【Spark分布式内存计算框架——Spark Streaming】7. Kafka集成方式
集成方式
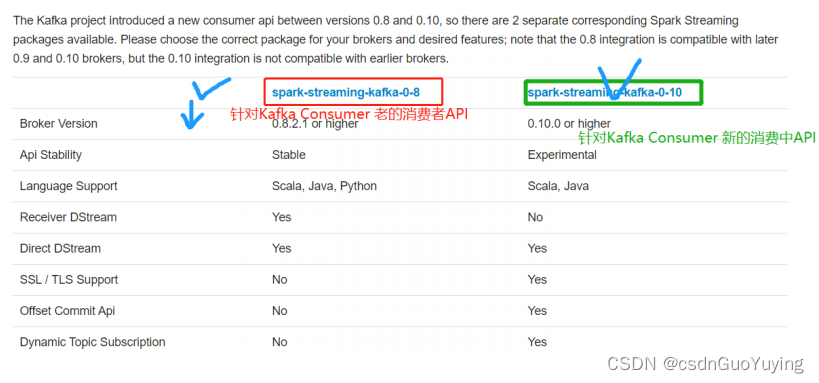
Spark Streaming与Kafka集成,有两套API,原因在于Kafka Consumer API有两套,
文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-integration.html。
方式一:Kafka 0.8.x版本
- 老的Old Kafka Consumer API
- 文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-8-integration.html
- 老的Old消费者API,有两种方式:
- 第一种:高级消费API(Consumer High Level API),Receiver接收器接收数据
- 第二种:简单消费者API(Consumer Simple Level API) ,Direct 直接拉取数据
方式二:Kafka 0.10.x版本
- 新的 New Kafka Consumer API
- 文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-10-integration.html
- 核心API:KafkaConsumer、ConsumerRecorder
两种方式区别
使用Kafka Old Consumer API集成两种方式,虽然实际生产环境使用Direct方式获取数据,但是在面试的时候常常问到两者区别。
文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-8-integration.html
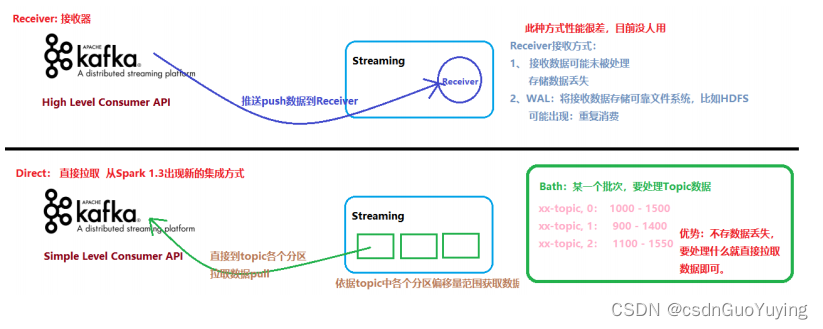
- Receiver-based Approach:
- 基于接收器方式,消费Kafka Topic数据,但是企业中基本上不再使用;
- Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启多个,再手动合并数据(union),再进行处理,很麻烦;
- Receiver那台机器挂了,可能会丢失数据,所以需要开启WAL(预写日志)保证数据安全,那么效率又会降低;
- Receiver方式是通过zookeeper来连接kafka队列,调用Kafka高阶API,offset存储在zookeeper,由Receiver维护;
- Spark在消费的时候为了保证数据不丢也会在Checkpoint中存一份offset,可能会出现数据不一致;
- Direct Approach (No Receivers):
- 直接方式,Streaming中每批次的每个job直接调用Simple Consumer API获取对应Topic数据,此种方式使用最多,面试时被问的最多;
- Direct方式是直接连接kafka分区来获取数据,从每个分区直接读取数据大大提高并行能力
- Direct方式调用Kafka低阶API(底层API),offset自己存储和维护,默认由Spark维护在checkpoint中,消除了与zk不一致的情况;
- 当然也可以自己手动维护,把offset存在MySQL、Redis和Zookeeper中;
上述两种方式区别,如下图所示:
4.2 Direct 方式集成
使用Kafka Old Consumer API方式集成Streaming,采用Direct方式,调用Old Simple Consumer API,
文档:
http://spark.apache.org/docs/2.4.5/streaming-kafka-0-8-integration.html#approach-2-direct-approach-no-receivers
编码实现
Direct方式会定期地从Kafka的topic下对应的partition中查询最新的偏移量,再根据偏移量范围,在每个batch里面处理数据,Spark通过调用kafka简单的消费者API读取一定范围的数据。

Direct方式没有receiver层,其会周期性的获取Kafka中每个topic的每个partition中的最新offsets,再根据设定的maxRatePerPartition来处理每个batch。较于Receiver方式的优势:
- 其一、简化的并行:Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据;
- 其二、高效:no need for Write Ahead Logs;
- 其三、精确一次:直接使用simple Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录。
添加相关MAVEN依赖:
<!-- Spark Streaming 集成Kafka 0.8.2.1 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.4.5</version>
</dependency>
提供工具类KafkaUtils专门从Kafka消费数据,其中函数【createDirectStream】消费数据:

创建Topic及Console控制台发送数据,命令如下:
# 1. 启动Zookeeper 服务
zookeeper-daemon.sh start
# 2. 启动Kafka 服务
kafka-daemon.sh start
# 3. Create Topic
kafka-topics.sh --create --topic wc-topic \
--partitions 3 --replication-factor 1 --zookeeper node1.itcast.cn:2181/kafka200
# List Topics
kafka-topics.sh --list --zookeeper node1.itcast.cn:2181/kafka200
# Producer
kafka-console-producer.sh --topic wc-topic --broker-list node1.itcast.cn:9092
# Consumer
kafka-console-consumer.sh --topic wc-topic \
--bootstrap-server node1.itcast.cn:9092 --from-beginning
具体演示代码如下:
import java.util.Date
import kafka.serializer.StringDecoder
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 集成Kafka,采用Direct式读取数据,对每批次(时间为1秒)数据进行词频统计,将统计结果输出到控制台
*/
object StreamingKafkaDirect {
def main(args: Array[String]): Unit = {
// 1、构建流式上下文实例对象StreamingContext,用于读取流式的数据和调度Batch Job执行
val ssc: StreamingContext = {
// a. 创建SparkConf实例对象,设置Application相关信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
//TODO: 设置每秒钟读取Kafka中Topic最大数据量
.set("spark.streaming.kafka.maxRatePerPartition", "10000")
// b. 创建StreamingContext实例,传递Batch Interval(时间间隔:划分流式数据)
val context: StreamingContext = new StreamingContext(sparkConf, Seconds(5))
// c. 返回上下文对象
context
}
// TODO: 2、从流式数据源读取数据
/*
def createDirectStream[
K: ClassTag, // Topic中Key数据类型
V: ClassTag,
KD <: Decoder[K]: ClassTag, // 表示Topic中Key数据解码(从文件中读取,反序列化)
VD <: Decoder[V]: ClassTag] (
ssc: StreamingContext,
kafkaParams: Map[String, String],
topics: Set[String]
): InputDStream[(K, V)]
*/
// 表示从Kafka Topic读取数据时相关参数设置
val kafkaParams: Map[String, String] = Map(
"bootstrap.servers" -> "node1.itcast.cn:9092",
// 表示从Topic的各个分区的哪个偏移量开始消费数据,设置为最大的偏移量开始消费数据
"auto.offset.reset" -> "largest"
)
// 从哪些Topic中读取数据
val topics: Set[String] = Set("wc-topic")
// 采用Direct方式从Kafka 的Topic中读取数据
val kafkaDStream: DStream[(String, String)] = KafkaUtils
.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, //
kafkaParams, //
topics
)
// 3、对接收每批次流式数据,进行词频统计WordCount
val resultDStream: DStream[(String, Int)] = kafkaDStream.transform(rdd => {
rdd
// 获取从Kafka读取数据的Message
.map(tuple => tuple._2)
// 过滤“脏数据”
.filter(line => null != line && line.trim.length > 0)
// 分割为单词
.flatMap(line => line.trim.split("\\s+"))
// 转换为二元组
.mapPartitions{iter => iter.map(word => (word, 1))}
// 聚合统计
.reduceByKey((a, b) => a + b)
})
// 4、将分析每批次结果数据输出,此处答应控制台
resultDStream.foreachRDD{ (rdd, time) =>
// 使用lang3包下FastDateFormat日期格式类,属于线程安全的
val batchTime = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
.format(new Date(time.milliseconds))
println("-------------------------------------------")
println(s"Time: $batchTime")
println("-------------------------------------------")
// TODO: 先判断RDD是否有数据,有数据在输出哦
if(!rdd.isEmpty()){
rdd
// 对于结果RDD输出,需要考虑降低分区数目
.coalesce(1)
// 对分区数据操作
.foreachPartition{iter =>iter.foreach(item => println(item))}
}
}
// 5、对于流式应用来说,需要启动应用,正常情况下启动以后一直运行,直到程序异常终止或者人为干涉
ssc.start() // 启动接收器Receivers,作为Long Running Task(线程) 运行在Executor
ssc.awaitTermination()
// 结束Streaming应用执行
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
从WEB UI监控页面可以看出如下信息:

相关文章:
【Spark分布式内存计算框架——Spark Streaming】7. Kafka集成方式
集成方式 Spark Streaming与Kafka集成,有两套API,原因在于Kafka Consumer API有两套, 文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-integration.html。 方式一:Kafka 0.8.x版本 老的Old Kafka Consum…...

如何引入elementUI
elementUI的引入完整引入按需引入完整引入 在 main.js 中写入以下内容: import Vue from ‘vue’; import ElementUI from ‘element-ui’; import ‘element-ui/lib/theme-chalk/index.css’; import App from ‘./App.vue’; Vue.use(ElementUI); new Vue({ el: ‘…...

vue3+rust个人博客建站日记4-Vditor搞定MarkDown
即然是个人博客,那么绝对不能丢给自己一个大大的输入框敷衍了事。如果真是这样,现在就可以宣布项目到此结束了。如今没人享受用输入框写博客。作为一个有追求的程序员,作品就要紧跟潮流。 后来,Markdown 的崛起逐步改变了大家的排…...
KDZD-JC软化击穿试验仪
一、概 述 KDZD-JC智能软化击穿试验仪是根据GB/T4074.6-2008和idtIEC60851-6:2004标准而设计的一种新型漆包圆线检测仪器。主要适用于固体绝缘材料(如:塑料、橡胶、层压材料、薄膜、树脂、云母、陶瓷、玻璃、绝缘漆等绝缘材料及绝缘件)在工…...

【数据结构】单链表的C语言实现--万字详解介绍
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:数据结构 🎯长路漫漫浩浩,万事皆有期待 文章目录1.链表1.1 链表的概念…...

电子科技大学软件工程期末复习笔记(七):测试策略
目录 前言 重点一览 V模型 回归测试 单元测试 集成测试 重要概念 自顶向下的集成方法 自底向上的集成方法 SMOKE方法 系统测试 验收测试 α测试 β测试 本章小结 前言 本复习笔记基于王玉林老师的课堂PPT与复习大纲,供自己期末复习与学弟学妹参考用…...

逆向-还原代码之除法 (Interl 64)
除法和32位差不多,毕竟背后的数学公式是一样的。区别只是32位的乘法需要两个寄存器来存放大数相乘的结果,而64位的不需要,一个寄存器就能存下。所以在64位的环境下,多了右移32位这条指令,其他指令一样。 //code #incl…...

Python WebDriver自动化测试
Webdriver Selenium 是 ThroughtWorks 一个强大的基于浏览器的开源自动化测试工具,它通常用来编写 Web 应用的自动化测试。 Selenium 2,又名 WebDriver,它的主要新功能是集成了 Selenium 1.0 以及 WebDriver(WebDriver 曾经是…...
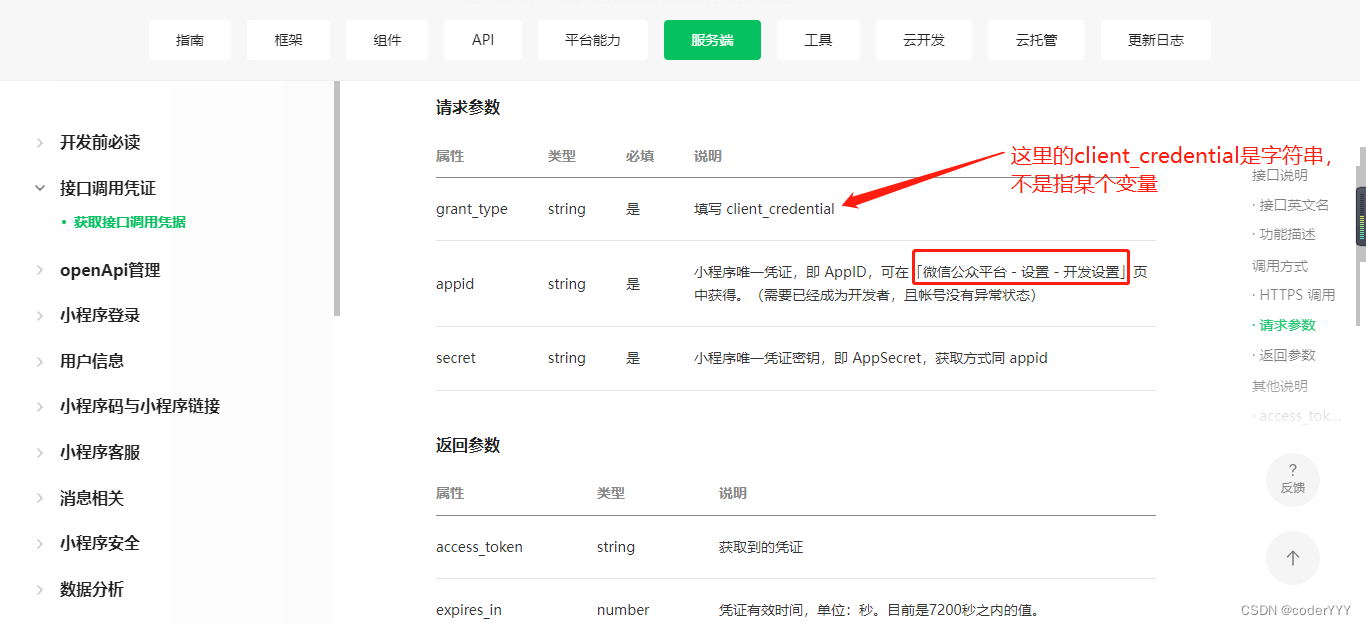
2023年微信小程序获取手机号授权登录注册详细教程,包含服务端教程
前言 小程序中有很多地方都会用到用户的手机号,比如登陆注册,填写收货地址等等。有了这个组件可以快速获取微信绑定手机号码,无须用户填写。网上大多数教程还是往年的,而微信官方的api已做了修改。本篇文章将使用最新的方法获取手…...
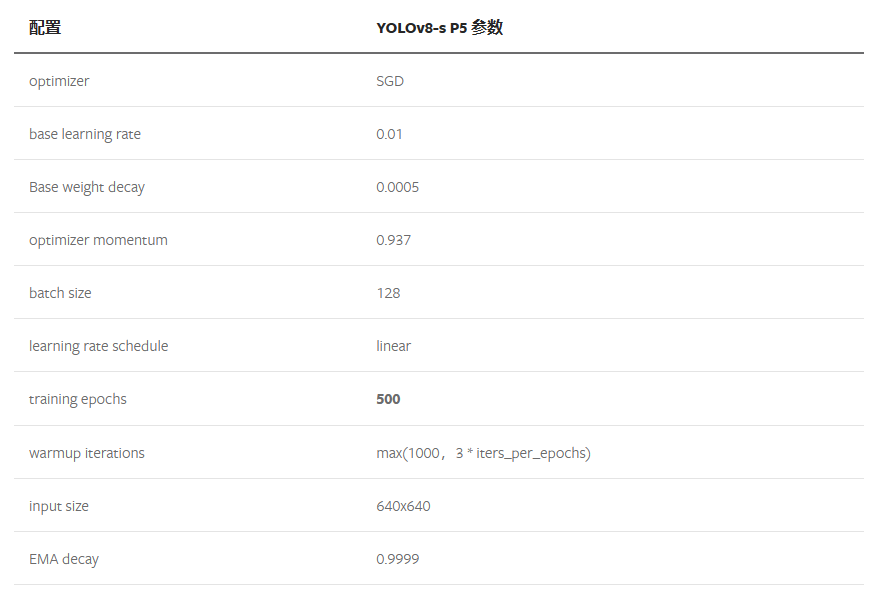
YOLOv8模型学习笔记
在前面的章节中博主学习了YOLOv5的相关知识,从YOLOv5的数据增强处理到模型设计,从正负样本匹配策略到LOSS设计,今天博主学习的是YOLOv8,同为ultralytics公司的产品,两者无论是思想层面还是具体的设计方面都有着异曲同工…...

Java SE知识点1
一、continue、break、和return的区别是什么? 在循环结构中,当循环条件不满足或者循环次数达到要求时,循环会正常结束。但是,有时候可能需要 在循环的过程中,当发生了某种条件之后 ,提前终止循环,这就需要用到下面几个关键词: 1. continue :指跳出当前的这一次循环,…...

华为OD机试模拟题 用 C++ 实现 - 端口合并(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 最多获得的短信条数(2023.Q1)) 文章目录 最近更新的博客使用说明端口合并题目输入输出示例一输入输出说明示例二输入输出说明示例三输入输出说明...

C++ Primer Plus 第6版 读书笔记(3) 第3章 处理数据
目录 3.1 简单变量 3.1.1 变量名 *位与字节 3.1.4 无符号类型 3.1.7 C如何确定常量的类型 C是在 C 语言基础上开发的一种集面向对象编程、泛型编程和过程化编程于一体的编程语言,是C语言的超集。本书是根据2003年的ISO/ANSI C标准编写的,通过大量短…...

ArrayList源码解读
参数 //默认初始容量private static final int DEFAULT_CAPACITY 10;//空数组(用于空实例)private static final Object[] EMPTY_ELEMENTDATA {};//用于默认大小空实例的共享空数组private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA {};//保存数据的数组tra…...
)
python实战应用讲解-【语法高级篇】时间与日期(附python示例代码)
目录 保持时间、计划任务和启动程序 time 模块 time.time() 函数 time.sleep() 函数 Python3 日期和时间...
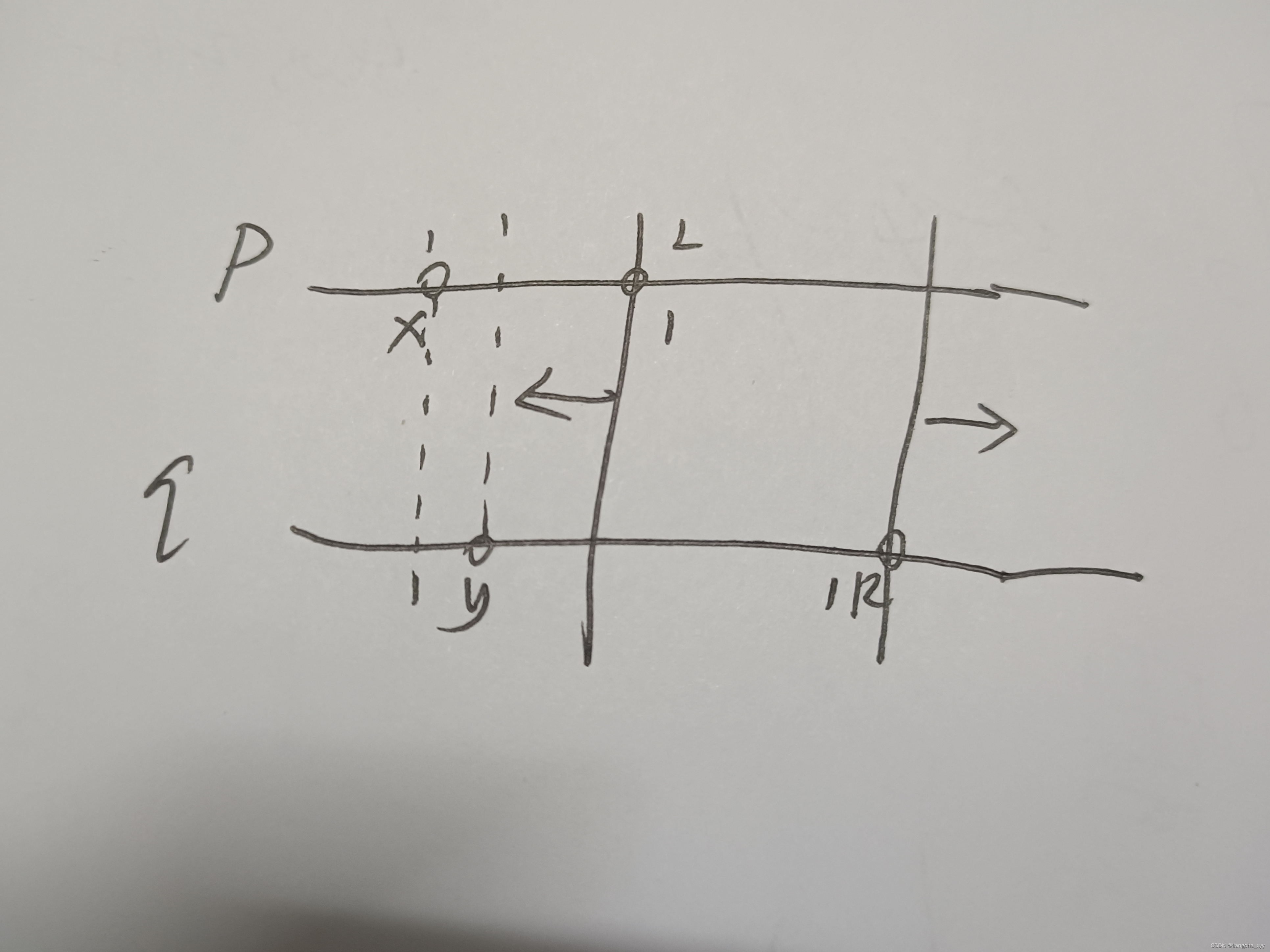
D. Moscow Gorillas(双指针 + 区间分析)
Problem - D - Codeforces 在冬天,莫斯科动物园的居民非常无聊,尤其是大猩猩。你决定娱乐他们,带了一个长度为n的排列p到动物园。长度为n的排列是由n个从1到n的不同整数以任意顺序组成的数组。例如,[2,3,1,5,4]是一个排列…...
华为OD机试题,用 Java 解【相同数字的积木游戏 1】问题
最近更新的博客 华为OD机试题,用 Java 解【停车场车辆统计】问题华为OD机试题,用 Java 解【字符串变换最小字符串】问题华为OD机试题,用 Java 解【计算最大乘积】问题华为OD机试题,用 Java 解【DNA 序列】问题华为OD机试 - 组成最大数(Java) | 机试题算法思路 【2023】使…...

Python实现GWO智能灰狼优化算法优化BP神经网络分类模型(BP神经网络分类算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。1.项目背景灰狼优化算法(GWO),由澳大利亚格里菲斯大学学者 Mirjalili 等人于2014年提出来的一种群智能优…...

无线蓝牙耳机哪个牌子好?2023质量好的无线蓝牙耳机推荐
近几年,随着蓝牙技术的不断进步,使用蓝牙耳机的人也越来越多。蓝牙耳机的出现,不仅能让我们摆脱线带来的约束,还能提升我们学习和工作的效率。最近看到很多人问,无线蓝牙耳机哪个牌子好?下面,我…...

Qt之QTableView自定义排序/过滤(QSortFilterProxyModel实现,含源码+注释)
一、效果示例图 1.1 自定义表格排序示例图 本文过滤条件为行索引取余2等于0时返回true,且从下图中可以看到,奇偶行是各自挨在一起的。 1.2 自定义表格过滤示例图 下图添加两列条件(当前数据大于当前列条件才返回true,且多个列…...

如何快速上手Podgrab:5分钟搭建个人播客下载中心完整指南
如何快速上手Podgrab:5分钟搭建个人播客下载中心完整指南 【免费下载链接】podgrab A self-hosted podcast manager/downloader/archiver tool to download podcast episodes as soon as they become live with an integrated player. 项目地址: https://gitcode.…...

凌晨还在改论文?这些降重黑科技帮你一键通关
凌晨对着电脑屏幕改论文,那种既疲惫又焦虑的感觉,经历过的人都懂。好在现在的降重工具已经不只是“替换同义词”那么简单了,像 毕业之家 和 PaperRed 这两款主流工具,各自走了完全不同的技术路线,可以根据你的痛点来选…...

gogoclaw:基于文件与技能的自主智能体运行时设计与实践
1. 项目概述:一个以文件为基石的自主智能体运行时如果你和我一样,对市面上那些“黑盒”式的AI智能体框架感到厌倦,总觉得它们把太多逻辑和状态藏在运行时深处,调试和扩展起来像在拆盲盒,那么gogoclaw这个项目可能会让你…...

模块化IC设计流程:应对复杂芯片挑战的解决方案
1. 现代IC设计面临的挑战与模块化流程的价值在当今半导体行业,芯片设计团队正面临前所未有的复杂挑战。随着工艺节点不断演进至5nm及以下,设计复杂度呈指数级增长。我曾参与的一个65nm SoC项目,团队最初采用传统线性设计流程,结果…...
)
别再手动折腾了!用Stack Builder一键搞定PostGIS 2.1 for PostgreSQL 9.2 (Windows 64位)
告别繁琐配置:用Stack Builder轻松部署PostGIS空间数据库 在Windows环境下配置PostgreSQL的空间扩展PostGIS,传统方式往往需要手动下载安装包、配置环境变量、执行SQL脚本等一系列操作。对于刚接触空间数据库的开发者来说,这个过程既耗时又容…...

模拟计算机应急救场:从400Hz电源故障看经典工程思维
1. 项目概述:一次由模拟计算机主导的“救场”1984年,在宾夕法尼亚州费城的一个大型测试实验室里,一个为海军战斗机设计的红外跟踪系统正面临一场突如其来的危机。这个系统被安装在一个三轴液压驱动的万向节上,需要在特定的400赫兹…...
图灵-人工智能之父)
图解人工智能(7)图灵-人工智能之父
图灵对人工智能这门学科做出了哪些贡献?这些贡献对于人工智能这门科学有什么重要意义?图灵提出图灵机模型,为人工智能准备了工具; 提出智能机器设想,奠定了人工智能的思想基础;提出图灵测试,为评估人工智能…...

ARM DAP调试架构核心机制与实践指南
1. ARM调试访问端口(DAP)架构解析调试访问端口(Debug Access Port, DAP)是ARM调试架构中的核心组件,它作为调试器与芯片内部调试资源的桥梁,提供了标准化的访问接口。DAP的设计遵循ARM Debug Interface v5.1(ADIv5.1)规范,支持两种物理接口协…...

cpdown:精准下载Git仓库文件,告别克隆整个项目的低效操作
1. 项目概述与核心价值最近在整理本地开发环境,发现一个高频痛点:从各种代码托管平台(比如 GitHub、GitLab、Gitee)下载单个文件或特定目录时,总是特别麻烦。要么得克隆整个仓库,动辄几百兆,浪费…...
)
别再只盯着原理图了!用Python+OpenCV动手模拟激光三角测距(斜射/直射对比)
用PythonOpenCV模拟激光三角测距:斜射与直射的实战对比 激光三角测距技术听起来高大上,但真正理解它的精髓往往需要跳出公式推导的泥潭。作为一名长期在工业检测领域摸爬滚打的技术人员,我发现用代码模拟物理过程是最有效的学习方式。本文将…...