Python集成学习和随机森林算法
大家好,机器学习模型已经成为多个行业决策过程中的重要组成部分,然而在处理嘈杂或多样化的数据集时,它们往往会遇到困难,这就是集成学习(Ensemble Learning)发挥作用的地方。
本文将揭示集成学习的奥秘,并介绍其强大的随机森林算法,通过本文将全面了解集成学习以及Python中随机森林的工作原理。
集成学习概论
集成学习是一种机器学习方法,它将多个弱模型的预测结果组合在一起,以获得更强的预测结果,集成学习的概念是通过充分利用每个模型的预测能力来减少单个模型的偏差和错误。
为了更好地理解,接下来举一个生活中的例子,假设你看到了一种动物,但不知道它属于哪个物种。因此询问十位专家,然后由他们中的大多数人投票决定,这就是所谓的“硬投票”。
硬投票是指考虑到每个分类器的类别预测,然后根据具有最大投票数的类别将输入进行分类。另一方面,软投票是指考虑每个分类器对每个类别的概率预测,然后根据该类别的平均概率(在分类器概率的平均值上取得)将输入分类到具有最大概率的类别。
集成学习总是用于提高模型性能,包括提高分类准确度和降低回归模型的平均绝对误差。此外,集成学习总能产生更稳定的模型。当模型之间没有相关性时,集成学习的效果最好,因为这样每个模型都可以学习到独特的内容,从而提高整体性能。
集成学习策略
尽管集成学习可以以多种方式应用在很多方面,但在实践中,有三种策略因其易于实施和使用而广受欢迎。这三种策略分别是:
-
装袋法(Bagging):Bagging是bootstrap aggregation的缩写,是一种集成学习策略,它使用数据集的随机样本来训练模型。
-
堆叠法(Stacking):Stacking是堆叠泛化(stacked generalization)的简称,是一种集成学习策略。在这种策略中,我们训练一个模型,将在数据上训练的多个模型结合起来。
-
提升法(Boosting):提升法是一种集成学习技术,重点在于选择被错误分类的数据来训练模型。
接下来深入探讨每种策略,并看看如何使用Python在数据集上训练这些集成模型。
装袋法集成学习
装袋法使用随机样本数据,并使用学习算法和平均值来获取装袋概率,也称为自助聚合,它将多个模型的结果聚合起来得到一个综合的结果。
该方法涉及以下步骤:
-
将原始数据集分割成多个子集,并进行替换。
-
为每个子集开发基础模型。
-
在运行所有预测之前,同时运行所有模型,并将所有预测结果汇总以获得最终预测结果。
Scikit-learn提供了实现BaggingClassifier和BaggingRegressor的能力。BaggingMetaEstimator可以识别原始数据集的随机子集以适应每个基础模型,然后通过投票或平均的方式将各个基础模型的预测结果聚合成最终预测结果,该方法通过随机化构建过程来减少差异。
【Scikit-learn】:https://scikit-learn.org/stable/
接下来本文以一个示例来说明如何使用scikit-learn中的装袋估计器:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=10, max_samples=0.5, max_features=0.5)
装袋分类器需要考虑几个参数:
-
base_estimator:装袋方法中使用的基础模型。这里我们使用决策树分类器。
-
n_estimators:装袋方法中将使用的估计器数量。
-
max_samples:每个基础估计器将从训练集中抽取的样本数。
-
max_features:用于训练每个基础估计器的特征数量。
现在,本文将在训练集上拟合该分类器并进行评分。
bagging.fit(X_train, y_train)
bagging.score(X_test,y_test)
对于回归任务,我们也可以做类似的操作,不同之处在于我们将使用回归估计器。
from sklearn.ensemble import BaggingRegressor
bagging = BaggingRegressor(DecisionTreeRegressor())
bagging.fit(X_train, y_train)
model.score(X_test,y_test)堆叠集成学习
堆叠是一种将多个估计器组合在一起以减小它们的偏差并产生准确预测的技术。然后将每个估计器的预测结果进行组合,并输入到通过交叉验证训练的最终预测元模型中;堆叠可以应用于分类和回归问题。
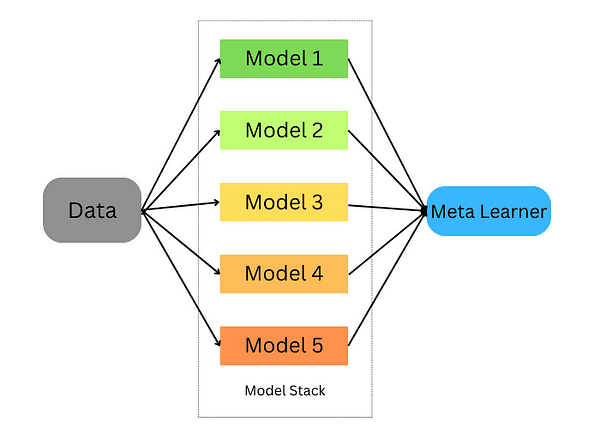
堆叠集成学习
堆叠的步骤如下:
-
将数据分为训练集和验证集。
-
将训练集分为K个折叠。
-
在K-1个折叠上训练基础模型,并在第K个折叠上进行预测。
-
重复步骤3,直到对每个折叠都有一个预测结果。
-
在整个训练集上拟合基础模型。
-
使用该模型对测试集进行预测。
-
对其他基础模型重复步骤3-6。
-
使用测试集的预测结果作为新模型(元模型)的特征。
-
使用元模型对测试集进行最终预测。
在下面的示例中,本文首先创建两个基础分类器(RandomForestClassifier和GradientBoostingClassifier)和一个元分类器(LogisticRegression),然后使用K折交叉验证从这些分类器的预测结果(iris数据集上的训练数据)中提取特征用于元分类器(LogisticRegression)的训练。
在使用K折交叉验证将基础分类器在测试数据集上进行预测,并将这些预测结果作为元分类器的输入特征后,再使用这两者的预测结果进行测试集上的预测,并将其准确性与堆叠集成模型进行比较。
# 加载数据集
data = load_iris()
X, y = data.data, data.target# 将数据拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义基础分类器
base_classifiers = [RandomForestClassifier(n_estimators=100, random_state=42),GradientBoostingClassifier(n_estimators=100, random_state=42)
]# 定义元分类器
meta_classifier = LogisticRegression()# 创建一个数组来保存基础分类器的预测结果
base_classifier_predictions = np.zeros((len(X_train), len(base_classifiers)))# 使用K折交叉验证进行堆叠
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, val_index in kf.split(X_train):train_fold, val_fold = X_train[train_index], X_train[val_index]train_target, val_target = y_train[train_index], y_train[val_index]for i, clf in enumerate(base_classifiers):cloned_clf = clone(clf)cloned_clf.fit(train_fold, train_target)base_classifier_predictions[val_index, i] = cloned_clf.predict(val_fold)# 在基础分类器预测的基础上训练元分类器
meta_classifier.fit(base_classifier_predictions, y_train)# 使用堆叠集成进行预测
stacked_predictions = np.zeros((len(X_test), len(base_classifiers)))
for i, clf in enumerate(base_classifiers):stacked_predictions[:, i] = clf.predict(X_test)# 使用元分类器进行最终预测
final_predictions = meta_classifier.predict(stacked_predictions)# 评估堆叠集成的性能
accuracy = accuracy_score(y_test, final_predictions)
print(f"Stacked Ensemble Accuracy: {accuracy:.2f}")提升集成学习
提升(Boosting)是一种机器学习的集成技术,通过将弱学习器转化为强学习器来减小偏差和方差。这些弱学习器按顺序应用于数据集,首先创建一个初始模型并将其拟合到训练集上。一旦第一个模型的错误被识别出来,就会设计另一个模型来进行修正。
有一些流行的算法和实现方法用于提升集成学习技术,接下来将探讨其中最著名的几种。
- AdaBoost
AdaBoost是一种有效的集成学习技术,通过按顺序使用弱学习器进行训练。每次迭代都会优先考虑错误的预测结果,同时减小分配给正确预测实例的权重;这种策略性地强调具有挑战性的观察结果,使得AdaBoost随着时间的推移变得越来越准确,其最终的预测结果由弱学习器的多数投票或加权总和决定。
AdaBoost是一种通用的算法,适用于回归和分类任务,但在这里本文更关注它在分类问题上的应用,使用Scikit-learn进行演示。接下来看看如何在下面的示例中将其应用于分类任务:
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100)
model.fit(X_train, y_train)
model.score(X_test,y_test)
在这个示例中,本文使用了Scikit-learn中的AdaBoostClassifier,并将n_estimators设置为100。默认的学习器是决策树,用户可以进行更改。此外,还可以调整决策树的参数。
-
极限梯度提升(XGBoost)
极限梯度提升(eXtreme Gradient Boosting),更常被称为XGBoost,是提升集成学习算法中最佳的实现之一,由于其并行计算能力,在单台计算机上运行非常高效,可以通过机器学习社区开发的xgboost软件包来使用XGBoost。
import xgboost as xgb
params = {"objective":"binary:logistic",'colsample_bytree': 0.3,'learning_rate': 0.1,'max_depth': 5, 'alpha': 10}
model = xgb.XGBClassifier(**params)
model.fit(X_train, y_train)
model.fit(X_train, y_train)
model.score(X_test,y_test)
- LightGBM
LightGBM是另一种基于树学习的梯度提升算法,但与其他基于树的算法不同的是,它使用基于叶子的树生长方式,这使其收敛更快。
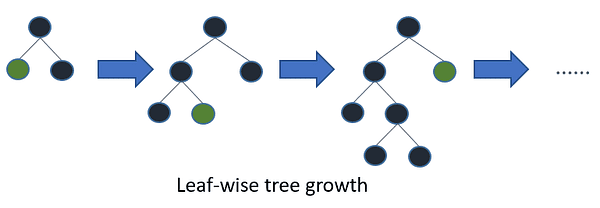
树叶的生长/图片来源:LightGBM
在下面的示例中,本文将使用LightGBM解决一个二元分类问题:
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt','objective': 'binary','num_leaves': 40,'learning_rate': 0.1,'feature_fraction': 0.9}
gbm = lgb.train(params,lgb_train,num_boost_round=200,valid_sets=[lgb_train, lgb_eval],valid_names=['train','valid'],)综上所述,集成学习和随机森林是强大的机器学习模型,机器学习从业者和数据科学家经常使用它们。本文中介绍了提升集成学习的基本原理、应用场景,并介绍了其中最受欢迎的算法及其在Python中的使用方法。
相关文章:
Python集成学习和随机森林算法
大家好,机器学习模型已经成为多个行业决策过程中的重要组成部分,然而在处理嘈杂或多样化的数据集时,它们往往会遇到困难,这就是集成学习(Ensemble Learning)发挥作用的地方。 本文将揭示集成学习的奥秘&am…...

代码随想录算法训练营第二十四天| 77 组合
目录 77 组合 暴力 减枝优化 77 组合 暴力 class Solution {List<List<Integer>>res new ArrayList<>();LinkedList<Integer>newList new LinkedList<>();public List<List<Integer>> combine(int n, int k) {dfs(n,k,1);r…...

el-dialog element-ui弹窗
bulkImport.vue 自定义组件 <template> <el-dialog :visible"modalVisible" title"批量导入" centered close"$emit(close)" :fullscreen"true"> <span>弹窗内容</span> <span slot"foot…...

计算机网络的发展
目录 一、计算机网络发展的四个阶段 1、第一阶段:面向终端的计算机网络(20世纪50年代) 2、第二阶段:计算机—计算机网络(20世纪60年代) 3、第三阶段:开放式标准化网络(20世纪70年…...

官宣!Wayland正式支持基于IntelliJ的IDE
对于基于IntelliJ IDE的Linux用户来说,一项令人期待的进步即将到来 – 对 Wayland 显示服务器协议的支持。 这项更新将带来许多好处,包括解决古老的分数缩放问题以及在与适用于 Linux 的 Windows 子系统 (WSLg)(在底层运行 Wayland 服务器&am…...
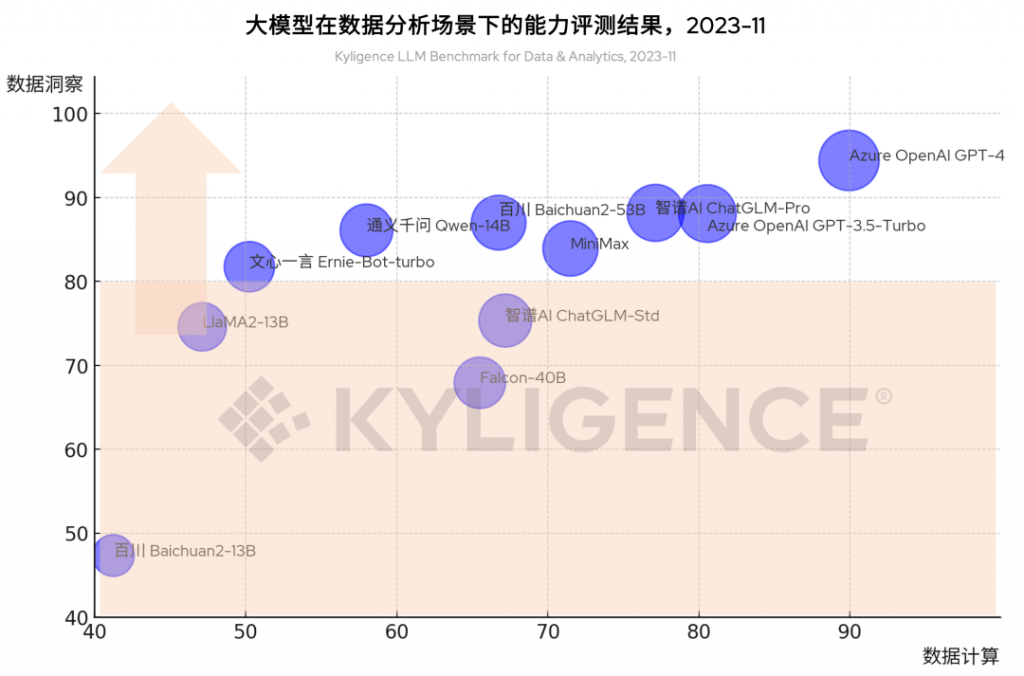
大模型在数据分析场景下的能力评测|进阶篇
做数据分析,什么大模型比较合适? 如何调优大模型,来更好地做数据计算和洞察分析? 如何降低整体成本,同时保障分析体验?10月25日,我们发布了数据分析场景下的大模型能力评测框架(点击…...
服务注册发现 springcloud netflix eureka
文章目录 前言角色(三个) 工程说明基础运行环境工程目录说明启动顺序(建议):运行效果注册与发现中心服务消费者: 代码说明服务注册中心(Register Service)服务提供者(Pro…...

Spring cloud负载均衡@LoadBalanced LoadBalancerClient
LoadBalance vs Ribbon 由于Spring cloud2020之后移除了Ribbon,直接使用Spring Cloud LoadBalancer作为客户端负载均衡组件,我们讨论Spring负载均衡以Spring Cloud2020之后版本为主,学习Spring Cloud LoadBalance,暂不讨论Ribbon…...
6.运行mysql容器-理解容器数据卷
运行mysql容器-理解容器数据卷 1.什么是容器数据卷2.如何使用容器数据卷2.1 数据卷挂载命令2.2 容器数据卷的继承2.3 数据卷的读写权限2.4 容器数据卷的小实验(加深理解)2.4.1 启动挂载数据卷的centos容器2.4.2 启动后,在宿主机的data目录下会…...

golang学习笔记——查找质数
查找质数 编写一个程序来查找小于 20 的所有质数。 质数是大于 1 的任意数字,只能被它自己和 1 整除。 “整除”表示经过除法运算后没有余数。 与大多数编程语言一样,Go 还提供了一种方法来检查除法运算是否产生余数。 我们可以使用模数 %(百…...

C++ 基础二
文章目录 四、流程控制语句4.1 选择结构4.1.1 if语句 4.1.2 三目运算符4.1.3 switch语句注意事项 4.1.4 if和switch的区别【CHAT】4.2 循环结构4.2.1 while循环语句4.2.2 do...while循环语句 4.2.3 for循环语句九九乘法表 4.3 跳转语句4.3.1 break语句4.3.2 continue语句4.3.3 …...

鼎盛合 | 宠物智能投食机方案设计开发
养宠物是一件治愈并解压的事情,与动物的相处中能够释放压力,并在与宠物的互动中小可爱们往往能带给你一种治愈的力量,所以养宠物成为了人们尤为热衷的事情。我们生活中随处可见主人与宠物相处的温馨画面,但养宠物也有些问题在困扰…...
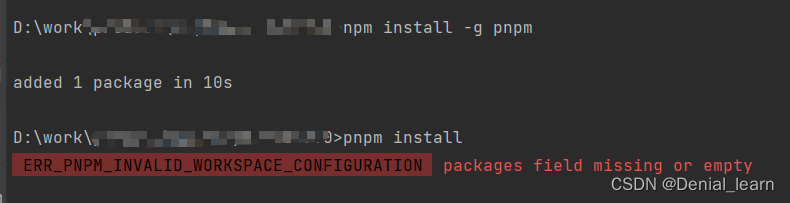
ERR_PNPM_INVALID_WORKSPACE_CONFIGURATION packages field missing or empty
vue执行 pnpm install命令时,报 ERR_PNPM_INVALID_WORKSPACE_CONFIGURATION packages field missing or empty错,在网上查询了很久,也没有传出来结果,最后发现是pnpm的版本不对引起的。 我先执行的是npm install -g pnpm&…...
ubuntu 23.04从源码编译安装rocm运行tensorflow-rocm
因为ubuntu22.04的RDP不支持声音转发,所以下载了ubuntu23.04.但官方的rocm二进制包最高只支持ubuntu22.04,不支持ubuntu 23.04,只能自己从源码编译虽然有网友告诉我可以用docker运行rocm。但是我已经研究了好几天,沉没成本太多&am…...

echarts 图表文字大小自适应 字体大小自适应
将文字大小自适应方法挂载到全局 //main.js Vue.prototype.fontSize function(res) {// 获取视口宽度const clientWidth window.innerWidth ||document.documentElement.clientWidth ||document.body.clientWidth;if (!clientWidth) return; // 如果获取不到视口宽度…...

【项目】云备份系统基础功能实现
目录 一.项目介绍1.云备份认识2.服务端程序负责功能与功能模块划分3.客户端程序负责功能与功能模块划分4.开发环境 二.环境搭建1.gcc升级7.3版本2.安装jsoncpp库3.下载bundle数据压缩库4.下载httplib库 三.第三方库认识1.json(1)json认识(2)jsoncpp认识(3)json实现序列化(4)jso…...

【Shell脚本13】Shell 文件包含
Shell 文件包含 和其他语言一样,Shell 也可以包含外部脚本。这样可以很方便的封装一些公用的代码作为一个独立的文件。 Shell 文件包含的语法格式如下: . filename # 注意点号(.)和文件名中间有一空格或source filename实例 创建两个 shell 脚本文件…...
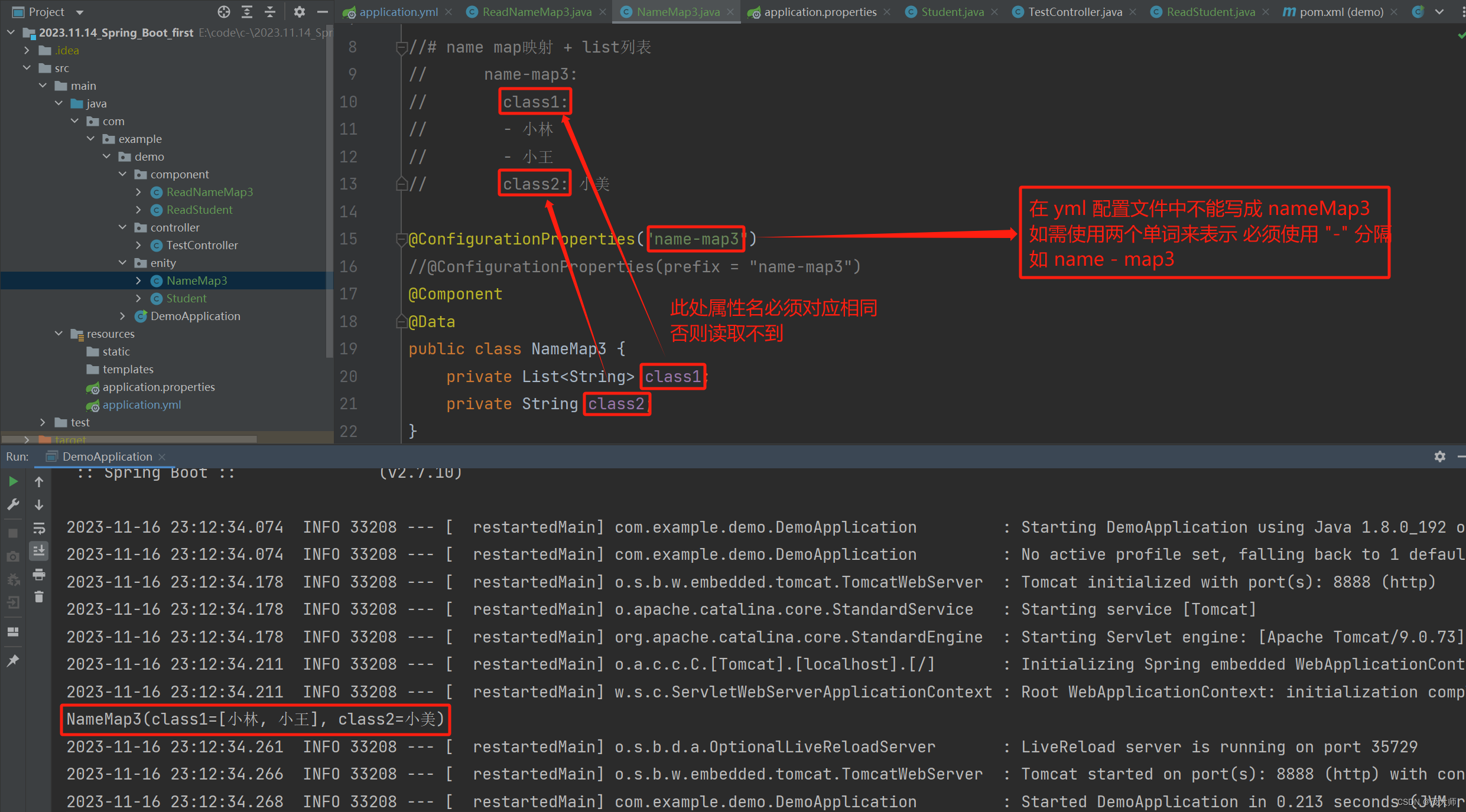
2023.11.15 关于 Spring Boot 配置文件
目录 引言 Spring Boot 配置文件 properties 配置文件说明 基本语法 读取配置文件 优点 缺点 yml 配置文件说明 基本语法 读取配置文件 yml 配置不同数据数据类型及 null 字符串 加单双引号的区别 yml 配置 列表(List) 和 映射(…...

2023年第九届数维杯国际大学生数学建模挑战赛A题
2023年第九届数维杯国际大学生数学建模挑战赛正在火热进行,小云学长又在第一时间给大家带来最全最完整的思路代码解析!!! A题思路解析如下: 完整版解题过程及代码,稍后继续给大家分享~ 更多题目完整解析点…...
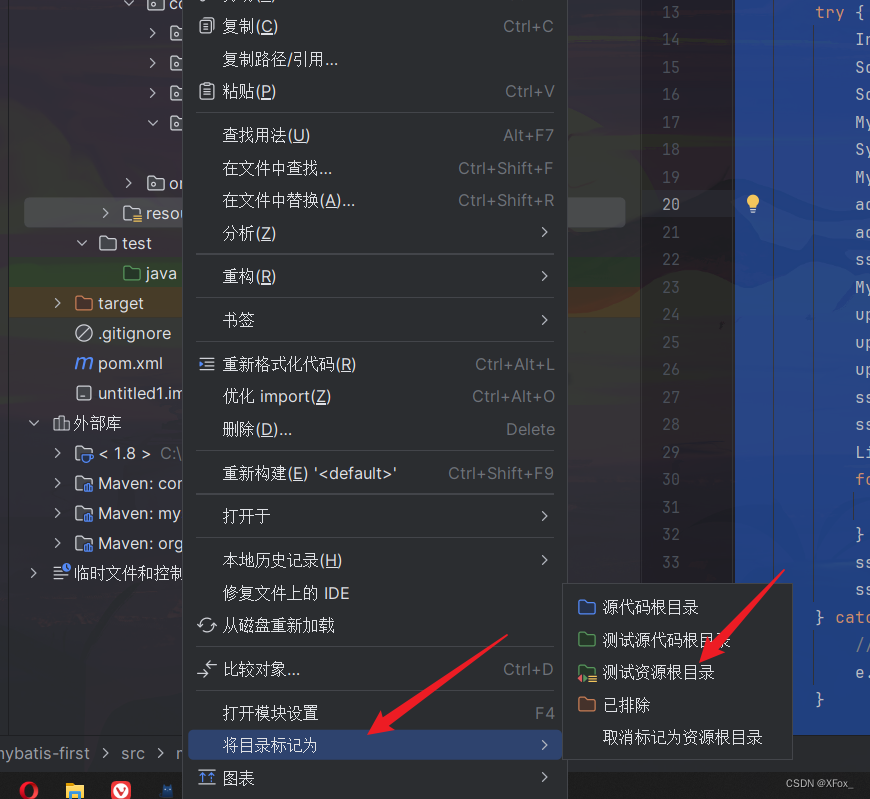
IDEA写mybatis程序,java.io.IOException:Could not find resource mybatis-config.xml
找不到mybatis-config.xml 尝试maven idea:module,不是模块构造问题 尝试检验pom.xml,在编译模块添加了解析resources内容依旧不行 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.or…...

反事实推理:用因果视角评估与缓解AI模型偏见
1. 项目概述:当模型决策需要“如果当初”在机器学习的世界里,我们常常面临一个困境:模型预测准确率很高,但我们却不知道它为什么做出这样的决策。更棘手的是,我们越来越频繁地发现,这些“黑箱”决策背后&am…...

边缘计算融合触觉互联网与数字孪生:构建超低延迟人机交互框架
1. 项目概述与核心价值最近几年,我一直在关注一个技术融合的交叉点:当边缘计算、触觉通信和数字孪生这三个看似独立的领域碰撞在一起时,会擦出什么样的火花?这个项目——“边缘计算赋能触觉互联网:构建沉浸式人机交互的…...

量子电路生成式AI技术:原理、应用与挑战
1. 量子电路生成式AI技术概述量子计算正在经历一场由生成式人工智能技术驱动的变革。作为量子计算的基本构建块,量子电路的自动生成技术正在从理论探索快速转向实际应用。这项技术通过AI模型自动产生可执行的量子电路描述,包括Qiskit代码、OpenQASM程序和…...

LLM可观测性实战:生产环境AI应用的监控体系建设
为什么LLM应用的监控与传统软件完全不同 传统软件监控关注的核心指标很清晰:响应时间、错误率、吞吐量、CPU/内存使用率。这些指标背后的系统行为是确定性的——同样的输入,永远产生同样的输出。LLM应用打破了这个假设。面对同样的用户输入:-…...

【AI Agent娱乐行业落地实战指南】:2024年头部平台已验证的7大爆款应用模型与避坑清单
更多请点击: https://intelliparadigm.com 第一章:AI Agent在娱乐行业的核心价值与演进趋势 AI Agent正从被动响应工具跃升为娱乐内容生态的主动协作者与智能策展者。其核心价值不仅体现在效率提升,更在于重构创意生产链路、深化用户参与机制…...

为小型创业团队搭建经济可控的大模型应用开发平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为小型创业团队搭建经济可控的大模型应用开发平台 对于资源有限的创业团队而言,在拥抱大模型技术的同时,必…...

DiskSpd深度解析:企业级存储性能调优的架构视角与实战指南
DiskSpd深度解析:企业级存储性能调优的架构视角与实战指南 【免费下载链接】diskspd DISKSPD is a storage load generator / performance test tool from the Windows/Windows Server and Cloud Server Infrastructure Engineering teams 项目地址: https://gitc…...

openpilot自动驾驶系统深度解析:从架构原理到300+车型适配实战
openpilot自动驾驶系统深度解析:从架构原理到300车型适配实战 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_…...

2000-2025年区县国家数字乡村试点DID
2019年《数字乡村发展战略纲要》明确数字乡村作为乡村振兴战略方向与数字中国重要内容,2022年《数字乡村发展行动计划(2022-2025年)》,部署了8个方面重点行动“数字乡村”一般指随着网络化、信息化、数字化在农业农村经济社会发展…...

LCD人体秤嵌入式方案全解析:从传感器到低功耗设计
1. 项目概述:从“称重”到“健康管理”的智能跨越“电子秤方案——LCD人体秤方案”这个标题,乍一看似乎只是关于一个简单的称重工具。但在这个全民关注健康、数据驱动生活的时代,一台现代的人体秤早已超越了“称体重”的单一功能。它集成了传…...