterator end, LessThan lessThan);
qHeapSort函数的功能是参数
对从begin到end(不包括end)的元素进行排序。
第一个参数begin是指向序列开始位置的迭代器
第二个参数end是指向序列结束位置的迭代器
第三个参数lessThan是一个比较函数或者一个比较对象,它可以自定义排序的规则,它接受两个元素作为参数,返回一个布尔值,表示第一个元素是否小于第二个元素。如果没有指定第三个参数,qHeapSort函数会使用默认的比较规则,即使用元素的<运算符进行比较。
qHeapSort函数的用法示例
qSort函数的用法基本相同,只是qHeapSort函数的特点是,它可以在不使用额外空间的情况下,对序列进行原地排序,也就是说,它不需要创建一个新的序列来存储排序结果,而是直接在原序列上进行操作。这样就可以节省空间,提高效率。
代码示例:
#include <QList>
#include <QString>
#include <QDebug>// 定义一个学生类,包含姓名和成绩两个属性
class Student
{
public:Student(const QString &name, int score) : name(name), score(score) {}QString name; // 姓名int score; // 成绩
};// 定义一个比较函数,按照姓名进行升序排序
bool compareByName(const Student &a, const Student &b)
{return a.name < b.name;
}// 定义一个比较函数,按照成绩进行降序排序
bool compareByScore(const Student &a, const Student &b)
{return a.score > b.score;
}// 创建一个学生的列表QList<Student> students;students << Student("Alice", 90) << Student("Bob", 80) << Student("Charlie", 85) << Student("David", 95);// 使用qHeapSort函数按照姓名进行排序qHeapSort(students.begin(), students.end(), compareByName);// 打印排序后的结果qDebug() << "Sorted by name:";for (const Student &s : students){qDebug() << s.name << s.score;}// 使用qHeapSort函数按照成绩进行排序qHeapSort(students.begin(), students.end(), compareByScore);// 打印排序后的结果qDebug() << "Sorted by score:";for (const Student &s : students){qDebug() << s.name << s.score;}运行这段代码,可以得到以下输出:
Sorted by name:
Alice 90
Bob 80
Charlie 85
David 95
Sorted by score:
David 95
Alice 90
Charlie 85
Bob 80
可以看到,qHeapSort函数的排序结果是不稳定的,也就是说,姓名相同的学生的成绩顺序可能会改变,而且它可以在不使用额外空间的情况下,对序列进行原地排序,也就是说,它不需要创建一个新的序列来存储排序结果,而是直接在原序列上进行操作。
qHeapSort函数的注意事项
- begin和end必须指向同一个序列,否则会导致未定义的行为。
- begin和end之间的元素必须能够被交换,否则会导致编译错误。
- begin和end之间的元素必须能够被比较,否则会导致编译错误或者运行时错误。
- lessThan必须是一个严格弱序关系,也就是说,它必须满足以下条件:
- 对于任何元素x,lessThan(x, x)必须返回false。
- 如果lessThan(x, y)返回true,那么lessThan(y, x)必须返回false。
- 如果lessThan(x, y)和lessThan(y, z)都返回true,那么lessThan(x, z)也必须返回true。
- qHeapSort函数的排序结果是不稳定的,也就是说,如果序列中有相等的元素,它们的相对位置可能会改变。
以上就是qHeapSort函数的介绍,下面我们将介绍qLowerBound和qUpperBound函数。
第六章:qLowerBound和qUpperBound函数
qLowerBound和qUpperBound函数是QT中提供的两个查找函数,它们可以在一个有序的序列中,查找一个给定的元素的下界和上界。下界是指序列中第一个不小于给定元素的位置,上界是指序列中第一个大于给定元素的位置。它们可以指定一个比较函数或者一个比较对象,来自定义查找的规则。它们的查找效率是对数级别的,也就是说,它们使用二分查找算法,每次查找都可以将查找范围缩小一半。
qLowerBound和qUpperBound函数的函数原型
template <typename ForwardIterator, typename T>
ForwardIterator qLowerBound(ForwardIterator begin, ForwardIterator end, const T &value);template <typename ForwardIterator, typename T, typename LessThan>
ForwardIterator qLowerBound(ForwardIterator begin, ForwardIterator end, const T &value, LessThan lessThan);template <typename ForwardIterator, typename T>
ForwardIterator qUpperBound(ForwardIterator begin, ForwardIterator end, const T &value);template <typename ForwardIterator, typename T, typename LessThan>
ForwardIterator qUpperBound(ForwardIterator begin, ForwardIterator end, const T &value, LessThan lessThan);
qLowerBound和qUpperBound函数的功能和参数
分别在从begin到end(不包括end)的元素中,查找value的下界和上界。
第一个参数begin是指向序列开始位置的迭代器
第二个参数end是指向序列结束位置的迭代器
第三个参数value是要查找的元素
第四个参数lessThan是一个比较函数或者一个比较对象,它可以自定义查找的规则,它接受两个元素作为参数,返回一个布尔值,表示第一个元素是否小于第二个元素。如果没有指定第四个参数,qLowerBound和qUpperBound函数会使用默认的比较规则,即使用元素的<运算符进行比较。
qLowerBound和qUpperBound函数的用法示例
- 如果要在一个数组中查找一个元素的下界和上界,可以直接传入数组的首地址和尾地址作为参数,例如:
int arr[] = {1, 2, 3, 3, 3, 4, 5};
int *lower = qLowerBound(arr, arr + 7, 3); // 查找3的下界
int *upper = qUpperBound(arr, arr + 7, 3); // 查找3的上界
qDebug() << "Lower bound of 3 is" << lower - arr; // 输出3的下界的索引
qDebug() << "Upper bound of 3 is" << upper - arr; // 输出3的上界的索引
- 如果要在一个QList或者QVector中查找一个元素的下界和上界,可以使用它们的begin()和end()方法来获取迭代器,例如:
QList<int> list;
list << 1 << 2 << 3 << 3 << 3 << 4 << 5;
QList<int>::iterator lower = qLowerBound(list.begin(), list.end(), 3); // 查找3的下界
QList<int>::iterator upper = qUpperBound(list.begin(), list.end(), 3); // 查找3的上界
qDebug() << "Lower bound of 3 is" << lower - list.begin(); // 输出3的下界的索引
qDebug() << "Upper bound of 3 is" << upper - list.begin(); // 输出3的上界的索引
- 如果要在一个QMap或者QSet中查找一个元素的下界和上界,可以使用它们的keys()或者values()方法来获取一个QList,然后在QList中查找,例如:
QMap<QString, int> map;
map["Alice"] = 90;
map["Bob"] = 80;
map["Charlie"] = 85;
map["David"] = 95;
QList<int> scores = map.values(); // 获取map的值的列表
qSort(scores.begin(), scores.end()); // 对scores进行排序
QList<int>::iterator lower = qLowerBound(scores.begin(), scores.end(), 85); // 查找85的下界
QList<int>::iterator upper = qUpperBound(scores.begin(), scores.end(), 85); // 查找85的上界
qDebug() << "Lower bound of 85 is" << lower - scores.begin(); // 输出85的下界的索引
qDebug() << "Upper bound of 85 is" << upper - scores.begin(); // 输出85的上界的索引第七章:总结
本文介绍了QT中的几种常用的排序函数,包括qSort,qStableSort,qPartialSort,qHeapSort,qLowerBound和qUpperBound,它们可以对QT中的一些容器类中的元素进行排序或者查找。
下面我们将比较一下不同排序函数的优缺点,以及给出一些使用建议:
- qSort函数是一个通用的排序函数,它使用快速排序算法,可以对任何可随机访问的序列进行排序。它的优点是,它的平均时间复杂度是O(nlogn),空间复杂度是O(logn),效率较高。它的缺点是,它的最坏情况下的时间复杂度是O(n^2),效率较低。另外,它的排序结果是不稳定的,也就是说,如果序列中有相等的元素,它们的相对位置可能会改变。因此,如果要对一个序列进行排序,可以使用qSort函数,但是要注意避免最坏情况的发生,以及考虑是否需要保持元素的相对位置。
- qStableSort函数是一个稳定的排序函数,它使用归并排序算法,可以对任何可随机访问的序列进行排序。它的优点是,它的时间复杂度是O(nlogn),效率较高。另外,它的排序结果是稳定的,也就是说,如果序列中有相等的元素,它们的相对位置不会改变。这一点在一些场景中是很重要的,例如,如果要对一个学生的列表按照姓名进行排序,然后再按照成绩进行排序,如果使用qSort函数,那么姓名相同的学生的成绩顺序可能会被打乱,而如果使用qStableSort函数,那么姓名相同的学生的成绩顺序会保持不变。它的缺点是,它的空间复杂度是O(n),需要额外的空间来存储排序结果。因此,如果要对一个序列进行排序,而且需要保持元素的相对位置,可以使用qStableSort函数,但是要注意空间的消耗。
- qPartialSort函数是一个部分排序函数,它使用堆排序算法,可以对任何可随机访问的序列进行部分排序。它的优点是,它可以指定一个范围,只对序列中的这个范围内的元素进行排序,而不影响其他元素。这样就可以节省时间,提高效率。它的缺点是,它的排序结果是不稳定的,也就是说,如果序列中有相等的元素,它们的相对位置可能会改变。另外,它的时间复杂度是O(nlogn),空间复杂度是O(1),效率和空间都不是最优的。因此,如果要对一个序列进行部分排序,可以使用qPartialSort函数,但是要注意元素的相对位置,以及是否有更好的算法。
- qHeapSort函数是一个堆排序函数,它使用堆排序算法,可以对任何可随机访问的序列进行排序。它的优点是,它可以在不使用额外空间的情况下,对序列进行原地排序,也就是说,它不需要创建一个新的序列来存储排序结果,而是直接在原序列上进行操作。这样就可以节省空间,提高效率。它的缺点是,它的排序结果是不稳定的,也就是说,如果序列中有相等的元素,它们的相对位置可能会改变。另外,它的时间复杂度是O(nlogn),空间复杂度是O(1),效率和空间都不是最优的。因此,如果要对一个序列进行排序,而且不需要保持元素的相对位置,也不需要额外的空间,可以使用qHeapSort函数,但是要注意是否有更好的算法。
- qLowerBound和qUpperBound函数是两个查找函数,它们可以在一个有序的序列中,查找一个给定的元素的下界和上界。它们的优点是,它们的查找效率是对数级别的,也就是说,它们使用二分查找算法,每次查找都可以将查找范围缩小一半。这样就可以快速地找到目标元素。它们的缺点是,它们的查找结果是一个迭代器,它可以用来访问或者修改序列中的元素,也可以用来计算元素的位置或者个数,但是它不能直接用来判断元素是否存在于序列中,也不能直接用来获取元素的值。因此,如果要在一个有序的序列中,查找一个给定的元素的下界和上界,可以使用qLowerBound和qUpperBound函数,但是要注意如何使用查找结果。
相关文章:

【QT深入理解】QT中的几种常用的排序函数
第一章:排序函数的概述 排序函数是一种在编程中常用的函数,它可以对一个序列(如数组,列表,向量等)中的元素进行排序,使其按照一定的顺序排列。排序函数可以根据不同的排序算法,如冒…...

自压缩llm 为 超长记忆
自压缩llm 为 超长记忆 解释数据处理实际例子解释 # 自压缩llm 为 超长记忆 # prompt 格式 # <|细颗粒词表|><|粗颗粒词表|><|细颗粒词表|> # 细颗粒词表 = 词1,词2,词3,词4,词5,词6,词7,词8,词9,词10, # 组颗粒词表id1, 组颗粒词表id2, 组颗粒…...

Perl的LWP::UserAgent库爬虫程序怎么写
Perl的LWP::UserAgent库是一个用于发送HTTP请求的Perl模块。它可以用于编写Web爬虫、测试Web应用程序、自动化Web操作等。以下是一个简单的使用LWP::UserAgent库发送HTTP GET请求的Perl脚本的例子: #!/usr/bin/perluse strict; use warnings; use LWP::UserAgent;# …...

【算法】算法题-20231116
这里写目录标题 一、合并两个有序数组(力扣88 )二、剑指 Offer 39. 数组中出现次数超过一半的数字三、移除元素(力扣27)四、找出字符串中第一个匹配项的下标(28) 一、合并两个有序数组(力扣88 &…...
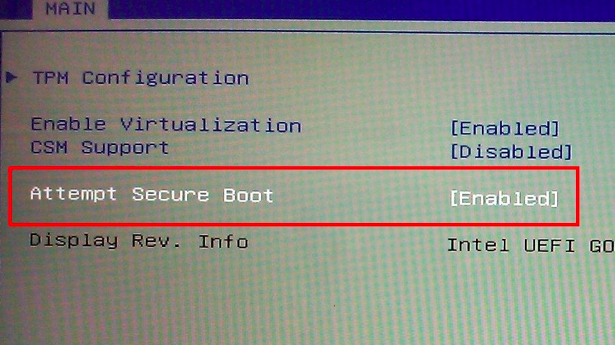
微软允许OEM对Win10不提供关闭Secure Boot
用户可能将无法在Windows 10电脑上安装其它操作系统了,微软不再要求OEM在UEFI 中提供的“关闭 Secure Boot”的选项。 微软最早是在Designed for Windows 8认证时要求OEM的产品必须支持UEFI Secure Boot。Secure Boot 被设计用来防止恶意程序悄悄潜入到引导进程。问…...

海康G5系列(armv7l) heop模式下交叉编译Qt qmqtt demo,出现moc缺少高版本GLibc问题之解决
1.编辑源 sudo vi /etc/apt/sources.list 2.添加高版本的源 deb http://th.archive.ubuntu.com/ubuntu jammy main #添加该行到文件 3.运行升级 sudo apt update sudo apt install libc6 4.strings /**/libc.so.6 |grep GLIBC_ 参考链接:version GLIBC_2.3…...

gRPC协议详解
gRPC介绍 gRPC是一个高性能、开源和通用的RPC(远程过程调用)框架,由Google发起并开发,于2015年对外发布。它基于HTTP/2协议和Protocol Buffers设计,支持多种编程语言(如C、Java、Python、Go、Ruby、C#、No…...

虹科方案 | 从概念到生产的自动驾驶软件在环(SiL)测试解决方案
来源:雅名特自动驾驶 虹科方案 | 从概念到生产的自动驾驶软件在环(SiL)测试解决方案 自动驾驶软件在环(SiL)测试解决方案 自动驾驶软件在环(SiL)测试解决方案能够研究和验证高历程实验和恶劣驾…...

demo(二)eurekaribbon----服务注册、提供与消费
前一篇实现了服务注册中心的搭建,并提供服务注册到注册中心上。在之前的基础上,实现服务消费。 一、相关介绍 1、RestTemplate工具 2、LoadBalanced注解 二、ribbon示例: 先启动eureka-service注册中心,再将eureka-client修改…...

2023年09月 Python(五级)真题解析#中国电子学会#全国青少年软件编程等级考试
Python等级考试(1~6级)全部真题・点这里 一、单选题(共25题,每题2分,共50分) 第1题 阅读以下代码,程序输出结果正确的选项是?( ) def process_keywords(keywords_list):unique_keywords = list(set(keywords_list))...

python3.8 安装 ssl 模块 和 _ctypes 模块
这文章目录 前情提要安装 openssl-1.1.1重新编译安装 python3.8-rpath 编译选项介绍python3.8 跟 python3.10 的区别那要怎么解决这个问题呢,我想到有四种解决方案: 前情提要 我在之前给 python3.10 安装 ssl 模块后以为该步骤 “对于 python3.6、pytho…...

阿里云99元ECS云服务器老用户也能买,续费同价!
阿里云近日宣布了2023年的服务器优惠活动,令用户们振奋不已。最引人瞩目的消息是,阿里云放开了老用户的购买资格,99元服务器也可以供老用户购买,并且享受续费的99元优惠。此外,阿里云还推出了ECS经济型e实例࿰…...
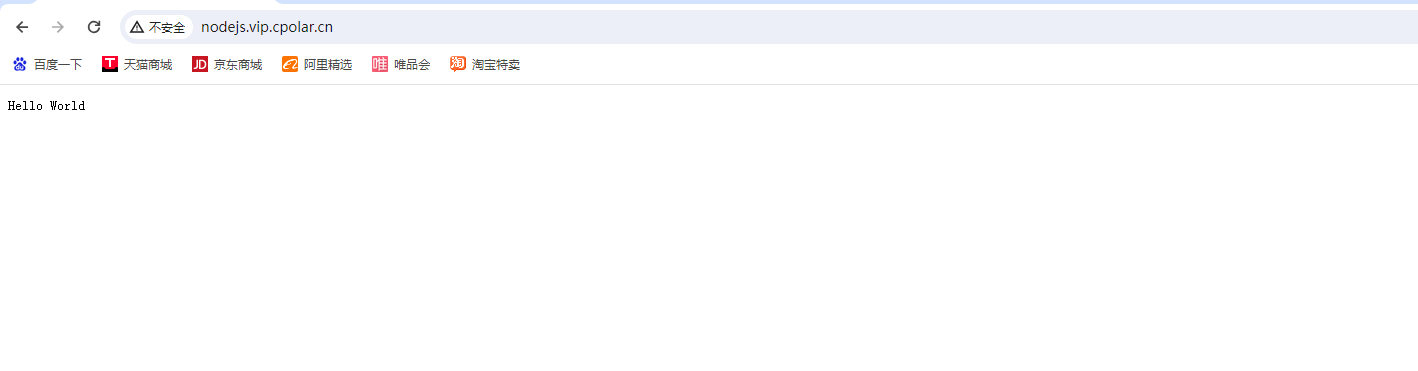
如何使用内网穿透实现远程公网访问windows node.js的服务端
使用Nodejs搭建简单的web网页并实现公网访问 前言 Node.js是建立在谷歌Chrome的JavaScript引擎(V8引擎)的Web应用程序框架。 Node.js自带运行时环境可在Javascript脚本的基础上可以解释和执行(这类似于JVM的Java字节码)。这个运行时允许在浏览器以外的任何机器上执行JavaScri…...
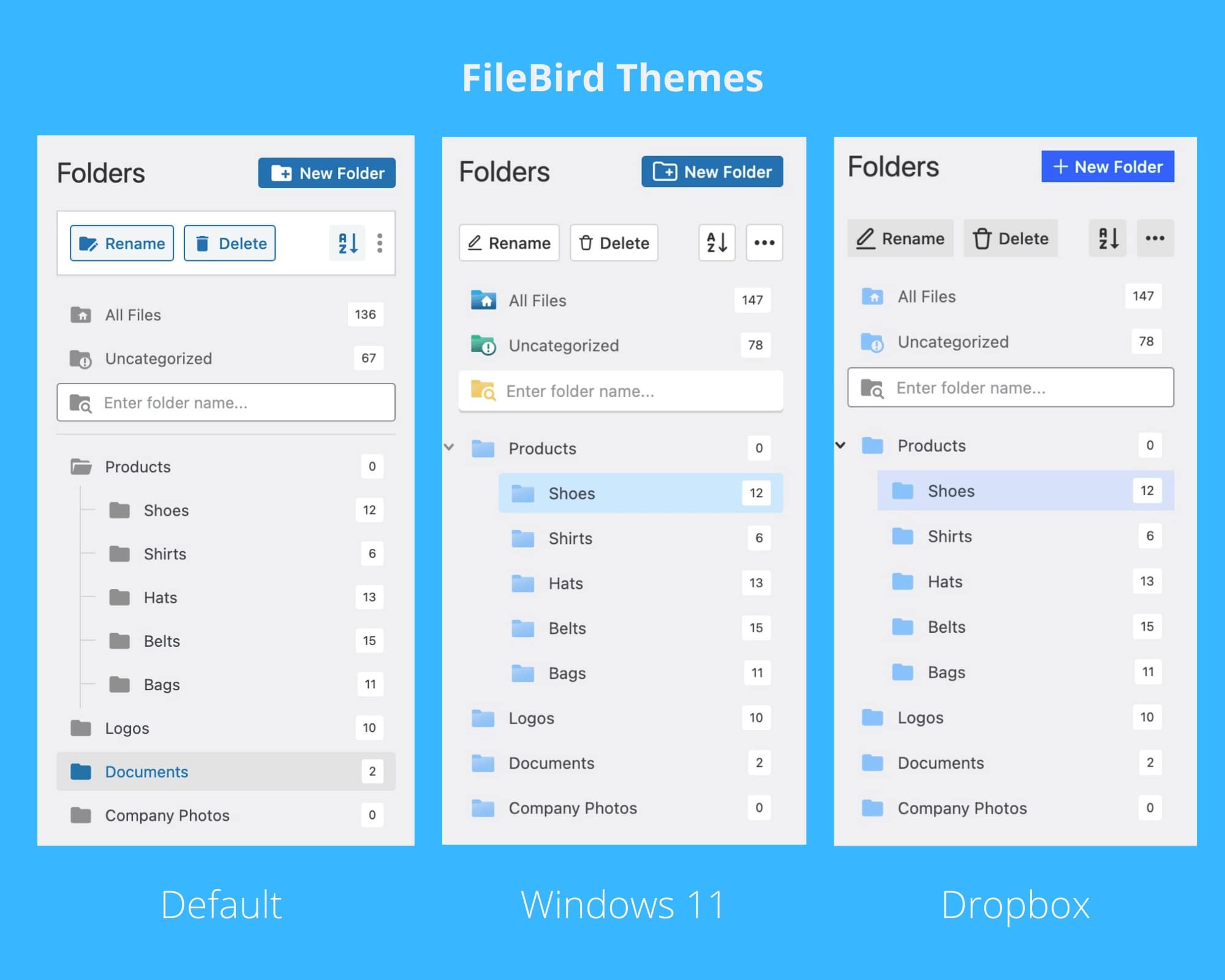
WordPress 媒体库文件夹管理插件 FileBird v5.5.4和谐版下载
FileBird是一款WordPress 按照文件夹管理方式的插件。 拖放界面 拖放功能现已成为现代软件和网站的标配。本机拖动事件(包括仅在刀片中将文件移动到文件夹以及将文件夹移动到文件夹)极大地减少了完成任务所需的点击次数。 一流设计的文件夹树展示 我们…...
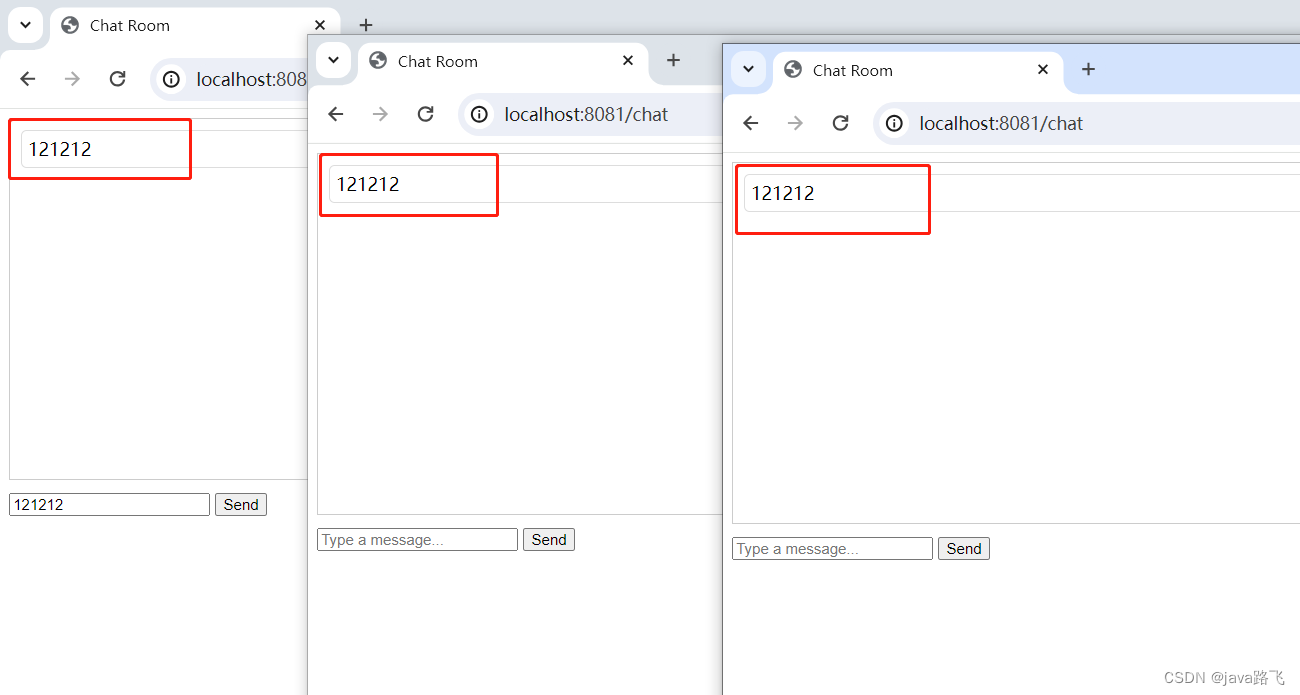
websocket学习笔记【springboot+websocket聊天室demo】
文章目录 WebSocket是什么?为什么需要WebSocket?WebSocket和Http连接的区别WebSocket的工作原理基本交互过程: Java中的WebSocket支持WebSocket的优势springboot websocket themlef 一个聊天室demopom.xmlWebSocketConfigChatControllerWebController…...
echarts:graph图表拖拽节点
需求:实现一个可视化编辑器,用户可以添加节点,并对节点进行拖拽编辑,线条要用折线而不是用自带的直线 实现期间碰到很多问题,特意记录下来,留待将来碰到这些问题的同学,省去些解决问题的时间 问…...

Unity地面交互效果目录
大家好,我是阿赵。 之前写了几篇关于地形交互、地面轨迹、脚印效果实现的博文。虽然写的篇数不多,但里面也包含了不少基础知识,比如局部UV采样、法线动态混合、曲面细分等知识,这些都是可以和别的效果组合在一起,做…...

tcp的1对多模型C++处理逻辑
连接多个设备进行TCP连接,可以采取以下策略: 创建一个设备连接管理器:使用一个类或结构体来管理每个设备的连接。这个管理器应该包含设备的IP地址和端口号,以及一个连接到该设备的TCP连接。使用并发连接:使用并发的方式同时连接到所有设备。可以使用多线程或异步编程技术来…...
)
【Python】基础(学习笔记)
一、Python介绍 1、Python优点 学习成本低 开源 适应⼈群⼴泛 应⽤领域⼴泛 2、Python解释器 Python解释器作用:运行Python文件 Python解释器分类 CPython:C语⾔开发的解释器[官⽅],应⽤⼴泛的解释器。 IPython:基于CPyth…...
)
目标检测YOLO实战应用案例100讲-基于改进YOLO v5的排水管网缺陷智能识别(续)
目录 3.3构建方法 3.3.1样本库框架 3.3.2总体流程 3.3.3图像获取 3.3.4质量控制 3.3.5数据扩增...

Jetson Orin Nano 升级jetpack5.1.2刷机过程记录
一.刷机起因 orin nano 接了个IMX477的摄像头,用 命令行DISPLAY:0.0 nvgstcapture-1.0 显示的画面有撕裂,让卖家查问题,卖家测试没有撕裂,对比环境,orin nano出厂默认的是jetpack5.1.1,卖家用的jetpack5.1.2版本,为了解决差异,要升级jetpack版本,前后搞了2天半,记录一下. 另外…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗
如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗 【免费下载链接】react-native-bottom-sheet-behavior react-native wrapper for android BottomSheetBehavior 项目地址: https://gitcode.com/gh_mirrors/re/react-native-bottom…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

UE5项目打包后RenderTarget导出图片全黑?手把手教你解决伽马校正与资产打包问题
UE5打包后RenderTarget导出图片全黑的终极解决方案当你花了整整三天时间调试RenderTarget导出功能,终于在编辑器里看到完美的截图效果,却在打包成可执行文件后发现所有导出的图片都变成了一片漆黑——这种从云端跌入谷底的感觉,每个UE开发者都…...

从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法
从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法在MOBA游戏中,野怪沿着固定路线巡逻时突然转向追击玩家;RTS战场上,上百个单位向同一目标点移动却能保持整齐队形;潜行游戏中&…...

国产大模型新王登基?Qwen3.7-Max全球第五、编程Agent登顶,千问APP免费体验全攻略
AI前线观察 | 2026.05.25 就在刚刚过去的阿里云峰会上,通义千问甩出了一张“王炸”。万亿参数MoE架构的旗舰模型Qwen3.7-Max正式接入千问APP、PC端及网页端。这不仅仅是一次版本更新,更是国产大模型在权威第三方榜单中首次稳居全球前五、国产第一的里程碑…...

LLM测试工程师必看,Claude E2E测试架构设计,从用例生成、黄金样本构建到回归基线告警闭环
更多请点击: https://codechina.net 第一章:LLM测试工程师必看,Claude E2E测试架构设计,从用例生成、黄金样本构建到回归基线告警闭环 核心架构概览 Claude端到端测试架构采用三层解耦设计:输入层(动态用…...