ClickHouse的分片和副本
1.副本
副本的目的主要是保障数据的高可用性,即使一台ClickHouse节点宕机,那么也可以从其他服务器获得相同的数据。
Data Replication | ClickHouse Docs
1.1 副本写入流程
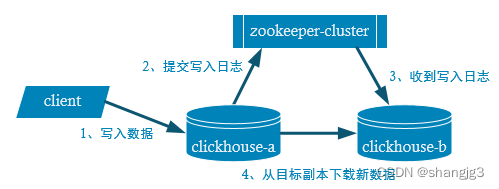
1.2 配置步骤
(1)启动zookeeper集群
(2)在hadoop102的/etc/clickhouse-server/config.d目录下创建一个名为metrika.xml的配置文件,内容如下:
注:也可以不创建外部文件,直接在config.xml中指定<zookeeper>
<?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
(3)同步到hadoop103和hadoop104上
sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.d/metrika.xml
(4)在 hadoop102的/etc/clickhouse-server/config.xml中增加
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>

(5)同步到hadoop103和hadoop104上
sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.xml
分别在hadoop102和hadoop103上启动ClickHouse服务
注意:因为修改了配置文件,如果以前启动了服务需要重启
[atguigu@hadoop102|3 ~]$ sudo clickhouse restart
注意:我们演示副本操作只需要在hadoop102和hadoop103两台服务器即可,上面的操作,我们hadoop104可以你不用同步,我们这里为了保证集群中资源的一致性,做了同步。
(6)在hadoop102和hadoop103上分别建表
副本只能同步数据,不能同步表结构,所以我们需要在每台机器上自己手动建表
①hadoop102
create table t_order_rep2 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_102')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
②hadoop103
create table t_order_rep2 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_103')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
③参数解释
ReplicatedMergeTree 中,
第一个参数是分片的zk_path一般按照: /clickhouse/table/{shard}/{table_name} 的格式写,如果只有一个分片就写01即可。
第二个参数是副本名称,相同的分片副本名称不能相同。
(7)在hadoop102上执行insert语句
insert into t_order_rep2 values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00');

(8)在hadoop103上执行select,可以查询出结果,说明副本配置正确

2.分片集群
副本虽然能够提高数据的可用性,降低丢失风险,但是每台服务器实际上必须容纳全量数据,对数据的横向扩容没有解决。
要解决数据水平切分的问题,需要引入分片的概念。通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过Distributed表引擎把数据拼接起来一同使用。
Distributed表引擎本身不存储数据,有点类似于MyCat之于MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
注意:ClickHouse的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分片,避免降低查询性能以及操作集群的复杂性。
2.1 集群写入流程(3分片2副本共6个节点)

2.2 集群读取流程(3分片2副本共6个节点)

2.3 3分片2副本共6个节点集群配置(供参考)
配置的位置还是在之前的/etc/clickhouse-server/config.d/metrika.xml,内容如下
注:也可以不创建外部文件,直接在config.xml的<remote_servers>中指定
<yandex>
<remote_servers>
<gmall_cluster> <!-- 集群名称-->
<shard> <!--集群的第一个分片-->
<internal_replication>true</internal_replication>
<!--该分片的第一个副本-->
<replica>
<host>hadoop101</host>
<port>9000</port>
</replica>
<!--该分片的第二个副本-->
<replica>
<host>hadoop102</host>
<port>9000</port>
</replica>
</shard>
<shard> <!--集群的第二个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>hadoop103</host>
<port>9000</port>
</replica>
<replica> <!--该分片的第二个副本-->
<host>hadoop104</host>
<port>9000</port>
</replica>
</shard>
<shard> <!--集群的第三个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>hadoop105</host>
<port>9000</port>
</replica>
<replica> <!--该分片的第二个副本-->
<host>hadoop106</host>
<port>9000</port>
</replica>
</shard>
</gmall_cluster>
</remote_servers>
</yandex>
2.4 配置三节点版本集群及副本
2.4.1 集群及副本规划(2个分片,只有第一个分片有副本)

| hadoop102 | hadoop103 | hadoop104 |
| <macros> <shard>01</shard> <replica>rep_1_1</replica> </macros> | <macros> <shard>01</shard> <replica>rep_1_2</replica> </macros> | <macros> <shard>02</shard> <replica>rep_2_1</replica> </macros> |
2.4.2 配置步骤
1)在hadoop102的/etc/clickhouse-server/config.d目录下创建metrika-shard.xml文件
注:也可以不创建外部文件,直接在config.xml的<remote_servers>中指定
<?xml version="1.0"?>
<yandex>
<remote_servers>
<gmall_cluster> <!-- 集群名称-->
<shard> <!--集群的第一个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>hadoop102</host>
<port>9000</port>
</replica>
<replica> <!--该分片的第二个副本-->
<host>hadoop103</host>
<port>9000</port>
</replica>
</shard>
<shard> <!--集群的第二个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>hadoop104</host>
<port>9000</port>
</replica>
</shard>
</gmall_cluster>
</remote_servers>
<zookeeper-servers>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<shard>01</shard> <!--不同机器放的分片数不一样-->
<replica>rep_1_1</replica> <!--不同机器放的副本数不一样-->
</macros>
</yandex>
2)将hadoop102的metrika-shard.xml同步到103和104
sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.d/metrika-shard.xml

3)修改103和104中metrika-shard.xml宏的配置
(1)103
[atguigu@hadoop103 ~]$ sudo vim /etc/clickhouse-server/config.d/metrika-shard.xml

(2)104
[atguigu@hadoop104 ~]$ sudo vim /etc/clickhouse-server/config.d/metrika-shard.xml

4)在hadoop102上修改/etc/clickhouse-server/config.xml

5)同步/etc/clickhouse-server/config.xml到103和104
[atguigu@hadoop102 ~]$ sudo /home/atguigu/bin/xsync /etc/clickhouse-server/config.xml
6)重启三台服务器上的ClickHouse服务
[atguigu@hadoop102 clickhouse-server]$ sudo clickhouse restart
[atguigu@hadoop102 clickhouse-server]$ ps -ef |grep click

7)在hadoop102上执行建表语句
- 会自动同步到hadoop103和hadoop104上
- 集群名字要和配置文件中的一致
- 分片和副本名称从配置文件的宏定义中获取
create table st_order_mt on cluster gmall_cluster (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);

可以到hadoop103和hadoop104上查看表是否创建成功


8)在hadoop102上创建Distribute 分布式表
create table st_order_mt_all2 on cluster gmall_cluster
(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
)engine = Distributed(gmall_cluster,default, st_order_mt,hiveHash(sku_id));
参数含义:
Distributed(集群名称,库名,本地表名,分片键)
分片键必须是整型数字,所以用hiveHash函数转换,也可以rand()

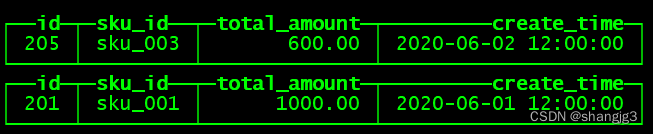
9)在hadoop102上插入测试数据
insert into st_order_mt_all2 values
(201,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(202,'sku_002',2000.00,'2020-06-01 12:00:00'),
(203,'sku_004',2500.00,'2020-06-01 12:00:00'),
(204,'sku_002',2000.00,'2020-06-01 12:00:00'),
(205,'sku_003',600.00,'2020-06-02 12:00:00');
10)通过查询分布式表和本地表观察输出结果
(1)分布式表
SELECT * FROM st_order_mt_all;
(2)本地表
select * from st_order_mt;
(3)观察数据的分布
| st_order_mt_all |
|
| hadoop102: st_order_mt |
|
| hadoop103: st_order_mt |
|
| hadoop104: st_order_mt |
|



2.5 项目为了节省资源,就使用单节点,不用集群
不需要求改文件引用,因为已经使用集群建表了,如果改为引用metrika-shard.xml的话,启动会报错。我们以后用的时候只启动102即可。
相关文章:
ClickHouse的分片和副本
1.副本 副本的目的主要是保障数据的高可用性,即使一台ClickHouse节点宕机,那么也可以从其他服务器获得相同的数据。 Data Replication | ClickHouse Docs 1.1 副本写入流程 1.2 配置步骤 (1)启动zookeeper集群 (2&…...
)
C语言编程陷阱(五)
陷阱21:不要使用逗号运算符代替分号 C语言中,我们可以使用分号来结束一个语句,比如a = b;,这样可以让编译器知道语句的边界,以及执行的顺序。但是,如果我们想要在一个语句中执行多个表达式,就可以使用逗号运算符,比如a = (b = c, c + 1);,这样可以让编译器按照从左到右…...

chardet检测文件编码,使用生成器逐行读取文件
detect_encoding 函数使用 chardet 来检测文件的编码。然后,在 process_large_file 函数中,根据检测到的编码方式打开文件。这样,你就能够更准确地处理不同编码的文件。 import chardetdef detect_encoding(file_path):with open(file_path,…...

html所有标签和DOCTYPE的总结
一、DOCTYPE 1. 意义 DOCTYPE是一种标准通用标记语言的文档类型声明,告诉标准通用标记语言解析器它应该使用什么样的文档类型定义来解析文档。 2. 应用 现在,我们需要告诉标准通用标记语言解析器,我们接下去要用html来编写代码了。 <…...
2023年11月15号期中测验判断题(Java)
1-1 局部变量可以与成员变量重名。 正确答案:T 解释: 局部变量可以和成员变量重名,通常,为了区分局部变量和成员变量,会使用this关键字(C称this指针,python是self关键字)来特别声…...
基于 selenium 实现网站图片采集
写在前面 有小伙伴选题,简单整理理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对…...

vue3相关内容
ref声明/赋值 操作基本类型数据 string number // 引入方法 import {ref} from vue // 声明变量 const name ref(A) // 修改值 name.value Breactive声明/赋值 操作引用类型数据 array object proxy不能直接赋值,会破坏响应式对象 // 引入方法 import {reacti…...

AWTK实现汽车仪表Cluster/DashBoard嵌入式GUI开发(七):FreeRTOS移植
前言: 一般的GUI工程都需要一个操作系统,可能是linux,重量级的,也可能是FreeRTOS,轻量级的。 一句话理解那就是工程就是FreeRTOS task任务的集合。 一个main函数可以看到大框架: 很显然,除了第一个是硬件配置的初始化,中间最重要的部分就是要创建任务,把AWTK的应用…...
《洛谷深入浅出进阶篇》P1995 程序自动分析——并查集,离散化
上链接:P1955 [NOI2015] 程序自动分析 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)https://www.luogu.com.cn/problem/P1955 上题干: 首先给你一个整数t,代表t次操作。 每一次操作包含以下内容: 1.给你一个整数n,让…...

基于单片机的自动循迹小车(论文+源码)
1.系统设计 此次基于单片机的自动循迹小车的设计系统,结合循迹模块来共同完成本次设计,实现小车的循迹功能,其其整体框架如图2.1所示。其中,采用STC89C52单片机来作为核心控制器,负责将各个传感器等模块链接起来&…...

linux系统中安装python到指定目录
Linux系统中安装python 下载Python源码包 根据服务器系统和需要的Python版本,在Python官网下载对应的Python源码包。 安装依赖(需要权限) yum install gcc gcc-c patch libffi-devel python-devel zlib-devel bzip2-devel openssl-devel…...
分布式事务 - seata安装
分布式事务 - seata 一、本地事务与分布式事务 1.1、本地事务 本地事务,也就是传统的单机事务。在传统数据库事务中,必须要满足四个原则(ACID)。 1.2、分布式事务 分布式事务,就是指不是在单个服务或单个数据库架构…...
CentOS to 浪潮信息 KeyarchOS 迁移体验与优化建议
浪潮信息KeyarchOS简介 KeyarchOS即云峦操作系统(简称KOS), 是浪潮信息研发的一款面向政企、金融等企业级用户的 Linux 服务器操作系统。它基于Linux内核、龙蜥等开源技术,支持x86、ARM 等主流架构处理器,其稳定性、安全性、兼容性和性能等核心能力均已…...

Go解析soap数据和修改其中数据
一、解析soap数据 package main import ("fmt" "encoding/xml" ) type Envelope struct { XMLName xml.Name Header Header } type Header struct { XMLName xml.Name xml:"Header" Security Security xml:"Security" } type Secu…...

LeetCode98. Validate Binary Search Tree
文章目录 一、题目二、题解 一、题目 Given the root of a binary tree, determine if it is a valid binary search tree (BST). A valid BST is defined as follows: The left subtree of a node contains only nodes with keys less than the node’s key. The right sub…...

【LeetCode】206. 反转链表
206. 反转链表 难度:简单 题目 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 示例 1: 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1]示例 2: 输入:head [1,2] 输…...

飞天使-通过GET 和POST进案例演示
文章目录 GETPOST GET def index(request):# 在url中获取学号sno request.GET.get("sno", None)print("学号为:",sno)# 判断学号如果有值,执行查询if sno:results get_student_by_sno(sno)# 展示在页面return render(request, ind…...
【MySql】12- 实践篇(十)
文章目录 1. 为什么临时表可以重名?1.1 临时表的特性1.2 临时表的应用1.3 为什么临时表可以重名?1.4 临时表和主备复制 2. MySql内部临时表使用场景2.1 union 执行流程2.2 group by 执行流程2.3 group by 优化方法 -- 索引2.4 group by 优化方法 -- 直接排序 3. Me…...

<C++> 反向迭代器
我们知道正向迭代器的设计:begin迭代器指向第一个数据,end迭代器指向最后一个数据的下一个位置 。移向下一个数据,解引用得到数据的值,并根据容器储存方式的不同,容器有不同类型的迭代器。 注意:rbegin迭代…...

【EI会议征稿】第三届网络安全、人工智能与数字经济国际学术会议(CSAIDE 2024)
第三届网络安全、人工智能与数字经济国际学术会议(CSAIDE 2024) 2024 3rd International Conference on Cyber Security, Artificial Intelligence and Digital Economy 第三届网络安全、人工智能与数字经济国际学术会议(CSAIDE 2024&#…...
)
Python实战:3种高效连接ClickHouse的方法对比(附性能测试)
Python实战:3种高效连接ClickHouse的方法对比(附性能测试) 在数据分析领域,ClickHouse凭借其卓越的列式存储和向量化执行引擎,已成为处理海量数据的首选解决方案之一。而Python作为数据科学家的瑞士军刀,如…...
—— 告别报错!Error in if (out == “[]“) 深度解析与TwoSampleMR参数调优全攻略)
孟德尔随机化实战(五)—— 告别报错!Error in if (out == “[]“) 深度解析与TwoSampleMR参数调优全攻略
1. 报错现象深度解析:为什么会出现"参数长度为零"? 最近在孟德尔随机化分析交流群里,这个报错出现的频率简直高得离谱:"Error in if (out "[]") { : argument is of length zero"或者它的中文版&q…...

药物发现必备:RDKit分子指纹在虚拟筛选中的7种高级用法
药物发现必备:RDKit分子指纹在虚拟筛选中的7种高级用法 在当今药物研发领域,虚拟筛选已成为加速药物发现流程的关键技术。面对海量化合物库,如何高效准确地识别潜在活性分子?RDKit分子指纹技术提供了强有力的解决方案。不同于基础…...

M2LOrder模型管理实战:Python脚本自动扫描/opt目录并生成模型索引表
M2LOrder模型管理实战:Python脚本自动扫描/opt目录并生成模型索引表 1. 项目背景与需求 在实际的AI模型部署和维护过程中,我们经常会遇到模型文件分散存储、版本混乱、信息不透明的问题。M2LOrder情感识别系统就是一个典型的例子,它包含了9…...
)
Xilinx Video IP实战:如何将HDMI输入转换为AXI4-Stream(附仿真+上板测试)
Xilinx Video IP实战:HDMI转AXI4-Stream全流程开发指南 在FPGA视频处理系统中,将HDMI等视频输入接口转换为标准化的AXI4-Stream协议是构建复杂视频处理流水线的关键第一步。不同于简单的接口转换,这一过程涉及视频时序解析、数据位宽适配、时…...

嵌入式系统调试常见问题与解决方案
嵌入式系统调试中的典型问题分析与解决策略1. 常见调试问题案例分析1.1 程序文件版本错误在嵌入式开发过程中,一个常见的低级错误是使用了错误的程序文件版本。某工程师在调试时发现单片机完全不执行程序,即使是最基本的GPIO控制也无法实现。经过以下排查…...

彻底解决Windows 11系统稳定性问题:ExplorerPatcher核心技术解析与实战指南
彻底解决Windows 11系统稳定性问题:ExplorerPatcher核心技术解析与实战指南 【免费下载链接】ExplorerPatcher 提升Windows操作系统下的工作环境 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 当你的Windows 11系统频繁出现界面无响应…...
)
Nuitka打包Python脚本为.exe的完整避坑指南(含Selenium解决方案)
Nuitka打包Python脚本为.exe的完整避坑指南(含Selenium解决方案) 将Python脚本打包成独立的可执行文件是许多开发者面临的常见需求,尤其是当需要分发工具或应用给没有Python环境的用户时。Nuitka作为一款强大的Python编译器,能够将…...

别再死记硬背了!用Python脚本+Modbus Poll工具,5分钟搞懂Modbus功能码怎么用
用PythonModbus Poll实战:5分钟解锁功能码核心逻辑 第一次接触Modbus协议时,那些晦涩的功能码总让我头疼——01H、03H、05H这些十六进制代码就像天书,文档里的理论描述看完就忘。直到我发现用Python脚本配合Modbus Poll工具进行实操测试&…...

Claude浏览器扩展漏洞允许通过任意网站实现零点击XSS提示注入
网络安全研究人员披露了Anthropic公司Claude谷歌浏览器扩展中存在的一个漏洞,攻击者只需诱使用户访问特定网页即可触发恶意提示注入。漏洞原理分析Koi Security研究员Oren Yomtov在提供给The Hacker News的报告中指出:"该漏洞允许任何网站静默地向该…...