Hadoop3.3.4分布式安装
安装前提:已经配置好java环境,所有机器之间ssh的免密登录。
注意:下文中的flinkv1、flinkv2、flinkv3是三台服务器的别名
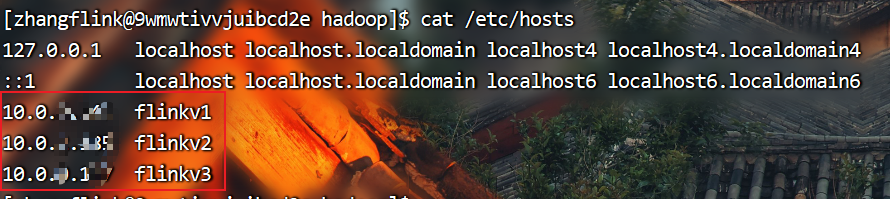
1.集群部署规划
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台
机器上。

2.上传安装包到linux系统上
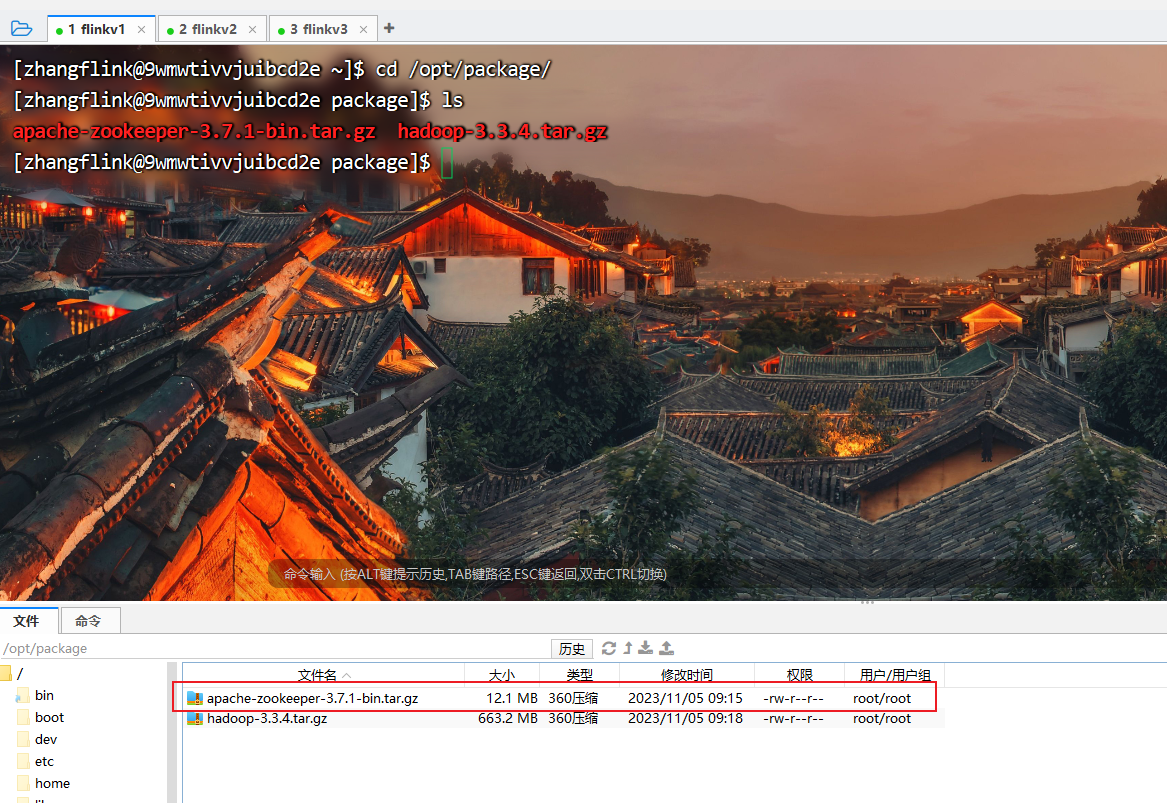
3.进入到Hadoop安装包路径下
[zhangflink@9wmwtivvjuibcd2e ~]$ cd /opt/package/
4.解压安装文件到/opt/module下面
[zhangflink@9wmwtivvjuibcd2e package]$ tar -zxvf hadoop-3.3.4.tar.gz -C ../software/
5.查看是否解压成功
[zhangflink@9wmwtivvjuibcd2e package]$ cd ../software/
[zhangflink@9wmwtivvjuibcd2e software]$ ls

6.重命名
[zhangflink@9wmwtivvjuibcd2e software]$ mv hadoop-3.3.4/ hadoop
[zhangflink@9wmwtivvjuibcd2e software]$ ls

7.将Hadoop添加到环境变量
(1)获取Hadoop安装路径
[zhangflink@9wmwtivvjuibcd2e software]$ cd hadoop/
[zhangflink@9wmwtivvjuibcd2e hadoop]$ pwd

(2)打开/etc/profile文件
[zhangflink@9wmwtivvjuibcd2e hadoop]$ sudo vim /etc/profile
在profile文件末尾添加JDK路径:(shitf+g)
> #HADOOP_HOME export
> HADOOP_HOME=/opt/software/hadoop
> export PATH=$PATH:$HADOOP_HOME/bin
> export PATH=$PATH:$HADOOP_HOME/sbin
(3)保存后退出
:wq
(4)分发环境变量文件
[zhangflink@9wmwtivvjuibcd2e hadoop]$ /home/zhangflink/bin/xsync /etc/profile
(5)source 是之生效(3台节点)
[zhangflink@9wmwtivvjuibcd2e hadoop]$ source /etc/profile
8.配置集群
(1)核心配置文件
配置core-site.xml
[zhangflink@9wmwtivvjuibcd2e hadoop]$ cd etc/
[zhangflink@9wmwtivvjuibcd2e etc]$ cd hadoop/
[zhangflink@9wmwtivvjuibcd2e hadoop]$ vim core-site.xml
在配置文件最下面的configuration中间添加如下配置项
<configuration>
<!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://flinkv1:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/software/hadoop/data</value>
</property><!-- 配置HDFS网页登录使用的静态用户为atguigu --><property><name>hadoop.http.staticuser.user</name><value>zhangflink</value>
</property><!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.zhangflink.hosts</name><value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.zhangflink.groups</name><value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.zhangflink.users</name><value>*</value>
</property>
</configuration>
(2)HDFS配置文件
[zhangflink@9wmwtivvjuibcd2e hadoop]$ vim hdfs-site.xml
<configuration>
<!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>flinkv1:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>flinkv3:9868</value></property><!-- 测试环境指定HDFS副本的数量1 --><property><name>dfs.replication</name><value>1</value></property>
</configuration>

(3)YARN配置文件
[zhangflink@9wmwtivvjuibcd2e hadoop]$ vim yarn-site.xml
<configuration>
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>flinkv2</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
</configuration>
(4)MapReduce配置文件
[zhangflink@9wmwtivvjuibcd2e hadoop]$ vim mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>

(5)配置workers
[zhangflink@9wmwtivvjuibcd2e hadoop]$ vim workers
flinkv1
flinkv2
flinkv3
9.配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器
(1)配置mapred-site.xml
[zhangflink@9wmwtivvjuibcd2e hadoop]$ vim mapred-site.xml
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>flinkv1:10020</value>
</property><!-- 历史服务器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>flinkv1:19888</value>
</property>
10.配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
(1)配置yarn-site.xml
<!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property><!-- 设置日志聚集服务器地址 -->
<property><name>yarn.log.server.url</name><value>http://flinkv1:19888/jobhistory/logs</value>
</property><!-- 设置日志保留时间为7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
11.分发Hadoop
[zhangflink@9wmwtivvjuibcd2e software]$ /home/zhangflink/bin/xsync hadoop/
12.群起集群
(1)启动集群
如果集群是第一次启动,需要在flinkv1节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[zhangflink@9wmwtivvjuibcd2e hadoop]$ bin/hdfs namenode -format

(2)启动HDFS
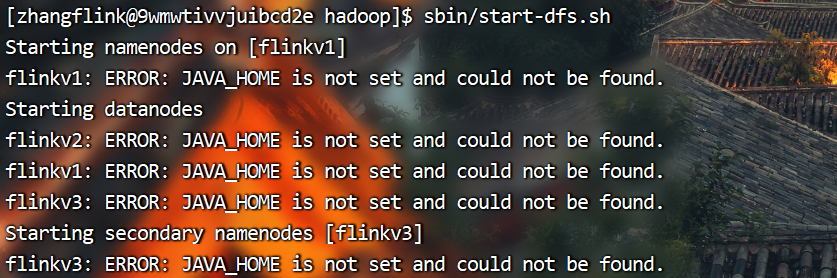
启动HDFS如果出现以上报错,可能是没有配置java环境变量,首先检查系统java环境是否配置成功

如果系统环境如上图所示正常,那么就是hadoop的配置文件没有配置java环境变量路径导致。
只需按如下配置hadoop-env.sh文件即可
编辑hadoop-env.sh文件
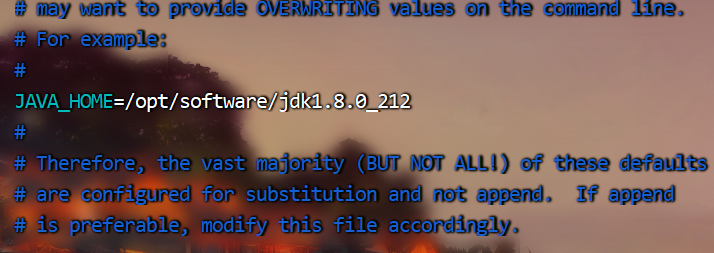
[zhangflink@9wmwtivvjuibcd2e hadoop]$ vim etc/hadoop/hadoop-env.sh
找到java环境修改配置
JAVA_HOME=/opt/software/jdk1.8.0_212
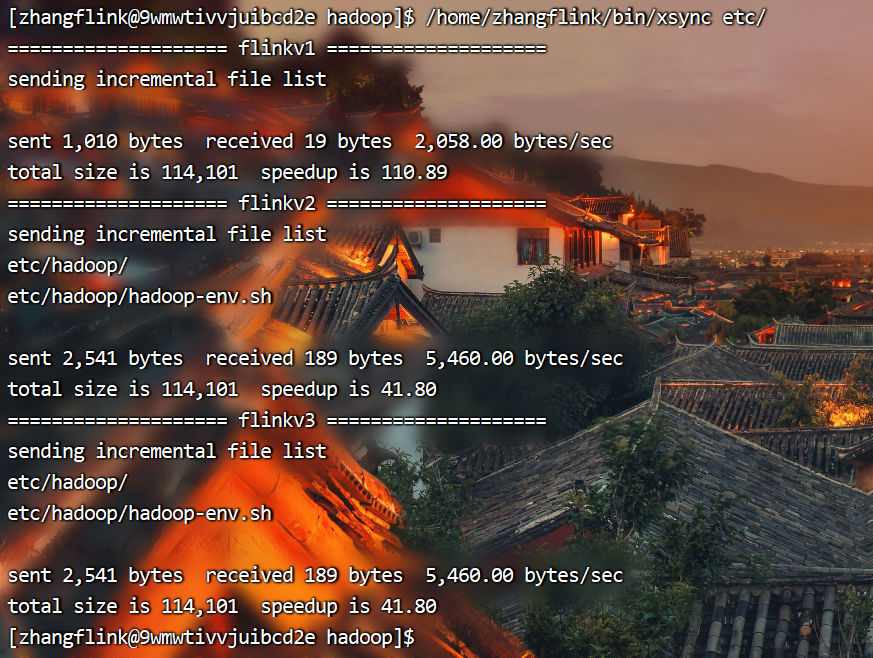
分发hadoop配置文件
[zhangflink@9wmwtivvjuibcd2e hadoop]$ /home/zhangflink/bin/xsync etc/
再次启动HDFS
[zhangflink@9wmwtivvjuibcd2e hadoop]$ sbin/start-dfs.sh
查看进程
[zhangflink@9wmwtivvjuibcd2e hadoop]$ jps
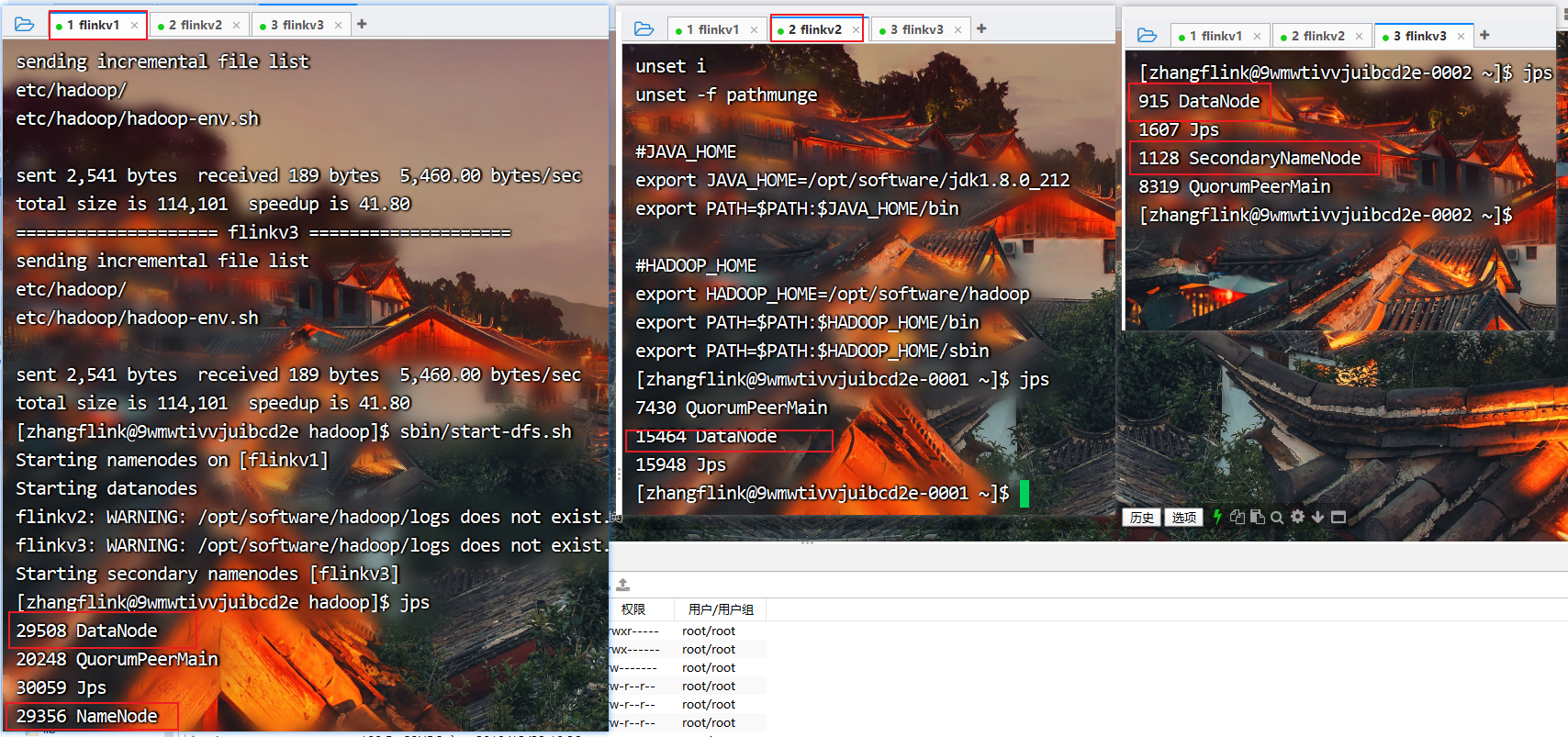
(3)在配置了ResourceManager的节点(flinkv2)启动YARN
[zhangflink@9wmwtivvjuibcd2e-0001 hadoop]$ sbin/start-yarn.sh
查看进程
[zhangflink@9wmwtivvjuibcd2e hadoop]$ jps

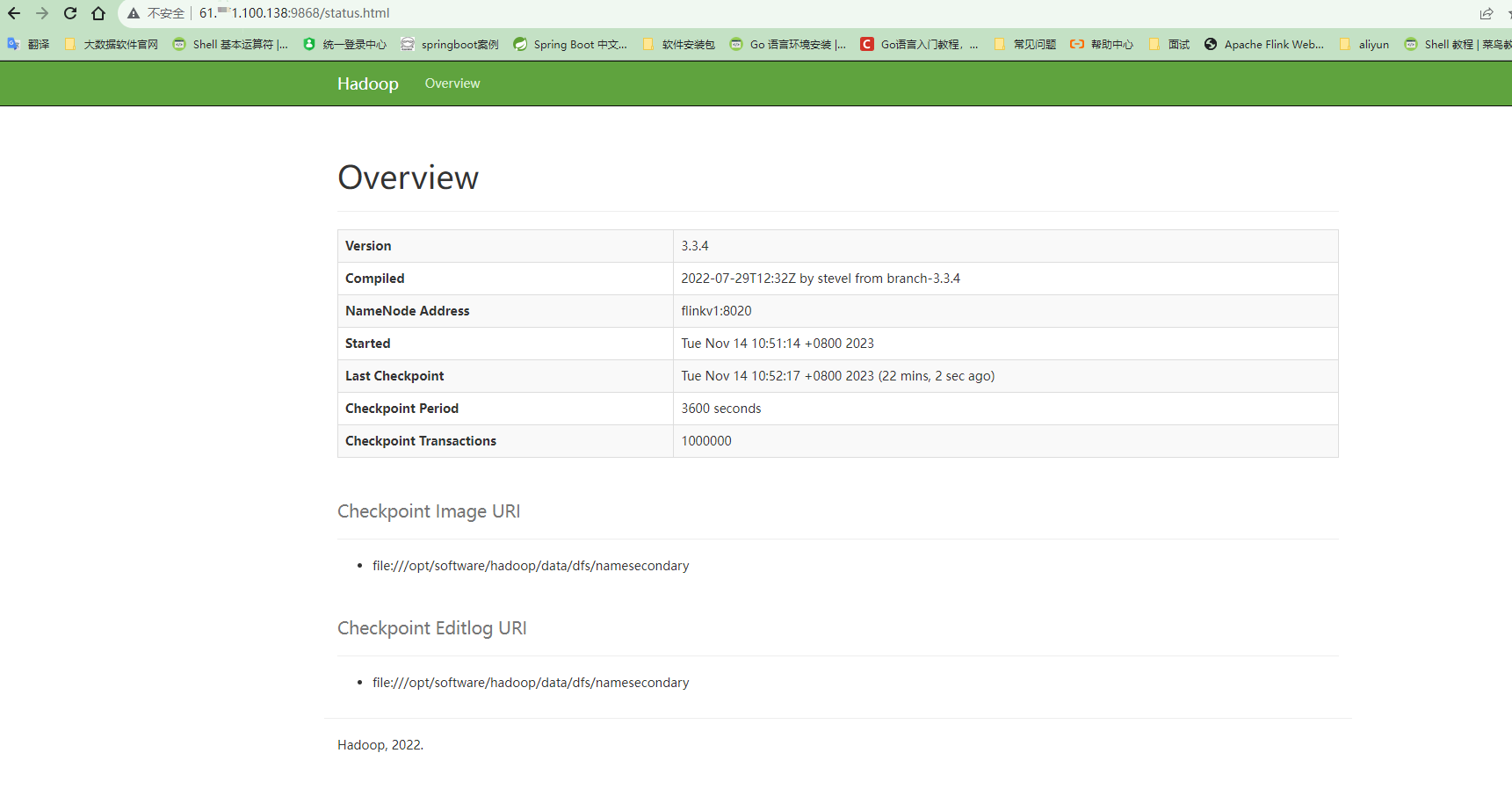
(4)Web端查看HDFS的Web页面:http://flinkv1:9870/ (云服务器请使用公网IP地址访问,确保端口的安全组入口已经开发)
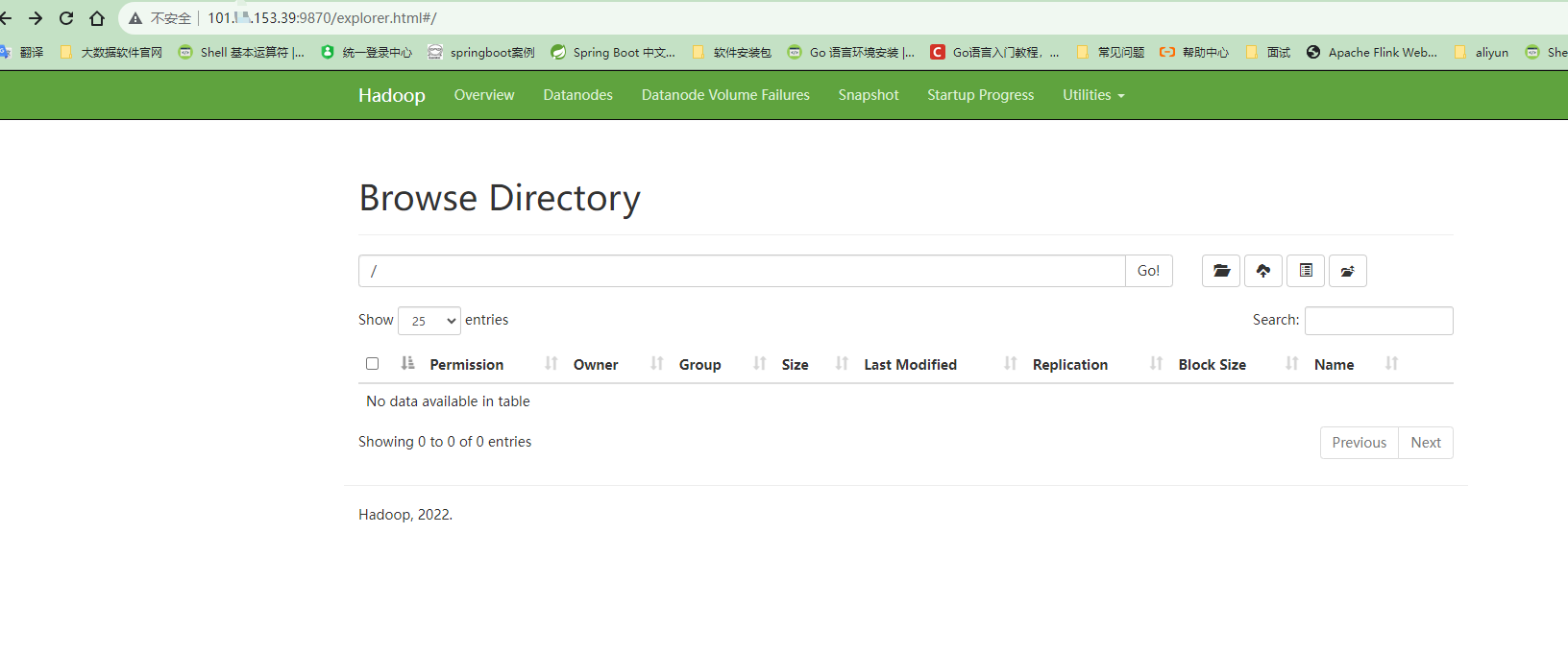
(5)Web端查看SecondaryNameNode
相关文章:
Hadoop3.3.4分布式安装
安装前提:已经配置好java环境,所有机器之间ssh的免密登录。 注意:下文中的flinkv1、flinkv2、flinkv3是三台服务器的别名 1.集群部署规划 注意:NameNode和SecondaryNameNode不要安装在同一台服务器 注意:ResourceMan…...

SQL ALTER TABLE 语句||SQL AUTO INCREMENT 字段
SQL ALTER TABLE 语句 ALTER TABLE 语句 ALTER TABLE 语句用于在现有表中添加、删除或修改列。 SQL ALTER TABLE 语法 若要向表中添加列,请使用以下语法: ALTER TABLE table_name ADD column_name datatype 若要删除表中的列&am…...

【源码系列】短剧系统开发国际版短剧系统软件平台介绍
系统介绍 短剧是一种快节奏、紧凑、有趣的戏剧形式,通过短时间的精彩表演,向观众传递故事的情感和思考。它以其独特的形式和魅力,吸引着观众的关注,成为了当代戏剧娱乐中不可或缺的一部分。短剧每一集都是一个小故事,…...
JavaWeb[总结]
文章目录 一、Tomcat1. BS 与 CS 开发介绍1.1 BS 开发1.2 CS 开发 2. 浏览器访问 web 服务过程详解(面试题)2.1 回到前面的 JavaWeb 开发技术栈图2.2 浏览器访问 web 服务器文件的 UML时序图(过程) ! 二、动态 WEB 开发核心-Servlet1. 为什么会出现 Servlet2. 什么是…...

如何解决小程序异步请求问题
小程序异步请求问题指的是在小程序中进行异步请求时可能会出现的问题,比如请求失败、请求超时等。以下是一些解决方案: 检查网络连接:首先需要确保网络连接正常,只有网络连接正常时才能正常进行异步请求。 检查请求参数ÿ…...
NSSCTF第12页(3)
[NSSCTF 2nd]php签到 首先,代码定义了一个名为 waf 的函数,用于执行一个简单的文件扩展名检查来防止上传恶意文件。 $black_list 是一个存储不允许的文件扩展名的数组,如 “ph”、“htaccess” 和 “ini”。 pathinfo($filename, PATHINF…...
基于ssm+vue交通事故档案系统
摘要 摘要是对文章、论文或其他文本的主要观点、结论和关键信息的简洁概括。由于你没有提供具体的文章或主题,我将为你创建一个通用的摘要。 本文介绍了一种基于SSM(Spring Spring MVC MyBatis)和Vue.js的交通事故档案管理系统的设计与实现…...

DNS1(Bind软件)
名词解释 1、DNS(Domain Name System) DNS即域名系统,它是一个分层的分布式数据库,存储着IP地址与主机名的映射 2、域和域名 域为一个标签,而有多个标签域构成的称为域名。例如hostname.example.com,其…...
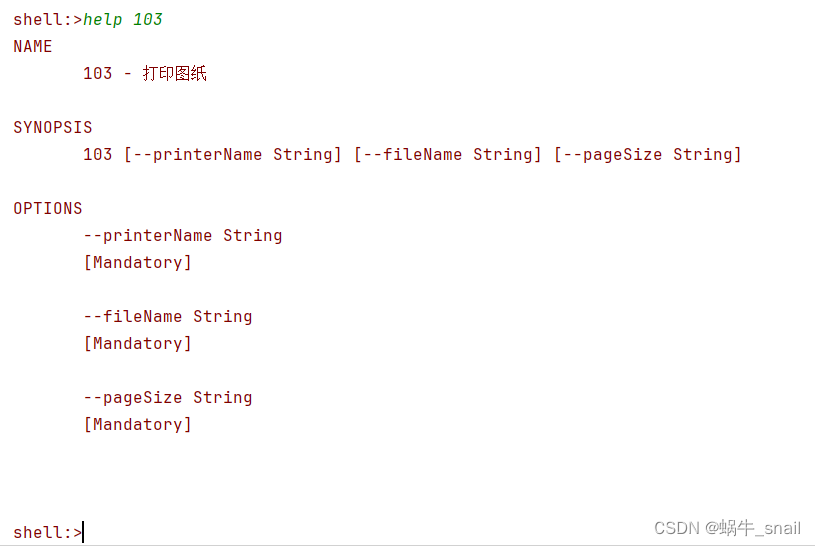
PDF自动打印
最近接到用户提过来的需求,需要一个能够自动打印图纸的功能,经过几天的研究整出来个初版了的,分享出来给大家,希望能有帮助。 需求描述: 生产车间现场每天都有大量的图纸需要打印,一个一个打印太慢了࿰…...

【C#】类型转换-显式转换:括号强转、Parse法、Convert法、其他类型转string
目录 一、括号强转 1.有符号整型 2.无符号整型 3.浮点之间 4.无符号和有符号 5.浮点和整型 6.char和数值类型 7.bool和string是不能够通过 括号强转的 二、Parse法 1.有符号 2.无符号 3.浮点型 4.特殊类型 三、Convert法 1.转字符串 2.转浮点型 3.特殊类型转换…...
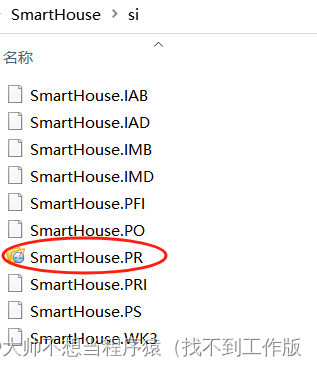
【智能家居】4、智能家居框架设计和代码文件工程建立
目录 一、智能家居项目框架 二、智能家居工厂模式示意 三、代码文件工程建立 SourceInsight创建新工程步骤 一、智能家居项目框架 二、智能家居工厂模式示意 三、代码文件工程建立 创建一个名为si的文件夹用于保存SourceInsight生成的文件信息,然后在SourceInsig…...

【GAN】数据增强基础知识
最近要用到,但是一点基础都没有,故开个文章记录一下笔记 目录 GAN DCGAN WGAN EEGGAN GAN 参考 生成对抗网络(GAN) - 知乎 (zhihu.com) 文章 [1406.2661] Generative Adversarial Networks (arxiv.org) 代码 GitHub - …...
)
Skywalking流程分析_3(服务的准备、启动、关闭)
前文将SkyWalkingAgent.premain中的: SnifferConfigInitializer.initializeCoreConfig(agentArgs)pluginFinder new PluginFinder(new PluginBootstrap().loadPlugins())这两个方法分析完毕,下面继续分析premain方法其余部分 创建byteBuddy final By…...
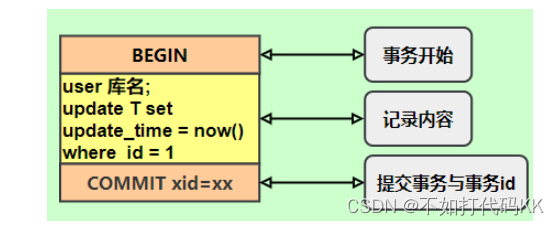
mysql中的各种日志文件redo log、undo log和binlog
mysql中的各种日志文件redo log、undo log和binlog mysql中的各种日志文件redo log、undo log和binlog1.MySQL日志文件类型2.redo log日志2.1 作用2.2工作原理:2.3详解 3.undo log日志4.binlog日志5.总结 mysql中的各种日志文件redo log、undo log和binlog 1.MySQL…...

【电视剧-长相思】经典语录
小编看了这么长时间的电视剧,突然感觉摘抄经典语录最有成就感,嘿嘿,下面是我在《长相思》(第一季)中感觉好的一些语录,语录是乱序排列哈 玟小六:我怕寂寞,寻不到长久的相依ÿ…...

串口通信原理及应用
Content 1. 前言介绍2. 连接方式3. 数据帧格式4. 代码编写 1. 前言介绍 串口通信是一种设备间非常常用的串行接口,以比特位的形式发送或接收数据,由于成本很低,容易使用,工程师经常使用这种方式来调试 MCU。 串口通信应用广泛&a…...
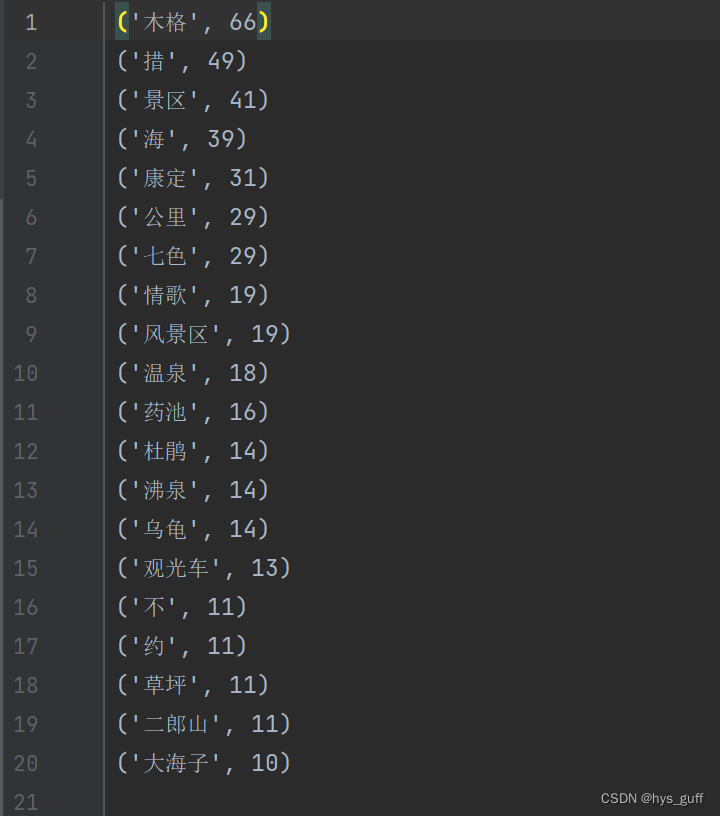
python爬取穷游网景点评论
爬取穷游网的景点评论数据,使用selenium爬取edge浏览器的网页文本数据。 同程的评论数据还是比较好爬取,不像大众点评需要你登录验证杂七杂八的,只需要找准你想要爬取的网页链接就能拿到想要的文本数据。 这里就不得不提一下爬取过程中遇到的…...

Phar 文件上传以及反序列化
1.phar反序列化 触发条件: 1、能将phar文件上传 2、可利用函数 stat、fileatime、filectime、file_exists、file_get_contents、file_put_contents、file、filegroup、fopen、fileinode、filemtime、fileowner、fileperms、is_dir、is_executable、is_file、is_link…...
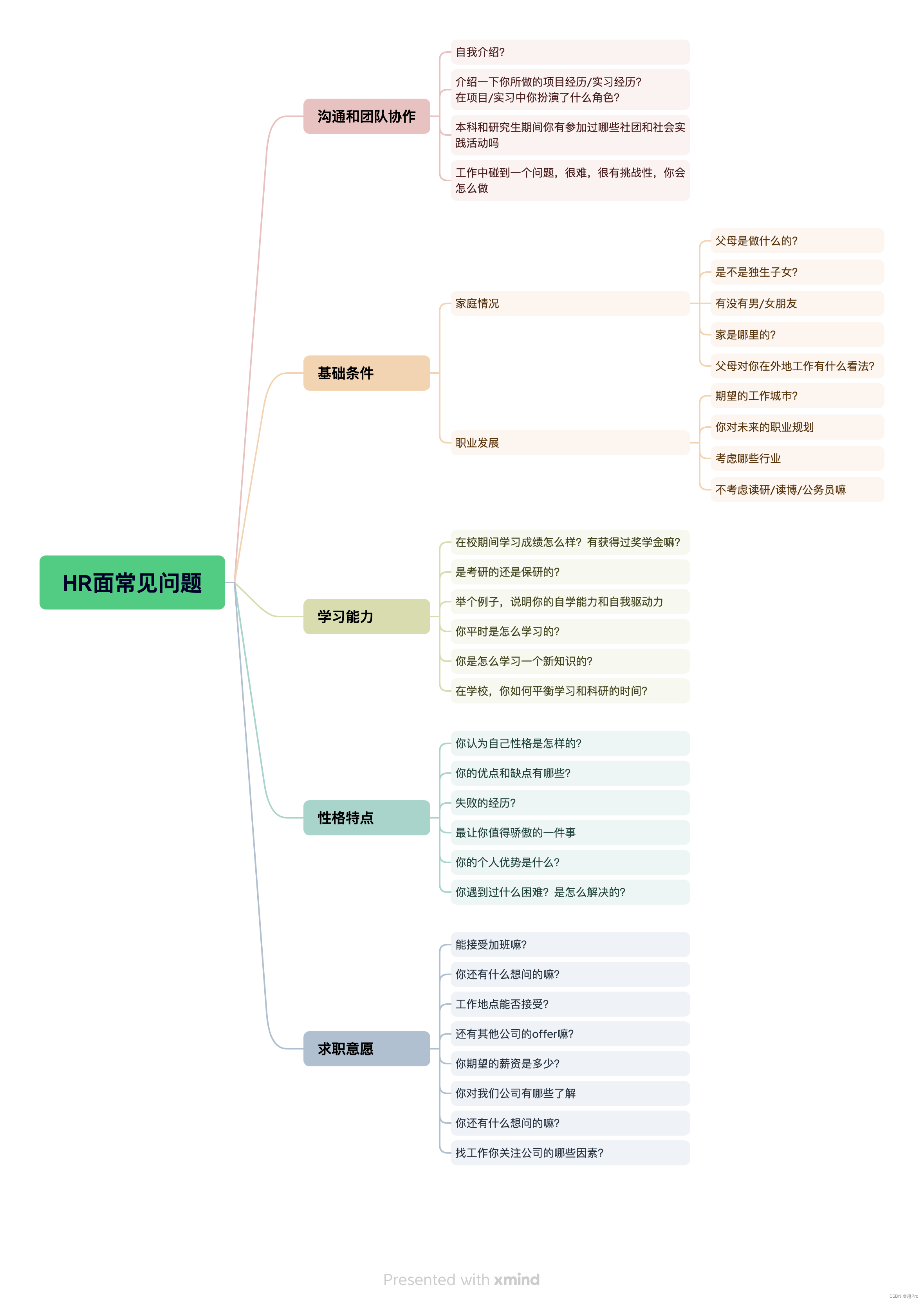
面试其他注意事项
面试其他注意事项 一、面试反问 这个岗位的日常工作和主要职责是什么?咱们这边主要负责什么业务,用到了哪些技术呢?对于我们校招生有没有培养体系呢?脱产培训,还是边工作边熟悉?会有导师带嘛?…...

sklearn 笔记 BallTree/KD Tree
由NearestNeighbors类包装 1 主要使用方法 sklearn.neighbors.BallTree(X, leaf_size40, metricminkowski, **kwargs) X数据集中的点数leaf_size改变 leaf_size 不会影响查询的结果,但可以显著影响查询的速度和构建树所需的内存metric用于距离计算的度量。默认为…...

基于 SpringBoot 的自助图书借阅管理系统源码讲解
以下是一个基于 SpringBoot 的自助图书借阅管理系统的 核心源码讲解,涵盖用户管理、图书管理、借阅管理、设备对接等关键模块,代码结构清晰,可直接用于学习或二次开发。一、项目结构src/main/java/com/library/ ├── config/ # 配…...

迪文串口屏C51开发避坑指南:从ModBus ASCII模式到音乐播放实战
迪文串口屏C51开发实战:从ModBus ASCII到音乐播放的深度解析 迪文串口屏在工业控制领域占据重要地位,其C51开发环境为开发者提供了高度灵活的定制能力。本文将聚焦三个典型开发场景:ModBus ASCII模式移植、C51变量定义导致的定时问题以及音乐…...

从FamNet到通用计数:小样本学习如何让AI“数”遍万物
1. 小样本计数的革命:从专用工具到通用能力 记得我第一次接触物体计数任务时,用的还是专门针对人群计数的模型。当时为了统计商场人流量,不得不专门训练一个模型。后来遇到统计停车场的需求,又要重新收集数据训练新模型。这种&quo…...

RexUniNLU异常检测能力:识别虚假评论与垃圾内容
RexUniNLU异常检测能力:识别虚假评论与垃圾内容 1. 效果惊艳开场 打开任何一个内容平台,评论区总是最热闹的地方。但你可能不知道,每10条评论里,就有2-3条是机器生成的广告、水军刷的好评,或者是纯粹的垃圾信息。这些…...

Graphormer在药物发现中的应用:催化剂吸附预测落地实践
Graphormer在药物发现中的应用:催化剂吸附预测落地实践 1. 项目背景与价值 在药物研发和材料科学领域,分子属性预测一直是一项耗时且昂贵的任务。传统实验方法需要大量试错,而计算化学方法又面临精度与效率的平衡问题。Graphormer作为一款基…...

编程技巧:模式切换程序框架
目录 1.模式切换程序框架 2.实现思路 3.模式切换程序框架 4.模式切换每个模式模块化流程 5.代码 Mode1.c Mode2.c Mode3.c Global.c main.c 1.模式切换程序框架 Init:进入模式前,执行一遍,用于初始化工作 Loop:执行完In…...

AIVideo效果对比展示:不同参数下的视频生成质量评测
AIVideo效果对比展示:不同参数下的视频生成质量评测 1. 开场白:参数设置对视频效果的影响 你有没有遇到过这样的情况:用AI生成视频时,明明输入的内容一样,但出来的效果却天差地别?有时候画面模糊不清&…...

工业质检实战:用Real-IAD D³的‘伪3D’光度立体数据,搞定MVTec搞不定的细微划痕
工业质检实战:用Real-IAD D的‘伪3D’光度立体数据,搞定MVTec搞不定的细微划痕 在精密制造领域,金属表面0.1mm级的发丝划痕往往成为质检工程师的噩梦。传统2D视觉系统受限于平面成像原理,对这类微观三维形变束手无策;而…...

SinricPro Business SDK:面向量产的ESP32物联网固件开发套件
1. SinricPro Business SDK 概述SinricPro Business SDK 是专为商业化物联网产品设计的嵌入式软件开发套件,其核心定位并非面向 hobbyist 的快速演示工具,而是面向量产级硬件产品的固件基础设施。与社区版 SinricPro SDK 不同,Business SDK 在…...
)
WebLogic T3协议漏洞实战:5分钟搞定ConnectionFilterImpl配置(附常见问题排查)
WebLogic T3协议安全加固实战:ConnectionFilterImpl配置与深度防御指南 1. 漏洞背景与防御必要性 WebLogic作为企业级Java应用服务器,其专有的T3协议长期存在反序列化漏洞风险。攻击者通过构造恶意T3协议数据包,可在未授权情况下实现远程代码…...