多视图聚类的论文阅读
当聚类的方式使用的是某一类预定义好的相似性度量时, 会出现如下情况:
数据聚类方面取得了成功,但它们通常依赖于预定义的相似性度量,而这些度量受原始方法的影响:当输入维数相对较高时,往往是无效的。
1. Deep Multi network Embedded Clustering
主要提出使用 DEC(deep Embed clutering ) 深度编码聚类的 方法,对特征进行聚类;
在此基础上加上了几个 多视图的特征;
2. Deep convolutional self-paced clustering
本文中主要用到的研究方法有:
- 无监督聚类;
- 自步学习方式, 将样本从简单到困难的学习方式;
2.1 存在问题与提出的解决方法
2.1.1 存在问题
当数据点均匀地分布在特征空间中相应的质心周围时,Kmeans算法非常有效。然而,K-means通常不适用于高维数据,因为“维数诅咒”造成的相似度度量效率低下。
2.1.2 解决方法
论文的主要贡献:
具体而言,
-
在预训练阶段,我们提出利用卷积自动编码器来提取包含空间相关信息的高质量数据表示。
-
然后,在精调阶段,直接对学习到的特征施加聚类损失,共同进行特征细化和聚类分配。我们保留解码器,以避免特征空间因聚类损失而被扭曲。
-
为了稳定整个网络的训练过程,我们进一步引入了自步长学习机制,并在每次迭代中选择最自信的样本。通过对7个流行图像数据集的综合实验,我们证明了所提出的算法可以持续地超过最先进的竞争对手。
前两个表明, 将特征学习与聚类过程 作为互相辅助的过程,
第三点使用自步 学习的方式,优化过程中样本由易到难,边际样本的不利影响可以得到有效的缓解。 是为了降低不可靠的样本会混淆甚至误导DNN的训练过程,从而严重降低聚类性能。
简单说来, 使用卷积提取特征; 然后对特征进行聚类; 3. 并且在训练过程中,引入自步学习步长机制, 每次迭代过程中选择,最自信的样本;
2.2 实现方法
具体来说,我们的方法包含两个阶段:预训练和微调。
-
在预训练阶段,我们通过最小化重构损失来训练卷积自动编码器 (convolutional autoencoder, CAE) [26]通过使用 CAE,我们的方法可以将数据从一个相对高维和稀疏的空间转换为一个低维和紧凑的空间。
-
,在微调阶段,不同于以往的一些作品[31,32,37]只保留编码器,我们通过使用聚类损失和重构损失对整个自动编码器(即CAE)进行调优,这样可以保留数据属性,避免特征空间的破坏。
- 问题: 代过程中选择,最自信的样本, 那么如何知道哪些样本的可信度高;
3. 多视图表示学习
4. 聚类方法
采用几种聚类方法与DCSPC方法进行比较,大致可分为三类:
-
1)传统方法,包括Kmeans (KM)[5]、高斯混合模型(GMM)[6]和谱聚类(SC) [7];
-
2)基于表示的方法,包括SAE[25]和CAE[26];
-
3)深度聚类方法,由深度嵌入聚类组成(DEC)[32]、改进深度嵌入聚类(IDEC)[33]、深度嵌入网络(DCN)[34]、深度K-means (DKM)[35]、卷积深度嵌入聚类(ConvDEC)[36]、自适应自步调聚类(ASPC)[37]、结构深度嵌入网络(SDCN)[38]、半监督深度嵌入聚类(SDEC)[39]、DDC (deep density-based clustering)[40]
4.1 K means 聚类
当数据点均匀地分布在特征空间中相应的质心周围时,Kmeans算法非常有效。然而,K-means通常不适用于高维数据,因为“维数诅咒”造成的相似度度量效率低下。因此,在实际应用中,我们应该使用降维方法,如PCA[8]、MDS[9]、NMF[10]等,将原始数据投影到低维空间,然后使用K-means算法对低维数据进行聚类,通常会得到更好的结果。除上述线性降维方法外,非线性算法如tSNE[17]、LLE[18]和基于dnn的方法[19-21]被广泛应用于Kmeans算法前的预处理。有兴趣的读者可参考[22-24]进行全面了解。在许多实际应用中,数据可能来自不同的视图,因此,许多多视图聚类方法被提出。例如,Zhang et al.[13]先将多视图样本映射到共享视图空间,然后将样本转换到判别空间,最后对转换后的样本进行K-means聚类。Wang et al.[14]提出了一种通用的基于图的多视图聚类框架,该框架通过提取多视图的特征矩阵,融合图矩阵,生成统一的图矩阵进行直接聚类。考虑到训练数据中可能存在特定类不存在的情况,Hayashi et al.[16]提出了一种基于聚类的零射击学习方法,将数据分为不可见类和可见类。
4.2 无监督聚类
深度无监督聚类方法大致可分为两类。一类是通常独立对待特征学习或聚类的方法,即先将原始数据投射到一个低维的特征空间中,然后用常规的聚类算法对特征点进行分组。不幸的是,这种分离的形式会对集群性能造成限制,因为忽略了这一点特征学习和聚类之间的一些潜在关系。
另一类是使用联合优化准则的方法,它同时进行特征学习和聚类,比分离的方法有很大的优越性。最近,人们提出了几种方法来将特征学习和聚类集成到一个统一的框架中。联合无监督学习(Joint unsupervised learning, JULE)[29]提出在统一加权三态损失的基础上,同时引导聚类和表示学习,但计算复杂度较高。Chang et al.[30]提出了成对图像之间二值关系的假设,并开发了深度自适应聚类(deep adaptive clustering, DAC)模型,将聚类任务重新建立为二值两两分类问题,在6个图像数据集上显示出良好的结果。自适应自定步长聚类(ASPC)[37]借鉴硬加权自定步长学习方法,在聚类网络训练时优先考虑高置信度样本,以消除边际样本的负面影响,稳定训练过程。Ren et al.[40]提出了一种基于深度密度的聚类(DDC)技术,该技术可以自适应估计任意形状的数据聚类数量。基于数据增强的深度嵌入聚类(Deep embedded clustering with data augmentation, DECDA)[36]将数据增强技巧引入到原始的深度嵌入聚类框架中,并在4个灰度图像数据集上取得了良好的聚类性能。半监督深度嵌入聚类(semi - supervised deep embedded clustering, SDEC)[39]克服了DEC[32]不能利用先验知识指导训练过程的缺点。
deep adaptive clustering, DAC 模型: Chang J, Wang L, Meng G, Xiang S, Pan C (2017) Deep adaptive
image clustering. In: International Conference on Computer
Vision, pp 5880–5888
https://github.com/vector-1127/DAC
自适应自定步长聚类(ASPC)[37]借鉴硬加权自定步长学习方法,Guo X, Liu X, Zhu E, Zhu X, Li M, Xu X, Yin J (2020) Adaptive
self-paced deep clustering with data augmentation. IEEE Trans Knowl Data Eng
https://github.com/XifengGuo/ASPC-DA;
半监督深度嵌入聚类(semi - supervised deep embedded clustering, SDEC) Ren Y, Hu K, Dai X, Pan L, Hoi SCH, Xu Z (2019) Semi- supervised deep embedded clustering. Neurocomputing 325:121–
130
https://github.com/yongzx/SDEC-Keras;
5. 自步学习
与课程学习[43]的核心思想相似,self-pace learning的目标是学习一个模型,由易到难,逐步引入样本进行训练。这两种方法之间的明显区别是,前者需要预先确定简单和困难的样本,而后者可以自动从数据本身选择顺序。给定一个训练集X ={(x1, y1), (x2, y2),…,(xn, yn)}和以θ为模型参数的训练模型fθ,则自步学习的总体目标可表示为:
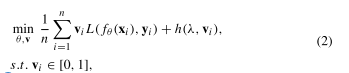
其中,L(·)表示特定问题的损失函数,h(λ, vi)表示独立于L(·)的自步长正则化器,可以以多种形式定义,
V =[v1, v2,…], vn] T代表反映样本复杂性的权重变量,λ是一个参数,称为学习速度,用于控制“模型年龄”,该年龄逐渐增加,以探索更多的样本。当h(λ, vi) =−λvi且vi等于0或1时,自定步学习退化为硬加权形式,即:

另外,对于用固定的v更新θ,问题(3)退化为加权损失最小化问题,该问题可以通过随机梯度下降(SGD)和反向传播(BP)很容易解决。
到目前为止,自定进度学习已被应用于各种任务和模型。Kumar等人的[44]首次证明了一种自定步学习算法在学习潜在结构支持向量机方面的性能优于目前最先进的方法。在[45]中,成功地将自定步长学习范式应用于时间序列的聚类。 Tang Y, Xie Y, Yang X, Niu J, Zhang W (2021) Tensor multi-
elastic kernel self-paced learning for time series clustering. IEEE
Trans Knowl Data Eng 33(3):1223–1237;
Jiang et al.[46]提出了一种自定进度课程学习(self-pace curriculum learning, SPCL)框架,该框架能够联合考虑先验知识和学习进度。为了同时增强有监督学习的鲁棒性和有效性,[47]等人首先提出了自步速boost learning (SPBL)框架,该框架能够揭示和利用boost与自步速学习的关联。Ren et al.[48]注意到标准的自进度学习可能存在类不平衡问题,通过为每个类分配权重和局部选择实例,精心设计了两种新的软加权方案来弥补这一问题。最近,SPUDRFs[49]在公平性方面解决了自进度学习中的排序和选择的基本问题,并可以方便地与各种深度判别模型结合。在SAMVC[50]中,在多视图聚类模型中引入一种软加权自步长学习形式,以减少离群值和噪声的不利影响,并提出一种自加权策略来判断不同视图的重要性。孟等人的[51]设法提供了一些自我节奏学习范式的解释,以追求理论理解。总的来说,这些文献出版物证实了自节奏学习有助于避免陷入不希望出现的局部最小值,并总体上改善模型的性能。
相关文章:
多视图聚类的论文阅读
当聚类的方式使用的是某一类预定义好的相似性度量时, 会出现如下情况: 数据聚类方面取得了成功,但它们通常依赖于预定义的相似性度量,而这些度量受原始方法的影响:当输入维数相对较高时,往往是无效的。 1. Deep Mult…...

shell脚本适用场景
1.适用场景 Shell脚本是一种用于自动化和批量处理任务的脚本语言。它通常在Unix/Linux系统中使用,并且被广泛应用于各种场景,包括但不限于以下几个方面: 自动化任务:Shell脚本可以用于编写自动化脚本,完成一系列重复性…...

Bash openldap同步AD组织数据
将AD的ou同步到openldap(可支持全量同步和增量同步) 整体思路如下: 从ad导出所有的数据,然后进行参数替换以及处理,处理后的文件称为A;从openldap导出所有的数据,然后进行参数替换以及处理&am…...
C#WPF文本转语音实例
本文介绍C#WPF文本转语音实例 实现方法:使用类库(SpeechSynthesizer )实现的。 一、首先是安装程序包。 二、创建项目 需要添加引用using System.Speech.Synthesis; UI界面 <Windowx:Class="TextToSpeechDemo.MainWindow"xmlns="http://schemas.micr…...

08-流媒体-RTMP拉流
整体方案: 采集端:摄像头采集(YUV)->编码(YUV转H264)->写封装(H264转FLV)->RTMP推流 客户端:RTMP拉流->解封装(FLV转H264)…...
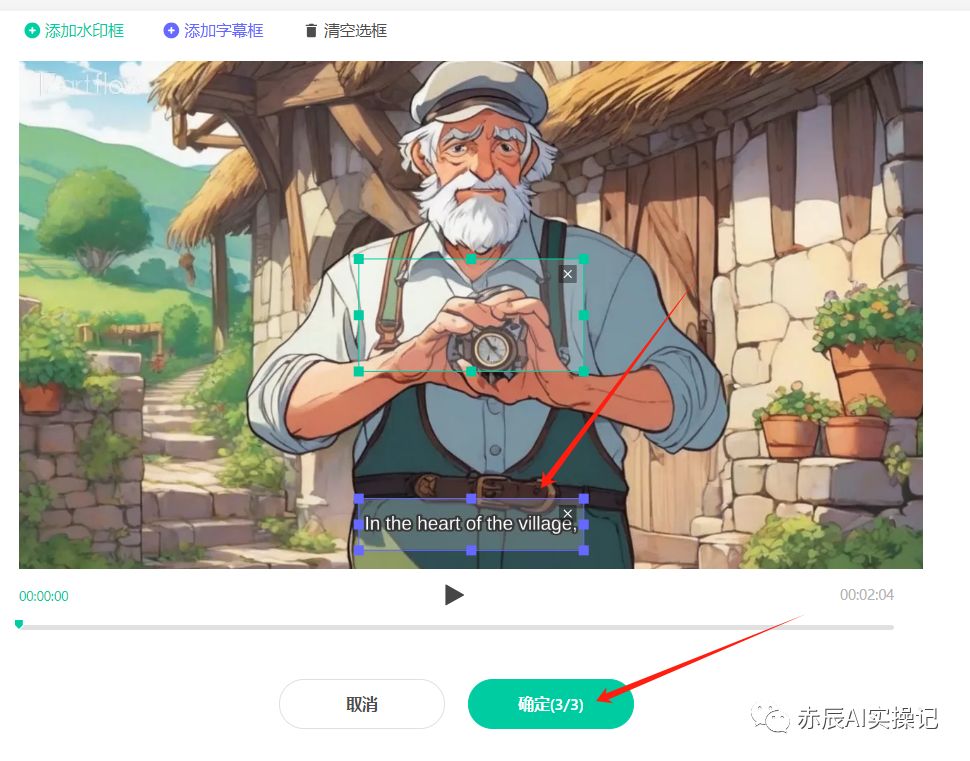
一键免费去除视频水印和字幕的AI工具
最近有学员经常让我分享好用的智能抹除视频水印字幕AI工具,今天就给大家分享一个我经常用到的这款工具——腾讯智影,这个平台提供的智能抹除功能,借助这个工具我们可以将视频中不需要的字幕或者水印删除掉。 不过这款工具每天有三次免费次数…...
实验六:Android的网络编程基础
实验六:Android 的网络编程基础 6.1 实验目的 本次实验的目的是让大家熟悉 Android 开发中的如何获取天气预报,包括了 解和熟悉 WebView、WebService 使用、网络编程事件处理等内容。 6.2 实验要求 熟悉和掌握 WebView 使用 了解 Android 的网络编程…...

09-流媒体-FLV解复用
整体方案: 采集端:摄像头采集(YUV)->编码(YUV转H264)->写封装(H264转FLV)->RTMP推流 客户端:RTMP拉流->解封装(FLV转H264)…...

信息的浏览
万维网(WWW)是目前Internet上最流行的一种服务,它是建立在Internet上的多媒体集合信息系统。它利用超媒体的信息获取技术,通过一种超文本的表达方式,将所有WWW上的信息连接在一起。我们使用浏览器浏览网上的信息。 ▶浏览器 浏览器是指可以…...

vue directive自定义指令实现弹窗可拖动
vue2 创建一个js文件 // draggable.js export default {// 定义 Vue 插件install(Vue) {Vue.directive(draggable, { // 全局指令名为 v-draggableinserted(el) {el.onmousedown function (ev) {// 获取鼠标按下时的偏移量(鼠标位置 - 元素位置)const…...

07-流媒体-RTMP推流
整体方案: 采集端:摄像头采集(YUV)->编码(YUV转H264)->写封装(H264转FLV)->RTMP推流 客户端:RTMP拉流->解封装(FLV转H264)…...
Neo4j安装(Docker中安装Neo4j)
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

面试求职者
顾x文 SQLite3数据的使用实现了多线程UDP数据收发功能Qt多线程的同步和异步熟悉GDB的调试了解Mysql的性能优化熟悉常见算法:快速排序、希尔排序、归并排序基于Nginx C Mysql Python ICE开发熟练Boost库负责搭建后台服务端,使用Nginx展示前端界面&am…...
Java NIO 详解
一、NIO简介 NIO 是 Java SE 1.4 引入的一组新的 I/O 相关的 API,它提供了非阻塞式 I/O、选择器、通道、缓冲区等新的概念和机制。相比与传统的 I/O 多出的 N 不是单纯的 New,更多的是代表了 Non-blocking 非阻塞,NIO具有更高的并发性、可扩…...

css设置下划线
css中设置下划线的方法 在CSS中可以使用text-decoration属性或border-bottom属性来给字体设置下划线样式。 1、使用text-decoration:underline;设置下划线样式 CSS的text-decoration属性用于指定添加到文本的修饰,其underline属性值可以定义文本下的一条线。 语…...

【献给过去的自己】栈实现计算器(C语言)
背景 记得在刚学C语言时,写了一篇栈实现计算器-CSDN博客文章。偶然间看到了文章的阅读量以及评论,居然有1.7w的展现和多条博友的点评,反馈。 现在回过头来看,的确有许多不严谨的地方,毕竟当时分享文章时,还…...

如何利用ChatGPT撰写学术论文?
在阅读全文前请注意,本文是利用ChatGPT“辅助完成”而不是“帮写”学术论文,请一定要注意学术规范! 本文我将介绍如何使用清晰准确的“指令”让ChatGPT帮助我们在论文写作上提高效率,希望通过本文的指导,读者能够充分…...

【PG】PostgreSQL高可用方案repmgr管理之配置文件
1 配置文件 1.1 配置文件格式 repmgr.conf是一个纯文本文件,每行包含一个参数/值组合。 空格是无关紧要的(除了在带引号的参数值内),并且空行将被忽略。#将该行的其余部分指定为注释。不是简单标识符或数字的参数值应该用单引号…...

labelme自动标注工具
可以实现多图中相同目标的追踪,自动标注目标位置,速度极快,有需要评论...

【C++学习手札】模拟实现vector
🎬慕斯主页:修仙—别有洞天 ♈️今日夜电波:くちなしの言葉—みゆな 0:37━━━━━━️💟──────── 5:28 🔄 ◀️ ⏸ ▶️ ☰…...
AgentCPM-Report研报系统实操:Pixel Epic贤者响应延迟优化教程
AgentCPM-Report研报系统实操:Pixel Epic贤者响应延迟优化教程 1. 认识Pixel Epic智识终端 Pixel Epic是一款基于AgentCPM-Report大模型构建的创新研究报告辅助系统。与传统AI工具不同,它将枯燥的科研过程转化为一场像素风格的RPG冒险。在这个系统中&a…...

AsrTools终极指南:三步实现免费语音转文本,效率提升300%的完整方案
AsrTools终极指南:三步实现免费语音转文本,效率提升300%的完整方案 【免费下载链接】AsrTools ✨ AsrTools: Smart Voice-to-Text Tool | Efficient Batch Processing | User-Friendly Interface | No GPU Required | Supports SRT/TXT Output | Turn yo…...

docker部署jar包的几种方式
docker部署jar包的几种方式前言使用Dockerfile手动打包jarDockerfile可复用容器jdk镜像直接创建可复用容器maven插件打包maven打包自动推送镜像到指定服务器关于docker容器启动后注册到nacos的ip是docker容器ip问题!总结前言 简单记录一下docker打包jar部署的几种方…...

Qwen3.5-2B轻量化技术解析:模型剪枝+KV Cache优化如何降低70%显存占用
Qwen3.5-2B轻量化技术解析:模型剪枝KV Cache优化如何降低70%显存占用 1. 轻量化模型的核心价值 在AI模型部署领域,大模型的资源消耗一直是阻碍其广泛应用的瓶颈。Qwen3.5-2B作为一款仅20亿参数的多模态基础模型,通过创新的轻量化技术实现了…...

解锁3大自由:5分钟掌握的音乐格式解放工具
解锁3大自由:5分钟掌握的音乐格式解放工具 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 在数字音乐时代,我们却常常面临这样的困境:下载的音乐被限制在特定播放器中,就像拥有一本精美…...

影墨·今颜模型API接口开发与调用全指南
影墨今颜模型API接口开发与调用全指南 你是不是已经成功部署了影墨今颜模型,看着它能在本地生成惊艳的图片,心里正盘算着怎么把它变成一个能对外服务的“产品”?比如,让公司的设计团队直接调用,或者集成到自己的应用里…...

SOONet模型Python入门实践:用10行代码实现视频片段搜索
SOONet模型Python入门实践:用10行代码实现视频片段搜索 你是不是也遇到过这种情况:手里有一段很长的视频,想快速找到某个特定场景,比如“主角第一次出场的时候”或者“那个爆炸的镜头”,结果只能手动拖进度条…...

忍者像素绘卷镜像免配置部署:自动检测GPU型号并加载最优配置
忍者像素绘卷镜像免配置部署:自动检测GPU型号并加载最优配置 1. 产品概览:打破次元壁的像素艺术工作站 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工作站,专为像素艺术创作而设计。它将传统漫画创作与现代AI技术相结合&#x…...

终极指南:如何使用RPGMakerDecrypter轻松解密游戏资源
终极指南:如何使用RPGMakerDecrypter轻松解密游戏资源 【免费下载链接】RPGMakerDecrypter Tool for extracting RPG Maker XP, VX and VX Ace encrypted archives. 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMakerDecrypter RPGMakerDecrypter是一款…...
)
【实用工具教程专栏】GitHub Actions自动化工作流入门(基础篇)
引言 在现代软件开发中,持续集成与持续部署(CI/CD)已成为提升开发效率、保证代码质量的核心实践。GitHub Actions作为GitHub官方推出的自动化工作流平台,以其原生集成、灵活配置、丰富生态等特点,成为开发者构建自动化…...