使用 Redis 构建轻量的向量数据库应用:图片搜索引擎(二)
本篇文章我们来继续聊聊轻量的向量数据库方案:Redis,如何完成整个图片搜索引擎功能。
写在前面
在上一篇文章《使用 Redis 构建轻量的向量数据库应用:图片搜索引擎(一)》中,我们聊过了构建图片搜索引擎的两个主要流程中的第一部分,关于如何将图片等数据集制作成向量并构建可查询的向量索引,以及如何实现以图搜图。
这篇文章中,我们来聊聊第二部分,如何快速构建一个搜索引擎交互界面,以及快速实现文本搜索图片的功能。
前置准备
本文中使用的相关程序,和之前的内容一样,都已经开源在了 soulteary/simple-image-search-engine,欢迎一键三连,😄
在继续实现搜索交互功能和文本搜索图片功能前,我们先来了解下 Clip 能够如何使用。
OpenAI Clip 模型在文本场景的两种使用方式
在上一篇文章中,我们使用 Clip 模型实现了效果还不错的以图搜图功能。如果你有留意我在文章中提到的OpenAI 公开的研究页面,你会发现 Clip 最强的能力在于文本和图片在模型中是可以通过 embeddings 被关联起来的。
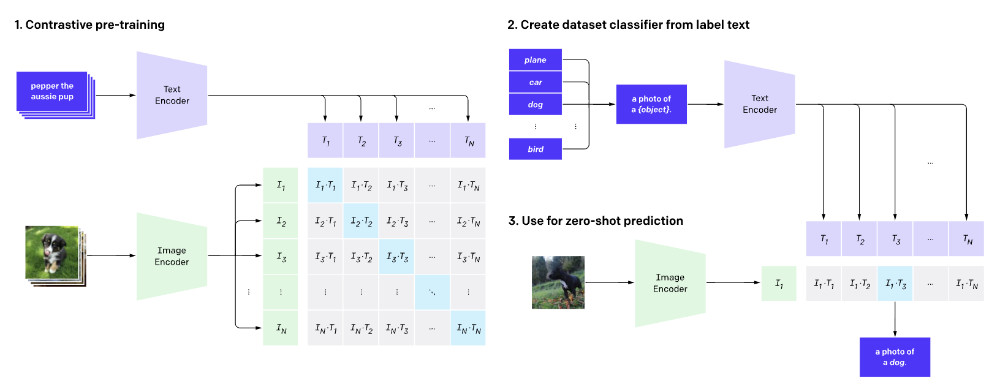
以这个能力为基础前提,我们来分别聊聊 Clip 模型的两种与文本进行交互的玩法。
借助“分类检测”能力实现的文本交互
我们可以参考上一篇文章中“将图片进行向量化处理”章节的代码,并做一些简单的调整,实现下面的程序:
import torch
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import time# 默认从 HuggingFace 加载模型,也可以从本地加载,需要提前下载完毕
model_name_or_local_path = "openai/clip-vit-base-patch16"
# 加载模型
model = CLIPModel.from_pretrained(model_name_or_local_path)
processor = CLIPProcessor.from_pretrained(model_name_or_local_path)# 记录处理开始时间
start = time.time()
# 读取待处理图片
image = Image.open("ball-8576.png")
# 处理图片数量,这里每次只处理一张图片
batch_size = 1# 要检测是否在图片中出现的内容
text = ['dog', 'cat', 'night', 'astronaut']with torch.no_grad():# 将图片使用模型加载,转换为 PyTorch 的 Tensor 数据类型# 相比较第一篇文章中的例子 1.how-to-embededing/app.py,这里多了一个 text 参数inputs = processor(text=text, images=image, return_tensors="pt", padding=True)# 将 inputs 中的内容解包,传递给模型,调用模型处理图片和文本outputs = model(**inputs)# 将原始模型输出转换为类别概率分布(在类别维度上执行 softmax 激活函数)probs = outputs.logits_per_image.softmax(dim=1)end = time.time()# 记录处理结束时间print('%s Seconds'%(end-start))# 打印所有的概率分布for i in range(len(text)):print(text[i],":",probs[0][i])
在上面的程序中,我们依旧会对之前的示例图片进行向量化处理。但是不同的是,我们不再对图片进行向量数据转换。而是在处理图片的时候,传入一个关键词列表:['dog', 'cat', 'night', 'astronaut']。这是假如我们在搜索的时候,搜索了一些关键词,比如 dog、cat、night、astronaut (狗子、猫子、夜晚、宇航员)。
当模型将文本关键词列表和图片一起进行处理的时候,我们将得到一些有趣的数据,经过一些简单的计算转换后,我们就能够得到我们传入的关键词和这个图片的关联性的概率了。
将上面的程序保存为 app.py(代码保存在 soulteary/simple-image-search-engine/steps/8.use-clip-detect-element),然后使用 python app.py 执行后,我们将得到类似下面的日志结果:
0.13835740089416504 Secondsdog : tensor(0.0005)
cat : tensor(0.0001)
night : tensor(0.0017)
astronaut : tensor(0.9976)
其中 tensor 后面的数字就是和我们的传入的关键词的相关性概率,可以看到包含“宇航员”的可能性在 99.76%,其他的几乎都在 0.05% ~ 0.1%左右的极低概率,所以这张图的答案和我们的搜索词 “宇航员(astronaut)”非常相关,适合被作为召回结果。
虽然,我们可以通过这个方式将我们搜索的内容(关键词,或抽取为关键词的搜索内容),在数据库存储的每一张图片的向量中进行循环比对,然后再选择相似度最高的结果,但是,这样效率太低了,并不推荐。
使用分类方式,在搜索引擎的场景下,最合适的可能是做内容发布、上架前的“内容的安全风控”。比如我们检测到有一些内容新添加到数据库中,可以用 Clip 结合我们的要进行检测的关键词库,来判断内容是否是合法规、健康的内容,是适合展示给用户的。
或者,从工程角度考虑,我们可以预先根据自己的业务或者图片大类,来进行一些数据的存储分堆,来提升搜索响应时的性能。
借助“内容预测”能力实现的文本交互
聊完 Clip 模型的第一种文本相关应用之后,我们来看看更有效率的方案,借助其内容预测和匹配能力来完成海量图片的文本搜索。
参考上篇文章中的“实现以图搜图功能”,我们稍加修改,可以得到下面的程序:
import torch
import numpy as np
from transformers import CLIPProcessor, CLIPModel, CLIPTokenizer
import time
import redis
from redis.commands.search.query import Querymodel_name_or_local_path = "openai/clip-vit-base-patch16"
model = CLIPModel.from_pretrained(model_name_or_local_path)
processor = CLIPProcessor.from_pretrained(model_name_or_local_path)
# 处理文本需要引入
tokenizer = CLIPTokenizer.from_pretrained(model_name_or_local_path)vector_indexes_name = "idx:ball_indexes"client = redis.Redis(host="redis-server", port=6379, decode_responses=True)
res = client.ping()
print("redis connected:", res)start = time.time()# 调用模型获取文本的 embeddings
def get_text_embedding(text): inputs = tokenizer(text, return_tensors = "pt")text_embeddings = model.get_text_features(**inputs)embedding_as_np = text_embeddings.cpu().detach().numpy()embeddings = embedding_as_np.astype(np.float32).tobytes()return embeddingswith torch.no_grad():# 获取文本的 embeddingstext_embeddings = get_text_embedding('astronaut')query_vector = text_embeddings
query = (Query("(*)=>[KNN 30 @vector $query_vector AS vector_score]").sort_by("vector_score").return_fields("$").dialect(2)
)def dump_query(query, query_vector, extra_params={}):result_docs = (client.ft(vector_indexes_name).search(query,{"query_vector": query_vector}| extra_params,).docs)print(result_docs)for doc in result_docs:print(doc['id'])dump_query(query, query_vector, {})end = time.time()
print('%s Seconds'%(end-start))
在上面的代码中,我们引入了 CLIPTokenizer 来调用模型将文本内容(搜索内容)转换为向量数据,与我们在数据库中存储好的图片内容进行关联匹配。
与将图片处理为向量类似的是,下面的函数我们会将我们传入的文本内容“astronaut” 转换为 Redis 搜索可以使用的数据类型(昨天文章有提,不再展开):
# 调用模型获取文本的 embeddings
def get_text_embedding(text): inputs = tokenizer(text, return_tensors = "pt")text_embeddings = model.get_text_features(**inputs)embedding_as_np = text_embeddings.cpu().detach().numpy()embeddings = embedding_as_np.astype(np.float32).tobytes()return embeddingswith torch.no_grad():# 获取文本的 embeddingstext_embeddings = get_text_embedding('astronaut')
当我们将上面所有的代码保存为 app.py,然后使用 python app.py 执行的时候,将会得到下面的结果:
[Document {'id': 'ball-6635.png', 'payload': None, 'json': '[-0.0013241395354270935,-0.8603543639183044,-0.0833742767572403,0.11372464150190352,-0.7410403490066528,-0.11845697462558746,-0.0472899004817009,..., 0.4744824767112732,0.26192834973335266]'}]ball-6635.png
ball-8317.png
ball-8367.png
ball-3340.png
ball-7194.png
ball-8352.png
ball-3571.png
ball-8103.png
ball-8279.png
ball-8648.png0.012780189514160156 Seconds
我们在日志输出的结果中,得到了一串图片名称,这说明我们的“文本搜索图片”功能正确的工作啦。
如果我们将搜索结果中的图片挑选出来仔细观察的话。你会发现,功能好像效果还凑合,是吧?

上面的程序执行日志结果记录着,这次从一万张图片中进行遍历式的相似性检索,找出最像“宇航员”的图片,其实只花了 0.01 秒左右,整体性能还是非常不错的。
搜索能力检测
为了更加客观的验证检索能力,我们当然不能只做一次搜索就结束啦。接下来我们就再简单的验证下两种搜索功能。
验证文本搜索能力
刚刚搜索的是“人”,接下来我们来试试搜索物品,比如剧中多次出现的帅气十足的 “飞机”。
我们调整代码中使用的搜索关键词:“get_text_embedding('airplane’)”,执行程序后,将得到下面的结果:
ball-1227.png
ball-1228.png
ball-1853.png
ball-1574.png
ball-894.png
ball-1521.png
ball-1673.png
ball-2020.png
ball-1299.png
ball-1814.png
观察程序执行结果,可以看到多数结果都是准确的。只有个别图片找到的是在“宇宙飞船”的驾驶舱内的画面,或许飞船也是飞机的一种?

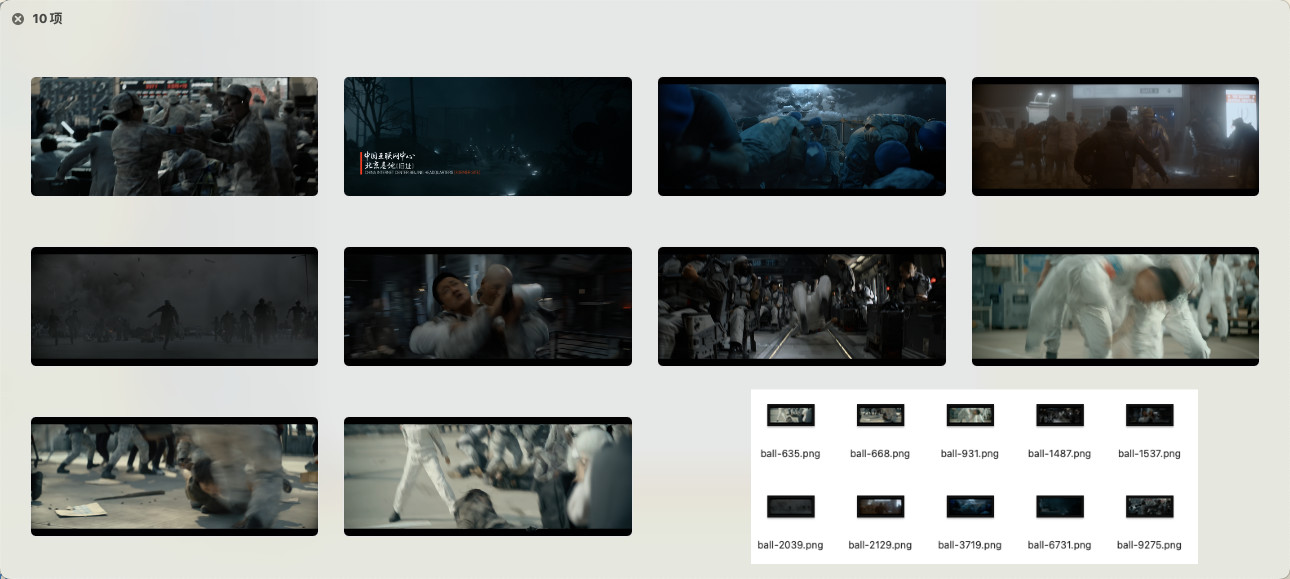
我们再来试试更复杂的词语,比如:“男人格斗”(get_text_embedding('men fighting'))。程序执行完毕后,找到的搜索结果是:
ball-9275.png
ball-668.png
ball-635.png
ball-2129.png
ball-931.png
ball-1537.png
ball-3719.png
ball-2039.png
ball-1487.png
ball-6731.png
可以看到,结果里多数的图片,找的还是比较准确的。
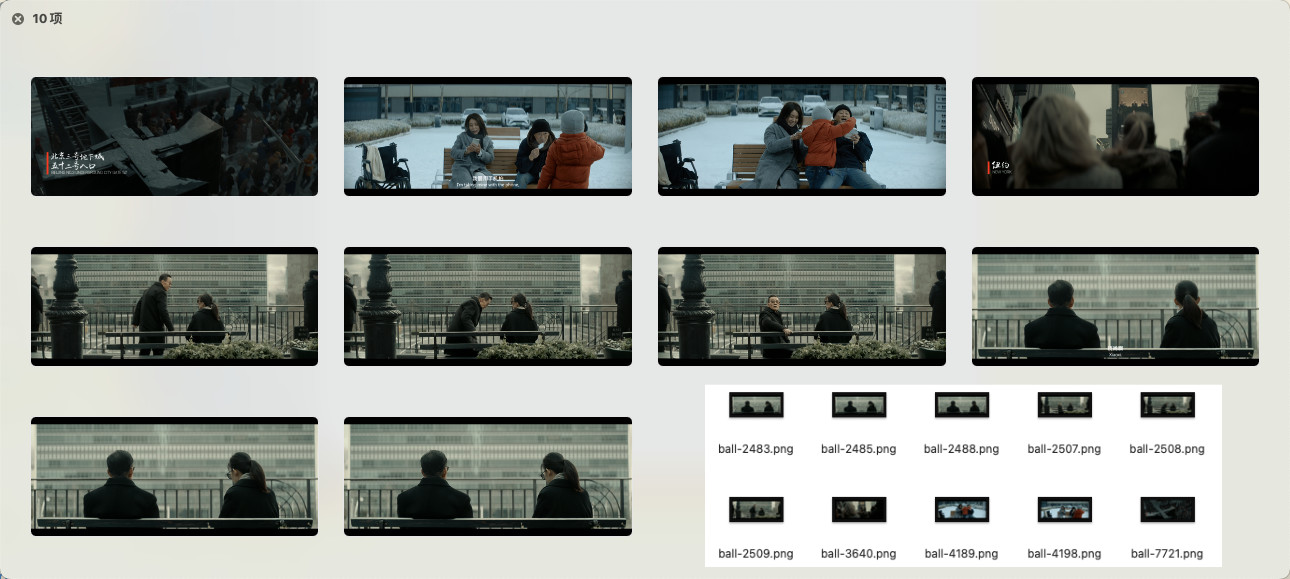
让我们继续增加难度,搜索一个更具体的场景:“城市里,男人和女人在聊天”(In the city, men and women are chatting):
ball-2483.png
ball-2485.png
ball-2508.png
ball-4198.png
ball-2509.png
ball-4189.png
ball-2488.png
ball-2507.png
ball-3640.png
ball-7721.png
虽然词汇更多,而且包含了完全不同的内容(两种性别的人,和具体的场景),程序依旧不负所望的找到了电影里,两个满足“男人和女人在城市聊天”的画面。并且结果里,多数内容依旧是对的:
验证图片搜索能力
在上一篇文章里,我们搜索过了电影中出现过的画面,效果非常不错。
所以在这篇文章里,我们就不测试简单的场景了,直接上难度:假设我们想找到电影里“玫瑰花相关”的画面,除了使用文本搜索之外,我们还可以使用网上找到的“神似的素材”来进行搜索。
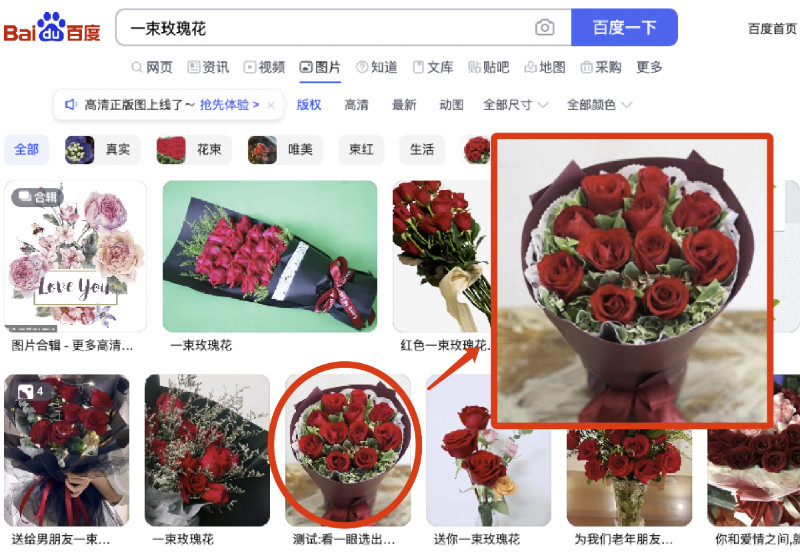
使用上一篇文章中的程序进行搜索,结果如下:
ball-5868.png
ball-6347.png
ball-7227.png
ball-1000.png
ball-5872.png
ball-1001.png
ball-5869.png
ball-999.png
ball-047.png
ball-8656.png
或许是因为我们使用的图片的风格和查找图片的风格差异较大,虽然还是能够找到符合条件的内容,但是确实出现了很多毫无关联的东西:
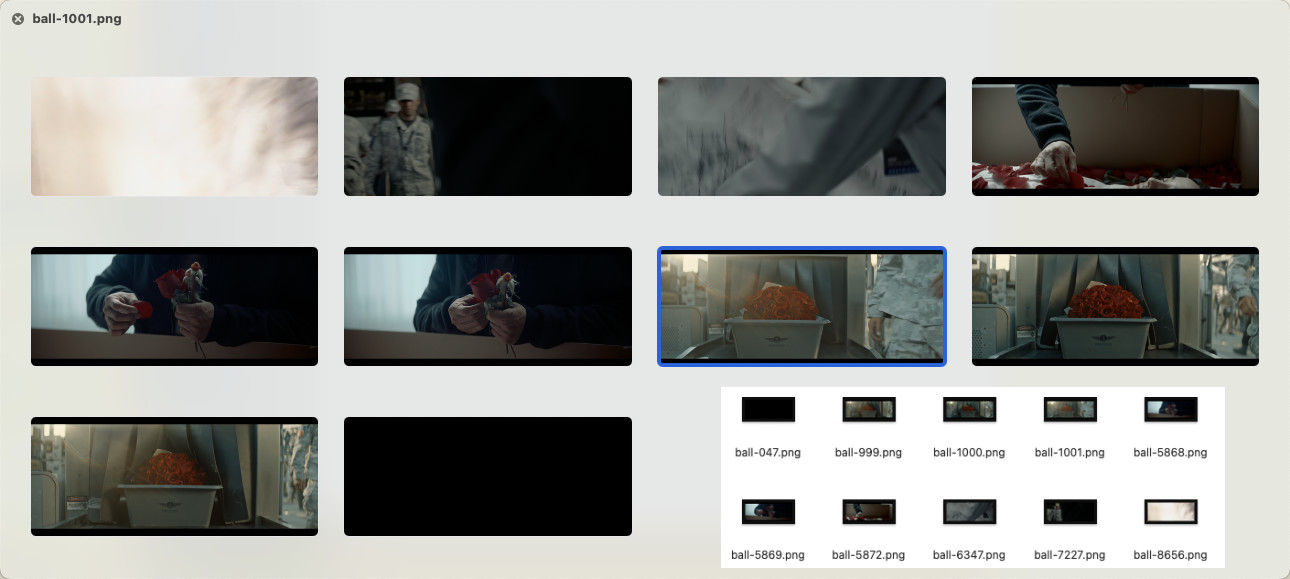
如果你想改进搜索结果,在重新训练模型、或者参考下文进行搜索效果优化之前,不妨试试用这里面比较符合我们需求的图片,再次进行搜索。或者在网上寻找更贴近原作画面中元素的搜索素材,让内容关联度增加,增加我们搜索的到想要的内容的概率。
额外的性能优化
尽管我们在一万张图片中,搜索出最接近“宇航员”内容的图片,只花了 0.01 秒左右。
但是,如果图片数据量增加,以及用户并发量提升,哪怕我们做了充分的应用缓存,服务的性能或许还是不如我们的预期。那么,有没有什么更好的方案呢?
接下来,我们来聊聊如何针对这个图片搜索引擎做性能优化,让它更快、以及效果更好。
优化向量数据库的索引
除了提升参与计算机器的数量和性能之外,对向量数据库进行索引优化,能够带来非常明显的性能提升。
在《向量数据库入坑指南:聊聊来自元宇宙大厂 Meta 的相似度检索技术 Faiss》一文中,我提到过 “为向量索引进行分区优化” 和 “尝试使用基于量化的索引类型” 两种优化方案。
如果你想只使用向量检索,并且尽可能准确的搜索到所有的最接近的图片内容,那么直接进行分区优化就是最好的方案,在不影响搜索精度的前提下,我们能够获得非常大的性能提升。

而如果,数据量极大,我们希望尽可能节约向量数据库使用的内存或磁盘空间,则可以采用量化分区的方案。
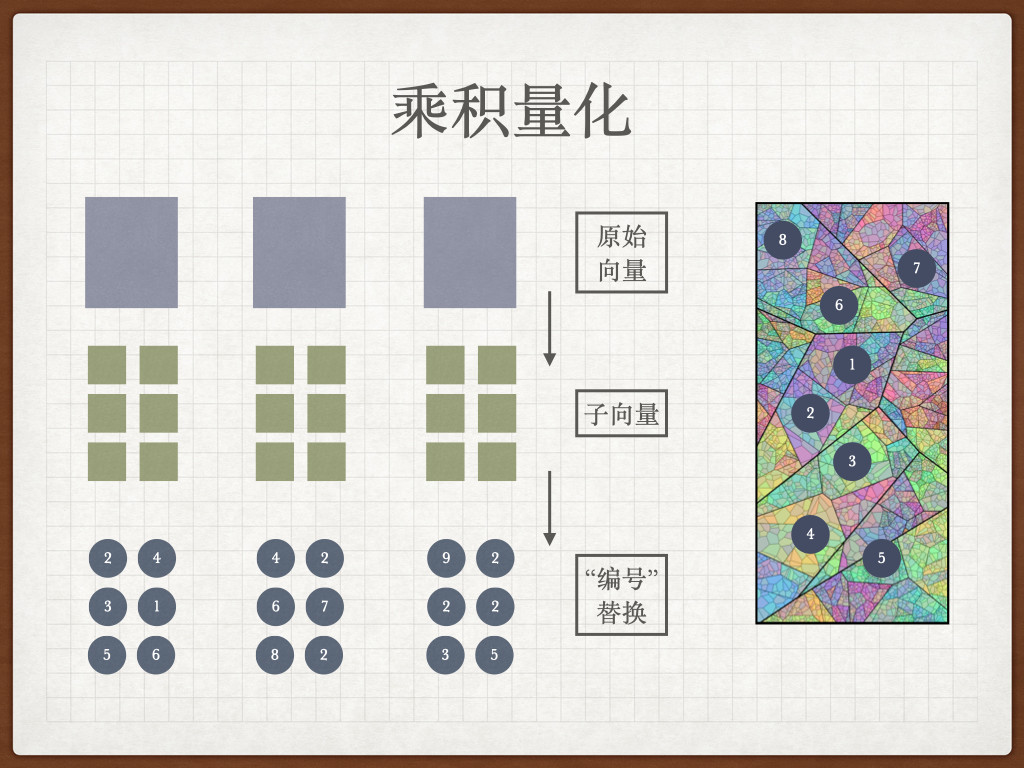
索引只有适不适合你的场景的方案,没有最好最差一说。
对图片进行预先分类,减少每个数据库中的图片总量
即使我们可以通过上面的操作来实现非常大规模的数据的索引和查询,但是代价是我们需要的硬件规格会变高、成本也会增加。
在聊 Clip 的第一种使用方式时,我们发现可以通过传入文本,来对图像进行分类,进行类似“分库分表”的操作,让每个分类中的数据都变的精准,数据量更低一些,查询遍历性能更低。
如果我们选择对一个非常大的数据集,进行一些预分类的 ETL 整理操作,让每个数据库中将存储的数据都在合理的数量级内,那么单一数据库中的查询计算压力将会降低非常多,也就能够同时在不同的数据库中进行并行查询,带来非常明显的搜索性能提升。
扩展图片信息,增加搜索维度
当然,除了上面的这些“空间换时间”的把戏之外,我们还可以提升可搜索的维度,让搜索结果的数据来源和维度更丰富。
比如,我们可以同时将文件名、文件类型、创建时间、甚至是文件所在的网页或者视频文件的描述都存到数据库中进行“组合式查询”。
除此之外,Clip 主打理解和匹配图片与文本,还有一类模型,则主打理解图片的内容,并转换为文本。我们可以通过类似 Blip 模型,来将图片进行预先的处理,对每一张图片进行“图片内容描述生成”。
那么,在搜索的时候,就不单单能够通过“关键词”的向量和“图片”向量的相似度来返回结果了,还可以直接使用“关键词”的文本向量和“图片描述”的文本向量进行相似匹配。
细粒度提取图片内容并解析
在图片被模型描述和解析的时候,因为很多原因,模型会“抓大放小”,只输出和保留主要部分,而可能忽略掉画面中的一些微小的元素。
如果我们预先对图像进行目标检测和切分,再对内容进行向量化处理,那么在搜索的时候,除了能够和原始内容对比之外,我们还能够和这些从图像中抽取出来的内容进行查找对比。而这些被检测出的物品,在此之前可能根本不会被模型注意到。
强化文本搜索能力
之前的文章里,我们吐槽过,目前的搜索很多都是纯纯的关键词匹配。
举个例子,比如我之前在另外一篇文章提到过(“借助平面索引,完成基础的相似内容查询功能”),我想在哈利波特中搜索“哈利波特猛然睡醒”的片段内容,这个内容绝对是不曾在书里体现,依赖传统的关键词匹配是碰不到内容的,但是确实有相关片段。如果使用语义查询,我们能够很明确的搜索到“哈利做噩梦惊醒”的相关描写。
如果你想了解这块相关的内容,还可以阅读这篇文章《向量数据库入坑:传统文本检索方式的降维打击,使用 Faiss 实现向量语义检索》,在此就不赘述啦。
最后
好啦,目前老牌数据库产品中,最轻量的向量数据库 Redis 就先聊到这里啦。
或许晚些时候,我会再展开聊聊这篇文章尚未完全展开的部分。
—EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾、彼此坦诚相待的小伙伴。
我们在里面会一起聊聊软硬件、HomeLab、编程上、生活里以及职场中的一些问题,偶尔也在群里不定期的分享一些技术资料。
关于交友的标准,请参考下面的文章:
致新朋友:为生活投票,不断寻找更好的朋友
当然,通过下面这篇文章添加好友时,请备注实名和公司或学校、注明来源和目的,珍惜彼此的时间 😄
关于折腾群入群的那些事
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2023年11月16日
统计字数: 10022字
阅读时间: 21分钟阅读
本文链接: https://soulteary.com/2023/11/16/use-redis-to-build-a-lightweight-vector-database-application-image-search-engine-part-2.html
相关文章:
使用 Redis 构建轻量的向量数据库应用:图片搜索引擎(二)
本篇文章我们来继续聊聊轻量的向量数据库方案:Redis,如何完成整个图片搜索引擎功能。 写在前面 在上一篇文章《使用 Redis 构建轻量的向量数据库应用:图片搜索引擎(一)》中,我们聊过了构建图片搜索引擎的…...

Java-贪吃蛇游戏
前言 此实现较为简陋,如有错误请指正。 其次代码中的图片需要自行添加地址并修改。 主类 public class Main {public static void main(String[] args) {new myGame();} }游戏类 import javax.swing.*; import java.awt.event.KeyEvent; import java.awt.event.…...
Python---数据序列类型之间的相互转换
list()方法:把某个序列类型的数据转化为列表 # 1、定义元组类型的序列 tuple1 (10, 20, 30) print(list(tuple1))# 2、定义一个集合类型的序列 set1 {a, b, c, d} print(list(set1))# 3、定义一个字典 dict1 {name:刘备, age:18, address:蜀中} print(list(dict1…...

gitlab 12.7恢复
一 摘要 本文主要介绍基于gitlab 备份包恢复gitlab 二 环境信息 科目老环境新环境操作系统centos7.3centos7.6docker19.0.319.0.3gitlab12.712.7 三 实施 主要有安装docker\docker-compose\gitlab 备份恢复三个文件 1.gitlab 配置文件gitlab.rb 2.gitlab 加密文件gitlab-s…...
将ECharts图表插入到Word文档中
文章目录 在后端调用JS代码准备ECharts库生成Word文档项目地址库封装本文示例 EChartsGen_DocTemplateTool_Sample 如何通过ECharts在后台生成图片,然后插入到Word文档中? 首先要解决一个问题:总所周知,ECharts是前端的一个图表库…...
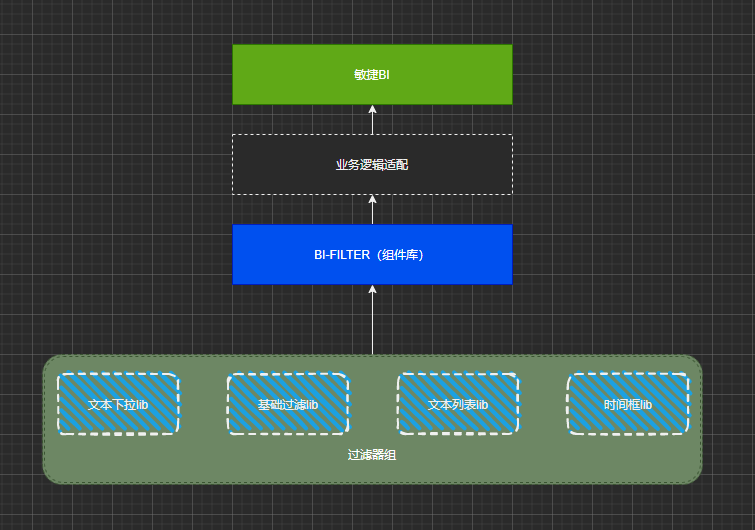
BI 数据可视化平台建设(2)—筛选器组件升级实践
作者:vivo 互联网大数据团队-Wang Lei 本文是vivo互联网大数据团队《BI数据可视化平台建设》系列文章第2篇 -筛选器组件。 本文主要介绍了BI数据可视化平台建设中比较核心的筛选器组件, 涉及组件分类、组件库开发等升级实践经验,通过分享一些…...
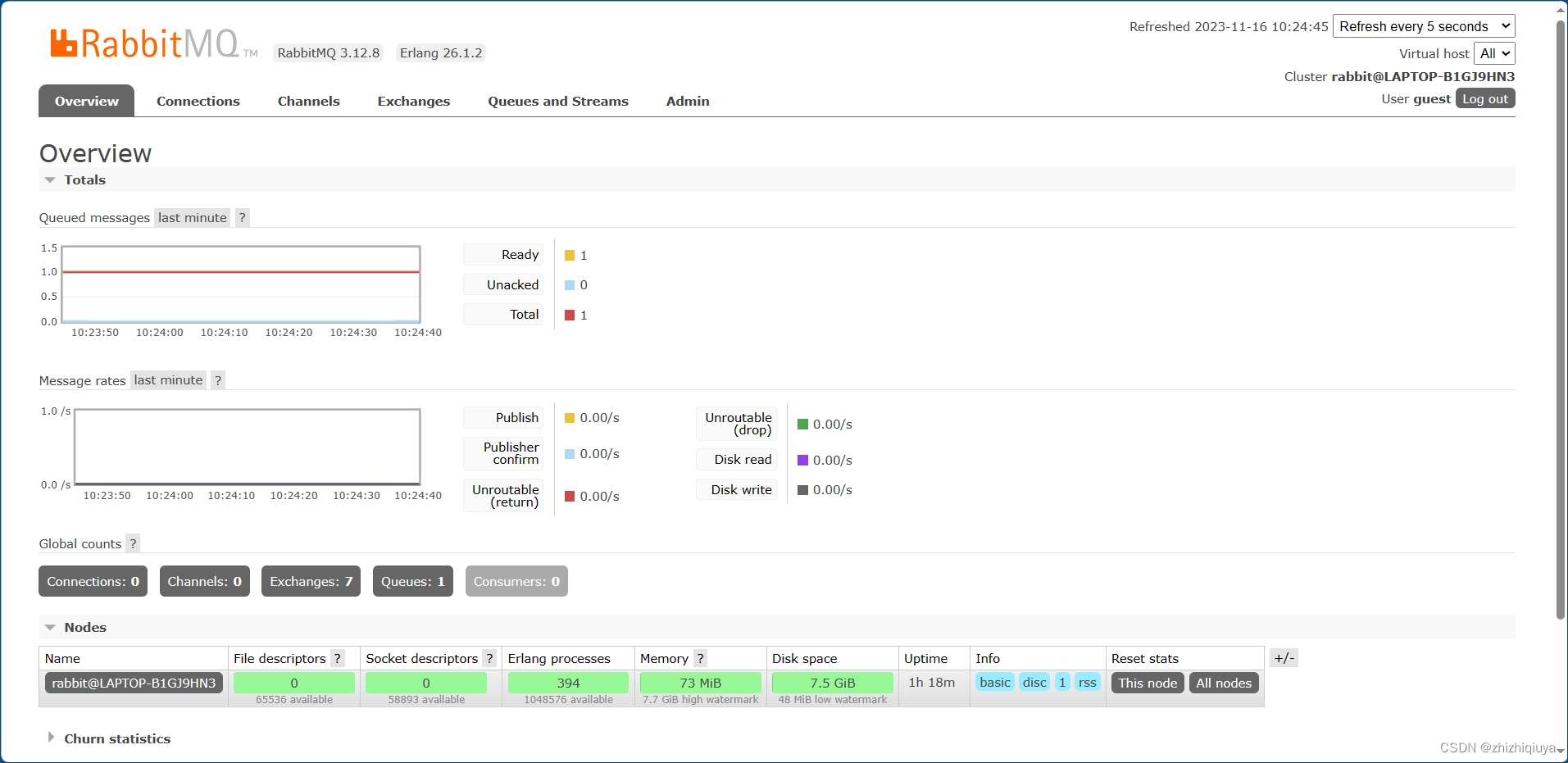
RabbitMQ 安装及配置
前言 当你准备构建一个分布式系统、微服务架构或者需要处理大量异步消息的应用程序时,消息队列就成为了一个不可或缺的组件。而RabbitMQ作为一个功能强大的开源消息代理软件,提供了可靠的消息传递机制和灵活的集成能力,因此备受开发人员和系…...

PHP写一个电商 Api接口需要注意哪些?考虑哪些?
随着互联网的飞速发展,前后端分离的开发模式越来越流行。编写一个稳定、可靠和易于使用的 API 接口是现代互联网应用程序的关键。本文将介绍在使用 thinkphp6 框架开发 电商API 接口时需要注意的要点和考虑的问题,并提供详细的逻辑步骤和代码案例。 1. …...
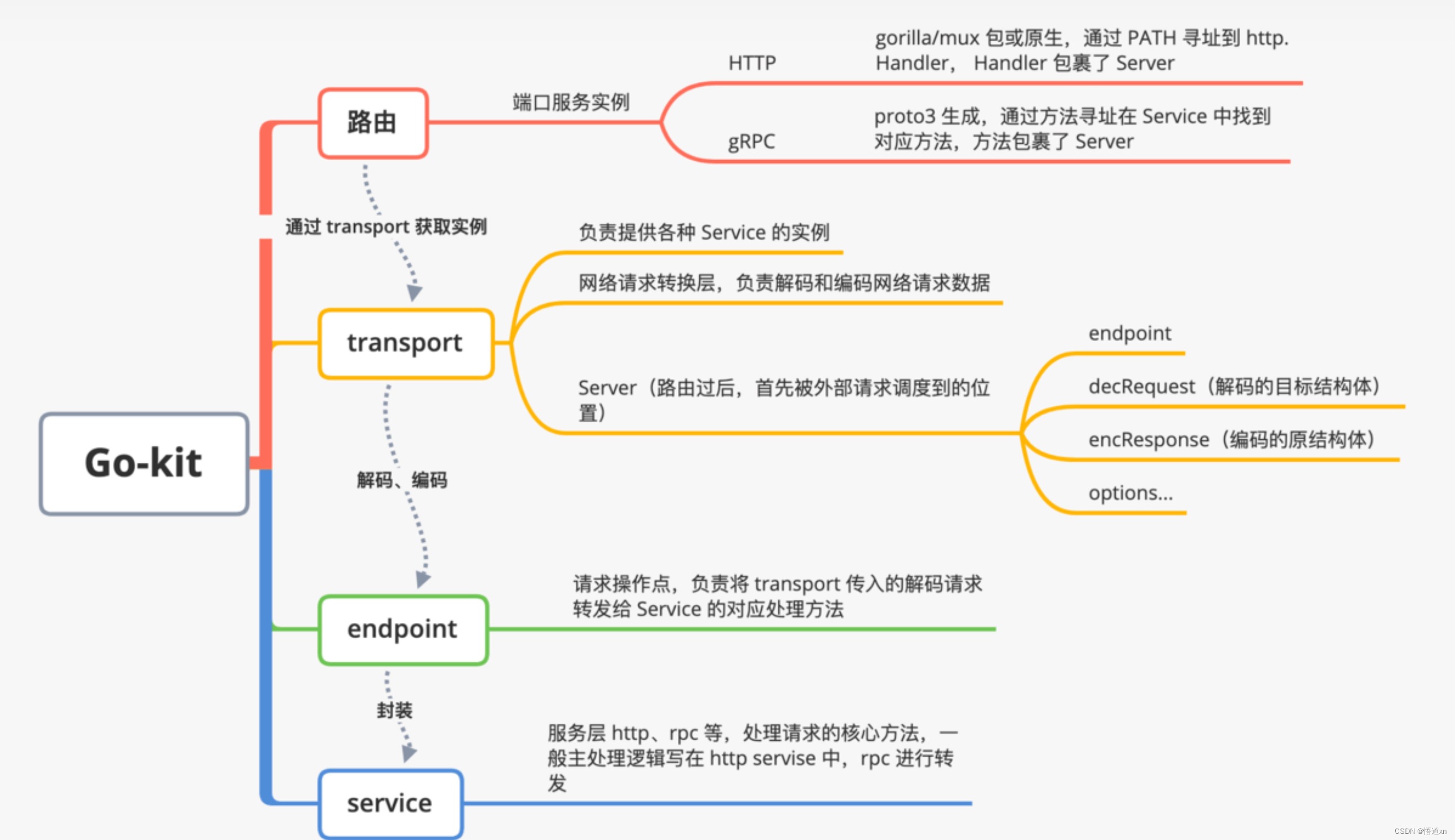
微服务概览
单体架构 传统的软件应用为单体架构。尽管也是模块化逻辑,但是最终还是会打包并并部署为单体应用。最主要的原因是太复杂。并且应用扩展性低,可靠性也低。敏捷开发和部署变得无法完成。 治理办法:化繁为简,分而治之。 微服务起源…...
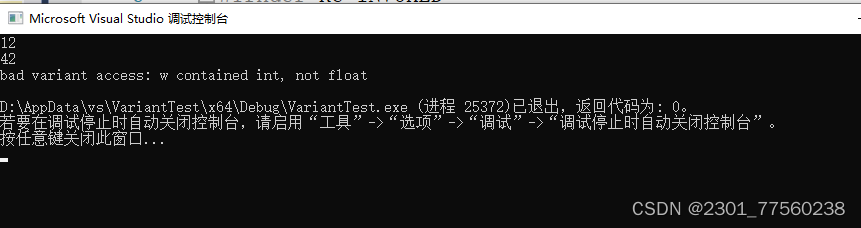
本地新建vs工程运行c++17std::varant
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结 前言 提示:这里可以添加本文要记录的大概内容: 例如:…...
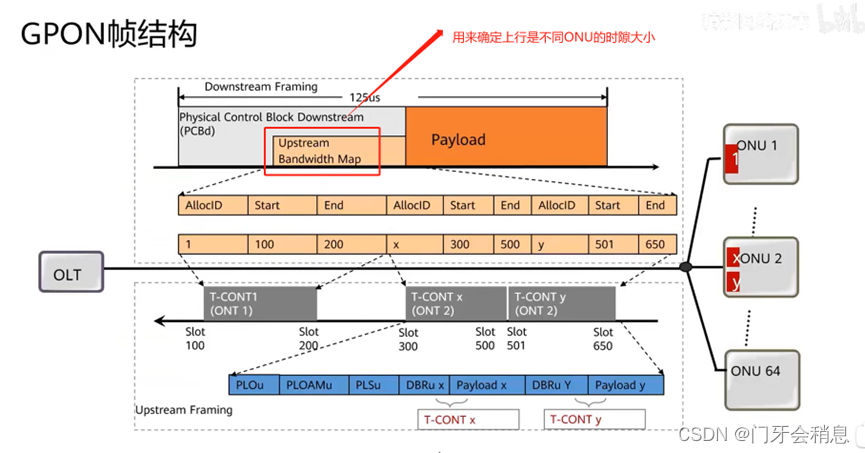
GPON、XG(S)-PON基础
前言 本文主要介绍了GPON、XG(S)-PON中数据复用技术、协议、关键技术、组网保护等内容,希望对你有帮助。 一:GPON数据复用技术 下行波长:1490nm,上行波长:1310nm 1:单线双向传输(WDM技术&am…...

CSS实现图片滑动对比
实现效果图如下: css代码: 知识点:resize: horizontal; 文档地址 <style>.image-slider {position: relative;display: inline-block;width: 500px;height: 300px;}.image-slider>div {position: absolute;top: 0;bottom: 0;left: …...
苹果电脑录屏快捷键,让你成为录屏达人
“苹果电脑录屏好麻烦呀,操作步骤很繁琐,有人知道苹果电脑怎么快速录屏呀,要是有快捷键就更好了,大家知道苹果电脑有录屏快捷键吗?谢谢啦!” 苹果电脑以其直观的用户界面和卓越的性能而闻名,而…...
)
9.2 Plotting with pandas and seaborn(用pandas和seaborn绘图)
9.2 Plotting with pandas and seaborn(用pandas和seaborn绘图) matplotlib是一个相对底层的工具。pandas自身有内建的可视化工具。另一个库seaborn则是用来做一些统计图形。 导入seaborn会改变matplotlib默认的颜色和绘图样式,提高可读性和美感。即使不适用seaborn的API,…...
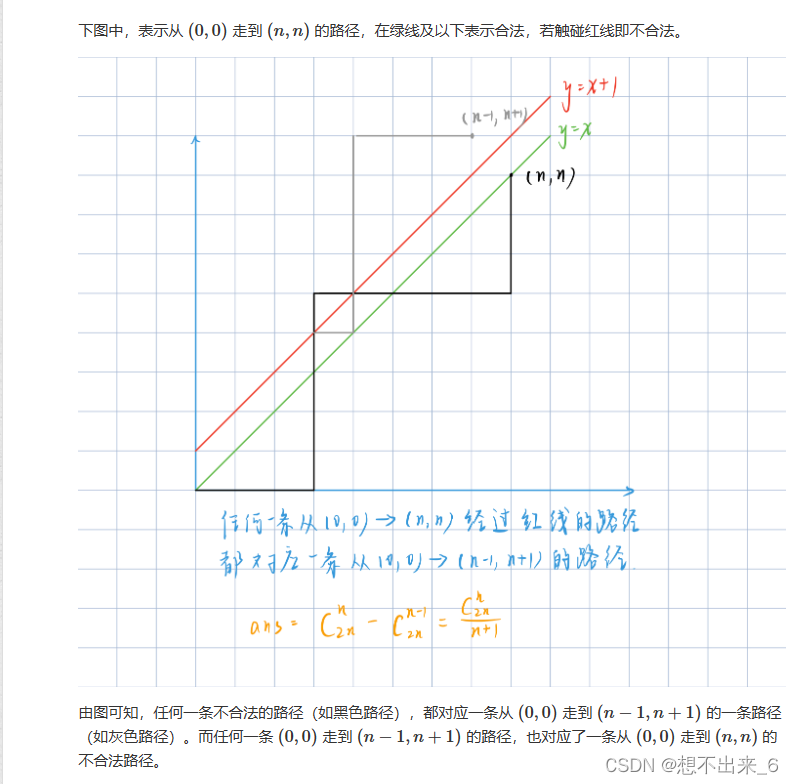
01序列 卡特兰数
解法: 将01序列置于坐标轴上,起始点为原点。0表示向右走,1表示向上走。这样就可以将前缀0的个数不少于1的个数就可以转换为路径上的点,横坐标大于纵坐标,也就是求合法路径个数。 注意题目mod的数是质数,所…...
java实现快速排序
图解 快速排序是一种常见的排序算法,它通过选取一个基准元素,将待排序的数组划分为两个子数组,一个子数组中的元素都小于基准元素,另一个子数组中的元素都大于基准元素。然后递归地对子数组进行排序,直到子数组的长度为…...

【Spring Boot】034-Spring Boot 整合 JUnit
【Spring Boot】034-Spring Boot 整合 JUnit 文章目录 【Spring Boot】034-Spring Boot 整合 JUnit一、单元测试1、什么是单元2、什么是单元测试3、为什么要单元测试 二、JUnit1、概述简介特点 2、JUnit4概述基本用法 3、JUnit5概述组成 4、JUnit5 与 JUnit4 的常用注解对比 三…...

基于安卓android微信小程序的师生答疑交流平app
项目介绍 本课题研究的是基于HBuilder X系统平台的师生答疑交流APP,开发这款师生答疑交流APP主要是为了帮助用户可以不用约束时间与地点进行所需信息。本文详细讲述了师生答疑交流APP的界面设计及使用,主要包括界面的实现、控件的使用、界面的布局和异常…...

开发一个接口,需要考虑什么
开发一个对外接口,一般会考虑以下因素: 用户需求:首先要考虑用户的需求,了解他们希望通过接口实现什么样的功能,以及他们期望接口具备怎样的特性和性能。 可扩展性:接口需要具备良好的可扩展性,…...

【owt】owt-p2p的vs工程构建
owt的p2p代码构建一个静态库 Build started... 1>------ Build started: Project: owtTalkP2P, Configuration: Debug Win32 ------ 1>p2ppeerconnectionchannel.cc 1>g:\webrtc_m98_yjf\src\media\base\codec.h : warning C4819: The file contains a character that…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

基于SMD与贝壳的微型音频装置:从电路设计到嵌入式开发的完整实践
1. 项目概述:一个藏在贝壳里的声音世界你小时候有没有捡起一个海螺壳,把它贴在耳边,然后听到里面传来“呜呜”的海风声?那个瞬间,仿佛整个海洋都被装进了小小的贝壳里。今天这个项目,就是把那个童年的魔法&…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...