机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测
机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测
作者:AOAIYI
作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 专栏案例:机器学习 |
|---|
| 机器学习:基于逻辑回归对某银行客户违约预测分析 |
| 机器学习:学习k-近邻(KNN)模型建立、使用和评价 |
| 机器学习:基于支持向量机(SVM)进行人脸识别预测 |
| 决策树算法分析天气、周末和促销活动对销量的影响 |
| 机器学习:线性回归分析女性身高与体重之间的关系 |
| 机器学习:基于主成分分析(PCA)对数据降维 |
文章目录
- 机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测
- 一、实验目的
- 二、实验原理
- 1.分类问题描述
- 2.Bayes’ theorem(贝叶斯法则)
- 3.朴素贝叶斯分类算法
- 三、实验环境
- 四、实验内容
- 五、实验步骤
- 1.朴素贝叶斯
- 2.业务理解
- 3.读取数据
- 4.数据理解
- 5.数据准备
- 6.构建数据训练集和测试集
- 7.构建三类模型
- 总结
一、实验目的
1.理解朴素贝叶斯的原理
2.掌握scikit-learn贝叶斯的用法
3.认识可视化工具seaborn
二、实验原理
1.分类问题描述
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法,对于分类问题,其实谁都不会陌生,日常生活中我们每天都进行着分类过程。例如,当你看到一个人,你的脑子下意识判断他是学生还是社会上的人;你可能经常会走在路上对身旁的朋友说“这个人一看就很有钱”之类的话,其实这就是一种分类操作,贝叶斯分类算法,那么分类的数学描述又是什么呢?

其中C叫做类别集合,其中每一个元素是一个类别,而I叫做项集合(特征集合),其中每一个元素是一个待分类项,f叫做分类器。分类算法的内容是要求给定特征,构造分类器f,让我们得出类别。
2.Bayes’ theorem(贝叶斯法则)
在概率论和统计学中,Bayes theorem(贝叶斯法则)根据事件的先验知识描述事件的概率。贝叶斯法则表达式如下所示:
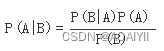
-
P(A|B) – 在事件B下事件A发生的条件概率
-
P(B|A) – 在事件A下事件B发生的条件概率
-
P(A), P(B) – 独立事件A和独立事件B的边缘概率
朴素贝叶斯方法是一组监督学习算法,它基于贝叶斯定理应用每对特征之间的“天真”独立假设。给定类变量y和从属特征矢量X1通过Xn,贝叶斯定理状态下列关系式:
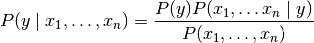
使用天真的独立假设
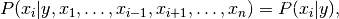
对所有人来说i,这种关系简化为
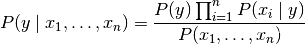
由于

输入是常数,我们可以使用以下分类规则:

我们可以使用最大后验(MAP)估计来估计的
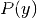 和
和 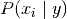
前者是y 训练集中类的相对频率。不同的朴素贝叶斯分类器主要区别于他们对分布的假设
3.朴素贝叶斯分类算法
在scikit-learn中,提供了3种朴素贝叶斯分类算法:GaussianNB(高斯朴素贝叶斯)、MultinomialNB(多项式朴素贝叶斯)、BernoulliNB(伯努利朴素贝叶斯)
可以参考文档:
http://scikit-learn.org/stable/modules/naive_bayes.html
http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html
三、实验环境
利用scikit-learn提供的三种朴素贝叶斯算法,构建分类器,根据花瓣花萼的宽度和长度判断他们属于哪一类
四、实验内容
Python 3.9
Jupyter notebook
五、实验步骤
1.朴素贝叶斯
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法
2.业务理解
先有一张表格,描述了花瓣的特征和种类,利用scikit-learn提供的三种朴素贝叶斯算法,构建分类器,根据花瓣花萼的宽度和长度预测他们属于哪一个品种
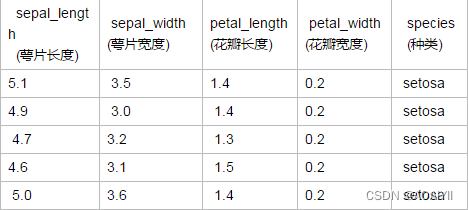
3.读取数据

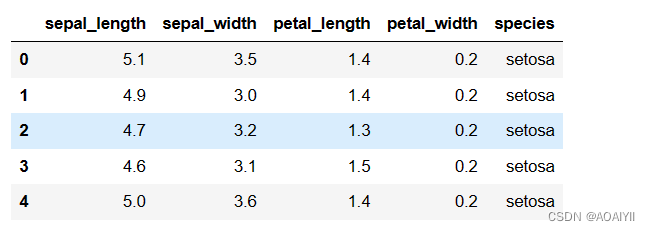
1.编写代码,读取数据
#导入pandas库和numpy库
import pandas as pd
import numpy as np
iris = pd.read_csv(r'D:\CSDN\数据分析\naivebayes\iris.csv')
iris.head()
4.数据理解
1.查看数据结构
iris.shape

说明:该数据总共有150行,5列
2.查看数据列名称
iris.columns
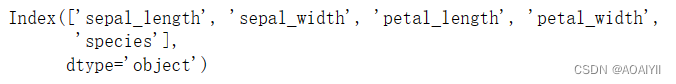
5.数据准备
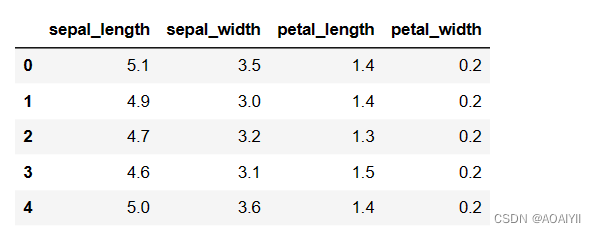
1.删除“种类”这列数据得到特征数据如下:
X_iris = iris.drop(['species'],axis=1)
X_iris.head()
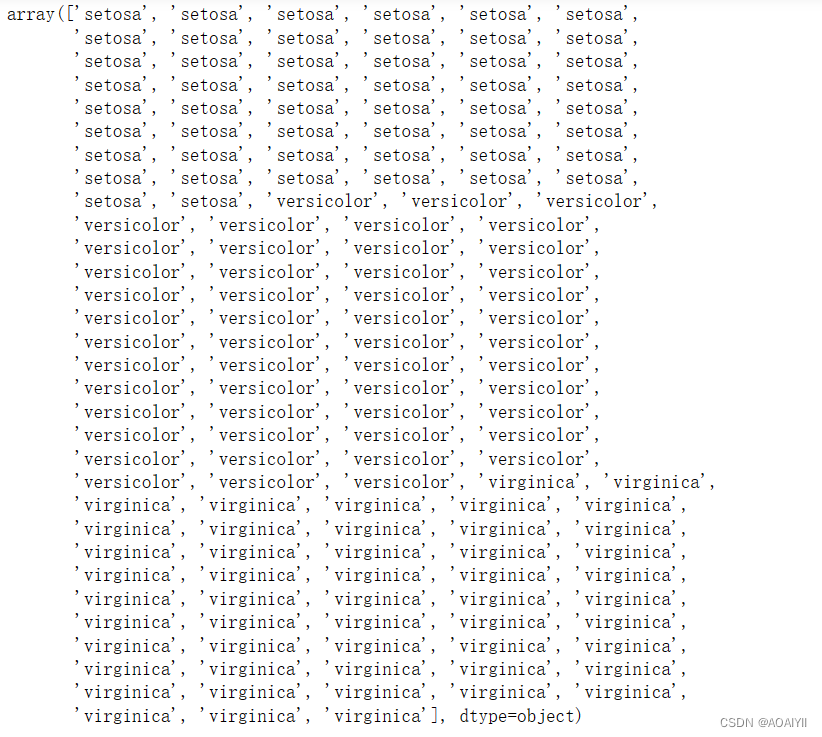
2.获取“species”这列数据并将其转换为数组,得到预测数据
y_iris = np.ravel(iris[['species']])
y_iris
3.查看y_iris总共有多少行
y_iris.shape

6.构建数据训练集和测试集
1.构建训练和测试数据集
#导入相应的库
from sklearn.model_selection import train_test_split
#将数据分为训练集,测试集
X_train,X_test,y_train,y_test = train_test_split(X_iris,y_iris,random_state=1)
#获取数据前5行
X_train.head()
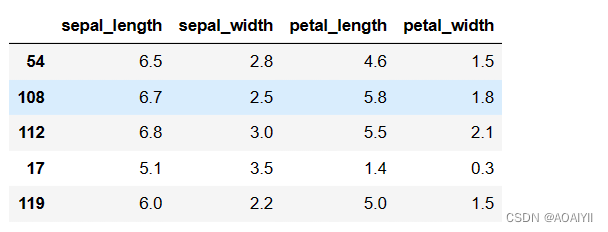
说明:将数据分为训练集和测试集,默认情况下,75%的数据用于训练,25%的数据用于测试
- 训练集是用于发现和预测潜在关系的一组数据。
- 测试集是用于评估预测关系强度和效率的一组数据。
2.查看训练集和测试集的数据结构
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)

说明:训练集:X_iris数据为(150,4),X_train为(112,4),X_test为(38,4)
sales数据为200行,y_train为(112,),y_test为(38,)
3.查看y_train数据
y_train

7.构建三类模型
在scikit-learn中,提供了3种朴素贝叶斯分类算法:GaussianNB(高斯朴素贝叶斯)、MultinomialNB(多项式朴素贝叶斯)、BernoulliNB(伯努利朴素贝叶斯)
GaussianNB实现高斯朴素贝叶斯算法进行分类。假设特征的可能性是高斯的:
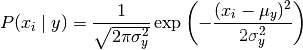
1.利用GaussianNB(高斯朴素贝叶斯)类建立简单模型并预测
from sklearn.naive_bayes import GaussianNB
#利用GaussianNB类建立简单模型
gb= GaussianNB()
model_GaussinaNB = gb.fit(X_train,y_train)
#predict(X):直接输出测试集预测的类标记,X_test为测试集
y_predict_GaussianNB= model_GaussinaNB.predict(X_test)
print("y_predict_GaussianNB",y_predict_GaussianNB)

构建一个新的测试数组
import pandas as pd
z_data ={'sepal_length':['5'],'sepal_width':['3'],'petal_length':['3'],'petal_width':['1.8']}
Z_data =pd.DataFrame(z_data,columns=['sepal_length','sepal_width','petal_length','petal_width'])
print(Z_data)

将测试数据带入模型预测得到预测结果
Z_model_predict=model_GaussinaNB.predict(Z_data)
print('Z_model_predict',Z_model_predict)
说明:当我们提供的数据为’sepal_length’:[‘5’],‘sepal_width’:[‘3’],‘petal_length’:[‘3’],‘petal_width’:[‘1.8’]时,预测它属于‘versicolor’这个种类,到底预测正确与否呢?接下来看一下预测结果的平均值
查看预测结果的平均值
#预测结果
y_predict_GaussianNB==y_test

mean()函数功能:求取均值
y_test_mean=np.mean(y_predict_GaussianNB==y_test)
print('y_test_GaussianNB_mean',y_test_mean)
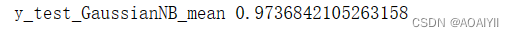
查看预测正确率
score(X, y[, sample_weight]) 返回给定测试数据和标签的平均精度
gb.score(X_train,y_train)
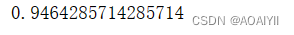
2.BernoulliNB(伯努利朴素贝叶斯)
BernoulliNB实现了根据多元伯努利分布的数据的朴素贝叶斯训练和分类算法; 即,可能存在多个特征,但每个特征被假定为二进制值(伯努利,布尔)变量。因此,该类要求将样本表示为二进制值特征向量;如果传递任何其他类型的数据,BernoulliNB实例可以将其输入二值化(取决于binarize参数)。
伯努利朴素贝叶斯的决策规则是基于
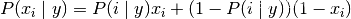
利用BernoulliNB类建立简单模型并预测
# ====================BernoulliNB
from sklearn.naive_bayes import BernoulliNB
model_BernoulliNB=BernoulliNB().fit(X_train,y_train)
y_predict_BernoulliNB=model_BernoulliNB.predict(X_test)
print('y_test_BernoulliNB_mean',np.mean(y_predict_BernoulliNB==y_test))
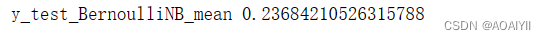
3.MultinomialNB(多项式朴素贝叶斯)
MultinomialNB实现用于多项分布数据的朴素贝叶斯算法,并且是用于文本分类的两种经典朴素贝叶斯变体之一(其中数据通常表示为单词向量计数,尽管tf-idf向量也已知在实践中很好地工作) 。
利用MultinomialNB类建立简单模型并预测
# ====================MultinomialNB
from sklearn.naive_bayes import MultinomialNB
model_MultinomialNB=MultinomialNB().fit(X_train,y_train)
y_predict_MultinomialNB=model_MultinomialNB.predict(X_test)
print('y_test_MultinomialNBB_mean',np.mean(y_predict_MultinomialNB==y_test)) 
总结
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法,对于分类问题,其实谁都不会陌生,日常生活中我们每天都进行着分类过程。例如,当你看到一个人,你的脑子下意识判断他是学生还是社会上的人;你可能经常会走在路上对身旁的朋友说“这个人一看就很有钱”之类的话,其实这就是一种分类操作。
每个人都会遇到困难跟挫折,要有同困难作斗争的决心跟勇气。困难跟挫折是成就事业的基石,岸在远方向我们招手,只要越过它,敢于在惊涛骇浪中博击,我们就会尝到胜利的果食。
相关文章:
机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测
机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 作者:AOAIYI 作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞…...

给VivoBook扩容重装系统
现在笔记本重装系统都这么复杂吗?原谅我还是10年前的装机水平,折腾了一天终于把系统重新安装好了。 笔记本: ASUS VivoBook 安装系统: Win10 1、扩容 电脑配的512G硬盘满了要换个大的,后盖严丝合缝,不…...

vue 依赖注入使用教程
vue 中的依赖注入,官网文档已经非常详细,笔者在这里总结一份 目录 1、背景介绍 2、代码实现 2.1、依赖注入固定值 2.2、 依赖注入响应式数据 3、注入别名 4、注入默认值 5、应用层 Provide 6、使用 Symbol 作注入名 1、背景介绍 为什么会出现依…...
【再临数据结构】Day1. 稀疏数组
前言 这不单单是稀疏数组的开始,也是我重学数据结构的开始。因此,在开始说稀疏数组的具体内容之前,我想先说一下作为一个有着十余年“学龄”的学生,所一直沿用的一个学习方法:3W法。我认为,只有掌握了正确的…...
)
二十四、MongoDB 聚合运算( aggregate )
MongoDB 聚合( aggregate ) 用于处理数据,比如统计平均值,求和等。然后返回计算后的数据结果 MongoDB 聚合有点类似 SQL 语句中的 COUNT( * ) aggregate() 方法 MongoDB aggregate() 为 MongoDB 数据库提供了聚合运算 语法 aggregate() 方法的语法如下 > d…...

【C++】6.模板初阶
交换两个数 任何一个类型交换还要重新写一个函数 如何解决? 模板->写跟类型无关的函数 1.泛型编程 泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。 如何写一个函数适用所有类型的交换? #include &…...

Docker部署Airbyte
Linux环境部署前置要求机器配置2c4g(最低),4c8g(推荐)dockerdocker-compose (要求新版本的docker-compose)安装airbyte,打开终端,进入你想安装airbyte的目录。#Clone代码 git clone https://github.com/air…...

2023王道考研数据结构笔记第一章绪论
第一章 绪论 1.1 数据结构的基本概念 1.数据:数据是信息的载体,是描述客观事物属性的数、字符以及所有能输入到计算机中并被程序识别和处理的符号的集合。 2.数据元素:数据元素是数据的基本单位,通常作为一个整体进行考虑和处理…...

告别空指针让代码变优雅,Optional使用图文例子源码解读
一、前言 我们在开发中最常见的异常就是NullPointerException,防不胜防啊,相信大家肯定被坑过! 这种基本出现在获取数据库信息中、三方接口,获取的对象为空,再去get出现! 解决方案当然简单,只…...
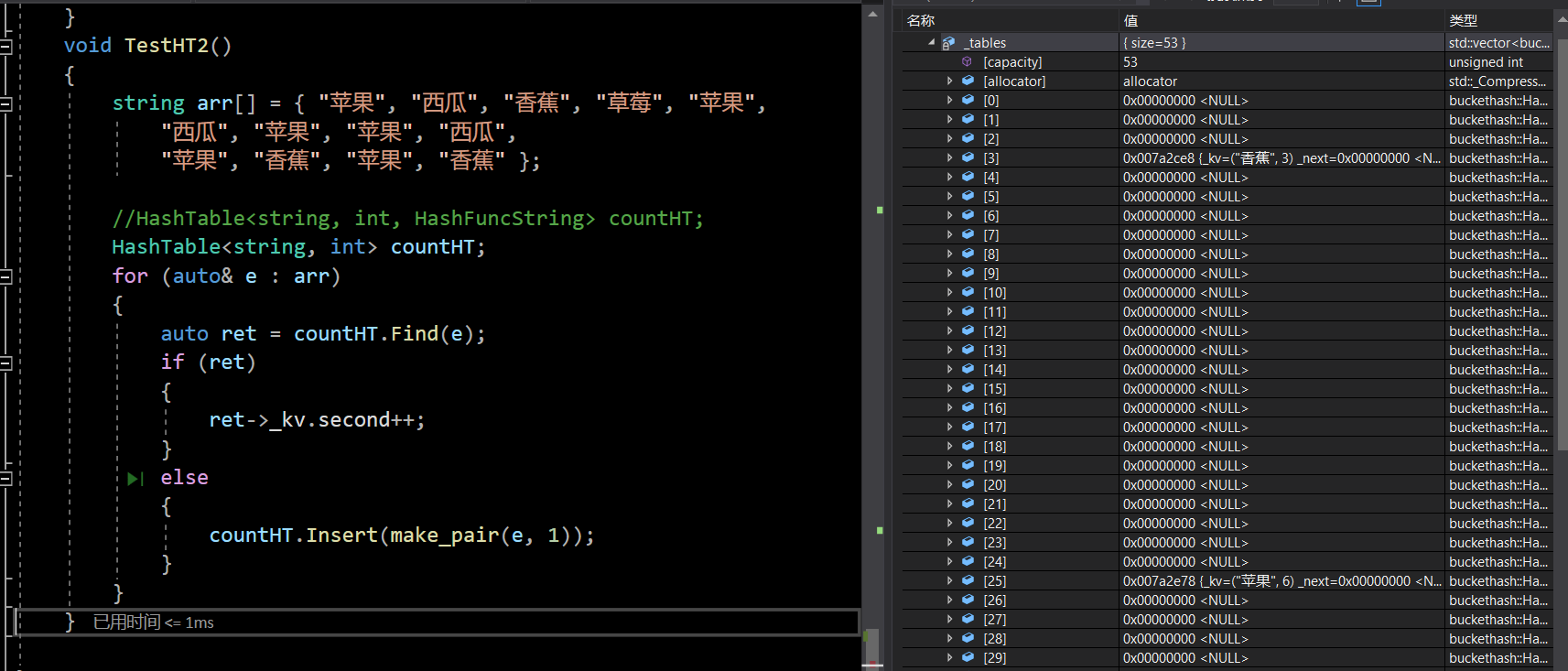
【C++】哈希——unordered系列容器|哈希冲突|闭散列|开散列
文章目录一、unordered系列关联式容器二、哈希概念三、哈希冲突四、哈希函数五、解决哈希冲突1.闭散列——开放定址法2.代码实现3.开散列——开链法4.代码实现六、结语一、unordered系列关联式容器 在C98中,STL提供了底层为红黑树结构的一系列关联式容器,…...

mysql-面试
锁: mysql的锁分为全局锁、表锁、行锁、间隙锁 全局锁:Flush tables with read lock 可以全局设计库为只读 表锁:一种是表锁,一种是元数据锁(meta data lock,MDL) lock tables t1 read,t2 wi…...
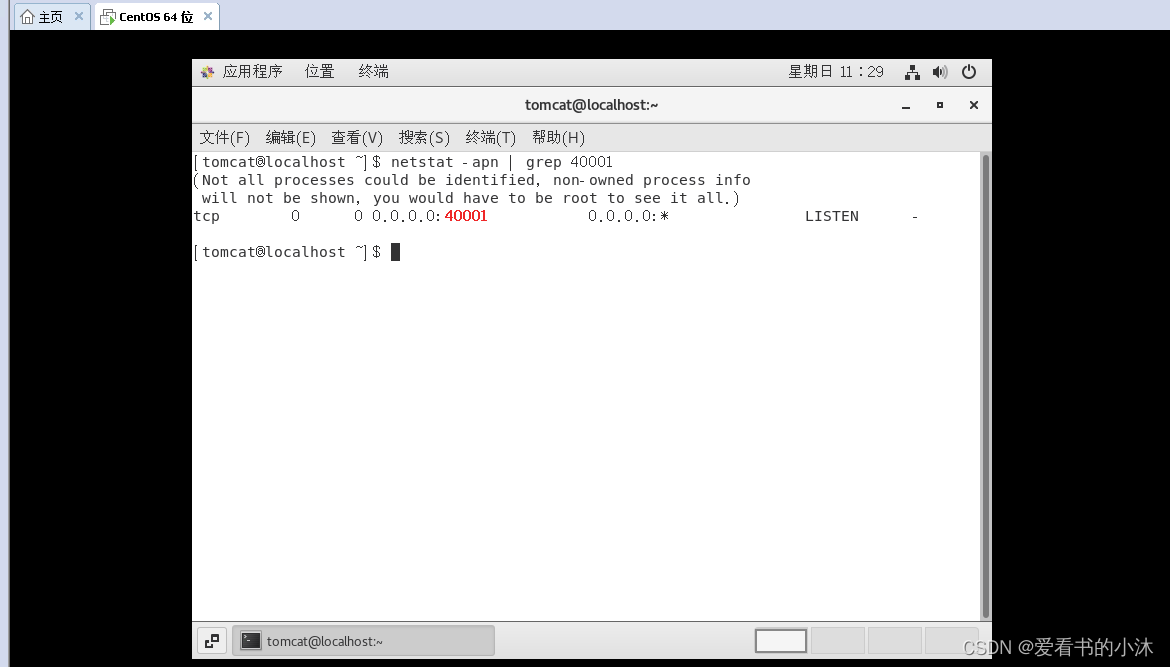
【夏虫语冰】Win10局域网下两台电脑无法ping通: 无法访问目标主机
文章目录1、简介2、修改高级共享设置3、启用防火墙规则4、局域网内的其他主机访问NAT模式下的虚拟机4.1 虚拟机网络设置4.2 访问测试4.2.1 http测试4.2.2 curl测试4.2.3 telnet测试4.2.4 端口占用测试5、其他结语1、简介 ping 192.168.31.134ping主机ip时,访问无法…...

大数据框架之Hadoop:MapReduce(三)MapReduce框架原理——Join多种应用
3.7.1Reduce Join 1、工作原理 Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。 Reduce端的主要工作:在Reduc…...

SSRF漏洞原理、危害以及防御与修复
一、SSRF漏洞原理漏洞概述SSRF(Server-side Request Forge,服务端请求伪造)是一种由攻击者构造形成由服务端发起请求的安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。正是因为它是由服务端发起的,所…...

CV学习笔记-ResNet
ResNet 文章目录ResNet1. ResNet概述1.1 常见卷积神经网络1.2 ResNet提出背景2. ResNet网络结构2.1 Residual net2.2 残差神经单元2.3 Shortcut2.4 ResNet50网络结构3. 代码实现3.1 Identity Block3.2 Conv Block3.3 ResNet网络定义3.4 整体代码测试1. ResNet概述 1.1 常见卷积…...
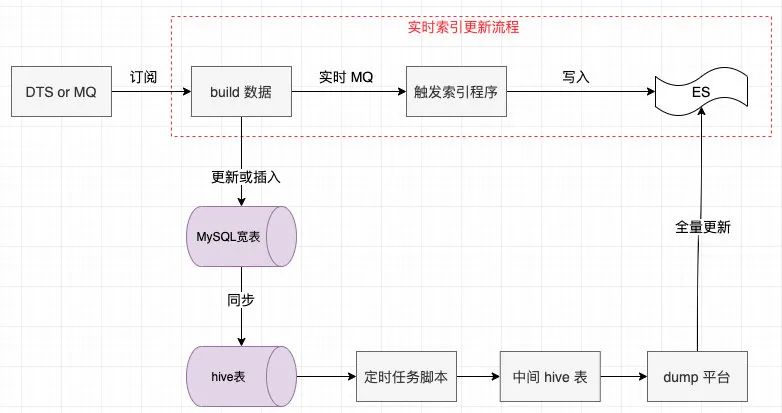
百亿数据,毫秒级返回查询优化
近年来公司业务迅猛发展,数据量爆炸式增长,随之而来的的是海量数据查询等带来的挑战,我们需要数据量在十亿,甚至百亿级别的规模时依然能以秒级甚至毫秒级的速度返回,这样的话显然离不开搜索引擎的帮助,在搜…...
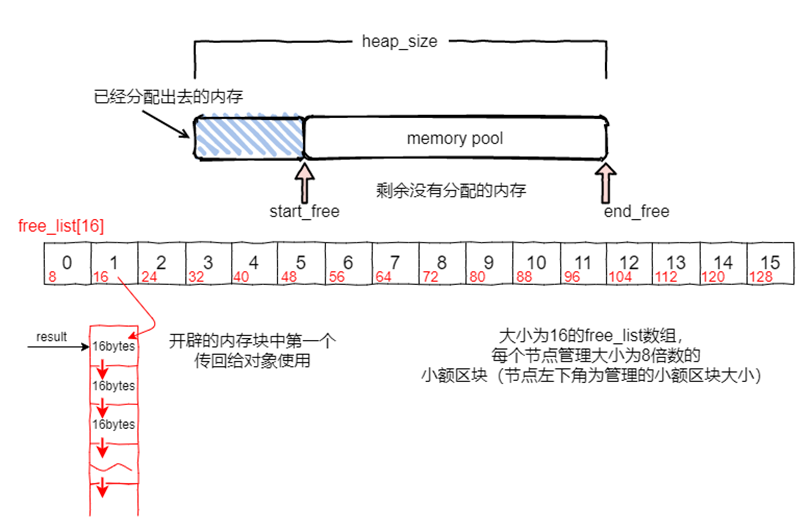
cpp之STL
STL原理 STL ⼀共提供六⼤组件,包括容器,算法,迭代器,仿函数,适配器和空间配置器,彼此可以组合套⽤。容器通过配置器取得数据存储空间,算法通过迭代器存取容器内容,仿函数可以协助算…...

基于Spring Boot开发的资产管理系统
文章目录 项目介绍主要功能截图:登录首页信息软件管理服务器管理网络设备固定资产明细硬件管理部分代码展示设计总结项目获取方式🍅 作者主页:Java韩立 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目…...

Markdown总结
文字的着重标记与段落的层次划分 Tab键可以缩进列表; shift Tab:取消缩进列表 加粗(****)、斜体(**)高亮:xxx$$:特殊标记删除:~~xxx~~多级标题:######无序列…...
字节跳动软件测试岗4轮面经(已拿34K+ offer)...
没有绝对的天才,只有持续不断的付出。对于我们每一个平凡人来说,改变命运只能依靠努力幸运,但如果你不够幸运,那就只能拉高努力的占比。 2021年10月,我有幸成为了字节跳动的一名测试工程师,从外包辞职了历…...

Cadence-OS深度解析:Uber Cadence增强发行版的生产实践指南
1. 项目概述与核心价值最近在梳理工作流自动化工具时,又翻出了paulophl94/cadence-os这个项目。它不是一个全新的轮子,而是基于 Uber 开源的 Cadence 工作流引擎,进行深度定制和增强的一个发行版。如果你正在为微服务架构下的复杂业务流程编排…...

ncmdump工具完全攻略:解锁网易云音乐NCM格式转换的终极指南
ncmdump工具完全攻略:解锁网易云音乐NCM格式转换的终极指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密格式无法在其他播放器播放而烦恼吗?你是否经历过精心收藏的音乐只能…...

设计师连夜删稿的真相:Onion Skin未启用导致版本错位!3分钟紧急修复+历史帧自动锚定脚本
更多请点击: https://intelliparadigm.com 第一章:设计师连夜删稿的真相:Onion Skin未启用导致版本错位!3分钟紧急修复历史帧自动锚定脚本 当动画师在 Toon Boom Harmony 或 Adobe Animate 中反复导出“看似正确”的中间帧&#…...

AI时代数据中心架构变革:从计算中心到加速基础设施
1. 从“计算中心”到“加速基础设施”:数据中心架构的范式转移最近和几个在头部云厂商做架构设计的老朋友聊天,话题总绕不开一个词:加速基础设施。这词儿听起来挺高大上,但说白了,就是咱们传统数据中心那套“通用计算存…...

AI建站多语言怎么做?先懂业务,再谈翻译
AI建站多语言怎么做?先懂业务,再谈翻译当同行还在卷“建站速度”时,聪明的出海商家已经开始卷“AI可见度”了。据近期行业数据显示,超过60%的海外采购商开始习惯使用ChatGPT、Perplexity等AI工具寻找供应商,而非传统的…...
)
集合进阶(Collection)
一、集合概述和分类1.1 集合的分类如下图所示:一类是单列集合元素是一个一个的,另一类是双列集合元素是一对一对的。 主要学习Collection单列集合。Collection是单列集合的根接口,也称之为顶层接口,Collection接口下面又有两个子接…...

HsMod终极指南:55项功能全面优化炉石传说游戏体验的完整方案
HsMod终极指南:55项功能全面优化炉石传说游戏体验的完整方案 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架开发的炉石传说模改插件,为…...

5分钟掌握HunterPie:解决《怪物猎人:世界》战斗信息盲区的终极指南
5分钟掌握HunterPie:解决《怪物猎人:世界》战斗信息盲区的终极指南 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_…...

【Portal实战指南】STEP 7 Basic许可证丢失排查与一键修复
1. 问题现象与紧急处理 当你满心欢喜地打开TIA Portal准备开始一天的工作,突然弹出一个令人窒息的提示框:"找不到许可证STEP 7 Basic"。这种情况我遇到过不下十次,每次都能让工程师血压瞬间飙升。别慌,我们先来快速判断…...

reverse-shell在企业安全测试中的最佳实践:风险评估与合规使用
reverse-shell在企业安全测试中的最佳实践:风险评估与合规使用 【免费下载链接】reverse-shell Reverse Shell as a Service 项目地址: https://gitcode.com/gh_mirrors/re/reverse-shell reverse-shell作为一款开源的"Reverse Shell as a Service"…...