Hive入门--学习笔记
1,Apache Hive概述
定义:
Hive是由Facebook开源用于解决海量结构化日志的数据统计,它是基于大数据生态圈Hadoop的一个数据仓库工具。
作用:
Hive可以用于将结构化的数据文件【映射】为一张表,并提供类SQL查询功能。
Hive的本质是将SQL转化成MapReduce程序。
使用场景:
主要用途:用来做离线数据分析,比直接MapReduce的开发效率更高。
总结作用:Hive可以简单理解为"SQL–MapReduce"框架的一个封装,可以将用户编写的SQL语句解析成对应的MapReduce程序,最终通过MapReduce运算框架形成运算结果,并提交给客户端Client。
1,Hive的优缺点
(1)优点
(a)操作接口采用类SQL语法,提供快速开发的能力;
(b)避免了直接去写MapReduce运算程序,减少开发人员的学习成本;
(c)Hive支持用户自定义函数,功能扩展很方便。
(2)缺点
(a)Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合;
(b)Hive优势在于处理大数据,对于处理小数据几乎没有优势,因为Hive的执行延迟比较高;
(c)直接使用MapReduce实现复杂查询逻辑开发难度太大,可以转而使用Hive完成。
2,Hive基础架构
(1)用户接口
用户接口包括CLI、JDBC/ODBC、WebGUI。
a)CLI(command line interface)为shell命令行;
b)JDBC/ODBC是Hive的Java实现,与传统数据库JDBC类似;
c)WebGUI是通过浏览器访问Hive。
Hive提供了Hive Shell、ThriftServer等服务进程向用户提供操作接口。
(2)元数据存储
元数据包含: 用Hive创建的database、table、表的字段等元信息。
元数据存储: 存在关系型数据库中,如:hive内置的Derby数据库或者第三方MySQL数据库等。
在Hive中,元数据存储需要使用MetaStore。
(3)Driver驱动程序
Driver包括语法解析器、计划编译器、优化器、执行器,可以完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。
生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行。
这部分内容不是具体的服务进程,而是封装在Hive所依赖的Jar文件即Java代码中。
2,当使用Hive时,与传统数据库对比,特性有
(1)Hive用于海量数据的离线数据分析;
(2)Hive具有SQL数据库的外表,但应用场景完全不同,Hive只适合用来做批量数据统计分析。
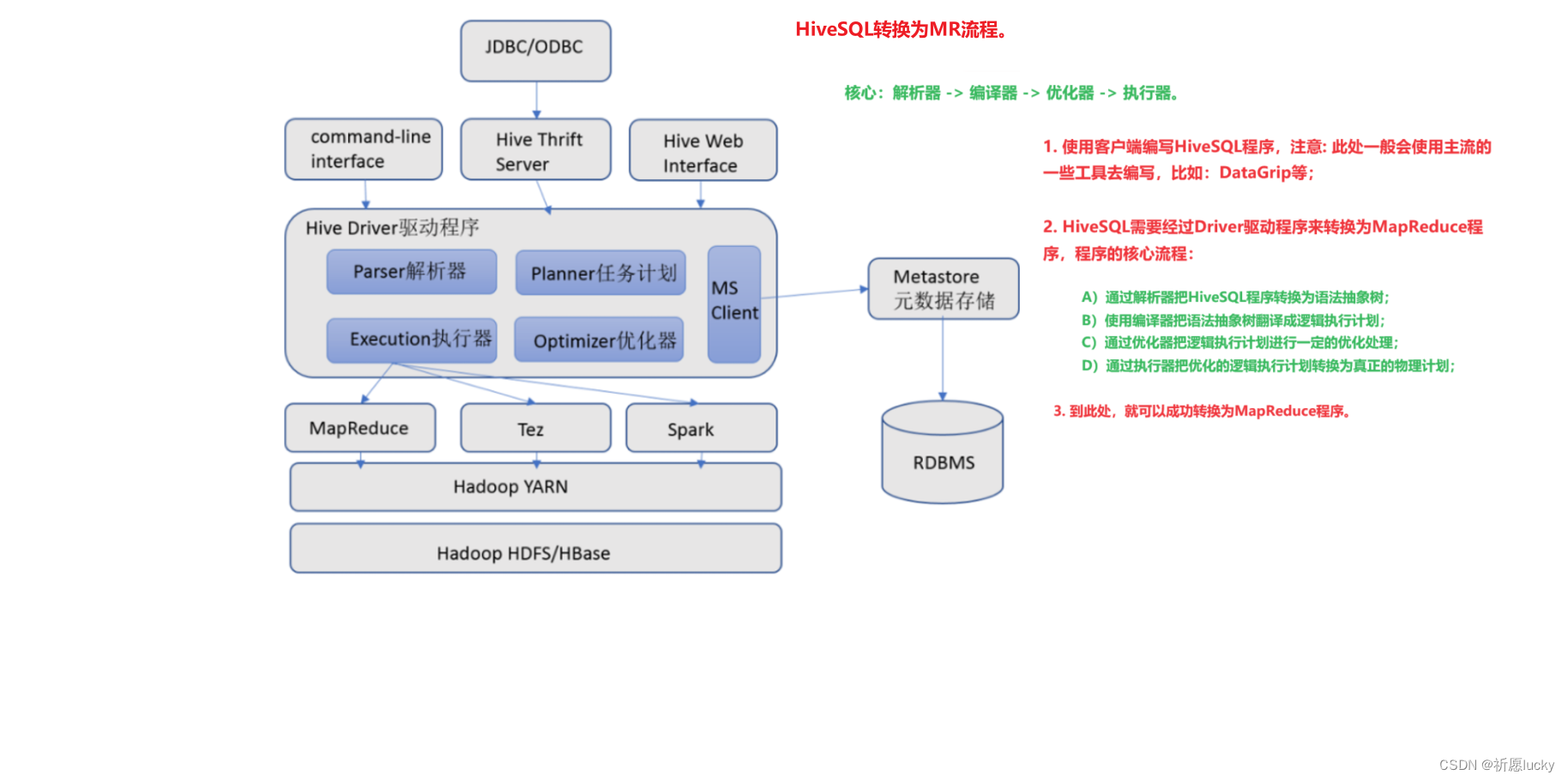
2,Hive部署
1,MetaStore元数据存储流程
(1)客户端Client连接MetaStore服务;
(2)MetaStore再去连接MySQL等关系型数据库来存取元数据。
2,存在的作用
当有了MetaStore服务后,就可以有多个客户端同时连接,且这些客户端不需要知道MySQL等数据库的用户名和密码,只需要连接MetaStore服务即可
3,MetaStore提供存储服务时,有三种不同的模式:
(1)MetaStore服务是否需要单独配置、单独启动?
(2)Metadata元数据是存储在内置库Derby中,还是第三方库MySQL等数据库中。

(1)内嵌模式
当MetaStore元数据存储采用内嵌模式时:
(1)优点:解压Hive安装包到bin/hive后,启动Hive即可使用MetaStore;(2)缺点:把Derby和MetaStore服务都嵌入在主Hive Server进程中,不适用于生产环境,原因:a)一个服务只能被一个客户端连接(如果用两个客户端以上就非常浪费资源);b)元数据不能共享。
(2)本地模式
当MetaStore元数据存储采用本地模式时:
(1)优点: 可以单独使用外部的数据库(MySQL), 元数据共享;(2)缺点: 相对浪费资源, MetaStore嵌入到了Hive进程中,每启动一次Hive服务,都内置启动了一个MetaStore。
(3)远程模式
当MetaStore元数据存储采用远程模式时:
(1)优点: 可以单独使用外部库(mysql) ,还可以共享元数据。可以连接MetaStore服务,也可以连接hiveserver2服务;(2)缺点: 需要注意如果想要启动hiveserver2服务,则先需要启动MetaStore服务。
4,启动MetaStore与HiveServer2
在hive安装的服务器上,首先启动MetaStore服务,然后启动hiveserver2服务。
(1)进入/export/server/apache-hive-3.1.2-bin/bin目录后,启动MetaStore服务,命令:
[root@node1 apache-hive-3.1.2-bin]# [nohup] ./hive --service metastore &
#启动hiveserver2服务
[root@node1 apache-hive-3.1.2-bin]# [nohup] ./hive --service hiveserver2 &
(a)查看进程是否开启,命令:
# 可以使用lsof命令查看对应进程是否开启
[root@node1 apache-hive-3.1.2-bin]# lsof -i:10000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 18804 root 520u IPv6 266172 0t0 TCP *:ndmp (LISTEN)
(b)杀死进程[关闭Hive服务]时,命令:
kill -9 进程号
2,当进程启动不成功时,需要杀死所有已经启动的runjar程序,然后再开始重新启动
5,HiveServer2服务
Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:jdbc:hive2://node1:10000。
使用Beeline客户端连接Hive时,命令:
(1)启动Beeline,进入hive的bin目录后:
./beeline(2)连接Hive
! connect jdbc:hive2://node1:10000
[root@node1 ~]# /export/server/hive/bin/beeline
Beeline version 3.1.2 by Apache Hive
beeline> ! connect jdbc:hive2://node1:10000
Connecting to jdbc:hive2://node1:10000
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node1:10000>
6,Hive环境变量
1,Shell脚本执行方式有三种:
方式一:sh执行
格式: sh 脚本
注意: 需要进入脚本的所在工作目录,然后使用对应的sh命令来执行脚本,
这种执行方式,脚本文件不需要具有可执行权限。
2,相对路径执行
格式: ./脚本
注意: 需要先进入到脚本所在的目录,然后使用 ./脚本方式执行,
这种执行方式,必须保证脚本文件具有可执行权限。
3,方式三:绝对路径执行
格式: /绝对路径/脚本
注意: 需要使用脚本的绝对路径中执行,指的是直接
4,配置Hive的环境变量,命令:
echo 'export HIVE_HOME=/export/server/apache-hive-3.1.2-bin' >> /etc/profile
echo 'export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbin' >> /etc/profile
source /etc/profile
另外的,也可以把使用Vi把如下配置Hive环境变量的语句添加到/etc/profile结尾处:
# HIVE_HOME
export HIVE_HOME=/export/server/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbin
7,Hive使用
1,使用SQL操作Hive
(1)创建表CREATE TABLE test(id INT, name STRING, gender STRING);(2)插入数据INSERT INTO test VALUES(1, '肖战', '男'), (2, '周杰伦', '男'), (3, '迪丽热巴', '女');(3)查询数据SELECT gender, COUNT(*) AS cnt FROM test GROUP BY gender;
(1)验证SQL语句启动的MapReduce程序
打开YARN的WEB UI页面查看任务情况:http://node1:8088
(2)验证Hive的数据存储
Hive的数据存储在HDFS的:/user/hive/warehouse中。
4,数据仓库和数据库
(1)数据库DataBase,简称为DB
用于把数据结果给外部各类程序使用,侧重于增删查改。
(2)数据仓库Data Warehouse,可简写为DW或DWH
用于分析历史数据而存在,为企业提供决策支持。
2,数据库和数据仓库的区别,就是说:OLTP与OLAP的区别。
(1)OLTP联机事务处理
操作型处理,叫联机事务处理OLTP(On-Line Transaction Processing,),也可以称面向交易的处理系统。
OLTP是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统,常用于数据管理,比如对数据增删查改,属于操作型处理。
(2)OLAP联机分析处理
分析型处理,叫联机分析处理OLAP(On-Line Analytical Processing),一般针对某些主题的历史数据进行分析,支持管理决策。
3,值得注意的是,数据仓库的出现,并不是要取代数据库。
通常,数据仓库的主要特征有:
a)面向主题的(Subject-Oriented )
b)集成的(Integrated)
c)非易失的(Non-Volatile)[或(不可更新性)]
d)时变的(Time-Variant )
数据仓库是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的。
4,主要区别如下:
A)数据库是面向事务的设计,数据仓库是面向主题设计的;
B)数据库一般存储业务数据,数据仓库存储的一般是历史数据;
C)数据库是为捕获数据而设计,数据仓库是为分析数据而设计
D)数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析;而数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计
数仓的分层架构
存在意义:数据仓库出于对历史数据进行分析性报告、决策支持目的而创建的。目的是构建面向分析的集成化数据环境,为企业提供决策支持。
1,数据仓库中的数据源来自企业
(1)RDBMS关系型数据库—>业务数据
(2)log file----->日志文件数据
(3)爬虫数据
(4)其他数据
2,数据仓库的发展,大致经历了三个阶段:
a)简单报表阶段
解决一些日常的工作中业务人员需要的报表,以及生成一些简单的能够帮助领导进行决策所需要的汇总数据。这个阶段的大部分表现形式为数据库和前端报表工具。
b)数据集市阶段
根据某个业务部门的需要,进行一定的数据采集、整理,按照业务人员的需要,进行多维报表的展现,能够提供对特定业务指导的数据,并且能够提供特定的领导决策数据。
c)数据仓库阶段
按照一定的数据模型,对整个企业的数据进行采集、整理,并且能够按照各个业务部门的需要,提供跨部门的,完全一致的业务报表数据,能够通过数据仓库生成对对业务具有指导性的数据,同时,为领导决策提供全面的数据支持。
3,数据仓库的架构可分为三层
(1)源数据层(ODS):直接使用外部系统数据结构和数据,这是接口数据的临时存储区域,为后一步的数据处理做准备;
(2)数据仓库层(DW):也称为细节层,DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗后的数据;
(3)数据应用层(DA或APP):前端应用直接读取的数据源,也是根据报表、专题分析需求而计算生成的数据。
4,ETL与ELT
数据仓库从各个数据源中,获取数据及在数据仓库内的数据转换和流动都可以认为是ETL(抽取Extract,转化Transform, 装载Load)的过程。
(1)ETL
先从数据源池中,抽取数据,并把数据保存在临时暂存数据库中(ODS)。
然后,执行转换操作,将数据结构化并转换为适合目标数据仓库(DW)系统的形式,然后将结构化数据加载到数据仓库中进行分析。
(2)ELT
使用ELT时,数据在从数据源中提取后立即加载。没有专门的临时数据库(ODS),这意味着数据会立即加载到单一的集中存储库中。
数据在数据仓库系统中进行转换,然后进行分析。大数据时代数仓这个特点很明显
5,数据库操作
1,HQL数据定义语言
数据定义语言 (Data Definition Language,DDL),指的是SQL语言集中对数据库内部的对象结构进行创建、删除、修改等操作。
其中,数据库对象包括有:数据库database(schema)、数据表table、视图view、索引index等。
核心语法:
(1)CREATE 创建
(2)ALTER 删除
(3)DROP 修改
2,创建数据库
create database [if not exists] 数据库名
[comment '解释说明']
[location '存储到HDFS路径名']
[with dbproperties (属性名='值', ...)];
指定文件夹下创建数据库
create database zuo location '/zuo';
3,查看数据库信息
desc database [extended] 数据库名;
(1)extended用于显示更多信息,比如位置路径等;
(2)查看数据库信息时,记得加上database。
查看正在使用哪个数据库
select current_database();
4,如果要查看创建数据库的语句时,命令:
show create database itcast;
5,删除库
DROP DATABASE语句用于删除数据库。语法:
drop database 数据库名 [restrict | cascade];
若要删除带有数据表的数据库zuo时,记得在语句结尾处添加cascade。
6,修改库
ALTER DATABASE语句可用于更改与Hive中的数据库关联的元数据信息。语法:
-- 修改数据库存储路径
alter database 数据库名 set location 存储路径名;-- 修改或新增数据库配置属性
alter database 数据库名 set dbproperties (属性名=值, ...);
使用alter语法来修改数据库的属性
alter database zuo set dbproperties('create_time'='21:15');
desc database extended zuo;
相关文章:
Hive入门--学习笔记
1,Apache Hive概述 定义: Hive是由Facebook开源用于解决海量结构化日志的数据统计,它是基于大数据生态圈Hadoop的一个数据仓库工具。 作用: Hive可以用于将结构化的数据文件【映射】为一张表,并提供类SQL查询功能。 H…...
)
【nlp】1文本预处理总括目录(附各章节链接)
文本预处理 1. 文本预处理机器作用2. 文本预处理包含的主要环节2.1 文本处理的基本方法2.1.1 分词2.1.2 词性标注2.2.3 命名实体标注2.2 文本张量表示方法2.2.1 one-hot编码2.2.2 Word2vec2.2.3 Word Embedding2.3 文本语料的数据分析2.3.1 标签数量分布2.3.2 句子长度分布2.3.…...
《增长黑客》思维导图
增长黑客这个词源于硅谷,简单说,这是一群以数据驱动营销、以迭代验证策略,通过技术手段实现爆发式增长的新型人才。 近年来,互联网公司意识到这一角色可以发挥四两拨千斤的作用,因此对该职位的需求也如井喷式增长。本…...
oracle-buffer cache
段,区,块。 每当新建一个表,数据库会相应创建一个段。然后给这个段分配一个区。 一个区包含多个块。 区是oracle给段分配空间的最小单位。 块是oracle i\o的最小单位。 原则上,一个块包含多行数据。 dbf文件会被划分成一个一个…...
)
数据可视化—D3(Data Driven Documents)
链接 教程链接安装教程官方github仓库 基础知识 D3是一个Javascript库,用于在浏览器中创建可视化和可交互的各种图表。通过以下代码的对比,说明D3的使用场景以及使用效果(理论上,以下两段代码效果是一样的)…...
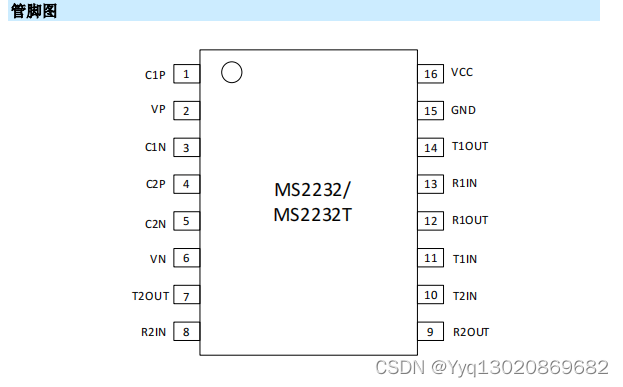
±15kV ESD 保护、3V-5.5V 供电、真 RS-232 收发器MS2232/MS2232T
产品简述 MS2232/MS2232T 芯片是集成电荷泵,具有 15kV ESD 保护的 RS-232 收发器,包括两路接收器、两路发送器。 芯片满足 TIA/EIA-232 标准,为异步通信控制器和串口连 接器提供通信接口。 芯片采用 3V-5.5V 供电,电荷泵仅用…...

企业版远程软件推荐
在当今的数字时代,为您的企业配备远程访问功能至关重要。通过远程访问,您的团队可以在办公室外工作,并且无论身在何处都可以保持相同的生产力水平。在本文中,我们汇总了市场上的四大选择。 我们在远程访问解决方案中寻找什么 远…...

独孤思维:没学会走就要跑,你只能一辈子是穷b
很多人眼高手低,没学会走就要跟别人比赛跑步; 很多人想要发财,没赚到钱就要喊着跟谁比有钱。 眼高手低,自命不凡,愚蠢至极。 上周团队要扩编,招一个运营。 来了一个00后女孩应聘。 上来就说自己目标三…...
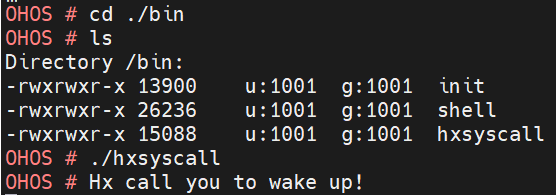
鸿蒙LiteOs读源码教程+向LiteOS中添加一个系统调用
本文分为2个部分:第1部分简要介绍如何读鸿蒙Liteos源码,第2部分是实验向LiteOS中添加一个系统调用的完整过程。 前置资料: imx6ull开发板使用方式详解 源码下载 编译运行简单程序 Ubuntu虚拟机使用鸿蒙LiteOs操作系统常见错误汇总 一、鸿…...

美国站群服务器IP如何设置分配?
在配置美国站群服务器时,IP的分配是一个重要的步骤。下面将介绍一些关于美国站群服务器IP分配的相关知识。 独享IP和虚拟IP 在租用美国站群服务器之前,我们需要了解提供的IP是独享的还是虚拟的。独享IP指每个网站都有独立的IP地址,而虚…...
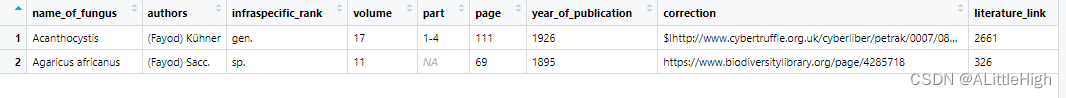
R语言——taxize(第二部分)
taxize(第二部分) 3. taxize 文档中译3.10. classification(根据类群ID检索分类阶元层级)示例1:传递单个ID值示例2:传递多个ID值示例3:传递单个名称示例4:传递多个名称示例5…...
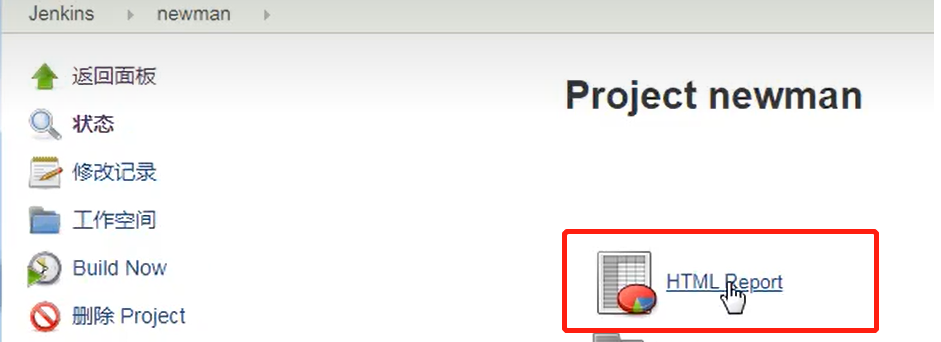
Postman+Newman+Jenkins实现接口测试持续集成
近期在复习Postman的基础知识,在小破站上跟着百里老师系统复习了一遍,也做了一些笔记,希望可以给大家一点点启发。 1.新建一个项目 2.设置自定义工作空间 3.执行windows的批处理命令 4.执行系统的Groovy脚本 5.生成的HTML的报告集成到Jenkin…...
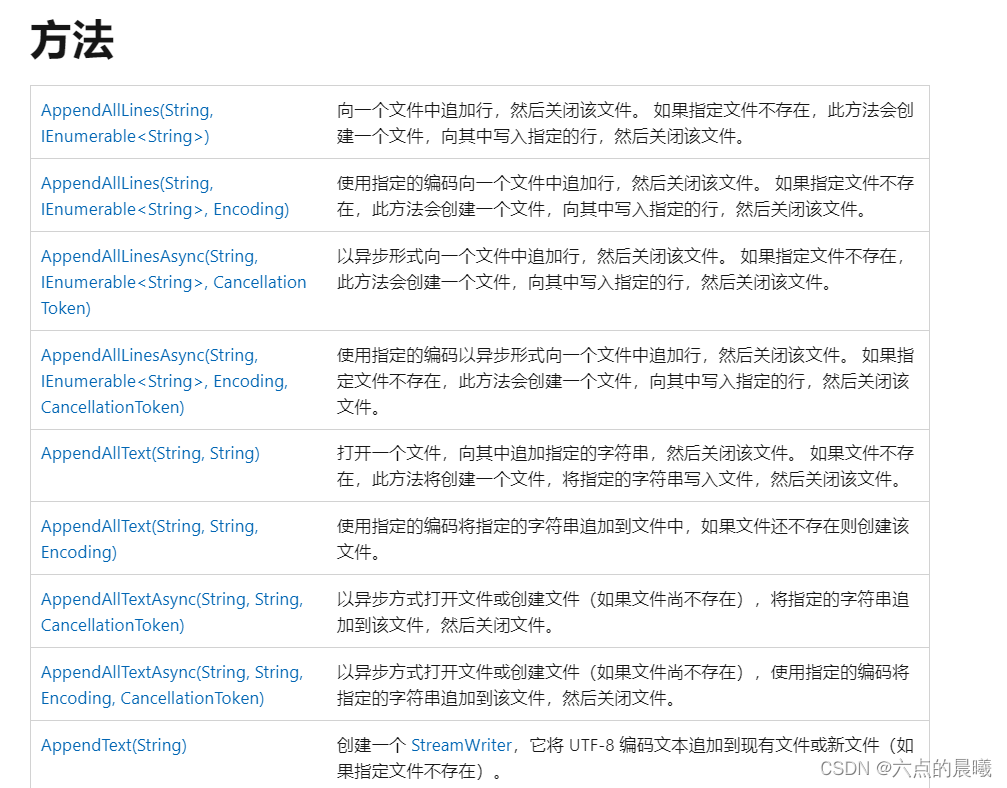
C#WPF中的实现读取和写入文件的几种方式
说明:C#中实现读取和写入的类根据需要来选择。 1、File类 File类是用于操作文件的工具类,提供了对文件进行创建、复制、删除、移动和打开单一文件的静态方法。但需要注意的是,WPF中使用File的类,需要先引用System.IO下的命名空间。…...
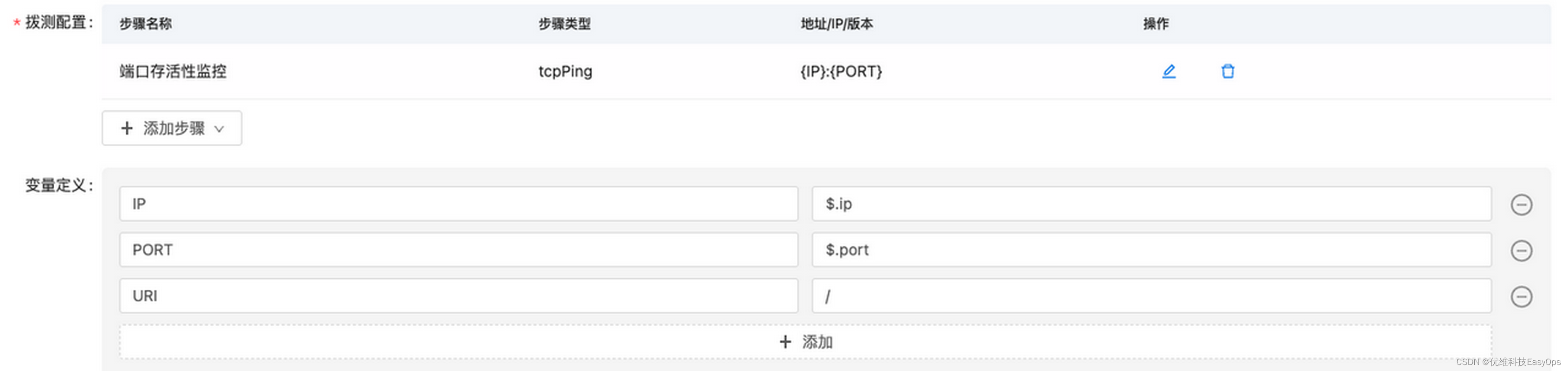
如何利用自动发现将现网的进程纳入到监控系统中?
进程监控是一项关键任务,旨在监测系统中运行的进程的性能和状态。通过有效的进程监控,可以实时了解进程的运行情况,及时发现问题并采取措施,确保系统的稳定性和性能。 本期EasyOps产品使用最佳实践,我们将为您揭晓&am…...
)
英语学习(过去篇)
一、询问别人一周的情况 1.日常活动词汇 1)I watched TV 我看了电视 2)I ate breakfast 我吃了早餐 3)I left the house 我离开了家 4)I did the dishes 我洗了碗 5)I washed my clothes …...
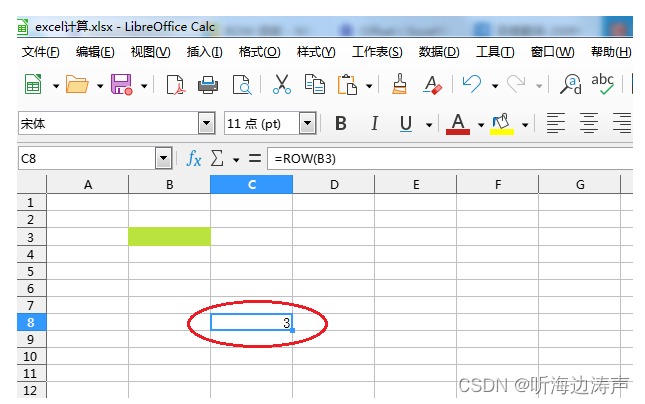
excel中通过ROW函数返回引用的行号
例如,想引用B3的行号(行号应该是3): 鼠标点在想输入函数的单元格: 插入-》函数: 选择ROW函数: 点击“继续”,然后点击红框圈出来的按钮: 鼠标点击B3单元格&…...
spring学习笔记-IOC,AOP,事务管理
目录 概述 什么是spring 侵入式的概念 spring的核心 spring的优势 注意 IOC控制反转 概述 核心 容器 DI,dependency injection依赖注入 概念 注入方式 循环依赖 spring如何解决循环依赖 spring生成Bean的方式 Bean属性注入(Bean属性赋值…...
MYSQL中的触发器TRIGGER
1.概念 触发器是一个特殊的存储过程,当触发器保护的数据发生变更时就会触发。 2.特性 1.触发器与表息息相关,一般我们一个表创建六个触发器。 2.六个触发器其实是三种类六个 insert 类型 before | after insertupdate 类型 before | af…...
用人话讲解深度学习中CUDA,cudatookit,cudnn和pytorch的关系
参考链接 本人学习使用,侵权删谢谢。用人话讲解深度学习中CUDA,cudatookit,cudnn和pytorch的关系 CUDA CUDA是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,是一种并行计算平台和编程模型&…...

【JavaEE】Servlet API 详解(HttpServletRequest类)
一、HttpServletRequest Tomcat 通过 Socket API 读取 HTTP 请求(字符串), 并且按照 HTTP 协议的格式把字符串解析成 HttpServletRequest 对象(内容和HTTP请求报文一样) 1.1 HttpServletRequest核心方法 1.2 方法演示 WebServlet("/showRequest&…...

原生态部署librenms
为什么写这个?1、别的帖子都要钱,我真看不惯。2、要了钱程序还搭不起来,恶心。3、法布施是智慧聪明才艺地修因。正题开始:一、部署目标 本次 LibreNMS 部署以官方推荐架构为基础,目标是搭建一套结构清晰、运行稳定、便…...

CVPR 2019 RKD论文复现踩坑记:从理论公式到可运行的PyTorch代码全解析
CVPR 2019 RKD论文复现实战:从数学推导到工业级PyTorch实现的关键细节当我在实验室第一次尝试复现CVPR 2019的Relational Knowledge Distillation(RKD)算法时,原以为按照论文公式直接编码就能快速跑通实验。但实际动手后才发现&am…...

从技术配置角度拆解全屋定制:五金件选型对柜体长期稳定性的影响
装修做全屋定制,大部分人的关注点集中在板材的环保等级和封边工艺上。但在日常使用中,决定一套柜子用起来顺不顺滑、耐不耐用的关键因素,还有一项容易被忽略——五金件的选型与安装精度。作为一个习惯把东西拆开研究明白的人,这次…...

别再手动调参了!用pmdarima的auto_arima批量预测300家门店销售额,我踩过的坑都在这
批量时间序列预测实战:用auto_arima高效处理300家门店销售数据的避坑指南当面对300家连锁门店的日销售额预测需求时,传统ARIMA建模方法会迅速暴露其局限性——手动调参不仅耗时费力,还会因人为判断差异导致模型效果参差不齐。这正是为什么越来…...

突破索尼相机数字枷锁:Sony-PMCA-RE逆向工程技术深度解析
突破索尼相机数字枷锁:Sony-PMCA-RE逆向工程技术深度解析 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 在数码摄影领域,索尼相机以其卓越的成像技术和创新…...

用PyTorch和TD3教AI玩赛车:从像素输入到稳定驾驶的保姆级调参指南
用PyTorch和TD3构建赛车AI:视觉输入下的强化学习调参实战当游戏画面从单纯的娱乐载体转变为强化学习的训练场时,每一个像素都承载着决策信息。CarRacing-v2环境将这种挑战具象化——96x96的彩色图像输入需要转化为精确的转向、油门和刹车控制。不同于传统…...
)
Mac到手别急着装软件,先搞定这3个基础设置(含开启任意来源命令)
Mac新机必做的3项底层优化:从系统设置到高效工作流刚拆封的MacBook总带着一种特殊的仪式感——光滑的铝金属外壳、视网膜屏幕的细腻显示、以及那个等待被按下的电源键。但在这份新鲜感之后,许多用户会直接跳转到软件安装环节,却忽略了更重要的…...

2026年AI论文工具实测排行,哪款真正适合顺利通关?
2026 年学术 AI 论文工具已形成全流程、理工 / 社科、英文 / 中文、免费 / 付费的清晰分化。综合实测排行与场景适配,千笔AI 是中文全能首选,DeepSeek 学术版是理工开源首选,毕业之家是国内毕业专属首选。 一、2026 年实测排行 TOP5ÿ…...

[开源] 临床路径卡牌化培训系统:面向医保办与临床科室的交互式规则教学工具
本项目是临床路径卡牌化培训系统(Pathway-Deck),专为医院医保办工作人员、临床科室教学负责人及新入职医师设计,将卫健委临床路径、DRG/DIP支付规则、医保负面清单等确定性规范,转化为可拖拽、可构筑、可验证的视觉化卡…...

[开源] 病历自举报系统:面向临床质控的电子病历智能预审工具,用大模型扮演质疑者角色发现逻辑矛盾与缺项问题
本项目是一个专为中文电子病历(EMR)设计的轻量级质控辅助工具,核心目标是让医生在提交病历前,就能快速识别出文本中潜藏的逻辑矛盾、信息缺项、时间线错乱、数值异常和主观夸大等典型质量问题。我们不替代人工质控,也不…...