YOLOv8模型学习笔记
在前面的章节中博主学习了YOLOv5的相关知识,从YOLOv5的数据增强处理到模型设计,从正负样本匹配策略到LOSS设计,今天博主学习的是YOLOv8,同为ultralytics公司的产品,两者无论是思想层面还是具体的设计方面都有着异曲同工之妙。那么就让我们来学习一下这个横空出世的YOLOv8算法吧。值得一提的是,YOLOv8相较于先前的YOLO系列算法,其目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。此外,现在各个 YOLO 系列改进算法都在 COCO 上面有明显性能提升,但是在自定义数据集上面的泛化性还没有得到广泛验证,至今依然听到不少关于 YOLOv5 泛化性能较优异的说法。
在上一篇中,博主对YOLOv8进行了调试,目前模型仍处于训练阶段,在这篇博文中,博主将对YOLOv8模型的各个文件进行讲解,由于YOLOv8刚刚问世,相关解读参考数量有限,如有不足之处,烦请诸位不吝赐教。
模型介绍
模型改进
- 提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
- 骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是无脑一套参数应用所有模型,大幅提升了模型性能。不过这个 C2f模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
- Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了Anchor-Free
- Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss
- 训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
从上面可以看出,YOLOv8 主要参考了最近提出的诸如 YOLOX、YOLOv6、YOLOv7 等算法的相关设计,本身的创新点不多,偏向工程实践,主推的还是 ultralytics 这个框架本身。
接下来我们将按照模型结构设计、Loss 计算、训练数据增强、训练策略和模型推理过程共 5 个部分详细介绍 YOLOv8 目标检测的各种改进,实例分割部分暂时不进行描述。
模型配置文件
我们先来看一下YOLOv8的模型配置文件,以yolov8n为例(我们训练时使用的便是这个模型)
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # scales module repeats
width_multiple: 0.25 # scales convolution channels
其中,nc是类别数;由于使用coco数据集进行预训练,而coco数据集类别有80种。
depth_multiple和width_multiple用来生成不同大小的模型,如果希望大一点,就把这个数字改大一点,网络就会按比例变深、变宽;如果希望小一点,就把这个数字改小一点,网络就会按比例变浅、变窄。
网络backbone部分
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9
与yolov5一样,yolov8会按照配置文件实例化各个层,每行的列表中的四个元素分别代表:[from, number, module, args],
from:-n 代表是从前n层获得的输入,如-1表示从前一层获得输入
number:该层的数量
module:表示网络模块的名称
args:类的初始化参数
随后我们看下具体模块设计:
class Conv(nn.Module):# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))
我们以[-1, 1, Conv, [64, 3, 2]] 为例,-1代表来自连接上一层,1代表创建一个Conv,Conv为模型名,【64,3,2】代表【输出通道数量=64,卷积核尺寸k=3,步长s=2】,(输入通道数量自动由上一层输出确定)一般按照[ch_out, kernel, stride, padding, groups]排列。
在暂时不考虑 Head 情况下,对比 YOLOv5 和 YOLOv8 的 yaml 配置文件可以发现改动较小。
Neck模块设计
骨干网络和 Neck 的具体变化为:
- 第一个卷积层的 kernel 从 6x6 变成了 3x3
- 所有的 C3 模块换成 C2f,结构如下所示,可以发现多了更多的跳层连接和额外的 Split 操作
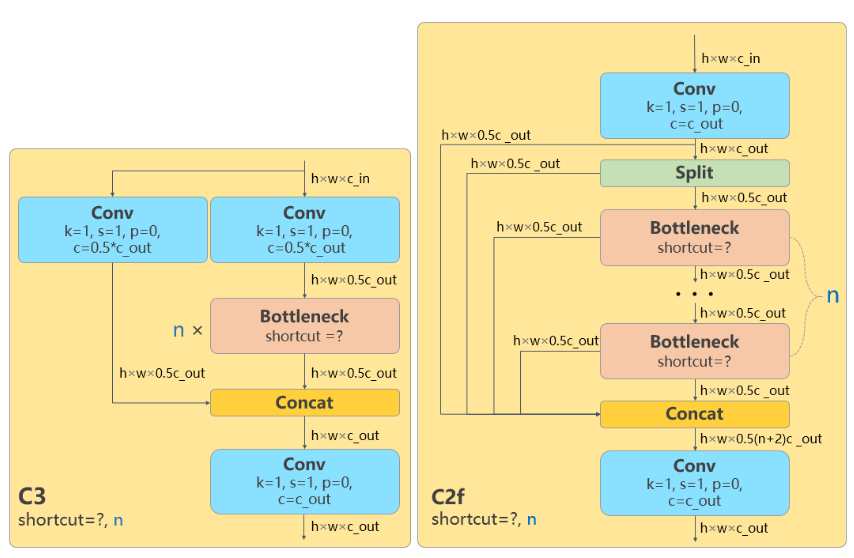
- 去掉了 Neck 模块中的 2 个卷积连接层
- Backbone 中 C2f 的 block 数从 3-6-9-3 改成了 3-6-6-3
查看 N/S/M/L/X 等不同大小模型,可以发现 N/S 和 L/X 两组模型只是改了缩放系数,但是 S/M/L 等骨干网络的通道数设置不一样,没有遵循同一套缩放系数。如此设计的原因应该是同一套缩放系数下的通道设置不是最优设计,YOLOv7 网络设计时也没有遵循一套缩放系数作用于所有模型。
Head模块设计
Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。其结构如下所示:
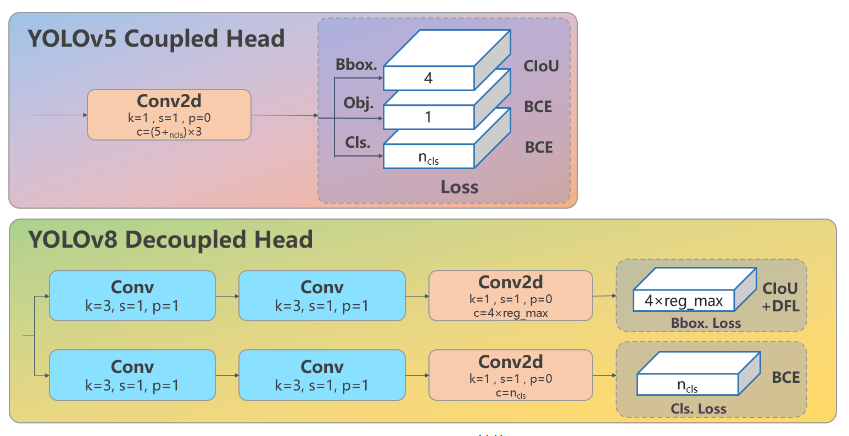
可以看出,不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法。
Loss 计算
Loss 计算过程包括 2 个部分: 正负样本分配策略和 Loss 计算。 现代目标检测器大部分都会在正负样本分配策略上面做文章,典型的如 YOLOX 的 simOTA、TOOD 的 TaskAlignedAssigner 和 RTMDet 的 DynamicSoftLabelAssigner,这类 Assigner 大都是动态分配策略,而 YOLOv5 采用的依然是静态分配策略。考虑到动态分配策略的优异性,YOLOv8 算法中则直接引用了 TOOD 的 TaskAlignedAssigner。 TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
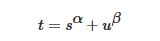
s 是标注类别对应的预测分值,u 是预测框和 gt 框的 iou,两者相乘就可以衡量对齐程度。
- 对于每一个 GT,对所有的预测框基于 GT 类别对应分类分数,预测框与 GT 的 IoU 的加权得到一个关联分类以及回归的对齐分数 alignment_metrics 。
- 对于每一个 GT,直接基于 alignment_metrics 对齐分数选取 topK 大的作为正样本
Loss 计算包括 2 个分支: 分类和回归分支,没有了之前的 objectness 分支。 - 分类分支依然采用 BCE Loss
- 回归分支需要和 Distribution Focal Loss 中提出的积分形式表示法绑定,因此使用了 Distribution Focal Loss, 同时还使用了 CIoU Loss
- Loss 采用一定权重比例加权即可。
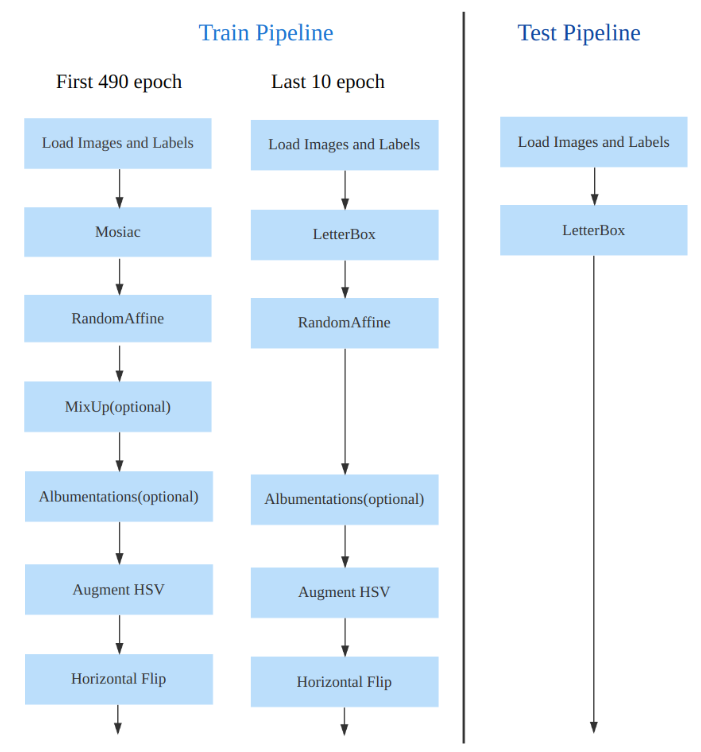
训练数据增强
数据增强方面和 YOLOv5 差距不大,只不过引入了 YOLOX 中提出的最后 10 个 epoch 关闭 Mosaic 的操作。假设训练 epoch 是 500,其示意图如下所示:
训练策略
YOLOv8 的训练策略和 YOLOv5 没有啥区别,最大区别就是模型的训练总 epoch 数从 300 提升到了 500,这也导致训练时间急剧增加。以 YOLOv8-S 为例,其训练策略汇总如下:
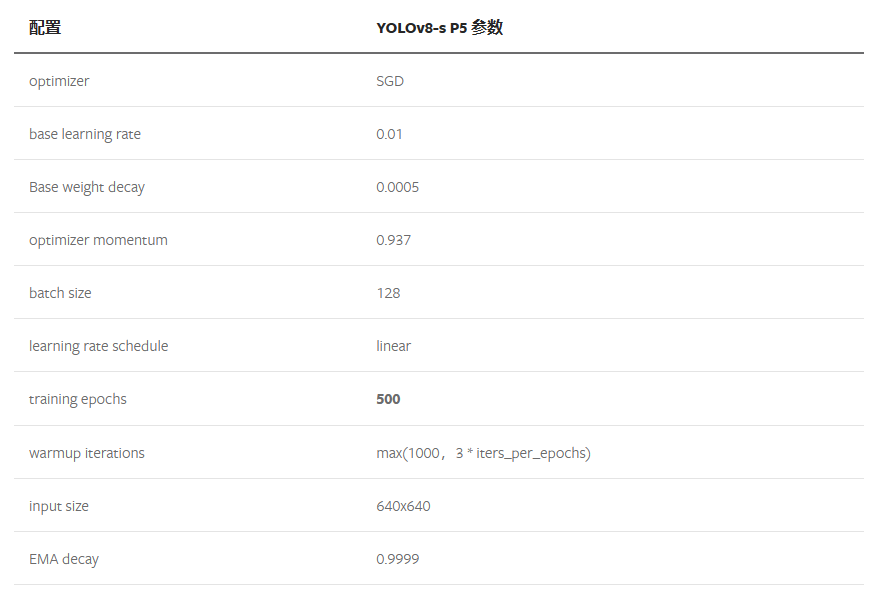
模型推理过程
YOLOv8 的推理过程和 YOLOv5 几乎一样,唯一差别在于前面需要对 Distribution Focal Loss 中的积分表示 bbox 形式进行解码,变成常规的 4 维度 bbox,后续计算过程就和 YOLOv5 一样了。
以 COCO 80 类为例,假设输入图片大小为 640x640,MMYOLO 中实现的推理过程示意图如下所示:
其推理和后处理过程为:
(1) bbox 积分形式转换为 4d bbox 格式
对 Head 输出的 bbox 分支进行转换,利用 Softmax 和 Conv 计算将积分形式转换为 4 维 bbox 格式
(2) 维度变换
YOLOv8 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图。Head 部分输出分类和回归共 6 个尺度的特征图。 将 3 个不同尺度的类别预测分支、bbox 预测分支进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支 和 bbox 预测分支 shape 分别为 (b, 80x80+40x40+20x20, 80)=(b,8400,80),(b,8400,4)。
(3) 解码还原到原图尺度
分类预测分支进行 Sigmoid 计算,而 bbox 预测分支需要进行解码,还原为真实的原图解码后 xyxy 格式。
(4) 阈值过滤
遍历 batch 中的每张图,采用 score_thr 进行阈值过滤。在这过程中还需要考虑 multi_label 和 nms_pre,确保过滤后的检测框数目不会多于 nms_pre。
(5) 还原到原图尺度和 nms
基于前处理过程,将剩下的检测框还原到网络输出前的原图尺度,然后进行 nms 即可。最终输出的检测框不能多于 max_per_img。
有一个特别注意的点:YOLOv5 中采用的 Batch shape 推理策略,在 YOLOv8 推理中暂时没有开启,不清楚后面是否会开启,在 MMYOLO 中快速测试了下,如果开启 Batch shape 会涨大概 0.1~0.2。
相关文章:
YOLOv8模型学习笔记
在前面的章节中博主学习了YOLOv5的相关知识,从YOLOv5的数据增强处理到模型设计,从正负样本匹配策略到LOSS设计,今天博主学习的是YOLOv8,同为ultralytics公司的产品,两者无论是思想层面还是具体的设计方面都有着异曲同工…...

Java SE知识点1
一、continue、break、和return的区别是什么? 在循环结构中,当循环条件不满足或者循环次数达到要求时,循环会正常结束。但是,有时候可能需要 在循环的过程中,当发生了某种条件之后 ,提前终止循环,这就需要用到下面几个关键词: 1. continue :指跳出当前的这一次循环,…...

华为OD机试模拟题 用 C++ 实现 - 端口合并(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 最多获得的短信条数(2023.Q1)) 文章目录 最近更新的博客使用说明端口合并题目输入输出示例一输入输出说明示例二输入输出说明示例三输入输出说明...

C++ Primer Plus 第6版 读书笔记(3) 第3章 处理数据
目录 3.1 简单变量 3.1.1 变量名 *位与字节 3.1.4 无符号类型 3.1.7 C如何确定常量的类型 C是在 C 语言基础上开发的一种集面向对象编程、泛型编程和过程化编程于一体的编程语言,是C语言的超集。本书是根据2003年的ISO/ANSI C标准编写的,通过大量短…...

ArrayList源码解读
参数 //默认初始容量private static final int DEFAULT_CAPACITY 10;//空数组(用于空实例)private static final Object[] EMPTY_ELEMENTDATA {};//用于默认大小空实例的共享空数组private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA {};//保存数据的数组tra…...
)
python实战应用讲解-【语法高级篇】时间与日期(附python示例代码)
目录 保持时间、计划任务和启动程序 time 模块 time.time() 函数 time.sleep() 函数 Python3 日期和时间...
D. Moscow Gorillas(双指针 + 区间分析)
Problem - D - Codeforces 在冬天,莫斯科动物园的居民非常无聊,尤其是大猩猩。你决定娱乐他们,带了一个长度为n的排列p到动物园。长度为n的排列是由n个从1到n的不同整数以任意顺序组成的数组。例如,[2,3,1,5,4]是一个排列…...
华为OD机试题,用 Java 解【相同数字的积木游戏 1】问题
最近更新的博客 华为OD机试题,用 Java 解【停车场车辆统计】问题华为OD机试题,用 Java 解【字符串变换最小字符串】问题华为OD机试题,用 Java 解【计算最大乘积】问题华为OD机试题,用 Java 解【DNA 序列】问题华为OD机试 - 组成最大数(Java) | 机试题算法思路 【2023】使…...

Python实现GWO智能灰狼优化算法优化BP神经网络分类模型(BP神经网络分类算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。1.项目背景灰狼优化算法(GWO),由澳大利亚格里菲斯大学学者 Mirjalili 等人于2014年提出来的一种群智能优…...

无线蓝牙耳机哪个牌子好?2023质量好的无线蓝牙耳机推荐
近几年,随着蓝牙技术的不断进步,使用蓝牙耳机的人也越来越多。蓝牙耳机的出现,不仅能让我们摆脱线带来的约束,还能提升我们学习和工作的效率。最近看到很多人问,无线蓝牙耳机哪个牌子好?下面,我…...

Qt之QTableView自定义排序/过滤(QSortFilterProxyModel实现,含源码+注释)
一、效果示例图 1.1 自定义表格排序示例图 本文过滤条件为行索引取余2等于0时返回true,且从下图中可以看到,奇偶行是各自挨在一起的。 1.2 自定义表格过滤示例图 下图添加两列条件(当前数据大于当前列条件才返回true,且多个列…...
电商(强一致性系统)的场景设计
领域拆分:如何合理地拆分系统? 一般来说,强一致性的系统都会牵扯到“锁争抢”等技术点,有较大的性能瓶颈,而电商时常做秒杀活动,这对系统的要求更高。业内在对电商系统做改造时,通常会从三个方面…...
)
算法与数据结构(一)
一、时间复杂度 一个操作如果和样本的数据量没有关系,每次都是固定时间内完成的操作,叫做常数操作。 时间复杂度为一个算法流程中,常数操作数量的一个指标。常用O(读作big O)来表示。具体来说,这个算法流程中,发生了多…...

【Python】元组如何创建?
嗨害大家好鸭!我是小熊猫~ Python 元组 Python 的元组与列表类似, 不同之处在于元组的元素不能修改。 元组使用小括号,列表使用方括号。 元组创建很简单,只需要在括号中添加元素, 并使用逗号隔开即可。 如下实例…...

qt操作文件以及字符串转换
//从文件加载英文属性与中文属性对照表QFile file(":/propertyname.txt");if (file.open(QFile::ReadOnly)) {//QTextStream方法读取速度至少快百分之30#if 0while(!file.atEnd()) {QString line file.readLine();appendName(line);}#elseQTextStream in(&file)…...
)
数组中只出现一次的两个数字(异或法思路)
题目简介 一个数组中只有2个数字只有一个,其他数字都有两个。找出这两个数字。a, b 用HashMap记录就不说了。 这里记录一下用异或的方式解决。 由于异或特性为自己异或自己为0。a^a 0;所以可以异或数组中的所有数字得出 a^b 的结果,其他相同的都消掉…...

python支持的操作系统有哪些
支持python开发环境的系统有Linux、OSX和windows,以及所有主要的操作系统中。 Linux,Linux系统是为编程而设计的,因此在大多数Linux计算机中,都默认安装了Python。编写和维护Linux的人认为会使用这种系统进行编程。要在Linux中运…...

S3C2440开发环境搭建
拿出了之前的S3C2440开发板,然后把移植uboot、移植内核、制作根文件系统、设备树编写驱动等几项再做一遍,这篇文章先记录下环境搭建过程,以及先把现成的uboot、内核、根文件系统下载进去,看看开发板还能不能用,先熟悉一…...

软件测试之测试用例
测试用例 1. 测试用例定义 测试用例又叫做test case,是为某个特殊目标而编制的一组测试输入、执行条件以及预期结果,以便测试某个程序路径或核实是否满足某个特定需求。 2. 编写测试用例的原因 2.1 理清思路,避免遗漏 如果测试的项目大而复杂&#…...

null和undefined的区别有哪些?
null和undefined的区别有哪些?相同点不同点undefinednull总结相同点 1.null和undefined都是js的基本数据类型 2.undefined和null都是假值(falsy),都能作为条件进行判断,所以在绝大多数情况下两者在使用上没有区别 if(undefined)…...

032随机链表的复制
随机链表的复制 题目链接:https://leetcode.cn/problems/copy-list-with-random-pointer/description/?envTypestudy-plan-v2&envIdtop-100-liked 我的解答: public Node copyRandomList(Node head) {Node dummy new Node(-1);Node curhead, newCu…...

从‘坍缩’到‘对齐’:用SimCSE解决BERT句子向量老难题,我的中文业务实验复盘
从语义坍缩到精准对齐:SimCSE在中文业务场景的实战指南 BERT模型在自然语言处理领域取得了巨大成功,但其原生句子向量存在一个令人头疼的问题——语义坍缩。简单来说,就是不同句子的向量在高维空间中倾向于聚集在一起,导致相似度计…...

MCP协议与n8n集成:构建标准化AI自动化工作流
1. 项目概述:当MCP遇见n8n,一个自动化新范式的诞生最近在折腾自动化工作流,特别是想把不同AI模型的能力串联起来,发现了一个挺有意思的项目:brunopelatieri/mcp-n8n-bruia。这名字乍一看有点复杂,拆开来看&…...

DeepFlow:基于eBPF与Wasm的零代码全栈可观测性平台实战解析
1. 项目概述:从零代码到全栈可观测,DeepFlow 如何重塑云原生与AI应用的监控体验 如果你正在管理一个由微服务、容器和AI模型构成的复杂云原生环境,那么“可观测性”这个词对你来说,可能既熟悉又头疼。熟悉的是,你知道没…...

AI编程助手文档自动化:dev-docs-skill实现PRD、API与CHANGELOG高效管理
1. 项目概述:一个为AI编程助手“赋能”的文档自动化工具 如果你和我一样,是个在多个项目间穿梭、既要写代码又要维护文档的开发者,那你一定对“文档债”深恶痛绝。代码写完了,功能上线了,但更新API文档、记录变更日志、…...

GPU云服务器选型指南:从核心参数到实际部署的深度解析
在当下人工智能跟高性能计算急剧速度发展状况里,GPU云服务器正沿着从专业领域迈向更为广泛应用场景的路径前行。对于构成企业的开发者、相关技术团队来讲,怎样精准无误理解这一技术方案所具备的本质,并且于实际选型期间做出合乎情理的判断&am…...

FPGA仿真库配置避坑指南:Xilinx 7系、Altera Cyclone V、Lattice ECP5在ModelSim 10.6d下的完整流程
FPGA仿真库配置避坑指南:Xilinx 7系、Altera Cyclone V、Lattice ECP5在ModelSim 10.6d下的完整流程 第一次在ModelSim 10.6d环境下配置FPGA仿真库时,我花了整整三天时间排查各种路径错误和权限问题。直到现在,我还清楚地记得那个深夜——当仿…...
:超出3个指标即触发强制重构——你达标了吗?)
DeepSeek Clean Code终极阈值(v2.3.1正式版):超出3个指标即触发强制重构——你达标了吗?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Clean Code终极阈值的演进与哲学内核 DeepSeek Clean Code 的“终极阈值”并非静态指标,而是代码可维护性、语义清晰度与执行确定性三者动态收敛的临界点。它源于对 LLM 推理链中 …...

自治性、反应性、学习能力:AI Agent的关键特性
自治性、反应性、学习能力:AI Agent的关键特性——从蚂蚁觅食到通用智能体的进化之路 关键词 AI Agent, 自治性, 反应性, 强化学习, 记忆机制, 环境交互, 通用人工智能萌芽 摘要 想象一下:你有一个能自己帮你规划周末露营路线(自治性)、中途遇到暴雨自动切换到附近民宿…...
)
基于开关电容器的级联多电平逆变器,使用布尔PWM控制技术研究(Simulink仿真实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...