ICCV 23丨3D-VisTA:用于 3D 视觉和文本对齐的预训练Transformer
来源:投稿 作者:橡皮
编辑:学姐

论文链接:https://arxiv.org/abs/2308.04352
开源代码:http://3d-vista.github.io
摘要:
3D视觉语言标定(3D-VL)是一个新兴领域,旨在将3D物理世界与自然语言连接起来,这对于实现具身智能至关重要。当前的 3D-VL 模型严重依赖复杂的模块、辅助损失和优化技巧,这需要简单且统一的模型。在本文中,我们提出了 3D-VisTA,这是一种用于 3D 视觉和文本对齐的预训练 Transformer,可以轻松适应各种下游任务。 3D-VisTA 仅利用自注意力层进行单模态建模和多模态融合,无需任何复杂的特定于任务的设计。为了进一步增强其在 3D-VL 任务上的性能,我们构建了 ScanScribe,这是第一个用于 3D-VL 预训练的大规模 3D 场景文本对数据集。 ScanScribe 包含源自 ScanNet 和 3R-Scan 数据集的 1,185 个独特室内场景的 2,995 个 RGBD 扫描,以及从现有 3D-VL 任务、模板和 GPT-3 生成的配对 278K 场景描述。 3D-VisTA 通过屏蔽语言/对象建模和场景文本匹配在 ScanScribe 上进行预训练。它在各种 3D-VL 任务上取得了最先进的结果,从视觉标定和密集字幕到问题回答和情境推理。此外,3D-VisTA 展示了卓越的数据效率,即使在下游任务微调期间注释有限,也能获得强大的性能。
1.引言
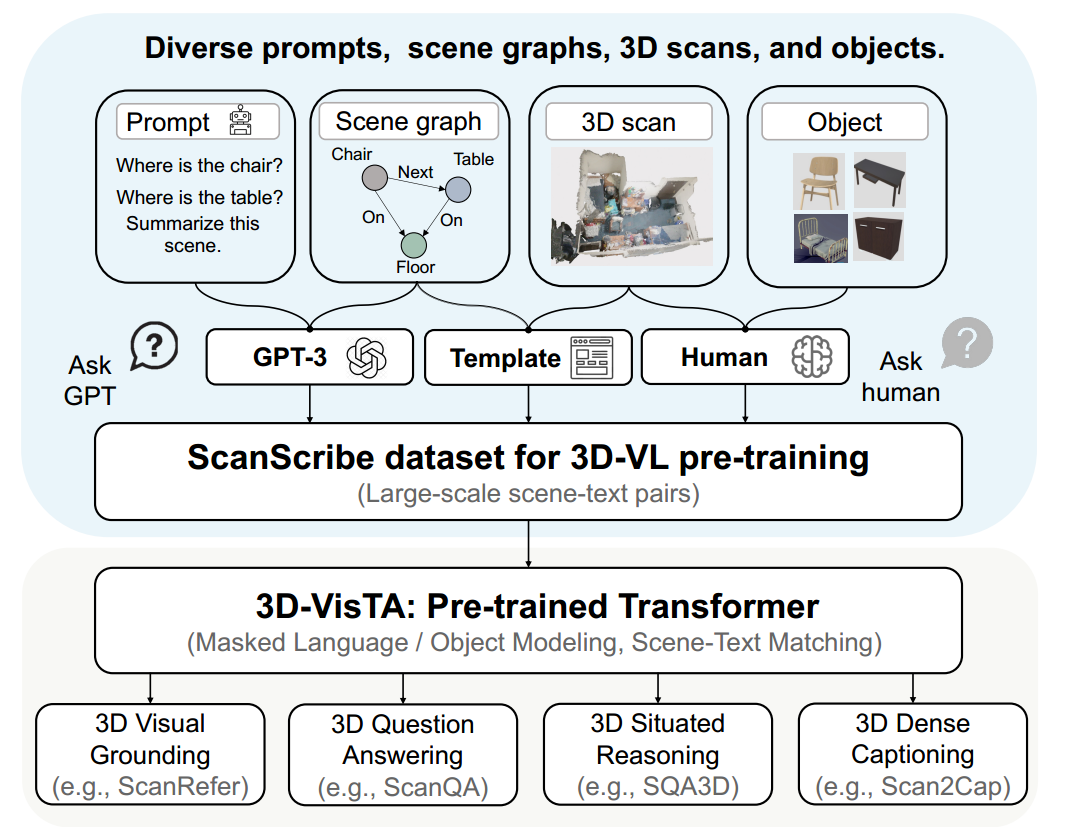
图 1:我们的 3D-VisTA 管道的总体框架。我们收集各种提示、场景图、3D 扫描和对象来构建 ScanScribe 数据集。通过自监督预训练,3D-VisTA 支持各种下游任务,包括 3D 视觉标定、密集字幕、问题回答和情境推理。
将 3D 物理世界与自然语言结合起来是实现具体人工智能的关键一步,其中智能代理可以理解并进一步执行现实世界中的人类指令。最近,3D 视觉语言 (3D-VL) 任务引起了越来越多的兴趣,包括 3D 视觉标定 、密集描述、语法学习、问题回答、和情境推理。
然而,大多数为 3D-VL 开发的模型仅关注其中一两个 3D-VL 任务,并采用特定于任务的设计。例如,3D-SPS和BUTD-DETR通过关注VL特征并检测每一层中的对象来逐步发现目标对象。 3DVG、MVT和 ViL3DRel通过将空间关系信息显式地注入模型设计中来改进 3D 视觉标定。 3DJCG通过具有两个独立的特定任务头的共享 3D 对象备选模块联合学习 3D 密集字幕和视觉标定。此外,训练这些模型通常需要手动指定的辅助损失(例如,3D 对象检测/分类和文本分类)或优化技巧(例如,知识蒸馏)。由于缺乏简单且统一的方法,在开发通用 3D-VL 模型方面存在巨大差距。
为了填补这一空白,我们引入了 3D-VisTA,这是一种基于 Transformer 的 3D 视觉和文本对齐模型,可以轻松适应各种下游任务。与之前设计复杂的特定任务模块的模型不同,我们只是利用普通的自注意力Transformer进行 3D-VisTA 中的单模态建模和多模态融合。作为进一步增强 3D 空间理解的通用方法,我们将对象之间的成对空间关系显式编码为 3D 对象建模的自注意力权重。
受到 NLP、CV和 2D-VL大规模预训练成功的启发,我们建议在 3D 场景文本数据上预训练 3D-VisTA,旨在在 3D-VL 任务上获得更好的性能。为此,我们构建了 ScanScribe,这是第一个用于 3D-VL 预训练的大规模 3D 场景文本对数据集。我们首先从 ScanNet和 3R-Scan数据集中收集室内场景的 RGB-D 扫描。我们还根据类别随机将场景中的一些对象替换为 Objaverse 3D 对象数据库中的对象,以增加对象多样性。为了获取文本,我们将基于 ScanNet 的现有数据集的文本转换为场景描述,包括来自 ScanQA的问答对以及来自 ScanRefer和 ReferIt3D的引用表达式。我们进一步利用 3R-Scan 扫描的场景图注释 ,并采用模板和 GPT-3从场景图生成场景描述。 ScanScribe 总共包含 278K 3D 场景文本对,用于 1,185 个室内场景的 2,995 次 RGB-D 扫描,以及 56.1K 个唯一对象实例。
我们在提出的 ScanScribe 数据集上预训练 3D-VisTA。我们的预训练任务包括屏蔽语言建模、屏蔽对象建模和场景文本匹配。值得注意的是,类似的目标在 2D-VL 领域被广泛采用,但在 3D-VL 领域却很少被探索。所提出的预训练过程有效地学习了 3D 点云和文本之间的对齐,从而消除了下游任务微调中辅助损失和优化技巧的需要。在六个具有挑战性的 3D-VL 任务上,从视觉标定(即 ScanRefer、Nr3D/Sr3D )和密集字幕(即 Scan2Cap)到问题回答(即 ScanQA)和情境推理(即 SQA3D),微调的 3D-VisTA 将 ScanRefer 上的 SOTA 结果提高了 8.1% (acc@0.5),在 Sr3D 上提高了 3.6%,在 Scan2Cap 上提高了 10.1%(C@0.25),在ScanQA 提高了 3.5%/2.1% (EM@1),SQA3D 提高了 1.9%。此外,3D-VisTA 展示了卓越的数据效率,只需对这些下游任务进行 30% 的注释即可获得出色的结果。
我们的主要贡献可以概括如下:
-
我们提出了3D-VisTA,一个简单且统一的Transformer,用于对齐3D 视觉和文本。所提出的 Transformer 简单地利用了自注意力机制,没有任何复杂的特定于任务的设计。
-
我们构建了ScanScribe,这是一个大规模3D-VL 预训练数据集,其中包含278K 3D 场景文本对,用于对1,185 个独特室内场景进行2,995 次RGB-D 扫描。
-
我们引入了一种用于 3D VL 的自监督预训练方案,具有掩码语言/对象建模和场景文本匹配。它有效地学习3D点云和文本对齐,并进一步简化和改进下游任务微调。
-
我们对 3D-VisTA 进行微调,并在各种 3D-VL 任务上实现最先进的性能,从视觉标定和密集字幕到问题回答和情境推理。 3D-VisTA 还展示了卓越的数据效率,即使注释有限也能获得出色的结果
2.相关工作
「3D 视觉语言学习。」 最近,人们对 3D 视觉语言 (3D-VL) 学习的兴趣日益浓厚。与传统的场景理解不同,3D-VL 任务将物理世界与自然语言连接起来,这对于实现体现智能至关重要。在这个新兴领域,Chen 等人和 Achlioptas 等人同时引入了 ScanRefer 和 ReferIt3D 数据集,用于对 3D 对象属性和关系的自然语言标定进行基准测试。除了 3D 视觉标定之外,Azuma 等人还开发了一个名为 ScanQA 的 3D 问答数据集,该数据集需要一个模型来回答有关给定 3D 场景的对象及其关系的问题。最近,Ma 等人提出了一种名为 SQA3D 的情境推理任务,用于 3D 场景中的具体场景理解。
已经针对这些基准提出了几种模型。值得注意的是,3D-SPS和BUTD-DETR通过利用交叉注意机制和语言指导逐步发现目标对象。 3DVG、MVT和 ViL3DRel通过将空间关系信息明确地注入到其模型中来解决 3D 视觉标定问题。尽管这些工作在桥接 3D 视觉和语言方面取得了令人印象深刻的成果,但它们仍然严重依赖模型设计中特定于任务的知识和复杂的优化技术。相比之下,所提出的 3D-VisTA 通过一个简单的基于 Transformer 的架构统一了视觉标定、问答和情境推理。训练 3D-VisTA 也很简单,不需要任何辅助损失或复杂的优化技术。请参阅表 1,了解 3DVisTA 与其他 3D-VL 模型之间的详细比较。任务、辅助损失和架构。

表 1:3D-VisTA 与其他模型之间的比较任务、辅助损失和特定于任务的架构。“VG”代表视觉标定,“QA”代表问题回答,“SR”代表情境推理,“DC”代表密集字幕。 “DET”代表对象检测损失,“KD”代表知识蒸馏损失,“O-CLS”代表对象分类损失,“T-CLS”代表文本分类损失。 “CA”代表交叉注意力,“2D”代表2D特征,“MV”代表多视图特征,“LC”代表语言条件模块。
「大规模预训练。」 近年来,大规模预训练已成为自然语言处理(NLP)、计算机视觉(CV)和2D视觉与语言(2D-VL)领域的基石。基于 Transformer 的架构,特别是 BERT和 GPT的引入,导致了各种 NLP 任务的显着改进。这些模型的成功促进了更先进的预训练技术的发展,例如 XLNet和 RoBERTa。这些模型在各种 NLP 任务上都取得了最先进的性能,包括文本分类、问答和语言生成。 CV 中最成功的预训练方法是 ImageNet预训练,它已被用作各种下游任务(例如对象检测和图像分割)的起点。最近,基于 Transformer 的模型(例如 ViT和 Swin Transformer)的引入导致了各种 CV 任务的显着改进。由于预训练技术,2D-VL 领域也取得了重大进展。特别是,ViLBERT和 LXMERT模型的引入在视觉问答和图像字幕等任务上取得了最先进的性能。最近,CLIP、ALIGN Flamingo的发展表明,对图像文本对进行大规模预训练可以带来更好的跨模态理解和上下文学习的出现以零样本或少样本的方式。
尽管大规模预训练已成为 NLP、CV 和 2D-VL 中的关键技术,但在 3D-VL 中却很少被探索。 探索视觉标定和密集字幕的多任务学习,然后进一步微调每个任务的模型。缺乏大规模预训练数据集可能会阻碍 3D-VL 预训练的探索。因此,我们构建了 ScanScribe,这是第一个用于 3D-VL 预训练的大规模 3D 场景文本对数据集。如表 2 所示,ScanScribe 比现有的 3D-VL 数据集大得多,并且文本也更加多样化。在 ScanScribe 上预训练 3D-VisTA 使 3D-VL 任务有了显着改进,因此我们相信 ScanScribe 可以推动未来 3D-VL 预训练的探索。

表 2:ScanScribe 与其他 3D-VL 数据集之间的比较。 “VG”代表视觉标定,“QA”代表问答,“SR”代表情境推理,“PT”代表预训练。 “词汇。”表示文本词汇量。
3.3D-VisTA
在本节中,我们介绍 3D-VisTA,一个简单且统一的 Transformer,用于对齐 3D 场景和文本。如图2所示,3D-VisTA以一对场景点云和句子作为输入。它首先通过文本编码模块对句子进行编码,并通过场景编码模块处理点云。然后,通过多模态融合模块将文本和 3D 对象标记融合,以捕获 3D 对象和文本之间的对应关系。 3D-VisTA 使用自我监督学习进行预训练,可以轻松针对各种下游任务进行微调。接下来,我们详细描述每个模块。
3.1 文本编码
我们采用四层 Transformer 将句子 S 编码为文本标记序列 {wcls, w1, w2, ···, wM},其中 wcls 是特殊分类标记([CLS]),M 是句子长度。该文本编码模块由预训练的 BERT的前四层初始化。
3.2场景编码
给定 3D 场景的点云,我们首先使用分割掩模将场景分解为一袋对象。分割掩模可以从地面实况或实例分割模型获得。对于每个对象,我们采样 1024 个点并将它们的坐标标准化为单位球。然后将对象点云输入PointNet++以获得其点特征和语义类。我们将点特征 fi 、语义类嵌入 ci 和位置 li (即 3D 位置、长度、宽度、高度)组合为对象标记 i 的表示:
![]()
其中 Wc 和 Wl 是附加投影矩阵,用于将 ci 和 li 映射到与 fi 相同的维度。
为了进一步提供对象的上下文表示,我们通过将对象标记注入四层 Transformer 来捕获对象到对象的交互。受之前工作的启发,我们将对象的成对空间关系显式编码到 Transformer 中(图 2 中的空间transformer)。更具体地说,我们定义对象对 i, j 的成对空间特征:
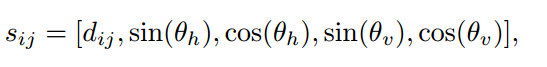
其中 dij 是欧几里德距离,θh、θv 是连接对象 i、j 中心的线的水平角和垂直角。成对的空间特征 S = [sij ] ∈ R N×N×5 用于调节 Transformer 中自注意力层的注意力权重:
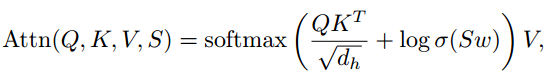
其中 w ∈ R 5 用于将空间特征映射到注意力分数,σ 是 sigmoid 函数。

图 2:我们的 3D-VisTA 的模型架构,包括文本编码、场景编码和多模态融合模块。 3D-VisTA 通过自监督学习目标进行预训练,其中包括屏蔽语言建模、屏蔽对象建模和场景文本匹配。通过添加轻量级任务头,预训练的 3D-VisTA 可以轻松适应各种下游任务,而无需辅助损失和优化技巧等特定于任务的设计。
3.3 多模态融合
我们简单地将文本和 3D 对象标记连接起来,并将它们发送到 L 层 Transformer(图 2 中的统一transformer)以进行多模态融合。可学习的类型嵌入被添加到标记中以区分文本和 3D 对象。我们将多模态融合模块的输出分别表示为 [CLS]、文本标记和 3D 对象标记的 {wcls, w1:M, o1:N }。
3.4 自监督预训练
为了以自我监督的方式学习 3D 场景和文本对齐,我们通过以下代理任务在 3D 场景-文本对上预训练 3D-VisTA:
「掩码语言建模MLM。」 我们按照BERT预训练[15]进行MLM:(1)随机选择15%的文本标记; (2) 80%的时间:将这些标记替换为[MASK]; (2) 10%的时间:用一些随机文本标记替换这些标记; (3) 10%的时间:这些代币保持不变。该模型经过训练,可以在给定剩余文本和 3D 对象标记的情况下预测屏蔽文本标记:
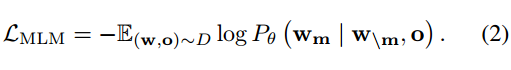
「蒙版对象建模MOM。」 与 MLM 类似,我们屏蔽了 10% 的 3D 对象标记。然而,我们通过仅用可学习的掩码嵌入替换其点特征和语义嵌入(即等式(1)中的“fi + Wcci”)来掩蔽 3D 对象标记,但保留其位置信息(即等式(1)中的“Wl li”)等式(1))不变。该模型经过训练,利用被遮蔽对象的位置线索在给定剩余 3D 对象和文本的情况下预测其语义类别 c:
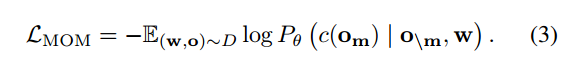
「场景文本匹配STM。」 虽然屏蔽语言和对象建模能够以细粒度实现本地文本-对象对齐,但我们还执行场景-文本匹配以增强场景和文本的全局融合,我们发现这对于下游问答任务非常有益。更具体地说,我们提取对应于 [CLS] 的输出作为输入场景-文本对的全局表示,并将其输入到两层 MLP 中以预测场景和文本是否匹配:

实际上,训练批次中 30% 的样本是负对,通过用随机选择的样本替换场景点云或文本来创建。
「最终的损失。」 我们的最终预训练目标是通过简单地添加上面代理任务的损失来获得的:
![]()
值得注意的是,所提出的预训练方案是自监督且与任务无关的,这与之前的工作[7]中使用的需要任务监督的监督多任务学习不同。
3.5 下游任务微调
通过添加轻量级任务头,预训练的 3D-VisTA 可以轻松适应各种 3D-VL 任务。更具体地说,我们在以下任务上微调 3D-VisTA:
「3D 视觉标定。」 任务模型根据引用表达式在 3D 场景中定位目标对象。为了找到被引用的对象,我们对每个对象标记 oi 应用两层 MLP,并获得该对象被引用的概率。该模型使用交叉熵损失进行微调。
「3D 密集字幕。」 引入用于测试模型检测和描述 3D 场景中的对象的能力。我们采用 w1:M 并自回归预测文本标记来生成句子。该模型使用交叉熵损失进行微调。
「3D问答。」 需要一个模型来回答给定 3D 场景的与对象相关的问题。我们将文本标记 w1:M 和对象标记 o1:N 馈送到模块化共同注意网络(MCAN)中以产生答案。该模型使用 QA 损失和对象定位损失进行微调。
「3D 情境推理。」 用于对具体代理的 3D 场景理解进行基准测试。为了使 3D-VisTA 适应此任务,我们将情况描述和问题连接成一个输入句子。答案分类类似于3D问答任务。该模型使用答案损失进行微调。
一般来说,我们发现使 3D-VisTA 适应这些下游任务比以前的方法简单得多,因为 3D-VisTA 仅使用任务损失进行微调,而不需要任何辅助损失(例如,句子/对象分类损失)或优化技巧(例如,多视图聚合和知识蒸馏)。这使得 3D-VisTA 成为更加统一和通用的 3D-VL 模型。
4.SceneScribe
近年来,大规模预训练被广泛用于提高 CV、NLP和 2D-VL中下游任务的性能。然而,大规模预训练在 3D-VL 领域几乎没有涉及,可能是由于缺乏 3D-VL 预训练数据集。为了促进 3D-VL 预训练的探索,我们构建了一个大规模 3D 场景文本对数据集,名为 ScanScribe。如表 3 所示,ScanScribe 中 3D 场景文本对的构建包括两部分:
3D 场景。我们从 ScanNet和 3R-Scan收集室内场景的 RGB-D 扫描。为了增加这些场景中 3D 对象的多样性,每个场景中 10% 的对象实例根据类别随机替换为 Objaverse 3D 对象数据库中的对象。
对于每个 ScanNet 和 3R-Scan 对象类别,我们从 Objaverse 下载大约 40 个对象实例作为候选对象替换。结果,我们收集了 1,185 个室内场景的 2,995 个 RGB-D 扫描,其中包含 56.1K 个独特的对象实例。
文本。对于来自 ScanNet 的扫描,我们将基于 ScanNet 的现有数据集的文本转换为场景描述,包括来自 ScanQA的问答对以及来自 ScanRefer和 ReferIt3D的引用表达式。对于 3RScan 的扫描,我们采用模板和 GPT-3根据场景图注释生成场景描述。具体来说,对于每个对象,我们首先从场景图中提取所有 〈object、relation、neighbor〉 三元组。然后,我们使用模板“这是一个对象,邻居与对象有关系”来生成描述。请注意,我们仅在基于模板的生成中选择少于 7 个邻居的对象。我们进一步探索使用 GPT-3 来生成描述,并提示“对象与邻居有关系......(重复直到所有邻居都被使用)。对象在哪里?或者概括一下场景。”最终,为收集的 3D 场景生成 278K 场景描述。

表 3:ScanScribe 的组成。 * 我们仅使用Objaverse为其他两个数据集中的3D场景提供候选对象替换;因此不会生成场景文本对。
5.实验
5.1 实验设置
实施细节。预训练运行 30 个 epoch,批量大小为 128。我们使用 AdamW优化器,β1 = 0.9,β2 = 0.98。学习率设置为 1e -4 ,预热步骤为 3,000 步,并进行余弦衰减。在预训练期间,我们使用ground-truth分割掩模来生成对象级点云。在微调期间,我们使用ground-truth掩模或Mask3d,这取决于任务设置。在 ScanRefer 数据集上,我们还合并了 PointGroup,以便与以前的方法进行比较。在消融研究中,为了简单起见,我们在所有任务中都使用真实掩模。预训练和微调均在单个 NVIDIA A100 80GB GPU 上进行。
3D 视觉标定。我们针对此任务在三个数据集上评估我们的模型:ScanRefer、Nr3D 和 Sr3D。对于 Nr3D/Sr3D,我们按照 ReferIt3D使用地面实况对象掩模并将结果报告为地面精度,即模型是否在地面实况对象建议中正确选择了引用的对象。对于 ScanRefer,我们使用检测器生成的目标备选并将结果报告为 Acc@k(k ∈ {0.25, 0.5}),即预测框与真实情况重叠且 IoU > 的引用查询的比例k.
3D 密集字幕 我们在 Scan2cap 数据集上评估我们的模型,并报告不同框重叠率下的文本相似度度量。
3D问答。我们在 ScanQA 数据集上评估我们的模型,并使用精确匹配(EM@1 和 EM@10)作为评估指标。我们还报告了几个句子评估指标,包括 BLEU-4、ROUGE、METEOR 和 CIDEr。我们的评估中使用了 ScanQA 的两个测试集(带或不带对象)。
3D 情景推理 我们在 SQA3D 数据集上评估我们的模型,并报告不同类型问题下的答案准确性作为评估指标。
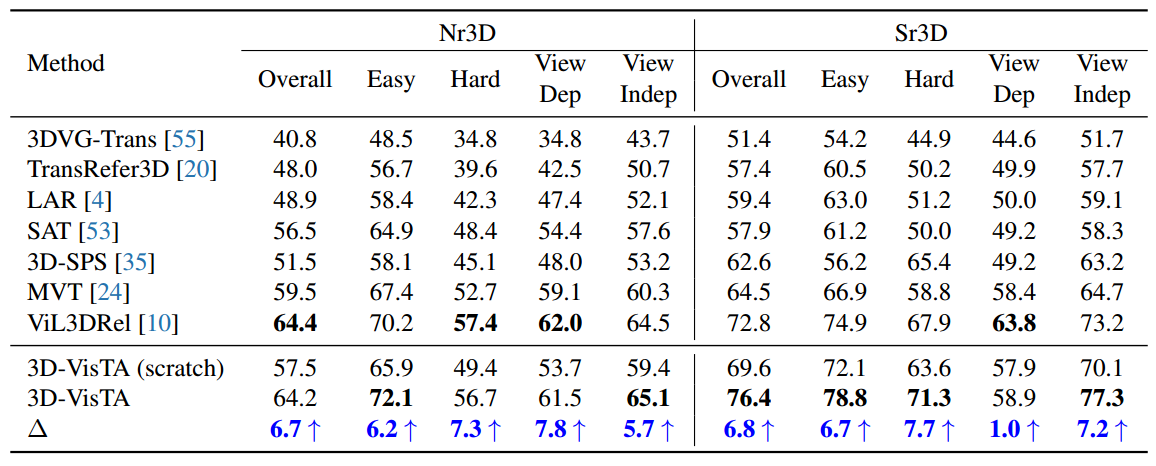
表 4:Nr3D 和 Sr3D 与地面实况对象建议的接地精度 (%)。 Δ 表示 3D-VisTA 和 3D-VisTA(从头训练)之间的性能差异。 3D-VisTA 在 Nr3D 上取得了与 SOTA 竞争的结果,并在 Sr3D 上优于 SOTA。

表 5:ScanRefer 上检测到的目标建议的接地准确度 (%)。 “Det”表示模型中使用的 3D 对象检测模块。 “VN”代表 VoteNet,“PG”代表 PointGroup,M3D 代表 Mask3D,而“Opt.”则代表 VoteNet。表示联合优化 ScanRefer 上的对象检测器。 Mask3D 通过提供更准确的对象备选显着提高了标定精度。
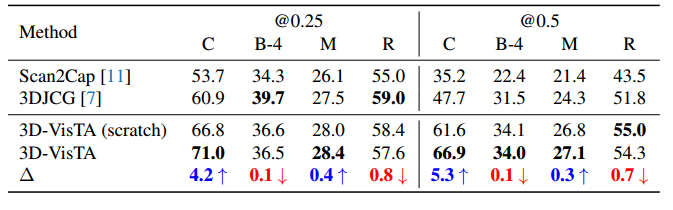
表 6:Scan2Cap 数据集上的字幕结果。 “C”代表“CIDEr”,“B-4”代表“BLEU-4”,“M”代表“METEOR”,“R”代表“ROUGE”。 “@0.25”和“@0.5”表示预测框和真实框之间的重叠率。
5.2 下游任务结果
在本节中,我们讨论下游任务的实验结果,并将所提出的 3D-VisTA 模型与最先进的 (SOTA) 方法进行比较。结果如表 4 至表 8 和图 3 所示,这些结果的主要观察结果如下:
-
「即使从头开始训练,3D-VisTA 也能通过 SOTA 方法实现具有竞争力的性能。」 具体来说,3D-VisTA(scratch)在 Nr3D 和 Sr3D 上获得了 57.5% 和 69.6% 的总体准确率,优于大多数之前的模型;它在 ScanQA 上的 EM@1 准确率为 25.2%,比 SOTA 高 1.7%。值得注意的是,3DVisTA 仅使用任务损失在这些数据集上进行训练,没有任何辅助损失或优化技巧,这表明 3D-VisTA 是用于 3D-VL 任务的非常简单但有效的架构。
-
「ScanScribe 上的预训练显着提高了 3D-VisTA 的性能。」 总体而言,预训练将 Nr3D/Sr3D 上的准确率提高了 6.7%/6.8%,ScanRefer 上的 acc@0.25/0.5 提高了 4.7%/4.3%,ScanQA 上的 EM@1 提高了 1.8%/2.6%,C @0.25 在 Scan2Cap 上提高了 4.2%,在 SQA3D 上的平均准确度提高了 1.8%。这些重大改进巩固了 ScanScribe 在 3D-VL 预训练方面的功效。
-
「预训练的 3D-VisTA 的性能大幅优于 SOTA。」 3D-VisTA 在 Sr3D 上比 ViL3DRel 好 3.6%,在 ScanRefer 上比 ViL3DRel好 2.7%/8.1% (acc@0.25/0.5),比 ScanQA好 3.5%/2.1 (EM@1),比 Scan2Cap SOTA10.1 %/19.2% (C@0.25/0.5),SQA3D 1.9%(平均)。 3D-VisTA 为这些 3D-VL 任务创造了新记录,并可能激发未来 3D-VL 预训练的研究。
-
「对带有有限注释的下游任务进行 3D-VisTA 的微调取得了很好的结果。」 如图 3 所示,使用 ScanRefer 和 ScanQA 上 30% 和 40% 的注释进行微调,预训练的 3D-VisTA 可以比使用完整数据从头开始训练的 3D-VisTA 获得更好的性能。我们假设 3D-VisTA 通过预训练成功捕获了 3D 对象和文本之间的对齐,因此能够轻松适应各种格式的下游任务。它还揭示了 3D-VisTA 以零样本或少样本方式学习看不见的任务的潜力,这种潜力已经通过大规模预训练出现在 NLP和 2D-VL中。

表 7:使用 Mask3D 的对象备选对 ScanQA 进行回答的准确性。每个条目表示“带对象的测试”/“不带对象的测试”。
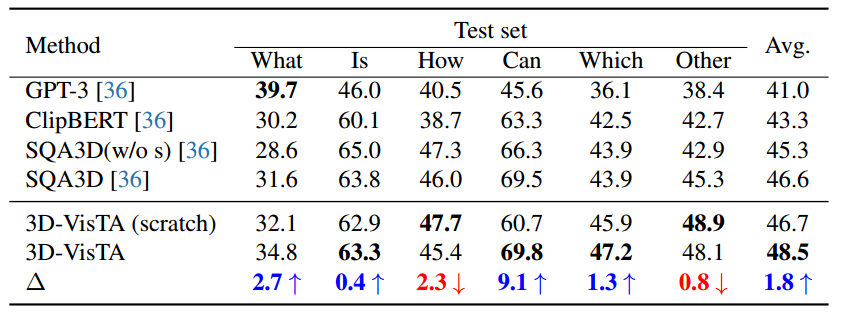
表 8:使用 Mask3D 的对象备选在 SQA3D 上回答准确性。预训练可以改善大多数问题类型的结果。
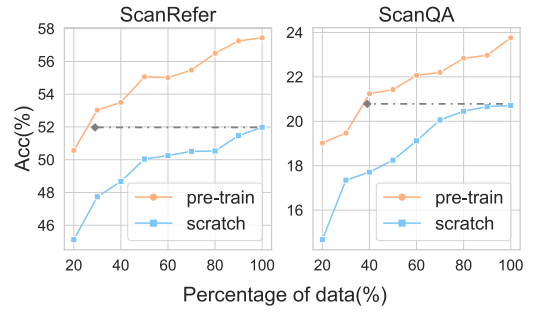
图 3:使用不同数量的训练数据微调 3D-VisTA 的性能。
5.3 消融实验
在本节中,我们进行消融研究来分析几个重要超参数的影响,包括 Transformer 深度、预训练目标和数据量。
「Transformer深度。」 由于模型大小是 NLP 和 2D-VL 预训练的关键因素,因此我们通过改变多模态融合模块中的层数来研究Transformer 深度的影响。如表 9a 所示,使用 4 层可实现最佳性能,简单地添加更多层并无帮助。这一观察结果与 NLP 和 2D-VL 的观察结果有些矛盾。它指出,尽管 ScanScribe 比现有的 3D-VL 数据集大得多,但仍远远不足以释放 3D-VL 领域预训练的全部潜力。
「预训练目标。」 表 9b 介绍了预训练目标的消融研究。传销目标本身对问答(QA)略有好处,但对视觉标定(VG)带来负面影响。添加 MOM 和 STM 可以提高 QA 和 VG 的性能,这凸显了 MOM 和 STM 对于对齐 3D 视觉和文本的重要性。总体而言,同时使用所有三个目标可以使这两项任务获得最佳性能,其中 STM 和 MOM 可以最大程度地提高准确性。
「预训练数据。」 表 9c 展示了使用各种预训练数据配置的结果。我们可以看到,简单地使用与下游任务来自同一领域的 ScanNet 数据进行预训练,可以在 VG 和 QA 方面带来显着的改进。这验证了预训练的有效性,即使在下游任务没有额外 3D 数据的情况下也是如此。添加 3R-Scan 和 Objaverse 增加了 3D 数据的数量和多样性,从而进一步提高了 VG 和 QA 的准确性。总体而言,当使用所有三个数据源时,这两项任务都可以获得最佳性能。这为改进 3D-VL 任务指明了一条有希望的途径——收集更多数据进行预训练。

表 9:3D-VisTA w.r.t. 的消融研究Transformer 深度、预训练目标和预训练数据。我们报告了 ScanRefer 上视觉标定 (VG) 的精度和 ScanQA 上问答 (QA) 的 EM@1 精度。
5.4 定性研究和其他结果
在本节中,我们进行了额外的研究,以更好地了解预训练的帮助。如图4所示,预训练提高了3D-VisTA对视觉标定的空间理解,因此它可以更好地与人类先前的观点和空间关系推理保持一致。当模型需要将目标对象与同一类的多个实例区分开来时,这非常有帮助。预训练还有助于更好地理解颜色和形状等视觉概念,以及回答问题和情境推理的情况。此外,预训练增强了长文本与 3D 场景对齐的能力,如图 5 中较长查询的较大改进所证明的那样。
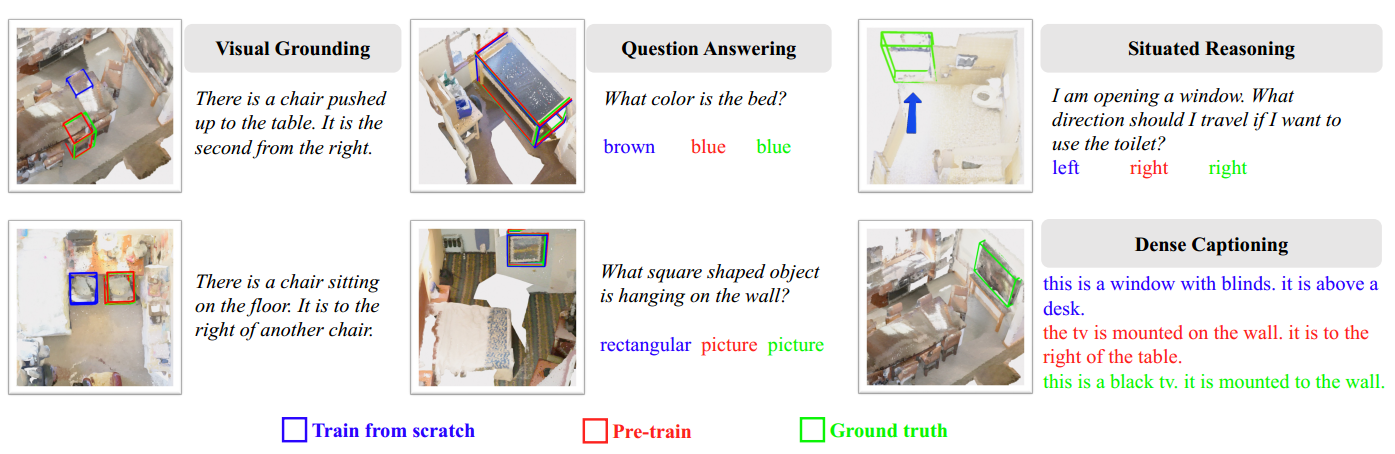
图 4:各种任务的定性结果。斜体文本代表输入,蓝色框或文本代表从头开始训练的 3D-VisTA 的预测,红色代表预先训练的 3D-VisTA 的预测,绿色代表基本事实。结果表明,预训练提高了对空间关系、视觉概念和情境的理解。
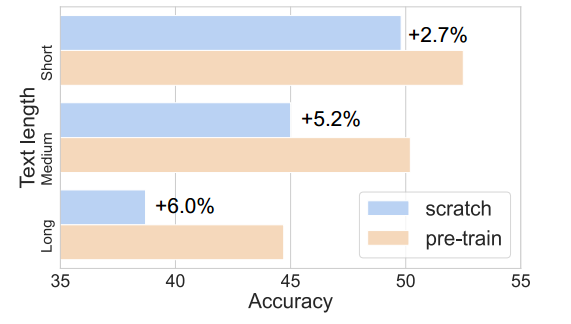
图 5:ScanRefer 中不同句子长度(≤ 15、≤ 30、> 30)的从头训练和预训练之间的性能差距。
6.结论
本文提出了 3D-VisTA,这是一种用于 3D-VL 任务的简单而有效的架构。该模型仅使用自注意力层,可以轻松适应各种下游任务,而不需要任何辅助损失或优化技巧。我们还介绍了 ScanScribe,这是第一个用于 3D-VL 预训练的大规模 3D 场景文本对数据集。预训练的 3D-VisTA 在各种 3D-VL 任务上取得了最先进的结果,具有卓越的数据效率,为未来 3D-VL 任务的标定模型铺平了道路。
未来的作品。目前,3D-VisTA使用离线3D物体检测模块,这可能是进一步改进的瓶颈。在预训练阶段联合优化目标检测模块是未来一个有趣的方向。此外,ScanScribe中的数据量仍然不足以进行大规模3D-VL预训练,因此扩大预训练数据集以及模型大小是进一步改进3D-VL学习的一个有希望的方向。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“ViT200”获取全部论文+代码合集
码字不易,欢迎大家点赞评论收藏!
相关文章:
ICCV 23丨3D-VisTA:用于 3D 视觉和文本对齐的预训练Transformer
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://arxiv.org/abs/2308.04352 开源代码:http://3d-vista.github.io 摘要: 3D视觉语言标定(3D-VL)是一个新兴领域,旨在将…...

SFP-10G-SR光模块指南
SFP-10G-SR通常是思科(Cisco)使用的型号名。是一种用于非常短距离应用的最低成本、最低功耗的10G SFP模块。本文汇总了初学者在第一阶段关于10G SFP SR模块的常见问题。 SFP-10G-SR模块是否支持GE? 10GBASE-SR模块本身是可以支持GE速度的&am…...

使用Java实现一个简单的贪吃蛇小游戏
一. 准备工作 首先获取贪吃蛇小游戏所需要的头部、身体、食物以及贪吃蛇标题等图片。 然后,创建贪吃蛇游戏的Java项目命名为snake_game,并在这个项目里创建一个文件夹命名为images,将图片素材导入文件夹。 再在src文件下创建两个包࿰…...
智能运维监控告警6大优势
随着云计算和互联网的高速发展,大量应用需要横跨不同网络终端,并广泛接入第三方服务(如支付、登录、导航等),IT系统架构越来越复杂。 快速迭代的产品需求和良好的用户体验,需要IT运维管理者时刻保障核心业务稳定可用,…...

保姆级使用Vue-count-to
安装 npm install vue-count-to 直接使用 <template><div class"vue-count-to"><div class"count-to"><div><CountTo :startValstartVal :endValendVal :durationduration /></div><div><CountTo :startV…...

install YAPI MongoDB 备份mongo 安装yapi插件cross-request 笔记
登录容器 docker exec -it mongodb bash 登录mongo mongo -u root -p 123456 查看db show dbs 查看collection show collections 进入db use yapi 查看数据 db.<collection_name>.find() 带条件查看 db.<collection_name>.find({ <field>: <value>…...
WPA-hashcat渗透)
无线WiFi安全渗透与攻防(N.4)WPA-hashcat渗透
WPA-hashcat渗透 WPA-hashcat渗透1.hashcat介绍2.渗透姿势1.查看网卡2.开启监听模式3.扫描wifi4.抓包保存5.进行冲突模式攻击6.重新连接wifi7.生成hccap文件8.破解WPA-hashcat渗透 严重声明:cpu加速都是幌子,aricrack-ng也用cpu,不然用爱跑的? 1.hashcat介绍 Hashcat系列…...
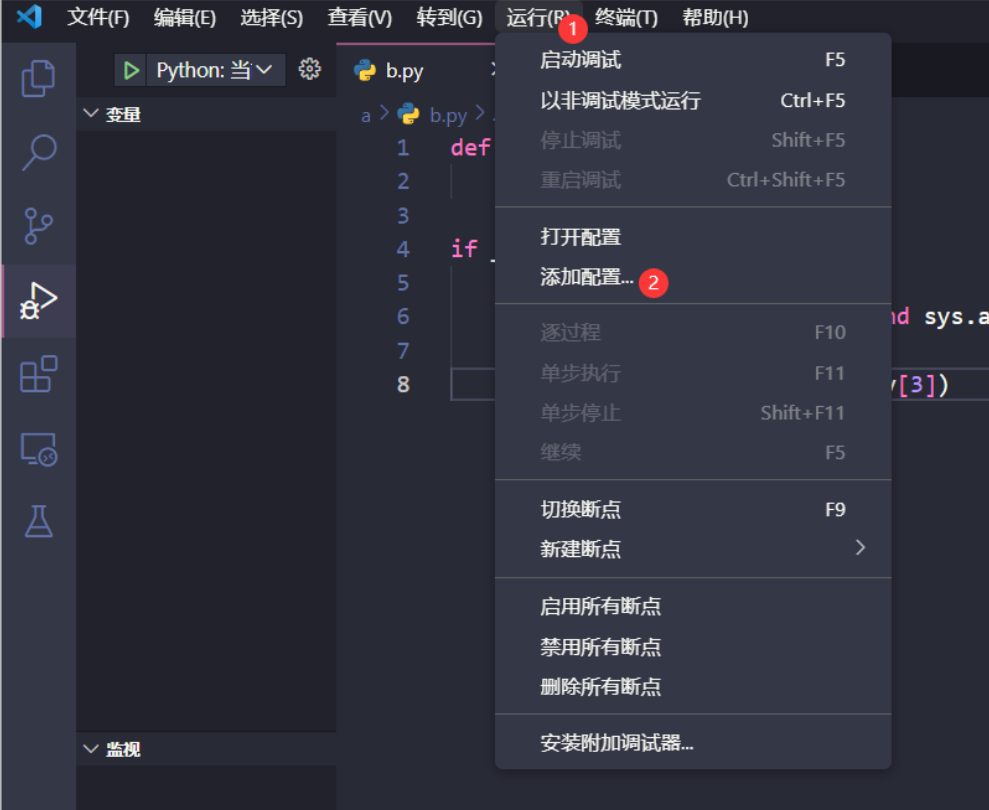
使用VSCode进行Python模块调试
使用VSCode进行Python模块调试 创建测试文件 创建文件test/a/b.py,且当前工作路径为test/ b.py文件内容: def cal(numa, numb):print(int(numa) int(numb))if __name__ "__main__":import sys# 判断系统参数长度是否为4且判断第2个参数是…...

【数据结构高阶】二叉搜索树
接下来我们来开始使用C来详细讲解数据结构的一些高阶的知识点 本期讲解的是二叉搜索树,对于初阶二叉树有所遗忘的同学可以看到这里: 【精选】【数据结构初阶】链式二叉树的解析及一些基本操作 讲解二叉搜索树主要是为了后面的map和set做铺垫ÿ…...
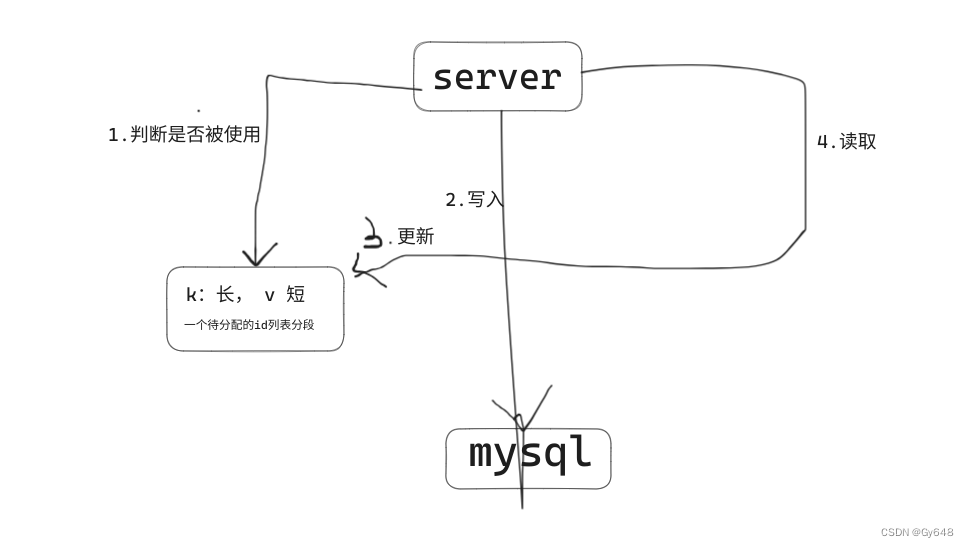
如何设计短域名系统
输入可能是 一个冗长的域名,过期时间和自定义的别名输出 自定义别名或者随机生成的短域名,在过期时间到来之前访问都可以被重定向到冗长的域名上约束条件 1.过期后就失效 2.短域名是唯一的 3.自定义短域名长度在7个字符(不包含域名长度&am…...
web缓存-----squid代理服务
squid相关知识 1 squid的概念 Squid服务器缓存频繁要求网页、媒体文件和其它加速回答时间并减少带宽堵塞的内容。 Squid代理服务器(Squid proxy server)一般和原始文件一起安装在单独服务器而不是网络服务器上。Squid通过追踪网络中的对象运用起作用。…...

nginx-location和proxy_pass的url拼接
在proxy_pass中端口号后面如果加入了"/",则location 匹配的内容全部去掉; Nginx中proxy_pass末尾带斜杠/和不带的区别 一、proxy_pass末尾有斜杠 location /api/ { proxy_pass http://127.0.0.1:8000/; } 请求地址:http://localhost/api/test 转发地…...

从零开始配置离线服务器
1.复制环境(包含torch包) 使用conda pack进行环境迁移(步骤很详细)_小舟%的博客-CSDN博客 注意:用pack的时候会默认把生成的tar.gz保存到当前目录,所以提前需要观测好在哪 注意:公用的环境必…...

Spring事务和事务的传播机制
目录 Spring中事务的实现 MySQL中的事务使用 Spring 编程式事务 TransactionTemplate 编程式事务 TransactionManager编程式事务 Spring声明式事务 Transactional 参数说明 事务因为程序异常捕获不会自动回滚的解决方案 Transactional 原理 Spring 事务隔离级别 Spring…...
软件开发提效工具——低代码(Low-Code)
目录 一、什么是低代码(Low-Code)? 二、构建轻量化平台 1、软件开发快效率高 2、满足企业的多样化需求 3、轻松与异构系统集成 4、软件维护成本低 5、为企业实现降本增效 三、小结 一、什么是低代码(Low-Code)…...
菜单栏管理软件 Bartender 3 mac中文版功能介绍
Bartender 3 mac是一款菜单栏管理软件,该软件可以将指定的程序图标隐藏起来,需要时呼出即可。 Bartender 3 mac功能介绍 Bartender 3完全支持macOS Sierra和High Sierra。 更新了macOS High Sierra的用户界面 酒吧现在显示在菜单栏中,使其…...

ef core code first pgsql
在使用efcode来操作pgsql的时候,总有些基础配置流程项目建立完之后后面就很少用,总是忘掉,写个文档记忆一下吧。基于net 6.0。 1.创建一个mvc项目和一个EF类库 2.在类库里面安装依赖dll Microsoft.EntityFrameworkCore.Design 需要添加的…...

容器化nacos部署并实现服务发现(gradle)
1.如何容器化部署mysql 2. 如何容器化部署nacos 为不暴露我的服务器地址,本文全部使用localhost来代替服务器地址,所有的localhost都应该调整为你自己的服务器地址。 为不暴露我的服务器地址,本文全部使用localhost来代替服务器地址&#x…...

金融行业如何数字化转型?_光点科技
金融行业的数字化转型涉及技术创新的引入、客户体验的改善、内部流程的优化、安全和合规性的加强以及员工技能和企业文化的转变。 技术创新 包括云计算、人工智能、大数据分析和区块链技术的采用。云计算增强数据处理的灵活性,AI和机器学习在风险评估和欺诈检测方面…...
【LeetCode刷题-滑动窗口】--1695.删除子数组的最大得分
1695.删除子数组的最大得分 注意:子数组为不同元素 方法:滑动窗口 使用变长滑动窗口寻找数组nums中的以每个下标作为结束下标的元素各不相同的最长子数组。用[start,end]表示滑动窗口,初始时startend0,将滑动窗口的右端点end向右…...

RedisDesktopManager Windows版:3分钟掌握免费Redis可视化工具,告别命令行操作!
RedisDesktopManager Windows版:3分钟掌握免费Redis可视化工具,告别命令行操作! 【免费下载链接】RedisDesktopManager-Windows RedisDesktopManager Windows版本 项目地址: https://gitcode.com/gh_mirrors/re/RedisDesktopManager-Window…...

《当下的力量》前三章深度解读:从思维奴隶到临在大师的觉醒之路
《当下的力量》前三章深度解读:从思维奴隶到临在大师的觉醒之路这是一本不能用大脑读的书,这是一本需要用生命去体验的书。——张德芬前言 在这个信息爆炸、节奏飞快的时代,我们似乎永远活在过去的遗憾和未来的焦虑中。我们的大脑像一台永不停…...

QMCDecode:终极QQ音乐格式解密指南,一键解放你的加密音乐库
QMCDecode:终极QQ音乐格式解密指南,一键解放你的加密音乐库 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&…...

扫地机器人行业 企业篇-石头科技
石头科技成立于2014年,2016年为小米代工推出首款米家扫地机器人,凭借自研LDS激光雷达导航技术快速打开市场。2020年登陆科创板,此后逐步减少对小米的依赖,专注自有品牌Roborock,定位高端市场。公司性质为A股科创板上市公司,总部位于北京。截至2025年6月底,研发人员规模达…...

机器学习发现物理守恒量:从数据中挖掘对称性与不变性
1. 项目概述:当机器学习遇见物理学的“不变性”在物理学的世界里,对称性与守恒量是理解宇宙运行规律的基石。从牛顿时代起,我们就知道一个系统如果具有时间平移对称性,那么它的能量就是守恒的;如果具有空间平移对称性&…...

数据科学揭秘椭圆曲线秩分布:BSD参数空间的拓扑结构探索
1. 项目概述:当数论遇到数据科学如果你研究过椭圆曲线,尤其是涉足过同余数问题,那你一定对Mordell-Weil秩和BSD猜想这些概念不陌生。这些名词听起来高深,本质上是在追问一个古老而迷人的问题:一条椭圆曲线上有多少个有…...

总结模式的智能化升级
📋 本文目录 一、前言 二、从工具到智能系统的升级 三、工具链完整演示 四、智能总结Agent整合实战 五、智能总结系统的核心价值 六、总结与展望 一、前言 1.1 本节内容简介 我们已经有了5个好用的总结工具,但问题来了:工具是死的&am…...

AhMyth短信管理器:远程读取和发送短信的终极技术指南 [特殊字符]
AhMyth短信管理器:远程读取和发送短信的终极技术指南 🚀 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.c…...

通过奇异的镜子:LLM 是否像人类大脑一样记忆?
原文:通过奇异的镜子:LLM 是否像人类大脑一样记忆? |LLM|AI|人类大脑|记忆|认知| https://github.com/OpenDocCN/towardsdatascience-blog-zh-2024/raw/master/docs/img/7fcf9c5caa8b28d372dbcb4caeb706af.png 作者使用 DALL-E 创建的图片 …...
)
避坑指南:用SARIMA做时间序列预测时,这5个参数调优错误千万别犯(Python实战)
SARIMA模型调优实战:避开时间序列预测中的五大陷阱引言在数据分析领域,时间序列预测一直是个既迷人又充满挑战的课题。每当我看到那些起伏的曲线,总能感受到数据背后隐藏的故事和规律。SARIMA模型作为时间序列分析的重要工具,因其…...