大数据基础设施搭建 - Hadoop
文章目录
- 一、下载安装包
- 二、上传压缩包
- 三、解压压缩包
- 四、配置环境变量
- 五、测试Hadoop
- 5.1 测试hadoop命令
- 5.2 测试wordcount案例
- 5.2.1 创建wordcount输入文本信息
- 5.2.2 执行程序
- 5.2.3 查看结果
- 六、分发压缩包到集群中其他机器
- 6.1 分发压缩包
- 6.2 解压压缩包
- 6.3 配置环境变量
- 七、配置集群
- 7.1 核心配置文件
- 7.2 HDFS配置文件
- 7.3 YARN配置文件
- 7.4 MapReduce配置文件
- 7.5 分发配置文件
- 八、启动集群
- 8.1 编辑workers文件确定数据节点
- 8.2 启动集群
- 步骤1: 格式化NameNode(首次启动集群时)
- 步骤2:启动HDFS
- 步骤3:启动YARN
- 步骤4:测试WEB访问
- (1)配置阿里云安全组
- (2)浏览器访问
- 九、测试集群
- 9.1 上传文件
- 9.2 查看文件
- 9.3 下载文件
- 9.4 执行程序
- 十、配置历史服务器
- 10.1 修改配置文件
- 10.2 分发配置文件
- 10.3 启动历史服务器
- 10.4 访问WEB
- 十一、配置日志的聚集
- 11.1 修改配置文件
- 11.2 分发配置文件
- 11.3 重启NM、RM、HistoryServer
- 11.4 测试
- (1)删除HDFS已经存在的输出文件
- (2)执行WordCount程序
- (3)查看日志
一、下载安装包
https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
二、上传压缩包
使用普通账号,上传到/opt/software目录
三、解压压缩包
使用普通账号
[hadoop@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
四、配置环境变量
[hadoop@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh
新增内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
让新的环境变量PATH生效:
[hadoop@hadoop102 hadoop-3.1.3]$ source /etc/profile
五、测试Hadoop
5.1 测试hadoop命令
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop version
5.2 测试wordcount案例
5.2.1 创建wordcount输入文本信息
[hadoop@hadoop102 hadoop-3.1.3]$ mkdir wcinput
[hadoop@hadoop102 hadoop-3.1.3]$ cd wcinput/
[hadoop@hadoop102 wcinput]$ vim word.txt
内容:
hadoop yarn
hadoop mapreduce
vimgo
jbl jbl jbl
5.2.2 执行程序
[hadoop@hadoop102 hadoop-3.1.3]$ cd /opt/module/hadoop-3.1.3
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput/ wcoutput/
5.2.3 查看结果
[hadoop@hadoop102 hadoop-3.1.3]$ cd wcoutput/
[hadoop@hadoop102 wcoutput]$ cat part-r-00000
hadoop 2
jbl 3
mapreduce 1
vimgo 1
yarn 1
六、分发压缩包到集群中其他机器
6.1 分发压缩包
[hadoop@hadoop102 module]$ cd /opt/software/
[hadoop@hadoop102 software]$ mytools_rsync hadoop-3.1.3.tar.gz
6.2 解压压缩包
同第三步骤
6.3 配置环境变量
同第四步骤
七、配置集群
有两种类型的配置文件:*-default.xml 和 *-site.xml。 *-site.xml 中的配置项覆盖 *-default.xml的相同配置项。
7.1 核心配置文件
core-default.xml:默认的核心Hadoop属性配置文件。该配置文件位于下面的JAR文件中:hadoop-common-x.x.x.jar
[hadoop@hadoop102 software]$ cd $HADOOP_HOME/etc/hadoop
[hadoop@hadoop102 hadoop]$ vim core-site.xml
新增内容:
<!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:9820</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置HDFS网页登录使用的静态用户为hadoop --><property><name>hadoop.http.staticuser.user</name><value>hadoop</value></property><!-- 配置该hadoop用户(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><!-- 配置该hadoop用户(superUser)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property><!-- 配置该hadoop用户(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.hadoop.users</name><value>*</value></property>
说明:
fs.defaultFS:文件系统地址。可以是HDFS,也可以是ViewFS等其他文件系统。
hadoop.tmp.dir:默认值为/tmp/hadoop-${user.name}。比如跑MR时生成的临时路径本质上其实就是生成在它的下面,当然如果你不想也可以去更改 mapred-site.xml 文件。再比如,如果你不配置namenode和datanode的数据存储路径,那么默认情况下,存储路径会放在hadoop.tmp.dir所指路径下的dfs路径中。
hadoop.http.staticuser.user:默认值是dr.who。需要调整为启动HDFS的用户(普通用户/root),才能访问(增删文件/文件夹)WEB HDFS。
代理配置:hadoop.proxyuser.hadoop.hosts必须配,hadoop.proxyuser.hadoop.groups和hadoop.proxyuser.hadoop.users至少配置一个。如果不配置代理会有什么问题?????
hadoop.proxyuser.hadoop.hosts和hadoop.proxyuser.hadoop.users:本案例配置表示允许用户hadoop,在任意主机节点,代理任意用户。
7.2 HDFS配置文件
hdfs-default.xml:默认的HDFS属性配置文件。该配置文件位于下面的JAR文件中:hadoop-hdfs-x.x.x.jar
[hadoop@hadoop102 hadoop]$ vim hdfs-site.xml
新增内容:
<!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property>
7.3 YARN配置文件
yarn-default.xml:默认的YARN属性配置文件。该配置文件位于下面的JAR文件中:hadoop-yarn-common-x.x.x.jar
[hadoop@hadoop102 hadoop]$ vim yarn-site.xml
新增内容:
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- yarn容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
说明:
yarn.nodemanager.env-whitelist:默认JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ
yarn.scheduler.minimum-allocation-mb:单位为MB
7.4 MapReduce配置文件
mapred-default.xml:默认的MapReduce属性配置文件。该配置文件位于下面的JAR文件中:hadoop-mapreduce-client-core-x.x.x.jar
[hadoop@hadoop102 hadoop]$ vim mapred-site.xml
新增内容:
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
说明:
mapreduce.framework.name 默认值为 local,设置为 yarn,让 MapReduce 程序运行 在 YARN 框架上。
7.5 分发配置文件
[hadoop@hadoop102 hadoop]$ mytools_rsync /opt/module/hadoop-3.1.3/etc/hadoop/
八、启动集群
8.1 编辑workers文件确定数据节点
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
[hadoop@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
内容:
hadoop102
hadoop103
hadoop104
同步到所有节点:
[hadoop@hadoop102 hadoop]$ mytools_rsync /opt/module/hadoop-3.1.3/etc/
8.2 启动集群
步骤1: 格式化NameNode(首次启动集群时)
注意:在NameNode所在节点(core-site.xml中配置的)执行命令
原因:先前在care_site.xml中配置了文件系统为HDFS,HDFS类似一块磁盘,初次使用硬盘需要格式化,让存储空间明白该按什么方式组织存储数据。
[hadoop@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
看到下图样例代表格式化成功

步骤2:启动HDFS
注意:在NameNode所在节点执行命令
[hadoop@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
步骤3:启动YARN
注意:在ResourceManager所在节点(yarn-site.xml中配置的)执行命令
[hadoop@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
步骤4:测试WEB访问
(1)配置阿里云安全组
查看本机ip:百度搜索ip
配置阿里云安全组放开ip + 端口
配置本机hosts文件:用swichhosts配置
(2)浏览器访问
Web端查看HDFS的NameNode:http://hadoop102:9870
Web端查看YARN的ResourceManager:http://hadoop103:8088
九、测试集群
9.1 上传文件
上传小文件:
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/wcinput/word.txt /input
上传大文件:
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop fs -put /opt/software/jdk-8u291-linux-x64.tar.gz /
9.2 查看文件
[hadoop@hadoop102 subdir0]$ cat /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-343847855-172.28.76.203-1700227787497/current/finalized/subdir0/subdir0/blk_1073741825
9.3 下载文件
[hadoop@hadoop102 software]$ cd /opt/software/test_tmp
[hadoop@hadoop102 test_tmp]$ hadoop fs -get /input ./
9.4 执行程序
[hadoop@hadoop102 software]$ cd /opt/module/hadoop-3.1.3/
[hadoop@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
查看执行结果(通过WEB页面下载执行结果文件):
配置安全组:放开9864端口
访问HDFS WEB下载文件
查看执行结果(在服务器上直接查看文件):
cat /opt/module/hadoop-3.1.3/data/xxx
十、配置历史服务器
10.1 修改配置文件
10.2 分发配置文件
10.3 启动历史服务器
10.4 访问WEB
十一、配置日志的聚集
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
11.1 修改配置文件
11.2 分发配置文件
11.3 重启NM、RM、HistoryServer
11.4 测试
(1)删除HDFS已经存在的输出文件
(2)执行WordCount程序
(3)查看日志
相关文章:
大数据基础设施搭建 - Hadoop
文章目录 一、下载安装包二、上传压缩包三、解压压缩包四、配置环境变量五、测试Hadoop5.1 测试hadoop命令5.2 测试wordcount案例5.2.1 创建wordcount输入文本信息5.2.2 执行程序5.2.3 查看结果 六、分发压缩包到集群中其他机器6.1 分发压缩包6.2 解压压缩包6.3 配置环境变量 七…...
测试开发环境下centos7.9下安装docker的minio
按照以下方法进行 1、安装docker,要是生产等还是要按照docker-ce yum install docker 2、启动docker service docker start 3、 查看docker信息 docker info 4、加到启动里 systemctl enable docker.service 5、开始docker pull minio/minio 但报错&#x…...

Django之模版层
目录 一、常用语法 二、模版语法之变量 三、模板之过滤器(Filters) 【1】default 【2】length 【3】filesizeformat 【4】slice 【5】date 【6】safe 【7】truncatechars 【8】其它过滤器(了解) 四、模版之标签 【1】for标签 【2】if 标签…...
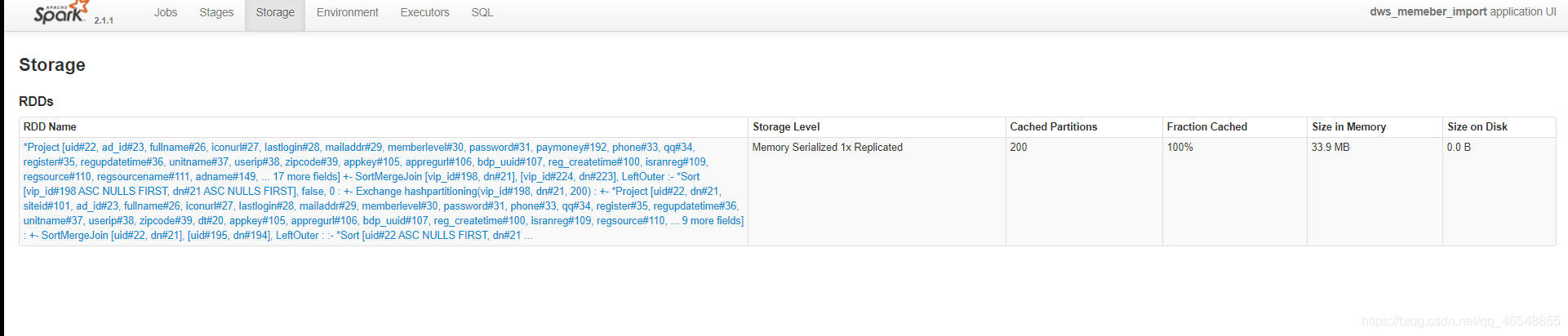
spark性能调优 | 内存优化
目录 我们先了解一下有哪些内存温馨提示RDD示范(spark版本2.1.1)RDD进行优化Df和Ds进行示范 我们先了解一下有哪些内存 1.storage内存 存储数据,缓存 可预估2.shuffle内存 计算join groupby 不可预估spark1.6之前 静态管理的,spark1.6之…...

【PG】PostgreSQL高可用之自动故障转移-repmgrd
前言 上面的几篇文章介绍了repmgr的部署,手动进行 从节点提升,主从切换,孤立从从节点找到新的主库等操作,但是都是需要通过手动去执行命令。大家都知道,在线上生产环境中数据库每秒钟的不可用都会造成严重的事故&am…...
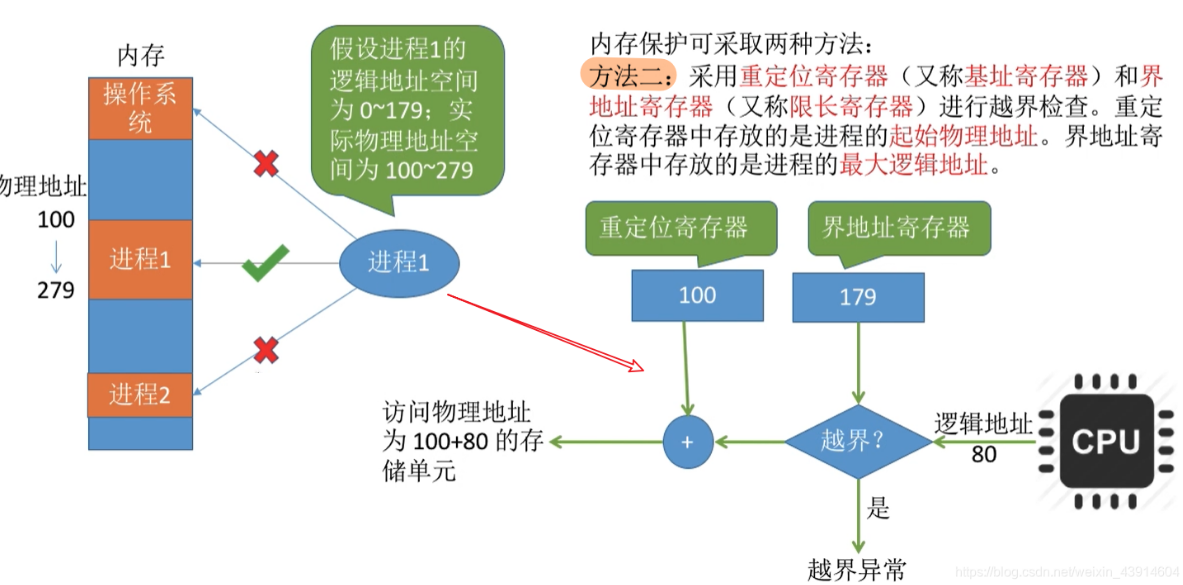
操作系统OS/存储管理/内存管理/内存管理的主要功能_基本原理_要求
基本概念 内存管理的主要功能/基本原理/要求 **内存管理的主要功能: ** 内存空间的分配与回收。由操作系统完成主存储器空间的分配和管理,使程序员摆脱存储分配的麻烦,提高编程效率。地址转换。在多道程序环境下,程序中的逻辑地…...

【手写数据库toadb】SQL解析器的实现架构,create table/insert 多values语句的解析树生成流程和输出结构分析
SQL解析器架构和实现 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定期更新,对应的代码也会定期更新,每个阶段的代码会打上tag,方…...
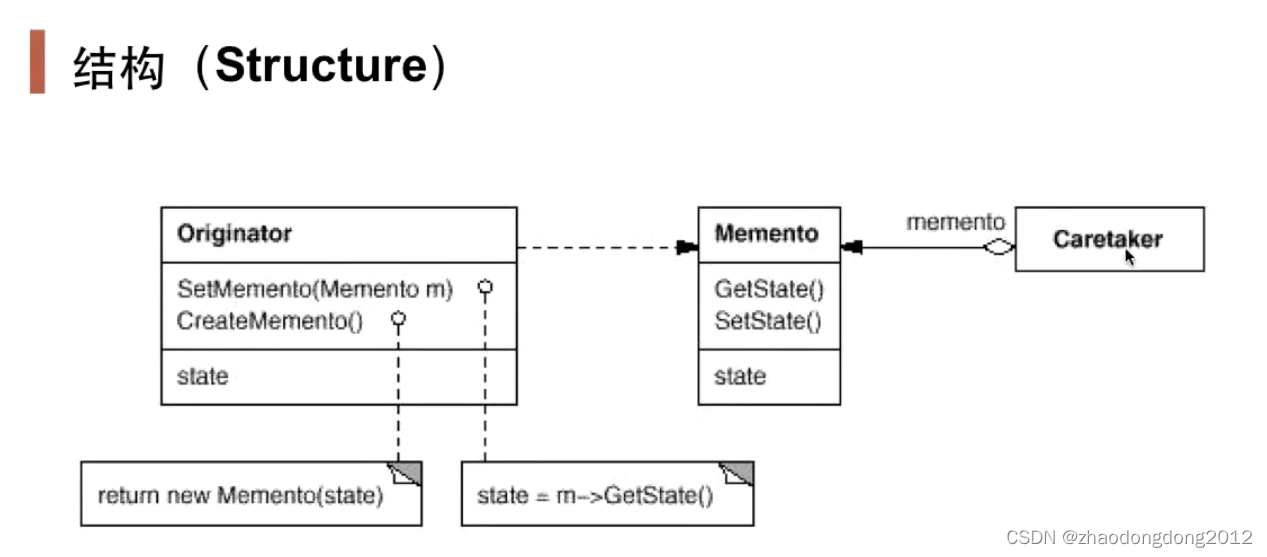
设计模式-备忘录模式-笔记
动机(Motivation) 在软件构建过程中,某些对象的状态在转换过程中,可能由于某种需要,要求程序能够回溯到对象之前处于某个点时的状态。如果使用一些公有接口来让其他对象得到对象的状态,便会暴露对象的细节…...
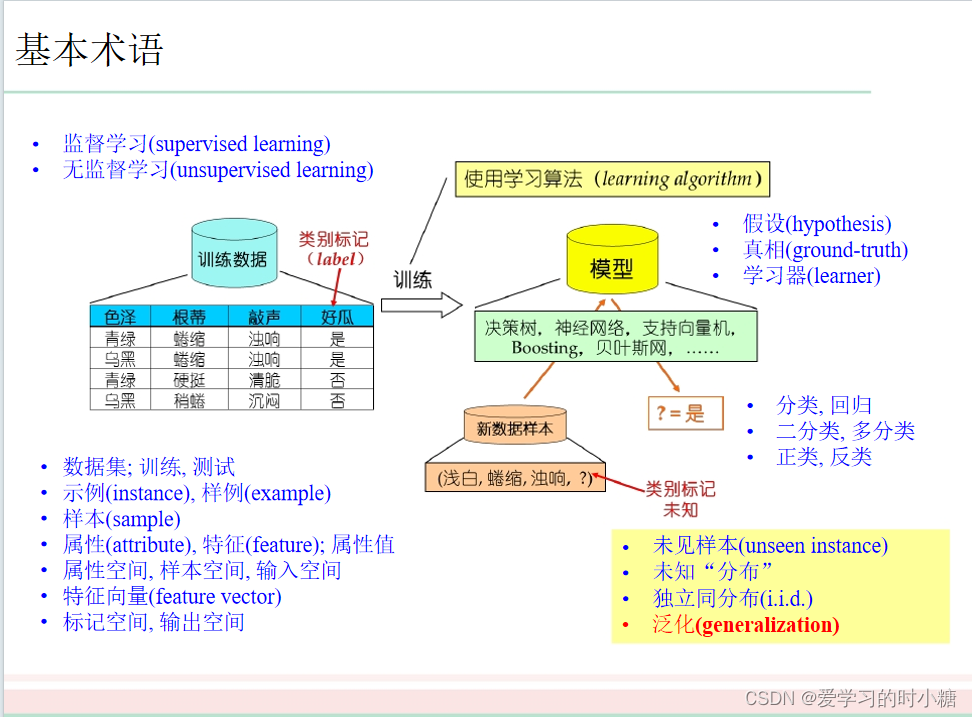
机器学习—基本术语
目录 1.样本(示例) 2.属性 3.属性值 4.属性空间 5.样本空间 6.学习(训练) 7.数据集 8.测试 9.假设 10.学习器 11.标记 12.样例 13.标记空间(样例空间) 14.分类与回归 15.有监督学习、无监督…...

pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed模型训练
pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed(环境没搞起来)模型训练代码,并对比不同方法的训练速度以及GPU内存的使用 代码:pytorch_model_train FairScale(你真…...
基于PHP的纺织用品商城系统
有需要请加文章底部Q哦 可远程调试 基于PHP的纺织用品商城系统 一 介绍 此纺织用品商城系统基于原生PHP开发,数据库mysql,前端bootstrap。用户可注册登录,购物下单,评论等。管理员登录后台可对纺织用品,用户…...

Go使用命令行输出二维码
引言 二维码(QR code)是一种矩阵条码的标准,广泛应用于商业、移动支付和数据存储等领域。在开发过程中,我们可能需要在命令行中显示二维码,这可以帮助我们快速生成和分享二维码信息。本文将介绍如何使用Go语言生成二维…...

最长连续序列[中等]
优质博文:IT-BLOG-CN 一、题目 给定一个未排序的整数数组nums,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。请你设计并实现时间复杂度为O(n)的算法解决此问题。 示例 1: 输入:nums […...
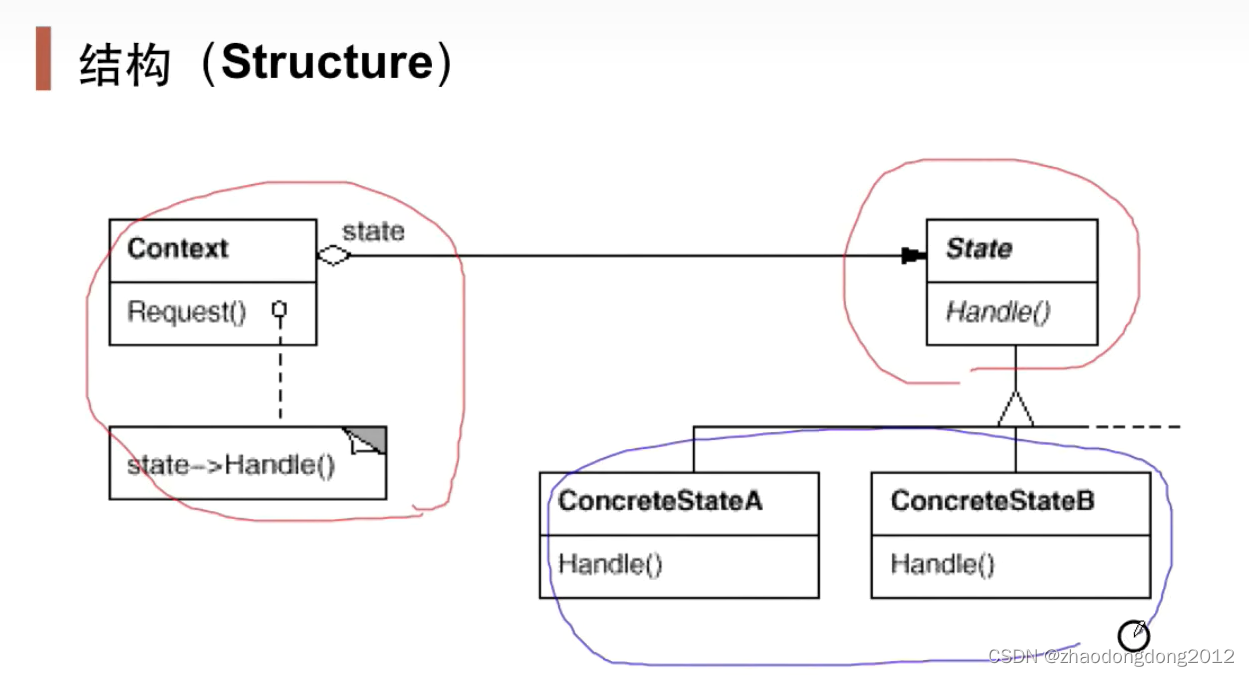
设计模式-状态模式-笔记
状态模式State 在组件构建过程中,某些对象的状态经常面临变化,如何对这些变化进行有效的管理?同时又维持高层模块的稳定?“状态变化”模式为这一问题提供了一种解决方案。 经典模式:State、Memento 动机(…...

Java中for、foreach、stream区别和性能比较
文章目录 性能比较区别使用方式和行为 性能比较 最终总结:如果数据在1万以内的话,for循环效率高于foreach和stream;如果数据量在10万的时候,stream效率最高,其次是foreach,最后是for。另外需要注意的是如果数据达到10…...
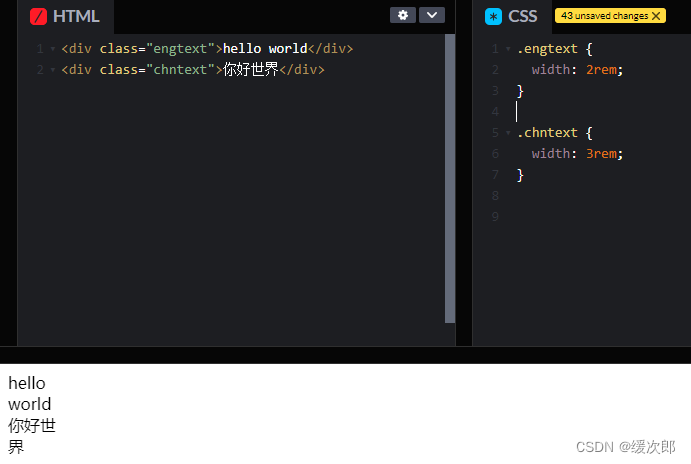
[CSS] 文本折行
文本折行一般分为两种情况: CJK(Chinese/Japanese/Korean) 字符和非 CJK 字符。一般非 CJK 字符折行发生在两个单词的空格中间,见下图: 图中文本 “hello world” 包裹容器的宽度为 2rem,但是 hello 并没有…...
)
033-从零搭建微服务-日志插件(一)
写在最前 如果这个项目让你有所收获,记得 Star 关注哦,这对我是非常不错的鼓励与支持。 源码地址(后端):mingyue: 🎉 基于 Spring Boot、Spring Cloud & Alibaba 的分布式微服务架构基础服务中心 源…...
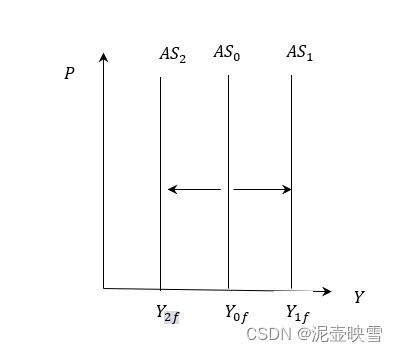
短期经济波动:均衡国民收入决定理论(三)
短期经济波动:国民收入决定理论(三) 文章目录 短期经济波动:国民收入决定理论(三)[toc]1 总需求曲线及其变动1.1 总需求曲线含义1.2 总需求曲线推导1.2.1 代数推导1.2.2 几何推导 1.3 AD曲线及其变动1.3.1 扩张性财政政策1.3.2 扩张性货币政策 2 总供给曲…...

电力感知边缘计算网关产品设计方案-网关软件架构
边缘计算网关采用ARM定制硬件平台架构,包含上位机端(内网)和FPGA网关端(外网)两部分,通过芯片间的高速信号总线实现边缘计算网关工业数据采集、数据实时传输、数据存储、网关状态信息收集等功能。 边缘计算网关上位机端(内网)重点完成工业数据采集、业务软件运算、客户…...
最新AI创作系统ChatGPT系统运营源码/支持最新GPT-4-Turbo模型/支持DALL-E3文生图
一、AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如…...

3个步骤掌握Markmap:将Markdown转换为交互式思维导图完全指南
3个步骤掌握Markmap:将Markdown转换为交互式思维导图完全指南 【免费下载链接】markmap Build mindmaps with plain text 项目地址: https://gitcode.com/gh_mirrors/ma/markmap Markmap作为一款强大的开源工具,能够将普通的Markdown文本转换为直…...

Leather Dress Collection 角色扮演效果:模拟不同风格的IT技术面试官
Leather Dress Collection 角色扮演效果:模拟不同风格的IT技术面试官 最近在玩一个挺有意思的AI工具,叫Leather Dress Collection。名字听起来有点怪,但它有个功能让我眼前一亮:角色扮演。你可以让它扮演各种角色,并且…...

Z-Image-Turbo-辉夜巫女惊艳效果:神社鸟居背景+巫女舞动姿态动态构图
Z-Image-Turbo-辉夜巫女惊艳效果:神社鸟居背景巫女舞动姿态动态构图 想看看AI如何将“辉夜巫女”的古典神秘与神社鸟居的庄严宁静完美融合,并赋予其灵动的舞姿吗?今天,我们就来深度体验一个名为“Z-Image-Turbo-辉夜巫女”的专属…...

重装系统后的环境快速恢复:包含BERT模型部署的自动化脚本
重装系统后的环境快速恢复:包含BERT模型部署的自动化脚本 重装系统,对开发者来说,就像一场“数字大扫除”。清爽是清爽了,但看着空空如也的终端和待部署的一长串服务列表,那种从头再来的疲惫感瞬间涌上心头。尤其是当…...
为什么MedNeXt能超越Transformer?揭秘大卷积核在医学图像分割中的独特优势
MedNeXt如何用大卷积核重塑医学图像分割?技术优势全解析 当你在深夜的医院影像科,看着屏幕上模糊的CT扫描图,试图从那些灰度渐变中分辨出肿瘤边界时,是否会想过AI模型眼中的世界?医学图像分割——这个决定患者治疗方案…...

Qwen3-TTS快速部署教程:一键启动Web服务,3分钟开始声音克隆
Qwen3-TTS快速部署教程:一键启动Web服务,3分钟开始声音克隆 1. 为什么选择Qwen3-TTS进行语音克隆 想象一下这样的场景:你需要为海外客户录制多语言产品介绍,但雇佣专业配音演员成本高昂;或者想为自己的视频内容添加个…...

AI读脸术备份恢复指南:手把手教你搭建高可用人脸识别服务
AI读脸术备份恢复指南:手把手教你搭建高可用人脸识别服务 1. 项目背景与需求分析 人脸识别技术已经成为现代数字服务的重要组成部分,从电商个性化推荐到智能安防系统,都依赖这项技术的稳定运行。AI读脸术镜像基于OpenCV DNN深度神经网络构建…...

忍者像素绘卷微信小程序接入:用户提示词历史+生成图云存储方案
忍者像素绘卷微信小程序接入:用户提示词历史生成图云存储方案 1. 项目背景与核心价值 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工作站,将16-Bit复古游戏美学与现代AI图像生成技术完美结合。这款工具特别适合创作具有忍者主题和复古像素…...

从synchronized到CompletableFuture:Java多线程完全进阶指南
在当今多核处理器普及的计算时代,充分利用硬件资源成为提升程序性能的关键。Java作为企业级应用的主流语言,其内置的多线程支持让并发编程变得触手可及。然而,多线程编程如同一把双刃剑——用得好,能成倍提升系统吞吐量࿱…...
)
BH1750光照传感器避坑指南:STM32的I2C通信那些事儿(附STM32F407调试心得)
BH1750光照传感器实战避坑:STM32 I2C通信深度解析与调试技巧 第一次用STM32驱动BH1750光照传感器时,我盯着纹丝不动的数据寄存器发呆了半小时——I2C总线明明显示通信成功,但读回来的光照值永远是零。这种看似简单却暗藏玄机的外设调试经历&a…...